
Какой вес опасен для здоровья базы? Большая не значит с лишним весом
У людей все просто – оптимальный вес вычисляется как соотношение роста и веса, + используются дополнительные показатели (возраст, пол …) для определения индекса массы тела. Калькулятор веса человека. Конечно всем не угодишь – например, культуристы могут возмутиться.
С оптимальным размером базы все гораздо сложнее – оптимальный объем базы определяется бизнес процессом и потоком данных, но и здесь можно сформулировать четкие критерии. Далее все изложено для финансового и управленческого учета 1С, поскольку в других сферах могут быть другие пропорции идеального веса базы.
База имеет оптимальный размер если:
В ней содержатся только данные, которые входят в период оперативной доступности данных для учета.
Данные обеспечивают необходимую детализацию в периоде оперативной доступности данных.
Сроки восстановления базы укладываются в целевые сроки восстановления (Recovery Time Objective) и согласуются с Business continuity planning.
Допустимые простои на обслуживание согласно Business continuity planning.
Стоимость хранения данных устраивает бизнес.
Подготовка тестовых баз с реальными данными не требует больших усилий
Я намеренно не указал влияние размера базы на общую производительность, здесь нет прямой зависимости при грамотном построении архитектуры, только косвенные эффекты вызванные ошибками проектирования и ограничениями возможности маштабирования 1С, см Язык мой враг мой.
Оперативную доступность можно пояснить на примере: Допустим у вас есть займ, сделка с датой поставки и датой оплаты. Очевидно, чтобы производить расчеты с периодом действия займа, или датой оплаты\ поставки эта операция должна быть доступна – даже если сама дата операции была 3 года назад. Тоже самое относится к амортизации основных средств, где важна дата приема основного средства, период действия. Хороший пример период регистрации\период действия в 1С Зарплата и кадры.
В целом большая база вызывает противоречивые чувства – с одной стороны гордость за объемы которыми оперируем, с другой стороны постоянное напряжение от обратного отсчета дискового пространства. Разница в ощущениях и квалификации как у капитана прогулочного судна против капитана морского танкера .
Далее все изложено на реальном примере управленческого и финансового учета сделок, см тут Язык мой враг мой, с применением горизонтального маштабирования.
Объем обрабатываемых данных за 1.5 года создает объем данных 5 Терабайт для базы 1С (включая детальные сделки\трансферы\проводки 1С и т.д.) на MS SQL 2019 с учетом мероприятий по обслуживанию индексов и устранению фрагментации. Размер сжатого бэкапа 0.5 Терабайт
Для процесса обработки\сверки данных (формирование проводок по исходным сделкам и операциям) применяются роботы (обработки запускаемые по расписанию), а пользователи уже работают с готовыми расчетами. По сути мы получаем нагруженную OLTP систему, полностью реализованную средствами 1С.
Буфер сообщений (за периметром 1С) из шины данных RabbitMQ – 3 терабайта каждые 2 месяца
Такой объем данных уже не позволяет использовать обычные средства платформы 1С для переиндексирования, сжатия таблиц, выгрузки бэкапа через dt файл, удаления помеченных на удаление объектов и т.д.
Временные метрики
Мероприятие |
Время |
Время полного бэкапа |
2 часа 30 минут |
Время полного восстановления с сети |
1 час – 1 час 30 минут |
Время копирования бэкапа в резервный ЦОД по WAN с задержкой 60мс |
3-4 часа |
Перестроение одного индекса по самой большой таблице |
2-3 часа |
Временные окна
Зарезервированный период времени |
|
Пн-Пт 6.00-11.00 |
Импорты операций\изменений поступивших с 0.00 до 6.00 ,пересчеты за предыдущие три дня |
Пн-Пт 13.00-15.00 |
Импорты и пересчеты с учетом текущего дня |
Пн-Пт 9.00-22.00 |
Работа пользователей в разных часовых поясах |
Пн-Пт с 22.00 – 1.00 |
Резервное копирование |
Пн-Вс с 1.00- 4.00 |
Импорты за предыдущие сутки, обновление агрегатов |
Сб 6.00 – 16.00 |
Пересчет недели |
Вс |
Свободно для регламентных операций |
Самые большие таблицы
В колонке Reserved можно видеть полный размер с данными и индексами
Table Name |
# Records |
Reserved (KB) |
Data (KB) |
Indexes (KB) |
Unused (KB) |
dbo._InfoRg19541 |
2 129 006 521 |
935 854 848 |
330 776 488 |
605 006 384 |
71 976 |
dbo._InfoRg18843 |
2 249 531 309 |
868 625 224 |
404 594 224 |
463 926 136 |
104 864 |
dbo._InfoRg18800 |
474 701 158 |
464 440 080 |
237 170 176 |
226 214 496 |
1 055 408 |
dbo._InfoRg18860 |
210 648 091 |
364 976 152 |
161 322 160 |
202 245 752 |
1 408 240 |
dbo._InfoRg19155 |
213 300 609 |
288 223 232 |
147 725 760 |
139 103 120 |
1 394 352 |
dbo._InfoRg17958 |
950 225 249 |
272 452 928 |
112 304 896 |
160 024 808 |
123 224 |
dbo._AccRg640 |
173 846 826 |
216 363 688 |
114 061 808 |
100 367 624 |
1 934 256 |
dbo._AccRgED677 |
719 075 121 |
210 720 168 |
85 568 344 |
124 133 600 |
1 018 224 |
dbo._InfoRg17039 |
370 016 366 |
187 902 208 |
38 467 072 |
149 404 080 |
31 056 |
dbo._Document16379 |
124 261 741 |
157 270 936 |
87 645 272 |
69 585 416 |
40 248 |
dbo._InfoRg17540 |
465 538 086 |
130 361 760 |
48 378 552 |
81 972 648 |
10 560 |
dbo._InfoRg19532 |
319 591 053 |
117 715 648 |
36 970 224 |
80 632 544 |
112 880 |
dbo._AccumRgAgg1efff3h18432 |
35 654 182 |
113 249 992 |
16 904 528 |
96 339 088 |
6 376 |
dbo._Document16378 |
44 003 768 |
109 851 688 |
58 681 312 |
50 688 960 |
481 416 |
dbo._InfoRg19498 |
85 023 186 |
109 818 320 |
29 883 608 |
79 798 344 |
136 368 |
dbo._Document17199 |
75 350 013 |
96 437 040 |
50 024 488 |
46 376 920 |
35 632 |
dbo._AccumRg16920 |
55 665 218 |
72 446 544 |
34 478 320 |
36 183 960 |
1 784 264 |
dbo._Document17554 |
46 735 956 |
61 361 048 |
30 128 088 |
31 202 152 |
30 808 |
Зарезервированное время, не всегда используется полностью, но в пиковых нагрузках приходится выходить за границы. Финансовый\Управленческий учет с высокой детализацией требует ресурсов и создает объемы. Из таблиц видно, что работа построена довольно плотно, и даже вклинится с регламентными процедурами не так просто
Обслуживание для plus size модели.
Такие размеры базы налагают определенные условия на мероприятия по обслуживанию:
Нужно забыть регламентных заданиях обновления статистики SQL это долго, хорошо жить с флагом трассировки-Т2371 - он изменяет порог обновления статистики на более частый. Если его не включить – вставка\обновление нескольких миллионов записей уже искажает статистику и влияет на запросы . Формально считается, что он не влияет на SQL 2016 - 2019 но есть нюансы.
Вы должны внимательны к режиму совместимости вашей базы даже, если вы ее перенесли на SQL Server 2019 . Напр. при переносе базы c SQL 2008 на SQL 2019 по умолчанию ставится режим совместимости с 2008. Во много это определяется изменившимся режимом оптимизатора в котором Microsoft видимо не уверен. Я бы тоже был осторожен при таком кардинальном изменение кардинальности см тут Улучшенная кардинальность в MS SQL.
Раз полгода нужна переиндексация НЕкластерных индексов с наибольшей фрагментацией. В 1С напр. много обновляющихся(insert, delete) таблиц (напр. итоги) в которых растет фрагментация. В такой базе как наша это позволяет выиграть 3 - 4 сотни гигабайт за мероприятие . Для эффективности используйте ALTER INDEX <Index_Name> ON dbo.<Table_Name> REBUILD WITH (SORT_IN_TEMPDB = ON). Это предотвратит рост размера файловой группы, ведь ее потом трудно сжать обратно не смотря на свободное место.
После свертки остатков и удаления лишних данных проведите реиндексацию кластерных индексов. С фрагментацией и перестройкой кластерных индексов сложнее – фактически нужно место равное размеру таблицы, но это решаемо
Такие размеры выявляют несовершенство оптимизатора SQL, я неоднократно сталкивался со случаями, когда вдруг запрос на одном дне работает очень медленно, а если период расширить до +N дней, то быстро. Если пересчитать статистику все начинает работать быстро на любых периодах.
Программист 1С в этом случае должен трансформироваться минимум в Эксперта 1С по технологическим вопросам, а в идеале знать в совершенстве Performance and tuning из сертификации DBA. 1С это всего лишь удобный инструмент для генерации запросов, как сыграешь на нем, так и будет работать.
Анонс: В целом детали управления слоном в клетке ЦОД это отдельная статья, поскольку избыточного места равного размеру базы почти никогда нет. Сложностей добавляет структура таблиц\индексов 1С которые генерируют метаданные.
Снижение веса как стиль жизни
При таком потоке данных разовыми мероприятиями по удалению лишнего не обойтись, нужно встраивать это в архитектуру. Рассмотрим варианты от самого плохого до самого хорошего
Удаление миллионов – дорого и долго.
Удаление миллионов средствами 1С будет в любом случае самым долгим, поскольку это можно делать либо по регистратору, либо по измерениям регистра с условием на равенство. Даже если это запустить в параллельных фоновых заданиях, маштабируя горизонтально, вы будете сталкиваться с waits на обновлении данных таблиц и что не маловажно индексов. Ведь любой удаляемый набор записей SQL Server должен исключить не только из таблицы, но и всех индексов.
Если вы решили ускорить удаление, делая это напрямую через SQL Server в цикле DELETE TOP 1000 FROM 1CTable, вас ожидает две проблемы:
В Цикле в один поток это будет медленно.
Распараллелить данный оператор на уровне SQL это прямой путь к блокировкам. Еще в MS SQL (Transact SQL) нет хороших средств распараллелить ваш код кроме механизма Jobs.
Если кто-то хочет сделать просто DELETE * FROM 1CTables – оцените влияние объемов на Transaction log и Вы много поймете в архитектуре СУБД.
Анонс: Вообще делать часть кода на MS SQL (Transact SQL ) это плохая затея, несмотря на кажущуюся эффективность. Тема для отдельной статьи.
Даже если вы все-таки удалили миллионы этим способом, MS SQL на этом не закончил – вы там обнаружите … призрака.
Выглядит он так:
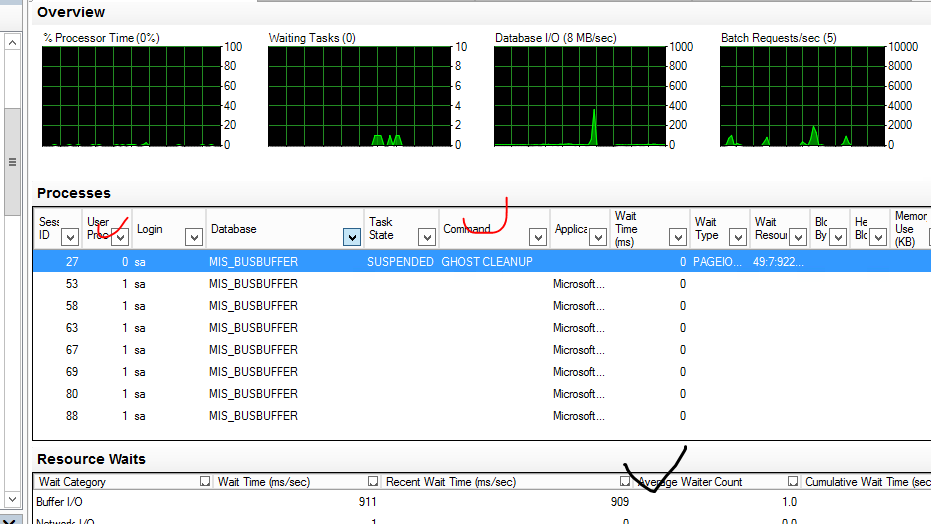
Это процесс очистки фантомных записей MS SQL. Забавно, что не только 1С умеет “помечать” на удаление, но и MS SQL, см. Ghost clean up process.
А в качестве бонуса всей процедуры удаления Вы получите хорошую фрагментацию файловой группы. См. Reorganize and rebuild indexes.
В итоге получается, что не смотря на простоту программной реализации, обычное удаление слишком дорого обходится для и так нагруженной системы даже если это делать в технологические окна.
Партицирование миллионов - дешево и сердито.
Для больших таблиц современные СУБД (MS SQL 2019 в Standard edition) предлагают механизм партицирования. Напр периодический регистр сведений можно партицировать по дате, а потом:
Данные старых партиций сохранять в архив.
Удаление старых данных в одной партиции производить операцией TRUNCATE TABLE WITH (PARTITIONS(N)), быстро, без фрагментаций и других неприятных последствий описанных выше.
Подробнее можно почитать тут:
Partitioned tables and indexes
И инструкция с примером тут:
Казалось бы вот хорошее решение, но проблемы кроются в деталях:
Партицирование возможно только по одной Partitioning column, т.е. использовать составной ключ для партицирования типа (Разделитель данных, Дата) которые часто используются в типовых конфигурациях невозможно.
Partition column должна присутствовать во всех индексах таблицы иначе вы сможете делать только DML операции, но не DDL TRUNCATE TABLE WITH (PARTITIONS(N));
Многие метаданные 1С напр, Регистр бухгалтерии по структуре состоит из нескольких таблиц, его партицировать невозможно. Т.е. в общем случае возможность эффективного использования партицирования должна быть заложена на уровне платформы, а этого нет.
Партицирование позволяет быстро удалить данные партиции, используя TRUNCATE TABLE WITH (PARTITIONS(N)); но не позволяет быстро поместить в архив и это сужает применение партицирование для узких задач. Напр хранение данных буфера сообщений для RabbitMQ, это сильно облегчает жизнь, но не решает общую проблему быстрого снижения веса.
Про помещение в архив стоит остановится подробнее. В партицировании есть операция SWITCH позволяющая переключить на уровне метаданных SQL (не путать с метаданными 1С) данные из партиции в таблицу той же структуры. Делается это мгновенно на уровне метаданных SQL, но пользы для быстрого архивирования нет
Переключение идет только в рамках той же файловой группы, мы не можем сделать SQL бэкап отдельно партиции с ее индексами. Только бэкап всей базы или файловой группы.
Бэкап можно сделать только через стандартную утилиту копирования таблиц MS SQL BCP , которая не сжимает данные и работает медленней чем SQL Backup на уровне экстентов
Получается, что партицирование позволяет только быстро удалять данные, но не быстро архивировать\восстанавливать и как следствие эффективно только для некоторых таблиц. Учитывая вышеперечисленные недостатки для 1С проще использовать другой метод.
Методика похудения для 1С – 100%
«Я беру камень и отсекаю всё лишнее.» - так творил шедевры Микеланджело, но это было долго.
В СУБД есть более простой способ - «Я беру все нужное и ничего лишнего». В этом нам поможет утилита BCP, которая позволяет выгрузить и загрузить данные таблицы в Native формате. Допустим, мы хотим оставить в базе данных данные оборотов в регистре бухгалтерии, только за 2022 год.
Сворачиваем остатки своей процедурой и фиксируем их под регистратором Документ.СворачиваниеОстатков на 31.12.2021.
Выгружаем через BCP данные из таблиц проводок включая проводки за 2022 год включая проводки Документ.СворачиваниеОстатков.
Делаем Truncate всех таблиц регистра бухгалтерии.
Отключаем все индексы регистра бухгалтерии кроме кластерных.
Загружаем через BCP данные сохраненные в пункте 2) обратно.
Включаем, выключенные индексы регистра бухгалтерии.
Пересчет итогов.
Далее примеры скрипта для некоторых таблиц и индексов регистра бухгалтерии
Детально про BCP можно почитать тут:
П 1 |
_RecorderTRef = 0x00004248 документ регистратор остатков |
П 2 |
bcp "SELECT * FROM [%2].[dbo].[_AccRgED677] WHERE _Period > CONVERT(datetime, '%3 %4', 120) OR _Period = CONVERT(datetime, '%3 %4', 120) AND _RecorderTRef = 0x00004248" queryout %5\_AccRgED677.bcp -a 16384 -b 10000 -S %1 -d %2 -N -T -e %5\_AccRgED677_unload_error.log -o %5\_AccRgED677_unload_report.log |
П 3 |
sqlcmd -S %1 -d %2 -Q "TRUNCATE TABLE [%2].[dbo].[_AccRgED677]" -o %5\_AccRgED677_truncate_report.log |
П 4 |
sqlcmd -S %1 -d %2 -Q "ALTER INDEX _AccRgED677_ByRecorder_RNN ON [%2].[dbo].[_AccRgED677] DISABLE" sqlcmd -S %1 -d %2 -Q "ALTER INDEX _AccRgED677_ByExtDim_RR ON [%2].[dbo].[_AccRgED677] DISABLE" |
П 5 |
bcp [%2].dbo.[_AccRgED677] IN %5\_AccRgED677.bcp -a 16384 -b 10000 -h "TABLOCK" -S %1 -E -N -T -e %5\_AccRgED677_load_error.log -o %5\_AccRgED677_load_report.log |
П 6 |
sqlcmd -S %1 -d %2 -Q "ALTER INDEX _AccRgED677_ByRecorder_RNN ON [%2].[dbo].[_AccRgED677] REBUILD" sqlcmd -S %1 -d %2 -Q "ALTER INDEX _AccRgED677_ByExtDim_RR ON [%2].[dbo].[_AccRgED677] REBUILD" |
П 7 |
Пересчет итогов |
Про предварительные бэкапы, и контрольные отчеты до и после включая аналитику я писать не буду, поскольку это не инструкция для американских домохозяек. Структура базы данных подробно изложена тут Структура базы 1С совершенно открыто поэтому не стоит боятся манипуляций с данными напрямую.
Есть один принципиальный момент – это сортировка загружаемых данных – она должна соответствовать сортировке кластерных индексов , от этого зависит фрагментация кластерного индекса и скорость. Далее цитата из ссылки про bcp:
«The sort order of the data in the data file. Bulk import performance is improved if the data being imported is sorted according to the clustered index on the table, if any. If the data file is sorted in a different order, that is other than the order of a clustered index key, or if there is no clustered index on the table, the ORDER clause is ignored. The column names supplied must be valid column names in the destination table. By default, bcp assumes the data file is unordered. For optimized bulk import, SQL Server also validates that the imported data is sorted.»
Минус у такой методики один – невозможность в BCP делать сжатые бэкапы таблиц. Размеры *.bcp файлов получаются большими, при том, что там только данные без индексов
Дальше одни плюсы
Место для *.bcp файлов может быть где угодно, на любых носителях и сетевых дисках.
Время только тратится на выгрузку и загрузку.
Можно параллельно выгружать\загружать разные таблицы увеличивая общую скорость.
Сразу решатся вопрос с фрагментацией , а ее нужно решать при любых вариантах.
Можно использовать сложные выборки для актуальных данных учитывая даты оплаты и поставки.
Для большей скорости Вам нужно использовать большие размеры пакетов в BCP (параметр -a_ ) .
Размер самой файловой группы возможно легко сократить не удасться из-за разбросанных экстентов, однако там появится свободное место для новых данных т.е. база будет в фиксированной форме.
Анонс: Увеличить широту пропускания сети либо технологиями Teamed Lan либо используя сетевые карты с технологией RDMA. В целом настройка сети это тема отдельной статьи
Анонс: Практическая реализация подсистемы очистки это хорошая тема для отдельной статьи.
Коллективная ответственность за вес базы, мифы и реальность?
В любой крупной организации можно выделить системы
FrontOffice (где заключаются сделки, контракты, оформляются продажи).
BackOffice (где производятся взаиморасчеты, отражается работа по контрактам и закрытие продаж).
Финансовый учет.
Управленческий учет.
Они могут совмещаться или делится в разных комбинациях, но суть в том что большинство информации там дублируется . Кроме того для финансового и управленческого учета требуются расшифровки с исходными сделками для сверок, проверок, аудиторов. И все эти базы требуют RAID с избыточным количеством дисков. Как правило пока все умещается на текущие сервера это устраивает разные ответственные подразделения, но когда количество сделок\операций во FrontOffice планируется увеличить на несколько сот тысяч в день, тогда простые расчеты показывают, что дублирование начинает грозить стабильности бизнес процессов.
Во первых это все нужно обработать в регламентное время на всех уровнях без ночных смен сотрудников.
Во вторых хранить на избыточных RAID, которые тянут за собой много другой ИТ инфраструктуры.
И этот момент хорош для внедрения агрегирования операций хотябы на уровне BackOffice – Фин\Упр учет иначе в потоке данных потонут все ИТ отделы, и это хорошая мотивация. Агрегация это непростой вопрос, поскольку она должна обязательно позволять обратную расшифровку и обновятся при изменениях задним числом.
Анонс: Варианты агрегации с расшифровкой это тема отдельной статьи.
Теперь можно подвести итоги:
Держать базу в фиксированной форме, означает внедрение подсистемы, которая работает на регулярной основе. Мы живем во время производства избыточных данных. Делитесь своими приемами обрезки базы. Как создать удобную подсистему по обрезке данных в 1С – тема отдельной статьи, пишите если эта тема интересна. Буду рад видеть интересующихся данными темами на нашем канале t.me/Chat1CUnlimited.
Комментарии (13)

edo1h
28.07.2022 01:33объем данных 5 Терабайт для базы 1С… Размер сжатого бэкапа 0.5 Терабайт
не экспериментировали со сжатием самой базы? я проверял на копиях, получалось примерно 1:4, негативного влияния на производительность не заметил, но на боевой базе не проверял.

1CUnlimited Автор
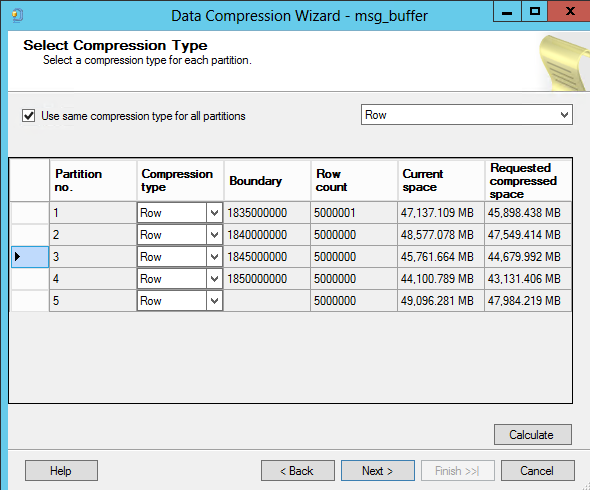
28.07.2022 13:00У меня нагруженная с точки зрения OLTP база , поэтому сжатие я не рассматривал - поскольку бесплатным оно не бывает. Хотел включить сжатие только на буфере сообщений - он 3 терабайта за 2 месяца , последовательно наполняется, запросы на нем простые. SQL Compression Wizard для него выдал такие цифры
Это при том что там хранятся XML сообщения. Выигрыш был небольшой и закрыл эту тему.
Проще настроить fillfactor Fill factor / Хабр (habr.com)
под конкретную базу и выстроить оптимальную работу с экстентами
Pages and Extents Architecture Guide - SQL Server | Microsoft Docs

Antiyellowguy
28.07.2022 23:02+1Ваш визард предлагает сжатие по строкам. А сжатие на уровне страниц пробовали? Ради эксперимента. Одинэсные базы отлично жмутся таким образом. Уж точно все тестовые базы можно жать для экономии места.
1CUnlimited Автор
28.07.2022 23:17Имеется ввиду это Enable Compression on a Table or Index - SQL Server | Microsoft Docs с типом DATA_COMPRESSION = PAGE ? Я выложу тут результаты wizard для самой большой таблицы.
Что касается практического применения для тестовых баз, скорее всего освободится место в файловой группы, но файловую группу сжать уже будет проблематично (поскольку двигать экстенты медленно и вредно.). А тестовые базы делаются сейчас как копия продуктива, поэтому без сжатия файловой группы я ничего не сокращу по факту
edo1h
29.07.2022 05:26Я выложу тут результаты wizard для самой большой таблицы.
выше уже писал, на моей базе размером в полтора терабайта получается 1:4
думаю, что у вас получатся похожие цифрыно файловую группу сжать уже будет проблематично (поскольку двигать экстенты медленно и вредно.)
с тем, что медленно, соглашусь. но чем особо вредно-то?
1CUnlimited Автор
29.07.2022 10:08https://www.brentozar.com/archive/2017/12/whats-bad-shrinking-databases-dbcc-shrinkdatabase/
Про dbcc shrinkfile ниже high watermark аналогичный эффект
edo1h
30.07.2022 02:22всё-таки статья немного про другое: она про то, что не надо пытаться включать shrink в рутинный скрипт обслуживания баз, а не про то, что им никогда пользоваться не надо.

uaggster
29.07.2022 09:51+1У меня нагруженная с точки зрения OLTP база , поэтому сжатие я не рассматривал - поскольку бесплатным оно не бывает.
На самом деле, если у вас дисковая полка - шпиндельная, или иопсы как-то лимитируются, или сервер в виртуальной среде - скорость обращения к данным даже вырастет после включения компрессии PAGE. Т.к. данных будет к диску и обратно будет путешествовать на 10-60% меньше.
Нагрузка на процессор при этом растет не сильно, на единицы процентов.
С тех пор, как у 2019 стандарт появилось постраничное сжатие - нет причины его не включить.1CUnlimited Автор
29.07.2022 10:14У есть тестовые на hdd . Прямо заинтриговали проверить - может и время отклика sec/transfer уменьшится?

uaggster
29.07.2022 09:45Если речь зашла о партиционировании, и в случае, если это партиционирование - правильно используется (т.е., например, запросы написаны так, что в них происходит partition eliminations) , то, очень часто, данные можно вообще не архивировать, а оставить в той же базе, или даже в той же таблице. Нужно просто преобразовать партицию в columnstore или columnstore archive.
Кстати, если у вас есть большие (больше нескольких миллионов записей) таблицы, которые по большей части всегда просматриваются целиком - смело преобразуйте их в clustered columnstore.
Это сжимает данные в 8-10 раз и ускоряет всяческое агрегирование в тысячи раз.
Обратная сторона медали - таблица или партиция всегда сканируется целиком, и плохо работает во всяческих join'ах... хотя это, по большей части не про 1С
edo1h
мне кажется, что вы сгущаете краски.
у нас база полтора терабайта, еженощно работают скрипты от ola с агрессивными настройками переиндексации и обновления статистики.
приведённый выше скрипт плюс полный бэкап на сетевой диск занимают 3 часа, ИМХО вполне приемлемо.
1CUnlimited Автор
Нисколько не сгущаю. Выше я привел время на переиндексацию одного! индекса большой таблицы . Это гдето 2 часа это на ssd . Кроме того использование флага для снижения порога автопересчета статистики позволяет избежать ситуации:
"Пришло 5 миллионов изменений по шине Rabbit MQ, прогрузили . Запрос за последний день не увидев статистики поехал по неэффективному плану".
Флагом трассировки-Т2371 эта проблема решается фундаментально. Кстати это рекомендует даже 1С в своей статье Флаги трассировки для работы с MS SQL Server :: MS SQL Server :: Методическая поддержка для разработчиков и администраторов 1С:Предприятия 8 (1c.ru)
Поэтому лучше жить с ним чем без него.
Добавлю что у меня нагрузка создается горизонтальным маштабированием роботов, которые перепроводят Т-3 ежедневно, импортируют изменения. Поэтому без Т-2371 жить проблематично
Кроме того до 2022 года у меня рабочий кластер был 2 Терабайтами SSD RAID 1 и 4 терабайт HDD RAID 10 . Наиболее нагруженные по OLTP таблицы были на SSD остальные на HDD raid . В феврале нам поставили новый полностью на SSD , но принципы обслуживания остались те же