

Почти все мы пользуемся социальными сетями. А почему бы и не пользоваться? Они ведь предоставляют так много возможностей! Взять ту же сеть ВКонтакте: можно пообщаться с друзьями, поделиться с подписчиками фотографиями только что сделанного крабового салата, посмотреть видео с котом соседа, вырастить огурцы на виртуальной ферме в каком-нибудь приложении… Сказка! Ой, а кто это в друзья добавляется?
Часть 0. Немного введения в лор
Прежде чем приступить к основной части, необходимо дать определение терминам бот и социальная сеть.
В общем случае под социальной сетью понимают некую социальную структуру, включающую в себя субъектов (которыми могут быть люди или их группы) и связи между ними. В данной статье рассматриваются социальные сети, организованные на специальных платформах в сети Интернет.
Бот – это специальное программное обеспечение, которое симулирует реального пользователя. То есть если аккаунт управляется ПО, то его можно считать ботом. Еще различают случай, когда аккаунт управляется частично программой, частично человеком — такое явление некоторые называют киборгом.
Часть 1. Они не уже рядом, они давно рядом
Ну бот и бот. Что он может нам сделать? Разослать спам-сообщение с просьбой вступить в группу «Домашние животные города N»? Давайте обратимся к громким случаям из мировых новостей.
2014 год. Исламское государство (ИГИЛ, запрещенная в России организация) ведет пропаганду в Twitter под хэштегом #AllEyesinISIS. Расширить масштабы вещания помогают боты, которые генерируют до 20% всего контента.
2016 год. Боты в Twitter оказывают влияние на выборы в США. Около 19% твитов, относящихся к выборам, генерируются ботами.
2020 год. В Twitter распространяется ложная информация о коронавирусе. Боты распространяют до 30% всех ссылок на недостоверные источники информации.
Про распространение вредоносного контента и оказание влияния на наш разум понятно. Что-то еще? Да.
Тема персональных данных. В последнее время прогремело немало случаев массового слива чувствительной информации в общий доступ. Потерять свои данные можно буквально в любой ситуации: сходив в магазин за хлебом (утечка баз данных сети магазинов «ВкусВилл»), отправив посылку по почте (утечка данных клиентов “Почты России”), заболев коронавирусом (утечка личных данных москвичей, переболевших COVID-19). В социальных сетях тоже можно потерять свои персональные данные. Например, если Олег решит пропарсить профиль Васи без согласия последнего для последующей продажи полученной информации. Или не только Васи, а еще ста человек. А еще подобными пакостями может заниматься не один человек-Олег, а целый ботнет без перерывов на обед и на покурить.
Нельзя промолчать и о проблемах бизнеса. Социальные сети давно зарабатывают себе на жизнь рекламой. Только вот реклама, по-хорошему, должна отображаться нужному человеку в нужное время, а не аккаунту, управляемому программным обеспечением. Насколько существенна проблема ботов в данном случае?
2022 год. Илон Маск чуть не отказался от сделки по покупке Twitter. Причиной, по заявлениям, является отказ Twitter предоставлять данные о степени распространенности в социальной сети спам-ботов и фейковых аккаунтов (также присутствуют обвинения в том, что заявляемый уровень распространенности сильно занижен по сравнению с реальной ситуацией). Информация является критической с точки зрения оценки бизнес-потенциала платформы.
Часть 2. Как искать
Почему боты могут быть вредны — понятно. Теперь нужно понять, как их искать. Существует три основных способа это сделать:
Проанализировать структуру графа, описывающего социальную сеть. Долго и в современных реалиях неэффективно.
Использовать краудсорсинг. Как минимум придется столкнуться с проблемами конфиденциальности пользователей.
Использовать методы машинного обучения. Оптимальный вариант.
Здесь необходимо определить, что такое машинное обучение. Существует множество определений этого термина, но если не вдаваться в различные особенности и подробности, описать его можно следующим образом. Машинное обучение — класс методов ИИ, позволяющих обучить программу решать поставленную задачу без строгих инструкций.
То есть мы выдаем общий алгоритм, а уже модель с конкретными параметрами получается в процессе итеративного обучения на данных — подстраивания алгоритма под представленные ему примеры.
В зависимости от того, известно ли точно, как модель должна реагировать на конкретный вход, различают:
Обучение с учителем — когда каждому входному примеру сопоставлен необходимый вывод, и модель пытается настроить свою работу так, чтобы выдавать правильный результат как можно большему количеству примеров.
Обучение без учителя — когда к входным данным не предоставляется нужный вывод, и модель должна сама понять, что ей необходимо иметь на выходе.
Гибридное обучение — сочетает в себе обучение как с учителем, так и без него.
Часть 3. Это база
Обучение без учителя опасно тем, что никогда точно не знаешь, что модель будет выдавать на выходе. Поэтому, так как преследуется задача обнаружения именно ботов, для экспериментов лучше всего подойдет обучение с учителем.
С этим определились, пора приступать к работе. Что нужно для начала? Во-первых, собрать набор данных. Во-вторых, выбрать метод (или даже несколько) для исследований.
Набор данных
Есть два способа получить данные. Первый – собрать данные и разметить их самостоятельно, второй – получить уже готовый набор данных из Интернета. Для текущих исследований использовался первый способ, так как чего-то уже готового банально не было.
Данные о профиле собирались исключительно с личной страницы пользователя, естественно, если данные были открытыми При этом заключение о том, является ли аккаунт ботом, делалось исходя из его деятельности вне личной страницы: под статьями, на страницах других пользователей.
Некоторые триггеры, на основе которых делался вывод, что пользователь — бот:
Активность 24 часа в сутки;
Комментарии, слово в слово дублирующие комментарии других пользователей;
Комментарии не в тему (случаи, когда бот призван распространять определенную информацию, реагируя на какие-то конкретные слова, встречающиеся в комментируемом материале).
Для анализа было получено 600 персон. Не очень много, но некоторые выводы сделать можно.
Методы машинного обучения
Среди всего разнообразия методов, для которых возможно обучение с учителем, было решено использовать самые хайповые и в то же время показывающие лучшие результаты на других социальных сетях.
«Дерево решений». Для принятия решения используется специальная структура – дерево. Оно строится в процессе обучения и содержит в своих узлах, если не считать листьев, вопросы об экземплярах данных. В зависимости от того, какой ответ дается на вопрос в узле, данные направляются по той или иной ветви дерева вниз и в итоге приходят в определенный лист. В листьях находятся классы, которые присваиваются пришедшим туда экземплярам.
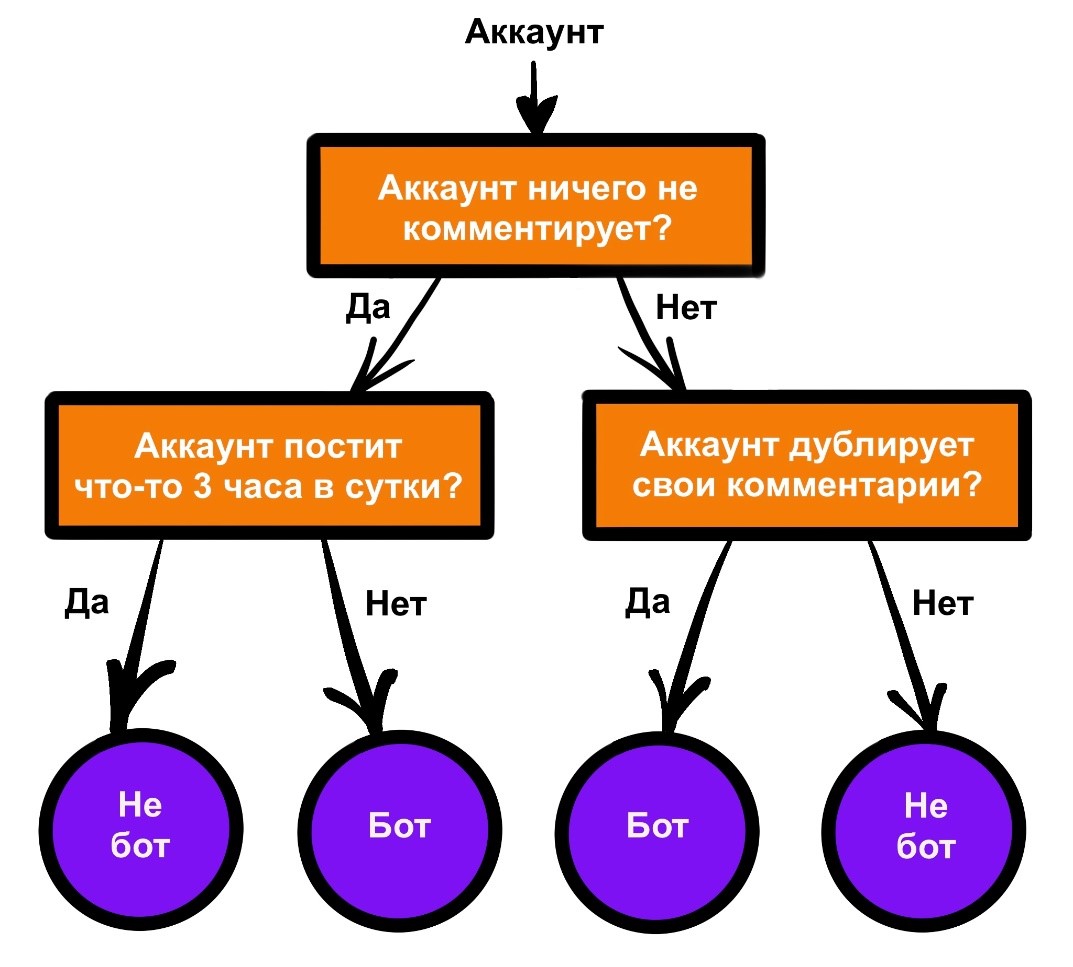
Однако одно дерево, обучающееся на всем датасете, плохо тем, что имеет свойство накапливать ошибки. И так можно сказать не только про дерево решений. Одним из способов избавиться от описанной проблемы является применение ансамблевых методов. Смысл их заключается в том, чтобы обучить несколько базовых алгоритмов решать поставленную задачу, и финальный ответ для каждого примера получать на основе объединения вердиктов этих моделей. Один из таких ансамблевых методов называется «Случайный лес», роль базовых алгоритмов в котором выполняют независимые друг от друга деревья решений.
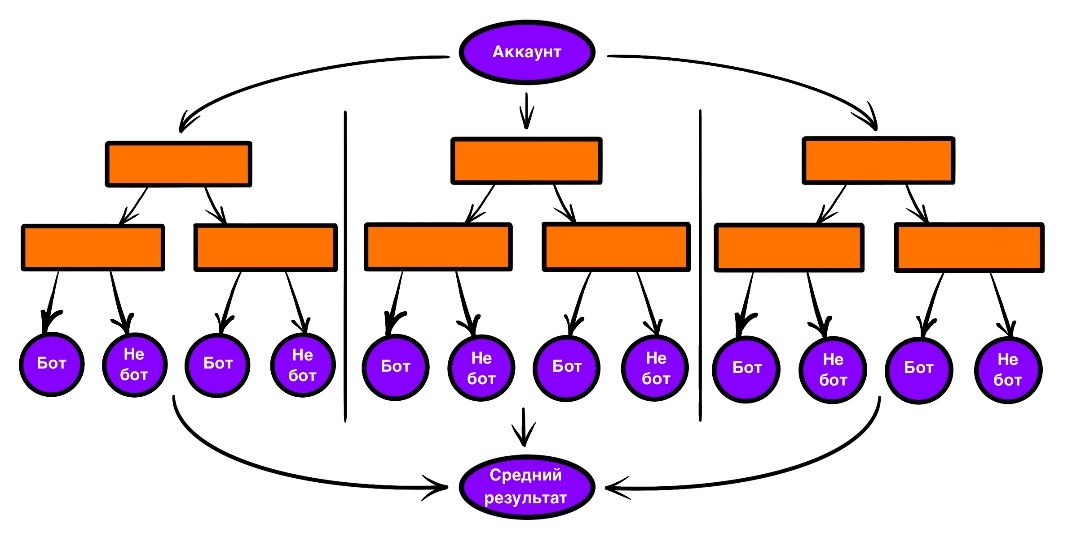
Еще один ансамблевый алгоритм – «Градиентный бустинг». Его особенность заключается, во-первых, в зависимости его учеников друг от друга — каждая новая модель обучается на основе результатов предыдущей, и, во-вторых, в использовании градиента в процессе обучения (почти как в нейросетях, получается).

Еще один применимый для решения нашей задачи алгоритм – искусственная нейронная сеть – набор нейронов, соединенных между собой определенным образом. Нейрон – математическая модель восприятия информации мозгом, состоящая из следующих частей:
Входы, представляющие собой числа, обычно с плавающей запятой;
Веса, на которые умножаются входы;
Сумматор результатов умножения весов на входы;
Смещение;
Функция активации – способ нормализации входных данных.
Нейронные сети бывают разными. Для исследований используются следующие:
Многослойный перцептрон. Та самая нейросеть, которую все представляют, когда слышат слово «нейросеть».

Рекуррентная нейронная сеть. Получила такое название, так как обрабатывает не каждый элемент в наборе обучающих данных по отдельности, а совокупность таких элементов. Например, это могут быть слова в предложении (работа с обработкой текстов — одно из основных направлений для рекуррентных сетей).

Сверточная нейронная сеть. Основная идея сверточных сетей заключается в том, что какая-то особенность объекта, переданного на вход, должна обнаружиться вне зависимости от того, в какой части объекта она находится (именно поэтому данные сети широко используются для работы с изображениями). Для реализации этой идеи используется операция свертки — поэлементное умножение фрагментов входной матрицы на ядро свертки, или по-другому матрицу весов, с последующим суммированием элементов внутри каждого фрагмента.
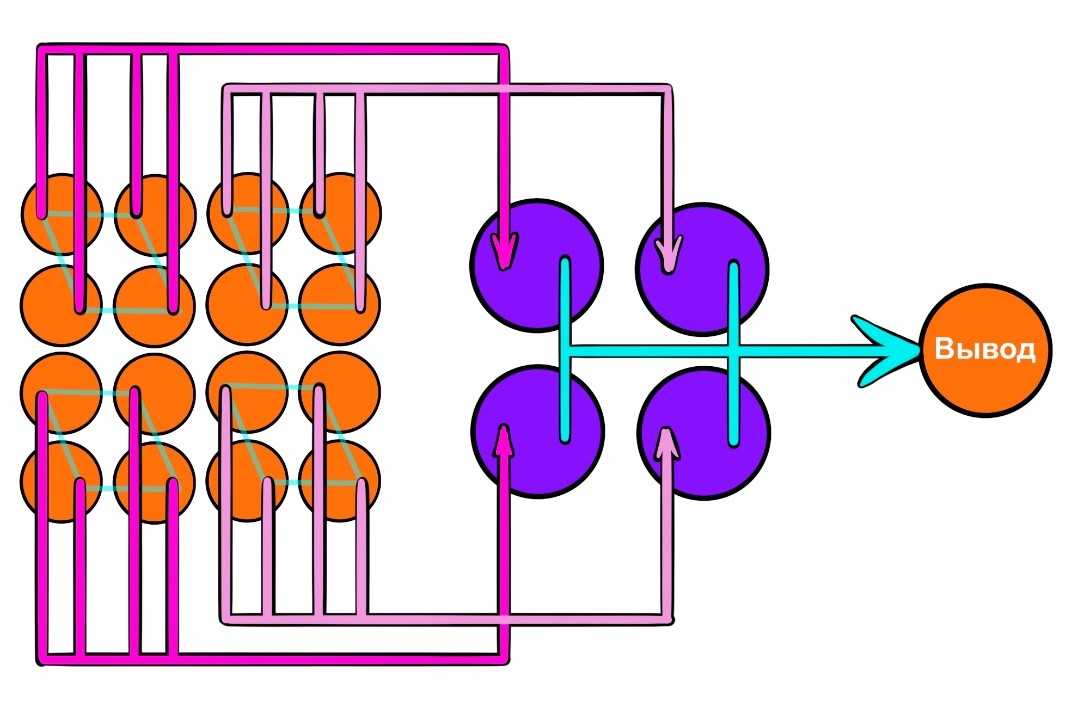
Часть 4. Получение признаков для моделей
Так много вариантов решить проблему... Но как передавать в модели профили пользователей?
Прежде всего необходимо осознать, что всякие модели работают с наборами векторов чисел. Да, они могут обрабатывать картинки, тексты, сайты и так далее, но все это, пусть и где-то внутри какого-нибудь продукта, преобразуется в векторы числовых значений, по-другому именуемые признаками. В нашем случае нет волшебной палочки для преобразования профилей пользователя в нужный вид, поэтому нужно делать все своими руками.
Стратегий получения признаков может быть множество – все зависит от фантазии исполнителя. Признаки, используемые в описанных далее в статье моделях, можно разделить на две группы:
Получаемые из статистики профиля (например, заполненность тех или иных полей, количество постов, отклонение по времени создания постов);
Получаемые из текстов (групп или постов).
Признаки, получаемые из статистики профиля
Профиль пользователя социальной сети обычно можно разделить на несколько зон. Это могут быть зоны с общей информацией, с фото или видео, с какими-то личными записями на странице.

Каждая из этих зон может что-то рассказать о пользователе. Однако мало просто рассказать, для моделей машинного обучения этот рассказ необходимо представить в читаемом виде. И что предлагаете делать с какими-нибудь фотографиями в данном случае? Давайте обратимся к конкретным объектам зон, которые обычно присутствуют в личных профилях пользователей, и подумаем, что из них все-таки можно вытащить полезного.
Общая информация о пользователе: можно получить данные о степени заполненности информации о профиле.
Зоны фото или видео:
можно определять, есть ли фотографии/видеозаписи, сколько их;
можно определять, присутствует ли на фотографиях/видеозаписях кто-то или что-то;
можно считать количество оценок (например, лайков) и комментариев под материалами;
можно анализировать текст оставленных под фото комментариев на наличие определенных слов или ссылок;
можно анализировать дату постинга материалов;
так как фото и видео – это чаще всего несколько объектов, для собранных о них данных можно считать различные статистические характеристики, например, арифметическое среднее, медиану или отклонение.
Зона групп или подписок:
можно определять, сколько групп или подписок у пользователя;
можно анализировать текст названий групп и подписок;
можно, опять-таки, считать различные статистические характеристики.
Зона аудио:
можно определять, сколько аудио у пользователя;
можно анализировать текст названий аудио, имен исполнителей;
можно анализировать предпочтения в музыке;
и опять, можно считать различные статистические характеристики.
Зона стены: обычно объединяет в себе возможности всех вышеперечисленных зон.
Конечно, это не все, что можно получить из исследуемого профиля, однако многое из этого использовалось для экспериментов.
Признаки, получаемые из текстов
Как уже было упомянуто, некоторые разработанные модели работают чисто на текстовых данных. И да, этот текст тоже как-то необходимо приводить в векторы чисел, которые называются эмбеддингами. Существуют различные способы это сделать. Часто в литературе упоминают следующие:
Каждое уникальное слово представить в виде уникального числа. А предложение – в виде вектора этих чисел. Минус такого подхода заключается в том, что полученное числовое значение вообще никак не отражает смысловую составляющую слова.
Использовать метод one-hot-encoding. Каждое уникальное слово представить в виде вектора, в котором все значения – нули, кроме одного, равного единице и находящегося по индексу, который отвечает за это слово. Данный способ интересен для целых текстов: можно просуммировать векторы слов и получить вектор текста. Для отдельных слов такой вариант не подходит: как и в случае ранее, новый вид не содержит в себе смысла слова, да еще и места много занимает.
-
Использовать схему TF-IDF. Эта схема применяется, когда на руках имеется набор разных текстов. Для каждого отдельного слова определенного текста составляется вектор – такой же, как в методе one-hot-encoding, только вместо единиц используются числа с плавающей точкой. Эти числа получаются умножением следующих значений:
частоты слова в пределах рассматриваемого документа;
обратной частоты появления документов, содержащих рассматриваемое слово.
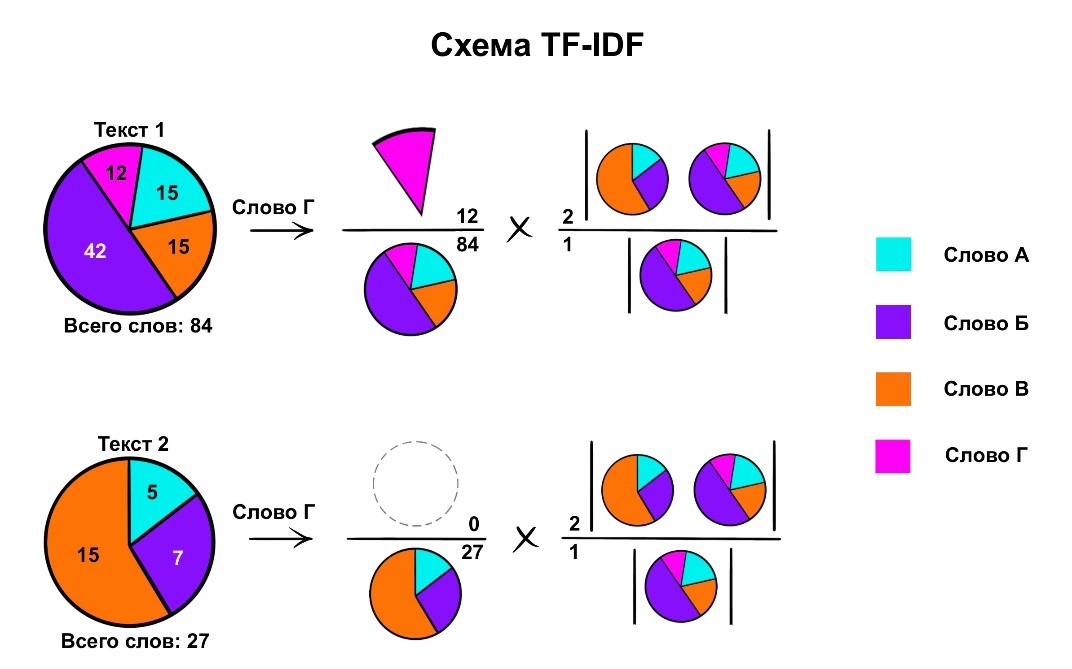
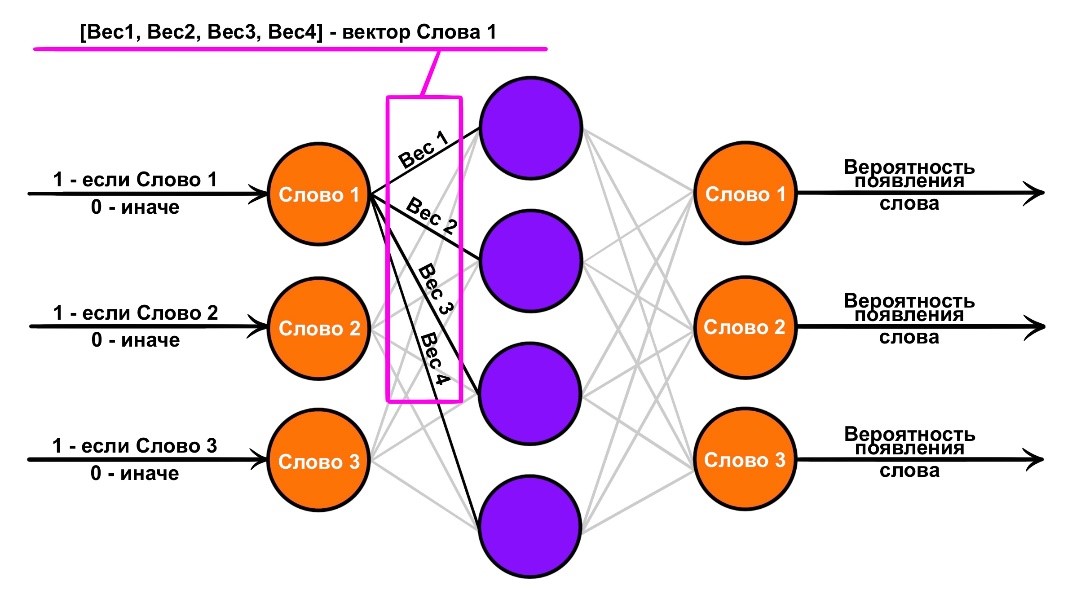
Каждый из перечисленных выше способов имеет свои достоинства и недостатки. Но можно придумать и лучше. И было придумано. Один из таких более продвинутых вариантов, использующийся в текущих экспериментах для моделей со сверточными сетями, –метод word2vec. Алгоритм получения векторов заключается в обучении многослойного перцептрона предсказывать для определенного слова вероятность появления в его окружении каждого слова из словаря, составленного на основе имеющихся на руках текстов.
Часть 5. Показ мод
Данные есть, методы машинного обучения есть – время накидывать алгоритмы и обучать модели. Алгоритмы получились следующими:
Просто дерево решений. Получаем признаки профилей (таких в наличии оказалось около 70-ти) и обучаем дерево решений.
Просто случайный лес. Та же ситуация, что и с просто деревом решений.
Модель на основе рекуррентной нейронной сети, обученной на текстах названий групп пользователей. В данном случае все уже не так просто. Сеть обучается давать каждому названию группы вывод (это группа бота или человека). Далее, когда есть готовая модель сети и необходимо понять, бот или нет определенный аккаунт, каждая из его групп прогоняется через сеть, получая свой вердикт — значение от 0 до 1, где 0 интерпретируется как «модель думает, что это точно человек», а 1 как «модель думает, что это точно бот». По полученному списку вердиктов берется медиана и сравнивается с заранее установленным порогом: если медианное значение встает слева от него, аккаунт причисляется к человеку, иначе к боту.
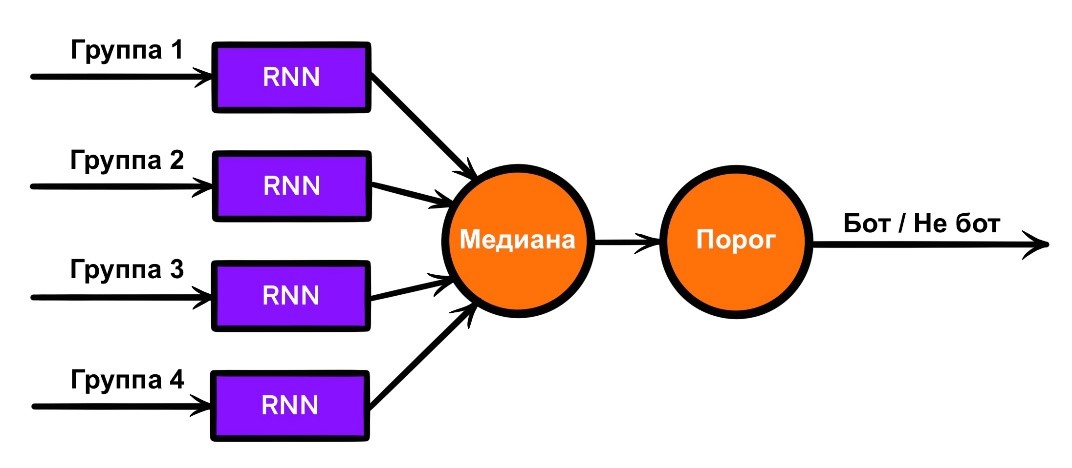
Модель на основе рекуррентной нейронной сети, обученной на текстах пользователей. В принципе, все так же, как и с прошлым пунктом, за исключением того, что на вход сети подается какой-нибудь текст пользователя.
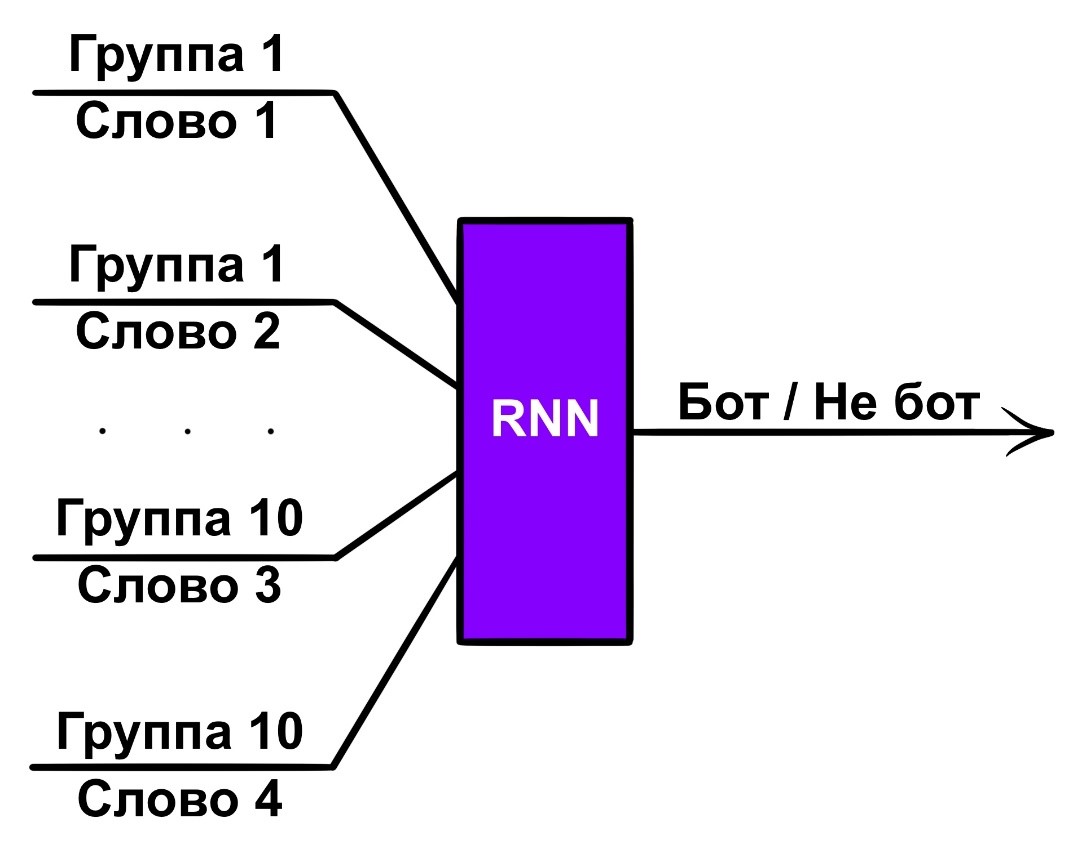
Рекуррентная нейронная сеть, обученная на текстах названий групп пользователей. В данном случае на вход сети подается не одно название, а сразу несколько, объединенных в одну строку. И результат, выдаваемый сетью для одной такой строки, является также итоговым результатом для самого аккаунта.
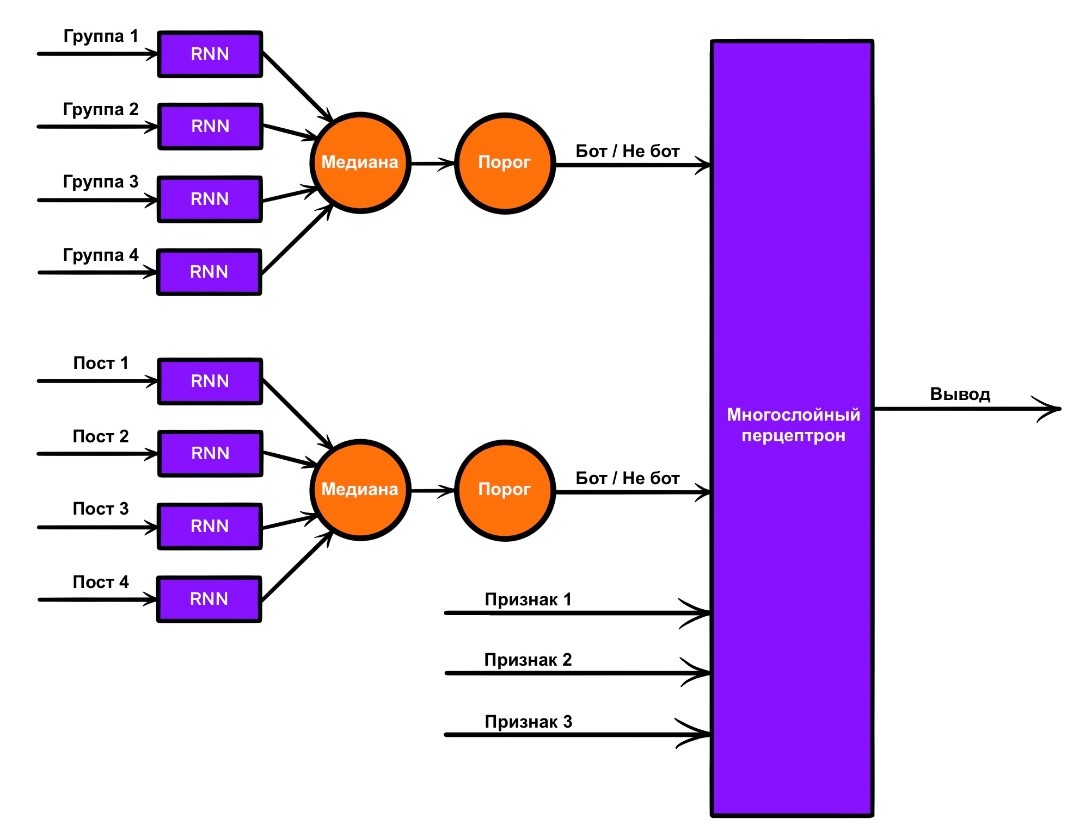
Просто многослойный перцептрон, обученный на тех же признаках, что и дерево решений, и случайный лес.
7. Многослойный перцептрон, в котором кроме упомянутых в пункте 6 признаков также учитываются результаты моделей из пунктов 3 и 4.
Сверточная нейронная сеть, принимающая на вход набор из названий групп пользователей.
Сверточная нейронная сеть, принимающая на вход набор из названий групп и текстов пользователей.
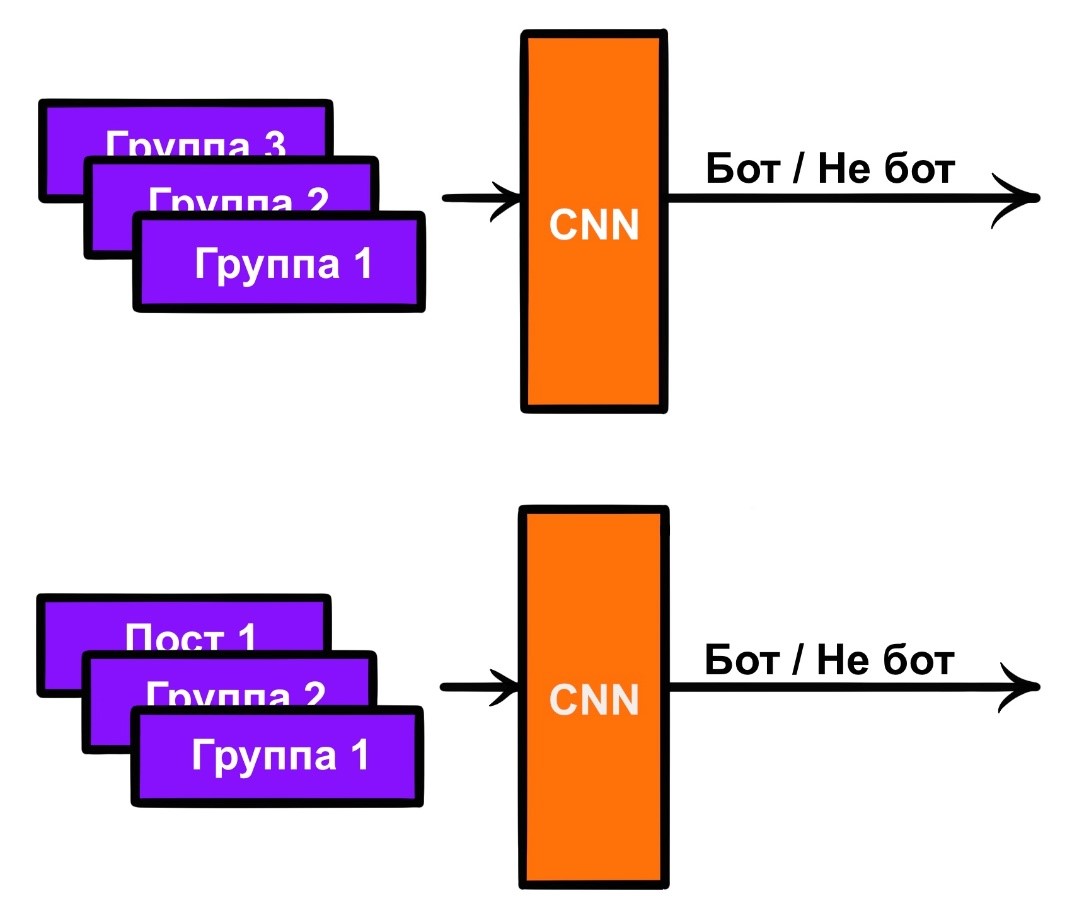
Просто модель на основе градиентного бустинга (использовался catboost). Признаки уже упомянуты в пункте 1.
Модель на основе градиентного бустинга и сверточной нейронной сети. В целом смысл тот же, что в пункте 10, только к уже упомянутым признакам добавляется дополнительный. Он формируется при помощи сверточной сети из пункта 8: через сеть прогоняется несколько наборов групп пользователя (сколько — зависит от количества этих групп, может получиться и так, что набор будет только один), для каждого формируется вывод. По массиву выводов берется среднее, сравнивается с порогом — получается предварительное предсказание, подающееся на вход модели градиентного бустинга.
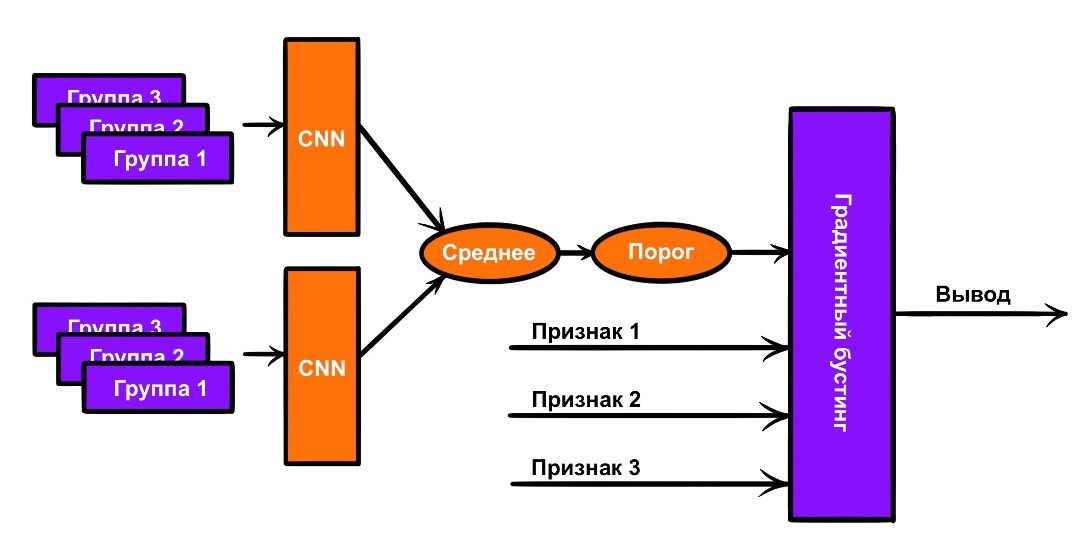
Модель на основе градиентного бустинга и сверточной нейронной сети, как и в пункте 11, только сверточная сеть берется из пункта 9.
Часть 6. Оценка результатов
Итак, модели обучены, можно оценивать результаты. Для оценки качества моделей использовались три метрики: полнота (recall), точность (precision), F-мера. Что это за названия и почему именно эти метрики?
Когда мы говорим об оценке работы какого-то классификатора, многим на ум приходит сразу же метрика. Получается она следующим образом: необходимо поделить количество правильно классифицированных объектов на общее количество объектов, переданных на вход модели. Проблема такого подхода заключается в том, что данная метрика дает информацию о работе модели сразу со всеми классами. То есть очень сложно сделать какие-то выводы о качестве работы с каким-то определенным классом.
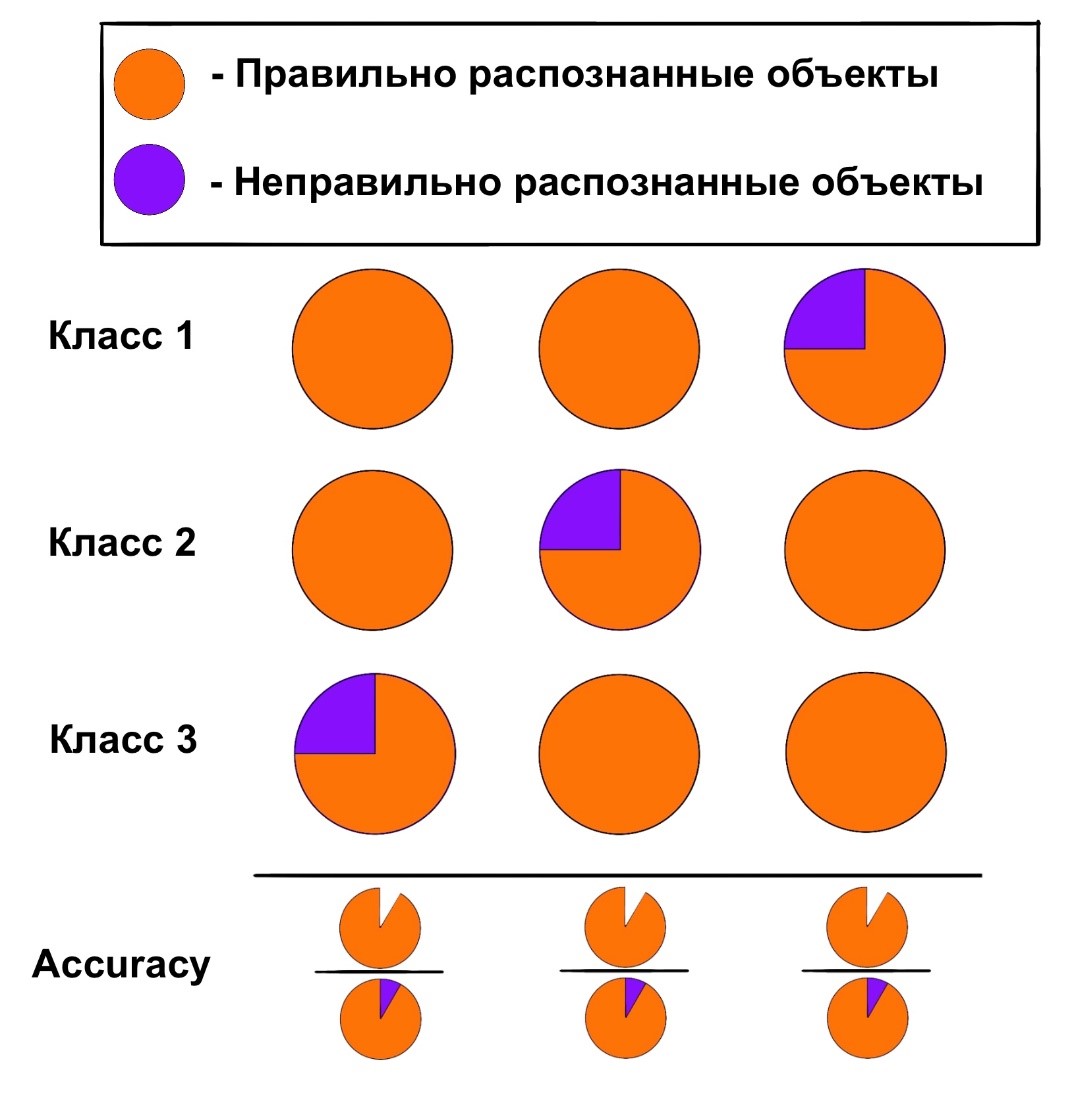
Кроме того, часто в наборах данных наблюдается диcбаланс классов: объектов одного класса больше, чем объектов другого (это, конечно, формулировка для бинарной классификации, но необходимо помнить, что многоклассовую классификацию можно рассматривать как бинарную со стороны каждого отдельно взятого класса). И получается, если модель очень хорошо работает с более объемным классом, но такого не наблюдается с противоположным классом, то Accuracy будет выдавать высокие показатели, что приведет к заблуждению о прекрасной работе модели.

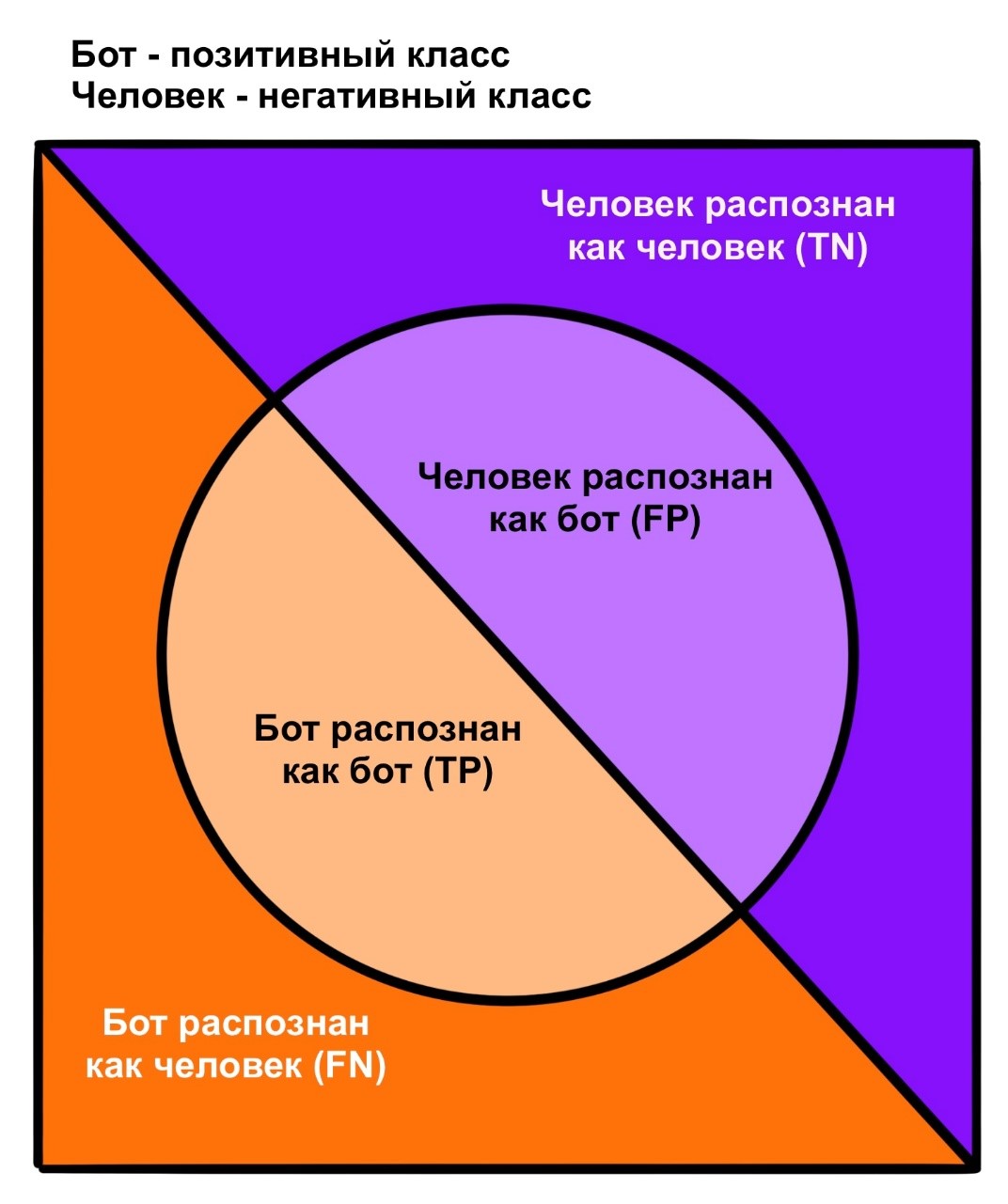
Напрашивается вывод: необходимо получать оценку для каждого отдельно взятого класса. Этим занимаются те самые полнота, точность и F-мера. Существуют, конечно, и другие метрики, но описанных часто достаточно. Для расчетов выбирается один интересующий класс и называется положительным (обозначается как 1). Остальные в совокупности принимают звание одного отрицательного класса (обозначается как 0). Далее каждый объект прогоняется через модель и получает вердикт. В зависимости от истинного класса (0 или 1) и предсказанного (0 или 1) тестовый набор делится на четыре группы:
Истинно-положительные (TP, True Positive). Истинный класс – 1, предсказанный класс: 1.
Истинно-отрицательные (TN, True Negative). Истинный класс – 0, предсказанный класс: 0.
Ложноположительные (FP, False Positive). Истинный класс – 0, предсказанный класс: 1. Ошибки первого рода.
Ложноотрицательные (FN, False Negative). Истинный класс – 1, предсказанный класс: 0. Ошибки второго рода.
Из количества объектов в этих группах вычисляются необходимые метрики:
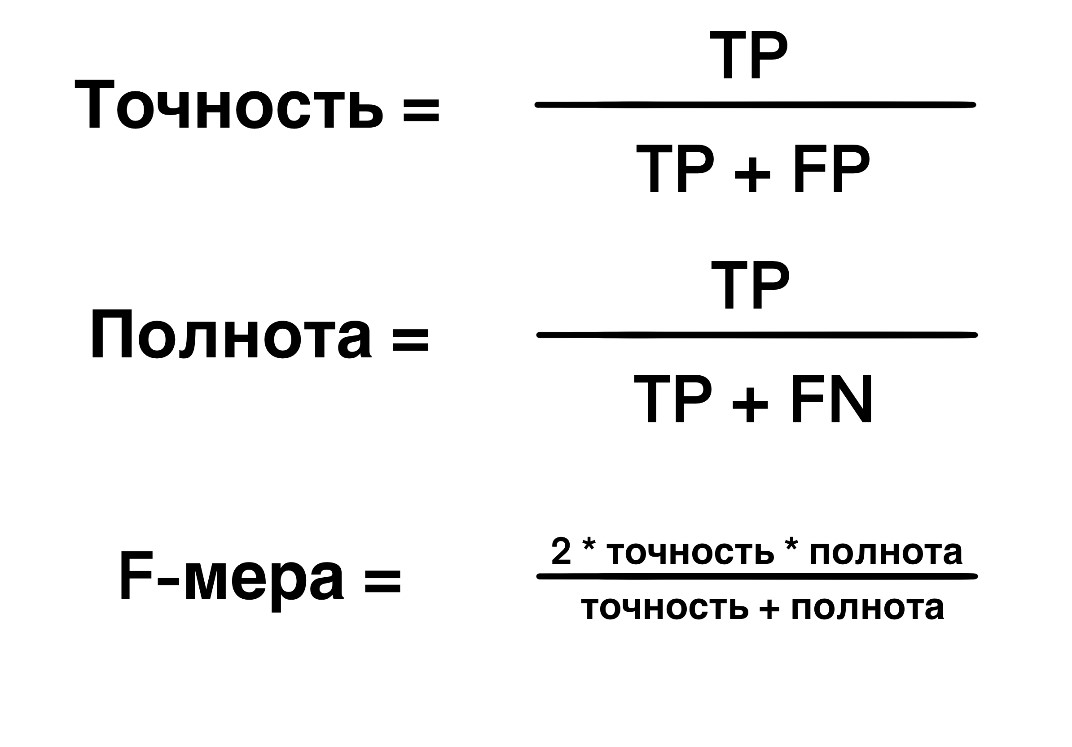
Как можно увидеть, точность учитывает ошибки первого рода, а полнота – ошибки второго рода. F-мера является гармоническим средним точности и полноты: высокие показатели этой метрики обеспечиваются только за счет высоких значений сразу обеих ее составляющих. Преимущества по сравнению с Accuracy очевидны.
Время переходить от теории непосредственно к результатам. Ниже представлена таблица с полученными значениями метрик на тестовом наборе данных.
Модель |
Точность |
Полнота |
F-мера |
1. Просто дерево решений |
0,755 |
0,925 |
0,831 |
2. Просто случайный лес |
0,886 |
0,975 |
0,928 |
3. Рекуррентная нейронная сеть + названия групп |
0,750 |
0,975 |
0,847 |
4. Рекуррентная нейронная сеть + тексты со стены |
0,540 |
0,825 |
0,653 |
5. Рекуррентная нейронная сеть + названия групп как один вход |
0,831 |
0,862 |
0,846 |
6. Просто многослойный перцептрон |
0,956 |
0,814 |
0,879 |
7. Многослойный перцептрон и Рекуррентные сети |
0,931 |
0,759 |
0,836 |
8. Сверточная нейронная сеть + названия групп |
0,852 |
0,838 |
0,844 |
9. Сверточная нейронная сеть + названия групп + тексты со стены |
0,922 |
0,787 |
0,849 |
10. Просто градиентный бустинг |
0,993 |
0,993 |
0,993 |
11. Градиентный бустинг и Сверточная нейронная сеть + названия групп |
1.000 |
1.000 |
1.000 |
12. Градиентный бустинг и Сверточная нейронная сеть + названия групп + тексты со стены |
1.000 |
1.000 |
1.000 |
Ну и визуализация, как же без нее: точность, полнота и F-мера в зависимости от номера модели.

Как видно, выделяется модель с рекуррентной нейронной сетью, работающей на текстах со стены пользователя – ее качество на порядок хуже остальных рассмотренных моделей. Как показали различные эксперименты, не отраженные в данной статье, по текстам со стены в принципе хорошее распознавание не получается. Также обращают на себя внимание модели с градиентным бустингом как почти идеальные в обнаружении ботов (в условиях текущего тестового набора данных). За ним стремится случайный лес. Это наводит на мысль, что ансамблевые методы могут иметь предрасположенность к решению обозначенной в данной статье задачи.
Часть 7. Итоги
Конечно, хоть и были получены довольно хорошие модели, нельзя вот прямо сейчас взять и сказать, что задача обнаружения ботов была решена. Тут и датасет не шибко большой, и полнота данных не особо радует (настройки приватности еще никуда не исчезли), и что-нибудь обязательно ещё. Тем не менее, в результате есть основания утверждать, что обнаружение ботов не является чем-то непреодолимым и что какую-то часть ботов находить все-таки точно можно.

Автор: Анна Яковленко, аналитик данных Центра продуктов Dozor "РТК-Солар"
Комментарии (4)

Paranoich
23.11.2022 16:31Кажется именно так и поступают крупнейшие соцсети. С миллионами ботов до сих пор существующих. Что-то новое, или вы пересказываете то что есть? Простите, если вопрос показался грубым или невежливым, но вы описали существующее, а в будущем что?
Мой знакомый, заведующей (админ, но сейчас админ — это часто слово ругательное*) соцсети обратился ко мне (примерно 50000 зарегистрированных пользователей, живых около 300, активных — голов 50) с похожей проблемой, я просто стал пробивать адрес зарегистрированного через гугль/яндекс, в результате чего 9 аккаунтов из 10 были снесены (ибо боты используют один и тот же или похожий адрес). Но то мелкая соцсеть и я мусор вычистил за пару дней.
Какой практический выход есть в дальнейшем?
Благодарю.Paranoich
23.11.2022 16:33+1«админ» Новый КРУТОЙ админ снова сдесь нажми и выиграй 1 беткойн лигедарный админ снова платит

KMartONLINE
24.11.2022 12:57+1Насчет мелких социальных сетей ничего не скажу, а в крупных, к которым, наверное, и есть претензия относительно "миллионов ботов", эти самые боты зачастую не блокируются по принципу "а что если это не бот" (этот прицип причем касается не только ботов, по наблюдениям, но и, к примеру, мошенников). Блокировка часто случается именно при наличии доказательств, что бот где-то нагрешил. И их большое количество в данном случае вообще не означает, что методы, существующие и использующиеся сейчас, не работают / плохо работают. Возможно, они просто работают незаметно для обычных пользователей, пока что :)
sunsexsurf
Отличное исследование. Не нашел в статье ссылку на гитхаб - иногда проще просто посмотреть код и графики. Спасибо за статью.