
Работая с текстами, часто приходится сталкиваться с проблемой грязных данных. Опечатки, орфографические ошибки, случайный CAPS LOCK. И это ещё не затрагивая всю огромную беду с непопулярными жаргонизмами и локальными аббревиатурами/названиями. Практически любой даже самый мощный и чудесный алгоритм анализа, не будучи предварительно подготовленным, на моменте обнаружения фразы «две однёрки» пошатнётся и икнёт. А если таких фраз в тексте будет много, то алгоритм просто сойдёт с рельсов, и полезный эффект нивелируется.
|
— ..И что сказал? — Нецензурную брань, ошибки и случайный капс пропустить? — Да. — [' ']. |
Именно поэтому процесс очищения данных — ужасно важная штука. Без хороших токенизаторов, нормализаторов и спеллчекеров, мы будем терять качество результата ещё до начала мало-мальски интересной обработки данных. Спеллчекером называют программу, которая принимает на вход слово (или сразу текст) и ставит ему в соответствие наиболее близкое правильное слово (или, опять-таки, целый правильный текст). Так, спеллчекеры должны бы исправлять орфографию и опечатки.
При очищении текстов, конечно же, хочется обойтись без потерь данных. А с этим есть, может быть, основная загвоздка. При применении спеллчекеров всегда есть риск лишиться специфических слов. Обычно проблемы возникают при анализе текстов, содержащих:
Ø жаргон, сленг, просторечия;
Ø редкие имена и фамилии;
Ø названия и наименования (особенно на фоне постоянного обновления языка);
Ø аббревиатуры и термины, редко (или не) употребляемые вне области.
Именно такие слова обычно включают в себя значительную часть смысловой нагрузки текстов. Фактически, при использовании некачественного спеллчекера мы обрекаем выборку на потенциальную смысловую ущербность: алгоритмы разберутся и поправят наши правильные слова на свои, ещё более правильные. Можно попытаться засунуть в алгоритм вообще все существующие слова, но это чревато ошибками вроде «Барье» → «барье» как название географического объекта (Люблянское барье, болотный массив в Словении), вместо «Дарье» как дательный падеж распространённого женского имени. Такие ошибки не сделают данные лучше.
Исходя из этих соображений, я провела небольшое исследование альтернатив для исправления ошибок. Мне требовалось выяснить их потенциал для построения на их основе качественного дополняемого алгоритма, и сейчас я хочу поделиться результатами. При анализе подходов к решению данной задачи я в первую очередь рассматривала известные мне и применяемые в задаче проверки написания библиотеки языка Python:
Ø Textblob
Ø Pyenchant
Ø Jamspell
Собственно, сами по себе алгоритмы исправления ошибок с использованием данных библиотек не представляют из себя ничего особенно интересного. С использованием Jamspell, например, код такого алгоритма сведётся к следующему.
import jamspell
g_corrector = jamspell.TSpellCorrector()
g_corrector.LoadLangModel('ru_small.bin') # файл с моделью
def clear_text(text):
return g_corrector.FixFragment(text)И на вход ему можно подавать целый текст. При применении Pyenchant и Textblob, видимо, предполагается подавать данные по одному слову. По крайней мере, я так и делала. К тому же я поместила туда функцию solver, которая принимает список из предположений модели (для одного слова) и выбирает из них наиболее похожее на правду, используя модуль для нечётких сравнений строк rapidfuzz. Вообще-то у rapidfuzz есть некоторые возможности для ускорения, но в моей конфигурации кода (с пословной передачей слов) я не придумала, как их эффективно задействовать. Из-за этого применение solver очень замедляло процесс обработки, и к тому же, как мне показалось, не давало значимого прироста в качестве — модули и так проводят подобный анализ, и первое из предположений обычно самое близкое. В итоге я отказалась от использования solver , но в коде оставила, чтобы поэкспериментировать с этим можно было потом.
Код для Textblob выглядел следующим образом.
from textblob.en import Spelling
from rapidfuzz import fuzz
spelling = Spelling('/home/iris/Repos/venviroments/orphograpy_reasearch/data/dicts/freq_dict/plain_dict.txt')
def __solver(word, suggestions):
qualities = [fuzz.ratio(word, s) for s in suggestions]
if len(qualities) > 0:
return suggestions[qualities.index(max(qualities))][0]
return word
def clear_word(word, use_solver=True):
suggestions = spelling.suggest(word)
if suggestions.count(word) > 0:
return word
if use_solver:
return __solver(word, suggestions)
else:
return suggestions[0][0]
Код алгоритма для проверки работы Pyenchant у меня был такой.
from rapidfuzz import fuzz
import enchant
g_dictionary = enchant.Dict("ru_RU")
def __solver(word, suggestions):
qualities = [fuzz.ratio(word, s) for s in suggestions]
if len(qualities) > 0:
return suggestions[qualities.index(max(qualities))]
return word
def clear_word(word, use_solver=True):
if not g_dictionary.check(word):
suggestions = g_dictionary.suggest(word)
if use_solver:
return __solver(word, suggestions)
elif len(suggestions) > 0:
return suggestions[0]
return wordЗдесь сразу отмечу возможные улучшения алгоритмов. Во-первых, для Textblob можно написать алгоритм, который будет исправлять целый текст — его тогда надо передавать в качестве параметра при инициализации переменной textblob. Однако в дальнейшем мной выполнялись тесты, связанные с исправлением одного слова за раз и представленные выше алгоритмы были вполне достаточны. Также отмечу, что при использовании solver вместо fuzz.ratio() в методе решения можно выбрать другую метрику близости или расстояния, а можно даже написать свою реализацию метрики, которая будет учитывать схожесть отдельных букв в конкретной задаче. Скажем, при распознавании текста с изображений случайная замена Б→Ь гораздо более вероятна, чем, например, Б→П или Б→Ж, так что у меня имеется гипотеза о том, что если назначить им сообразный вес при вычислении метрики, то можно ожидать прироста качества в некоторых случаях, но в эти детали я не стала углубляться.
Гораздо интереснее было оценить качество существующих алгоритмов на каких-нибудь сложных данных. Для примера у меня были датасеты имён и фамилий на русском языке. Эти данные выглядят примерно так.
ID |
Surnames |
PeoplesCount |
… |
… |
… |
100093 |
Иванковский |
176 |
100094 |
Иванник |
247 |
100095 |
Иванников |
9000 |
100096 |
Иванникова |
11000 |
100097 |
Иванничкин |
0 |
100098 |
Иванничкина |
0 |
100099 |
Иваннов |
195 |
100100 |
Иваннова |
118 |
100101 |
Иванов |
562000 |
100102 |
Иванова |
689000 |
… |
… |
… |
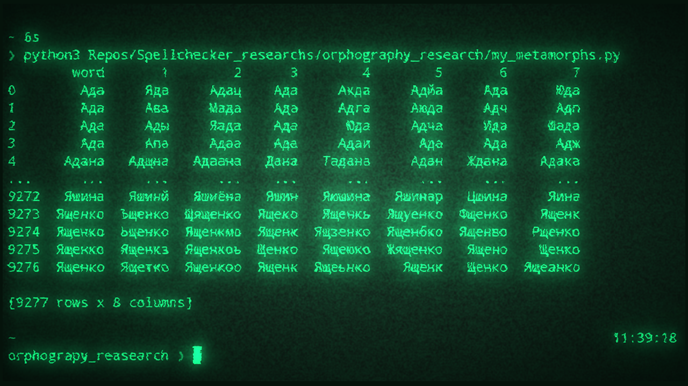
Здесь в колонке PeoplesCount указано количество людей с соответствующим именем или фамилией. Мне неизвестно, как были получены эти данные, но я решила использовать их для отсеивания редких имён из выборки. На основе этих данных с помощью следующего кода построила что-то типа тестовой выборки — в имена вносится контролируемое количество ошибок трёх типов: 1) замена случайной буквы на другую; 2) вставка буквы в случайное место; 3) удаление случайной буквы из имени, если только оно не короче пяти символов.
import random
import os
import pandas as pd
letters = 'ёйцукенгшщзхъфывапролджэячсмитьбю'
def commit_metamorph(word, k): # функция для искажения буквы
ind = random.randint(0, len(word))
letter = letters[min(random.randint(0, len(letters)), len(letters) - 1)]
# k - тип искажения
# 0 -> изменение, 1 -> вставка, 2 -> удаление
if k == 0:
return word[:min(ind, len(word)-1)] + letter + word[ind+1:]
if k == 1:
return word[:ind] + letter + word[ind:]
if k == 2:
if len(word) < 5:
return word
return word[:min(ind, len(word)-1)] + word[ind+1:]
def generate_spoiled_data(df_data,
morph_list,
max_one_name=5,
num_substitution=1):
if 'word' not in df_data.columns:
print('No words in dataframe')
return None
true_names = df_data['word'].tolist()
true_names_labels = []
num_sets = len(morph_list)
all_spoiled_names = []
for i in range(num_sets):
all_spoiled_names.append([])
for name in true_names:
name = name.lower()
num_for_name = random.randint(0, max(max_one_name, 0))
for i in range(num_for_name):
true_names_labels.append(name.capitalize())
for k_set in morph_list:
spoiled_name = name
for j in range(max(num_substitution, 1)):
ind = random.randint(0, len(k_set)-1)
k = k_set[ind]
spoiled_name = commit_metamorph(spoiled_name, k)
all_spoiled_names[morph_list.index(k_set)].append(spoiled_name.capitalize())
df_test_data = pd.DataFrame({'word': true_names_labels})
for i in range(num_sets):
df_test_data[i+1] = all_spoiled_names[i]
return df_test_data
Хотя вообще-то проверять орфографию в фамилиях выглядит затеей, заранее обречённой на полный провал. Дело в том, что многие фамилии (ещё когда самый эффективный спеллчекер был учителем русского языка и литературы) писались чёрт-те как. Многочисленные ошибки в паспортах породили на свет великое множество самых разнообразных фамилий, и на текстуальном уровне невозможно определить, когда эта ошибка старая и нужная, а когда — свежая, и надо её убрать.
Но для анализа модулей далее нужно было подготовить алгоритмы для них. Их код уже был выше, однако к нему нужно добавить подключаемые русскоязычные модели. Для тестирования Jamspell была взята минимальная модель анализа русского языка, предлагаемая разработчиками модуля с настоятельной рекомендацией обучить свою (модель можно найти тут https://github.com/bakwc/JamSpell по ссылке на ru.tar.gz в конце README.md).
Тестирование Pyenchant проводилось с подключением Hunspell-словаря, собранного и постоянно пополняемого экспертами. Эта модель не специфицирована под имена и фамилии, и в ней отсутствует буква «ё», зато она находится в открытом доступе (ссылка https://code.google.com/archive/p/hunspell-ru/).
Для проверки Textblob искала готовые модули и решения для русского языка, однако ничего подобного не было. В итоге сымитировала обучение на корпусе, подобное тому, которое можно найти здесь https://stackabuse.com/spelling-correction-in-python-with-textblob/. Правда, надо оговорить, что там оно всё-таки на английском и может использовать сведения об английском языке, поставляемые вместе с библиотекой в файлах en-morphology.txt, en-context.txt и т.д., хотя мне и неизвестно, используются ли они на самом деле при работе спеллчекера. Итак, для имитации я взяла частотный словарь русского языка, собранный экспертами в 2011 году на основании НКРЯ (ссылка http://dict.ruslang.ru/freq.php), и выбрала оттуда в новый файл только леммы и количество слов в корпусе, и только для слов, которые не содержали пробелы и дефисы («административно-правовой»), а кроме того собрала количества слов, встречающихся по нескольку раз в одном написании: это были слова, размеченные на разные части речи («а» как союз и «а» как междометие). В итоге, теоретически, должен был получиться файл, содержащий примерно то, что получилось бы, если бы алгоритм прошёлся по корпусу, как это было сделано в упомянутой в начале абзаца статье.
Код всей этой прелести я разместила на github, в репозитории https://github.com/IrizGem/Spellchecker_researchs, в папке orphography_research.
Важно отметить: ни одна из моделей не готовилась на тестовых данных, и даже не была специально обучена на фамилиях. Полученное качество — это результаты моделей «из коробки».
Для проведения испытаний были сгенерированы три выборки: с чистыми добавлениями, заменами и удалениями соответственно — а также четвёртая выборка со случайными изменениями всех трёх типов. Кроме того, алгоритмы запускались на чистых данных, чтобы посмотреть их в работе, так сказать, без шума и оценить их собственное искажение. Алгоритмы тестировались последовательно на одних и тех же данных, так что зависимость результатов от разницы случайных выборок снижена (но всё ещё присутствует, так как от выборки к выборке может меняться количество простых и сложных имён для каждой из моделей, оценить которое довольно сложно).
Первый прогон всех трёх моделей был на 4187 образцах, сгенерированных с двумя изменениями, проводился последовательнои занял порядка 80 минут. Из них алгоритм на Jamspell работал 41 секунду, алгоритм Pyenchant — около 24 минут, а Textblob — оставшиеся 55. На скриншоте ниже показан итог для трёх алгоритмов. Были получены метрики качества по каждой выборке (только изменения, только вставки, только удаления, смеси из всех трёх типов и чистые данные).

Второй прогон производился аналогично первому, но на выборке из 4183 образцов всего с одним изменением (что, пожалуй, ближе к возможным реальным данным), и длился примерно столько же, за исключением того, что Jamspell, по неизвестной причине, отработал выборку за 5 секунд (что выглядит подозрительно быстро, ведь выборка практически та же), а на отработке Textblob расчёты приостанавливались на ночь, и число прогресс-бара получилось более 15 часов, хотя по факту считалось оно, как и в первый раз, где-то около часа.
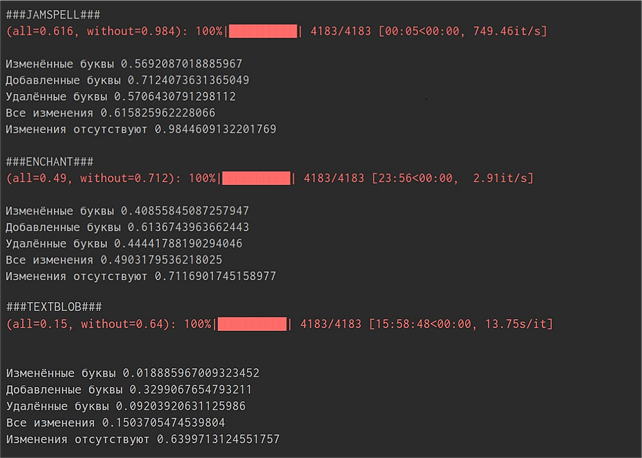
Интерпретируя результаты испытаний, можно сказать следующее.
1. Касательно быстродействия. Алгоритм Pyenchant работает быстрее алгоритма Textblob примерно в два раза. Но при сравнении с алгоритмом Jamspell, они оба выглядят совершенно неконкурентно по скорости. Собственно, кажется, где-то в репозитории Jamspell было сравнение скоростей с другими алгоритмами (в том числе с Hunspell), из которого следует то же самое.
2. Относительно качества для разных ошибок. Все три модели имеют заметный прирост качества на выборке с чистыми вставками, а на выборках с изменениями и удалениями их качество несколько ниже — где-то на 20-25%. Это может быть связано с тем, что только при добавлении правильные буквы остаются в слове. Технически, задача подобрать букву для имени или фамилии и должна быть сложнее. Допустим, существуют фамилии «СтирижнЯков» и «СтрижнИков», приходит слово «СтрижнХков», и ничто не подсказывает, какой из двух вариантов предпочтительнее, в то время как с добавлением буквы нужная буква в слове бы осталась, и выбор был бы обусловлен ею.
3. Проверка собственных искажений. Модели запускались на чистых данных, чтобы оценить количество экземпляров выборки, которые в моделях гарантированно отсутствуют. Если чистая фамилия алгоритмом была модифицирована, то значит она ему неизвестна — он заменил её на другое, близкое по написанию, слово. Притом если чистая фамилия алгоритмом модифицирована не была, то это ещё не значит, что она известна: она просто не была исправлена. Процент собственных искажений будет равен 100% минус процент правильно распознанных чистых слов (пятое число на скриншоте). Фактически, в процент правильно распознанных чистых слов входят известные фамилии и неизвестные фамилии, для которых в модели нет критически похожих слов (и поэтому они не были исправлены моделью), а в процент собственного искажения — неизвестные фамилии, для которых есть критически похожие слова. Иными словами, это данные, которыми мы гарантированно можем обогатить модель (но не все такие данные).
4. Textblob. Алгоритм Textblob хуже всего справился с испытаниями: результат на смешанных типах ошибок для 2-х изменений равен 7.5%, для 1-ого изменения — где-то 15%. Из правильных фамилий (чистые данные) она не искажает где-то 65%, то есть примерно 35% процентов всей выборки гарантированно неизвестно модели. Ещё, по видимости, он существенно хуже справляется со случаем изменения буквы, 0.4% для 2-х случаев и 0.18% для 1‑го, при том удаление имеет 10% и 9% соответственно. Кстати, отчего-то эти результаты не повысились, а даже немного упали на эксперименте с 1-ой правкой вместо 2-х. Вообще из результата алгоритма можно заключить, что либо моя имитация обучения не сработала, и для использования Textblob необходимо на самом деле обучать модель на корпусе (если там результат будет лучше, то она действительно хранит какие-то дополнительные данные), либо перенос качества Textblob с английского на другой язык стоит выполнять ещё более внимательно, прикладывая туда файлы морфологии языка и т.д. (тогда её использование с русским языком будет затруднено).
5. Jamspell. Алгоритм Jamspell показал наибольшее качество на тестовых данных. Точность на смешанных типах ошибок для 2-х правок 33%, для 1-ой — 61,5%. Процент собственных искажений модели держится на уровне 1,5%. С одной стороны, это можно интерпретировать как хороший признак: возможно, модель настолько хорошо понимает язык, что не исправляет даже странные и не встречавшиеся ранее фамилии. С другой стороны, можно из такого маленького процента сделать вывод, что у нас не такой большой запас улучшения качества, и, возможно, мы близки к пределу модели. Но вообще-то, суммируя всё, что мы знаем о модели, надо вспомнить, что это минимальная модель, которую разработчик настоятельно советует использовать только для первичных тестирований. Итак, скорее всего, модель в принципе не очень-то много слов знает, а такое низкое собственное искажение отражает лишь способность модели не исправлять то, что выглядит совершенно непонятно. Тем не менее, сочетание такого низкого собственного искажения с 60% верных предположений на смешанной выборке выглядят довольно вдохновляюще для дальнейшей работы с данной библиотекой. И, кстати, это без использования контекста, то есть Jamspell ещё дал остальным немного форы.
6. Pyenchant. В свою очередь, алгоритм на Pyenchant справился немного хуже алгоритма на Jamspell, однако есть смысл их сравнивать. Качество на смешанной выборке: 27% для 2-х правок и 49% для 1-ой. Почти по всем результатам они отличаются с Jamspell где-то на 10-15% с отставанием Pyenchant. При этом собственное искажение этой модели было на уровне 29% — то есть где-то такой процент фамилий можно гарантированно добавить в Hunspell-словарь, который используется моделью. Такой процент собственного искажения вызван ещё и тем, что во взятом нами словаре довольно много редких слов, в том числе таких, которые похожи на имена или фамилии из тестовых данных.
7. Возможности дообучения. Чтобы улучшить алгоритм с Textblob, нужен хороший корпус, время и много разбираться с переносимостью качества библиотеки с английского на русский язык (и пока у меня нет фактических свидетельств, что оно вообще переносимо). Чтобы улучшить алгоритм с Jamspell, нужен просто хороший корпус и время. Но для сохранения качества подобных алгоритмов нужно будет с определённой периодичностью дообучать модель, пополняя корпус новыми текстами. На этом фоне особенно интересно, что «дообучить» Pyenchant можно фактически вручную. Pyenchant, а точнее Hunspell в его начинке, очень простой и прозрачный инструмент. Чтобы внести новые слова в модель нужно добавить их в .dic файл, и единственная сложность тут — корректно определить префиксы, что вполне реализуемо. Таким образом, можно добавлять и аббревиатуры, и термины, используя лишь знания эксперта области, а не поддерживая целый корпус.
Итак, по итогу этого небольшого исследования я выяснила некоторые перспективы для создания хорошего спеллчекера для русскоязычных текстов на Python. Из трёх я выделила для себя два возможных пути: дообучать Jamspell или дополнять Hunspell-словарь.
«Из коробки» лучше себя показывает Jamspell, и работа с ним предполагает сбор корпуса, но, к тому же, у него есть дополнительные технические трудности, поскольку для оптимизации ресурсов Jamspell написан на C++ и задействует swig (пакет для использования C++-штук из модулей на других языках, в том числе на Python). Естественно, можно этих сложностей избежать, и найти другую похожую библиотеку с похожим быстродействием и качеством или найти способ установить требуемый пакет на корпоративный компьютер, но, тем не менее, эта проблема пока не решена.
С другой стороны, можно собрать специализированный словарь, включающий всю необходимую терминологию. Для этого нужно анализировать тексты, разговаривать с экспертами, собирать сложную для существующего словаря лексику (тоже на текстах, но всё-таки может хватить меньшего количества, чем для целого корпуса).
Ну, а про хороший спеллчекер без заморочек я всё выяснила — такого, вероятно, просто не бывает.
Комментарии (13)

akakoychenko
17.10.2022 17:32+1Можно попытаться засунуть в алгоритм вообще все существующие слова, но это чревато ошибками вроде «Барье» → «барье» как название географического объекта (Люблянское барье, болотный массив в Словении), вместо «Дарье» как дательный падеж распространённого женского имени. Такие ошибки не сделают данные лучше.
Не согласен в корне. Весь подобный софт (который работает с произвольным человеческим текстом, включая умные клавиатуры, голосовые распознавалки, и поиск Гугл) работает через оценку вероятностей (причем, не имеет значения, это прописано явно в коде, или скрыто в недрах нейросети). И, в данном случае, такие алгоритмы сравнивают вероятности P(написано Барье, вместо Дарье)*P(речь в контексте идет о Дарье) и P(написано Барье, вместо барье)*P(речь в контексте идет о барье).
Подобным допущением вы, по сути, приравниваете P(речь в контексте идет о барье) к 0, забив хардкод. Что в этом хорошего, - да, работать будет быстрее, и памяти понадобится меньше, но мы хотим качество, а не, чтобы айтишников заменяло на артишоки?
теперь посмотрим вот это
>letter = letters[min(random.randint(0, len(letters)), len(letters) - 1)]тут, снова таки, взят какой-то сферический конь в вакууме, ведь, ошибки не происходят просто так, - они обусловлены способом ввода (qwerty, надиктовка, кнопочный телефон) и особенностью конкретного человека (все ли у него исправны клавишы, печатает одной рукой, или двумя, насколько грамотен). Все это влияет на распределения, и хороший спеллчекер должен именно там черпать информацию для того, чтобы оценить, например, P(написано Барье, вместо Дарье). Если метать ошибки от балды при помощи randint, то, фактически, мы этим даем преимущество плохому спеллчекеру, ибо он не будет снижать качество работы, пытаясь найти вероятности, исходя, например, из раскладки клавиатуры, или статистики ошибок
NewTechAudit Автор
18.10.2022 14:14Интересное замечание. Во-первых, не все алгоритмы анализа близости работают в стохастическом предположении - те же расстояние Левенштейна или алгоритм шинглов. Они отлично работают вне вероятностного подхода.
Анализ с контекстом - это принципиально другой путь, который труднее, и даёт определённые преимущества, однако в контексте рассматриваемой задачи - эти преимущества не особо помогают, а, наоборот могут помешать. Да, "барье" и "Дарье" вы отличите, но с контекстуальным подходом легко возможен следующий сценарий. Например, фамилии Барьев и Дарьев (никак не связанные, кроме похожести написания) встречаются в корпусе в разных контекстах, например Барьев встречается в контексте спорта, а Дарьев в контексте кульинарии и выпечки. Означает ли это, что все их однофамильцы поголовно (или, иначе - в строгом соответствии пропорции, которая отражена в выбранном корпусе) заняты исключительно соответствующей тематикой? Ну, нет. Сможем ли мы избежать этого эффекта "примагничивания тёзок и однофамильцев", пользуясь исключительно средствами контекстуальной вероятности? Без дополнительных телодвижений - очень вряд ли. Напомню, что контекст задачи в основном правописание фамилий.
Во-вторых, я не настаиваю на каком-то из подходов как на единственном. Фактически, я просто даю подспорье тем, кто ищет статистические данные для аналогичных задач. Jumspell, который я тестирую здесь, построен на работе с корпусом и контекстом, Pyenchant, который я также рассмаотриваю, работает на основе полностью прописанного экспертами словаря, без частот. Они интересны в применении к нетривиальной проблеме правки фамилий, которая на практике возникает довольно часто.
BTW, как-то раз мне попадался прекрасный сайт, на котором были представлены чьи-то результаты - просто англоязычный текст "Гордости и Предубеждения", к которому была применена контекстуальная замена. Всё не могу его найти, жалко - очень меня этот текст впечатлил в своё время. Там прямо с первых слов понимаешь, что у контекстуального представления о слове есть и свои минусы - "man" было заменено на "woman", "wife", кажется, на "bride" - и пословно всё выглядит ещё куда ни шло, но от прагматического смысла оригинальных строчек просто следа не остаётся.
Касательно внесения правок - да, я тестирую на рандомных правках - не то чтобы я как-то держу это в тайне. И я не обучаю эти алгоритмы на данной выборке (вот это действительно было бы вредно). Для начала мне интересно было получить эти результаты, на выборке, абстрагированной от механики ошибки. Чтобы специфицировать ошибку, нужно было бы выбрать конкретный характер текстов - рукописный сканируемый (это одни соответствия), вводимый голос (совсем другие), неаккуратная печать на клавиатуре (уже третьи) и т.д. Можно придумать, как прикрутить туда симуляцию более натуральной ошибки (и посмотреть, даст ли соединение классического расстояния Левенштейна и нечёткой матрицы соответствий букв что-то интересное по точности).
akakoychenko
18.10.2022 19:42Сможем ли мы избежать этого эффекта "примагничивания тёзок и однофамильцев", пользуясь исключительно средствами контекстуальной вероятности?
Тут интересная философская проблема. Действительно, тому меньшинству, которому не повезло быть в тени какого-то большего созвучного смысла, предначертано страдать. На эту тему есть старая история о том, как кто-то из великих писателей писал (племянник) после своей фамилии в начале творческого пути, а в конце, уже его дядя стыдливо уточнял (дядя).

nehrung
17.10.2022 23:49Раз уж речь зашла о спеллчекерах… Проясните мне, несведущему — а кто вообще отвечает за наполнение языковых баз данных того же Гугла (как наиболее влиятельной конторы)? Как эти базы пополняются и корректируются? К кому обращаться, заметив явную языковую ошибку, на которой спеллчекер настаивает?
Если непонятно, что я имею ввиду, привожу поясняющий пример: слово «флешка» Гугл считает правильным, а слово «флэшка» — ошибочным, тогда как по-моему, должно быть наоборот.
Если мне ответят, что Гугл советуется с русскими языковыми академиками — извините, не поверю, там явно кто-то попроще, да ещё этот кто-то хорошо прикрыт от обращений простого народа с улицы.NewTechAudit Автор
18.10.2022 15:02Не знаю, как это происходит в Гугл, но вообще-то почему бы им не пользоваться услугами российских специалистов русской лингвистики? Так же как логично было бы привлечь испанского лингвиста для формирования языковой модели испанского языка. Даже если нет, у них могут быть лингвисты русского языка другой национальности - у нас же существуют углубленные специалисты по английскому, китайскому или немецкому. Если у вас есть в этом потребность, наверное, можно обратиться в поддержку Гугл. Или поискать какие-нибудь конференции, где Гугл, может быть выступал - может быть, касательно русского языка - может быть, там были какие-нибудь адреса почтовых ящиков. Но вообще-то это всё - зыбкие предположения. Меня вполне устраивает и вариант "флешка")
nehrung
18.10.2022 21:36А вас не беспокоит то, что формируя свои языковые базы, Гугл (ну, не только он, MS тоже, а возможно, и кое-кто ещё) фактически влияет на формирование языка чужого языкового сообщества целиком?
Ведь не секрет, что на практике многие подтягивают свою нормативную грамотность, хромающую ещё со школы, именно через пользование спеллчекерами. И если там в базах изначально присутствуют ошибки, то со временем эти ошибки в сознании людей устаканиваются, приобретают статус нормы. И никакие академические словари с их мизерными тиражами этого перебороть не смогут, потому что спеллчекер — это повседневность.
Так что меня удивляет ваше легковесное отношение к тому, что норма русского языка формируется не в русском обществе. Сразу скажу, политика тут ни причём, и если бы у меня была возможность влиять на гугловские языковые базы данных, я бы так не беспокоился.
IrizGem
19.10.2022 15:23Язык формируют люди, которые его используют: в том числе - и в первую очередь - читают на нём и пишут. Причём не просто пишут, но формируют литературу - книги, журналы, научные статьи. Когда человек корябает в социальной сети что-то полуправильное - это всё равно не литературная речь, по сути, а свободный разговор в письменной форме. Как на заборе.
Не представляю себе ситуации, в которой какой-нибудь писатель, рецензер, корректор - посмотрит в словарь Гугла или MS (или, ещё хуже - социальную сеть), чтобы скорректировать свои представления о правилах орфографии. То, что сервис "Google.Documents" не воспринимает букву "ё", никогда не было и не станет (для меня, во всяком случае) причиной заменять при письме букву "ё" на "е". Точно так же, между прочим, как игнорирование буквы "ё" в российском учебнике по русскому языку не было причиной писать иначе. Моя фамилия, которой обычно не бывает в словарях, не меняется на что-то попроще, чтобы только Word перестал её подчёркивать красненьким.
Спеллчекер - это такой же сервис, как все остальные. Из речи ведь не пропадают слова только потому, что в словаре Гугла их нет. Потому что сервис делают для реальности, но ни в коем случае не наоборот. Норма языка формируется совершенно иначе - не через то, как большинство людей пишет или думает надо писать - а через то, что считается правильным у довольно узкого круга действительно образованных людей.
Если вам кажется, что базы Гугла недостаточно хороши - наверное, нам с вами имеет смысл изучать официальные словари, через них проверять написания слов, в которых мы затрудняемся. Но вообще-то вполне вероятно, что базы Гугла во многом опираются на те же самые словари.
LordDarklight
Интересная тема - но, всё-таки, мне кажется лучше делать основной спелчек в рантайм - т.е. во время основного набора текста программы - условно так же как это делается в офисных программах с обычным текстом. Так же и пополнять словари - в идеале они должны быть облачные
NewTechAudit Автор
Здравая мысль) так будет, конечно, гораздо-гораздо лучше - человек сможет видеть опечатку, и чаще её не допустит. Однако спелчек в рантайме, во-первых, штука не принудительная (если вы хотите получать выборку текстов для алгоритма, то вас могут не устроить опечатки, сделанные по приколу или потому что пофиг), а во-вторых, это всё-таки решение на уровне архитектуры, не всегда это можно реализовать. Когда мы имеем дело с выборкой, вытащенной со стороннего источника (а это, имхо, частый случай в практике обработки текстов) - условно, с сайта социальной сети - мы никак не прикрутим туда спелчекер в рантайм, если его там нет (ну, если только это не наша собственная соцсеть, но тогда это не сторонний источник).
LordDarklight
О какой выборке вы говорите. Я думал статья об исправлении ошибок в текстовых ресурсах, литералах и комментариях (ну может ещё в идентификаторах) внутри программного кода.
Если же речь идёт о переводе условно пользовательских текстов - то это совсем другой вопрос и другие решения.
Но всё равно, опечатки и ошибки куда проще анализировать и устранять в рантайм, чем автоматической обработкой готового результата, да ещё и без автора оного опуса.
Да, я не исключая, что обработка готовых текстов тоже важна - но её качество будет ниже. А настройка такой системы - куда сложнее и затратнее.
Просто я намедни тоже думал на подобную тему - но у меня задача другая - не исправление опечаток, а языковой перевод - с одной стороны те же ошибки и опечатки и уникальные термины и имена для перевода тоже большая проблема; с другой стороны - даже без них по сути у меня те же проблемы - анализ словоформы и поиск перевода по словарю по адаптированному слову (но у меня хуже - мне ещё и контекстный анализ делать нужно - но это уже другая проблема), а затем адаптация перевода к исходной словоформе.
И я как раз задумывался над тем, что в программных алгоритмах (вне самого программного кода) может быть внутри много специфической терминологии - в тех же комментариях могут быть просто алгоритмы, или их отдельные части. И всё это надо вычленять из обработки, и вообще там свою нюансы. А уж если говорить о литеральных строках - то там, в-первых, могут быть выражения программного кода (как нынче модно стало), или на крайняк какие-то идентификаторы, на которые ориентируется программный код; во-вторых, изменение текста в строке может нарушить всю работу программной обработки этой строки. Короче - проблем куча - вот и задумался я, как же это всё можно было бы порешать. Пока надумал только то - что нужно создавать специальные "словари" для описания исключений - где можно было бы их задавать (и нужен ещё удобный инструмент по их настройке, в т.ч. прям чтобы можно было в исходном коде настраивать даже), так же как нужен будет и специальный лог - куда алгоритм трансляции мог бы записывать выявленные условно сложные и не однозначные места - чтобы потом по ним настраивать исключения (с готовыми решениями). В общем тут есть над чем подумать. Увы, Вы пока эту тему никак не раскрыли - хотя проблемы у нас схожие
NewTechAudit Автор
"Качество обработки готовых текстов не так хорошо работает, как в рантайме, но иногда это всё чем мы располагаем. Иногда просто говорят — вот у нас там есть база за десять лет — и спеллчек, будет он вам нужен, в рантайм уже не поставить.
Вообще проблема интерпретации в комментариях и кодах — это интересная тема. Все вот эти тонкости анализа на низком уровне: стили написания переменных, специальные машинные и обычные человечьи комментарии, куски кода. Но мне она в основном приходила в голову во времена, когда у меня была активная переписка кусками кода в перемешку с текстом, либо когда была необходимость, собственно настроить, спеллчек в IDE — на практике,чтобы надо было решать, не встречалось. Вообще-то мне казалось, в PyCharm это как-то интересно работает... И как-то он игнорирует конструкции кода. Но это ж IDE, она видит весь проект, либы, вычленяет функции и так далее.
Собственно, и с фамилиями, мне кажется, самый интересный путь — их оттуда выковыривать NER-ом, примерно как вы говорите о вашей задаче и о вычленении кода из комментариев. И попытаться специальную понималку сделать, отдельную. Её, технически, можно дополнять с каких-нибудь баз, если таковые для задачи имеются. Можно попытаться строить предположения по датам в контексте, по каким-то таким факторам…
А с переводом и комментариями, кстати, наверное, совсем весело — комментарий-то может быть написан на двух языках пополам (притом один из них может существовать только в голове автора). Но, возможно, это не кейс для больших и качественных проектов, которые станут проверять орфографию автоматически.
Но вообще-то, да, проблем действительно куча. Будем думать) Когда возьмёмся за что-нибудь интересненькое — постараемся рассказать."
LordDarklight
Говоря о комментариях, наверное первую очередь имел в виду комментарии авто документирования (а там свои правила их написания есть; да на Python это литеральные строки, а не комментарии, но у меня C#) и TODO блоки. С остальными комментариями всё хуже - но перевести их тоже хоть как-то хотелось бы.
Ну а литеральные строки - так и есть - просто текст, всё бы ничего - вот только интерполированные строки всё портят (особенно учитывая, что там ещё и вложенная интерполяция может быть неограниченной глубины; ну и алгоритмы завязанные на содержимом строк, особенно когда в строке, условно, часть алгоритма или хотя бы какие-то идентификаторы содержатся - вот это да, проблема, наверное только через словарь исключений это решить можно.
К счастью, для меня этот перевод не являются ключевой задачей - пока хотя бы как-нибудь реализовать надо
IrizGem
Для неключевой задачи звучит очень серьёзно)
Очень любопытная задача у вас. Для чего же это требуется - по дороге - реализовать автоперевод? Есть какой-то вывод автокомментирования, и его хотелось бы иметь на другом языке?
Мне почему-то кажется, что если бы вот сделать какой-нибудь алгоритм, который бы смотрел на слово (токен) и определял, условно, исповедимы ли пути того, кто это написал (ну там, если это переменная, или конструкция, или вроде, то отбрасывать), то качество спелчека (и перевода, вероятно) возросло бы. В PyCharm - вроде как - они, хитрые черти, просто не проверяют слова, из 3-х букв и меньше. Но это тоже, на самом деле, не так качественно. Можно попробовать нейронку для этого сделать) Или какой-то ещё классификатор. Ну, и, вероятно, какой-нибудь специфицированный под такое токенизатор взять.