
Давайте вместе попробуем создать основы большой базы данных, с помощью готового dataset. Для поиска нужного нам материала воспользуемся помощью прекрасного ресурса KAGGLE
Что такое Kaggle

Kaggle - - платформа созданная для проведение конкурсов по исследованию данных. Организаторы выкладывают Datasets , описывают задачи , метрики по которым будут выявляться победители конкурса , призы и время проведения. Каждый желающий может выставить свою работа по этим данных , красиво описать её , показать свои умения и надеяться на победу.
Мы будем использовать Used Cars Dataset
Также мы можем посмотреть Code других участников соревнования
подчерпнуть оттуда интересную информацию
найти нестандартные подходы к обработке данных
На примере других работа , научиться чему-то новому
и даже наткнуться на
боже зачем это тут ?интересную работу по ''Ускорение рабочего процесса Pandas с Modin''
Можем посмотреть Обсуждения
Найти друзейЗаставить других сделать свою работуУзнать ответ на интересующий тебя вопрос(есть шанс)
Перейдём к делу, Pgadmin4

pgAdmin — это платформа с открытым исходным кодом для администрирования и разработки на PostgreSQL и связанных с ней систем управления базами данных.
pgAdmin будет предложен в установке PostgreSQL, я пользуюсь 14.3. Багов и проблем не боюсь , беру самую новую версию сразу видно профессионал. Если боитесь устанавливать приложение без ведения за ручку , вам поможет интернет()_(). Уже 1000 раз было рассказывать как это делать и что за чему , так что не буду тратить наше драгоценное.
Перейдём к делу 2, Python

Python - - высокоуровневый язык программирования. и нам нужна библиотека pandas
Перейдём к делу 3, Pycharm

Pycharm - - среда разработки(IDE) созданная специально для языка программирования Python.
Предоставляет средства для анализа кода
графический отладчик
инструменты для отладки юнит-тестов
интуитивно понятный интерфейс
очень много полезных функций для продвинутых пользователей
Начнём кодить(0)_(з)
экспорт данных + получение основной информации
для начала открываем Pycharm, создаём там новый проект и в терминале инсталлируем библиотеку pаndas Открываем терминал и пишем там pip install pandas, нажимаем enter и ждём установки.
pip install pandasДалее нам надо открыть для чтения наш файл -
import pandas as pd
# загружаем наш csv
car = pd.read_csv(r'C:\Users\ratmu\PycharmProjects\Cars\vehicles.csv')
# просмотр первыйх 5 строк
print(car.head(5))

видим что из-за 26 столбцов, Pycharm не подгружает всё таблицу( в дальнейшем исправим)
# Cведения о датафрейме, выходит общая информация о нём вроде заголовка, количества значений, типов данных столбцов.
print(car.info())
Получаем основные данные из таблицы.
Название всех столбцов
Количество значений в них
Типы данных
# загружаем нашу csv , смотрим тольна на первые 100 строк ибо долго грузиться полный файл )
car = pd.read_csv(r'C:\Users\ratmu\PycharmProjects\Cars\vehicles.csv',nrows=100)
# просмотр всей таблици без ограничений колличество знаков , на строку)
print(car.to_csv(None))
Получаем гигантский DF который я не могу передать как картинку , так что переходим сразу обработке этих данных
Очистка данных
Убирает лишние столбцы
Нам точно не нужны url ссылки, и пустая строка country , так же нам не надо описание автомобиля на 1000+ символов(description) Так что пишемс простой код
import pandas as pd
# загружаем нашу csv
car = pd.read_csv(r'C:\Users\ratmu\PycharmProjects\Cars\vehicles.csv')
# удлаляем столбци с которыми не будем работать
car.drop(['description', 'county', 'url', 'region_url', 'image_url', 'posting_date'], axis=1, inplace=True)drop удаления столбцов , Axis: указывает, что столбцы или строки должны быть удалены, inplace = True, он возвращает Data Frame с удаленными столбцами или None
После этого сохраняем наш изменённый df в новый файл , что бы в дальнейшем работать только с нужными данными
# сохраняем обработанный df в csv файл
car.to_csv('car_info.csv')Убираем выбросы
Выбросы - - это данные, которые существенно отличаются от других наблюдений. Они могут соответствовать реальным отклонениям, но могут быть и просто ошибками
Нас интересуют выбросы в колонке price, согласитесь если цена на машину будет 5 000 000 000 долларов это будет сильно менять среднее значение цены и мешать нашим вычислениям
Находим выбросы
Узнаем самые часто встречаемые цены с помощью value_counts И_И узнаем статистику по цене в нашем df с помощью describe
print(car['price'].value_counts().iloc[:5])
print(car.price.describe())
слева видим что у нас есть 32к значений = 0, которые стоят обрезать , и множество значений цены = около 3к
справа у нас показатели зашкаливают и выдают огромные цифры. ЧТО ТО ТУТ НЕ ТАК!!!
А теперь сделаем грубую и ужасную профессиональную вырезку. Я называю её "и так сойдёт"(объясняю, мы как бы не готовим данные для отчётов и т.д , а просто убираем самый явный бред)
Импортируем 2 крутые штуки seaborn
pip install seaborn
pip install matplotlibТеперь в шапку нашего кода добавляем
import matplotlib.pyplot as plt
import seaborn as snsСтроем простецкий графии
plt.figure(figsize=(5,8))
sns.boxplot(y='price', data=car,showfliers=True)
plt.show()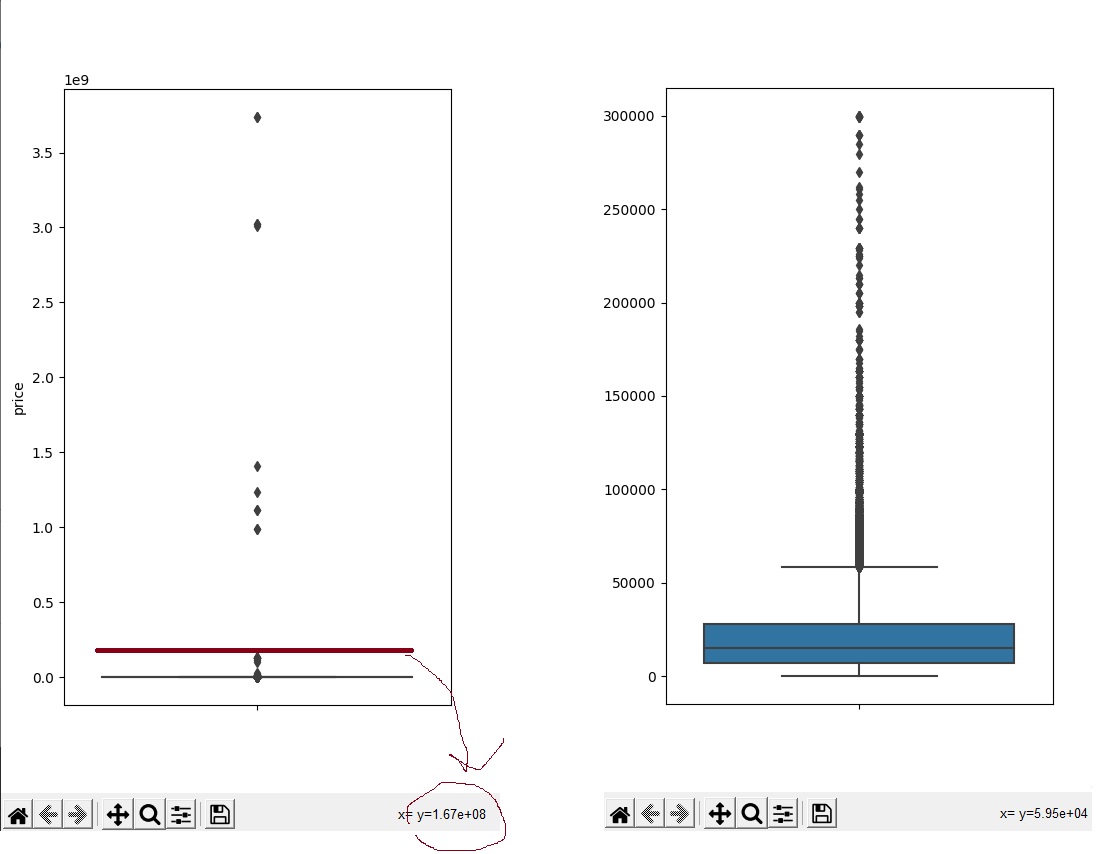
Тут мы смотря на значения Y будем постепенно обрезать наши выбросы , пока они не станут чуть-чуть адекватными( код ниже)
Убираем выбросы
# price > 300000 если труе обрезаем ( а эту цифру берём из значение Y с графика выше)
car.drop(car[car.price > 300000].index, inplace = True)
# + убираем все лишнии значения
car.drop(car[car.price == 0].index, inplace = True)да это всё можно делать с помощью IQR (но это совершенно другая история)
И с помощью value_counts, describe проверяем похоже ли это на правду
Сохраняем то что сделали
# сохраняем обработанный df в csv файл без заголовка и интекса , для экспорта в pgadmin
car.to_csv('car_info.csv', index=False)Переноcим данные в СУБД
Создаём пустую бд под экспорт
Осталось дело за малым, открываем pgAdmin4(и подключаемся к серверу)

Далее нам нужно, создать базу данных

Выбираем нашу базу данных и открываем запросник

Вводим туда простейший код
CREATE TABLE car
(
car_id int8,
region text,
price int8,
year float4,
manufacture text,
model text,
condition_car text,
cylinders text,
fuel text,
odometer float4,
tittle_status text,
transmision text,
VIN text,
drive text,
size text,
type text,
paint_color text,
state text,
lat float4,
long float4
)дааааааа -- можно использовать CHARACTER VARYING , int4 , date . Но мы сейчас не про экономию места на диске
Далее нам надо импортировать наши данные в таблицу
Занимаемся экспортом данных
Находим и открываем sql Shell (psql) -- терминальный интерфейс для PostgreSQL

просто нажимаем на enter везде кроме, Database(название вашей базы данных) и Пароль пользователя postgres. И у нас начинается подключение
Далее вводим команду
\COPY car FROM 'C:\Users\ratmu\PycharmProjects\Cars\vehicles.csv' DELIMITER ',' CSV HEADER;и бежим проверять в pgAdmin всё ли сработало
SELECT *
FROM carЕсли увидели таблицу значит вы молодец

Конец
Комментарии (11)

hello_my_name_is_dany
04.07.2022 04:18+2То есть всю статью можно сократить до:
Нажать кнопочки в интерфейсе
Ввести запрос COPY FROM
Такие задачи, конечно, не всем под силу

rat_muzzle Автор
04.07.2022 18:11-1Пост подразумевался, как рассказ о простом(основы-основ).В следующий раз постараюсь поднять более сложны и интересные темы.( Всё таки первый пост, не надо бить кулаками)

Z55
04.07.2022 08:01+1видим что из-за 26 столбцов, Pycharm не подгружает всё таблицу( в дальнейшем исправим)
Это не так. Просто pandas выводит на экран ограниченное число столбцов. Изменить можно например так:
pd.set_option('display.max_rows', 100)drop удаления столбцов , Axis: указывает, что столбцы или строки должны быть удалены
Вы используете устаревший синтаксис. В текущем виде нет необходимости гадать, что именно удаляется, т.к. это теперь указывается явно:
car.drop(columns=['description', 'county', 'url', 'region_url', 'image_url', 'posting_date'], inplace=True)Находим и открываем sql Shell (psql) -- терминальный интерфейс для PostgreSQL
просто нажимаем на enter везде кроме, Database(название вашей базы данных) и Пароль пользователя postgres.
А что делать, если сервер не локальный и у меня нет доступа к учётке суперпользователя?
И ещё, непонятно зачем мы убирали выбросы, если это данные реальных датасетов?
Если статья не про данные, то почему тогда в статье больше всего буков про выбросы?rat_muzzle Автор
04.07.2022 18:36Это не так. Просто pandas выводит на экран ограниченное число столбцов. Изменить можно например так:
pd.set_option('display.max_rows', 100)Возьму себе на заметку, спасибо за совет
Вы используете устаревший синтаксис. В текущем виде нет необходимости гадать, что именно удаляется, т.к. это теперь указывается явно:
car.drop(columns=['description', 'county', 'url', 'region_url', 'image_url', 'posting_date'], inplace=True)Тут я вас плохо понял, разве в статье я не тоже самое написал ?
car.drop(['description', 'county', 'url', 'region_url', 'image_url', 'posting_date'], axis=1, inplace=True)
И ещё, непонятно зачем мы убирали выбросы, если это данные реальных датасетов?
дата сет c Kaggle, подразумевается что он не готовый может иметь пропуски и опечатки.
Если статья не про данные, то почему тогда в статье больше всего буков про выбросы?
Всё что мы храним в PosctgreSQL это данные , так что не считаю информацию про данные лишние( но возможно про выбросы многовато)
А что делать, если сервер не локальный и у меня нет доступа к учётке суперпользователя?
COPY FROM STDIN может помочь найти ответ.

IvaYan
05.07.2022 01:12Тут я вас плохо понял, разве в статье я не тоже самое написал ?
car.drop(['description', 'county', 'url', 'region_url', 'image_url', 'posting_date'], axis=1, inplace=True)
Нет. Сравните внимательно, как вы указываете имена столбцов и то как вам предлагают их указывать.
Z55
05.07.2022 07:31Тут я вас плохо понял, разве в статье я не тоже самое написал ?
Как всегда, внимание к деталям )
Из доки: "columns single label or list-likeAlternative to specifying axis (
labels, axis=1is equivalent tocolumns=labels)."
COPY FROM STDIN может помочь найти ответ.
Я намекал вам на то, что у psql есть много нужных параметров, которые необходимо учитывать. Ваш способ запуска сработает только если БД - локальная и вы - суперюзер. Для остальных вариантов, нужно использовать ключи.

ic3shot
04.07.2022 09:16Вы, кажется, забыли проверить датасет на пропущенные данные (null'ы), проверка делается через
dataset.isnull().sum(), дроп пропущенных значений черезdataset = dataset.dropna().На стадии предварительной подготовки данных это достаточно важный шаг.rat_muzzle Автор
04.07.2022 18:18Согласен , стоило посмотреть полностью пропущенные строки и удалить их. Или удалять полностью строку при отсутствии модели.(цены есть в каждой строке)

AlexanderPro
06.07.2022 17:02Оставлю небольшой пример импорта CSV файла в разные СУБД средствами самих СУБД
dimuska139
Почему вы думаете, что CHARACTER VARYING занимает места на диске (в случае PostgreSQL) меньше, чем TEXT?
rat_muzzle Автор
согласен ,я довольно-таки грубо выразился. Моё заявления скорее относиться к int2_int4_int8(real) они согласно официальной документации занимают разный объём данных. CHARACTER VARYING and TEXT не относятся к этому высказыванию и вообще , это другая тема для разговора.