

Не подлежит сомнению, что высококачественные размеченные массивы данных играют критичную роль в разработке новых алгоритмов глубокого обучения. Однако понимание ML и глубокого обучения по-прежнему остаётся в зачаточном состоянии. Именно поэтому команды прикладного ML и исследований ML нашей компании совместно трудятся над пониманием последних исследований в сфере ML, пытаясь разобраться, как мы можем преодолеть одну из самых больших сложностей в современной разработке ИИ, как у наших клиентов, так и для отрасли в целом.
Недавно наша команда исследователей провела глубокий анализ состояния данных в области компьютерного зрения. Исследовательская статья, одобренная для Human-in-the-Loop Learning Workshop на ICML 2021, показала, что высококачественная разметка по-прежнему остаётся незаменимой для разработки точных моделей глубокого обучения.
Полную статью можно найти здесь.
В этом посте мы вкратце расскажем об её основных выводах:
- О влиянии размера и качества массива данных на точность и надёжность модели;
- об эффективности предварительного обучения;
- об успехах и сложностях, с которыми сталкиваются синтетические массивы данных;
- про обучение с самоконтролем;
- о непрерывном обучении и о его связи с большими массивами данных; а также
- о явлении двойного снижения
Наш ключевой вывод заключается в том, что высококачественные аннотации остаются незаменимыми для разработки точных моделей глубокого обучения.
Компромисс между предварительным обучением и точной настройкой размеров массивов данных
Допустим, у нас есть фиксированный бюджет на разметку. Что будет выгоднее сделать: выделить средства на разметку обобщённого массива данных, например, классификации, или сосредоточиться на более специфическом массиве, например, на сегментации и распознавании объектов?
В нашем исследовании мы выяснили, что предварительное обучение в ImageNet не помогает при тонкой настройке под другую задачу, а именно под распознавание объектов в MSCOCO. В частности, при использовании менее чем 10% от массива данных COCO мы наблюдали существенное снижение точности. Однако при сравнении метрик AP@50 и AP мы выяснили, что предварительное обучение может помочь модели достигать улучшенной классификации (та же задача, что и в предварительном обучении), но не локализации (другая задача). Если модели обучаются до насыщения, они проявляют ту же степень точности; тем не менее, предварительно обученная модель может достигать той же точности при меньшем количестве итераций.
Эффект предварительного обучения
В этом разделе мы провели исследование при помощи JFT-300M и массива данных Instagram, поскольку это одни из самых крупных массивов. JFT-300M содержит 300 миллионов изображений с 375 миллионами шумных меток из 18291 класса. Массив Instagram содержит 3,5 миллиарда изображений с 17 тысячами классов и неизвестным количеством шума меток. Главный вывод заключался в том, что если предварительное обучение схоже с целевыми задачами, то предварительное обучение на крупных массивах данных однозначно помогает. Также мы наблюдали три явления:
- Точность модели растёт как логарифмическая функция от размера массива данных предварительного обучения.
- Достаточно большой размер модели критически важен для обеспечения роста точности, вызываемого предварительным обучением на больших массивах данных.
- Гиперпараметр во время предварительного обучения может сильно отличаться от обучения на целевых задачах.
Синтетические массивы данных
Синтетические массивы данных — привлекательный путь, когда сбор реальных данных невозможен. Однако хорошо известно, что глубокие нейронные сети чувствительны к изменению распределения. Модель, обученную на синтетическом массиве данных, всё равно нужно подстраивать на реальных данных. Рихтер и соавторы выяснили, что в случае задач в сфере беспилотного вождения всего одна треть реальных данных вместе с синтетическими рендерами из видеоигрового движка могут обойти по точности обучение только на реальных данных. Однако реальные данные всё равно были критически важны для достижения такой точности, повысив результаты обучения на синтетических данных на более чем 20%.
Обучение с самоконтролем
В недавних статьях обучение с самоконтролем (self-supervised learning) демонстрировало превосходные результаты. В сочетании с простым линейным классификатором или регрессором эти модели можно использовать для выполнения downstream tasks с высокой точностью. Наша цель заключалась в ответе на вопрос, полезен ли самоконтроль, когда для downstream tasks существуют большие размеченные массивы данных. В статье Хендрикса и соавторов было выявлено, что обучение с самоконтролем не повышает точность, но увеличивает надёжность при работе с шумными метками, вредными примерами и искажёнными входящими данными.
В задачах NLP самоконтроль стал ключевым аспектом современных структур моделей наподобие BERT, RoBERTa и XLM. Эти модели обучены прогнозировать замаскированные или удалённые слова или токены. В области компьютерного зрения хорошие результаты, которые можно использовать в качестве фундамента для классификаторов, показывает контрастное обучение. В конечном итоге, обучение с самоконтролем может снизить количество аннотаций, требуемых для обучения, но его лучше всего использовать в тандеме с полностью контролируемым обучением.
Непрерывное обучение
Отрасль беспилотного вождения — выдающийся пример непрерывного и постоянного глубокого обучения. В процессе сбора транспортными средствами новых данных изображения с определённым состоянием отказа могут запрашиваться из потока данных и повторно размечаться людьми. После этого модель может обучаться этим состояниям отказа и снова разворачиваться в транспортных средствах. Такой цикл позволяет модели непрерывно совершенствовать свою точность.
Однако при непрерывном обучении моделей может произойти катастрофическое забывание (catastrophic forgetting), из-за которого модель перестаёт иметь высокую точность на предыдущих данных. При помощи методики pseudo-rehearsal и методики на основе регуляризации можно компенсировать катастрофическое забывание, однако ни одно современное исследование не может решить эту проблему.
Двойное снижение
Явление двойного снижения (double descent) постулирует, что модели среднего размера более предрасположены к чрезмерному обучению, чем модели меньшего и большего размера. С увеличением сложности модели ошибка тестирования изначально является большим числом, потом уменьшается, увеличивается, а затем, наконец, снова уменьшается.
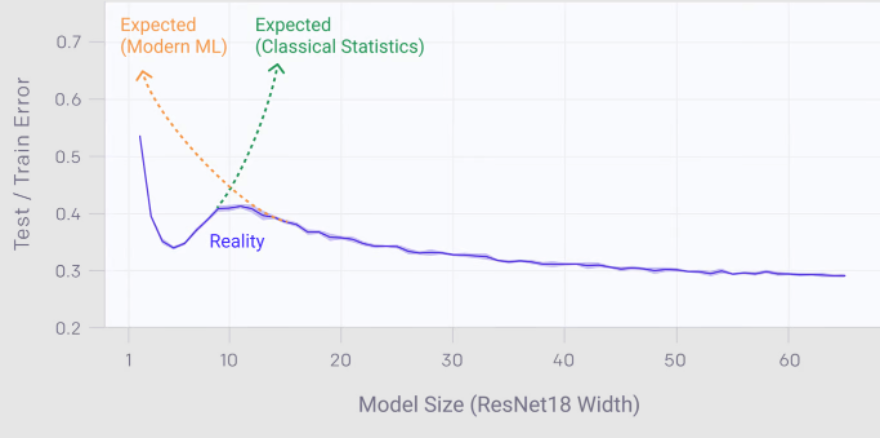
Когда используется ранняя остановка (early stopping) явление двойного снижения оказывается менее выраженным. Хотя по-прежнему есть много неотвеченных вопросов об оптимальных размерах моделей при небольших объёмах данных, мы далеки от насыщения при больших объёмах данных. В целом, можно сделать вывод, что при наличии достаточного количества размеченных данных с малым шумом меток крупные модели, обученные с ранней остановкой, обычно превосходят по показателям модели меньшего размера.
Заключение
В конечном итоге, обучение на кажущихся бесконечными данных — сложная задача, и мы только начинаем осознавать его плюсы и минусы. Хотя обучение в таком режиме затратно и требует существенных вычислительных ресурсов, мы считаем, что в долговременной перспективе стоимость каждого этапа будет уменьшаться. Мы видим надежду в новых технологиях, например, в крупномасштабном обучении с самоконтролем. Но на современном этапе развития исследований и технологий обучение с human-in-the-loop, в том числе и с аннотированием данных, будет оставаться незаменимым при глубоком обучении моделей на различных задачах машинного обучения.
Полную исследовательскую статью можно прочитать в Arxiv.