

Меня зовут Алексей Некрасов (@znbiz), я лидер направления Python в МТС, программный директор направления Python и спикер профессии «Python-разработчик» в Skillbox. Сегодня предлагаю обсудить best practices подбора оптимального конкурентного API на Python с учётом поставленной задачи и аппаратных возможностей целевой платформы. Под катом — туториал на эту непростую тему, который я для вас перевел.
При помощи Python решаются задачи для все более высоконагруженных приложений, и для таких вычислений необходимо реализовывать конкурентную обработку. В этом руководстве описана полезная пошаговая процедура для выбора наиболее подходящего конкурентного API.
Проблема с API Python для реализации конкурентности
В стандартной библиотеке Python (stdlib) предлагается три способа для конкурентного выполнения задач в программе — это модуль multiprocessing для конкурентности на уровне процессов, модуль threading для конкурентности на уровне потоков, а также модуль asyncio для конкурентности на основе корутин. Выбор такой широкий, что можно запутаться.
Но на самом деле все еще хуже, чем кажется:
Например, вы выбрали модуль — и что делать дальше: применить пул воркеров (pool of workers, далее в статье будет просто пул воркеров) либо запрограммировать конкурентную задачу самостоятельно?
Если вы выберете пул воркеров, то далее придется использовать Pools API или Executors API.
Даже бывалых Python-разработчиков может обескуражить такое разнообразие.
Какие API для обеспечения конкурентности в Python следует использовать в проекте?
Нужны эмпирические правила, которые помогли бы при выборе наиболее подходящих API для конкурентности. Прежде чем рассмотреть удобную процедуру, помогающую при таком выборе, давайте подробнее рассмотрим задачу и тщательно ее структурируем.
Какой конкурентный API для Python следует использовать? Рассмотрим задачу и тщательно ее структурируем
Итак, вы пишете на Python программу, в которой нужно реализовать конкурентность. Возникает проблема: какой API для этого выбрать?
Не вы один с ней сталкиваетесь. Вероятно, это один из самых распространенных вопросов по поводу Python.
В Python существуют три основных API для конкуренции, вот они:
Корутиновый, предоставляемый в модуле asyncio.
Поточный, предоставляемый в модуле threading.
Процессный, предоставляемый в модуле multiprocessing.
Выбор из этих трех вариантов, можно сказать, относительно простой. Он будет подробнее рассмотрен в следующем разделе. Проблема в том, что потребуется принимать и дальнейшие решения, в частности, использовать ли пул многоразовых воркеров?
Например:
Если вы решите, что вам требуется потоковая конкурентность, то воспользоваться ли пулом потоков или каким-то образом опираться на класс Thread?
Если вы решите, что вам требуется параллелизм на основе процессов, то следует ли воспользоваться пулом процессов или найти способ воспользоваться классом Process?
Далее, если вы решите реализовать конкурентность при помощи повторно используемых рабочих потоков, то и здесь у вас будет на выбор несколько вариантов.
Например:
Если вы решите, что вам нужен пул потоков, то каким классом воспользоваться — ThreadPool или ThreadPoolExecutor?
Если вы решите, что вам нужен пул процессов, то каким классом воспользоваться — Pool или ProcessPoolExecutor?
На следующем рисунке обобщено это дерево решений.
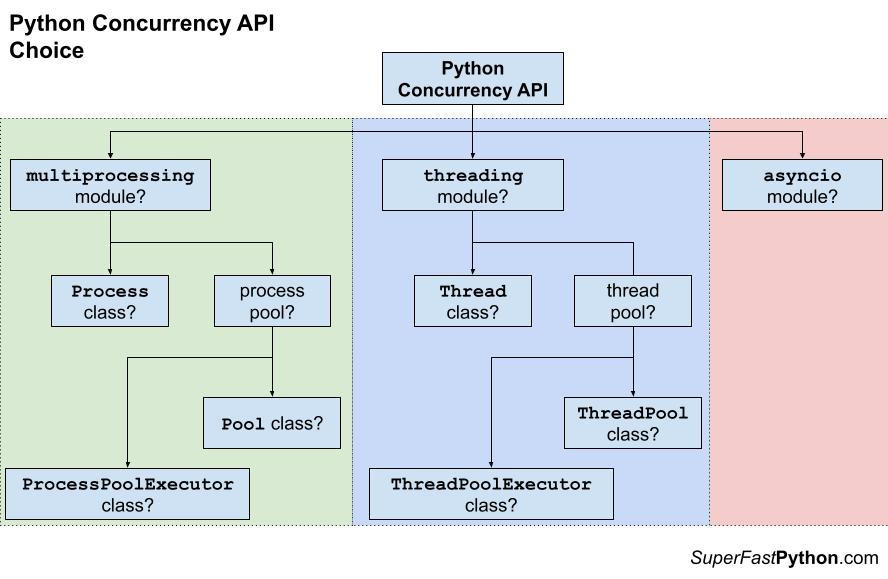
Как же во всем этом сориентироваться?
Процесс выбора API для реализации конкурентности на Python
Один из возможных подходов — пожалуй, самый распространенный — выбирать API ситуативно. При разработке многие решения принимаются именно так, и обычно программа от этого работает ничуть не хуже. Но случается и иначе.
Рекомендуем подбирать конкурентный API Python для вашего проекта в три этапа.
Вот эти этапы:
-
Шаг 1: CPU-Bound (опираемся на ЦП) или I/O-Bound (на операции ввода/вывода) (многопроцессность или многопоточность).
Шаг 1.1 Выбор между AsyncIO и Threading.
Шаг 2: Организация задач: много специальных или одна большая сложная?
Шаг 3: Пулы или исполнители?
Кроме того, вот вам удобная схема, на которой обобщены эти решения:
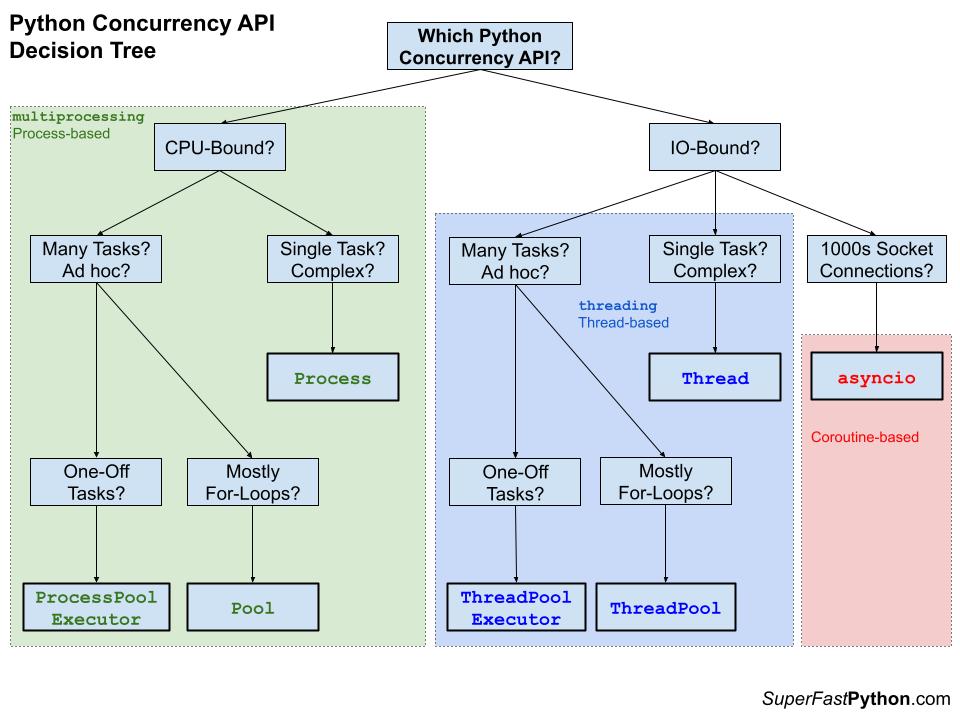
Далее давайте подробнее рассмотрим каждый из этапов и некоторые нюансы.
Шаг 1: CPU-Bound или I/O-Bound?
Первый шаг при выборе API для конкурентности на Python — обдумать ограничивающие факторы той задачи (тех задач), что вы собираетесь решать.
Будут ли эти задачи завязаны в основном на использование ЦП или на ввод/вывод?
Если с этим аспектом разобраться правильно, то все последующие ваши решения будут уже менее важны.
Рассмотрим эти варианты по очереди.
CPU-Bound задачи
CPU-Bound (вычислительными) называются такие задачи, которые требуют выполнения вычислений, но не связаны с вводом/выводом.
В этих операциях участвуют только данные, находящиеся в основной памяти, и над этими данными (или с их применением) выполняются вычисления.
В принципе, единственным ограничивающим фактором этих операций является скорость процессора. Вот почему их называют CPU-Bound.
Примеры таких задач:
Вычисление точек во фрактале.
Оценка числа π.
Разложение на простые множители.
Синтаксический разбор HTML, JSON и т. д., а также документов.
Обработка текста.
Выполнение симуляций.
CPU очень быстрые, а на многих машинах их несколько. Обладая современным аппаратным обеспечением, желательно на полную мощность использовать множество процессорных ядер.
Итак, получив представление о CPU-Bound задачах, давайте поговорим о задачах, предполагающих ввод/вывод.
I/O-Bound задачи
Задачи, ориентированные на ввод/вывод, предполагают считывание данных или запись их на устройство, в файл или в сокет.
Соответственно, это операции над входящими и исходящими данными, и скорость этих операций ограничена возможностями устройства, скоростью чтения/записи с жесткого диска или скоростью сетевого соединения.
Современные ЦП реально быстрые. Процессор с частотой 4 ГГц способен выполнять 4 миллиарда команд в секунду, а на вашей машине процессор наверняка не один.
Выполнение ввода/вывода — очень медленная операция по сравнению со скоростью процессора.
При взаимодействии с устройствами, сокетными соединениями, при считывании и записи файлов требуется вызывать инструкции у вас в операционной системе (и в ядре) и при этом дожидаться, пока операция завершится. Если именно этой операцией в основном и занят ваш процессор — например, если она выполняется в главном потоке программы на Python, — то процессору придется ждать много миллисекунд, фактически простаивать. Поэтому операции ввода/вывода называют блокирующими, так как они ожидают действия либо от пользователей, либо от других компонент системы.
Так теряется время, за которое потенциально можно было бы выполнить миллиарды операций.
Вот примеры задач, ориентированных на ввод/вывод:
Считывание файла с жесткого диска или запись его на диск.
Считывание или запись в стандартный ввод, стандартный вывод или стандартный канал ошибки (stdin, stdout, stderr).
Печать файла.
Загрузка или выгрузка файла.
Запрос к серверу.
Запрос к базе данных.
Съемка фото или запись видео и многое другое.
Теперь познакомившись как с CPU-Bound задачами, так и с I/O-Bound задачами, давайте рассмотрим, какие API Python для реализации конкурентности следует использовать при их решении.
Выбираем API для реализации конкурентности в Python
Напомню, что модуль multiprocessing предоставляет работу с конкурентностью на уровне процессов, а модуль threading обеспечивает конкурентность на уровне потоков в рамках одного процесса.
В принципе, следует использовать конкурентность на уровне процессов, если в решаемой задаче активно задействуется процессор, и конкурентность на уровне потоков, если ожидается много операций, связанных с вводом/выводом.
Модуль multiprocessing подходит для решения задач, сводящихся к вычислению или подсчету неких сущностей, причем когда относительно невелик объем данных, разделяемых между задачами. Многопроцессная обработка не подходит для решения задач, при которых одни процессы активно обмениваются информацией с другими, так как в таком случае накапливаются большие вычислительные издержки, а данные, разделяемые между процессами, необходимо сериализовать.
В таком случае лучше было бы выполнять по задаче на каждое логическое или физическое ядро процессора, тем самым максимально эффективно задействовав аппаратные возможности вашей машины.
Модуль threading лучше подходит для решения задач, которые сводятся к считыванию с устройства ввода/вывода или записи на такое устройства, а вычислений при решении такой задачи относительно немного. Если при решении задачи требуется сильно загружать вычислениями процессор, то многопоточная обработка здесь подойдет плохо. В Python используется глобальная блокировка интерпретатора (GIL) — механизм, не допускающий, чтобы в любой момент выполнялось более одного потока в Python. Как правило, GIL снимается только при выполнении блокирующих операций, например ввода/вывода, либо при работе со специфическими сторонними библиотеками, написанными на C, например с NumPy.
Можно выполнять десятки, сотни или тысячи поточно-ориентированных задач, чтобы максимально задействовать возможности аппаратного обеспечения, поскольку при вводе/выводе большая часть времени тратится на ожидание.
На следующем рисунке обобщено дерево решений, которым стоит пользоваться при выборе подхода к конкурентности — многопоточного или многопроцессного.
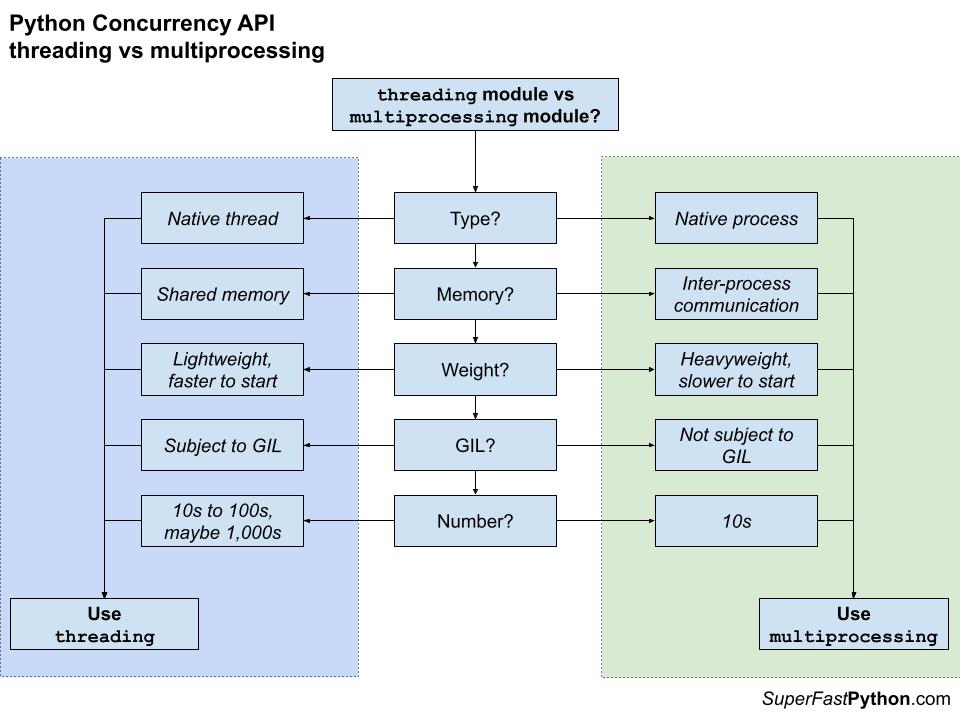
Подробнее о выборе между потоками и процессами можно почитать в следующих статьях:
Далее давайте поговорим об AsyncIO и обсудим, в каких случаях уместен такой подход.
Шаг 1.1 Выбор между Threading и AsyncIO
Если ваши задачи ориентированы в основном на ввод/вывод, то у вас возникает еще одна развилка, на которой требуется принимать решение.
Необходимо выбрать между модулями threading и asyncio.
Напомним, что первый обеспечивает конкурентность на уровне потоков, а второй — конкурентность на уровне корутин в пределах одного потока.
В принципе, следует отдавать предпочтение конкурентности на основе корутин, если у вас много сокет-соединений (или если вы предпочитаете асинхронное программирование), а в других случаях выбирать конкурентность на основе потоков.
Много сокет соединений: пользуйтесь модулем asyncio для организации конкурентности на уровне корутин.
В иных случаях: пользуйтесь модулем threading для организации конкурентности на основе потоков.
Модуль asyncio делает акцент на конкурентном неблокирующем вводе/выводе для сокет-соединений. Например, если ваши задачи ввода/вывода предполагают работу с файлами, то уже по этой причине вариант с asyncio будет неподходящим.
В пользу корутин говорит то, что они легковеснее потоков. Следовательно, единственный поток может нести гораздо больше корутин, чем уместится управляемых потоков в одном процессе. Например, asyncio позволяет выполнять тысячи, десятки тысяч и даже больше корутин для ввода/вывода на основе сокетов. Для сравнения: потоковый API в таком случае может предоставить сотни или в лучшем случае несколько тысяч потоков.
Еще одно соображение — возможно, вы захотите или будете вынуждены применить при разработке программы парадигму асинхронного программирования, например async/await. Следовательно, это требование возобладает над всеми иными требованиями, которые выдвигаются на уровне задач.
Аналогично, вы можете испытывать неприятие к асинхронному программированию, и этот фактор также окажется весомее любых требований, предъявляемых на уровне задач.
Подробнее о том, чем различаются асинхронный подход и конкурентный на основе потоков, рассказано в следующей статье:
Шаг 2: Множество специальных задач или одна глобальная сложная задача?
На втором шаге нужно рассмотреть, требуется ли вам выполнять независимые задачи, обусловленные контекстом, либо перед вами стоит большая сложная задача.
Принимая решение на данной развилке, также нужно обдумать, потребуется ли вам решать одну или много специальных задач — и, если так, не лучше ли задействовать пул воркеров, каждый из которых поддается многократному использованию. Или же перед вами стоит всего одна задача, и в таком случае пул повторно используемых воркеров — это уже перебор.
Этот момент можно обдумать и в другом ключе. С одной стороны, перед вами может стоять всего одна сложная задача (или ограниченное количество таких задач) — например реализовать мониторы, планировщики или подобные задачи, которые могут оказаться долгоживущими и просуществовать до самого завершения программы. Такие задачи не назовешь разовыми, поэтому в их случае не будет особой пользы от пула переиспользуемых воркеров.
Короткоживущие и/или многочисленные специальные задачи: используем пул потоков или пул процессов.
Долгоживущие и/или сложные задачи: используем класс Thread или Process.
В случае, если вы решите работать с конкурентностью на уровне потоков, придется выбирать между пулом потоков и классом Thread.
В случае, если вы решите работать с конкурентностью на уровне процессов, придется выбирать между пулом процессов и классом Process.
Также потребуется учесть и иные соображения, в частности, такие:
Неоднородные или однородные задачи: пожалуй, пул более уместен для набора разнообразных (гетерогенных) задач, а класс Process/Thread лучше использовать в случаях, когда задачи являются однотипными (однородными).
Многократное или однократное использование: пул хорош для многократного использования базовых единиц, на которых построена конкурентность, например для многоразового применения потока или процесса при решении множества задач. В свою очередь, класс Process/Thread более уместен для решения единственной задачи, например, долгоживущей.
Множество задач или одна задача: естественно, пул поддерживает множество задач, возможно, выдаваемых разными способами, тогда как класс Process/Thread поддерживает всего один тип задач, то есть задача решается от начала и до конца, как только она сконфигурирована или переопределена.
Чтобы обрисовать ситуации конкретнее, давайте приведем несколько примеров:
Цикл for, многократно вызывающий функцию, принимающую на каждой итерации разные аргументы. Его лучше реализовать на основе пула потоков, так как воркеры можно автоматически переиспользовать для каждой новой задачи по мере необходимости.
Фоновую задачу, наблюдающую за ресурсом, лучше реализовать при помощи класса Thread/Process, поскольку это долгоиграющая задача, и в ней может заключаться много сложного специализированного функционала, возможно, распределенного между вызовами многих функций.
Со сценарием, скачивающим множество файлов, было бы уместно использовать пул потоков, так как каждая задача длится недолго, и файлов может быть гораздо больше, чем воркеров. Соответственно, каждый воркер можно было бы задействовать многократно, а задачи можно было бы выстраивать в очередь для выполнения.
При решении однократной задачи, в которой поддерживается состояние, можно было бы остановиться на классе Thread/Process, так как класс поддается переопределению: так, чтобы он хранил состояние в переменных экземпляра, а для реализации модульного функционала задействовал методы.
Следующий рисунок поможет выбрать, что лучше использовать: пул воркеров или класс Thread/Process.

Более подробное сравнение пула потоков/процессов и решения одной сложной задачи приводится в постах:
Далее давайте рассмотрим тип пула, который может нам понадобиться.
Шаг 3: пулы или исполнители?
На третьем шаге давайте подберем тип пула, которым будем пользоваться.
В данном случае существует два основных таких типа, вот они:
Пул: multiprocessing.pool.Pool и класс для поддержки потоков в multiprocessing.pool.ThreadPool.
Исполнители (Executors): класс concurrent.futures.Executor и два подкласса ThreadPoolExecutor и ProcessPoolExecutor.
Оба предоставляют пулы воркеров. Сходство между ними большое, а вот различия небольшие и тонкие.
Вот некоторые сходные черты:
Оба существуют в двух версиях: для работы с потоками и для работы с процессами.
Оба могут выполнять специальные задачи.
Оба поддерживают синхронное и асинхронное выполнение задач
Оба поддерживают проверку статуса и ожидание асинхронных задач.
Оба поддерживают функции обратного вызова для выполнения асинхронных задач.
Какой бы вариант вы ни выбрали, это особо не отразится на вашей программе.
Основное различие заключается в интерфейсе, предоставляемом каждым из них. Точнее, речь идет о небольших различиях в расстановке акцентов и в том, как именно обрабатываются задачи.
Например:
Исполнители позволяют отменять уже выданные задачи, а пул — нет.
Исполнители позволяют работать с коллекциями неоднородных задач, а пул — нет.
Исполнители не позволяют принудительно завершить все задачи, а пул позволяет.
Исполнители не предоставляют несколько параллельных версий функции map(), в отличие от пула.
Исполнители позволяют работать с исключениями, выброшенными в рамках задачи, а пул не позволяет.
Пожалуй, основная разница между этими пулами заключается в том, что Pool сосредоточен на конкурентных циклах for, работающих со множеством разных версий функции map(), например, если нужно применить к функции каждый аргумент, содержащийся в списке на перебор.
У исполнителей также есть такая возможность, но они делают акцент скорее на асинхронном выполнении задач и на управлении коллекциями задач.
Следующий рисунок резюмирует различия между пулами и исполнителями
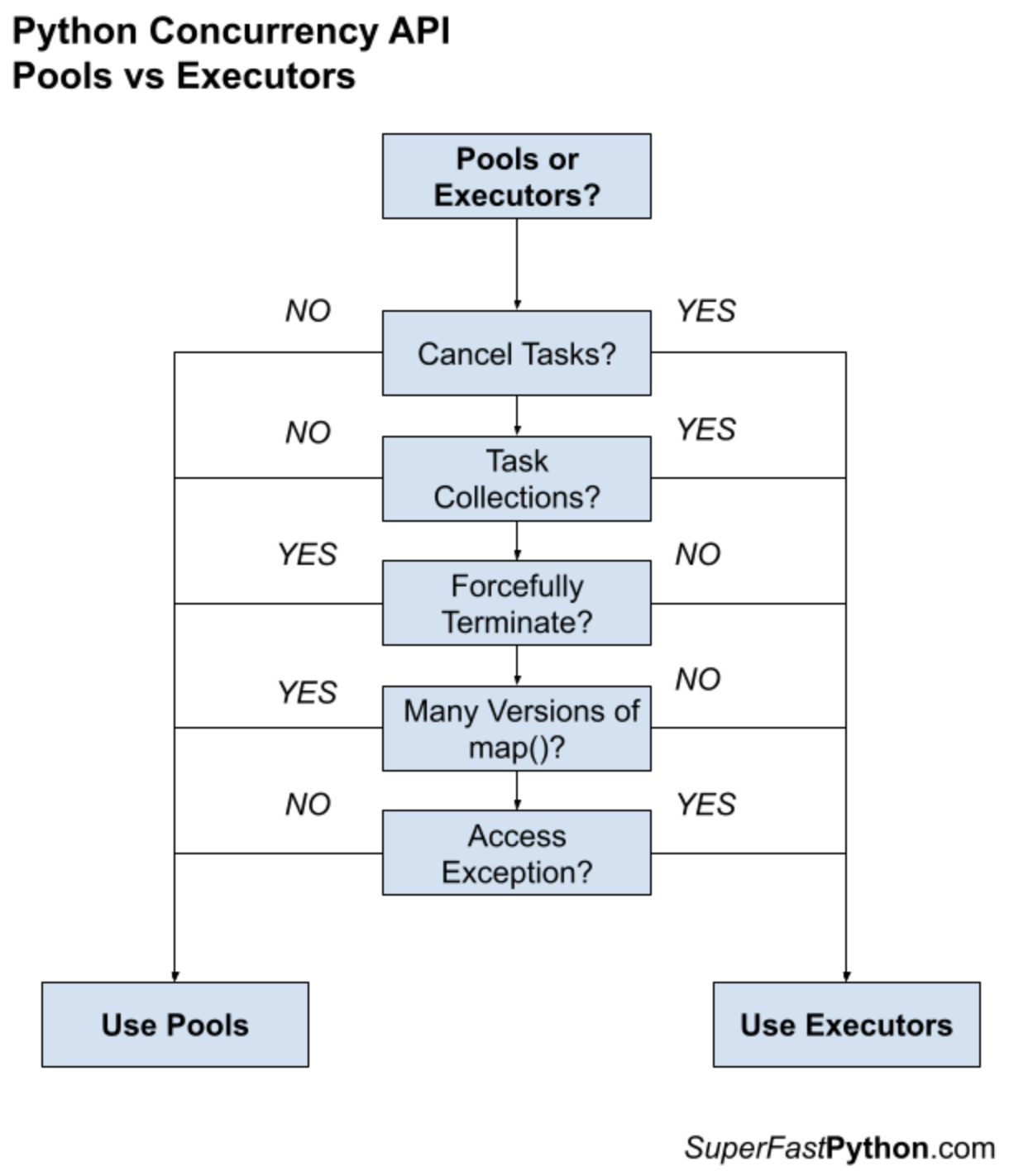
Подведём итог:
В Python для решения конкурентных задач есть три разных реализации:
Многопроцессная — реализованная в модуле multiprocessing. Этот подход стоит выбирать, если у вас CPU-Bound-задачи.
Многопоточная — реализованная в модуле threading. Этот подход стоит выбирать для I/O-Bound-задач.
-
На основе корутин, реализованных в модуле asyncio. Этот подход стоит выбирать для I/O-Bound-задач. Стоит применять когда вы:
3.1 Явно хотите или должны использовать парадигму асинхронного программирования.
3.2 Вам нужно выполнить более 1000 I/O-Bound-задач.
Комментарии (5)

teleport1995
01.09.2022 19:49+1В конце главы "Шаг 3: пулы или исполнители" прикреплен не тот рисунок.

danilovmy
Опять забыт любимый мной curio. A ведь это реально интересная альтернатива asyncio!
Автору спасибо. Я вспомнил, почему я не читаю инфоцыганский SFP: У них много абзацев повторяющих сами себя.
znbiz Автор
Интересный инструмент, почитал.
Единственное, что смущает:
Q: Is Curio meant to be a clone of asyncio?
A: No. Although Curio provides a significant amount of overlapping functionality, the API is different. Compatibility with other libaries is not a goal. (Совместимость с другими библиотеками не является целью.)
Как он себя покажет если мы начнём строить большую систему, где за основу возьмём curio? Придётся ли нам переизобретать велосипеды из-за того что curio не поддерживает интеграцию с текущими библиотеками?
P.S. в статье и правда есть, лишнее, что-то незначительное убрал, но в целом это перевод другой статьи, если совсем причёсывать, то это будет не перевод, а пересказ:)
danilovmy
я фанат David Beazley, автора curio. Потому использую его с начальных версий (rc1). Соответственно - весь код у меня ориентирован на curio. Работает без сбоев, утверждается, что curio быстрее, чем... Но, если я захочу библиотеку поменять на asyncio - то код придется переписывать. Просто импорт иcправить не прокатит. Наоборот, соответственно тоже. И, конечно, dependencies, что в проекте используют asyncio - будут ее и дальше использовать, от этого не уйти. Я думаю, именно это имеется ввиду.