

Данная статья будет полезна тем, чья деятельность связана с Data Engineering, и тем, кто только знакомится с этой славной профессией. Вы узнаете про особенности настройки и интеграции Kafka со Structured Streaming, а также увидите различные способы чтения данных, работы с водяными метками и скользящим окном.
Привет, меня зовут Андрей, я работаю дата-инженером и по совместительству тимлидом разработки на проекте из банковского сектора. За плечами у меня и моих коллег большое количество успешных проектов, касающихся проектирования DWH и разработки ETL-процессов. Нам всем стали уже «родными» такие системы и инструменты как: Oracle, PostgreSQL, GreenPlum, Hive, Impala, YARN, Spark и Airflow (и прочие бигдата-покемоны), которые применялись в режиме пакетной обработки данных. А вот с потоковыми процессами на тот момент плотно работать ещё не приходилось. Нашей команде предстояло разработать «под ключ» систему типа «Real Time Marketing» – в онлайн формате анализировать действия пользователей в мобильном и интернет банке, сверяться и джойниться с множеством различных источников данных, чтобы в итоге эффективно генерировать актуальные и выгодные предложения для каждого из пользователей. В ходе реализации этого проекта мы вынесли много нового для себя, так как задача проектировать многослойное хранилище данных и его наполнение – весьма отличается от стриминговых сервисов. Новым было как проектирование и оптимизация, так и сами технологии. Одними из ключевых инструментов оказались Kafka и Spark Structured Streaming в контексте Python, поэтому в данной статье я хотел бы поделиться набитыми шишками и умозаключениями касательно настройки этих инструментов и их интеграции друг с другом. Уверен, для начинающих это будет полезно и сэкономит много времени и нервов. Ведь время, как известно, самый ценный ресурс.
Итак, начну с более конкретного обозначения проблемы. Первое, с чем мы столкнулись – это отсутствие информации о версиях Hadoop и Spark, которые будут настроены банком на кластере. Безусловно, мы дали свои рекомендации, но последние слово оставалось за заказчиком. Было два очевидных варианта: Spark 2.x и Spark 3.x. Вдобавок к этому, оказалось, что ранее другим подрядчиком уже был написан фрагмент желаемого функционала и написан на RDD-диалекте, который, буду откровенен – весьма недружелюбен своим синтаксисом, особенно после «ванильного» Spark SQL. На старте проекта архитектором ещё не было окончательно решено, в какой версии Spark работать и в какой манере нам предстоит писать.
Возможные варианты:
Kafka 2.X + Spark 3.x совместимый с Kafka + Hadoop 3;
Kafka 2.X + Spark 2.4 + совместимый с Kafka + Hadoop 2 или 3;
Kafka 2.X + Spark 2.x не совместимый с Kafka + Hadoop 2;
Kafka 2.X + Spark 2.x или Spark 3.x, но писать всё равно надо в RDD-манере (что достойно отдельной статьи);
После ещё одной итерации общения с заказчиком мы сошлись, что надо применять Spark не ниже версии 2.4, в котором уже есть поддержка Structured Streaming и Kafka. То есть с Kafka можно работать как со встроенным типом источника и приёмника.
Пару часов поисков в интернете дали понять, что полезная информация о работе с Kafka через Spark есть, но она очень разрозненна. Стало очевидным, что необходимо собрать всё в одном месте и систематизировать на практических примерах. В нашем случае на проекте уже была известна примерная архитектура будущей системы и для экспериментов был предоставлен демо-стенд из нескольких виртуальных серверов.
Из джентельменских соображений для сохранения коммерческой тайны и спасения читателя от лишней информации предлагаю рассмотреть в статье более понятный пример – сервис интернет-рекламы. На демонстрации возможностей Spark это никак не отразится и будет даже наглядней. Помимо этого, хорошими примерами потоковых данных могут служить различные данные с бирж (криптобирж) или всевозможные датчики на предприятии и в офисе.
Если вы недавно начали погружаться в «океан» Big Data-технологий, то будет полезным предварительно узнать – что из себя представляет Kafka, Spark и чем принципиально отличаются Spark Streaming и Structured Streaming. Тех, кому эти слова уже хорошо знакомы, предлагаю перейти к описанию архитектуры системы и её настройке.
Кратко о Spark
Spark – это научный проект зародившийся в калифорнийском университете в 2009 и ставший на текущий момент одним из самых популярных инструментов обработки данных. Его главным автором является румыно-канадский учёный в области информатики Матей Захария (Matei Zaharia). Spark изначально был написан на Scala и затем доработан с помощью Java. Данный инструмент является фрэймворком для распределённой обработки как структурированных, так и слабо структурированных данных. Помимо родных языков Scala, Java, а также R, данный фрэймворк возможно применять и в Python-скриптах.
Spark позволяет работать с различными источниками и приёмниками: будь то реляционные базы данных (PostgreSQL, Oracle), NoSQL (Cassandra, MongoDB), файлы различных форматов (csv, json, parquet) или топики Kafka. Вдобавок к этому в Spark есть 4 модуля, которые упрощают жизнь не только дата-инженеру, но и дата-сайентисту:
SQL – позволяет писать SQL-подобные запросы над различными источниками данных;
Streaming – модуль для работы с потоковыми данными. Именно этому модулю по сути и посвящена статья;
MLlib – набор библиотек машинного обучения;
GraphX – модуль распределённой обработки графов.
Одной из основных идеологий Spark является такое понятие как «ленивые вычисления» (lazy evaluation). То есть реальные вычисления над данными начнутся не сразу, а только тогда, когда Spark увидит в своём плане конкретное действие – например, сохранение данных.
Ещё одной его идеологией (или особенностью) является принцип – не данные к вычислениям, а вычисления к данным. Этот принцип эффективно применяется на HDFS кластере, где большой файл, поделенный и реплицированный на несколько частей, хранится на разных нодах кластера. Spark сам распределяет (транслирует) код-вычислений по всем узлам кластера, разбивает его на подзадачи, создает план выполнения и отслеживает результат выполнения. Все вычисления происходят в оперативной памяти. Ниже – изображение типичной схемы работы Spark-приложения.

При выполнении Spark-приложения первым через SparkSession (в ранних версиях SparkContext) запускается центральный координатор, называемый Driver, он общается со всеми Worker’ами (рабочими узлами кластера), запрашивает выделение ресурсов (RAM и CPU). Каждый рабочий узел состоит из одного или нескольких Executor’ов (Исполнителей), которые отвечают за выполнение Task’а (Задачи) – наименьшая единица процесса, конкретное конечное действие с порцией данных, которая соответствует конкретному разделу RDD. Исполнители регистрируются в Driver’е, который всегда содержит всё информацию об исполнителях. RDD (Resilient Distributed Dataset) – это простая, неизменяемая, распределенная коллекция объектов, хранящихся в оперативной памяти.
Надо отметить, что Spark не стоит на месте – его регулярно улучшают и оптимизируют. До Spark 1.6 был только RDD API с не самой удобной манерой написания трансформаций, а именно – в манере MapReduce. Потом появились такие сущности как Dataframe и Dataset, которые позволили работать с данными как c виртуальной таблицей, хранящейся в оперативной памяти. Тем самым стало возможным работать с данными в SQL-манере (ура!).
В Spark 2.0 появился SparkSession, который стал единой точкой входа для всех операций и данных Spark. Тем самым он заменил предыдущие точки входа, такие как SparkContext, SQLContext, HiveContext, SparkConf и StreamingContext (хотя и продолжает их поддерживать).
Начиная с версии 2.4, Kafka стал встроенным форматом, с которым можно работать с помощью модуля Structured Streaming. В 3 версии Spark произошли
большие изменения в оптимизации: значительно улучшен SQL-движок,
улучшена обработка ошибок Python и исключений PySpark, обрезка динамических
партиций и многое другое. Кому интересны все нововведения Spark 3.0, то рекомендую ознакомиться со статьёй: https://databricks.com/session_na20/deep-dive-into-the-new-features-of-apache-spark-3-0
Особенности Spark Structured Streaming

Библиотека Structured Streaming была представлена в Spark 2.0 в 2016 году как часть проекта Apache Spark и в качестве механизма обработки микропакетного потока. С версии Spark 2.2 он был признан стабильным, что делает Structured Streaming стандартным механизмом потоковой обработки в фреймоврке Spark, а технологию DStreams – устаревшим.
Structured Streaming, так же как и его предшественник Spark Streaming, предназначен для работы с потоковыми источниками данных: TCP-сокеты, файлы (из HDFS, S3, локальных ФС), Kafka, AWS Kinesis и помимо этого SQL и NoSQL базы данных.
Библиотека структурированной потоковой передачи позволяет работать со стандартным инструментарием SQL-запросов, основанном на модуле Spark SQL и API его основных структур данных – Dataframe и Dataset, поддерживаемыми в языках Java, Scala, Python и R.
Устаревший Spark Streaming (также называемый DStream) применяет RDD API и работает по принципу микропакетной обработки потока, при которой потоковые вычисления моделируются как непрерывная серия небольших заданий пакетной обработки в стиле map/reduce.

В новом Structured Streaming’е было внедрена единая унифицированная модель программирования и интерфейс для пакетной и потоковой обработки, тем самым отойдя от RDD API. Поток данных стал рассматриваться как неограниченная таблица.

В Structured Streaming есть три режима вывода:
Append mode
Только новые строки, добавленные к таблице результатов с момента последнего триггера, будут записаны во внешнее хранилище. Это применимо только в запросах, в которых существующие строки в результирующей таблице (в DataFramе) не могут измениться;Update mode
Во внешнем хранилище будут изменены только те строки, которые были обновлены в таблице результатов с момента последнего триггера. Этот режим работает для приемников данных, которые можно обновлять изнутри, например, для таблицы PostgreSQL;Complete mode
Вся обновленная таблица (DataFrame) будет записана во внешнее хранилище.
Помимо этого, в Structured Streaming есть две очень полезные фичи – window() и withWatermark(). Что это такое:
window() – позволяет агрегировать данные с разбивкой по временным окнам (отрезкам), например, каждые 30 секунд или каждые 5 минут. Указываем – по какому полю типа timestamp (дата-время, миллисекунды не обязательно) выполняем агрегацию микропакетов и агрегируем. Вдобавок можно задать время скольжения этого окна, например, в 1 минуту. Таким образом, каждую 1 минуту приложение будет выполнять агрегацию за последние 5 минут;
withWatermark() – предназначен для управления временем ожидания данных для заданного временного периода. Иными словами, позволяет определять «просроченность» приходящих микропакетов. Например, если на часах 12:15, а мы установили окно в 5 минут, такой же период ожидания, и в эти 12:15 пришёл пакет из прошлого за 12:03, то такую порцию данных мы отбросим. Причём это можно делать как по временной метке приёма сообщений, так и по времени их создания на источники (зависит от задачи).
Также важно отметить один очень важный механизм в работе с потоковыми данными – механизм контрольных точек (checkpoint). Их основная цель– обеспечить отказоустойчивость потоковых заданий. Благодаря метаданным, хранящимся в файлах контрольных точек, можно перезапустить обработку в случае сбоя бизнес-логики или технической ошибки. Контрольная точка в Spark представляет из себя физический каталог, отвечающий за хранение четырех типов данных:
source – файлы в этом каталоге содержат информацию о различных источниках, используемых в потоковом запросе. Например, для Apache Kafka исходный файл с контрольной точкой будет содержать карту между разделами (партициями) топика и смещениями при первом выполнении запроса. Это значение неизменяемо и не меняется при выполнении запроса;
offsets – содержит файл с информацией о данных, которые будут обрабатываться при выполнении данного микропакета. Он генерируется перед физическим выполнением микропакета и представлен классом apache.spark.sql.execution.streaming.OffsetSeqLog. Последний элемент из файла смещения – это строка JSON с сопоставлением разделов и смещений для каждого источника данных, задействованного в запросе. Например, в случае с источником «Kafka» он будет хранить имя топика, номер партиции и начальное смещение для данного микропакета: {"some_data": {"0": 341}};
commits (коммиты или логи фиксации) – файл-маркер с информацией о водяном знаке (watermark), который будет использоваться в следующем микропакете. Он представлен классом apache.spark.sql.execution.streaming.CommitLog, а метаданные – org.apache.spark.sql.execution.streaming.CommitMetadata. Файл коммитов содержит только одну запись с водяным знаком, примененным к следующему выполнению запроса: {“nextBatchWatermarkMs”: 1655500250234};
state (состояние) – местоположение контрольной точки. Также отвечает за хранение состояния, созданного логикой обработки с отслеживанием состояния. Эти файлы хранятся в сжатом виде.
Кратко о Kafka
Apache Kafka – это успешный проект компании LinkedIn, который выпущена в свет под лицензией Apache в 2012 году. Это распределённый программный брокер сообщений, т.е. шина сообщений с высокой пропускной способностью, на которой можно в реальном времени обрабатывать все проходящие через неё данные. Если кратко, то Kafka – это распределённый журнал коммитов. У данного инструмента удобный API, он легко масштабируем и отказоустойчив. Базовая терминология:
producer – генератор/источник сообщений;
consumer – подписчик/читатель сообщений;
topic – тема, т.е. тематически отдельный (в идеале однородный) поток сообщений с уникальным наименованием. К примеру: на кабельном телевидении есть канал про рыбалку и, соответственно, все передачи на нём будут только про рыбалку, никак не про кулинарию;
partition – секция/раздел внутри темы. Бытовой пример: перенесёмся во времена, когда бумажные газеты были популярным источником информации. Каждое утро у киоска (брокера) выстраивается длинная очередь, чтобы купить одну и туже финансовую (топик) газету (сообщение), и далее каждый уже читает интересную ему информацию (поле из сообщения). Очередь гудит из-за недовольства долгим ожиданием, некоторые опаздывают на работу. Однажды ставят ещё два киоска (партиции), продающие такие же газеты – очередь значительно сокращается;
offset – смещение. Упрощённо – это порядковый номер сообщения внутри топика (темы).
Принцип работы:

Источники данных (producer'ы) регулярно отправляют сообщения в Kafka и далее они считываются и обрабатываются различными приложениями, то есть потребителями. Сообщения сохраняются в топике, a потребители подписываются на него для получения новых сообщений. Топики (темы) могут «раздуваться» из-за большого количества поступающих данных, поэтому предусмотрена возможность делить такие топики на более мелкие секции (partitions) для улучшения производительности и масштабируемости.
Kafka гарантирует, что все сообщения в пределах партиции будут упорядочены в той последовательности, в которой поступили. Важно отметить, что Kafka не отслеживает, какие записи считываются потребителем и после этого удаляются, а просто хранит их в течение заданного периода времени (в миллисекундах, но можно указать и целые сутки), либо до тех пор, пока не будет достигнут некоторый предел.
Напоследок стоит добавить, что Kafka разворачивается и работает вместе с Zookeeper – службой поддержки информации о конфигурации, именовании, обеспечении синхронизации распределенных приложений. Kafka применяет ZooKeeper для хранения метаданных о партициях своих топиков и брокерах, а также для выбора брокера в качестве контроллера. В версии Kafka 2.8.0 появилась возможность работать без Zookeeper: https://itchef.ru/articles/60157/
Архитектура системы «Рекламная аналитика»
Идея системы вполне простая. Представим, что интернет-агентство размещает рекламу на сайтах и в социальных сетях. Рекламные блоки пишут в топики Kafka информацию о просмотрах и кликах. Далее приложение PySpark Structured Streaming принимает эти данные и всевозможными способами вычисляет/агрегирует/фильтрует/ обогащает и сохраняет в различные приёмники.
Компоненты системы:
Ubuntu;
Java X;
Scala X;
Kafka 2.12;
Spark 2.4 / 3.1.1;
Python 3.X;
Jupyter notebook (опционально).
Это концептуальная модель, поэтому в ней намеренно у некоторых компонентов не указаны конкретные версии в виду их вариативности и взаимосвязанности.
Модель данных:
Поток Kafka «adViews» (источник) – просмотры рекламных блоков (на сайтах и в социальных сетях);
Поток Kafka «adClicks» (источник) – клики по рекламным блокам;
Обработчик данных на PySpark – ETL-процессор;
Локальная ФС – приёмник данных (json-файлы);
Таблица PostgreSQL;
Поток Kafka «adDescription» (приёмник/источник) – дополнительная информация о рекламных блоках;
Поток Kafka «adStatistic» (приёмник/источник) – агрегированная информация о рекламных показателях.

Данные в исходные топики Kafka будут генерироваться с помощь скриптов на Python, моделируя таким образом работу рекламных блоков. Я предпочту демонстрировать разработку в Jupyter notebook, который удобен для отладки простых скриптов и нетребователен к настройке. Вы можете использовать то, что вам привычнее – PyCharm, к примеру, или по «труайтишному» – запускать всё в консоли.
Архитектура системы:
Py-скрипт «producerAdViews.py» генерирует данные в топик Kafka «adViews»;
Py-скрипт «producerAdViewsAndClicks.py» генерирует данные в топики Kafka «adViews» и «adClicks»;
-
Обработчик данных на PySpark принимает данные из Kafka, различными способами обрабатывает их и далее:
Выводит в консоль;
Сохраняет данные в локальную ФС json-файлы;
Отправляет обогащённые данные в топик Kafka «adDescription»;
Сохраняет агрегированные данные порций микропакетов в pg-таблицу «ad_country_aggregations»;
Отправляет агрегированные данные в топик Kafka «adStatistic» – агрегированная информация о рекламных показателях.
Теперь нужно настроить всё это окружение и после перейдём к генерации данных.
Настройка окружения
Установка и настройка всех компонентов системы – это может и не самый интересный, но точно очень важный этап. Именно на нём и было набито больше шишек, которые немного прокачали навыки работы с Linux’ами. Надеюсь, это поможет и вам избежать типичных ошибок и так же прокачаться.
Этап 1 – установка PySpark
Скачиваем свежую и чистую версию Ubuntu (20-ая в моём случае) и устанавливаем все необходимые компоненты для работы c PySpark тех версий, что предлагаются по умолчанию.
Компоненты:
Java 11 (OpenJDK "11.0.15");
Scala 2.11.12;
Python 3.8;
Spark 3.1.1 для Hadoop 3.2 (spark-3.1.1-bin-hadoop3.2);
Jupyter notebook (6.3.0).
Перечень команд установки этих компонентов:
Установка и настройка компонентов в Ubuntu
sudo apt install python3-pip
pip3 install jupyter
jupyter notebook
[shutdown]
sudo apt-get update
sudo apt-get install default-jre
java -version
sudo apt-get install scala
scala -version
pip3 install py4j
>>sudo apt-get install default-jre
переместить в Home
>> скачать spark-3.1.1-bin-hadoop3.2.tgz
>> разорхивировать
sudo tar -zxvf spark-3.1.1-bin-hadoop3.2.tgz
export SPARK_HOME='/home/andrey/spark-3.1.1-bin-hadoop3.2'
export PATH=$SPARK_HOME/bin:$PATH
export PYTHONPATH=$SPARK_HOME/python:$PYTHONPATH
nano ~/.bashrc
[copy all comands creating os variables]
[# - optional]
sudo chmod 777 spark-3.1.1-bin-hadoop3.2
sudo chmod -R 777 spark-3.1.1-bin-hadoop3.2
cd spark-3.1.1-bin-hadoop3.2
cd python
python3
>>> import pyspark
>>> quit()
cd spark-3.1.1-bin-hadoop3.2
sudo chmod 777 python
cd python
sudo chmod 777 pyspark
Компоненты установлены, давайте запустим Jupyter notebook через терминал и проверим работу PySpark.
Пишем в терминале:
jupyter notebookВ браузере должна открыться похожая страница – это и будет среда разработки.
Первыми строками в каждом из скриптов будем подключать модуль PySpark с помощью утилиты «findspark». Для проверки создадим и запустим простое Spark-приложение, которое генерирует датафрэйм и сохраняет его в csv-формате.
import findspark
findspark.init('/home/andrey/spark-3.1.1-bin-hadoop3.2')
import pyspark
from pyspark.sql import SparkSession
print("<<---***--- START ---***--->>")
spark = (SparkSession
.builder
.appName('pyspark_example')
.getOrCreate())
rows = [
(1,"clothes"), (2,"games"), (3,"electronics"),
(4,"cars"), (5,"travel"), (6,"books")
]
schema = "ad_id BIGINT, category STRING"
adCategoryDF = spark.createDataFrame(rows, schema)
adCategoryDF.show()
adCategoryDF.repartition(1).write \
.format("csv") \
.mode("overwrite") \
.option("header", "true") \
.option("sep", "\t") \
.save("./files/test")
print("<<---***--- END ---***--->>")
Убедились, что Spark работает и идём устанавливать Kafka.
Этап 2 – установка Kafka
На момент подготовки материалов версией Kafka, которая была стабильна и наша команда ей доверяла, была «2.12», а если точно – kafka_2.12-3.0.0. Хоть в версии Kafka 2.8.0 появилась возможность работать без Zookeeper, мы решили действовать наверняка, так сказать по старинке, и применять Zookeeper.
Установка и настройка Kafka:
Установка и настройка Kafka в Ubuntu
#download package information from all configured sources
sudo apt-get update
#install java
sudo apt-get install default-jre
java -version
#download binary file
wget -P kafka_distr/ "https://dlcdn.apache.org/kafka/3.0.0/kafka_2.12-3.0.0.tgz"
#extract file
tar -xvzf kafka_distr/kafka_2.12-3.0.0.tgz
#create link on path with kafka
ln -s kafka_distr/kafka_2.12-3.0.0.tgz kafka
#edit config
via~/kafka/config/server.propeties
delete.topic.enable = trueКогда Kafka установлена, запускаем и тестируем – создаем один топик и отправляем в него пару сообщений.
Стартуем Zookeeper:
cd ~/kafka
bin/zookeeper-server-start.sh config/zookeeper.propertiesСтартуем Kafka:
bin/kafka-server-start.sh config/server.propertiesСоздаём топик для тестирования:
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 2 --topic testTopicОтправляем сообщения:
bin/kafka-console-producer.sh --topic testTopic --bootstrap-server localhost:9092
> message_1
> message_2Читаем сообщения (в новом терминале):
bin/kafka-console-consumer.sh --topic testTopic --from-beginning --bootstrap-server localhost:9092 
Убедились, что сообщения отправляются и принимаются – значит, можно приступить к отладке чтения из Kafka с помощью PySpark, где нас и поджидают сюрпризы.
Этап 3 – установка PostgreSQL
С установкой PostgresSQL никаких нюансов нет – просто ставим текущую версию и создаём дополнительно пользователя «developer». С его помощью будем осуществляться jdbc-подключение в Spark-приложении. Также сразу создадим таблицу «ad_country_aggregations» для сохранения порций данных.
Установка и настройка PostgreSQL в Ubuntu
sudo apt update
sudo apt install postgresql postgresql-contrib
#create new role
sudo -u postgres createuser --interactive
>>
Output
Enter name of role to add: developer
Shall the new role be a superuser? (y/n) y
<<
#create db
sudo -u postgres createdb advertising
#add pg-user to Ubuntu
sudo adduser developer
>>
enter password: 123456
Retype new password:
Full name []: developer
Room Number []: 1
Work Phone []: 1
Home Phone []: 1
Other []: 1
Is the information correct? [Y/n] Y
<<
#change password in PostgreSQL for users: postgres and developer
sudo -i -u postgres
psql
ALTER USER postgres PASSWORD 'xxxxxxx';
ALTER USER developer PASSWORD 'xxxxxxx';
>>quite
#connect to db
sudo -i -u developer
psql -U developer -d advertising
CREATE TABLE ad_country_aggregations (
row_timestamp TIMESTAMP default current_timestamp,
row_id SERIAL PRIMARY KEY,
country VARCHAR(50),
count INT,
min INT,
max INT,
sum INT,
avg DOUBLE PRECISION,
time_interval VARCHAR(50)
);
Этап 4 – Интеграция PySpark и Kafka
Так как ранее был установлен Spark версии 3.1.1, то в нём уже давно есть встроенная поддержка Structured Streamig – значит можно смело применить его. Для отладки прочтём данные из того же тестового топика «testTopic». Одно обращение к официальной документации по Spark 3.1.1 сразу же подскажет как написать скрипт. Давайте напишем его и запустим. В скрипте все сообщения, отправленные в топик, будут выводиться в консоль.
Отладочный скрипт чтения из Kafka:
checkpoint_path = "./checkpoint/test_1"
kafka_servers = "localhost:9092"
topic = "testTopic"
import findspark
findspark.init('/home/andrey/spark-3.1.1-bin-hadoop3.2')
from pyspark.sql import SparkSession
spark = (SparkSession
.builder
.appName("consumer_structured_streaming_test_1")
.getOrCreate())
adViewsDF = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("subscribe",topic) \
.option("startingOffsets", "earliest") \
.load() \
.selectExpr("CAST(value AS STRING)")
query = adViewsDF.writeStream.format("console") \
.option("truncate", "false") \
.outputMode("append") \
.option("checkpointLocation", checkpoint_path) \
.start() \
.awaitTermination()Запустив скрипт, сразу же получаем ошибку, что Spark не смог найти библиотеку для работы с таким типом источника как «Kafka».
AnalysisException: Failed to find data source: kafka. Please deploy the application as per the deployment section of "Structured Streaming + Kafka Integration Guide".
Проблема не страшная и решается первой страницей поиска. Находим, что в PySpark-приложении надо явно указать для какой версии Spark какую версию Kafka мы хотим использовать. Делается это командой в пару строк:
import os
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-streaming-kafka-0-10_2.12:3.1.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.1 pyspark-shell'Выполняем и вновь сталкиваемся с ошибкой:
java.lang.IllegalArgumentException: Unsupported class file major version 55
pyspark.sql.utils.StreamingQueryException: 'Unsupported class file major version 55
Недолгие хождения в поисковике наводят на мысль, что лучше поставить Java 8, так как с текущей Java 11-й версии могут быть сюрпризы несовместимости.
Что ж, значит, нам нужно установить Java 8 и указать её как основную (11-ю версию удалять необязательно). Сделать это в Ubuntu можно разными способами, но мне понравился вот этот, как самый быстрый и очевидный:
Скачиваем Java 8, а именно java-8-openjdk-amd64 (1.8.0_312)
sudo apt -y install openjdk-8-jreНастраиваем Java 8, как основную версию.
sudo update-alternatives --config java
# Нажимаем <enter> что бы сохранить текущий выбор [*], или укажите номер из списка:
>> Выбираем usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java
>> Done
Проверяем версию Java.
java -versionСработало.

Давайте вновь попытаемся запустить тестовое приложение. Для проверки можете через терминал отправить в топик новое сообщение – оно должно появится в консоли.
Доработанный отладочный скрипт чтения из Kafka
import os
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-streaming-kafka-0-10_2.12:3.1.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.1 pyspark-shell'
checkpoint_path = "./checkpoint/test_1"
kafka_servers = "localhost:9092"
topic = "testTopic"
import findspark
findspark.init('/home/andrey/spark-3.1.1-bin-hadoop3.2')
from pyspark.sql import SparkSession
spark = (SparkSession
.builder
.appName("consumer_structured_streaming_test_1")
.getOrCreate())
adViewsDF = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("subscribe",topic) \
.option("startingOffsets", "earliest") \
.load() \
.selectExpr("CAST(value AS STRING)")
query = adViewsDF.writeStream.format("console") \
.option("truncate", "false") \
.outputMode("append") \
.option("checkpointLocation", checkpoint_path) \
.start() \
.awaitTermination()Отправляем ещё одно сообщение в Kafka

Приём нового сообщения в PySpark-приложении

На этом настройку среды можно считать завершённой и переходить к генерации данных для исследования различных способов чтения и обработки информации из Kafka.
Но если вдруг интерес или проектная необходимость вынудила вас применять Spark 2.4, то ниже, в свёрнутом блоке, вы узнаете какой ещё нюанс в настройках вас будет ждать.
Настройки для Spark 2.4
Рассмотрим случай, когда необходимо применять Spark ниже 3 версии, но выше 2.3 (если вы используете на проекте версию ещё ниже, то лучше примените не технические навыки, а дипломатические и убедите руководство перейти на более свежую версию). Именно с версии 2.4 Kafka можно применять как встроенный тип источника и приёмника. Держим это в уме и запускаем простое PySpark-приложение для проверки из выше упомянутого примера, без дополнительных подключений (но с py-модулем KafkaUtils).
Примечание:
Чтобы в Jupyter notebook работать со Spark 2.4, достаточно скачать соответствующий jar-ник «spark-2.4.4-bin-hadoop2.7.tgz» и подключить его в приложение.
Приложения для чтения из Kafka:
import findspark
findspark.init('/home/andrey/spark-2.4.4-bin-hadoop2.7')
from pyspark.sql import SparkSession
from pyspark.streaming.kafka import KafkaUtils
checkpoint_path = "./checkpoint/test_2"
kafka_servers = "localhost:9092"
topic = "testTopic"
spark = (SparkSession
.builder
.appName("consumer_structured_streaming_test_2")
.getOrCreate())
adViewsDF = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("subscribe",topic) \
.option("startingOffsets", "earliest") \
.load() \
.selectExpr("CAST(value AS STRING)")
query = adViewsDF.writeStream.format("console") \
.option("truncate", "false") \
.outputMode("append") \
.option("checkpointLocation", checkpoint_path) \
.start() \
.awaitTermination()При запуске скрипта сразу получаем ошибку:
TypeError: an integer is required (got type bytes)
Из топиков на форумах понимаем, что ошибка намекает на несовместимость версии Python 3.8 (и 3.9) для PySpark 2.4. Надо установить Python 3.7 и указать его как основную версию.
Скачиваем и устанавливаем Python 3.7.
sudo apt update
sudo apt install python3.7Меняем основную версию Python:
Способ 1
nano ~/.bashrc
>> [write OS variable]
alias python=/usr/bin/python3.7Способ 2
sudo update-alternative --install usr/bin/python python usr/bin/python3.7 1
sudo update-alternative --install usr/bin/python python usr/bin/python3.8 2Но увы, в случае с Jupyter’ом этого оказалось мало. В нём продолжала работать по умолчанию версия Python 3.8 и самый простой способ поменять её – явно указать в начале скрипта. Также можно воспользоваться модулем venv (который мы и применяли на проекте), но в рамках тренировок в Jupyter’е можно прибегнуть к более короткому способу. Помимо этого, мне пришлось скопировать набор библиотек для Python 3.7 из директории Python 3.8:
# копируем python библиотеки для Jupyter из python3.8 (директория site-packages) в python3.7
cp -R /home/andrey/.local/lib/python3.8/site-packages /home/andrey/.local/lib/python3.7/site-packages
sudo chmod -R 777 /home/andrey/.local/lib/python3.7/site-packages
# Первой строкой в notebook’е Jupiter указывайте явно применение pythhon 3.7
%%script /usr/bin/python3.7Запускаем приложение ещё раз и получаем новую ошибку:
py4j.protocol.Py4JJavaError: An error occurred while calling o31.load.
: org.apache.spark.sql.AnalysisException: Failed to find data source: kafka. Please deploy the application as per the deployment section of "Structured Streaming + Kafka Integration Guide".;
Идём искать причины и решения. Находим то, что необходимо скачать и подключить в config’e spark-приложения пару jar-ников для Kafka. Помимо этого нужно будет подключить библиотеку «pyspark.streaming.kafka».
.config("spark.jars","/home/andrey/spark_jars/spark-sql-kafka-0-10_2.11-2.4.4.jar,/home/andrey/spark_jars/kafka-clients-0.10.1.0.jar")Теперь всё готово для запуска тестового приложения.
%%script /usr/bin/python3.7
checkpoint_path = "./checkpoint/test_2"
kafka_servers = "localhost:9092"
topic = "testTopic"
import findspark
findspark.init('/home/andrey/spark-2.4.4-bin-hadoop2.7')
from pyspark.sql import SparkSession
from pyspark.streaming.kafka import KafkaUtils
spark = (SparkSession
.builder
.appName("consumer_structured_streaming_test_2")
.config("spark.jars","/home/andrey/spark_jars/spark-sql-kafka-0-10_2.11-2.4.4.jar,/home/andrey/spark_jars/kafka-clients-0.10.1.0.jar")
.getOrCreate())
adViewsDF = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("subscribe",topic) \
.option("startingOffsets", "earliest") \
.load() \
.selectExpr("CAST(value AS STRING)")
query = adViewsDF.writeStream.format("console") \
.option("truncate", "false") \
.outputMode("append") \
.option("checkpointLocation", checkpoint_path) \
.start() \
.awaitTermination()Генерация данных
Как уже упоминал ранее, в качестве исходных данных будут применяться два скрипта-генератора на Python, которые будут посылать сообщения в Kafka, и 1 csv-файлик. О них по порядку:
producerAdViews.py – информация о просмотрах рекламы на сайтах. Передаёт в формате json атрибуты:
event_time – время события с добавлением или вычитанием случайной величины;
ad_id – ID рекламного блока (из справочника);
country – страна из которой зашли на сайт;
site;
view_duration – длительность просмотра рекламы.
В скрипте настроено так, что сообщения будут отправляться с паузой в 1 секунду и всего таких сообщений должно отправиться 60. Вы можете изменить эту величину.
producerAdViews.py
from kafka import KafkaProducer
from json import dumps
from kafka.errors import KafkaError
from time import sleep
from numpy.random import choice, randint
import time
import datetime
def getRandomValue():
new_dict = {}
country_list = ['ISL','DEU','SWE','ESP', 'UGA','JPN']
site_list = ['site1.ru','site2.com','site3.com','site4.es','site5.de','site6.jp',
'site7.ru','site8.com','site9.com','site10.es','site11.de','site12.jp']
ts = time.time() + randint(-15, 0)
event_time = datetime.datetime.fromtimestamp(ts).strftime('%Y-%m-%d %H:%M:%S')
new_dict['event_time'] = event_time
new_dict['ad_id'] = randint(1, 5)
new_dict['country'] = choice(country_list)
new_dict['site'] = choice(site_list)
new_dict['viewing_duration'] = randint(1, 15)
return new_dict
producer = KafkaProducer(bootstrap_servers=['localhost:9092'],
value_serializer = lambda x:dumps(x).encode('utf-8'),
compression_type = 'gzip')
topic_name = 'adViews'
k = 0
while k < 60:
k += 1
random_data = getRandomValue()
print(random_data)
try:
future = producer.send(topic = topic_name, value = random_data)
message_metadata = future.get(timeout=10)
print(f"""[+] message_metadata: {message_metadata.topic}, partition: {message_metadata.partition}, offset: {message_metadata.offset}""")
except Exception as e:
print(f">>> Error: {e}")
finally:
producer.flush()
sleep(1)
producer.close()producerAdViewsAndClicks.py – генератор двух потоков о просмотрах и кликах по рекламным блокам. Для просмотров всё аналогично предыдущему скрипту и для кликов почти так же:
click_time – время события с добавлением или вычитанием случайной величины;
ad_id;
country;
site.
producerAdViewsAndClicks.py
from kafka import KafkaProducer
from json import dumps
from kafka.errors import KafkaError
from time import sleep
from numpy.random import choice, randint
import time
import datetime
def getRandomValue():
adViews_dict = {}
adClicks_dict = {}
country_list = ['ISL','DEU','SWE','ESP','UGA','JPN','BRA']
site_list = ['site1.ru','site2.com','site3.com','site4.es','site5.de','site6.jp',
'site7.ru','site8.com','site9.com','site10.es','site11.de','site12.jp']
ts = time.time() + randint(-10, 0)
event_time = datetime.datetime.fromtimestamp(ts).strftime('%Y-%m-%d %H:%M:%S')
ts = time.time() + randint(-20, 0)
click_time = datetime.datetime.fromtimestamp(ts).strftime('%Y-%m-%d %H:%M:%S')
ad_id = randint(1, 5)
country = choice(country_list)
site = choice(site_list)
viewing_duration = randint(1, 15)
adViews_dict['event_time'] = event_time
adViews_dict['ad_id'] = ad_id
adViews_dict['country'] = country
adViews_dict['site'] = site
adViews_dict['viewing_duration'] = viewing_duration
adClicks_dict['click_time'] = click_time
adClicks_dict['ad_id'] = ad_id
adClicks_dict['country'] = country
adClicks_dict['site'] = site
return adViews_dict, adClicks_dict
producer1 = KafkaProducer(bootstrap_servers=['localhost:9092'],
value_serializer = lambda x:dumps(x).encode('utf-8'),
compression_type = 'gzip')
producer2 = KafkaProducer(bootstrap_servers=['localhost:9092'],
value_serializer = lambda x:dumps(x).encode('utf-8'),
compression_type = 'gzip')
k = 0
while k < 60:
k += 1
random_data_views, random_data_clicks = getRandomValue()
print(random_data_views)
try:
res = producer1.send(topic = 'adViews', value = random_data_views)
msg = res.get(timeout=10)
print(f""" [+] message_metadata: {msg.topic}, partition: {msg.partition}, offset: {msg.offset}""")
except Exception as e:
print(f">>> Error: {e}")
finally:
producer.flush()
click_is_happend = randint(0, 10)
if click_is_happend > 5:
print("+ click:")
print(random_data_clicks)
try:
res = producer2.send(topic = 'adClicks', value = random_data_clicks)
msg = res.get(timeout=10)
print(f""" [+] message_metadata: {msg.topic}, partition: {msg.partition}, offset: {msg.offset}""")
except Exception as e:
print(f">>> Error: {e}")
finally:
producer.flush()
print("-------------------------------------------------------------------------------------------------")
sleep(1)
producer1.close()
producer2.close()В обоих генераторах в поле event_time, а также click_time значение может отклонятся от реального на +-10 и 20 секунд – это нужно для демонстрации работы водяных знаков с окнами (withWatermark(); window()), в том числе, в объединении двух потоков (Stream-Stream Join).
ad_parameters.csv – различная информация о рекламных блоках, которые транслируются на сайты. Этот файл будет полезен для выполнения операции Join между потоком и статичными данными (Stream join Static DataFrame). Структура файла весьма простая:
ad_id;
category – краткое наименование категории рекламы;
ad_block_parameters.csv
ad_id category
1 clothes
2 games
3 electronics
4 cars
5 travel
6 booksKafka и Structured Streaming
Ниже – примеры методов чтения и обработки данных из Kafka, так сказать, на все случаи продуктовой жизни (почти на все). Принцип отладки скриптов прост – запускайте Spark-приложение и затем скрипт генератора данных.
Чтение данных по триггеру
Можно читать данные сразу по мере поступления от источника. В нашем случае микропакеты поступают каждую секунду. Данные будем выводить в консоль:
kafkaDF = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("subscribe",topic) \
.option("startingOffsets", "earliest") \
.load() \
.selectExpr("CAST(value AS STRING)")
query = kafkaDF.writeStream.format("console") \
.option("truncate", "false") \
.outputMode("append") \
.option("checkpointLocation", checkpoint_path) \
.start() \
.awaitTermination()Полный скрипт (ex_1_1)
import os
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-streaming-kafka-0-10_2.12:3.1.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.1 pyspark-shell'
checkpoint_path = "./checkpoint/ex_1_1"
kafka_servers = "localhost:9092"
topic = "adViews"
import findspark
findspark.init('/home/andrey/spark-3.1.1-bin-hadoop3.2')
from pyspark.sql import SparkSession
spark = (SparkSession
.builder
.appName("consumer_structured_streaming_ex_1_1")
.getOrCreate())
adViewsDF = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("subscribe",topic) \
.option("startingOffsets", "earliest") \
.load() \
.selectExpr("CAST(value AS STRING)")
query = adViewsDF.writeStream.format("console") \
.option("truncate", "false") \
.outputMode("append") \
.option("checkpointLocation", checkpoint_path) \
.start() \
.awaitTermination()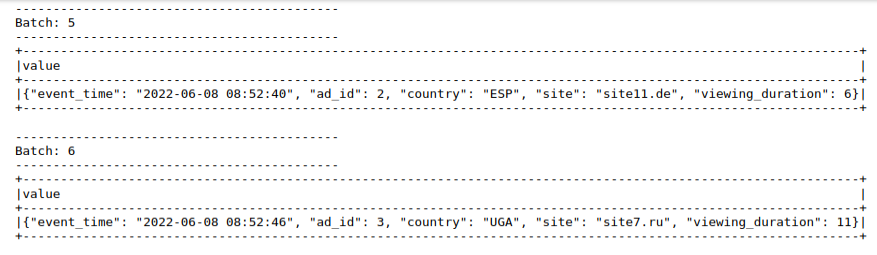
Примечание:
Если вы будете отлаживать скрипты в Jupyter и в одном notebook’е у вас будет несколько разных spark-скриптов, то лучше перезапускайте ядро Notebook’а перед запуском нового Spark-скрипта.
Можно увеличить размер микропакета и накапливать в нём по несколько сообщений. Это делается с помощью триггера и параметра «processingTime». Настроим размер микропакета в 5 секунд. Также добавим парсинг json-полей с помощью функции «from_json» на основании объявленной схемы. Это уже более интересный вариант в отличии от предыдущего, где данные поля выводились одной строкой. Чтобы этот метод работал, понадобится подключить пару библиотек: «pyspark.sql.functions» и «pyspark.sql.types».
schema = StructType([ \
StructField("event_time", TimestampType(), True), \
StructField("ad_id", IntegerType(), True), \
StructField("country", StringType(), True), \
StructField("site", StringType(), True), \
StructField("viewing_duration", IntegerType(), True) \
])
query = kafkaDF.select(from_json(col("value"), schema).alias("t")) \
.select("t.event_time", "t.ad_id", "t.country", "t.site", "t.viewing_duration") \
.writeStream.format("console") \
.option("truncate", "false") \
.outputMode("append") \
.option("checkpointLocation", checkpoint_path) \
.trigger(processingTime='5 seconds') \
.start() \
.awaitTermination()полный скрипт (ex_1_2)
import os
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-streaming-kafka-0-10_2.12:3.1.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.1 pyspark-shell'
checkpoint_path = "./checkpoint/ex_1_2"
kafka_servers = "localhost:9092"
topic = "adViews"
import findspark
findspark.init('/home/andrey/spark-3.1.1-bin-hadoop3.2')
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
spark = (SparkSession
.builder
.appName("consumer_structured_streaming_ex_1_2")
.getOrCreate())
kafkaDF = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("subscribe",topic) \
.option("startingOffsets", "earliest") \
.load() \
.selectExpr("CAST(value AS STRING)")
schema = StructType([ \
StructField("event_time", TimestampType(), True), \
StructField("ad_id", IntegerType(), True), \
StructField("country", StringType(), True), \
StructField("site", StringType(), True), \
StructField("viewing_duration", IntegerType(), True) \
])
query = kafkaDF.select(from_json(col("value"), schema).alias("t")) \
.select("t.event_time", "t.ad_id", "t.country", "t.site", "t.viewing_duration") \
.writeStream.format("console") \
.option("truncate", "false") \
.outputMode("append") \
.option("checkpointLocation", checkpoint_path) \
.trigger(processingTime='5 seconds') \
.start() \
.awaitTermination()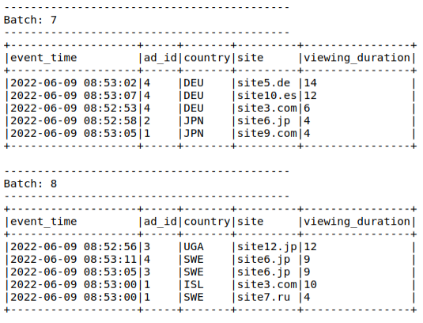
Надписи наподобие «Batch 7, Batch 8» означают порядковый номер микропакета на основании сохранённых данных в директории checkpoint’а.

Давайте взглянем на содержимое – 8-го offset’а
{"batchWatermarkMs":0,"batchTimestampMs":1654753995003,"conf":{"spark.sql.streaming.stateStore.providerClass":"org.apache.spark.sql.execution.streaming.state.HDFSBackedStateStoreProvider","spark.sql.streaming.join.stateFormatVersion":"2","spark.sql.streaming.stateStore.compression.codec":"lz4","spark.sql.streaming.flatMapGroupsWithState.stateFormatVersion":"2","spark.sql.streaming.multipleWatermarkPolicy":"min","spark.sql.streaming.aggregation.stateFormatVersion":"2","spark.sql.shuffle.partitions":"200"}}
{"adViews":{"1":635,"0":620}}
Первая часть текста с указанием значений параметров не представляет большого интереса, а вот последняя строка – наоборот. В этой строке содержится информация о том, на каком смешении (подобие id-сообщения) в каждой из партиций завершилось чтение данных из Kafka в микропакет. То есть в 8-мом микропакете для партиции 1 последнее сообщение 635 – 1 = 634, а для партиции 0 это 620 – 1 = 619.
Давайте взглянем на сообщения, которые отправлял генератор данных «producerAdViews.py».
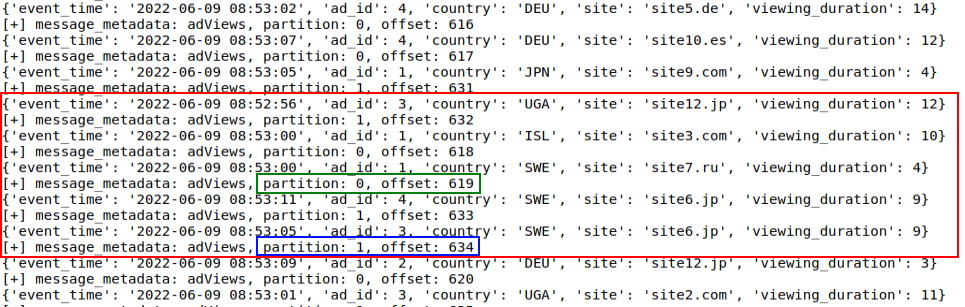
Красной рамкой выделены те 5 сообщений, которые попали в 8-й Микропакет (с 5 секундным наполнением). Также на нём выделены последние сообщения в каждой из партиций: 1 – 634, 0 – 619. Таким образом, после падения и повторного запуска приложения будет понятно – с каких сообщений надо продолжить чтение.
Подробно назначение ChekPoint’ов в Spark и принцип работы Kafka описан в начале статьи, в блоках с теорией.
При повторном запуске приложения после остановки может появится ошибка/исключение «StreamingQueryException: Writing job aborted». Это исключение указывает на то, что Spark не может сопоставить последние данные checkpoint’a с момента паузы с новым микропакетом и не может корректно обработать его для записи (или вывода в консоль). Это, как правило, возникает, если ваше потоковое приложение долго простояло в паузе и незагруженные сообщения уже успели удалиться их Kafka. Длительностью хранения сообщений в топике Kafka можно управлять с помощью параметра «retention.ms».
Быстро решается это как минимум двумя способами:
1) Предварительное очищение директории checkpoint и чтение потока продолжиться «с чистого листа». Микропакеты будут считаться опять с 1;
def remove_thing(path):
if os.path.isdir(path):
shutil.rmtree(path)
else:
os.remove(path)
def empty_directory(path):
for i in glob.glob(os.path.join(path, '*')):
remove_thing(i)
try:
empty_directory(checkpoint_path)
except Exception as e:
print("Exception: ", e)Полный скрипт (ex_1_3)
import os
import shutil
import glob
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-streaming-kafka-0-10_2.12:3.1.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.1 pyspark-shell'
checkpoint_path = "./checkpoint/ex_1_3"
kafka_servers = "localhost:9092"
topic = "adViews"
def remove_thing(path):
if os.path.isdir(path):
shutil.rmtree(path)
else:
os.remove(path)
def empty_directory(path):
for i in glob.glob(os.path.join(path, '*')):
remove_thing(i)
try:
empty_directory(checkpoint_path)
except Exception as e:
print("Exception: ", e)
import findspark
findspark.init('/home/andrey/spark-3.1.1-bin-hadoop3.2')
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
kafka_servers = "localhost:9092"
topic = "adViews"
spark = (SparkSession
.builder
.appName("consumer_structured_streaming_ex_1_3")
.getOrCreate())
kafkaDF = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("subscribe",topic) \
.option("startingOffsets", "earliest") \
.load() \
.selectExpr("CAST(value AS STRING)")
schema = StructType([ \
StructField("event_time", TimestampType(), True), \
StructField("ad_id", IntegerType(), True), \
StructField("country", StringType(), True), \
StructField("site", StringType(), True), \
StructField("viewing_duration", IntegerType(), True) \
])
query = kafkaDF.select(from_json(col("value"), schema).alias("t")) \
.select("t.event_time", "t.ad_id", "t.country", "t.site", "t.viewing_duration") \
.writeStream.format("console") \
.option("truncate", "false") \
.outputMode("append") \
.option("checkpointLocation", checkpoint_path) \
.trigger(processingTime='5 seconds') \
.start() \
.awaitTermination()2) Указать опцию «failOnDataLoss - false».
.option("failOnDataLoss", "false") \Полный скрипт (ex_1_4)
import os
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-streaming-kafka-0-10_2.12:3.1.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.1 pyspark-shell'
checkpoint_path = "./checkpoint/ex_1_4"
kafka_servers = "localhost:9092"
topic = "adViews"
import findspark
findspark.init('/home/andrey/spark-3.1.1-bin-hadoop3.2')
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
spark = (SparkSession
.builder
.appName("consumer_structured_streaming_ex_1_4")
.getOrCreate())
kafkaDF = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("subscribe",topic) \
.option("startingOffsets", "earliest") \
.option("failOnDataLoss", "false") \
.load() \
.selectExpr("CAST(value AS STRING)")
schema = StructType([ \
StructField("event_time", TimestampType(), True), \
StructField("ad_id", IntegerType(), True), \
StructField("country", StringType(), True), \
StructField("site", StringType(), True), \
StructField("viewing_duration", IntegerType(), True) \
])
query = kafkaDF.select(from_json(col("value"), schema).alias("t")) \
.select("t.event_time", "t.ad_id", "t.country", "t.site", "t.viewing_duration") \
.writeStream.format("console") \
.option("truncate", "false") \
.outputMode("append") \
.option("checkpointLocation", checkpoint_path) \
.trigger(processingTime='5 seconds') \
.start() \
.awaitTermination()Во всех вариантах вы потеряете некоторое количество сообщений, но это не помешает приложению принимать последующие порции данных из Kafka.
Чтение конкретного диапазона сообщений Kafka в Static DataFrame
Если ваш поток пропустил сообщения за какой-то период, но фактически в Kafka они всё ещё лежат или вам в принципе нужно прочесть какой-то конкретный диапазон данных, в Spark это делается очень просто. Нужно указать левую и правую границы смещений для партиций Kafka и применить метод «read» вместо «readstream».
kafkaDF = spark \
.read \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("subscribe",topic) \
.option("startingOffsets", """{"adViews":{"1":910,"0":908}}""") \
.option("endingOffsets", """{"adViews":{"1":928,"0":925}}""") \
.load() \
.selectExpr("CAST(value AS STRING)")Полный скрипт (ex_1_6)
import os
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-streaming-kafka-0-10_2.12:3.1.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.1 pyspark-shell'
checkpoint_path = "./checkpoint/ex_1_6"
kafka_servers = "localhost:9092"
topic = "adViews"
import findspark
findspark.init('/home/andrey/spark-3.1.1-bin-hadoop3.2')
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
spark = (SparkSession
.builder
.appName("consumer_structured_streaming_ex_1_2")
.getOrCreate())
kafkaDF = spark \
.read \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("subscribe",topic) \
.option("startingOffsets", """{"adViews":{"1":910,"0":908}}""") \
.option("endingOffsets", """{"adViews":{"1":928,"0":925}}""") \
.load() \
.selectExpr("CAST(value AS STRING)")
schema = StructType([ \
StructField("event_time", TimestampType(), True), \
StructField("ad_id", IntegerType(), True), \
StructField("country", StringType(), True), \
StructField("site", StringType(), True), \
StructField("viewing_duration", IntegerType(), True) \
])
batchDataDF = kafkaDF.select(from_json(col("value"), schema).alias("t")) \
.select("t.event_time", "t.ad_id", "t.country", "t.site", "t.viewing_duration") \
batchDataDF.show()
batchDataDF.write.format("json") \
.mode("overwrite") \
.save("./results/ex_1_6")
Чтение только новых сообщений
Если при повторном запуске приложения вы хотите сперва получать огромный микропакет со множеством предыдущих сообщений из топика Kafka, укажите в опции «startingOffests» значение «latest».
kafkaDF = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("subscribe",topic) \
.option("startingOffsets", "latest") \
.option("failOnDataLoss", "false") \
.load() \
.selectExpr("CAST(value AS STRING)")
Полный скрипт (ex_1_5)
import os
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-streaming-kafka-0-10_2.12:3.1.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.1 pyspark-shell'
checkpoint_path = "./checkpoint/ex_1_5"
kafka_servers = "localhost:9092"
topic = "adViews"
import findspark
findspark.init('/home/andrey/spark-3.1.1-bin-hadoop3.2')
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
spark = (SparkSession
.builder
.appName("consumer_structured_streaming_ex_1_5")
.getOrCreate())
kafkaDF = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("subscribe",topic) \
.option("startingOffsets", "latest") \
.option("failOnDataLoss", "false") \
.load() \
.selectExpr("CAST(value AS STRING)")
schema = StructType([ \
StructField("event_time", TimestampType(), True), \
StructField("ad_id", IntegerType(), True), \
StructField("country", StringType(), True), \
StructField("site", StringType(), True), \
StructField("viewing_duration", IntegerType(), True) \
])
query = kafkaDF.select(from_json(col("value"), schema).alias("t")) \
.select("t.event_time", "t.ad_id", "t.country", "t.site", "t.viewing_duration") \
.writeStream.format("console") \
.option("truncate", "false") \
.outputMode("append") \
.option("checkpointLocation", checkpoint_path) \
.trigger(processingTime='5 seconds') \
.start() \
.awaitTermination()Также повторного чтения данных из Kafka можно избежать (точнее сократить) за счёт настроек самого топика. Измените время хранения сообщений в топике до 1 секунды, чтобы не считывать при повторном запуске Spark-приложения все предыдущие сообщения. Длительность хранения указывается в миллисекундах.
#purge kafka topic (change retention)
bin/kafka-configs.sh --bootstrap-server localhost:9092 --alter --topic transaction --add-config retention.ms=1000Фильтрация данных
Structured Streaming позволяет очень легко фильтровать данные. Для этого достаточно указать опцию «filter» и прописать условие. Давайте, к примеру, будем выводить только те рекламные показы, которые были сделаны из Уганды (UGA).
query = kafkaDF.select(from_json(col("value"), schema).alias("t")) \
.select("t.event_time", "t.ad_id", "t.country", "t.site", "t.viewing_duration") \
.filter("t.country = 'UGA'") \
.writeStream.format("console") \
.option("truncate", "false") \
.outputMode("append") \
.option("checkpointLocation", checkpoint_path) \
.trigger(processingTime='5 seconds') \
.start() \
.awaitTermination()Полный скрипт (ex_2_1)
import os
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-streaming-kafka-0-10_2.12:3.1.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.1 pyspark-shell'
checkpoint_path = "./checkpoint/ex_2_1"
kafka_servers = "localhost:9092"
topic = "adViews"
import findspark
findspark.init('/home/andrey/spark-3.1.1-bin-hadoop3.2')
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
kafka_servers = "localhost:9092"
topic = "adViews"
spark = (SparkSession
.builder
.appName("consumer_structured_streaming_ex_2_1")
.getOrCreate())
kafkaDF = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("subscribe",topic) \
.option("startingOffsets", "latest") \
.option("failOnDataLoss", "false") \
.load() \
.selectExpr("CAST(value AS STRING)")
schema = StructType([ \
StructField("event_time", TimestampType(), True), \
StructField("ad_id", IntegerType(), True), \
StructField("country", StringType(), True), \
StructField("site", StringType(), True), \
StructField("viewing_duration", IntegerType(), True) \
])
query = kafkaDF.select(from_json(col("value"), schema).alias("t")) \
.select("t.event_time", "t.ad_id", "t.country", "t.site", "t.viewing_duration") \
.filter("t.country = 'UGA'") \
.writeStream.format("console") \
.option("truncate", "false") \
.outputMode("append") \
.option("checkpointLocation", checkpoint_path) \
.trigger(processingTime='5 seconds') \
.start() \
.awaitTermination()Как видно, некоторые пакеты пришли пустыми, так как не содержали показов по заданному фильтру.


Фильтрацию можно выполнять и по нескольким условиям. Например, выводить только те рекламные показы, что были в Европейских странах и длительностью более 4 секунд.
query = kafkaDF.select(from_json(col("value"), schema).alias("t")) \
.select("t.event_time", "t.ad_id", "t.country", "t.site", "t.viewing_duration") \
.filter("t.country in ('DEU','SWE','ESP') and t.viewing_duration > 4") \
.writeStream.format("console") \
.option("truncate", "false") \
.outputMode("append") \
.option("checkpointLocation", checkpoint_path) \
.trigger(processingTime='5 seconds') \
.start() \
.awaitTermination()Полный скрипт (ex_2_2)
import os
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-streaming-kafka-0-10_2.12:3.1.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.1 pyspark-shell'
checkpoint_path = "./checkpoint/ex_2_2"
kafka_servers = "localhost:9092"
topic = "adViews"
import findspark
findspark.init('/home/andrey/spark-3.1.1-bin-hadoop3.2')
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
kafka_servers = "localhost:9092"
topic = "adViews"
spark = (SparkSession
.builder
.appName("consumer_structured_streaming_ex_2_2")
.getOrCreate())
kafkaDF = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("subscribe",topic) \
.option("startingOffsets", "latest") \
.option("failOnDataLoss", "false") \
.load() \
.selectExpr("CAST(value AS STRING)")
schema = StructType([ \
StructField("event_time", TimestampType(), True), \
StructField("ad_id", IntegerType(), True), \
StructField("country", StringType(), True), \
StructField("site", StringType(), True), \
StructField("viewing_duration", IntegerType(), True) \
])
query = kafkaDF.select(from_json(col("value"), schema).alias("t")) \
.select("t.event_time", "t.ad_id", "t.country", "t.site", "t.viewing_duration") \
.filter("t.country in ('DEU','SWE','ESP') and t.viewing_duration > 4") \
.writeStream.format("console") \
.option("truncate", "false") \
.outputMode("append") \
.option("checkpointLocation", checkpoint_path) \
.trigger(processingTime='5 seconds') \
.start() \
.awaitTermination()Join со статическим DataFrame
Допустим вам нужно дополнить получаемую информацию из топика Kafka какой-то дополнительной информацией из csv / json файла или таблицы БД. Для этого можно воспользоваться методом join, если есть ключ, по которому соединяться.
В случае с нашей рекламной системой в файле «ad_parameters.csv» хранится информация о категориях рекламных блоков. В нём есть поле <ad_id>, как и в потоке данных, по ним и будем джойниться. Spark поддерживает все типовые SQL соединения: INNER, LEFT OUTER, RIGHT OUTER, LEFT ANTI, LEFT SEMI, CROSS, SELF JOIN. В примере ниже будет применён inner join для вывода категории рекламы.
query = adViewsDF.select(from_json(col("value"), schemaAdViews).alias("t")) \
.select("t.event_time", "t.ad_id", "t.country", "t.site", "t.viewing_duration") \
.join(adParametersDF, "ad_id") \
.select("event_time", "ad_id", "category", "country", "site", "viewing_duration") \
.writeStream.format("console") \
.option("truncate", "false") \
.outputMode("append") \
.option("checkpointLocation", checkpoint_path) \
.trigger(processingTime='5 seconds') \
.start() \
.awaitTermination()Полный скрипт (ex_3_1)
import os
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-streaming-kafka-0-10_2.12:3.1.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.1 pyspark-shell'
checkpoint_path = "./checkpoint/ex_3_1"
kafka_servers = "localhost:9092"
topic = "adViews"
import findspark
findspark.init('/home/andrey/spark-3.1.1-bin-hadoop3.2')
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
spark = (SparkSession
.builder
.appName("consumer_structured_streaming_ex_3_1")
.getOrCreate())
schemaAdParam = "ad_id int, category string"
adParametersDF = spark \
.read \
.format("csv") \
.option("header", "true") \
.option("delimiter","\t") \
.schema(schemaAdParam) \
.load("./files/ad_parameters.csv")
#adParametersDF.show()
#adParametersDF.printSchema()
adViewsDF = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("subscribe",topic) \
.option("startingOffsets", "latest") \
.option("failOnDataLoss", "false") \
.load() \
.selectExpr("CAST(value AS STRING)")
schemaAdViews = StructType([ \
StructField("event_time", TimestampType(), True), \
StructField("ad_id", IntegerType(), True), \
StructField("country", StringType(), True), \
StructField("site", StringType(), True), \
StructField("viewing_duration", IntegerType(), True) \
])
query = adViewsDF.select(from_json(col("value"), schemaAdViews).alias("t")) \
.select("t.event_time", "t.ad_id", "t.country", "t.site", "t.viewing_duration") \
.join(adParametersDF, "ad_id") \
.select("event_time", "ad_id", "category", "country", "site", "viewing_duration") \
.writeStream.format("console") \
.option("truncate", "false") \
.outputMode("append") \
.option("checkpointLocation", checkpoint_path) \
.trigger(processingTime='5 seconds') \
.start() \
.awaitTermination()
А чтобы пример был интересней, добавим фильтр «показы только категории ‘clothes’».
Полный скрипт (ex_3_2)
import os
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-streaming-kafka-0-10_2.12:3.1.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.1 pyspark-shell'
checkpoint_path = "./checkpoint/ex_3_2"
kafka_servers = "localhost:9092"
topic = "adViews"
import findspark
findspark.init('/home/andrey/spark-3.1.1-bin-hadoop3.2')
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
spark = (SparkSession
.builder
.appName("consumer_structured_streaming_ex_3_2")
.getOrCreate())
schemaAdParam = "ad_id int, category string"
adParametersDF = spark \
.read \
.format("csv") \
.option("header", "true") \
.option("delimiter","\t") \
.schema(schemaAdParam) \
.load("./files/ad_parameters.csv")
#adParametersDF.show()
#adParametersDF.printSchema()
adViewsDF = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("subscribe",topic) \
.option("startingOffsets", "latest") \
.option("failOnDataLoss", "false") \
.load() \
.selectExpr("CAST(value AS STRING)")
schemaAdViews = StructType([ \
StructField("event_time", TimestampType(), True), \
StructField("ad_id", IntegerType(), True), \
StructField("country", StringType(), True), \
StructField("site", StringType(), True), \
StructField("viewing_duration", IntegerType(), True) \
])
query = adViewsDF.select(from_json(col("value"), schemaAdViews).alias("t")) \
.select("t.event_time", "t.ad_id", "t.country", "t.site", "t.viewing_duration") \
.join(adParametersDF, "ad_id") \
.select("event_time", "ad_id", "category", "country", "site", "viewing_duration") \
.filter("category = 'clothes'") \
.writeStream.format("console") \
.option("truncate", "false") \
.outputMode("append") \
.option("checkpointLocation", checkpoint_path) \
.trigger(processingTime='5 seconds') \
.start() \
.awaitTermination()Обогащённые данные можно далее отправлять в ещё один топик Kafka.
query = adViewsDF.select(from_json(col("value"), schemaAdViews).alias("t")) \
.select("t.event_time", "t.ad_id", "t.country", "t.site", "t.viewing_duration") \
.join(adParametersDF, "ad_id") \
.select(to_json(struct("event_time", "ad_id", "category", "country", "site", "viewing_duration")).alias("value")) \
.writeStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("topic","adDescription") \
.option("checkpointLocation", checkpoint_path) \
.trigger(processingTime='5 seconds') \
.start() \
.awaitTermination()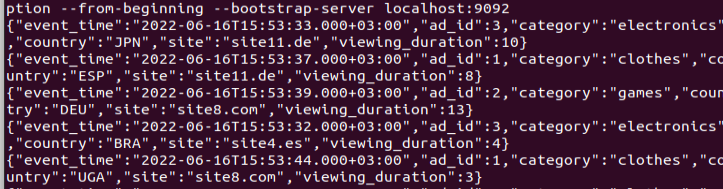
Стоит отметить, что вы можете записывать эти потоковые данные в файлы различных форматов. Самые типичные – это json, parquet и csv. Сохраняя эти файлы в директорию, из которой читает Hive-таблица, вы по сути будете дописывать данные в эту самую Hive-таблицу (главное – будьте внимательны со схемой данных).
Агрегация данных
Одной из типичных задач при работе с данными и, в частности, с потоковыми данными является аналитика. И под этой аналитикой могут подразумеваться различные подсчёты: средние значения, суммы, количества, минимум, максимум и так далее. Давайте же попробуем подсчитать все такие значения для поля c длительностью просмотра рекламы в разрезе наименования стран.
query = adViewsDF.select(from_json(col("value"), schemaAdViews).alias("t")) \
.select("t.event_time", "t.ad_id", "t.country", "t.site", "t.viewing_duration") \
.groupBy("country") \
.agg(count("*").alias("count"),
min("viewing_duration").alias("min"),
max("viewing_duration").alias("max"),
sum("viewing_duration").alias("sum"),
avg("viewing_duration").alias("avg")) \
.writeStream \
.format("console") \
.option("truncate", "false") \
.outputMode("append") \
.option("checkpointLocation", checkpoint_path) \
.trigger(processingTime='5 seconds') \
.start() \
.awaitTermination()Вместо результата получаем исключение
AnalysisException: Append output mode not supported when there are streaming aggregations on streaming DataFrames/DataSets without watermark;
Spark чётко указывает на необходимость применения «водяного знака».
Но прежде чем перейти к следующему разделу про водяные знаки, будет полезным показать – как всё-таки можно выполнять агрегацию над каждым из микропакетов. Для этого необходимо воспользоваться оператором «foreachBatch(<userFunction>)» – он позволяет применять пользовательскую функцию с произвольной логикой к каждому микропакету на выходе потокового запроса. По сути внутри функции вы уже работаете со статичным DataFram’ом и, соответственно, можете применять все доступные для него методы.
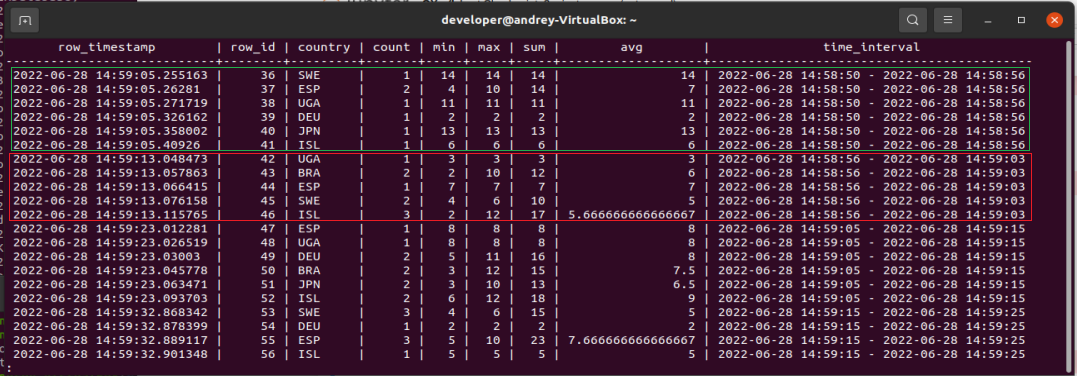
Ниже пример записи пакетов из Structured Streaming в PostgreSQL-таблицу «ad_country_aggregations». В этом скрипте каждые 10 секунд «накопленный» микропакет отправляется в пользовательскую функцию «writeToPostgres()». В этой функции выполняется агрегация значений для статистики и отдельно определяется минимальное и максимальное время начала просмотра рекламы в рамках всего микропакета. Это позволит видеть примерный интервал происхождения действий.
def writeToPostgres(df, epoch_id):
intervalDF = df.agg(min("event_time").alias("min_event_time"),
max("event_time").alias("max_event_time"))
min_event_time = intervalDF.head(1)[0][0]
max_event_time = intervalDF.head(1)[0][1]
agrDF = df.groupBy("country") \
.agg(count("*").alias("count"),
min("viewing_duration").alias("min"),
max("viewing_duration").alias("max"),
sum("viewing_duration").alias("sum"),
avg("viewing_duration").alias("avg")) \
.select("country","count", "min", "max", "sum", "avg",
concat(lit(min_event_time), lit(" - "), lit(max_event_time)).alias("time_interval"))
agrDF.show(truncate=False)
agrDF.write \
.format('jdbc') \
.option("url", "jdbc:postgresql://" + db_host) \
.option("driver", "org.postgresql.Driver") \
.option("dbtable", "ad_country_aggregations") \
.option("user", db_user) \
.option("password", db_password) \
.mode("append") \
.save()
. . .
streamData = adViewsDF.select(from_json(col("value"), schemaAdViews).alias("t")) \
.select("t.event_time", "t.ad_id", "t.country", "t.site", "t.viewing_duration") \
streamData.writeStream \
.foreachBatch(writeToPostgres) \
.option("checkpointLocation", checkpoint_path) \
.trigger(processingTime='10 seconds') \
.start() \
.awaitTermination()Полный скрипт (ex_4_2)
import os
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-streaming-kafka-0-10_2.12:3.1.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.1 pyspark-shell'
checkpoint_path = "./checkpoint/ex_4_1"
kafka_servers = "localhost:9092"
import os
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-streaming-kafka-0-10_2.12:3.1.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.1 pyspark-shell'
checkpoint_path = "./checkpoint/ex_4_2"
kafka_servers = "localhost:9092"
topic = "adViews"
db_host = "localhost:5432/advertising"
db_user = "developer"
db_password = "123456"
import findspark
findspark.init('/home/andrey/spark-3.1.1-bin-hadoop3.2')
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
def writeToPostgres(df, epoch_id):
intervalDF = df.agg(min("event_time").alias("min_event_time"),
max("event_time").alias("max_event_time"))
min_event_time = intervalDF.head(1)[0][0]
max_event_time = intervalDF.head(1)[0][1]
agrDF = df.groupBy("country") \
.agg(count("*").alias("count"),
min("viewing_duration").alias("min"),
max("viewing_duration").alias("max"),
sum("viewing_duration").alias("sum"),
avg("viewing_duration").alias("avg")) \
.select("country","count", "min", "max", "sum", "avg",
concat(lit(min_event_time), lit(" - "), lit(max_event_time)).alias("time_interval"))
agrDF.show(truncate=False)
agrDF.write \
.format('jdbc') \
.option("url", "jdbc:postgresql://" + db_host) \
.option("driver", "org.postgresql.Driver") \
.option("dbtable", "ad_country_aggregations") \
.option("user", db_user) \
.option("password", db_password) \
.mode("append") \
.save()
spark = (SparkSession
.builder
.appName("consumer_structured_streaming_ex_4_2")
.config("spark.jars","/home/andrey/spark_jars/postgresql-42.4.0.jar")
.getOrCreate())
adViewsDF = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("subscribe",topic) \
.option("startingOffsets", "latest") \
.option("failOnDataLoss", "false") \
.load() \
.selectExpr("CAST(value AS STRING)")
schemaAdViews = StructType([ \
StructField("event_time", TimestampType(), True), \
StructField("ad_id", IntegerType(), True), \
StructField("country", StringType(), True), \
StructField("site", StringType(), True), \
StructField("viewing_duration", IntegerType(), True) \
])
streamData = adViewsDF.select(from_json(col("value"), schemaAdViews).alias("t")) \
.select("t.event_time", "t.ad_id", "t.country", "t.site", "t.viewing_duration") \
streamData.writeStream \
.foreachBatch(writeToPostgres) \
.option("checkpointLocation", checkpoint_path) \
.trigger(processingTime='10 seconds') \
.start() \
.awaitTermination()Выводим агрегированные DataFram’ы

Проверяем записи в PostgreSQL.
Скрипты установки PostgreSQL и создания таблицы приведены в начале статьи.
Водяные знаки и скользящее окно
Если механика работы withWatermark() и window() в Structured Streaming вам хорошо знакома, то можете переходить к примерам, а если нет, то рекомендую ознакомится с теорией в начале статьи и со статьёй по ссылке (в ней создатели Sparkподробно рассказали о механике работы водяных знаков и скользящего окна): https://databricks.com/blog/2017/05/08/event-time-aggregation-watermarking-apache-sparks-structured-streaming.html
Для демонстрации работы данных фич давайте реализуем агрегацию из предыдущего раздела. И для начала установим следующие настройки:
Период актуальности / ожидания записи – 10 секунд по полю <event_time>;
Группировка по полю и полю <event_time> так же каждые 10 секунд;
Таким образом, благодаря случайному уменьшению значения <event_time> в генераторе часть значений будут откидываться из подсчёта из-за своей «запоздалости». Оставшиеся, прошедшие проверку на свежесть значения, будут агрегированы в рамках заданного периода. Важно отметить, что без применения window() Spark не дал бы выполнять данные операции в режиме добавления (append).
query = adViewsDF.select(from_json(col("value"), schemaAdViews).alias("t")) \
.select("t.event_time", "t.ad_id", "t.country", "t.site", "t.viewing_duration") \
.withWatermark("event_time", "10 seconds") \
.groupBy("country", window("event_time", "10 seconds").alias("timewindow")) \
.agg(count("*").alias("count"),
min("viewing_duration").alias("min"),
max("viewing_duration").alias("max"),
sum("viewing_duration").alias("sum"),
avg("viewing_duration").alias("avg")) \
.writeStream \
.format("console") \
.option("truncate", "false") \
.outputMode("append") \
.option("checkpointLocation", checkpoint_path) \
.start() \
.awaitTermination()Полный скрипт (ex_5_1)
import os
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-streaming-kafka-0-10_2.12:3.1.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.1 pyspark-shell'
checkpoint_path = "./checkpoint/ex_5_1"
kafka_servers = "localhost:9092"
topic = "adViews"
import findspark
findspark.init('/home/andrey/spark-3.1.1-bin-hadoop3.2')
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
spark = (SparkSession
.builder
.appName("consumer_structured_streaming_ex_5_1")
.getOrCreate())
adViewsDF = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("subscribe",topic) \
.option("startingOffsets", "latest") \
.option("failOnDataLoss", "false") \
.load() \
.selectExpr("CAST(value AS STRING)")
schemaAdViews = StructType([ \
StructField("event_time", TimestampType(), True), \
StructField("ad_id", IntegerType(), True), \
StructField("country", StringType(), True), \
StructField("site", StringType(), True), \
StructField("viewing_duration", IntegerType(), True) \
])
query = adViewsDF.select(from_json(col("value"), schemaAdViews).alias("t")) \
.select("t.event_time", "t.ad_id", "t.country", "t.site", "t.viewing_duration") \
.withWatermark("event_time", "10 seconds") \
.groupBy("country", window("event_time", "10 seconds").alias("timewindow")) \
.agg(count("*").alias("count"),
min("viewing_duration").alias("min"),
max("viewing_duration").alias("max"),
sum("viewing_duration").alias("sum"),
avg("viewing_duration").alias("avg")) \
.writeStream \
.format("console") \
.option("truncate", "false") \
.outputMode("append") \
.option("checkpointLocation", checkpoint_path) \
.start() \
.awaitTermination()Запускаем приложение, генератор и ждём, когда накопятся первые микропакеты с агрегацией. Первый пакет содержит всего две записи и его временной промежуток «09:30:00- 09:30:10».

Давайте посмотрим на логи генератора данных:

Видим те самые два сообщения, попавшие в первый интервал. Обратите внимание, что Spark определяет значения интервалов в «ровных значениях». Пусть первое сообщение произошло по <event_time> в «09:30:04» – агрегируемый интервал в 10 секунд будет считаться с «09:30:00».
Далее мы получаем следующий пакет, в котором для агрегации применились сообщения с <evet_time> между «09:30:10 – 09:30:20».
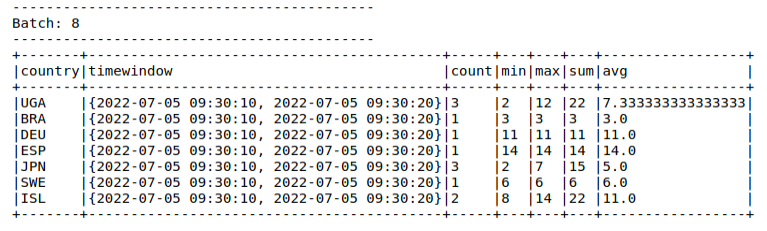
Для наглядной демонстрации работы withWatermark() увеличим в генераторе размер искажения значений <event_time> c «-10» до «-30», сохранив withWatermark("event_time", "10 seconds")
ts = time.time() + randint(-30, 0)
Запустим Spark-приложение заново. В результате были сформированы вот такие микропакеты:

Один интервал был пропущен (16:46:10 – 16:46-20), а для первого пакета было учтено только одно сообщение.
Смотрим исходные данные: в логах producer’а видно, что для пропущенного интервала относительно <event_time> сообщения были как будто сформированы раньше, но отправлены заметно позже этого времени (более 10 секунд). Аналогично и для сообщения в «16:46:09». Spark, сравнивая <event_time> полученного сообщения с предыдущим, счёл некоторые из них запоздавшими.
Теперь добавим окну интервал скольжения в 5 секунд и посмотрим, как будут агрегироваться данные.
query = adViewsDF.select(from_json(col("value"), schemaAdViews).alias("t")) \
.select("t.event_time", "t.ad_id", "t.country", "t.site", "t.viewing_duration") \
.withWatermark("event_time", "10 seconds") \
.groupBy("country", window("event_time", "10 seconds", "5 seconds").alias("timewindow")) \
.agg(count("*").alias("count"),
min("viewing_duration").alias("min"),
max("viewing_duration").alias("max"),
sum("viewing_duration").alias("sum"),
avg("viewing_duration").alias("avg")) \
.writeStream \
.format("console") \
.option("truncate", "false") \
.outputMode("append") \
.option("checkpointLocation", checkpoint_path) \
.start() \
.awaitTermination()Пакеты стали формироваться чаще за счёт увеличенного количества интервалов. Каждый следующий интервал вмещает в себя часть предыдущих значений, которые попадают во вторые 5 секунд предыдущего периода.

Агрегированную информацию вы также можете записывать файлами и в последствии периодически обрабатывать их и записывать далее в различные приёмники.
Пример записи в json с партицированием по странам.
Полный скрипт (ex_5_3)
import os
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-streaming-kafka-0-10_2.12:3.1.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.1 pyspark-shell'
checkpoint_path = "./checkpoint/ex_5_3"
kafka_servers = "localhost:9092"
topic = "adViews"
import findspark
findspark.init('/home/andrey/spark-3.1.1-bin-hadoop3.2')
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
spark = (SparkSession
.builder
.appName("consumer_structured_streaming_ex_5_3")
.getOrCreate())
adViewsDF = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("subscribe",topic) \
.option("startingOffsets", "latest") \
.option("failOnDataLoss", "false") \
.load() \
.selectExpr("CAST(value AS STRING)")
schemaAdViews = StructType([ \
StructField("event_time", TimestampType(), True), \
StructField("ad_id", IntegerType(), True), \
StructField("country", StringType(), True), \
StructField("site", StringType(), True), \
StructField("viewing_duration", IntegerType(), True) \
])
query = adViewsDF.select(from_json(col("value"), schemaAdViews).alias("t")) \
.select("t.event_time", "t.ad_id", "t.country", "t.site", "t.viewing_duration") \
.withWatermark("event_time", "10 seconds") \
.groupBy("country", window("event_time", "10 seconds", "5 seconds").alias("timewindow")) \
.agg(count("*").alias("count"),
min("viewing_duration").alias("min"),
max("viewing_duration").alias("max"),
sum("viewing_duration").alias("sum"),
avg("viewing_duration").alias("avg")) \
.writeStream \
.format("json") \
.partitionBy("country") \
.option("path", "./results/ex_5_3") \
.option("checkpointLocation", checkpoint_path) \
.start() \
.awaitTermination()Соединение двух потоков (Stream – Stream join)
И вот, мы подошли к самому интересному – соединению/сопоставлению данных из двух потоков. В принятых условиях рекламной системы – в потоках с информацией о просмотрах и о кликах по рекламным блокам – нет уникального id-сессии пользователя. В нашем случае есть возможность сопоставить данные только по вторичным признакам, но это даже интереснее. Для join’а потоков будем проверять на равенство id-рекламы, страну, сайт, а также период времени совершения действия. Очевидно, что клики, совершённые ранее начала просмотра рекламы, явно выглядят аномально и они нам не интересны. Условием вхождения клика в период просмотра рекламы сделаем 15 секунд – максимальная длительность демонстрации рекламы.
Поскольку генераторы настроены так, что информация может приходить с задержкой, то при формировании StreamDataFram’ов нужно обязательно указать размер Watermark(). Для просмотров это 10 секунд, а для кликов – 20, так как в генераторе указан такой размер возможного отклонения. Обратите внимание, что генератор не всегда отправляет информацию о клике, что является эмуляцией реальной ситуации. Далеко не каждый переходит по ссылке, увидев рекламу. Давайте же теперь взглянем на этот скрипт.
Джойним два потока:
query = adViewsStream.join(adClicksStream,
expr("""
click_ad_id = ad_id
AND click_site = site
AND click_contry = country
AND click_time >= event_time
AND click_time <= event_time + interval 15 seconds
"""
)
) \
.select("event_time", "click_time", "ad_id", "site", "country", "viewing_duration") \
.writeStream \
.format("console") \
.outputMode("append") \
.option("checkpointLocation", checkpoint_path) \
.start() \
.awaitTermination()Полный скрипт (ex_6_1)
import os
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-streaming-kafka-0-10_2.12:3.1.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.1 pyspark-shell'
checkpoint_path = "./checkpoint/ex_6_1"
kafka_servers = "localhost:9092"
import findspark
findspark.init('/home/andrey/spark-3.1.1-bin-hadoop3.2')
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
spark = (SparkSession
.builder
.appName("consumer_structured_streaming_ex_6_1")
.getOrCreate())
adViewsDF = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("subscribe","adViews") \
.option("startingOffsets", "latest") \
.option("failOnDataLoss", "false") \
.load() \
.selectExpr("CAST(value AS STRING)")
schemaAdViews = StructType([ \
StructField("event_time", TimestampType(), True), \
StructField("ad_id", IntegerType(), True), \
StructField("country", StringType(), True), \
StructField("site", StringType(), True), \
StructField("viewing_duration", IntegerType(), True) \
])
adViewsStream = adViewsDF.select(from_json(col("value"), schemaAdViews).alias("t")) \
.select("t.event_time", "t.ad_id", "t.country", "t.site", "t.viewing_duration") \
.withWatermark("event_time", "10 seconds")
adClicksDF = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("subscribe","adClicks") \
.option("startingOffsets", "latest") \
.option("failOnDataLoss", "false") \
.load() \
.selectExpr("CAST(value AS STRING)")
schemaAdClicks = StructType([ \
StructField("event_time", TimestampType(), True), \
StructField("ad_id", IntegerType(), True), \
StructField("country", StringType(), True), \
StructField("site", StringType(), True)
])
adClicksStream = adClicksDF.select(from_json(col("value"), schemaAdClicks).alias("t")) \
.select(col("t.event_time").alias("click_time"), col("t.ad_id").alias("click_ad_id"),
col("t.country").alias("click_contry"), col("t.site").alias("click_site")) \
.withWatermark("click_time", "10 seconds")
query = adViewsStream.join(adClicksStream,
expr("""
click_ad_id = ad_id
AND click_site = site
AND click_contry = country
AND click_time >= event_time
AND click_time <= event_time + interval 15 seconds
"""
)
) \
.select("event_time", "click_time", "ad_id", "site", "country", "viewing_duration") \
.writeStream \
.format("console") \
.outputMode("append") \
.option("checkpointLocation", checkpoint_path) \
.start() \
.awaitTermination()Запустив скрипт будет заметно, что не каждый пакет возвращает данные – оно и ожидаемо. Но давайте взглянем на пример микропакета, что пришёл с соединёнными данными.

Из данных видно, что «недавно» было совершено пару кликов после просмотров рекламы на сайте. Давайте сопоставим эту информацию с логами от генератора и проверим – корректно ли отработало условие join’а.
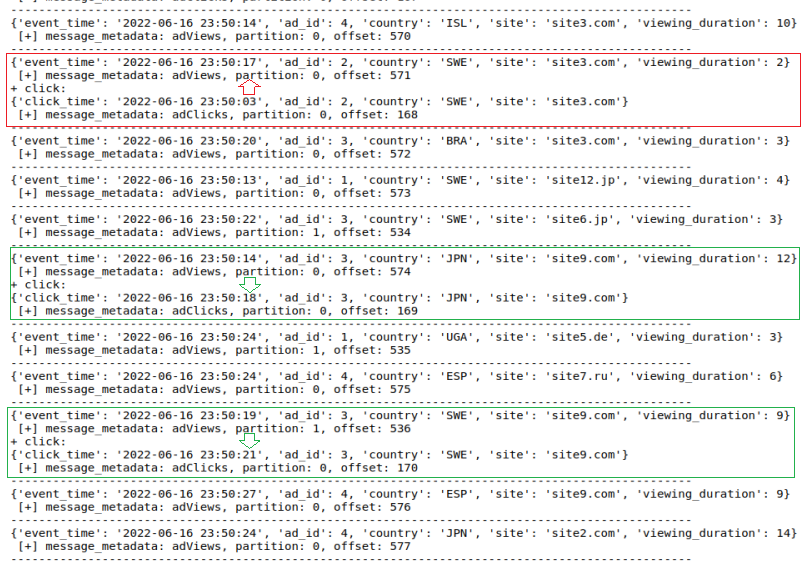
Видим, что было совершено якобы три клика по рекламе. Но первый блок данных противоречит условию, так как клик был раньше начала просмотра рекламы, поэтому эту строку данных Spark-приложение справедливо исключило.
Если в скрипте применить левое соединения «leftOuter», тогда каждый из приходящих пакетов будет содержать данные о просмотрах и иногда – ещё и время клика.
query = adViewsStream.join(adClicksStream,
expr("""
click_ad_id = ad_id
AND click_site = site
AND click_contry = country
AND click_time >= event_time
AND click_time <= event_time + interval 15 seconds
"""
),
"leftOuter"
) \
.select("event_time", "click_time", "ad_id", "site", "country", "viewing_duration") \
.writeStream \
.format("console") \
.outputMode("append") \
.option("checkpointLocation", checkpoint_path) \
.start() \
.awaitTermination()
Эти данные далее так же можно записывать в другой топик Kafka.
Полный скрипт (ex_6_3)
import os
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-streaming-kafka-0-10_2.12:3.1.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.1 pyspark-shell'
checkpoint_path = "./checkpoint/ex_6_3"
kafka_servers = "localhost:9092"
import findspark
findspark.init('/home/andrey/spark-3.1.1-bin-hadoop3.2')
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
spark = (SparkSession
.builder
.appName("consumer_structured_streaming_ex_6_3")
.getOrCreate())
adViewsDF = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("subscribe","adViews") \
.option("startingOffsets", "latest") \
.option("failOnDataLoss", "false") \
.load() \
.selectExpr("CAST(value AS STRING)")
schemaAdViews = StructType([ \
StructField("event_time", TimestampType(), True), \
StructField("ad_id", IntegerType(), True), \
StructField("country", StringType(), True), \
StructField("site", StringType(), True), \
StructField("viewing_duration", IntegerType(), True) \
])
adViewsStream = adViewsDF.select(from_json(col("value"), schemaAdViews).alias("t")) \
.select("t.event_time", "t.ad_id", "t.country", "t.site", "t.viewing_duration") \
.withWatermark("event_time", "10 seconds")
adClicksDF = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("subscribe","adClicks") \
.option("startingOffsets", "latest") \
.option("failOnDataLoss", "false") \
.load() \
.selectExpr("CAST(value AS STRING)")
schemaAdClicks = StructType([ \
StructField("click_time", TimestampType(), True), \
StructField("ad_id", IntegerType(), True), \
StructField("country", StringType(), True), \
StructField("site", StringType(), True)
])
adClicksStream = adClicksDF.select(from_json(col("value"), schemaAdClicks).alias("t")) \
.select("t.click_time", col("t.ad_id").alias("click_ad_id"),
col("t.country").alias("click_contry"), col("t.site").alias("click_site")) \
.withWatermark("click_time", "20 seconds")
query = adViewsStream.join(adClicksStream,
expr("""
click_ad_id = ad_id
AND click_site = site
AND click_contry = country
AND click_time >= event_time
AND click_time <= event_time + interval 15 seconds
"""
)
) \
.select(to_json(struct("event_time", "click_time", "ad_id", "site", "country", "viewing_duration")).alias("value")) \
.writeStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_servers) \
.option("topic","adStatistic") \
.option("checkpointLocation", checkpoint_path) \
.start() \
.awaitTermination()На основании накопленной статистики можно, к примеру, вычислять среднее время реакции или в разбивке по странам, сайтам учитывать время суток, день недели и так далее.
Заключение
В статье продемонстрированы особенности работы с Kafka с помощью механизма Structured Streaming. Мы увидели, что при взаимодействии разных наборов инструментов одной из наиболее часто встречающихся проблем является несовместимость некоторых их версий. В материале подробно разобраны такие проблемы и указаны необходимые версии инструментов. Также даны рекомендации по устранению наиболее типовых ошибок, часто возникающих при инсталляции и настройке. На практическом примере показаны широкие возможности технологии Spark, которые позволяют решать большой набор самых разнообразных задач.
Комментарии (3)

md_backend_binance
05.09.2022 21:25одна из лучший статей , моё уважение!
Такой вопросик: как в этом всем сделать такую вещь: например котировки акций, тоесть в postgres есть LAG и LEAD которыми можно выбрать предыдущие значение допустим если агрегировалось по дням
будет:
LABEL | CURRENT PRICE | PREV DAY VALUE | CHANGE
GGL | 75 | 50 | +50%

nanshakov
А если надо совсем не терять данные?