
Концепция data mesh, как распределенной архитектуры для управления данными уже достаточно подробно представлена в нашем интернете. Еще лучше разобраться в этой теме нам поможет создание прототипа сети, демонстрирующего принципы работы data mesh.

При создании data mesh используют разные подходы. При стандартном методе сеть строится с использованием технологии потоковой передачи событий. Она обеспечивает безопасный управляемый механизм для перемещения данных между узлами сети в режиме реального времени. Любой выбираемый подход должен варьироваться в зависимости от конкретных требований сети.
Подготовленные читатели могут сразу перейти к созданию своего проекта:
Запустить (и изменить) собственную копию прототипа, выполнив шаги, описанные в репозитории GitHub.
А это наша версия этого прототипа в Confluent Cloud. Обратите внимание, что в этой версии вы не сможете получить доступ к Confluent Cloud.

Что такое Data Mesh и зачем она нужна?
Дело в том, что традиционные аналитические архитектуры баз данных часто бывают ненадежными и сложными, медленно обновляются. Устранить эти недостатки позволяет концепция data mesh за счет перехода от централизованного к децентрализованному принципу. Впервые она была предложена Жамак Дехгани (Zhamak Dehghani).
Традиционно, поступающие из разных источников данные преобразуются и загружаются в центральное хранилище для последующего анализа. При этом часто возникают ошибки, в значительной степени из-за нестабильности данных. Доступность, надежность и достоверность данных в этой архитектуре определяются центральным узлом сети, а не теми сетевыми компонентами, которые их генерируют и используют.
Поэтому в процессе анализа может появляться несколько (часто противоречивых) источников информации и, как следствие, возникает недоверие к результатам анализа данных. Устранить эти проблемы призвана топология data mesh. Для ее описания Zamak использовала четыре принципа:
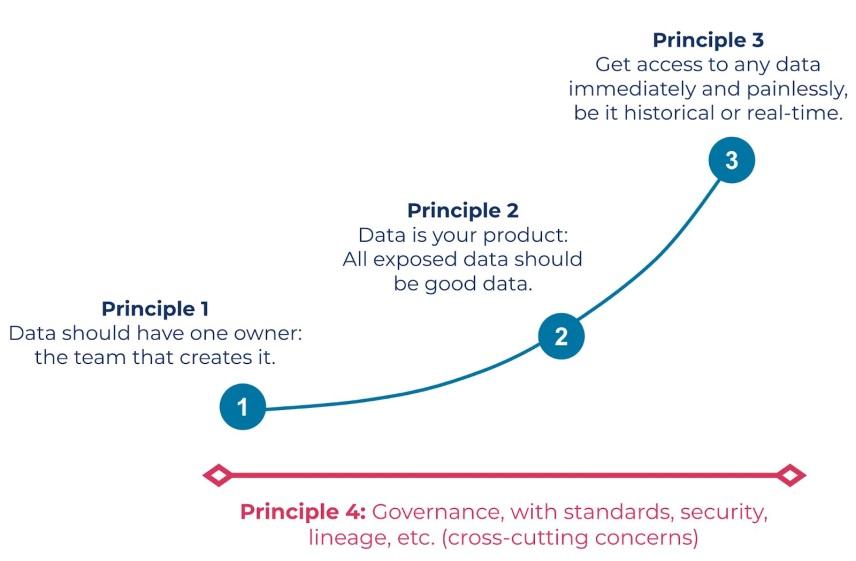
domain ownership (владение доменом);
data as a product (данные как продукт);
self-service data platform (самообслуживаемая платформа данных);
federated computational governance (совместное управление вычислениями).
domain ownership: Бизнес-домены (административные единицы в компании) являются ответственными собственниками данных. Которые они создают для собственного пользования и предоставляют их другим подразделениям.
data as a product: Сотрудники доменов должны создавать удовлетворяющий заданным стандартам качества продукт данных. Его формат и интерфейсы должны соответствовать запросам клиентов.
self-service data platform: Платформа self-service предоставляет корпоративным пользователям инструменты для самостоятельного анализа и другой работы с имеющимися в базе данными, минимизируя обращения к специалистам по обработке данных.
federated computational governance :Совместное управление данными в data mesh предусматривает централизованные стандарты управления данными. Но локальные доменные группы, действуя автономно, имеют ресурсы для выполнения этих стандартов в оптимально подходящей для их среды манере.
При реализации нашего проекта будем опираться на эти принципы. Полезными будут статья Жамак Дехгани «Принципы построения и логическая архитектура Data Mesh», а также Data Mesh 101 course на Confluent Developer. Эти источники послужили основой данной статьи.
Потоки событий как элемент Data Mesh
Строительными блоками data mesh являются data products. Это распределенные по отделам вашей компании источники должным образом формируемых данных. Каждый из них рассматривается как самостоятельный цифровой продукт. Идея состоит в том, чтобы тщательно обрабатывать, контролировать и предоставлять эти продукты другим потребителям как надежный и заслуживающий доверия источник корпоративных данных.
Потоки событий (event streams) являются основными строительными блоками в технологиях data in motion, поэтому неудивительно, что они тесно связаны с data products. Наш прототип mesh-сети включает функции исследования, потребления, создания и управления data products. Поток событий в data mesh определяется как тема (Topic) диспетчера сообщений Apache Kafka в паре со схемой данных (Schema). Публикуя в mesh-сети поток событий, мы добавляем его метаданные в каталог данных. Тема, схема и метаданные формируют базовое определение data product на основе потоков.
Преимущества потоков событий для Data Mesh
Потоки событий оптимально подходят для data products за счет ряда факторов:
Устранение разрыва между оперативными и аналитическими данными: Аналитические и оперативные данные часто берутся из разных источников. Например, orders (заказы) создаются в службе заказов и запрашиваются через REST API, но те же orders также доступны для создания отчетов из хранилища данных. Такая ситуация может вызывать расхождения между источниками и потерю доверия к ним.
Потоки событий поддерживают операционные, аналитические и гибридные рабочие процессы, предоставляя единый источник data product. Например, потоковые сценарии использования могут потреблять данные непосредственно из потока событий, а аналитические сценарии могут передавать данные в систему пакетных запросов.
Прием необходимых данных в режиме реального времени: Потоки событий – это масштабируемый, надежный способ передачи и длительного хранения важных бизнес-данных. Потоки обновляются по мере поступления новых данных, распространяя последние обновления среди всех потребителей. Данные в режиме реального времени можно получать в виде потоков и пакетов из разных центров обработки, а также из облака или регионов.
Потребители определяют свои модели данных и хранилища: Они самостоятельно перестраивают потоки событий, в том числе объединяют несколько data products для специфических сценариев использования. Например, можно извлечь данные о клиентах и заказах из соответствующих data products, но затем дополнить эти данные собственной схемой категоризации клиентов. Дополненные данные могут храниться в хранилище, наиболее подходящем для ваших шаблонных запросов, например в хранилище значений ключей для быстрого поиска по клиентам.
Всегда ли Data Product – это поток событий?
Потоки событий оптимально соответствуют самым разным типам данных, учитывая характер постепенного обновления, простоту использования и свободу смешивания потоков отдельных data products. Потоки событий – лучший вариант для раздачи data products, особенно когда эти данные используются разными потребителями с уникальными потребностями.
Однако для некоторых data products могут быть предпочтительнее другие интерфейсы. Например, для увязанных с местоположением data products могут лучше подходить хранилища данных геолокации и поиск с синхронным API запросов. Кроме того, для data product может не требоваться поддержка таких функций потоковой передачи, как ежемесячная агрегация финансовых данных, которая нужна лишь для персональных запросов.
Для определенных сценариев без потоковой передачи можно перенаправить поток событий в выбранное хранилище данных. Kafka Connect упрощает использование потоков событий, позволяет преобразовывать и записывать их в разные конечные точки. Это упрощает создание новых представлений data product, позволяя использовать существующие пакетные рабочие процессы и инструменты.
Но как показывает наш опыт, постоянно растущая потребность в передаче данных в масштабе всей организации приводит к тому, что потоки событий играют важную роль в реализации data mesh.
Data Mesh и человеческий фактор
Успех реализации data mesh зависит от ряда ключевых факторов социальной среды. Рассматривая данные как продукт, вы соглашаетесь применять к ним такие же , как и к другим программным продуктам, требования, включая выпуск новых версий, предоставление соглашения о минимальном уровне обслуживания. В этом случае клиенты получат единообразный, надежный и заслуживающий доверия доступ к данным в своих целях.
Data mesh – это интеграция data products из разных доменов организации для совместного использования.

В прототипе для публикуемых data products нужны метаданные домена и владельца (domain и owner). Они предоставляют информацию об источнике данных. Например, data product о биржевых торгах содержит метаданные, указывающие на происхождение из домена execution. @execution – это одна из рабочих групп в этом домене. Она полностью владеет data product по биржевым сделкам и отвечает за них, включая создание, публикацию и обновление продукта. Наряду с description (описанием) это может помочь при выборе продукта.
В полнофункциональной реализации проекта было бы полезно связать owner со стандартным списком команд (или людей) вашей организации, например, полученным из списка команд GitHub или групп пользователей AWS IAM. Кроме того, по нажатию на owner должно открыться окно для общения с пользователем по электронной почте, либо корпоративный чат обмена мгновенными сообщениями.

Два других обязательных по условиям federated governance поля метаданных в нашем прототипе – Quality (Качество данных) и SLA (Соглашение об уровне обслуживания). Они помогают определить качество набора данных, отличая канонические наборы данных (authoritative) от наборов данных с более низкими (curated) стандартами или без стандартов (raw). SLA, предоставляемые владельцем домена, указывают уровень обслуживания, на который может рассчитывать потребитель. Это помогает предотвратить создание критически важных приложений на недостаточно поддерживаемых data products.
Децентрализованное управление данными (Data Governance)
В отличие от централизованных подходов, таких как data lake или data warehouse, data mesh является объединением множества источников и приемников данных, связанных друг с другом в виде сети (mesh). Очевидно, что это дает целый ряд преимуществ, включая мобильность рабочих команд, с большей автономией в отношении потребляемых ими данных. Но ценой за эту свободу является повышенная вероятность несогласованности в данных, что также является проблемой и в архитектуре микрослужб. Система управления (federated governance) призвана уравновесить эту свободу и несогласованность. Для этого используется набор правил, положений и руководств, которые не ограничивают владение доменом, но облегчают междоменную совместимость и упрощают использование data products.
Система управления (governance) data mesh должна сбалансировать потребности всех участников и найти необходимые для их совместной работы компромиссы. Должны быть определены такие стандарты, как:
Типы data product могут включать доступные через потоки событий продукты, облачные службы хранения, API gRPC, API REST или запросы GraphQL.
Типы схемы данных (Shema), включая применение Avro или Protobuf для всех тем Kafka при ограничении использования JSON, применение формата Parquet в S3 при запрете использования ORC.
Рекомендации по жизненному циклу продукта, такие как требования к эволюции схемы, обработка критических изменений, миграция, устаревание и удаление продуктов данных.
Стандарты безопасности и контроля доступа на основе передовых методик.
Политики депрекации, истощения и миграции, позволяющие корректно прекращать использование data products.
Метаданные, такие как корпоративные стандарты качества и SLA.
Соглашения об именах, такие как система доменных имен для согласованных названий data product и упрощения поиска.
Self-serve для Data Products в облачном сервисе
Хорошая data mesh минимизирует процесс создания приложения для управления данными благодаря принципу self-serve. Мы структурировали наш прототип таким образом, чтобы полностью продемонстрировать рабочие процессы исследования, создания и управления data product, делающие продукты максимально удобными для self-serve.
, создания (Tab 2) и управления (Tab 3) продуктами данных")
Для потребителя важна доступность, как текущих, так и архивных данных data products. Используя потоки событий они могут самостоятельно выбирать и неоднократно, по мере необходимости, считывать требуемые им архивные данные. Это позволяет выстраивать в приложениях любую модель данных и состояния, требующиеся в бизнес-процессах.
Облачные вычисления значительно упрощают операции self-serve. В нашем прототипе проблемы масштабирования в значительной степени перенесены на Confluent Cloud. Сжатие и Infinite Storage (бесконечное хранение) позволяют неограниченно долго хранить и обрабатывать архивные события любого объема. Вы можете подключить нового пользователя, прочитать архивные данные потока событий, а затем продолжить обработку в режиме реального времени.

Прототип демонстрирует несколько сценариев использования в бизнесе вместе с операторами ksqlDB, чтобы проиллюстрировать, насколько простым должен быть доступ к data products. Добиться чего-то подобного можно также, развернув управляемые событиями микрослужбы, которые потребляют потоки событий и генерируют преобразованные события. В любом случае, самое главное, чтобы разработчики могли быстро создавать необходимые для их домена приложения, минимизируя при этом накладные расходы на доступ к данным.
Проблемным может оказаться подключение к data mesh ранее созданных приложений, которые не могут использовать потоки событий. Решает эти проблемы Kafka Connect, предоставляя средства для передачи data products в целевое хранилище данных. Создавать data products можно также на основе коннекторов сбора измененных данных. Для создания насыщенных событий с малой задержкой можно использовать, например, шаблон сквозной записи в базу данных database write through pattern, отказавшись от сложных опрашивающих запросов производственных систем. После публикации data product, вы отвечаете за соблюдения минимальных соглашений по этому продукту. Невыполнение этих требований должно рассматриваться как отказ в обслуживании. Экстренное реагирование может быть ограниченным для data products низкого уровня и продуктов с очень удобными SLA, в то время как для data product уровня 1, с очень жестким SLA, может потребоваться ротация по вызову (on-call rotation).

Удаление data product из mesh может быть выполнено одним нажатием кнопки. Однако владелец data product должен быть уверен, что все потребители продукта были уведомлены об этом и не используют его в момент удаления. Пока в нашем прототипе нет такой полезной функциональности. Между тем, доступ к новым потребителям можно было бы предотвратить, отклоняя запросы на доступ для чтения по теме.

Хорошая платформа самообслуживания data mesh будет отслеживать и учитывать всех потребителей и производителей data products, а также предоставлять информацию о взаимозависимостях компонентов (Stream Lineage). Lineage помогает идентифицировать потребителей data product, чтобы они могли получать уведомления о предстоящих: устаревании данных, удалениях и изменениях в схеме данных.
Прототип Data Mesh с открытым исходным кодом
Этот прототип написан на Spring Boot Java с интерфейсом Elm. Он поддерживается Confluent Cloud, включая Apache Kafka, ksqlDB, реестр схем и недавно выпущенный data catalog. Вы можете опробовать размещенную версию или запустить (и разветвить) свою собственную копию прототипа, выполнив действия, описанные в репозитории GitHub.
Если вы развернете этот прототип локально, он создаст кластер, несколько тем Kafka, приложение ksqlDB и несколько генераторов данных для заполнения тем. По мере появления событий, схемы регистрируются в реестре, в то время как в каталоге данных хранятся метаданные data product.
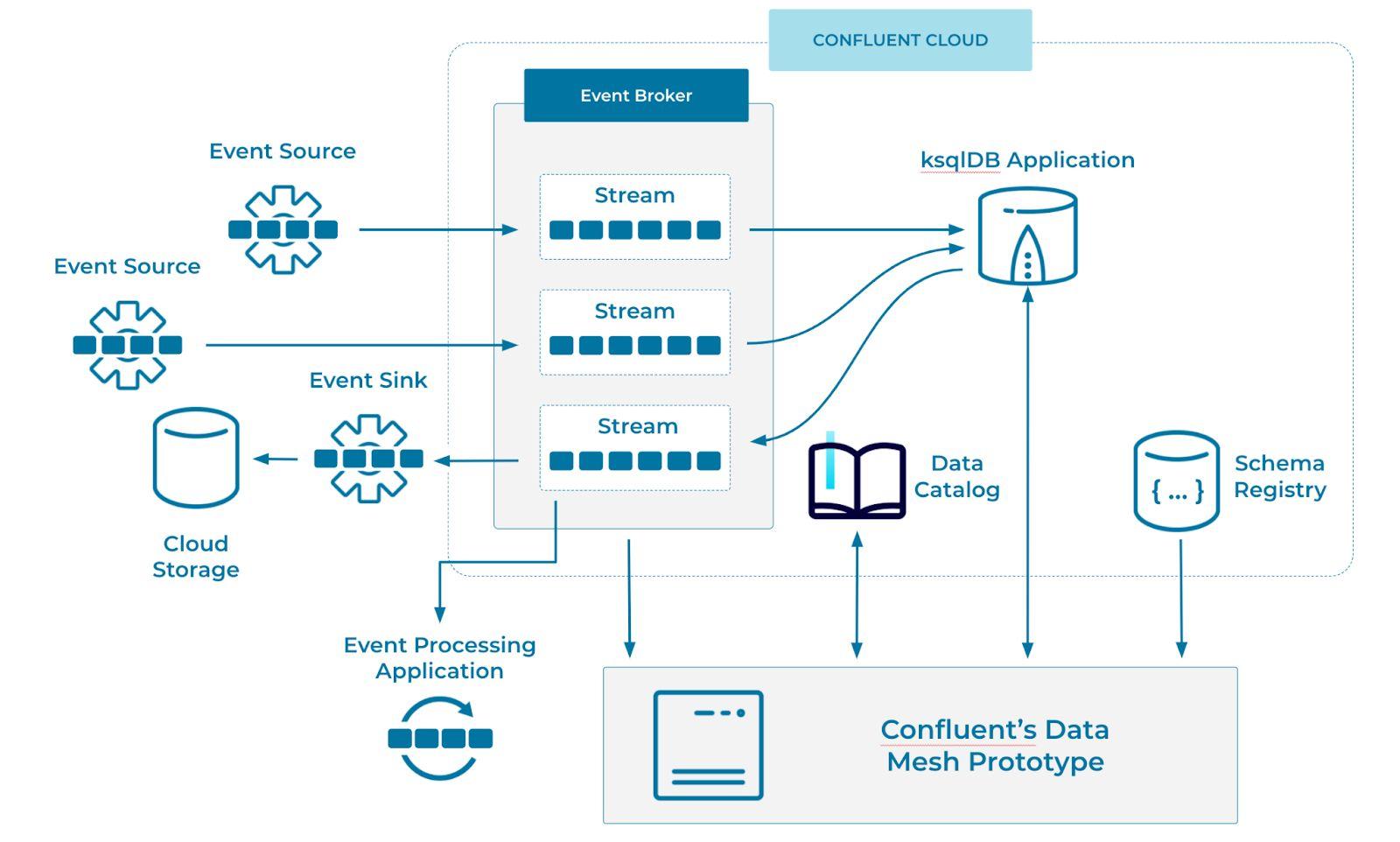
Этот прототип взаимодействует с Confluent Cloud через REST API. Метаданные data product хранятся в каталоге данных и содержат ссылку на соответствующие тему и схему. Эта информация извлекается в прототип при просмотре data products для исследования и публикации. Для создания примеров бизнес-приложений прототип взаимодействует с размещенной базой данных ksqlDB через свой REST API, запуская приложение ksqlDB с длительным запросом.
Что еще нужно для создания Data Mesh
Эта статья задумана как руководство по созданию data mesh, однако прототип – это лишь начальный этап в изучении этой технологии. Для создания идеальной data mesh понадобится ряд дополнений.
Уведомления пользователей о создании, обновлении, устаревании или удалении data product через электронную почту.
Автоматизированная проверка data products на соответствие законам о защите данных (например, GDPR), требованиям безопасности и политикам локализации данных, которые предотвращают передачу данных из определенных регионов.
Встроенный процесс проверки кода data products, чтобы случайно не допустить критических изменений. Изменения в data product должны быть предварительно проверены и одобрены потребителями.
Автоматическая обработка некорректных изменений data product может уменьшить количество ошибок при изменениях и автоматическом создании нового продукта, отказе от старого и уведомлении потребителей об изменениях. Также может понадобиться автоматизированная поддержку как старых, так и новых data products, пока все потребители не перейдут на новый.
Дополнительные метаданные потока событий. Потоки событий могут содержать только последние данные (например, за последние 30 дней), сжатый снимок состояния или все события, когда-либо опубликованные в продукте. Предоставление этой информации позволит улучшить self-service и умерить ожидания пользователей.
Заключение
Хорошо спроектированная data mesh облегчает доступ к продуктам данных, их использование и публикации. Ваше время должно быть потрачено на использование данных и создание приложений, а не на поиск и интерпретацию данных или создание собственных механизмов доступа.
Этот прототип показывает, как data mesh может работать на практике. Мы рекомендуем опробовать его, настроить под свои нужды и присоединиться к сообществу, если возникнут какие-либо вопросы.
НЛО прилетело и оставило здесь промокод для читателей нашего блога:
— 15% на все тарифы VDS (кроме тарифа Прогрев) — HABRFIRSTVDS.