

Сложность вычислительных задач и систем растёт с каждым днём. Для бизнеса ускорение кода даже на пару процентов даёт улучшение производительности, заметное снижение издержек и уменьшение задержки(latency). В первую очередь это касается мобильных и встраиваемых систем, высоконагруженных серверов, научных вычислений и 3D-графики. Так был разработан относительно перспективный и молодой метод оптимизации — Profile-Guided Optimization, далее просто PGO-оптимизация. Данный метод эффективно используют такие известные компании, как Google, Mozilla Foundation, Intel, Oracle, IBM и другие. Практически ни один современный веб-браузер не обходится без PGO-оптимизации.
Не так давно компанией Google был предложен набор патчей, включающий PGO-оптимизацию в ядре Linux. Мною был протестирован этот набор патчей в работе и доработан. Мне хотелось бы рассказать об этом методе оптимизации ядра Linux, о том, с какими трудностями можно столкнуться, и как их решить.
Если вас заинтересовала эта тема, вам интересно развитие технологий и тренды крупных компаний, то добро пожаловать под кат.
Теория
При классической компиляции кода компилятор вынужден строить предположения об оптимальном методе оптимизации, а где-то вовсе отказаться от одного из методов, т. к. по простым подсчётам из теории сложностей оптимизация будет слишком трудоёмкая. При PGO-оптимизации сначала собирается реальная статистика об исполняемом коде, и далее эта статистика в обработанном виде передаётся компилятору. Теперь же при выборе метода оптимизации компилятор меньше полагается на предположения о коде, а руководствуется статисткой, что, в свою очередь, помогает оптимизировать некоторые участки кода более эффективно. Как можно понять, основным недостатком этого метода является двойная компиляция: сначала надо скомпилировать код, собрать статистику, и уже повторно скомпилировать код. Также недостатком является то, что для правильного сбора статистики надо использовать правильную нагрузку на реальных задачах. Если при сборе статистики будут в основном участвовать одни участки кода, а другие будут простаивать, то это негативно скажется на статистике, и приложение на практике может работать даже медленнее, чем до PGO-оптимизации. Поэтому правильному созданию нагрузочных тестов уделяется большое внимание. Основное, что вы должны запомнить, — мы должны собрать статистику, максимально приближённую к реальному использованию в дальнейшем. Если у нас есть высоконагруженный сервер, то мы создаём нагрузку, максимально приближённую к боевым условиям. Для этого используют тестовые стенды, пишутся программы-симуляторы нагрузки. Как правильно это сделать, подскажут ваши задачи и ваш реальный опыт. Что-то советовать тут, увы, сложно.
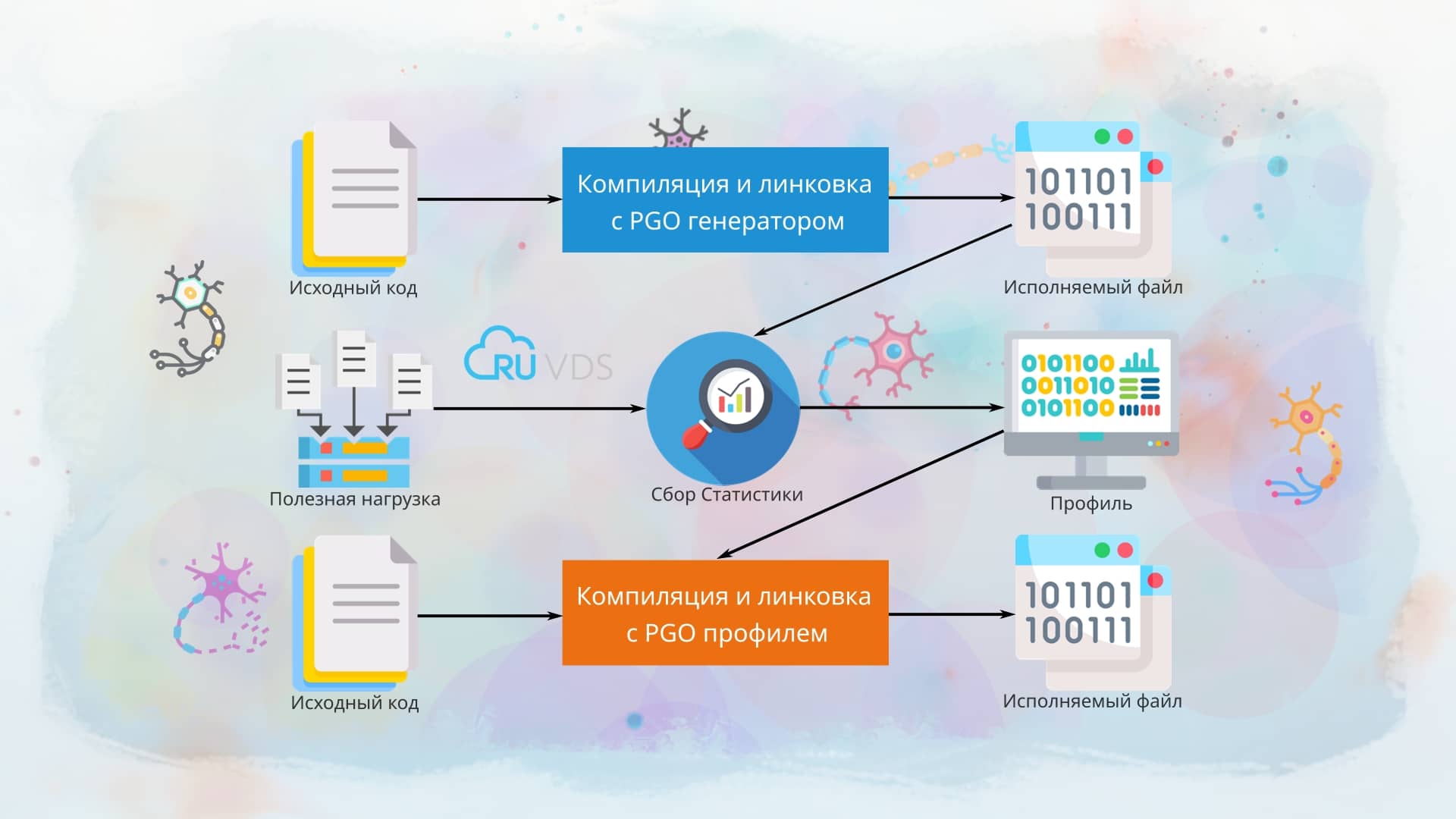
По этой же причине в случае с ядром Linux данный метод оптимизации неприменим к тяжёлым ядрам с большим количеством модулей, т. е. он подходит только к hardware-dependent ядрам (кастомным ядрам, сконфигурированным под определённую конфигурацию железа), например, ядру для смартфона, из которого мы хотим выжать максимум производительности.
В компиляторе clang для PGO-оптимизации существует два вида профилей:
• Инструментальный профиль (Instrumentation-based profiles). Такой вид профиля содержит более подробную информацию, но имеет более низкую скорость работы. Его ещё называют AST-based профилем или профилем, основанным на Абстрактном Синтаксическом Дереве (Abstract Syntax Tree, подробнее про AST можно прочитать в литературе по теории компиляторов). Чтобы собрать программу с таким видом профиля, надо передать компилятору параметр -fprofile-instr-generate. Во время линковки к исполняемому файлу будет прилинкована статическая библиотека libclang_rt.profile-arch.a из состава компилятора clang, в нашем случае это libclang_rt.profile-x64_86.a для 64-битных приложений, libclang_rt.profile-i386.a для 32-битных, для андроид это libclang_rt.profile-arch-android.a, где arch — архитектура процессора.
• Профиль на основе выборки (Sampling-based profile). Такой профиль обычно собирается аппаратными счётчиками процессора — hardware performance counters (HPC). Для такого вида профиля характерны более низкие накладные расходы на профилирование и он может быть собран без какого-либо инструментария, и сложной модификации бинарного файла. Также к данному виду профиля относят профиль основанный на байткоде LLVM(LLVM IR-based). Для создания LLVM IR-based профиля надо передать компилятору: -fprofile-generate. Такжe можно добавить параметр -gline-tables-only для уменьшения отладочной информации.
Оба вида профилей предоставляют статистику выполнения кода и информацию о предпринятых переходах и вызовах функций. Стоит заметить — какой бы вид профиля вы ни использовали, не указанный в профиле код будет оптимизироваться как ненужный или мусорный, то есть к нему будет применяться минимальная оптимизация. Поэтому очень важна правильная и комплексная нагрузка для создания профиля.
▍ Оптимизация с использованием инструментального профиля
clang -O2 -fprofile-instr-generate myprog.c -o myprog
LLVM_PROFILE_FILE=myprog.profraw ./myprogКомандой выше мы компилируем файл myprog.c с инструментальным профилем и запускаем исполняемый файл. LLVM_PROFILE_FILE указывает на имя файла, в который будет сохраняться профиль. Далее необходимо обработать сырой профиль и очистить от ненужной информации.
llvm-profdata merge --output=myprog.profdata myprog.profrawНа выходе мы получим файл профиля myprog.profdata. Далее уже компилируем исходный код с нашим профилем:
clang -O2 -fprofile-use=myprog.profdata myprog.c -o myprog▍ Оптимизация с использованием профиля на основе выборки и LLVM IR
clang -O2 -fprofile-generate myprog.c -o myprog
LLVM_PROFILE_FILE=myprog.profraw ./myprogКомпилируем файл myprog.c с профилем на основе выборки и запускаем исполняемый файл. Всё также обрабатываем и очищаем сырой профиль от ненужной информации.
llvm-profdata merge --output=myprog.profdata myprog.profrawСнова получем файл профиля myprog.profdata и компилируем исходный код с нашим профилем:
clang -O2 -fprofile-use=myprog.profdata myprog.c -o myprog▍ Оптимизация с использованием профиля на основе выборки и стороннего инструментария perf и AutoFDO
Компилируем нашу программу:
clang -O2 -gline-tables-only myprog.c -o myprogСобираем статистику с помощью инструмента perf:
perf record -b ./myprogСоздаём профиль:
create_llvm_prof --binary=./myprog --out=myprog.profdataКомпилируем нашу программу с полученным ранее профилем:
clang -O2 -fprofile-sample-use=myprog.profdata myprog.c -o myprogИнструментарий
В своей работе мы будем использовать компилятор clang >= 12. К сожалению для clang 12 и llvm 12 необходим набор дополнительных патчей, т. к. для PGO оптимизации ядра нужен дополнительный атрибут для кода __attribute__((no_profile)), который появился только в clang 13 и запрещает профилирование функции и добавление в неё дополнительного служебного кода для создания профиля. Он нам нужен, так как в некоторых функциях может неправильно генерироваться код, что, в свою очередь, вызывает kernel panic. Изначально этот атрибут был в clang 13, как __attribute__((no_profile_instrument_function)), но в более поздних коммитах llvm 13 был переименован в __attribute__((no_profile)) для совместимости с GCC. На данный момент мною используется clang 14. Необходимый набор патчей и сборочный скрипт для llvm 12 вы можете найти здесь. Сборочный скрипт для llvm 14 вы можете найти здесь. Также рекомендую к ознакомлению мою предыдущую статью — LTO оптимизация ядра Linux.
Практика
Скачайте патч по ссылке Патч PGO Оптимизация.
Скачаем и распакуем архив с исходным кодом ядра в /tmp:
wget https://cdn.kernel.org/pub/linux/kernel/v6.x/linux-6.0.9.tar.xz
tar -xf linux-6.0.9.tar.xz -C /tmpПерейдём в рабочий каталог:
cd /tmp/linux-6.0.9Применим патч с PGO оптимизацией:
patch -p1 < путь к патчу/pgo.patchКопируем конфигурация ядра или создаём конфигурацию с нуля:
zcat /proc/config.gz > .configили
cp путь к вашему конфигу .configили создаём конфигурация с нуля
make tinyconfig
Запускаем конфигуратор ядра:
make nconfig LLVM=1В конфигураторе нам важен параметр ядра CONFIG_PGO_CLANG=y, для этого переходим в General architecture-dependent options в самом низу будет пункт Profile Guided Optimization (PGO), заходим в него и выбираем Enable clang’s PGO-based kernel profiling.

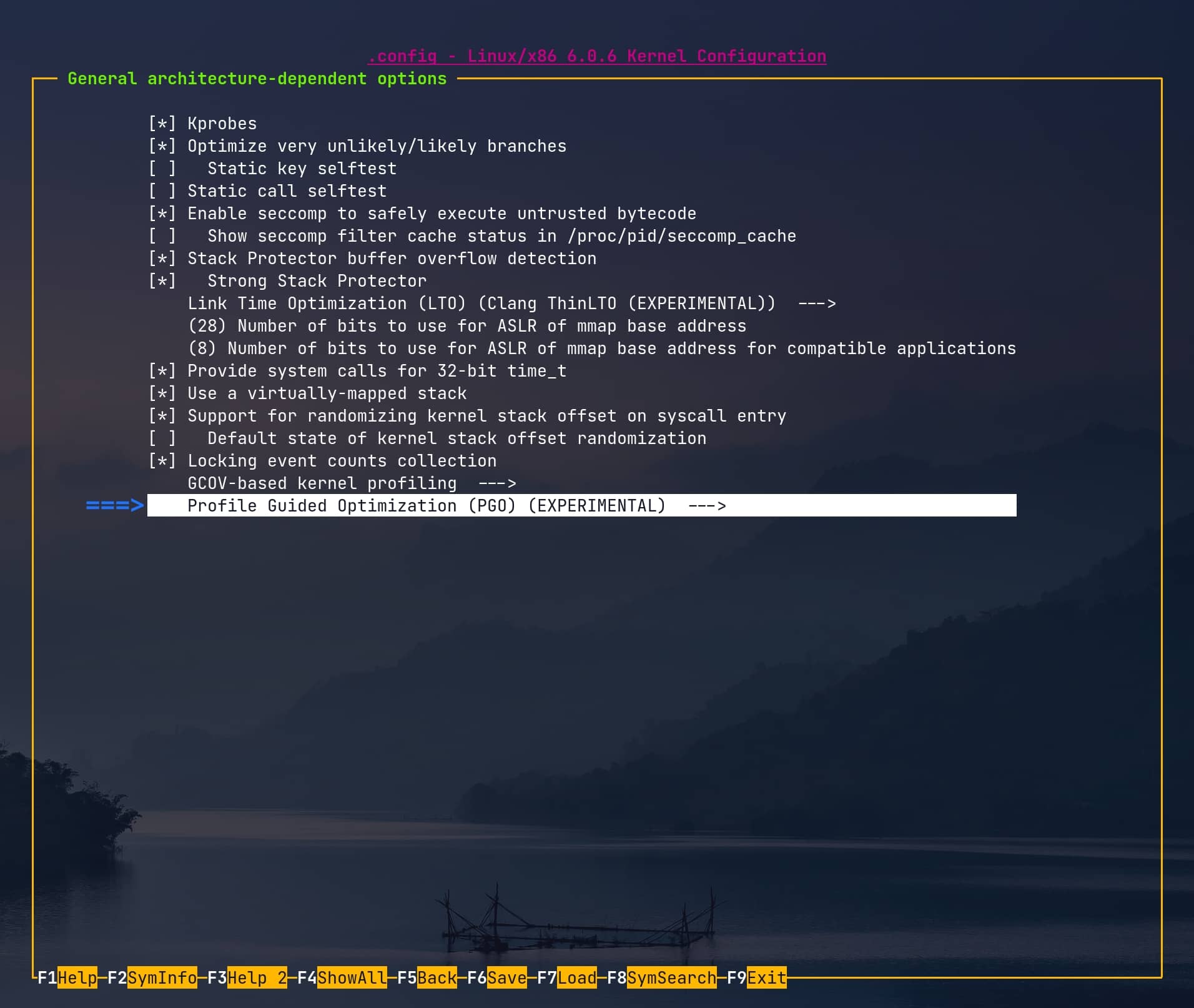

Обязательно необходимо отключить в конфигурации ядра AMD Secure Memory Encryption (SME), если этот параметр включён, то ядро зависает на самой ранней стадии загрузки ядра, и эту ошибку очень сложно понять и отловить, и её невозможно даже отловить дебагером. Для этого заходим Processor type and features и снимаем галочку с AMD Secure Memory Encryption (SME) support.


Наши настройки ядра закончены, поэтому сохраняем конфигурацию ядра и выходим из конфигуратора.
Собираем ядро:
make -j $(nproc) LLVM=1Внимательно смотрим на предупреждения при сборке ядра! Если мы встретим, что-то типа этого:
vmlinux.o: warning: objtool: can't decode instruction at .text.calc_rc_params:0x92
arch/x86/tools/insn_decoder_test: warning: Found an x86 instruction decoder bug, please report this.
arch/x86/tools/insn_decoder_test: warning: ffffffff81d68bb2: f2 0f 78 c0 08 08 insertq $0x8,$0x8,%xmm0,%xmm0
arch/x86/tools/insn_decoder_test: warning: objdump says 6 bytes, but insn_get_length() says 0
arch/x86/tools/insn_decoder_test: warning: Decoded and checked 7200326 instructions with 1 failures
То это плохой знак, и наше ядро не загрузится после перезагрузки. Как мы можем понять из сообщения, варнинг возникает в функции calc_rc_params. Для этого делаем поиск по файлам в поисках нашей функции:
grep -lR "calc_rc_params"Просматриваем все файлы, и в итоге находим, что наша функция находится в файле drivers/gpu/drm/amd/display/dc/dsc/rc_calc.c.
Открываем файл, находим функцию void calc_rc_params (struct rc_params *rc, const struct drm_dsc_config *pps) и перед ней добавляем строку __attribute__((no_profile)), которая говорит, что мы запрещаем её профилировать и встраивать какой-либо необходимый компилятору служебный код. В итоге у нас получится:
__attribute__((no_profile))
void calc_rc_params(struct rc_params *rc, const struct drm_dsc_config *pps)Сохраняем наш файл. Очищаем сборку ядра:
make cleanПовторяем сборку:
make -j $(nproc) LLVM=1Если всё впорядке, то после сборки переходим к установке ядра и модулей (mykernel необходимо заменить на имя вашего ядра):
sudo make modules_install
sudo cp -v arch/x86_64/boot/bzImage /boot/vmlinuz-mykernelСоздаём cpio загрузочный образ с помощью dracut или mkinicpio. Прописываем ваше новое ядро в grub или systemd-boot и перезагружаемся в новое ядро.
Загружаем новое ядро.
Проверяем подмонтирован ли proc в системе:
mount | grep procЕсли всё в порядке — мы должны увидеть похожую строку:
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)Если proc не подмонтирован, то это можно сделать под root командой:
mount -t proc proc /procВ /proc/pgo находятся 2 файла. Файл reset используется для обнуления статистики, и чтобы начать её сбор по новой. Файл vmlinux.profraw содержит необходимый нам не обработанный PGO профиль.
Чтобы обнулить статистику — необходимо c правами root выполнить:
echo 1 > /proc/pgo/resetДаём системе поработать и максимально нагружаем её задачами приближёнными к реальным нагрузкам. Сколько времени для этого необходимо сказать сложно, зависит от нагрузки, ядра. Но обычно действует правило чем дольше тем лучше.
После того как система поработала, копируем наш профиль (нужны root права) в директорию доступную для чтения обычному пользователю:
cp -a /proc/pgo/vmlinux.profraw vmlinux.profrawДаём пользователю права на чтения файла:
chown ruvds:ruvds vmlinux.profrawС правами обычного пользователя конвертируем сырой профиль и генерируем конечный профиль для компилятора:
llvm-profdata merge --output=vmlinux.profdata vmlinux.profrawПерейдём в рабочий каталог с исходниками ядро:
cd /tmp/linux-6.0.9Очистим исходный код ядра:
make distcleanКопируем конфигурация текущего ядра:
zcat /proc/config.gz > .configЗапускаем конфигуратор ядра:
make nconfig LLVM=1Переходим в General architecture-dependent options в самом низу будет пункт Profile Guided Optimization (PGO), заходим в него и снимаем галочку напротив Enable clang’s PGO-based kernel profiling. Выходим и сохраняем новый конфиг.
Собираем наше ядро с профилем:
make -j $(nproc) LLVM=1 KCFLAGS=-fprofile-use=полный путь к профилю/vmlinux.profdataЕсли компиляция прошла успешно, то устанавливаем наше новое ядро и модули:
sudo make modules_install
sudo cp -v arch/x86_64/boot/bzImage /boot/vmlinuz-mykernelПерезагружаем систему и наслаждаемся новым оптимизированным ядром.
Итоги
Если отбросить лень и предрассудки, то сборка ядра — несложная задача. А при определённом опыте, сборка ядра с PGO оптимизацией под силу многим. После несложных и понятных операций мы получили более быстрое и оптимизированное ядро Linux. Применить которое вы можете дома и в своей работе. Также не стоит бояться новых технологий, ведь «Только смелым покоряются моря!». Поэтому только вам под силу достичь новых высот, и продвигать технический прогресс!
Комментарии
После того как компания Google выпустила набор патчей для PGO оптимизации, мною была добавлена поддержка LLVM 13 и LLVM 14, т.к. в них менялся формат профиля и с оригинальными патчами clang его не понимает. Также файл профиля и сброса были перенесены из debugfs в proc для устранения проблем с включённым kernel_lockdown (man kernel_lockdown) в ядре Linux, который не даёт прочесть профиль. Данное изменение позволять профилировать ядро с включёнными системами безопасности ядра, без их отключения на этапе загрузки. Дополнительную информацию вы можете найти в файле Documentation/dev-tools/pgo.rst после применения патча ядра.
Результаты бенчмарков
По указанной ссылке вы сможете найти результаты бенчмарков, и скрипт для тестирования: скачать.
Telegram-канал с полезностями и уютный чат

Комментарии (28)

webhamster
22.11.2022 15:51+3clang -O2 -fprofile-use=myprog.profdata
clang -O2 -profile-use=myprog.profdata
clang -O2 -profile-sample-use=myprog.profdata
Буковка f не потерялась в двух из трех?

perfect_genius
22.11.2022 16:59+1Почему программа не может сама себя постоянно анализировать и адаптироваться под ситуацию, т.е. подправлять себя?
Слишком сложно? Постоянный анализ бьёт по производительности? Или современные ОС и антивирусы будут активно мешать самомодификации?
nullc0de Автор
22.11.2022 17:12Самомодификация это полиморфный код, антивирусы на него будут реагировать. Анализ ресурсоемкая задача, поэтому выигрыш от производительности будет съедать ее деградация от анализа. Плюс самомодификация тоже тяжеловесная задача, возьмите к примеру LTO оптимизацию и сравните насколько она увеличивает время линковки. Да банально возьмите упаковщик PE и сравните насколько медленее стала программа. И как вы можете заметить сами время компиляции на порядок дольше чем запуск самой программы. Что вы написали уже есть, и называет JIT-компиляция, правда она не везде применима. У любого метода есть плюсы и свои ограничения, нет ничего идеального в этом мире, везде используют компромиссы.

klirichek
23.11.2022 11:38Вам в принципе никто не мешает вместе с программой тащить обёртку (и вроде как её даже не очень сложно написать), которая будет снимать профиль, запускать анализ, пересобирать программу из исходников с полученным профилем и далее перезапускать.
Кстати, заметил на страничке LLVM тулзу bolt. Кажется, появилась не очень давно. Судя по описанию, это почти то, что вы ищете, только не автоматизированное.
Буквально - снимаете профиль нагрузки (например, с помощью perf), а потом с помощью этого профиля и bolt обрабатываете бинарь. Получается другой бинарь, перелинкованный так, чтобы работать быстрее при данном профиле. Магия в том, что для этого не нужен ни компилятор, ни исходники. И даже бинарь может быть не прямо тот же самый, а какой-нибудь близкой версии.

dzhidzhoev
23.11.2022 16:01Этот подход - "self-driven" - имеет место быть, например, в СУБД. https://noise.page/


DrMefistO
22.11.2022 17:23+8Всё же какие-то замеры были бы кстати. А то вдруг у Вас как раз и вышло, что стало медленнее.
nullc0de Автор
22.11.2022 17:31-6Что будет у меня не факт, что будет у вас. Что именно вы предлагаете замерить?
Замеры должны делать вы сами, все экспериментальные методы так и помечены в ядре, как экспериментальные. Т.е. вы их используете на свой страх и риск, и сами решаете нужно это вам или нет.
Вы делаете замеры на своей нагрузке и смотрите дает это вам выигрыш с вашей нагрузкой или нет.DrMefistO
22.11.2022 18:00+12Я эти утверждения уже видел в статье.
Вы же говорите, что, мол, наслаждайтесь оптимизированным(!) ядром, но как Вы это без замеров (на Ваших же задачах) можете утверждать? В этом и вопрос.
nullc0de Автор
22.11.2022 18:17-7Могу задать встречный вопрос. Как вы можете утверждать обратное, если не привели доказательств и опровержений?

alan008
22.11.2022 23:30+1Я не автор заданного вам вопроса, но всё-таки вмешаюсь. Вы сказали, что есть некая pgo-оптимизация по умолчанию (текущая реализация), а вы её якобы ещё ускорили и предложили какой-то патч. Вот вас и спросили, а в чем конкретно ваше ускорение состоит?
>Скачайте патч по ссылке Патч PGO Оптимизация.
Вот в этом патче что конкретно ?
nullc0de Автор
23.11.2022 00:11Я там ничего не ускорял, перечитайте внимательно статью, там все изменения написаны в последнем абзаце.
Если в кратце я добавил поддержку профиля llvm 13-14, оригинальная версия патча работала с профилем 12 версии, она собирала профиль, но при конвертации сырого профиля выскакивала ошибка т.к. формат профиля отличался.После того как компания Google выпустила набор патчей для PGO оптимизации, мною была добавлена поддержка LLVM 13 и LLVM 14, т.к. в них менялся формат профиля и с оригинальными патчами clang его не понимает. Также файл профиля и сброса были перенесены из debugfs в proc для устранения проблем с включённым kernel_lockdown (man kernel_lockdown) в ядре Linux, который не даёт прочесть профиль. Данное изменение позволять профилировать ядро с включёнными системами безопасности ядра, без их отключения на этапе загрузки. Дополнительную информацию вы можете найти в файле Documentation/dev-tools/pgo.rst после применения патча ядра.
alan008
23.11.2022 11:07Спасибо за разъяснения, я примерно так и думал, но решил уточнить.
насчет
>> добавил поддержку профиля llvm 13-14
а в мейнстрим эти изменения никто не хочет добавить?nullc0de Автор
23.11.2022 13:40Нет, Линус Торвальдс не принял патчи по причине того, что якобы можно для этого еще использовать написанный им perf, но я нигде не видел как это сделать. Теоретически можно использовать AutoFDO, но когда я с ним игрался и с ядром ничего хорошего из этого не вышло, профиль нормально не собирался. Чистой воды политика.

myxo
23.11.2022 00:29+6Что будет у меня не факт, что будет у вас.
Так у вас никто не просит гарантий что у всех всё станет быстрее. Но писать статью об оптимизациях без цифр — это что-то крайне странное. Откуда вы знаете, что там что-то соптимизирорвалось? Может наоборот медленнее стало (примеров замедляющих «оптимизаций» навалом). Апелляция к авторитетам («Думаю создатели PGO оптимизации и компании производители программного обеспечения не дураки») тут не работает
nullc0de Автор
23.11.2022 05:50Откройте ссылку, там есть все результаты github.com/h0tc0d3/linux_pgo
Для удобства сравнения результатов можете использовать KDiff3 или Kompare.DrMefistO
23.11.2022 10:12+1Приложите, плиз, данную ссылку в конце статьи, она будет выглядеть хотя бы законченной.

Gumanoid
22.11.2022 23:06arch/x86/tools/insn_decoder_test: warning: Found an x86 instruction decoder bug, please report this. arch/x86/tools/insn_decoder_test: warning: ffffffff81d68bb2: f2 0f 78 c0 08 08 insertq $0x8,$0x8,%xmm0,%xmm0 arch/x86/tools/insn_decoder_test: warning: objdump says 6 bytes, but insn_get_length() says 0А что это значит? Компиляция с профилем привела к ошибочным оптимизациям, из-за которых сломался встроенный в ядро декодер длин инструкций? Выглядит опасно, тогда ведь могло сломаться и другое место, но не покрытое такой проверкой.
nullc0de Автор
22.11.2022 23:37Я думаю это произошло из-за линковки стаба rt llvm необходимого для профилирования, и в начале каждой функции встраивался ассемблерный код, который вызывал этот стаб, в коде могли быть ассемблерные вставки, или слишком большой код и inline вставки, которые компилятор чудным образом оптимизировал, как помню это была очень тяжелая функция со сложным ветвлением, и происходил сбой. Потом эта проблема исчезла из ядра. Но я запечатлил ее, чтобы потом показать. В переписке к патчу ядра это тоже упоминалось, что не каждую функцию можно просто так профилировать. Ядро обычно все ошибки сразу сообщает, на край ядро обкатывается на qemu. Я пока ловил баг с AMD Secure Memory Encryption (SME) support, ядро успешно запускалось в qemu, долго не мог понять в чем причина, ни кернел паник, ни дампов ядра, просто ядро зависало на самом раннем этапе загрузки.

Racheengel
23.11.2022 02:10+1Оптимизация это (почти) всегда хорошо, особенно если прирост в производительности ощутимый. А какой у Вас он в итоге получился и как производились измерения? Какой метод оптимизации сколько выжал? Просто самое основное не совсем очевидно из статьи.
Aquahawk
А итоги то какие, есть адекватные замеры где можно увидеть результат? А то тут недавно писали про студентов которые оптимизировали, оптимизировали, а что соптимизировали сказать не смогли: https://habr.com/ru/post/698988/
nullc0de Автор
По ядру Linux нет, все зависит от правильно собранного PGO профиля и нагрузки. Но в интернете есть бенчмарки очень большого количества программного обеспечения, так же бенчмарки есть в исходниках языков программирования где используется PGO оптимизация при сборке. Не говоря о том, что большая часть сложного софта сейчас собирают с PGO оптимизацией. Думаю создатели PGO оптимизации и компании производители программного обеспечения не дураки. Ну а если ..., то ждем от вас доказательств и пруфы. Ваша же статья по ссылке касается больше вас самих. Поэтому применять или нет, это вопрос только к вам. Мое дело только рассказать и открыть новые горизонты читателям.
www.phoronix.com/news/GCC-12-PGO-TR-3990X-AMD