
Привет всем! Каждую зиму в русских (да и не только) городах появляется зловредный гололед. Множество людей подскальзывается и травмирует различные части тела. Скажете, эта проблема должна решаться коммунальщиками — да, так и есть, но они часто не доглядывают за состоянием тротуаров и дворовых тропинок, а может быть и просто не знают, куда смотреть. Чтобы хоть как-то улучшить ситуацию, в решение проблемы все больше должны включаться современные технологии. Возможное улучшение — это приложение, в котором люди могут определить для себя наиболее безопасный маршрут из точки A в точку B, глядя на карту заледенелости. Итак, сегодня поговорим о создании системы оценки степени заледенелости улиц, основанной на статистике падений людей. Под катом машинное обучение, облака и мобильные приложения.

Где еще может быть полезно?
Позвольте мне назвать еще два применения будущей системы (при необходимых изменениях). Помимо падений, рассматриваемых глобально в городской среде, нам хочется отслеживать состояние наших близких (в особенности престарелых). Здесь информация о падении (инфаркт, потеря сознания и пр.) и немедленное уведомление родственников позволит среагировать как можно быстрее и вызвать скорую помощь бабушке/дедушке, не находясь непосредственно рядом с ними.
Еще одним полезным применением окажется получение тренером информации о падениях своих спортсменов на длинных трассах: лыжников, бегунов и пр. Все три галлюцинации полезных по мнению автора случая показаны на картинке выше для более полного осознания проблем. Автор же представляет разбор реализации системы для городского случая и называет ее Sleet Monitor. Система будет реализована в связке мобильного Android приложения и облачной составляющей. Сразу скажу, что весь код находится в репозитории на GitHub
В чем сложность?
В первую очередь нужно решить вопрос с определением факта падения. Начинка системы будет представлена классификатором падений. Сложность его построения состоит в основном в данных, которые мы получаем со смартфонов. Данные — это показания акселерометра по трем осям, собираемые непрерывно. На картинке ниже показаны два примера полутора-секундных фреймов: левый соответствует падению, правый — не падению.
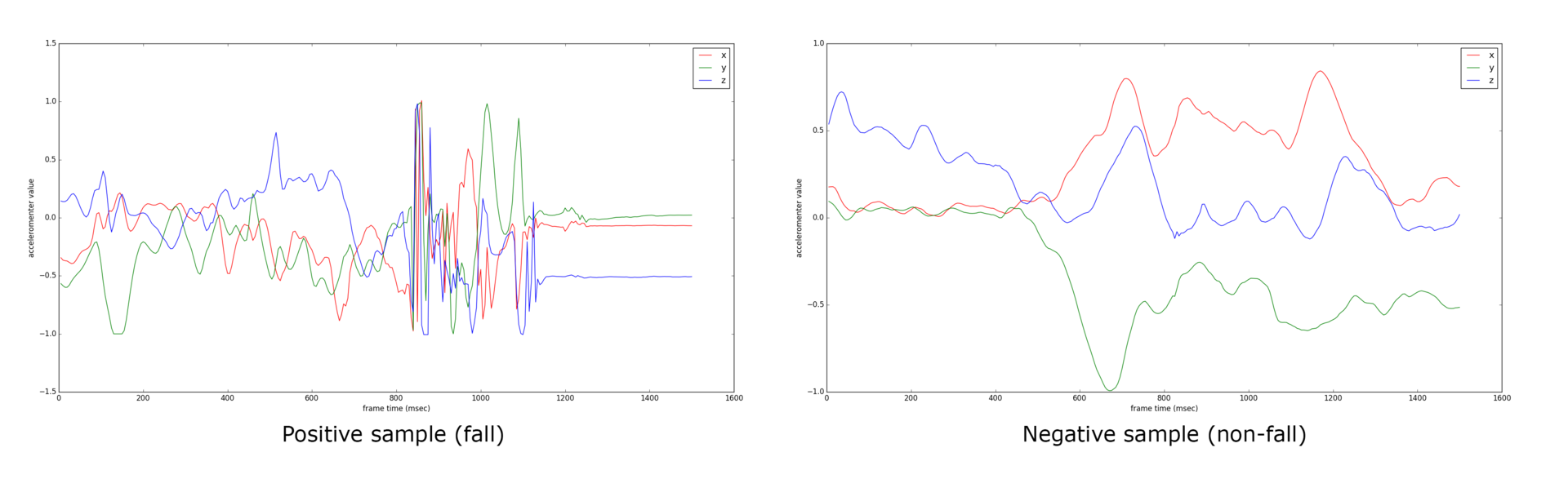
Ввиду различных характеристик смартфонов данные могут быть разреженными, причем разрешение по времени непостоянно для одного и того же устройства (операционная система по определенным причинам не возвращает данные с одной и той же частотой на многих устройствах). Также направление осей акселерометра может варьироваться от устройства к устройству. Плюсом к перечисленному будет проблема «замораживания» приложения (в заблокированном режиме ОС может очень редко выдавать показания акселерометра, а может неожиданно принести целую пачку данных).
На данный момент решена первая и частично последняя проблема путем использования интерполяции данных. Ввиду перечисленных трудностей и того факта, что разработать классификатор падений, основываясь на некоторых эвристиках трудно, взгляд упал на подходы с машинным обучением.
Сбор данных
 Чтобы машину чему-то научить, нужно показать ей это что-то, и еще лучше указать, что хорошо, а что плохо. Для сбора данных было написано отдельное Android приложение, собирающее показания акселерометра с максимально возможной частотой и записывающее их в файл. Размер фрейма не превышает 1.5 сек (автор предположил, что в среднем человек падает на протяжении этого промежутка времени).
Чтобы машину чему-то научить, нужно показать ей это что-то, и еще лучше указать, что хорошо, а что плохо. Для сбора данных было написано отдельное Android приложение, собирающее показания акселерометра с максимально возможной частотой и записывающее их в файл. Размер фрейма не превышает 1.5 сек (автор предположил, что в среднем человек падает на протяжении этого промежутка времени).
Данные представляют собой строки следующего формата: time_offset: x_value y_value z_value ... time_offset: x_value y_value z_value is_fall. Показания акселерометра нормированы по максимально возможному для конкретного типа акселерометра значению. Кол-во кортежей (time_offset, x_value, y_value, z_value) в строке зависит от частоты предоставления данных операционной системой. Здесь стоит заметить, что вся выборка была собрана на смартфоне LG Nexus 5, который выдает стабильно данные раз в 5 мсек при не заблокированном экране. Таким образом, за 1.5 секунды мы имеем 300 кортежей данных с пометкой времени.
Все данные приходилось собирать путем самостоятельных падений при помощи своего друга Кручинина Дмитрия. Таким образом, собранный датасет основан на выборке падений двух людей. Все собранные данные (грязные и очищенные) находятся в директории ml/data в репозитории.
В интерфейсе приложения можно указать, что в данный момент записывается — падение или не падение. Предусмотрена также система избавления от некорректных данных — кнопки 1, 2, 3 предназначены для добавления в конец файла метки Label1, Label2, Label3, сигнализирующих о том, что последние измерения в кол-ве 1, 2 или 3 соответственно некорректны. В дальнейшем исследователь удалит эти данные из файла. Также существует отдельная метка GOOD, которую человек может поставить, чтобы сказать, что все предыдущие измерения гарантированно корректны.
Еще на экране имеются поля Falls и Non-Falls, соответствующие кол-ву записанных измерений в данной сессии приложения по каждому типу состояния. При новом запуске приложения система запишет в файл строчку DataWriter was initialized, которая позволит исследователю увидеть новую сессию приложения и в случае ошибок в данных сузить область поиска для их удаления.
Здесь еще стоит отметить интерфейс со звуковыми сигналами в приложении. Он был разработан специально для сбора позитивных (падения) примеров. Когда человек осуществляет падение, ему нельзя доставать смартфон из кармана чтобы остановить или начать запись, ибо в таком случае данные будут испорчены (не соответствуют реальности). Картинка снизу поясняет принцип работы интерфейса со звуковыми сигналами.
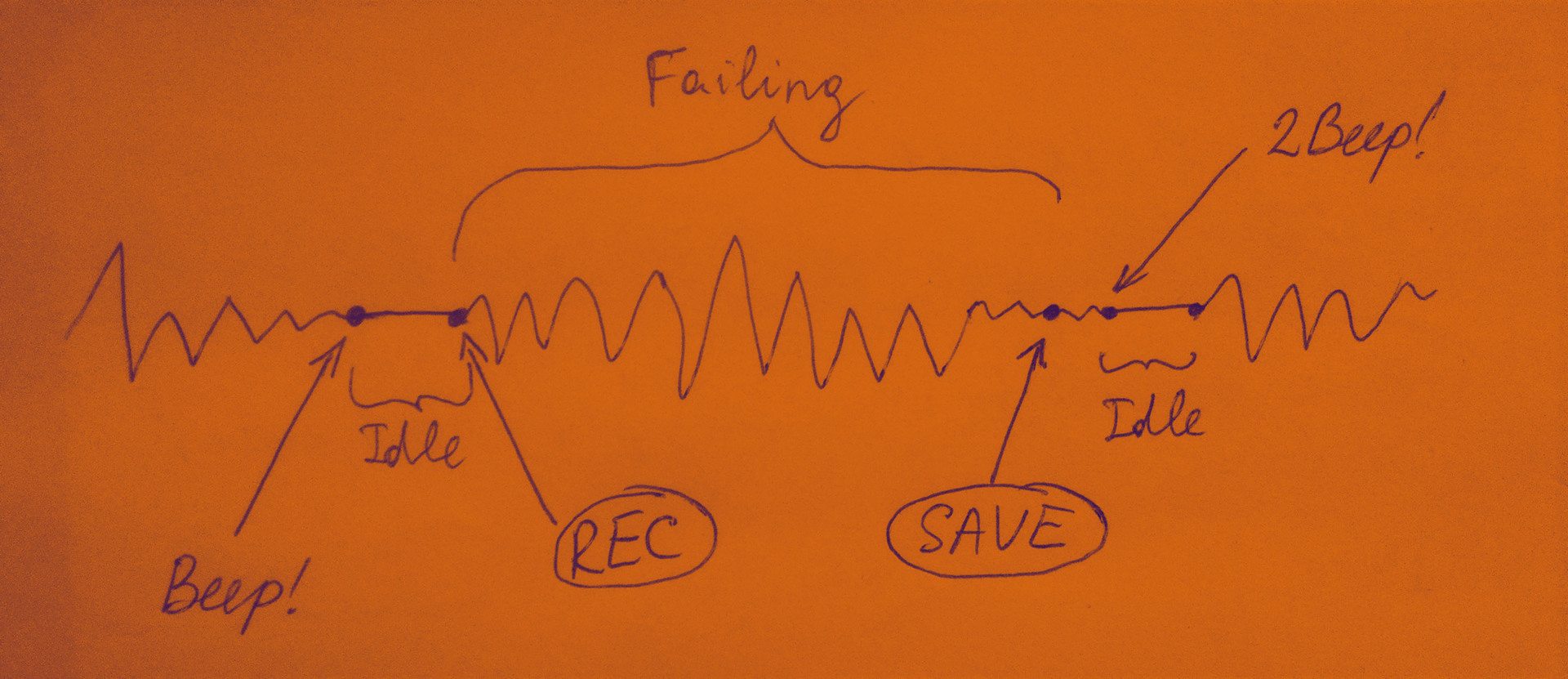
После нажатия на кнопку PLAY система ждет, когда колебания смартфона станут незначительными — человек держит телефон в руке, либо кладет его в карман перед началом записи. Как только колебания стали незначительными, система понимает, что человек готов к записи, и она тоже готова — издает короткий звук Beep. Дальше идет состояние Idle (безделие), которое длится до тех пор, пока человек не начнет двигаться, либо не начнет колебать смартфон в руке. Тогда система начинает записывать данные (на рисунке эта стадия называется Failing). Запись происходит на протяжении 1.5 секунд и завершается длинным сигналом Beep (система записала данные в файл). Пока человек лежит, он не двигается (опять стадия Idle). Как только человек начал двигаться, а вместе с ним и смартфон в кармане, система понимает, что человек поднимается. С этого момента цикл повторяется. Для записи не падения все работает точно так же.
Архитектура
Поскольку система основана на статистических данных со множества пользователей, ей необходима поддержка с воздуха центральная система, обрабатывающая данные. Она представляет из себя несколько машин и сервисов, развернутых в облаке Microsoft Azure, которые делятся на три типа в соответствии с их задачами:
- Получение данных со смартфона
- Детектирование падений
- REST API получения карты заледенелости улиц
Все машины находятся в одной сети и «общаются» через базу данных Apache Cassandra. Эта NoSQL DBMS была выбрана благодаря ее главному свойству — она эффективно работает с большим потоком данных, приходящих в реальном времени со множества устройств. Сразу здесь стоит упомянуть дизайн базы данных. В базе имеется две таблицы со следующими схемами:
sensor_data(user_id: varchar, x: float, y: float, z: float, lat: double, lon: double, timestamp: bigint, fall_status: int). Здесь хранятся все кортежи данных, приходящих с Android устройств. Почему храним все? Считается, что эти данные могут пригодиться в будущем, например, для обучения какого-либо алгоритма без учителя. Физическое хранение строк в этой таблице расположено по убыванию значенияtimestamp, чтобы можно было эффективно работать с более свежими кортежами данных.
update_info(user_id: varchar, is_updated: boolean). Эта таблица нужна только для того, чтобы приложению-детектору определить, от каких пользователей пришли новые данные. Добавлена, чтобы не искать в большой таблицеsensor_dataсвежие записи по каждому пользователю, а сразу знать, у кого есть обновления.
На картинке изображена полная архитектура системы, а за ней следует более детальное описание каждой составляющей.
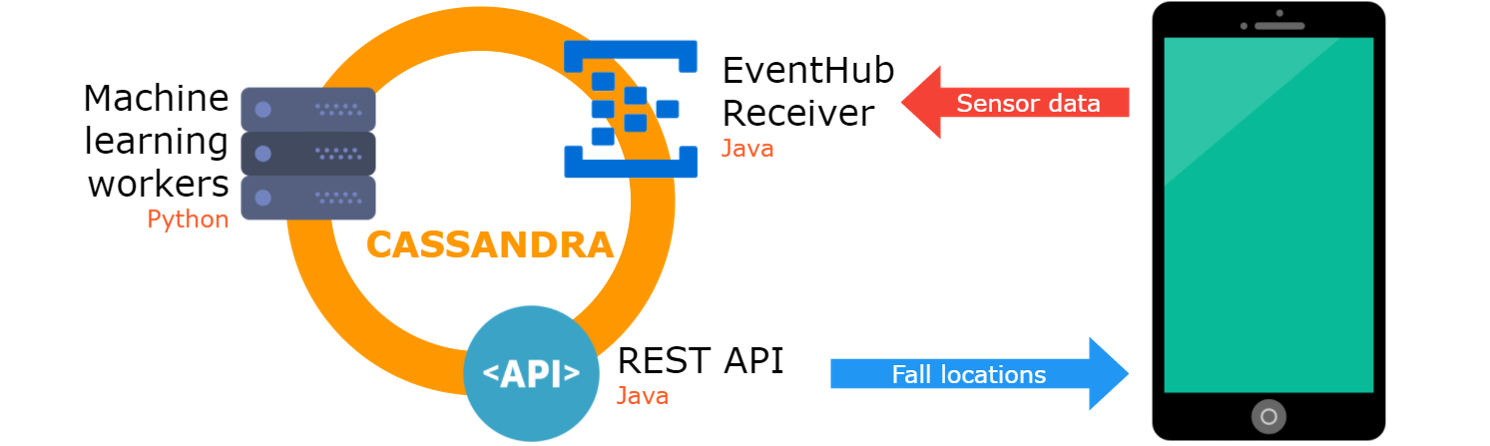
На данный момент в Microsoft Azure развернута одна Linux-машина с пакетом DataStax Enterprise, включающая в себя предустановленную Apache Cassandra. Характеристики машины: 4-х ядерный 2.4 GHz Intel Xeon E5-2673 v3 (Haswell), 14 Гб RAM, 200 Гб SSD. Автор арендует машину на средства, получаемые ежемесячно по программе Microsoft Bizspark.
Получение данных со смартфона
Для отправки и получения данных со смартфона был использован Azure Event Hub, специально предназначенный для большого потока коротких сообщений. На серверной стороне имеется машина с запущенным Java приложением, которое читает данные из очереди Event Hub`а и записывает их в базу данных Cassandra.
Данные представлены в формате JSON. Каждое сообщение от клиента содержит показания акселерометра, временные метки и GPS-координаты для всех измерений, полученных в промежутке 1 минуты.
Если собираетесь реализовывать Azure Event Hub отправителя на Андроиде, то автор может посоветовать сразу смотреть на HTTPS API, поскольку на Андроид нет (или автор не смог найти) подходящей реализации AMQP протокола, который используется всеми Azure Event Hub SDK.
Детектор падений
Для обработки потока данных от пользователей в облаке запущена машина с Python приложением. Почему именно Python? Просто потому что исследования с машинным обучением проводились на Python с использованием библиотеки scikit-learn, а переписывать приложение с использованием других технологий только для того чтобы запустить его на сервере на данном этапе было лишним.

Детектор падений работает по принципу скользящего окна (англ. — sliding window). Окно скользит по интерполированным данным (да, каждый кусок свежих данных, взятых из базы, интерполируется по причине проблемы, описанной вначале) и запускает классификатор для определения факта падения. Решение классификатора 1 (падение) или -1 (не падение) записывается обратно в базу данных для первого извлеченного кортежа в исследованном куске данных. Естественно, вся эта процедура выполняется независимо для каждого пользователя, который определяется по user_id в таблице.
Классификатор
Отдельно стоит поговорить про классификатор. Он основан на классическом (без использования нейронных сетей) алгоритме машинного обучения. Качество классификации оценивается по метрике F1-score. В поле исследования попало следующее:
- Алгоритм машинного обучения и его параметры. Кандидатами на звание лучшего классификатора падений были выставлены Random Forest Classifier, Support Vector Classification/Regression и Linear Regression. После проведения нескольких запусков было выявлено, что Random Forest Classifier с кол-вом деревьев 10 и остальными параметрами по умолчанию (которые установил scikit-learn) показывает наилучшие результаты.
- Датасет. Здесь варьировались тестовая и тренировочная выборки по соотношению <кол-во позитивов>:<кол-во негативов> и менялся набор самих негативов. Финальная тренировочная выборка негативов включает примеры простых движений смартфона в воздухе, хождений по комнате, подбрасываний, а также примеры, на которых классификатор давал ложные срабатывания в боевых условиях (т.е. когда весь цикл системы был реализован, а автор намеренно делал хождения по комнате и прыжки без падений). Итого датасет составлял 84 позитивных примера и 400 негативных. Из них 80% случайных примеров отводилось на обучение, остальные 20% — на тестирование.
- Набор осей акселерометра. Исследования показали, что набор осей
{x, z}дает наилучшие результаты в классификации, что также положительно влияет на сокращение интернет-трафика пользователя. Но здесь стоит оговориться. Дело в том, что данные падений собирались автором при постоянном положении смартфона в кармане верхней его частью вниз. Именно это направление соответствует направлениюyна LG Nexus 5. Алгоритм переобучался на данных по осиy, и, несмотря на то, что он показывал неплохие результаты на тестовой выборке, в боевых условиях он давал очень много ложных срабатываний при простом повороте смартфона «вниз головой». Эту проблему можно решить путем создания более репрезентативной выборки. Но на данный момент результат с учетом только двух осей очень даже неплохой.
- Параметры интерполяции. Как было сказано ранее, ввиду большого зоопарка устройств на Android приходится работать с разреженными данными. Здесь помогает линейная интерполяция. И раз уж мы беремся за интерполяцию, неплохо было бы попробовать уменьшить разрешение данных для сокращения интернет-трафика со стороны пользователя и для уменьшения серверной нагрузки на детектирование падений. Напомню, базовый датасет содержит полутора-секундные фреймы данных, разбитые на 300 кортежей
(x, y, z, timestamp)(один кортеж в 5 мсек). При уменьшении разрешения до одного кортежа в 50 мсек наблюдается все еще приемлемое качество классификации, но объем данных сокращается в 10 раз!
Итоговое максимальное по нескольким тренировочным эпохам значение F1-score при всех указанных наилучших параметрах и с учетом намеренного разрежения данных в 10 раз оказывается на уровне ~90%. Без разрежения — ~95%.
Объем данных, отправляемых с Android приложения в бинарном представлении, небольшой. В самом деле, 2(кол-во осей) * 4 байта(размер значения по оси) + 4 байта(размер timestamp) + 8 байт(размер координат) = 20 байт — размер одного кортежа данных. 1000 мсек / 50 мсек = 20 — максимальное кол-во кортежей за секунду. 20 байт * 20 = 400 байт в секунду. Дальше 400 байт * 60 * 60 * 24 * 30 = 1 036 800 000 байт или ~980 Мб в месяц. Это при условии, что пользователь ходит 24 часа в сутки, и приложение непрерывно отправляет данные. Но на деле в среднем пользователь проводит не больше трети суток в движении. С учетом этого грубого допущения получаем нагрузку на трафик в районе 300 Мб, что можно считать весьма адекватным.
REST API и отображение точек на карту
Для получения обновлений всеми пользователями приложения Sleet Monitor о степени заледенелости улиц был написан простенький REST API на Java с использованием библиотеки spark-java. Приложение обращается все к той же базе данных Cassandra и достает свежие координаты тех точек, для которых значение fall_status = 1 (в этом месте было обнаружено падение). По-хорошему, здесь можно провести некоторую очистку данных вроде проверки на совпадение координат нескольких точек. На данный момент без дополнительной обработки координаты добавляются в R-Tree для быстрого поиска по прямоугольной области, которая приходит в запросе от клиента.
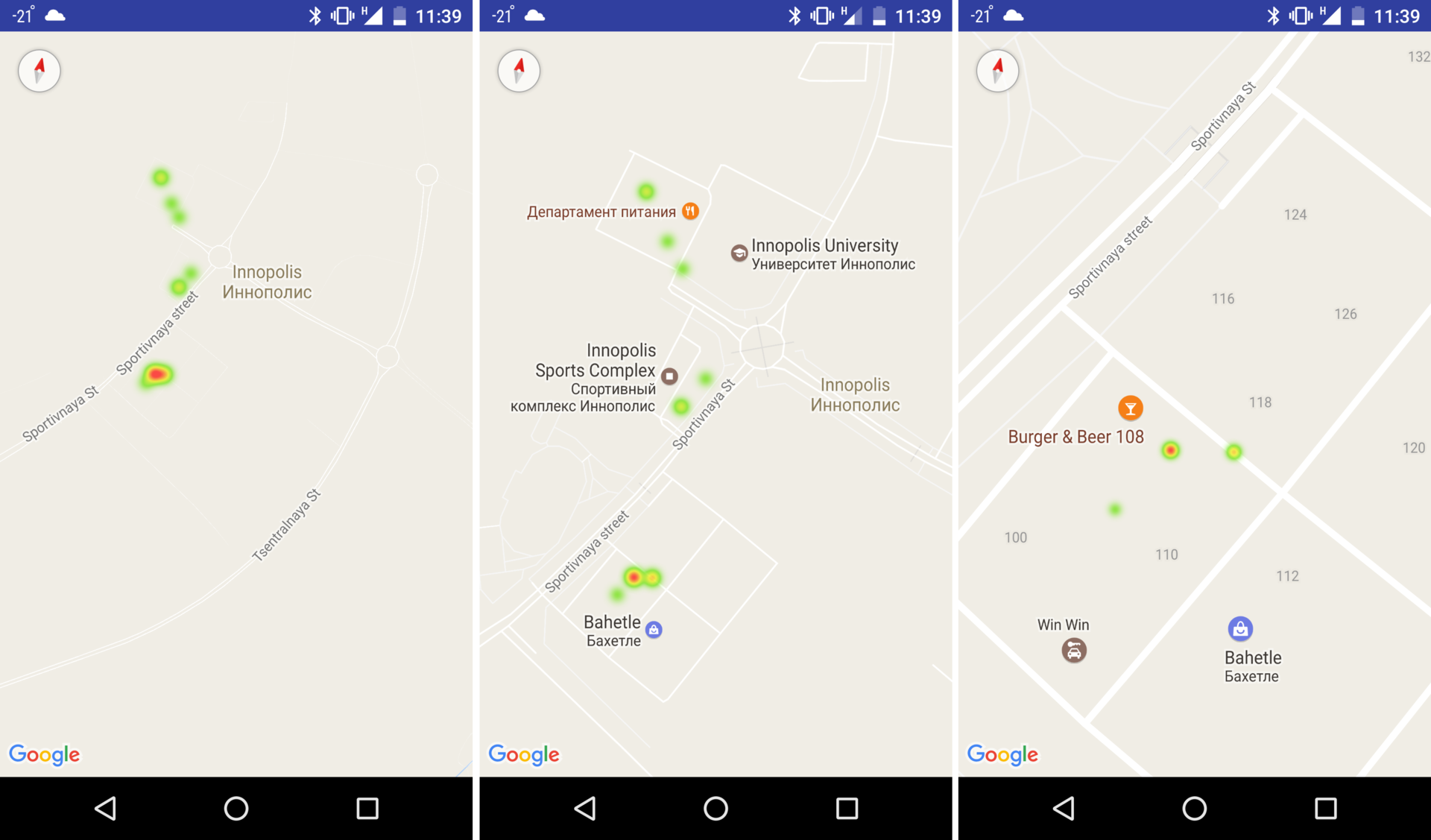
Чтобы отобразить точки на карте моим товарищем Бондарем Богданом был реализован принцип heat map, позаимствованный из примера Google для Android. Суть принципа заключается в том, что при изменении масштаба карты в сторону увеличения области обзора отрисованные точки схлопываются так, что там, где чем больше плотность точек в окрестности, тем крупнее выглядит пятно на карте.
На рисунке ниже показан пример отрисованных точек падений. Это настоящие падения, «нападанные» автором на снегу специально для демонстрации работы системы. В красных областях автор намеренно падал несколько раз, чтобы показать, что классификатор падений работает неплохо, и при записи не было ниодного ложного срабатывания, при том что запись производилась непрерывно с одинаковой скоростью обхода улиц.
Заключение
Итак, небольшое улучшение в городской жизни людей сделать возможно. Система отслеживания падений людей реализована. Естественно, здесь можно и нужно сделать много оптимизаций, чтобы снизить как серверную нагрузку, так и нагрузку на интернет-трафик пользователя — натренировать модель сразу на более разреженных данных, тем самым сократив вычислительные затраты на детектор падений; увеличить шаг бегущего окна в детекторе; для сокращения трафика передавать данные с Android устройства в бинарном виде, а не как сейчас в JSON; и др.
Улучшения всегда можно делать, многие из них тривиальные, и при этом могут принести значительное снижение затрат как на серверную часть, так и по трафику пользователя. Цель разработки была в том, чтобы получить опыт запуска полного конвейера, включающего мобильное приложение и высоконагруженную серверную часть, обрабатывающую огромный поток данных в реальном времени. Но чтобы запустить эту систему в реальных условиях, нужно значительно расширить парк машин в облаке и распространить мобильное приложение с достижением высокой концентрации пользователей хотя бы в одном городе. А с монетизацией пока ничего не ясно.
Предвидя эту проблему на этапе зарождения идеи, сразу было решено делать проект открытым. Напомню, весь код находится в репозитории на GitHub. Цель написания дебютной для автора статьи на Хабрахабр заключалась не только в том чтобы рассказать о полученном опыте построения подобных систем, но и в том, чтобы получить какую-то обратную связь от сообщества. Поэтому комментарии очень приветствуются, равно как и предложения по дальнейшему развитию системы. Спасибо за внимание.
Комментарии (13)

puhoshville
26.12.2016 22:13Как я понял из статьи, на вход алгоритмам подаются сырые данные длинной 1.5с, верно? Не пробовали дополнить их (сырые данные) вычисленными признаками по типу: среднее расстояние между соседними пиками, амплитуда и т.д. По графикам fallen/non-fallen видно наличие характерных «вибраций» для первого класса.
Хорошие результаты, несмотря на низкое качество данных с MEMS датчиков!)
VladVin
26.12.2016 22:22Да, хорошая идея насчет дополнения признаками. Результаты неплохие, но стоит иметь в виду, что обучение и тестирование производилось на данных с одного и того же смартфона. Если составить выборку с данными от разных устройств, картина может сильно ухудшиться. К сожалению, это не проверялось.
VladVin
26.12.2016 22:32Есть подозрения, что здесь могут помочь какие-нибудь методы работы с временными рядами. Если есть опыт в этом, был бы рад услышать, что можно с этим сделать в этой задаче :)
shurupkirov
27.12.2016 09:55Проблема в том, что это не надо администрации. Они на звонки-то не отвечают про неубранные улицы, гололед на тротуарах и т.п.
Реакция начинается только тогда, когда "жареный петух клюнул"VladVin
27.12.2016 17:49Возможно, они игнорируют единичные жалобы из разных уголков города. А если бы информация о степени заледенелости была в одном месте, причем основанная на статистике, скорее всего администрация использовала бы ее.
Вообще первоначальная идея была в создании сервиса, в котором люди выбирают наиболее безопасный маршрут из A в B зимой, исходя из статистики падений других людейshurupkirov
27.12.2016 19:30да нет. Проблема не в этом. муниципальная дорожная служба по тендеру отдает на откуп 1-2 кампаниям уборку, те еще берут по 10-20 субподрядчиков и на тебе отсутствие контроля и заинтересованности

ceperaang
27.12.2016 13:20По заголовку был уверен, что речь идёт о распознаваний заледеневших улиц с изображения с камер, например. А тут вовсе не заледенелость отслеживается, а падения — люди могут и по другим причинам падать.
VladVin
27.12.2016 17:52А по каким ещё причинам могут подать? Я думаю, что если это не дети, то люди падают скорее всего из-за скользкой поверхности. И тут даже не важно какой она природы. Или я ошибаюсь?
IronHead
То же самое, но объединить с навигатором для авто.
Получаем детектор ям на дорогах.
При правильной статистической обработке — можно будет заранее предупредить водителя о крупной выбоине в дорожном полотне (особенно полезно на загородных трассах).
Можно слать претензию в росавтодор в автоматическом режиме с указанием координат места.
Можно показывать ненавязчивую контекстную рекламу пользователям приложения: влетел в яму? ближайший шиномонтаж через 200м.
VladVin
Именно такую систему сейчас разрабатываем в команде из трех человек :) Спасибо за комментарий.
the_ghost
https://texnomaniya.ru/internet-news/vestinet-google-schitaet-jami-spros-na-planshetniki-rastet.html
https://geektimes.ru/post/113497/
http://www.sciencedirect.com/science/article/pii/S1877042812042905
Вдруг поможет )