

В продолжение предыдущей статьи поговорим о том, как использовать SQL Server Machine Learning Services. В этой статье приведены варианты использования на языке R.
Для чего должна быть установлена R 4.2.1(https://cran.r-project.org/src/base/R-4/).
Также нам потребуется пакет e1071, его можно установить в R Gui (меню) Пакеты -> Установить пакет.

Если же у вас тоже windows и это не будет работать как и у меня, скачивайте пакет c CRAN и выбирайте Пакеты -> Установить пакеты из локальных файлов, а затем скаченный архив.
Некоторые пакеты требуют установки всех зависимостей, поэтому лучше устранить ошибки загрузки пакетов, если они у вас есть. Список ошибок и пути их решения описаны в блоге у Алексея Селезнева.
Для знакомства с возможностями SQL Server в машинном обучении используется датасет с пассажирами Титаника с Kaggle.

Это самое популярное состязание и есть очень много статей и примеров кода для работы с датасетом, поэтому даже если вы совсем не знаете R получится построить простые модели и визуализацию для датасета.
Идея SQL Server сервисов машинного обучения в том, чтобы работать с данными в БД и анализировать их никуда не выгружая, для нашего эксперимента нужно будет наоборот загрузить данные из csv в SQL Server.
Скачиваем csv файлы с Kaggle.
В SQL Server Management Studio запускаем скрипт создания БД titanic:
CREATE DATABASE titanic;На созданной БД выбираем правой кнопкой в студии “Задачи -> Импорт неструктурированного файла”:
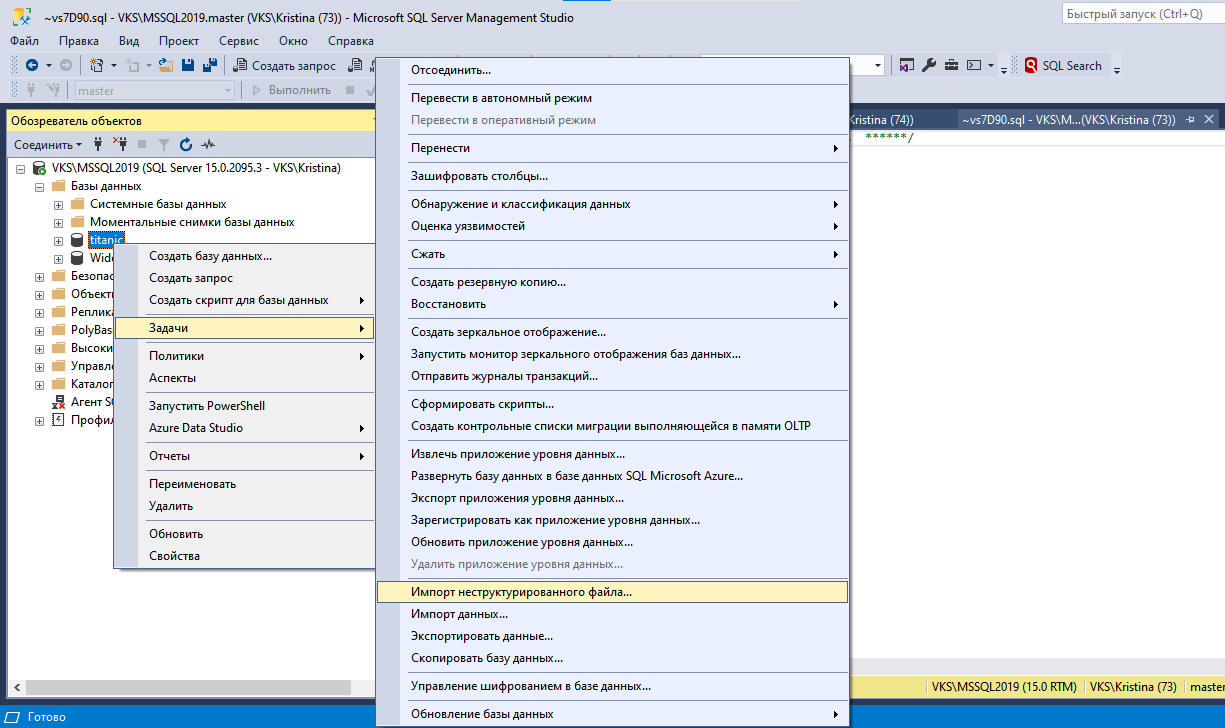
Далее указываем путь к файлу с датасетом train.csv Титаника (таблицу инструмент создаст), и проходим Далее без изменения структуры таблицы или столбцов.

Тоже самое проделываем со вторым файлом test.csv.
Запустим простые скрипты, которые считают процент выживших среди мужчин и женщин:
EXEC sp_execute_external_script @language =N'R'
, @script=N'total_women <- sum(train_data$Sex == ''female'')
# Get the total number of women who survived
survived_women <- sum(train_data[which(train_data$Sex == ''female''), "Survived"])
rate_women = survived_women/total_women
print(total_women)
print(survived_women)
print(rate_women)'
, @input_data_1 =N'SELECT * from dbo.train'
, @input_data_1_name = N'train_data';
GO
EXEC sp_execute_external_script @language =N'R'
, @script=N'# Get the total number of men on the titanic
total_men <- sum(train_data$Sex == ''male'')
# Get the total number of women who survived
survived_men <- sum(train_data[which(train_data$Sex == ''male''), "Survived"])
rate_men = survived_men/total_men
paste("% of men who survived:", rate_men * 100)
print(total_men)
print(survived_men)
print(rate_men)'
, @input_data_1 =N'SELECT * from dbo.train'
, @input_data_1_name = N'train_data';
GO
Далее нам потребуются библиотеки R. Иногда SQL Server не видит библиотек, даже если вы установили их через R приложение:

Для того, чтобы понять есть ли нужная библиотека в доступе SQL Server запустите скрипт:
EXEC sp_execute_external_script @language = N'R', @script = N'OutputDataSet <- data.frame(installed.packages())'Если нужной библиотеки не нашлось, то нужно перейти в каталог SQL Server и установить ее с помощью R.exe (подробнее описано https://www.mssqltips.com/sqlservertip/4760/common-issues-with-r-services-packages/)
У меня SQL Server находится по пути E:\Microsoft SQL Server\MSSQL15.MSSQL2019\R_SERVICES\bin
В норме это будет C:\Program files\Microsoft SQL Server\MSSQL15.<instance_name>\R_SERVICES\bin
В окне R.exe запустите команду установки пакетов (Install Packages from Repositories or Local Files)
install.packages("название пакета", "директория MS SQL Server R Library")В моем случае это:
install.packages("e1071", "E:\\Microsoft SQL Server\\MSSQL15.MSSQL2019\\R_SERVICES\\library", dependencies=TRUE, repos='http://cran.rstudio.com/')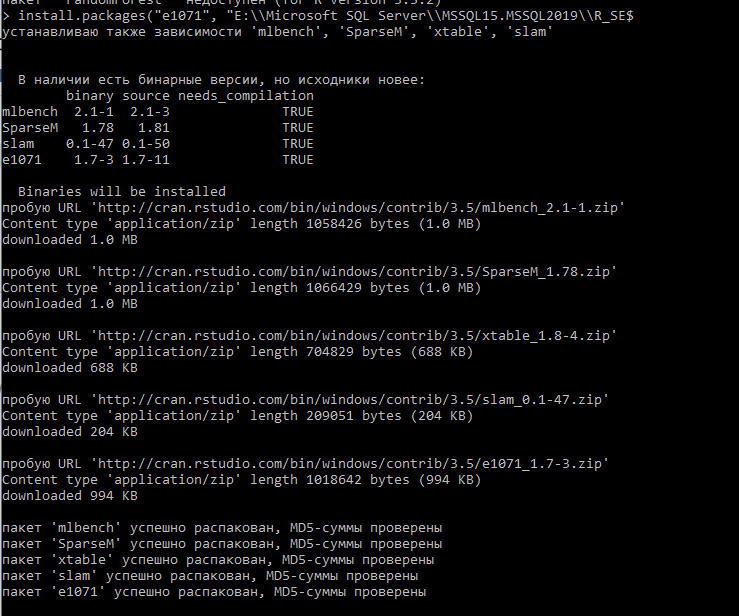
Проверяем наличие пакета в SSMS:

Запускаем создание модели:
EXEC sp_execute_external_script
@language = N'R'
, @script = N'
library(e1071);
fit <-naiveBayes(as.factor(Survived) ~ Pclass + Sex + SibSp + Parch, data=train_data);
trained_model <- data.frame(payload = as.raw(serialize(fit, connection=NULL)));
'
, @input_data_1 = N'SELECT * from dbo.train'
, @input_data_1_name = N'train_data'
, @output_data_1_name = N'trained_model'
WITH RESULT SETS ((model varbinary(max)));Получаем модель и можем ее использовать на тестовых данных из таблицы test, которая получена из загрузки test.csv.
Далее используем несколько входных данных. Для того, чтобы к вашему инстансу можно было подключиться включите TCP/IP

Затем создайте пользователя для подключения к БД
CREATE LOGIN [usrdemo] WITH PASSWORD=N'usrdemo', DEFAULT_DATABASE=[master], CHECK_EXPIRATION=OFF, CHECK_POLICY=OFF
GO
CREATE USER [usrdemo] FOR LOGIN [usrdemo] WITH DEFAULT_SCHEMA=[dbo]
GOЗапускаем создание модели, а затем предсказание на данных из датасета test
USE titanic;
DECLARE @rscript NVARCHAR(MAX),
@sqlscript NVARCHAR(MAX);
SET @rscript = N'
library(e1071);
# train data from InputDataSet
train_data <- InputDataSet
# test from table
conn <- "Driver={SQL Server};Server=VKS\\MSSQL2019;Database=titanic;Uid=usrdemo;Pwd=usrdemo"
query <- "SELECT * FROM dbo.test;"
test_data <- RxSqlServerData(connectionString = conn, sqlQuery = query)
test_data <- rxDataStep(test_data)
fit <-naiveBayes(as.factor(Survived) ~ Pclass + Sex + SibSp + Parch, data=train_data);
trained_model <- data.frame(payload = as.raw(serialize(fit, connection=NULL)));
pred <- predict(fit, test_data, writeModelVars = TRUE)
submission <- data.frame(PassengerId = test_data$PassengerId, Survived = pred)
';
SET @sqlscript = N'SELECT * FROM dbo.train;';
EXEC sp_execute_external_script
@language = N'R',
@script = @rscript,
@input_data_1 = @sqlscript,
@output_data_1_name = N'submission'
WITH RESULT SETS ((PassengerId int, Survived BIT));
GO


Далее можно поэкспериментировать с датасетом - обогатить другими полями и добавить их в формулу, чтобы предсказание получилось более точным.
Также с помощью R можно делать визуализацию данных, но об этом мы поговорим на открытом уроке.