
В июне я выступил на объединенной конференции DevOpsConf & TechLead Conf 2022. Доклад был посвящен LINSTOR — Open Source-хранилищу от компании LINBIT (разработчики DRBD). Основной идеей выступления было показать [на примере Kubernetes], как работает и устроен LINSTOR, какие проблемы решает, как его правильно настроить и использовать. Эта статья — основная выжимка из доклада (его полное видео см. в конце).
Итак, давайте копнем вглубь, в устройство LINSTOR, и посмотрим на его сходство с K8s.

Краткая эволюция хранилищ
Давайте перенесемся назад во времени, когда у нас были физические серверы, на которые устанавливались приложения. Постепенно серверов становилось все больше. Позже на них стали запускать виртуальные машины (ВМ), каждой их них требовался как минимум один виртуальный диск. Примерно тогда и возникла потребность в надежном хранилище.
Конечно, можно хранить данные на тех же серверах, где запускаются ВМ, но это создаёт некоторые трудности:
ВМ нельзя мигрировать между серверами;
сложно обеспечить отказоустойчивость и высокую доступность данных.
Так появились аппаратные хранилища, которые подключаются к compute-узлам по сети, позволяют виртуальным машинам хранить данные безопасно и раздельно. К основному аппаратному хранилищу можно добавить еще одно и реплицировать все данные на него: если одно из хранилищ выходит из строя, ВМ могут продолжать работать с другим.
Сегодня аппаратные хранилища традиционно предоставляют такие вендоры, как Dell, NetApp, HP и IBM. Также есть большое количество программно-определяемых систем хранения, а именно — кластерных файловых систем, которые хорошо зарекомендовали себя в мире Open Source, например Ceph, GlusterFS, Lustre, Moose, BeeGFS.
Для связи с compute-узлами СХД используют различные протоколы — например, NFS, iSCSI или собственный — как RDB (RADOS Block Device) у Ceph.
Помимо готовых решений есть также большое количество свободных компонентов, которые решают одну конкретную задачу. Комбинируя такие решения, можно построить собственное отказоустойчивое хранилище. Например, DRBD позволяет реплицировать блочные устройства по сети, то есть по сути представляет собой сетевой RAID1.
Как строились хранилища до LINSTOR
DRBD был широко известен и до прихода LINSTOR, однако принцип построения хранилища с использованием DRBD несколько отличался от того, что мы имеем сейчас.
Представим, что у нас есть два узла с набором дисков. Как правило, диски объединяются в общий массив с помощью аппаратного или программного RAID-массива. Далее поверх блочного устройства, которое предоставляет RAID-массив, создается одно большое DRBD-устройство для репликации данных по сети.
Поверх DRBD обычно запускается LVM (Logical Volume Manager). Он «нарезается» на виртуальные тома, которые отдаются виртуальным машинам:
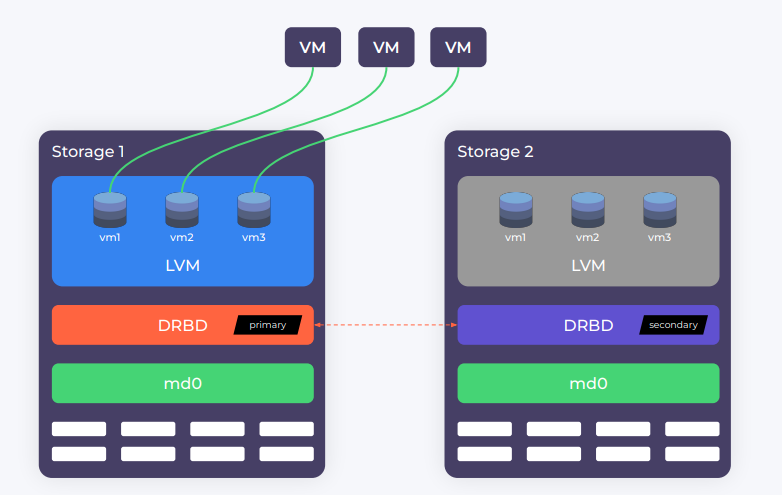
При поломке одного из хранилищ специальный алгоритм запускает виртуальный IP на другом узле и переводит его DRBD в статус primary, после чего ВМ работают уже с новым узлом. Когда упавшее хранилище восстанавливается, все данные реплицируются обратно.
Для доставки виртуальных дисков ВМ чаще всего использовался протокол iSCSI. Однако нередко можно было встретить и конфигурации с обычным NFS: тогда вместо LVM использовалась обычная файловая система вроде ext4, а виртуальные диски размещались в файловом формате QCOW2. Впрочем, высокой производительностью такое хранилище похвастаться не может.
В интернете также можно найти кучу статей, где люди ошибочно советуют запускать DRBD в режиме dual-primary и поверх него настроить кластерную файловую систему. Это наихудший вариант, потому что получается двунаправленная синхронизация, и в случае каких-либо проблем вы рискуете получить неразрешимый split-brain с гарантированной потерей данных. Никогда не используйте опцию
allow-two-primariesв DRBD для чего-либо, кроме live-миграции виртуальных машин.
Тем временем количество ВМ продолжало расти. Появился Kubernetes, который позволил запускать ещё более мелкие сущности — контейнеры. Всем ВМ и контейнерам мог понадобиться виртуальный том.
Хранилища продолжали эволюционировать:
Появилась возможность запускать целые кластеры из storage-серверов и реплицировать данные между ними.
Данные теперь можно «размазывать» по всему кластеру, как это делает Ceph, или размещать целыми блоками на конкретных узлах и реплицировать на другие.
LINSTOR — как раз и есть такой оркестратор, который позволяет всем этим делом управлять.
Сходство LINSTOR и Kubernetes
По сути, оба решения — оркестраторы. Только если Kubernetes запускает Pod’ы, то LINSTOR размещает тома для хранения данных и включает для них репликацию.

Для лучшего понимания сходства Kubernetes и LINSTOR сравним их архитектуру и интерфейс взаимодействия.
Архитектура
У Kubernetes и LINSTOR есть схожие компоненты, которые отвечают за бэкенд хранения, интерфейс взаимодействия, планирование, управление сущностями, экспорт метрик и запуск ресурсов:
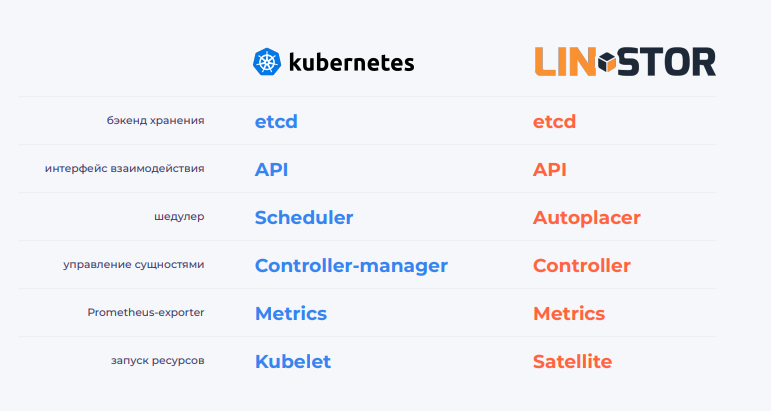
Интерфейс
У LINSTOR есть сущности (или наборы сущностей), аналогичные по функциональности объектам Kubernetes API:

Отличия LINSTOR и Kubernetes
Как мы видим, здесь у нас много общего, однако у LINSTOR есть свой набор ресурсов, логика которых работает несколько иначе, чем в Kubernetes.

Рассмотрим их чуть подробнее.
1. storage-pools
Чтобы «объяснить» LINSTOR’у, на каких дисках мы хотим хранить данные, сначала надо создать storage-пулы. LINSTOR не приносит какой-либо сложной логики нарезания томов — вместо этого он использует уже существующие и широко известные менеджеры логических томов, такие как LVM и ZFS.
Допустим, у нас есть кластер из 6 узлов:

На этих узлах мы должны создать LVM-пул или ZFS-датасет и зарегистрировать его в LINSTOR’е как storage-pool (пул хранения):

Посмотрим на список пулов:

Обратите внимание:
все пулы одного типа называются одинаково на разных узлах;
у каждого пула есть драйвер — в данном случае LVMthin. В зависимости от выбранного драйвера могут быть доступны те или иные функции хранения. Например, LVMthin позволяет делать снапшоты, когда для классического LVM эта возможность не поддерживается со стороны LINSTOR.
2. layers
layers — слои хранения. Здесь мы можем представить следующую картинку, которую разберём снизу-вверх:

Hardware — физические диски, которые подключены непосредственно к узлу: HDD, SSD, NVMe.
Node-level volume management — LVM, ZFS или другие менеджеры виртуальных томов.
Block storage features — дополнительные функции вроде шифрования (LUKS), дедупликации (VDO), кэширования и т. п.
Block transport systems — транспортный уровень, с помощью которого можно настроить репликацию либо доставить устройства с одного узла на другой.
Желаемые слои можно указать LINSTOR’у как для всей конфигурации хранения, так и отдельно для каждого создаваемого ресурса.
3. resources
Одна реплика в DRBD называется ресурсом. Набор таких ресурсов представляет собой самодостаточный DRBD-кластер, который, хоть и управляется LINSTOR’ом, но работает полностью независимо от него.
Когда требуется создать какой-либо DRBD-ресурс, сначала необходимо определить resource-definition — сущность, которая описывает все наши реплики. На его основе создаются DRBD-ресурсы, которые реплицируются между собой.
Создадим resource-definition и посмотрим, как он выглядит:

ResourceName— имя ресурса;Port— TCP-порт, который будет использоваться для репликации данных;ResourceGroup— обязательная ссылка на resource-group, в котором описана конфигурация хранения: сколько реплик, где и как они должны размещаться (ближайший аналог — StorageClass в Kubernetes);State— статус.
После создания resource-definition необходимо определить volume-definition. Это означает, что внутри него мы описываем том (volume) определенного размера:

ResourceName— имя ресурса;VolumeMinor— уникальный номер в кластере, определяющий имя DRBD-устройства в ядре;Size— объем, который требуется для тома.
В LINSTOR есть возможность определить более одного тома на ресурс, но на практике в современных оркестраторах, таких как Kubernetes, OpenStack, Proxmox и OpenNebula, такая возможность нигде не используется.
Таким образом, создаются ресурсы:

Теперь посмотрим на них:

Внутри каждого ресурса, как было сказано выше, можно увидеть тома и дополнительную информацию о них:

MinorNr— номер, назначенный LINSTOR’ом в этом ресурсе;DeviceName— название DRBD-устройства, которое связано сMinorNr;InUse— на каком узле в данный момент используется устройство;State— его состояние.
Создание ресурсов в LINSTOR
При интеграции с Kubernetes для создания ресурса в LINSTOR можно использовать лишь высокоуровневый API оркестратора — например, PersistentVolumeClaims в Kubernetes. Но мы с вами попробуем посмотреть на то, как это действие происходит в самом LINSTOR.
resource-group spawn
Как правило, все драйверы при создании какого-либо устройства используют команду resource-group spawn. Напомню, resource-group — сущность, которая определяет параметры хранения данных в кластере (аналог StorageClass для Kubernetes).
Посмотрим на список доступных resource-groups:

ResourceGroup— имя resource-group.-
Параметры
SelectFilter:PlaceCount— всегда размещать две реплики;StoragePool(s)— размещать с именемssd-lvmthin;LayerStack— используемые слои хранения.
VlmNrs— ID volume-группы. Обратите внимание: как все ресурсы состоят из томов (volume’ов), так и resource-group состоит из volume-групп. Значение0означает не количество volume-group, а их ID.
Посмотрим на volume-группы для нашего resource-group:

Вывод показывает, что внутри resource-group будут создаваться ресурсы всего лишь с одним томом — это стандартная конфигурация для Kubernetes, OpenStack, OpenNebula и Proxmox.
Для создания виртуального тома используется команда:
linstor resource-group spawn default test2 10G default— название resource-группы;test2— название ресурса;10G— необходимый объем.
Таким образом, помимо resource-definition создастся и нужное количество реплик. В нашем случае — три: две — для хранения данных и дополнительная «реплика-арбитр» для обеспечения кворума (она всегда создается автоматически).
Посмотрим на ресурсы:

Дополнительная реплика для поддержания кворума называется TieBreaker.
Resource-definitions, как и сами ресурсы, можно создавать вручную, например:
с помощью команды
create --auto-place(подробнее — в видео c докладом);или
resource create node1 -s storpool(подробнее).
Доставка данных на compute-узлы
Итак, у нас есть хранилище и compute-узлы. Чтобы доставить тома со storage-узлов на compute-узлы, можно было бы использовать iSCSI, но теперь нам это не нужно, так как DRBD начиная с 9 версии умеет создавать бездисковые (diskless) устройства. Они позволяют не хранить данные, но в то же время перенаправлять все операции чтения-записи на storage-узлы.
Создадим такое diskless-устройство:
linstor resource create node3 test4 --disklessВажно понимать, что Kubernetes-драйвер или любой другой драйвер прежде, чем запустить ВМ или контейнер, всегда создаёт diskless-устройство, если на узле нет локальной storage-реплики.
В итоге у нас есть две storage-реплики и один diskless, у которого, когда контейнер запустится, состояние изменится на InUse:

На самом деле этот паттерн позволяет отказаться от отдельных storage-узлов. При этом все тома можно разместить в одном общем кластере:

Получим гиперконвергентную систему:

(Прим. ред.: см. также наш недавний обзор Harvester как пример гиперконвергентного Open Source-решения на базе Kubernetes.)
Это имеет смысл, например, когда медленная сеть или когда необходимо получить максимальную производительность хранилища. Можно размещать данные локально, чтобы реплицировать эти данные через один hop по сети. Это эффективнее, чем, например, два удаленных storage-узла, к которым необходимо обращаться дважды, чтобы записать данные.
Работа компонентов LINSTOR
Есть два основных сервиса:
linstor-controller — запускается в одном экземпляре и представляет собой центральное API и шедулер ресурсов;
linstor-satellite — миньоны LINSTOR’а, устанавливаются на всех storage- и compute-узлах, используются для взаимодействия с менеджером логических томов и настройки DRBD.
Когда мы обращаемся к LINSTOR, чтобы создать том определенного размера, LINSTOR автоматически сканирует все узлы в кластере и выбирает наиболее подходящие. После этого linstor-satellite создает том, конфигурационный файл для DRBD и выполняет команду drbdadm adjust с названием ресурса:
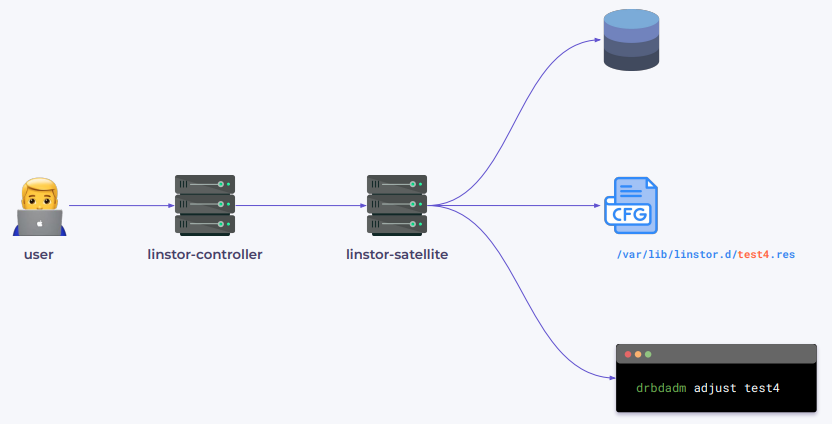
У DRBD есть собственный набор утилит, которые используются для взаимодействия с конфигурацией и ядром:
drbdadm (требует наличия конфигурационного файла) читает конфигурацию ресурса, после чего выполняет все команды через более низкоуровневую утилиту drbdsetup;
drbdsetup — общается напрямую с ядром для настройки DRBD, позволяя добавлять или изменять специфические свойства для каждого устройства.
Работа с DRBD
Копнём ещё чуть глубже и рассмотрим, как DRBD взаимодействуют друг с другом, как выполняется репликация и какие состояния могут быть у наших ресурсов*.
* Обычным пользователям LINSTOR’а эта информация не нужна. Но она крайне полезна для понимания механизмов его работы и при отладке в случае сложных проблем.
Посмотрим на содержимое конфигурационного файла test4.res, который сгенерировал LINSTOR и поместил его для каждого узла отдельно в /var/lib/linstor.d:

test4— название ресурса;options— опции хранения ресурса, из которых видно, что включен кворум;on node 1/2/3— конфигурация каждого из узлов;node-id— ID, который назначается каждому узлу;disk— имя backing-устройства, которое используется для хранения данных; здесь можно увидеть, что на node1 мы используем LVM-том, когда как на node3 значениеnoneуказывает на diskless-устройство;minor— номер устройства в ядре, определяющий его имя (/dev/drbd1008)
Также можем выполнить команду для просмотра состояния устройства. Пример для первого узла:

Важно понимать, что каждый узел — это независимый член кластера со своим собственным состоянием и «мнением».
В данном случае мы видим, что реплика находится в UpToDate, т.е. содержит актуальные данные, а также «видит» состояние двух других реплик в кластере.
Использование созданного ресурса
Начиная с девятой версии ресурс автоматически переводится в режим primary при монтировании или открытии устройства в эксклюзивном режиме.
У DRBD нет как таковой master/slave-репликации. Поэтому даже diskless-узел может быть primary. В таком случае он будет ответственнен за репликацию данных на два других storage-узла, то есть будет читать и писать сразу на оба.
Про взаимодействие с DRBD и split-brain
На данном моменте я предлагаю остановиться, так как объём статьи и так уже выходит за рамки разумного предела. Если вам всё же интересно, как осуществляется взаимодействие с DRBD на низком уровне, предлагаю посмотреть интерактивную презентацию в моем докладе.
Наличие кворума в DRBD позволяет сильно сократить возможность возникновения split-brain. Но рано или поздно вы всё-таки можете столкнуться с такой ситуацией. Split-brain означает, что в кластере есть два независимых состояния и вам нужно выбрать одно из них, чтобы восстановить кластер. Важно понимать, как работает DRBD, чтобы с легкостью диагностировать такие проблемы.
Подробно о том, как работать с DRBD и как «вылечить» split-brain, я рассказываю
в докладе и в комментарии к статье про отладку DRBD9 в LINSTOR.
Подытожим
Kubernetes и LINSTOR очень похожи: оба являются оркестраторами, но работают с разными сущностями.
Kubernetes используется для рабочих нагрузок, использует Docker, containerd, CNI, CSI. А LINSTOR ориентирован на блочные устройства, взаимодействует с DRBD, OpenZFS, LUKS, LVM, ZFS.
Оба оркестратора предоставляют удобный API-интерфейс для взаимодействия.
Несмотря на сходство, у LINSTOR есть своя специфическая логика.
Видео и презентация
Видео с выступления (~46 минут):
Слайды презентации:
Полезные ссылки
«В поисках идеальной кластерной ФС: опыт использования LINSTOR» — мой доклад на Saint HighLoad 2021.
Статья «Траблшутинг DRBD9 в LINSTOR».
Русскоязычное сообщество в Telegram — LINSTOR / DRBD.
P.S.
Читайте также в нашем блоге:
Комментарии (3)

Hixon10
13.08.2022 20:56А какая область применения у такого хранилища? Подозреваю, что для баз данных это не подойдет из-за перфоманса, а также из-за того что многие БД сами занимаются репликацией и шардированием данных, и не требуется такая функциональность.

creker
14.08.2022 15:34Когда нет хранилки и не хочется local path provisioner использовать по тем или иным причинам. Каким-то базам и сервисам не нужно сильно быстрое хранилище, но хочется все же возможность свободно мигрировать поды и не выключать ноды. Тем более что не сказать, что это все будет сильно медленно.
FlashHaos
Хранилища появились несколько раньше. SAN используют уже давно и некорректно это связывать с виртуализацией и контейнерами.