

Текстов про Midjourney, DALL-E 2 и Stable Diffusion много: их обозревали и даже сравнивали с дизайнерами. Мы решили пойти дальше и устроить между ними баттл: проверить, как нейросети генерируют литературных персонажей, исторических личностей, абстракции и другое. Что из этого получилось — показываем под катом.
Дисклеймер: статья не претендует на научную точность. Мы просто попробовали сравнить популярные нейросети. По фану!????
Особенности в работе с нейросетями
У каждой нейросети есть свои особенности, которые нужно учитывать перед началом работы.
Midjourney
1. Работает через Discord-канал: для генерации изображений нужно отправить свой запрос в чат-канале newbies. Другие пользователи будут видеть ваши результаты.
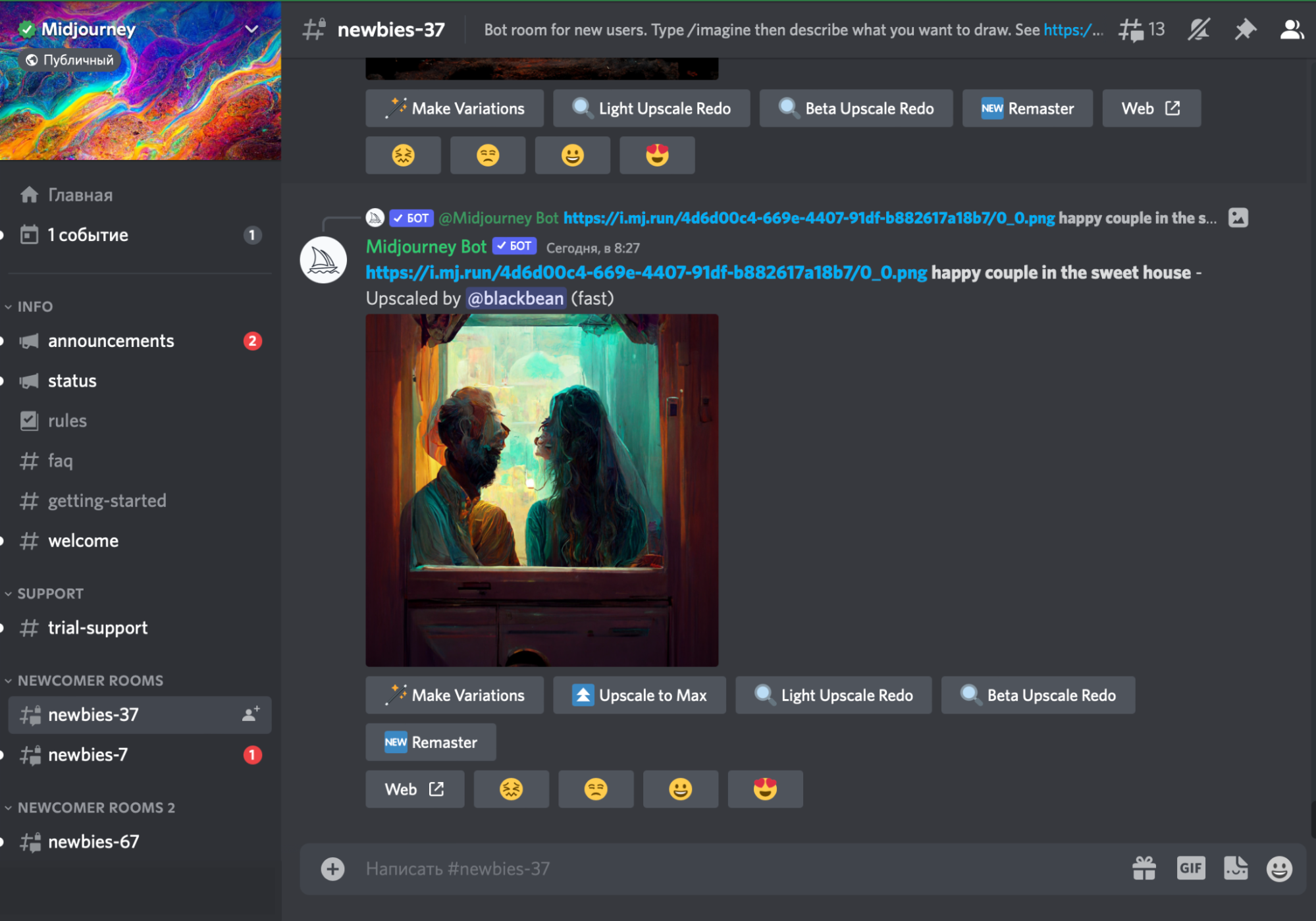
Окно Discord-канала Midjourney
2. Каждому новому пользователю доступны бесплатные 25 запросов. Дополнительные 200 запросов обойдутся в $10.
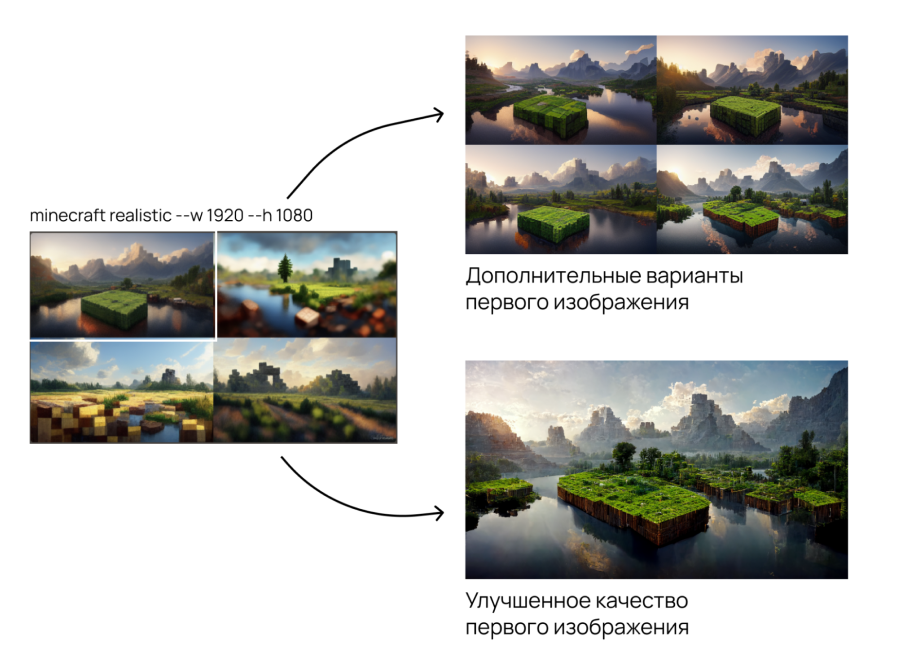
3. В ответ на запрос нейросеть рисует коллаж из четырех изображений. Их размеры можно устанавливать с помощью специальных флагов --w и --h.

Пример настройки разрешения изображений
4. Изображения можно улучшать или генерировать для них дополнительные варианты.
DALL-E 2
1. Каждому пользователю доступны бесплатные 50 запросов в первый месяц и 15 — в каждый следующий месяц. Проект работает через API. Для пользователей из России он доступен только через VPN. Кроме того, при аутентификации понадобится SMS-подтверждение, которое работает только для иностранных номеров.

DALL-E 2, сообщение об ошибке: «Что-то пошло не так. OpenAI недоступен в вашей стране»
2. С помощью встроенного модификатора можно изменять отдельные участки изображений. Например, превращать котиков в… кепки.
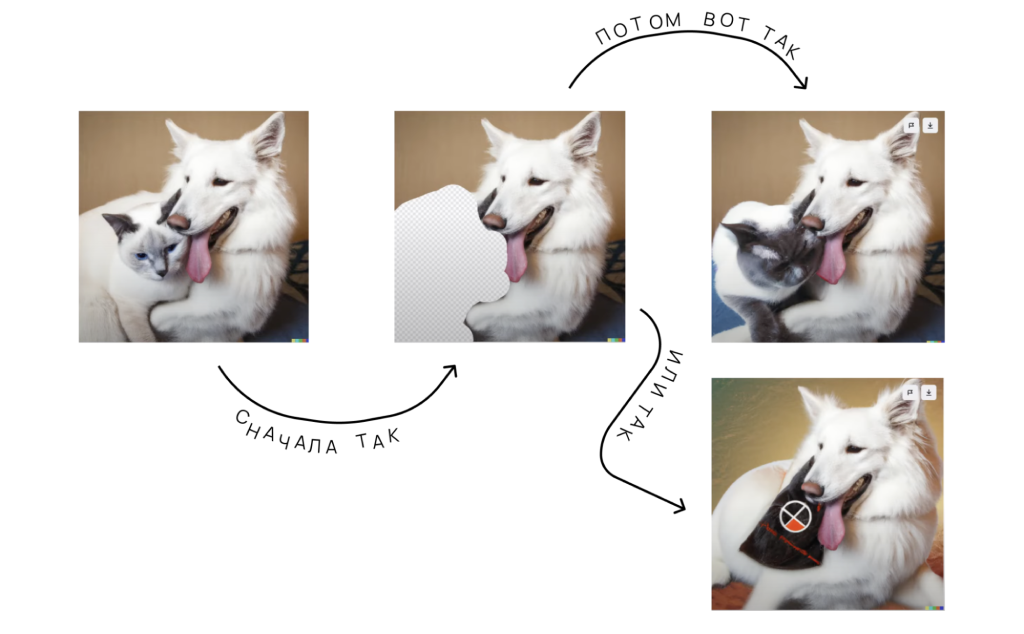
3. Для каждого изображения можно сгенерировать дополнительные варианты, из которых можно отобрать лучшие иллюстрации.
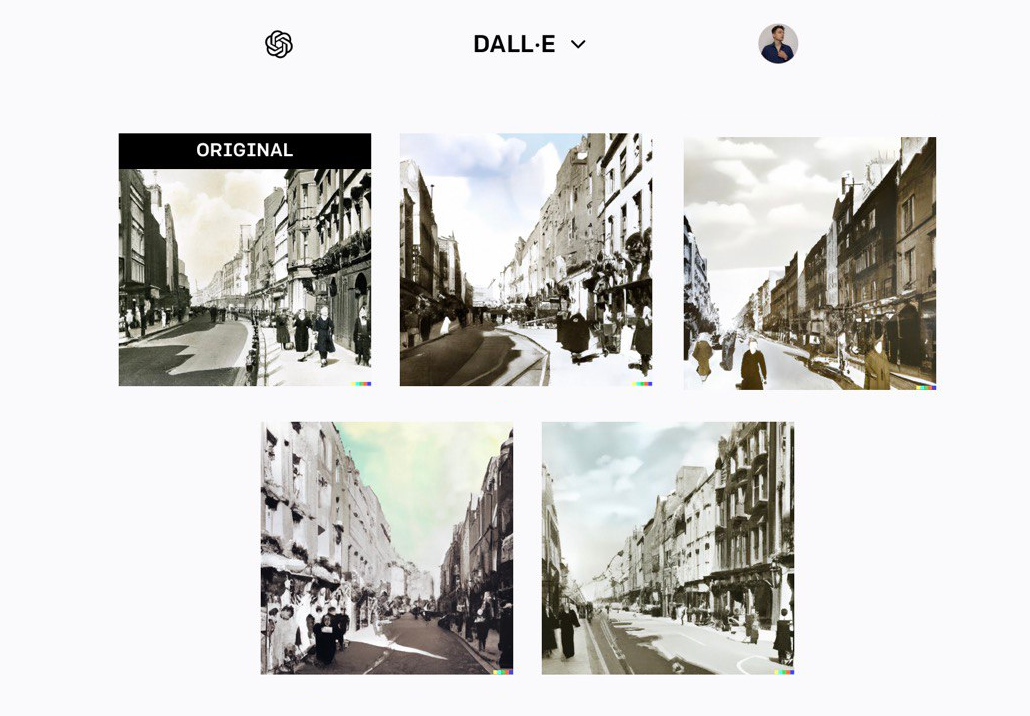
4. В DALL-E 2 нельзя устанавливать размеры изображений. Нейросеть умеет работать только с форматом 1:1. Это минус, если нужно сделать обложку, например, для статьи на Хабре.
Stable Diffusion
1. Исходный код проекта есть в открытом доступе. Для работы с нейросетью можно скачать git-репозиторий и развернуть свой web-сервер.
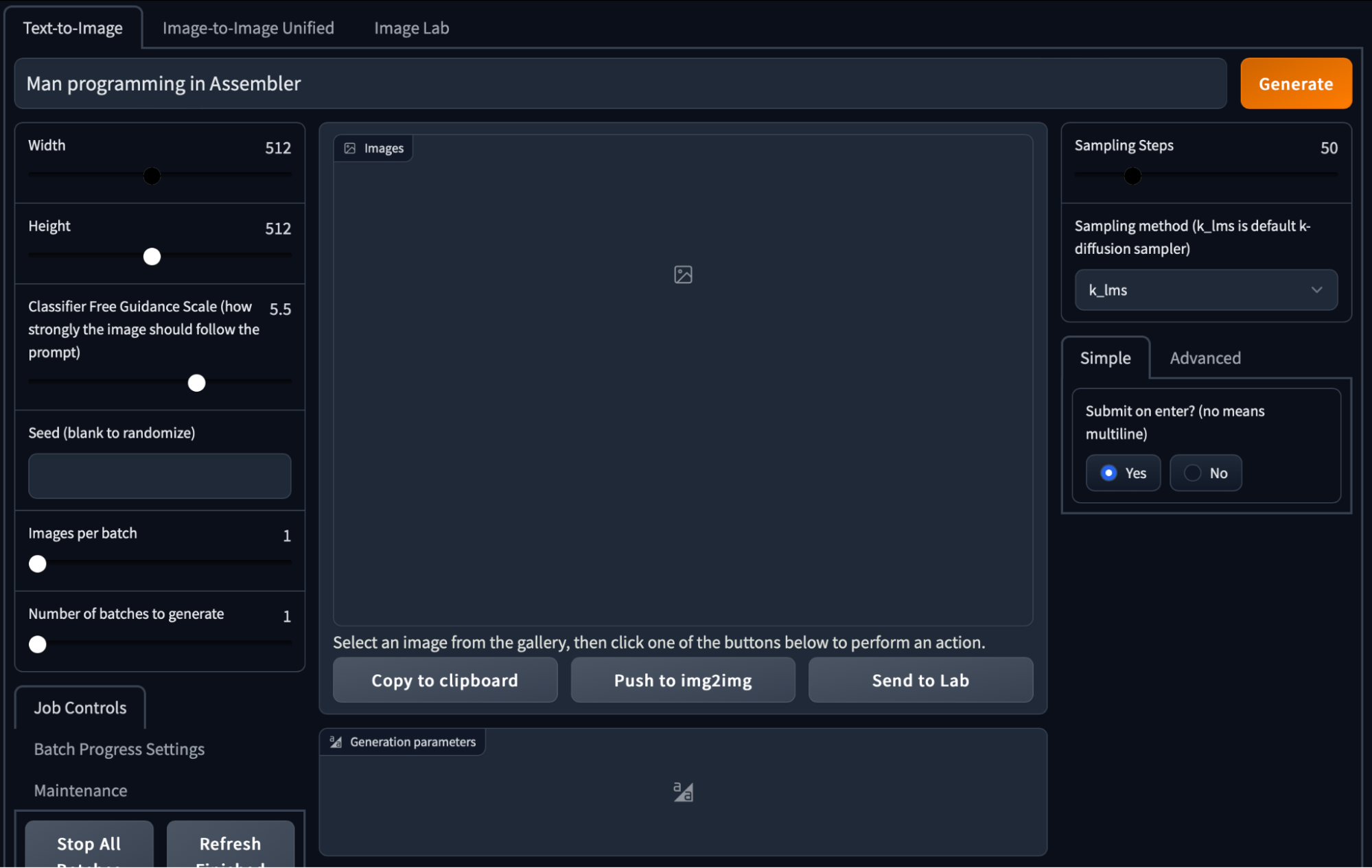
Stable Diffusion, WebUI

Для работы с нейронными сетями можно использовать облачные серверы Selectel с видеокартами. О том, почему ML-модели лучше запускать на GPU, рассказали в статье.
2. В Stable Diffusion есть ряд параметров для гибкой настройки генератора изображений:
- Height, Width — размер изображения.
- Classifier Free Guidance Scale — насколько точно изображение должно соответствовать запросу. Рекомендуем использовать стандартное значение — 7,5.
- Number of batches to generate — сколько всего подборок сгенерирует нейронная сеть.
- Images per batch — количество изображений в одной подборке.
- Sampling steps — количество раз, которое нейронная сеть обрабатывает изображение. Для всех изображений в статье параметр равен 70.
- Sampling method — метод выбора «лучших» изображений во время генерации — для простых запросов разница незаметна. В большинстве случаев использовали стандартный метод k_lms.

Stable Diffusion, изображения с разными значениями Sampling method
3. Изображения можно улучшать с помощью встроенного параметра — Upscale images using RealESRGAN.
Сравнение результатов нейросетей
Несмотря на различия между проектами, есть общие правила по формированию запросов. Основные из них описаны в прошлой статье.
Для баттла нейросетей мы придумали и провели шесть испытаний:
- Литературный персонаж. Нейросети сгенерировали образ того, чье имя нельзя называть.
- Историческая личность. Как думаете, каким нейросети нарисуют Уинстона Черчилля: с сигарой или без?
- Айтишный сценарий. Проверили, «слышали» ли нейронки про Assembler и программирование.
- Абстракции. Нарушили правила формирования запросов и попросили изобразить «чувство любви».
- Сборная солянка. Что получится, если просто перечислить объекты в запросе?
Волан-Де-Морт
В серии фильмов «Гарри Поттер» роль лорда Волан-Де-Морта играли 5 актеров. Интересно, каким чародея видят нейросети?
Запрос: Lord Voldemort stands and smiles digital art

Кажется, нейросети смогли передать композицию. Насколько каждая из версий темного лорда похожа на канон — вопрос для поттерианцев.
Несмотря на прописанный в запросе стиль digital art, «испытуемые» показали разные результаты. Самым удачным кажется вариант от Midjourney. Он очень похож на персонажа из фильмов о Гарри Поттере.
Сложней всего было сгенерировать картинку в Stable Diffusion. В большинстве случаев у персонажа силуэт был неуклюжим, с глюками.

Изображение, сгенерированное Stable Diffusion
Уинстон Черчилль
Лондон, 1947 год. По тротуарам ходят люди в выглаженных костюмах, а вдоль дорог — красивые фонари. Дайте угадать: вы представили картину в черно-белых тонах? DALL-E 2 и Stable Diffusion — да.
Запрос: Winston Churchill standing in front

По умолчанию DALL-E 2 и Stable Diffusion генерируют «фотографии», которые сложно отличить от настоящих. Хотя в первом случае есть недоработки: лица размазаны, а текст не разобрать.
На общую картину это не влияет. У нейросетей получилось «визуализировать» запрос. Однако Midjourney, кажется, справилась лучше. Она по умолчанию сгенерировала полноценную цветную картину. С помощью DALL-E 2 и Stable Diffusion можно получить похожие результаты, но для этого нужно «пошаманить» со стилями и настройками.
Удивительно! Ни одна нейросеть не сгенерировала Уинстона Черчилля с сигарой.

Программирование на Assembler
В прошлой статье мы пытались повторить обложку для одной из статей. И обнаружили, что Midjourney не может изобразить программный код. Решили проверить, какая из нейросетей лучше всего справится с иллюстрацией на тему программирования.
Запрос: man programming in Assembler

На первом и третьем изображениях — люди за компьютером. Программируют они или нет — неизвестно. Но отдаленно похоже на это. А вот на второй картинке не понятно, что нейросеть хотела показать. Иногда Midjourney рисует слишком абстрактные вещи.
Скорректировали запрос и добавили деталей: Man sits at computer and programming in Assembler

Мыслитель сидит в позе лотоса и программирует, Midjourney
Чувство любви
Как вы представляете себе чувство любви? Ассоциируется ли оно у вас с близким человеком или, может, любимым растением? Представить — просто, а объяснить — трудно. Потому что чувство абстрактно и субъективно. Вопреки рекомендациям по запросам проверили, какой любовь видят нейросети.
Запрос: feeling of love, digital art

Sampling method = k_euler
Абстрактные композиции лучше получаются у DALL-E 2. Они не тривиальны и передают сюжет. Midjourney и Stable Diffusion фокусируются же на первом, что приходит в голову, когда слышишь слово «любовь».
Набор объектов
Во время создания иллюстраций дизайнер думает о том, как лучше объединить разные элементы, прописанные в техническом задании. Иногда сложно представить «сцену»: объекты могут быть абсолютно не связаны, а их нужно как-то «скрепить» в композицию. Мы решили проверить, что придумают нейросети, если просто перечислить ключевые элементы через запятую.
Запрос: computer, photos with cats, robot, fish
Что не так с третьим изображением? Сначала подумали, что нужно откалибровать параметр Classifier Free Guidance Scale (cfgscale). Он отвечает за то, насколько точно изображение должно соответствовать запросу. Но это ни на что не повлияло: при разных значениях cfgscale получаются обычные слияния картинок.

Результаты по запросу «computer, photos with cats, robot, fish» при разных значениях cfgscale.
В остальном, кажется, с задачей лучше справилась DALL-E 2. На рисунке изображен котик, который с недоумением смотрит в монитор компьютера. Нейросеть не проигнорировала в запросе и рыбу: на стене есть ее фотография.
Видение себя
И напоследок: как нейросети видят сами себя? Мы проверили и были в замешательстве.

Stable Diffusion ассоциирует себя с лошадьми, Midjourney — с пейзажами и закатами, DALL-E 2 смотрит на себя по-разному. Сначала как на пиво с тумбочкой, а теперь — как на гедзе. Разработчики от нас что-то скрывают.
Возможно, эти тексты тоже вас заинтересуют:
→ Увеличиваем FPS в аниме с помощью нейросети и GPU Tesla T4
→ Сможет ли Midjourney заменить дизайнеров? Тестируем нейронную сеть
→ ML в Managed Kubernetes: для каких задач нужен кластер с GPU
Общая проблема: нейросети генерируют мутантов
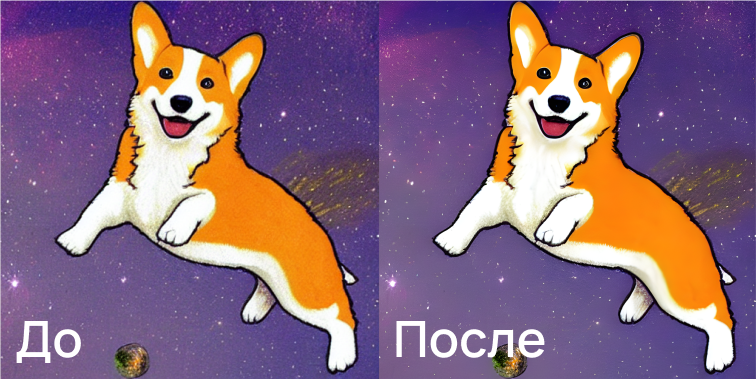
С какой бы нейросетью мы ни работали, у всех одна проблема — артефакты на лицах. Нос может быть на щеке, а рот — на лбу.

И бывает такое, что изображение почти идеальное: фигуры стоят на своих местах, цвета и стиль сочетаются, но лицо «не пропечатано». Для борьбы с такими артефактами есть специальные сервисы. Один из них — Arc Tencent.

«Пофиксили» левый глаз. Arc Tencent Face Restoration, пример работы
Возвращаясь к особенностям Stable Diffusion: у нейросети есть встроенный инструмент для постобработки лиц (Fix faces using GFPGAN).

Сравнение лиц до обработки и после, Stable Diffusion
Что выбрать для создания обоев на рабочий стол? Midjourney или Stable Diffusion?
Артефакты — не единственная проблема, с которой можно столкнуться. Иногда при генерации горизонтальных и вертикальных изображений некоторые объекты дублируются. Это особенность Stable Diffusion. В Midjourney с этим проблем нет.

Изображения, сгенерированные Stable Diffusion
Какая нейросеть победила?
Midjourney, DALL-E 2 и Stable Diffusion способны генерировать как потрясающие, так и «слабые» изображения. В каких-то случаях нужно больше поработать с запросами, а в других — достаточно одной попытки, чтобы получить хороший результат. И сложно сказать, какая нейросеть победила. Но в частных случаях выбирать не приходится.
Если нужно сгенерировать изображение здесь и сейчас — используйте Midjourney. Достаточно подключиться к Discord-каналу. Не нужно настраивать VPN или разворачивать целый web-сервер. Можно получить хорошее изображение даже без настроек стилей. Хотя иногда может понадобиться не одна попытка.
У Midjourney есть свой «универсальный почерк». Она по умолчанию генерирует картины, будто написанные маслом, а не фотографии или рисунки, как это делают DALL-E 2 и Stable Diffusion. Преимущество ли это — решать вам.
Хотите объединить несколько разных объектов? С задачей поможет DALL-E 2. Она умеет строить сложные и «осмысленные» композиции. Это полезно, когда дизайнеру нужно получить большое количество референсов в сжатые сроки.
Также в DALL-E можно изменять изображения при необходимости. Пример: нейросеть нарисовала пейзаж, но на горизонте стоит лишнее дерево. Вы можете его выделить и удалить.
Но помните: для работы с нейросетью нужен VPN и иностранный номер телефона. Это затрудняет работу. Зато сервис бесплатный и не ограничивает в количестве запросов.
В Stable Diffusion есть настройки для гибкой работы с генератором изображений. Например, если нужно контролировать нагрузку нейросети на сервер, можно уменьшить параметр Sampling steps. А если ресурсов достаточно и цель — получить наиболее качественные рисунки, можно выкрутить параметры на максимум. Хотя с Classifier Free Guidance Scale лучше не экспериментировать. Крайние значения генерируют изображения, состоящие из одних «глюков». Зато в Stable Diffusion есть встроенная постобработка лиц и апскейл.
Однако для работы с нейросетью нужно развернуть Google Collab или собственный web-сервер. Это решение может оказаться дороже, чем подписка в Midjourney.
Комментарии (21)

Doman
04.10.2022 17:03+3DALL-E 2 в статье несколько раз называется бесплатным, но он вполне себе платный, хоть и выдает каждый месяц десяток бесплатных кредитов для генерации. За сравнение спасибо, сети действительно очень разные, и prompt-ы для каждой нужно отдельно подбирать.

esselesse
04.10.2022 18:38+1Как-то "до" фиксинга и апскейлинга рисунки выглядят реалистичнее, если честно :)
Вопрос - в статье специально использовались довольно простые запросы к нейросеткам?
просто, насколько я знаю, тому же миджорнею для особо красивых картинок предлагают многострочные запросы.
как пример:"small stream that passes through the middle of the forest, 8K, ultra realistic, photography, RTX, light mode, octane render"
то есть, с задаванием параметров по качеству рисунка и его стилистике
Doctor_IT Автор
04.10.2022 19:39+1Здравствуйте!
Да, у нас была задача посмотреть именно на композиции и на то, какие получаются генерации по умолчанию.
Запросы можно дополнять и указывать, например, стиль определенного художника. Но тогда крайне сложно выявить, что именно не понимают нейронки. Это тема, кажется, для отдельной статьи ????
esselesse
05.10.2022 15:36вообще, мне кажется, неплохая идея - сравнить разные режимы работы у разных нейросеток)
вдруг у одной из них "фотореалистичность" означает не то, что у другой
но я понимаю, что тут должно быть весьма кропотливая работа проведена, на паре картин вряд ли получится

Astus
05.10.2022 00:11+9Stable Diffusion для меня номер один с недосягаемым отрывом, потому как у него есть важнейшая, по моему мнению, фича — локальная работа и локальный же результат, независимо от сторонних серверов, sjw, дискордов, санкций, политиков и прочего. По-старомодному так — скачал, настроил, пользуйся! Красота же.
И выдавать он может ой какое искусство, если правильно с ним договориться, например из последнего:Заголовок спойлера




vassabi
05.10.2022 00:41+1вот кстати да. Отлично работает, настраивается так, что потребляет до 4гб видеопамяти (привет ноутбуки).
Кроме правки лиц - ей еще бы подкрутить руки-ноги (а то бывают многоножки), но все равно классно работает.
esselesse
05.10.2022 15:40нам в чатик один раз скинули "эротишные" картинки от нее... выглядят, если честно, крипово
кидать сюда, по понятным причинам, не буду, но если их описывать - у женщин из грудей вырастали руки, делающие селфи на айфон, или была, к примеру, моделька без руки, но с двойным глазом... крипота, да и только =/
Astus
05.10.2022 16:36+2Это да, тратить время всё равно приходится, подбирать слова и потом полировать, отделяя зёрна от плевел.
Впрочем, неудавшиеся кадры мне тоже нравятся, половину сохраняю как референс для хоррора/сайфай, или просто как хохму)Идеальной девушки не существу...

perfect_genius
05.10.2022 16:29Похоже, сейчас правилом хорошего тона станет обязательное упоминание ключёвых слов как пруф, что изображение не было доделано вручную в графических редакторах.

Kristaller486
05.10.2022 18:51+2Изображения из комментария выше - результат работы зафайнтюненой Waifu Diffusion - специально дообученеый на анимешных девушках вариант Stable Diffusion. Это ещё одно преимущество SD, её можно дообучать.






Kazzagor
05.10.2022 09:11+5Я развернул SD на домашних картофельных компах с 1060/6гб, 8гб рам и 1660/6гб, 16гб рам. Датасеты качал разные, вроде как на 4 и 7гб. 1 картинка 512* вылетает за 20-25 секунд по методу эйлер. Апскейлер лакруа в пределах двух секунд на максимальное увеличение, есрган гдето 30сек работает.
Sd больше всех похожа на рабочий инструмент. Вопервых, бесплатно сидит на твоем компе средних характеристик (у нас i7 890 и i7 2600). Во вторых, картинка с нуля по промту, ок, поискать идей и композиций. Во-вторых, img2img - работа по запросу и исходному изображению, позволяет накидать композицию самому и фотобашить промежуточные варики, прикрепляя в фоше "подсказки" по местам. В-третьих, апскейлер на финише, можно разогнать 512пикс в 2048, а 2048 в... Ну тут картофельный комп начинает лагать) И! Никаких ограничений.
Делаем с женой на SD закотовки под реальную живопись, плюс промежуточный этап в цифровом рисунке. Помимо ржаки с косяков, упрощает, убыстряет работу. Ну и вообще мы счастливы увидеть "новые сюжеты" босха, брейгеля, малевича, кандинского, родченко. Рад что такой инструмент запилили.
Да, косячит, но люди косячат тоже, ток в других аспектах. По времени - вне конкуренции
vassabi
05.10.2022 16:00Делаем с женой на SD закотовки под реальную живопись, плюс промежуточный этап в цифровом рисунке.
вот кстати да!



redpax
05.10.2022 09:28+1Судя по всему в midjourney не использовали команды
—test —creative —upbeta —s —chaos тогда бы результат был бы без артифактов на лицах и был бы реалистичным. Вот мои эксперименты с этими параметрами pikabu.ru/story/mashina_mozhet_sozdat_iskusstvo_tvoreniya_midjourney_9451125
Kristaller486
05.10.2022 19:11Сравнение разных нейросетей на одних и тех же запросах, имхо, сомнительная идея, которая не дает реального понимания качества результата инструмента.
Midjourney действительно выдает картинки в среднем эстетичнее, но плохо рисует конкретные вещи и стили, которые сильно отличаются от её собственного.
SD плохо генерирует фотографии, зато отлично совмещает стили, а то, что веса открыты дают бесконечные возможности для её использования и исследования.
DALLE-2 отлично следует тексту запроса, но это черный ящик на серверах OpenAI, который жрет много денег и имеет жёсткую входную цензуру для запроса.

CAJAX
06.10.2022 08:49В тесте "нарисовать себя" mj скорее всего понял midjourney как "полпути", а sd понял stable, как конюшню
CodeName33
DALL-E не пробовал, но что у Midjourney, что у Stable Diffusion, на мой взгляд, одна и та же проблема. Приходится прокрутить несколько (а иногда и несколько десятков) вариантов, чтобы просто получить то, что я просил (про качество я уже не говорю). Т.е. например, если я ввожу запрос типа: "кот с мордой собаки летит на крыльях над ночным городом" (на английском естественно), то нейросеть, порой, тупо выкидывает некоторые условия и рисует только часть из запрошенного. Либо просто кота в городе, либо собак, либо не рисует город, либо кота рисует как дом и т.д., приходится дублировать условия и то, это не гарантирует их выполнение.
Doctor_IT Автор
Да, вы верно отметили. В Midjourney и Stable Diffusion иногда сложней получить что-то "годное". Если нужно придумать, как объединить набор рандомных объектов, то лучше воспользоваться DALL-E. Она хотя бы не игнорирует условия.