
"По классике" FIFO-очередь для обработки некоторого потока задач обычно реализуется в виде связанного списка элементов. Но для JavaScript такой подход нехорош - он требует либо создания "обвязки" над элементом очереди в виде дополнительного объекта, содержащего ссылки на сам элемент и указатель на следующий, либо превращения элемента в объект и расширения его таким же указателем.


В таких нагруженных системах, как коллектор нашего сервиса мониторинга PostgreSQL-серверов, создание и последующая подчистка Garbage Collector'ом подобных избыточных объектов и полей - непозволительная роскошь.
Но если внимательно посмотреть на эту схему, то можно заметить, что сами элементы очереди A, B, C линейно упорядочены. Так нельзя ли использовать в качестве очереди обычный массив с его .push() и .shift()?..

Массив-как-очередь
Давайте сначала напишем микро-тест, который продемонстрирует нам производительность такой очереди в зависимости от ее длины:
// test.js
const queue = [];
const usec = hrtb => {
const us = process.hrtime(hrtb);
return us[0] * 1e9 + us[1];
};
const totalLength = 1 << 20; // обрабатываем миллион элементов
console.log('scale | push, us | shift, us');
for (let n = 0; n <= 16; n++) { // перебираем размеры массивов по 2^N
const ln = 1 << n;
let tw = 0;
let tr = 0;
for (let iter = 0; iter < (totalLength >> n); iter++) { // прогоняем 1M/2^N итераций
// записываем 2^N случайных целых чисел в массив
{
const hrt = process.hrtime();
for (let i = 0; i < ln; i++) {
queue.push(Math.random() * 1e9 | 0);
}
tw += usec(hrt);
}
// считываем все числа
{
const hrt = process.hrtime();
while (queue.length) {
queue.shift();
}
tr += usec(hrt);
}
}
// выводим усредненные данные на один элемент
console.log(`${n.toString().padStart(5)} | ${(tw/totalLength | 0).toString().padStart(8)} | ${(tr/totalLength | 0).toString().padStart(9)}`);
}Запустим на текущей LTS-версии 16.17, минимизируя влияние GC:
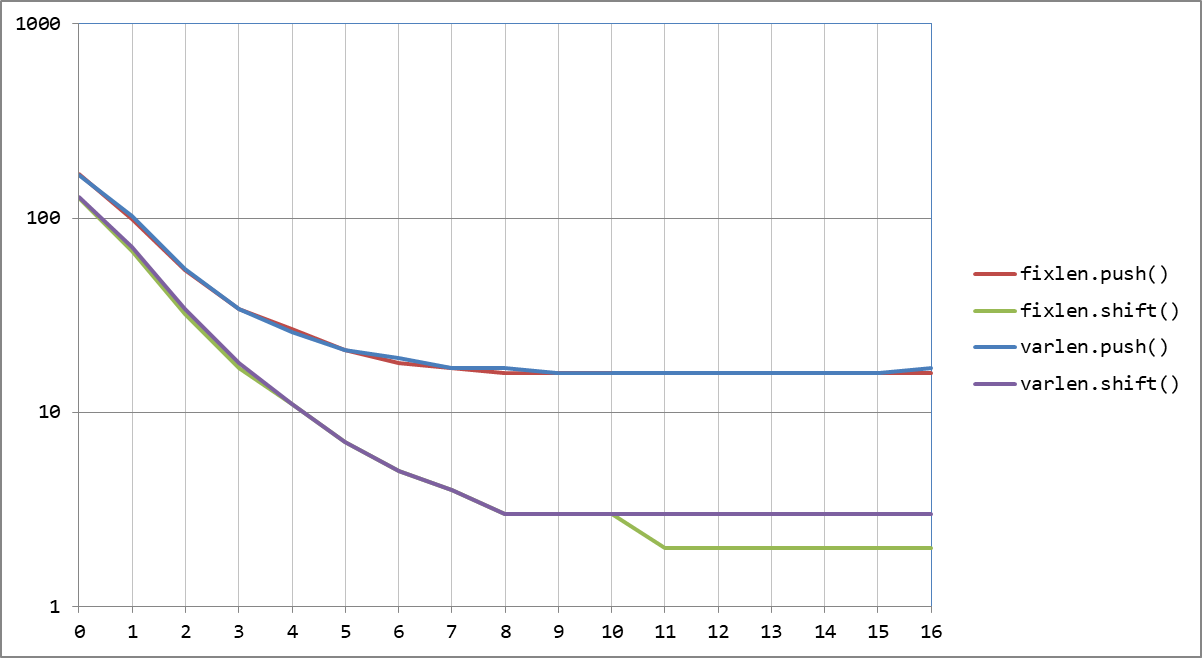
$ node --expose-gc testИ получим красивый, но не очень приятный график:

.push() держится молодцом, укладываясь в 20нс на интервале длин очереди [32..8192], а за его пределами подрастая до 50-100нс.
А вот с .shift() картина другая. Если к 16-элементному массиву время снижается до 14нс, то к 8192 оно дорастает до 100нс, а затем резкий рост вплоть до 10000нс/элемент при длине массива 65536.
То есть чтобы просто прочитать, даже без какой-либо обработки, все элементы очереди такого размера, потребуется почти секунда! И такое поведение движка V8, лежащего в основе Node.js и Chrome - не новость, есть даже открытая таска Performance: make Array.shift an O(1) operation.
Кольцевой буфер
Но для подобных задач и незачем постоянно двигать элементы в самом массиве - достаточно в фиксированном массиве двигать только лишь указатели на "начало", откуда мы будем читать следующий элемент, и "конец", куда будем записывать.
Такая структура данных называется кольцевым буфером.

У такой структуры есть два неприятных для производительности момента:
необходимость постоянных операций с длиной массива;
его конечность, то есть в какой-то момент пишущий "хвост" может догнать "голову" с обратной стороны и начать перезаписывать еще непрочитанный контент.

Давайте напишем собственную реализацию, которая частично устранит эти проблемы. Лишь частично, поскольку фиксированная длина массива может быть не только проблемой, но и благом - в случае, когда мы можем частью самых старых задач в очереди пожертвовать ради производительности.
if против математики
Начнем нашу реализацию с самого простого варианта: head и tail всегда численно находятся внутри буфера, а если tail уже "убежал за край", то мы сохраним эту информацию в отдельном over-флаге:
class RingBuffer {
_buffer;
_tail = 0;
_head = 0;
_over = false;
constructor(len) {
this._buffer = Array(len).fill();
}
get length() {
return this._over * this._buffer.length + this._tail - this._head;
}
push(val) {
if (this._tail === this._head && this._over) {
// "хвост" догнал "с обратной стороны" - надо продвинуть и "голову"
if (this._head++ === this._buffer.length) {
this._head = 0;
this._over = false; // при переходе "головы" флаг сбрасываем
}
}
this._buffer[this._tail++] = val;
if (this._tail === this._buffer.length) {
this._tail = 0;
this._over = true; // при переходе "хвоста" флаг устанавливаем
}
return this.length;
}
shift() {
if (this._head !== this._tail || this._over) {
const val = this._buffer[this._head++];
if (this._head === this._buffer.length) {
this._head = 0;
this._over = false; // при переходе "головы" флаг сбрасываем
}
return val;
}
}
}Соответственно, в test.js нам надо поменять инициализацию очереди:
const queue = new RingBuffer(65536); // мы точно знаем, что размер очереди не больше существенно быстрее Array.shift()")
Но в этой реализации достаточно много сравнений и сложных условий, которые CPU, традиционно, не очень любит.
Давайте чуть изменим логику работы, и if-сравнения пересечения границы массива заменим на операцию взятия остатка по модулю %. Но вспомним, что для некоторых чисел эту операцию можно заменить на & (побитовое "И") - такими числами являются 2^N.
Тесты показывают, что (Math.random() * 1e6 | 0) & 0xFFFF на 1-2% быстрее, чем (Math.random() * 1e6 | 0) % 65536, что сущая мелочь в общей массе, но все-таки идет на пользу общей производительности.
Поэтому мы будем длину массива всегда устанавливать равной некоторой степени 2 - все равно непринципиально, будете вы ее задавать как 1000 или как 1024.
В новой реализации, чтобы не городить сложных условий, будем всегда придерживаться следующей логики:
head <= tail- то есть численно читающая "голова" всегда левее, чем пишущий "хвост"0 <= head < 2 ^ pow- "голова" всегда находится внутри массив0 <= tail < 2 ^ (pow + 1)- "хвост" может численно убегать за границу массива не более, чем на его длинукогда "голова" переходит через границу массива, от "хвоста" отсекаем все лишнее, чтобы он попал в диапазон массива

class Pow2Buffer {
_buffer;
_tail = 0;
_head = 0;
_mask; // битовая маска
constructor(pow) {
this._buffer = Array(1 << pow).fill(); // .length = 100..00b
this._mask = this._buffer.length - 1; // mask = 11..11b
}
get length() {
return this._tail - this._head;
}
push(val) {
if ((this._tail & this._mask) === this._head && this._tail > this._head) {
// "хвост" догнал "с обратной стороны" - надо продвинуть и "голову"
this._head++;
this._head &= this._mask;
this._tail = this._head + this._mask; // mask = buffer.length - 1
}
this._buffer[this._tail++ & this._mask] = val;
return this.length;
}
shift() {
if (this._head < this._tail) {
const val = this._buffer[this._head++];
if ((this._head & this._mask) === 0) {
this._head = 0;
this._tail &= this._mask; // при переходе "головы" вгоняем "хвост" в границы массива
}
return val;
}
}
}Теперь при вызове мы указываем степень 2, поэтому в test.js поправим так:
const queue = new Pow2Buffer(16); // 2^16 = 65536
В этой реализации .push() "стоит" около 16нс, а .shift() - вообще стремится к 2нс.
Добавляем гибкости
Заметим, что ради производительности, мы не "зануляем" прочитанную ячейку массива, поэтому объект остается доступен в памяти и не может быть зачищен GC все то время, пока "хвост" не пройдет весь остальной массив и не перезапишет ячейку новым элементом.
Это побуждает нас использовать в качестве буфера как можно более короткий массив - исходя из графика задержек, 256 элементов будет достаточно эффективно.
С другой стороны, при кратких пиковых нагрузках 256 элементов в очереди нам может не хватить, и мы начнем терять данные, хотя легко можем этого избежать. Достаточно всего лишь позволить буферу при необходимости расширяться и "схлапываться", когда потребность пропадает.
Логично пытаться расширить массив только тогда, когда это действительно необходимо - то есть когда "хвост догнал голову", и запись элемента уже приведет к утрате данных. Тогда, если мы еще не достигли верхнего ограничения на разрешенный размер буфера, мы просто вставляем сегмент из пустых элементов в текущей позиции так, чтобы длина массива удвоилась:

Со "схлапыванием" ситуация похожая, с той лишь разницей, что делать мы ее будем пытаться только при переходе "головы" через границу массива:

Конечно, может оказаться так, что "хвост" уже успел сдвинуться во вторую половину массива. Ничего страшного - тогда просто не будем никак массив менять в этом случае.
class Pow2Buffer {
_buffer;
_tail = 0;
_head = 0;
_mask;
_MIN_BUFFER; // минимальный, стартовый размер буфера
_MAX_BUFFER; // максимально допустимый размер буфера
constructor(powMin, powMax) {
this._MAX_BUFFER = 1 << powMax;
this._MIN_BUFFER = 1 << powMin;
this._buffer = Array(this._MIN_BUFFER).fill();
this._mask = this._buffer.length - 1;
}
get length() {
return this._tail - this._head;
}
_tryExpand() {
const ln = this._buffer.length;
if (ln < this._MAX_BUFFER) {
this._buffer.splice(this._head, 0, ...Array(ln).fill()); // удваиваем длину
this._mask = this._buffer.length - 1;
this._tail += ln; // "хвост" теперь снова за границей массива
this._head += ln; // а "голова" - в конце вставленного сегмента
return true;
}
}
push(val) {
if ((this._tail & this._mask) === this._head && this._tail > this._head) {
if (!this._tryExpand()) { // пытаемся расширить массив
// вот если расширять уже некуда - тогда двигаем "голову"
this._head++;
this._head &= this._mask;
this._tail = this._head + this._mask;
}
}
this._buffer[this._tail++ & this._mask] = val;
return this.length;
}
_tryCollapse() {
const ln = this._buffer.length;
if (ln > this._MIN_BUFFER && (this._tail << 1) < ln) { // "хвост" в первой половине массива
// подбираем наиболее близкую 2^N-длину не меньше powMin
this._buffer.length = Math.max(1 << Math.ceil(Math.log2(this._tail + 1)), this._MIN_BUFFER);
this._mask = this._buffer.length - 1;
return true;
}
}
shift() {
if (this._head < this._tail) {
const val = this._buffer[this._head++];
if ((this._head & this._mask) === 0) {
this._head = 0;
this._tail &= this._mask;
this._tryCollapse(); // пытаемся "схлопнуть" массив
}
return val;
}
}
}Попробуем заведомо заставить наш буфер расширяться в некоторых тестах:
const queue = new Pow2Buffer(8, 16); // размер буфера в диапазоне [256..65536]Как можно заметить, производительность пострадала лишь немного в тестах, когда буфер вынужден расширяться по несколько раз:
Наводим "красоту"
Осталось совсем немного - сделать все "стильно, модно, молодежно".
Иногда бывает необходимо "заглянуть" в следующий элемент очереди без его извлечения - поддержим обращение queue[0] по аналогии с обычным массивом. Для этого прямо в конструкторе объявим геттер для свойства .0:
constructor(powMin, powMax) {
this._MAX_BUFFER = 1 << powMax;
this._MIN_BUFFER = 1 << powMin;
this._buffer = Array(this._MIN_BUFFER).fill();
this._mask = this._buffer.length - 1;
// поддержка обращения к "следующему" (нулевому) элементу очереди
Object.defineProperty(this, 0, {
get : () => this._head < this._tail ? this._buffer[this._head] : undefined
});
}Можно было бы поддержать доступ по произвольному индексу через Proxy так или так, но тогда через него пойдут и все обращения к локальным полям, что явно снизит производительность. К тому же, такой задачи обычно и не возникает.
Давайте также добавим нашей очереди возможность перебора в цикле for .. of. Для этого нам понадобится объявить примитивный генератор:
* [Symbol.iterator]() {
while (this.length) {
yield this.shift();
}
}А заодно - методы .toArray() и .toString():
toArray() {
return this._tail <= this._buffer.length // если "хвост" в границах массива
? this._buffer
.slice(this._head, this._tail) // просто вырезаем [head, tail]
: this._buffer
.slice(this._head)
.concat( // иначе "клеим" [head, ...] + [..., tail]
this._buffer
.slice(0, this._tail & this._mask)
);
}
toString() {
return this.toArray().toString();
}Ну, и сделаем, наконец, все приватные свойства и методы такими с точки зрения языка, заменив префикс _ на #:
class Pow2Buffer {
#buffer;
#tail = 0;
#head = 0;
#mask;
#MIN_BUFFER;
#MAX_BUFFER;
constructor(powMin, powMax) {
this.#MAX_BUFFER = 1 << powMax;
this.#MIN_BUFFER = 1 << powMin;
this.#buffer = Array(this.#MIN_BUFFER).fill();
this.#mask = this.#buffer.length - 1;
Object.defineProperty(this, 0, {
get : () => this.#head < this.#tail ? this.#buffer[this.#head] : undefined
});
}
get length() {
return this.#tail - this.#head;
}
#tryExpand() {
const ln = this.#buffer.length;
if (ln < this.#MAX_BUFFER) {
this.#buffer.splice(this.#head, 0, ...Array(ln).fill());
this.#mask = this.#buffer.length - 1;
this.#tail += ln;
this.#head += ln;
return true;
}
}
push(val) {
if ((this.#tail & this.#mask) === this.#head && this.#tail > this.#head) {
if (!this.#tryExpand()) {
this.#head++;
this.#head &= this.#mask;
this.#tail = this.#head + this.#mask;
}
}
this.#buffer[this.#tail++ & this.#mask] = val;
return this.length;
}
#tryCollapse() {
const ln = this.#buffer.length;
if (ln > this.#MIN_BUFFER && (this.#tail << 1) < ln) {
this.#buffer.length = Math.max(1 << Math.ceil(Math.log2(this.#tail + 1)), this.#MIN_BUFFER);
this.#mask = this.#buffer.length - 1;
return true;
}
}
shift() {
if (this.#head < this.#tail) {
const val = this.#buffer[this.#head++];
if ((this.#head & this.#mask) === 0) {
this.#head = 0;
this.#tail &= this.#mask;
this.#tryCollapse();
}
return val;
}
}
* [Symbol.iterator]() {
while (this.length) {
yield this.shift();
}
}
toArray() {
return this.#tail <= this.#buffer.length
? this.#buffer
.slice(this.#head, this.#tail)
: this.#buffer
.slice(this.#head)
.concat(
this.#buffer
.slice(0, this.#tail & this.#mask)
);
}
toString() {
return this.toArray().toString();
}
}На этом сегодня все. Надеюсь, данный концепт позволит вам получить более производительные Node.js-решения.
Комментарии (7)

rock
15.09.2022 21:30создание и последующая подчистка Garbage Collector'ом подобных избыточных объектов и полей - непозволительная роскошь
При этом, генератор по
Symbol.iteratorна каждый шаг итерации создает эти самые объекты и поля - хотя, возможно, движок это и оптимизирует.Вообще, интересно было бы посмотреть на сравнение производительности с очередью, реализованной классически, с цепочкой объектов.
rock
15.09.2022 22:03Простая очередь:
class Queue { #tail = null; #head = null; length = 0; push(value) { const element = { next: null, value }; if (this.#head) this.#head.next = element; if (this.#tail === null) this.#tail = element; this.#head = element; this.length++; } shift() { const element = this.#tail; if (element === null) return; this.#tail = element.next; if (this.#head === element) this.#head = null; this.length--; return element.value; } }Результаты:
// Массив: scale | push, us | shift, us 0 | 41 | 33 1 | 22 | 15 2 | 15 | 10 3 | 11 | 6 4 | 9 | 6 5 | 8 | 9 6 | 7 | 18 7 | 7 | 29 8 | 8 | 30 9 | 9 | 30 10 | 9 | 30 11 | 10 | 31 12 | 8 | 30 13 | 8 | 30 14 | 11 | 975 15 | 12 | 2425 16 | 18 | 5109 // Pow2Buffer: scale | push, us | shift, us 0 | 38 | 42 1 | 22 | 16 2 | 15 | 11 3 | 13 | 6 4 | 10 | 3 5 | 9 | 2 6 | 8 | 2 7 | 8 | 2 8 | 8 | 1 9 | 9 | 1 10 | 9 | 1 11 | 9 | 1 12 | 8 | 1 13 | 9 | 1 14 | 9 | 1 15 | 10 | 1 16 | 9 | 1 // Queue: scale | push, us | shift, us 0 | 57 | 31 1 | 34 | 26 2 | 22 | 9 3 | 21 | 6 4 | 15 | 5 5 | 14 | 4 6 | 14 | 4 7 | 13 | 1 8 | 13 | 1 9 | 12 | 1 10 | 12 | 1 11 | 12 | 1 12 | 12 | 1 13 | 12 | 1 14 | 13 | 2 15 | 13 | 1 16 | 16 | 1Как-то так.

Kilor Автор
15.09.2022 23:01На самом деле, даже странно, что push в список оказался почти на треть медленнее. Видимо, сказывается пара if'ов - вряд ли создание объекта-обертки.
rock
16.09.2022 23:59Ну пару if'ов можно сократить и до одного, вот только это сокращает время всего на пол наносекунды.
if (this.length) { this.#head.next = element; } else { this.#tail = element; }У вас в тесте используется
Math.random()- очень тяжелая операция, так что большая часть времени у вас в тесте.push- время исполненияMath.random(). Если его заменить на счетчик, разница будет ещё значительней - примерно, двукратная. Почему - разбираться и копаться в сгенерированном коде лень. Может, особенности доступа к полям / модификации объектов.
SGordon123
интересно, если запруженную систему на ц переписать, че будет?
Kilor Автор
Будет достаточно много как возможностей, так и неудобств - начиная от ручного управления памятью и заканчивая не всегда удобными способами работы со строками, регулярными выражениями и "асинхронщиной" в C/C++.
gev
а если на Rust или Haskell? =)