

Иннополис — место, где формируются идеи, которые затем вырываются в большой мир, чтобы сделать его немного лучше, удобнее и технологичнее. Так произошло и с разработками компании EORA, которая опубликовала пайплайн для машинного обучения, заточенный под работу с компьютерным зрением.
Все необходимое для работы с ним опубликовано на GitHub под лицензией Apache 2.0, но если хотите подробностей из первых уст — добро пожаловать под кат. Передаем слово руководителю отдела компьютерного зрения EORA Data Lab Владу Виноградову.
Мы много лет разрабатывали TorchOk, и чувствуем, что настало время для презентации: нам есть, что показать и о чем рассказать.
Пайплайн в основном предназначен для работы с моделями компьютерного зрения. Он включает в себя ряд нейросетевых моделей, начиная с ключевых ResNet, HRNet и заканчивая новомодными трансформерами вроде Swin, DaViT. При этом фишка пайплайна в агрегации трюков, зарекомендовавших себя среди исследователей. Речь о таких приемах машинного обучения, как аугментации, поэтапная разморозка весов и т. п.
Помимо моделей, в пайплайн включены реализации метрик для компьютерного зрения — классификационные метрики, метрики сегментации и метрики для поиска похожих изображений. Также есть несколько датасетов: классификационных, под многоклассовую классификацию, multilabel-классификацию, поиск похожих изображений, сегментацию и не только. Функционально TorchOk заточен под задачи обучения без учителя, классификации, сегментации, детектирования, поиска похожих изображений.
Как все начиналось или чуточку истории
Все мы учились в Университете Иннополис, участвовали в хакатонах и kaggle-соревнованиях и в 2018 году основали в городе собственную студию машинного обучения.
Сначала писали на основе YAML-конфигов, самостоятельно разрабатывали инфраструктурный код, перенос тензоров и графа модели между CPU и GPU устройствами, добавляли поддержку FP16. Но к лету 2020 года набрал популярность кастомизируемый инструмент обучения моделей PyTorch Lightning, и мы поняли, что лучше перейти на этот движок и разом избавиться от всей возни с инфраструктурным кодом. Вот только эта светлая мысль независимо пришла в голову сразу двум нашим ключевым разработчикам.
В результате в какой-то момент у нас на руках было два пайплайна. Половина команды работала с одной версией, половина — с другой. Свои преимущества были у обоих конвейеров, и мы так и не сумели выбрать. Пришлось их «скрестить».

Объединенную версию назвали TorchOk — название, пришедшее за 5 секунд, но эта непереводимая игра слов с намеком, что фреймворк PyTorch на самом деле довольно хорош, понравилась команде. Правда же, запоминается?
Почему мы пошли в open-source
Мы не без оснований считаем open-source двигателем прогресса — чем больше инструментов в открытом доступе, тем легче экспериментировать и проще работать. Но есть и чисто практические соображения: так пайплайн можно использовать для личных задач, например, Kaggle-соревнований.
Открытая лицензия позволяет студентам Университета Иннополис использовать TorchOk в учебе. Фактически пайплайн помогает в подготовке наших новых сотрудников. К тому же, сообщество пользователей и разработчиков, сформировавшееся вокруг проекта, помогает пересмотреть подходы и прийти к лучшим решениям, иными словами, отточить реализацию.
Архитектура и конфигурация экспериментов в торчке
Подготовка к выходу в open-source, вынудила допилить инфраструктурные задачи, связанные с проверкой качества кода, CI/CD, публикацией в репозиторий PyPi и т. д. Публичный релиз здорово мотивирует навести порядок в продукте. Но самой сложной концептуальной проблемой стала декомпозиция нейросетевых моделей.
С одной стороны хотелось использовать замечательные готовые модели из Torch Image Models, с другой — дизайн моделей в формате timm не расширяется под общие задачи компьютерного зрения, оставляя возможность использовать их только для классификации. В конце концов мы пришли к выводу, что модели из timm все же стоит переносить в наш пайплайн (да, дублирование), но при этом кастомизировать только внешний класс бэкбонов. Поэтому мы разделили наши модели на четыре компонента:
Backbone — основная часть сети, которая принимает изображение и делает извлечение признаков с разных уровней (receptive fields). Например, стандартный ResNet для классификации без линейного слоя и последнего пулинга.
Neck — сеть, принимающая карты признаковых с разных уровней и преобразующая их в карты признаков либо одного, либо нескольких уровней. Например, декодер U-Net.
Pooling — модуль понижения пространственных размерностей. Например, для классификации Average Pooling.
Head — модуль, принимающий одну или более карт признаков и преобразующий их в предсказания. На выходе из него получается финальный тензор, отправляемый в функцию ошибки. Например, сегментационная карта признаков на несколько классов.
Такой подход обеспечивает модульность и возможность комбинировать компоненты разных моделей под конкретные задачи. Например, для решения задачи классификации — достаточно взять только backbone, pooling и head. Если задача изменилась и нужна сегментация, можно задать в конфигах backbone, neck и head и настроить согласно классам в ваших данных. При необходимости можно заменить только голову. Функция ошибок, оптимизаторы — все это добавляется поверх и никак не зависит от моделей.
В целом же архитектура TorchOk достаточно линейна, хотя по схеме этого и не скажешь.
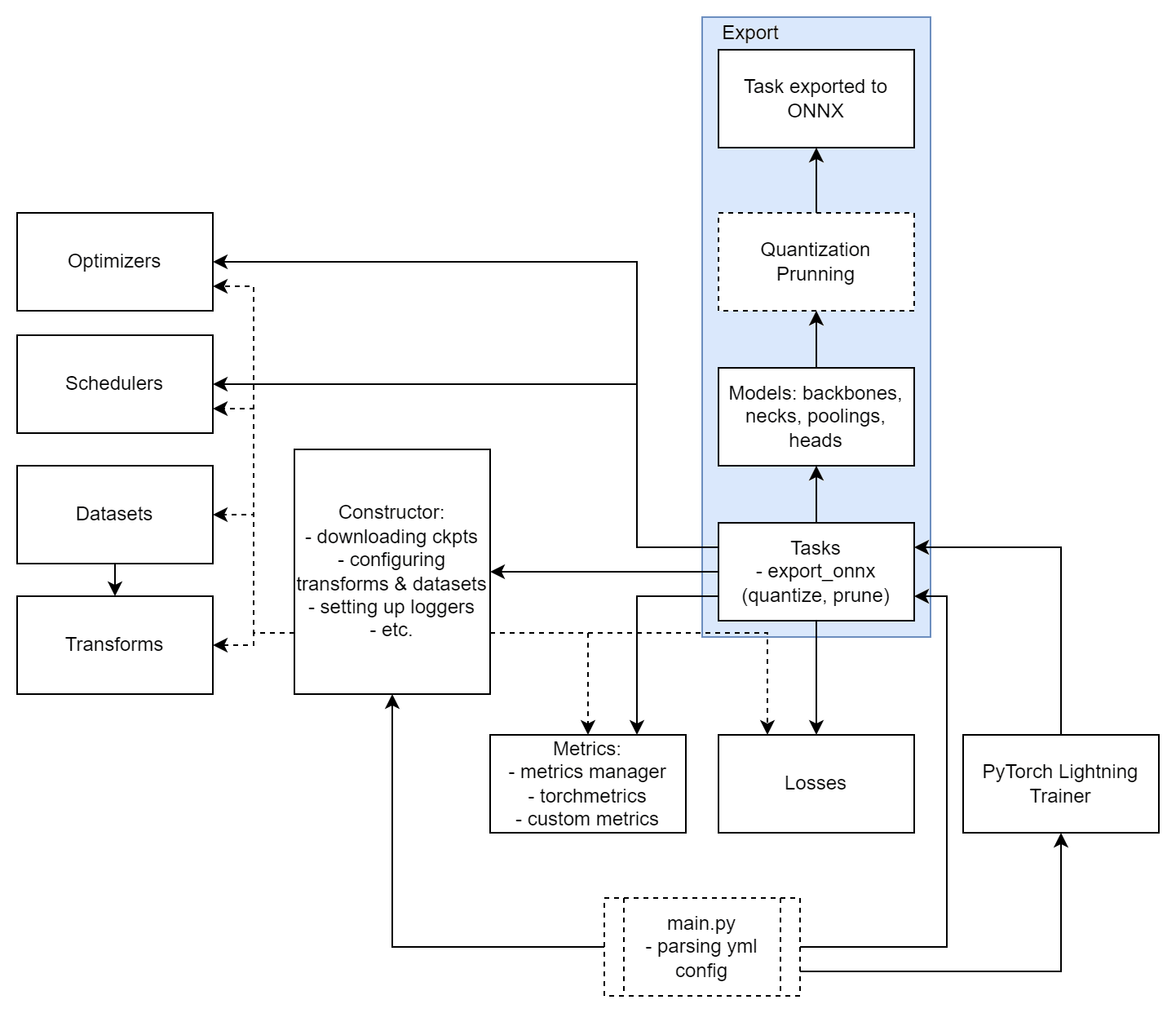
В основе пайплайна лежит концепция Tasks, решающая задачи компьютерного зрения: классификация, сегментация и так далее. Любая Task наследуется от BaseTask, а BaseTask в свою очередь от Lightning модуля. Таким образом, задачу компьютерного зрения можно целиком решить с помощью одного модуля по интерфейсу PyTorch Lightning.
Модуль оптимизации объединяет в себе подходы из библиотеки PyTorch и найденные нами потенциально полезные оптимизаторы. Сюда же входит планировщик шага обучения.
Отдельным компонентом идут метрики. Мы поддерживаем метрики согласно интерфейсу Torchmetrics — это означает, что можно использовать метрики «из коробки» Torchmetrics, а также легко реализовать свои. Например, мы реализовали собственные метрики для задачи поиска похожих изображений с использованием эффективной библиотеки ranx и индексом faiss.
Еще один компонент — функции ошибок. В PyTorch есть базовые функции ошибок, но часто требуется реализовывать свои. К примеру, label smoothing — функция ошибки для задачи классификации с размывающими коэффициентами. Кроме этого, TorchOk из коробки поддерживает взвешенную сумму функций ошибок, что позволяет комбинировать несколько функций ошибок.
Также TorchOk включает часто используемые наборы данных и модуль для аугментации и преобразования изображений на базе Albumentations. Он позволяет разнообразить датасет благодаря вариациям изображений с поворотами, искажениями, заменой цветов и т. д.
Все это объединяет специальный конструктор, который собирает датасеты, модели, loss-функции, метрики и готовит сборку для Lightning модуля.
Наш пайплайн предназначен для быстрого проведения экспериментов, поэтому основные параметры обучения устанавливаются в одном YAML-конфиге. Там можно задать нейросеть, указать данные для подгрузки, определить, какие метрики будут считаться, сколько GPU выделить. Трансформации в TorchOk тоже задаются прямо из YAML-конфига, в том числе и композиционные трансформации.
Использование единого конфига позволяет легко воспроизводить эксперименты. Для парсинга конфигов мы используем Hydra, из полезных нам функций в ней нашлись возможности переопределения параметров из командной строки и задания переменных окружения в конфиге.
Как запустить TorchOk и, главное, зачем?
Честно говоря, мы еще не подготовили исчерпывающую документацию, однако README на главной странице репозитория отвечает на все базовые вопросы. TorchOk готов к работе как есть. Предварительно нужно только установить актуальную версию PyTorch. Установку самого TorchOk можно выполнить через pip, запустив:
pip install --upgrade torchokА можно установить TorchOk через Docker. Созданный образ поддерживает доступ по SSH, открытие портов Jupyter Lab и Tensorboard. Просто соберите его и запустите контейнер:
docker build -t torchok --build-arg SSH_PUBLIC_KEY="<public key>".
docker run -d --name <username>_torchok --gpus=all -v
<path/to/workdir>:/workdir -p <ssh_port>:22 -p <jupyter_port>:8888
-p <tensorboard_port>:6006 torchokЗатем нужно найти файлы YAML в папке examples/configs. По умолчанию там уже прописано несколько предустановленных конфигураций для обучения и вывода данных. Вот, например, шапка конфига обучения для CIFAR10:
task:
name: ClassificationTask
params:
backbone_name: semnasnet_100
backbone_params:
pretrained: true
in_channels: 3
pooling_name: Pooling
head_name: ClassificationHead
head_params:
num_classes: &num_classes 10
inputs:
- shape: [3, &height 32, &width 32]
dtype: 'bfloat16'Так задается общая конфигурация задачи. Чтобы поставить новый эксперимент, достаточно ее просто отредактировать. Полный файл конфигурации можно посмотреть на GitHub. После этого остается только запустить пайплайн командой:
python -m torchok -cp ../examples/configs -cn
classification_cifar10По нашему опыту пайплайн заметно экономит время на реализацию проекта. Он легок в запуске, и с ним спокойно работают инженеры, начиная с уровня junior (необязательно Computer Vision инженеры). Для использования TorchOk требуются только базовые знания Linux, Python, машинного обучения и компьютерного зрения. Не нужно копаться в коде, подгонять и отлаживать отдельные инструменты.
Рабочий процесс складывается из трех шагов:
Пользователь определяется с задачей и подбирает класс датасета, оптимально подходящий под проект. Подготавливает свои данные в ожидаемом формате.
Затем выбирает аугментации для данных, нейросетевую модель, функцию ошибки, оптимизатор и базовые параметры обучения (количество эпох, определенный батч-сайз и т. д.).
Все эти данные заносятся в конфиг — все, можно запускать обучение.
TorchOk поддерживает различные трюки, которые применяют на Kaggle-соревнованиях. Например, разморозку слоев нейросети по мере обучения. Причем конфиг-файл позволяет указать на какой эпохе какие слои нейронной разморозить, и пайплайн делает это автоматически в процессе обучения.
Нам кажется, что TorchOk достаточно прост для студентов, но при этом гибок и обладает потенциалом для решения практических задач. Четыре года практики это подтверждают.
Наш опыт
С пайплайном мы заняли достойные места в нескольких соревнованиях: серебро (71 место из 2426) на Kaggle в задаче поиска похожих товаров, 9 место на соревновании распознавания рукописей Петра I от Сбера (для просмотра нужна авторизация на ods.ai), а также реализовали три десятка коммерческих проектов. Например, трехэтапное нейросетевое решение распознавания аналоговых и цифровых счетчиков.
Решение состояло из трех нейросетей — модель сегментации счетчика и циферблата с учетом поворота, модель сегментации цифр и разделителя дробной части и модель классификации цифр
В другой раз, помогли пивоварам с рекламной кампанией. Они хотели сделать сервис, который бы накладывал разные эффекты на видео. Для этого мы использовали инструменты сегментации в высоком разрешении при помощи нейросети HRNet. Используя TorchOk, мы научили сетку сегментировать одежду человека, сегментировать несколько классов мебели на фоне, а также — раскрашивать глаза, волосы, рисунки на одежде в разные цвета. Получилось психоделично.
Мы просто рады сдаче проекта, и нет, пиво здесь не при чем
С помощью этого пайплайна реализовали поиск по картинкам для патентного бюро. Перед тем как зарегистрировать товарный знак, эксперты неделями вручную отсматривали базы в поисках похожих изображений.
Короткий ролик, в котором наша команда рассказывает о проекте с патентным бюро
TorchOk помог автоматизировать этот процесс. Мы вместе с экспертами заказчика разметили датасет, около года экспериментировали с различными архитектурами нейросетей, постепенно повышали точность работы модели и внедрили ее в уже готовое приложение.
Что дальше
Все наши планы подчинены одной простой задаче: улучшению пайплайна. За время работы над TorchOk мы поняли: мало просто опубликовать конвейер, его необходимо поддерживать и пополнять новыми моделями. Не обязательно самыми свежими, но лучшими с точки зрения скорости и качества. Мы стараемся выбирать именно такие решения. Недавно добавили backbone DaViT — развитие Visual Transformer с использованием двунаправленной токенизации карт признаков.
Мы продолжаем хантить молодых датасайнтистов со свежими идеями и привлекать их к работе над проектом. Планируем доработать выгрузку моделей в универсальный формат ONNX, улучшить CI/CD, написать подробную документацию и описать Contribution Guideline.
Это наш основной рабочий инструмент, так что мы продолжим поддерживать и развивать TorchOk дальше, вне зависимости от числа контрибьюторов или форков.
Комментарии (7)

arseniy2
29.09.2022 13:29+3Не знаю. Мне нравится название. Учитывая, какие наркоманские результаты бывают у всяких нейросетей. Типо, взгляд торкнутого. А с другой стороны - Факел ОК, что освещает хорошо.
Также забавно можно пошутить про Толчок
Главное, чтоб люди с некоторыми предрассудками и плохим ЧЮ не были главной ЦА.

HYIBYDESHSOSATA
30.09.2022 11:05Хочу ароматный порошок занюхать, и всё на видео записать что я думаю, и выложить анонимно вместе с хакерами!
vesper-bot
Если это не перевод, то вам стоит подумать о ребрендинге.
denisromanenko
Задолбали, я не торч, я просто сладко разметил датасет
Maccimo
Зачем ребрендинг?
«Торчок из Иннополиса» звучит отлично.
Если кто-то от такого названия хлопается в обморок — тем лучше для пиара.
Вы бы ещё Яндексу кокаин переименовать предложили.
alan008
Так это же название, похожее на PyTorch