
В предыдущей статье “Jira без боли” (ч1, ч2) был небольшой эпизод про интеграции с другими сервисами через инструмент автоматизации n8n (читается как нейтн).
В этом материале расскажу, зачем он нам понадобился, какие задачи мы начали с его помощью решать, какую роль он сейчас играет у нас. И чем он может быть полезен вам.
Диспозиция
Всё началось сильно давно: с того, что мы внедрили одну мощную CDXP систему для нашего Marketing. Система позволила выстроить омниканальную коммуникацию с конечными пользователями. В этой тулзе был визуальный редактор сценариев, который позволял делать примерно вот такие штуки:

Я в тот момент управлял проектом по интеграции вот этого всего. И если у писем, пушей и смс есть кучи готовых интеграций с конкретными сервисами по доставке, то настраиваемые в интерфейсе WebHook’ки — куда угодно, с возможностью обработки полученных ответов — выглядели как настоящая магия, с помощью которой можно решить любую бизнес проблему.
Данную особенность я запомнил, и мы потом реализовали множество интересных фич за счёт неё.
Шло время, я вырос из своей прошлой позиции и получил повышение до Head of Internal Automation. Мне предстояло стать руководителем над несколькими тимлидами команд, которые пилили всякое разное для внутренних бизнес потребностей.
У нас в Каруне, как, наверное, и везде, было много сложностей с тем, что огромное количество действий между системами пользователи делают в ручном режиме: например, просто поддерживают консистентность данных. И вот это всё нужно автоматизировать, сотрудники должны перестать заниматься Monkey Job, а начать тратить своё время на развитие бизнеса, ну а ещё целую кучу самых разных гугл таблиц надо было заменить на какие-то инструменты.
И вот тут я как раз вспомнил про ту самую CDXP систему и её возможности, и у меня появилась мысль, что, может быть, мы её сделаем основным движком автоматизации между сервисами? Она получает запрос из системы Х, на основе него в ней происходит МАГИЯ, мы настраиваем в визуальном редакторе и ваще без кода некий сценарий, а потом она шлёт куда-то запрос. Вуаля, бизнес ценность принесена.
Бизнес мои мысли послушал и отправил ресерчить рынок, так как разворачивать огромную тулзу под такие скромные запросы не хотел. К тому же, она облачная, а хотелось бы такую, чтоб на своих серверах жила. Я некоторое время искал альтернативные варианты. Первым, конечно же, в голову пришёл Zappier, но его мы быстро исключили по соображениям безопасности. И — вот чудо, я нашёл n8n.io.
Hello World в n8n
Прежде чем нести тулзу на "продажу" бизнесу, мне было важно проверить, что она сможет закрывать наши потребности, в первую очередь, отправлять кастомные WebHook’ки.
План для проверки у меня родился достаточно быстро и выглядел вот так:

Шлём запрос из n8n в Jira на получение данных. Например, гетаем конкретную задачу.
Из полученной задачи вытаскиваем описание.
Отправляем описание задачи в канал #automations_tests в слаку.
Бот для отправки запросов в Slack у нас уже был, и креды лежали под рукой. Технический пользователь в Jira, через которого можно авторизовать запрос, тоже. Так что на стороне сервисов всё было готово, требовалось только развернуть локально n8n.
У инструмента есть готовый docker образ и инструкция по работе с ним — https://docs.n8n.io/hosting/installation/docker/. Там рекомендуется поставить docker desktop, запустить из терминала команду и просто получать удовольствие.
docker run -it --rm \
--name n8n \
-p 5678:5678 \
-v ~/.n8n:/home/node/.n8n \
n8nio/n8nНу, и, собственно, всё. Тыкаем запустить, заходим в браузере по адресу localost:5678 и можем начать работу.
Инструмент предлагает на выбор огромное количество готовых интеграций, в том числе с Jira & Slack, однако мне было важно протестировать работу с любым инструментом через отправку базовых HTTP запросов. Поэтому моя первая автоматизация выглядела примерно вот так:

Мне не понадобился никакой отдельный блок / нода для обработки ответа. Так как я подставил данные из ответа в отправку запроса в Slack через переменную. Чуть позже я покажу, как делать автоматизации гораздо подробней.
Поняв, что всё работает, я помчался готовить презентацию инструмента для бизнеса.
Сколько это стоит и какую ценность принесёт?
Именно к таким вопросом стоит быть готовым, когда вы что-то пытаетесь продать бизнесу. Просто сделать красивую презентацию в духе “смотрите, как могу” — не вариант.
Нужно описать, какие задачи мы будем решать, с какой примерно скоростью, есть ли уже бэклог этих задач, какими ресурсами, потребуется ли кого-то нанимать под это дело. А ещё, если вы печётесь о безопасности, сходите и пообщайтесь со своей СБ.
Наиболее сложная часть последующей работы была в проведении встреч с коллегами для сбора и актуализации бэклога. А красивая презентация даже не потребовалась, когда на предварительных синках я сказал, что тулза БЕСПЛАТНАЯ, и нанимать первые пару месяцев, за которые мы решим вот такой круг задач, ваще никого не нужно. Максимум — разместить тулзу на наших серверах.
Реакция коллег была примерно такая, и они уже с нетерпением ждали первых результатов...

Мы решили, что не стоит браться без экспертизы работы в инструменте за самые адовые задачи и лучше набить руку на чём-то тривиальном. Поэтому бэклог на первое время у нас был примерно такой:
Автоматически выдавать доступы в Slack для всех новых сотрудников.
Автоматически выдавать доступы в Miro для тех, кому надо.
Автоматически отправлять OnBoarding письма новым сотрудникам.
Автоматически поздравлять сотрудников с днём рождения письмом.
Автоматически отправлять сотрудникам Exit опрос при увольнение по собственному.
И так далее, в том же ключе.
Основными нашими заказчиками на первое время стали HR & HelpDesk.
Внедрение
Тут уже проще постфактум сказать, чего просить от людей, ответственных за инфраструктуру, чтобы n8n в ней появился.
Объём запросов через эту тулзу планировался небольшой. Сколько могут породить ваши сотрудники? Наши могут десятки тысяч, это немного, даже не Highload. Так что на первое время мы решили остановиться на виртуалке.
4 vCPU, 6144 MB RAM, 100 GB SSD.
По деньгам выходило порядка 65$/месяц.
Первый ой
Внутри самого инструмента нет никаких настроек, ограничивающих доступ или возможности. То есть либо ты к нему доступ имеешь и творишь там, чего хочешь, либо доступа не имеешь никакого. В итоге доступ к нему был ограничен нашим
периметром + настройкой и логированием Basic Auth.
Таким образом, админы стали ответственными за выдачу доступа к тулзе. Неприятно, но поскольку такие запросы происходят ~ раз в три месяца — не страшно.
Второй ой
Разумеется, мы обернули сервис FireWall’ом от всех входящих запросов, но для выполнения своей основной функции ему как раз надо получать запросы извне, а значит в этом firewall надо прорубить дырок. Первое время мы рубили дырки поштучно, к конкретным endpoint’ам вроде:
https://n8n.yourdomain.com/webhook-test/v1/onboarding/welcome-email
https://n8n.yourdomain.com/webhook/v1/onboarding/welcome-email
Но когда мы пришли уже с третьей задачей на новые дырки, админы раскрутили нам гаек, чтобы их больше не доставали, и пробили нам дыру по маске.
https://n8n.yourdomain.com/webhook-test/*
https://n8n.yourdomain.com/webhook/*
Это лучше сделать сразу, а также добавить endpoint
https://n8n.yourdomain.com/rest/oauth2-credential/callback
ну или тоже по маске
https://n8n.yourdomain.com/rest/*
Первая автоматизация
Возможно, будет не той, которую вы запланируете. Сначала мы хотели первой сделать отправку onboarding письма всем новым сотрудникам, но решили, что неплохо бы под это дело завести отдельный сервис-отправщик, и начали процедуру заведения нового сервиса. А ещё оказалось, что нет свёрстанного шаблона письма. Мы понесли задачу в дизайн.

Потом мы решили, что самой ценной автоматизацией будет автоматическая выдача доступа в Slack ВСЕМ новым сотрудникам. Начали её реализовывать, но в процессе настройки HTTP запроса в Slack поняли, что нужный endpoint не поддерживается нашим тарифным планом.
Поэтому первой нашей автоматизацией стала “Автоматическая выдача доступа в Miro” для тех, кому надо. Хоть она и была несколько сложней описанных выше, в production она ушла первой. Мы открыли шампанское и обсудили, какой урок можем вынести из этой истории.
85-90% времени мы тратим не на реализацию самой автоматизации, а на скрупулёзный бизнес и системный анализ. Именно качественный анализ до реализации помог бы нам выяснить, что у нас и тариф не тот, и сендера почты, с которым легко по API работать, нема. Более детальный бизнес анализ подсветил нам проблему отсутствия свёрстанного шаблона письма. А вот когда “все карты на руках”, автоматизация делается очень быстро.
Как делать автоматизации
Давайте попробуем разобрать на примере одной из самых простых автоматизаций — в частности, про которую я писал в прошлой статье.
Бизнес-задача. Мы хотим делать некое действие, например, отправлять данные в стороннюю систему, когда пользователи в Jira переводят задачу в некий статус.
Не буду говорить, какое конкретное действие совершить, чтобы вы смогли применить свою фантазию и подставить под это вашу собственную задачу.
Давайте разматывать клубок по ниточкам. Свои действия буду записывать в виде гифок.
0. У автоматизации есть начало, это некий триггер
У n8n достаточно много готовых триггеров, но самый простой способ начать что-то делать — это использовать WebHook. То есть некие действия тулза начнёт делать, как только получит HTTP запрос.
Иногда вам, конечно, может понадобиться реализация действий по CRON. А иногда и готовая нода аля “Kafka Trigger” или “Redis Trigger”, но тут вы сами уже решите.
А мы для нашего Example давайте выберем WebHook.

Пока, как видите, ничего страшного. Выбираем метод авторизации запросов, подставляем конкретные credentials. Да, это очень удобно, что credentials являются отдельной сущностью, которую можно переиспользовать в разных автоматизациях.
Вписываем URL, по которому будем ожидать получение запроса. Можем поменять код и формат ответа. Собственно, всё готово, двигаемся дальше.
1. Работа на стороне Jira
Или любой другой интегрируемой системы. Вам нужно настроить эту систему так, чтобы она отправляла HTTP запрос в ваш инстанс n8n.
Если вы администратор проекта в Jira, то, скорее всего, вам и без админских прав на всё будут доступны базовые Jira автоматизации — с их помощью можно слать запросы вовне.
Зайдите в настройки вашего проекта, автоматизации, тыкаем создать и приступаем.
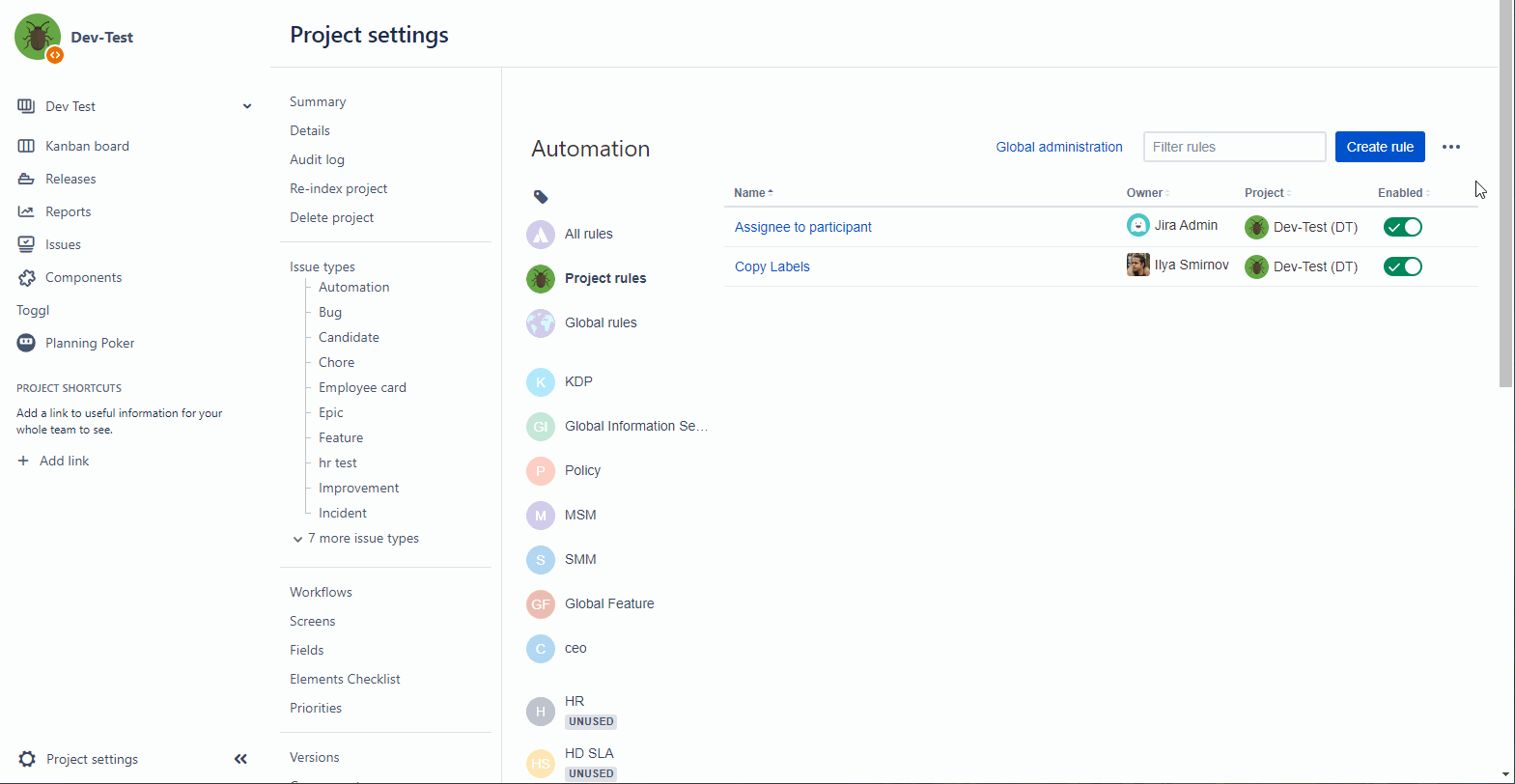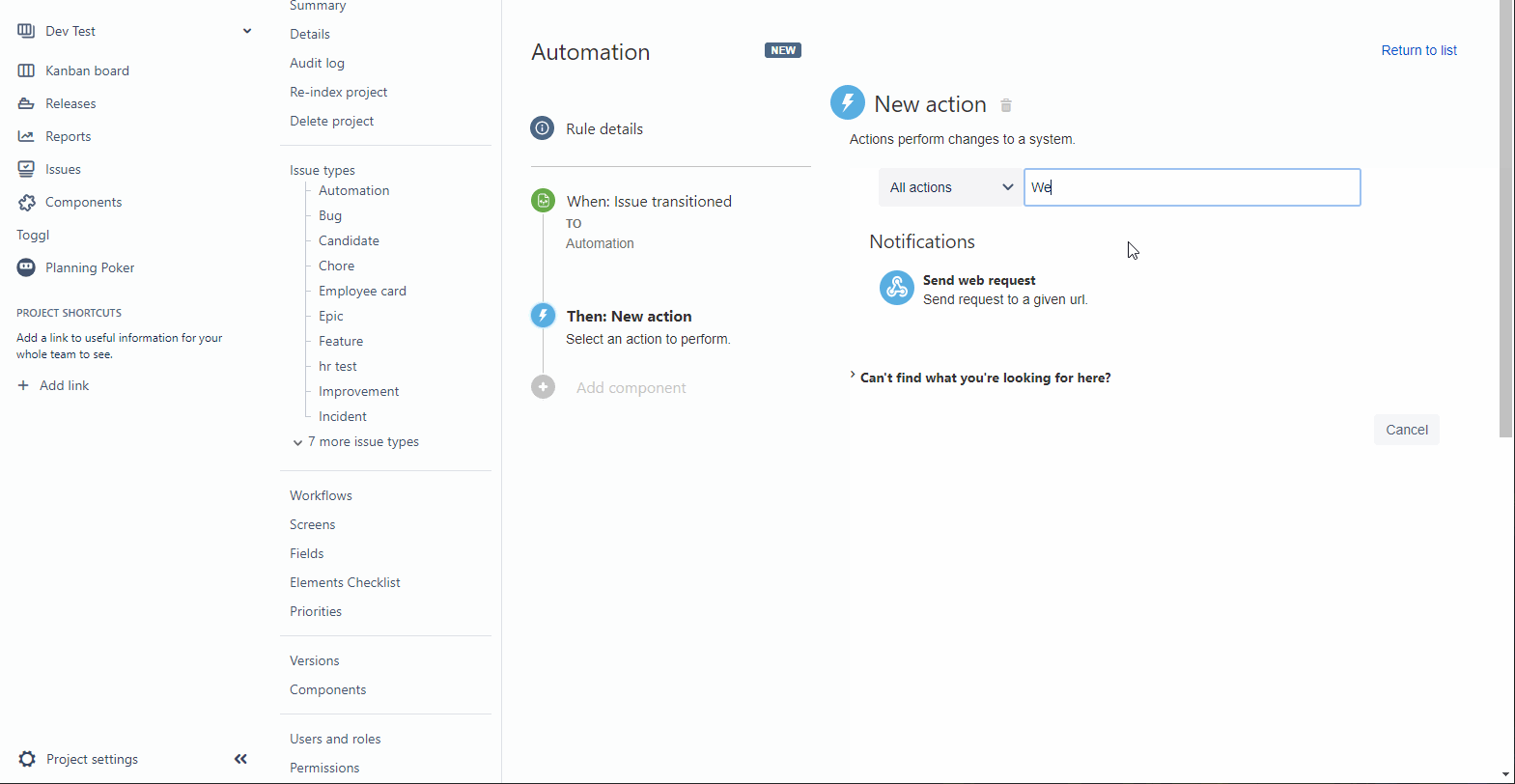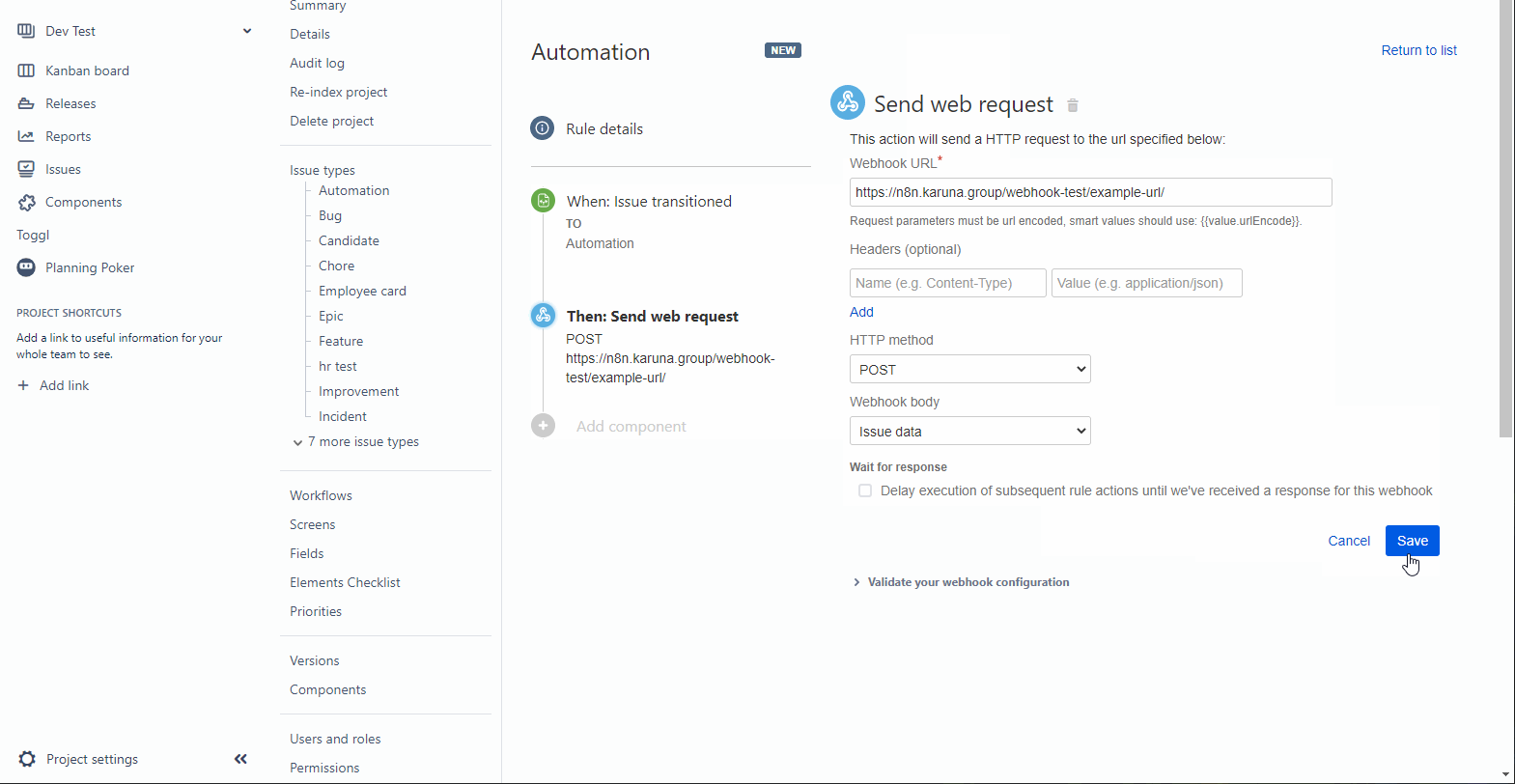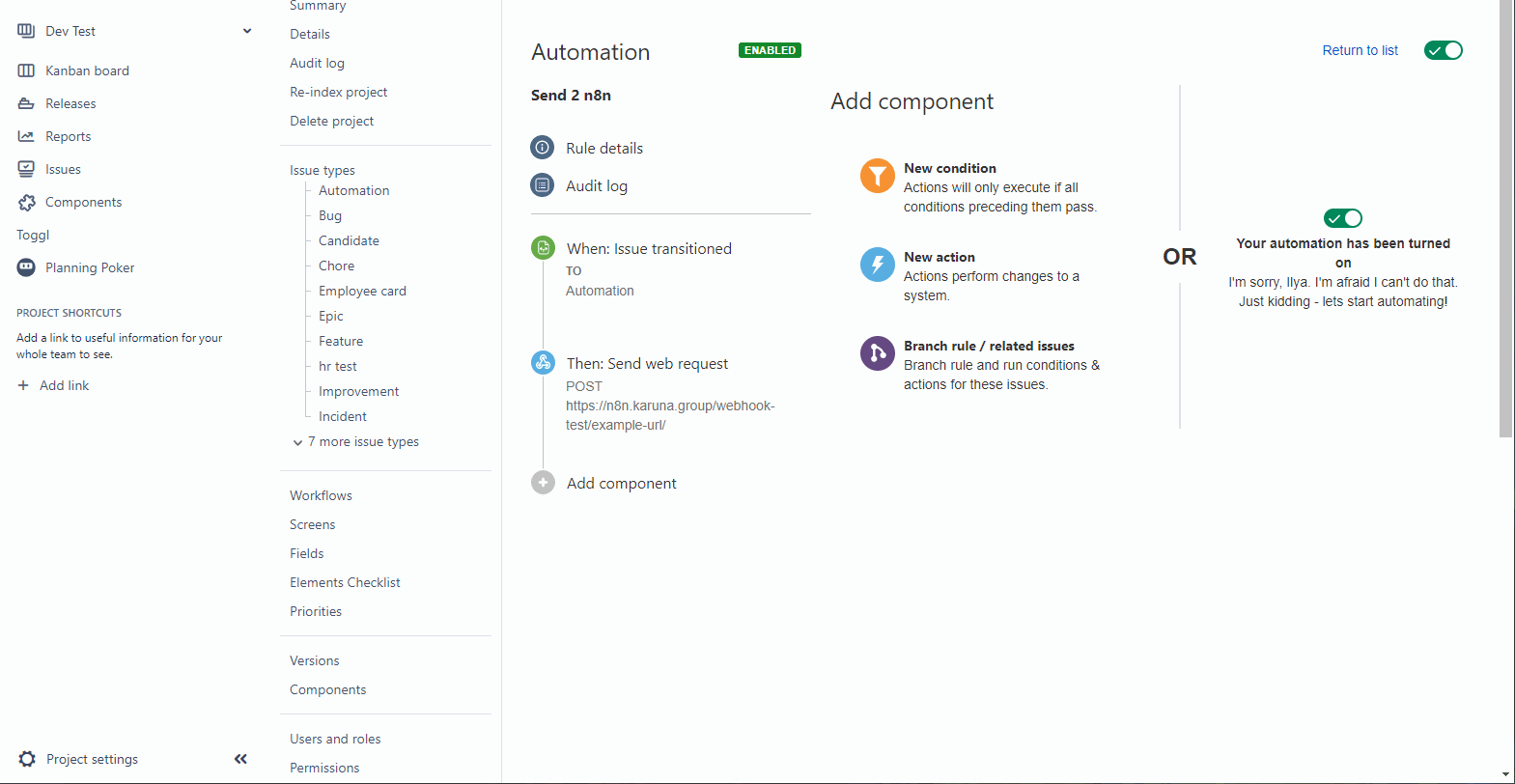
Нашим триггером будет переход задачи в статус, это до кучи ещё и самый простой триггер, так как его легко воспроизвести самостоятельно при тестировании, или если что-то пошло не по плану.
После выбора триггера и конкретного статуса, выбираем действие — Send Web Request. В нём нужно указать, куда мы отправляем этот самый запрос, для чего возвращаемся в автоматизацию, открываем ноду и копируем оттуда тестовый URL.
Дальше указываем, какие данные отправлять. Вы можете отправлять кастомно собранный JSON, но для простоты я ставлю галочку под “прислать все данные задачи”.
Также там нужно указать credentials, но светить в гифке я ими не буду, так что называю автоматизацию и сохраняю.
2. Проверка получения данных
Выполнив эти два действия, вы можете проверить, что данные доходят, и с ними можно начать работать на стороне n8n. Вот, как это делается:
Вы можете запустить исполнение всего WorkFlow, нажав на кнопку Execute WorkFlow в процессе работы над ним. А можете нажать на маленькую кнопочку Execute node над каждой конкретной нодой, чтобы проверить именно её работу.
Итак, нажимаем Execute node.
Переходим в Jira и тыкаем перевод в нужный статус.
Переходим обратно в n8n и видим, что нода загорелась зелёненьким, а снизу пришло уведомление о том, что всё прошло успешно.
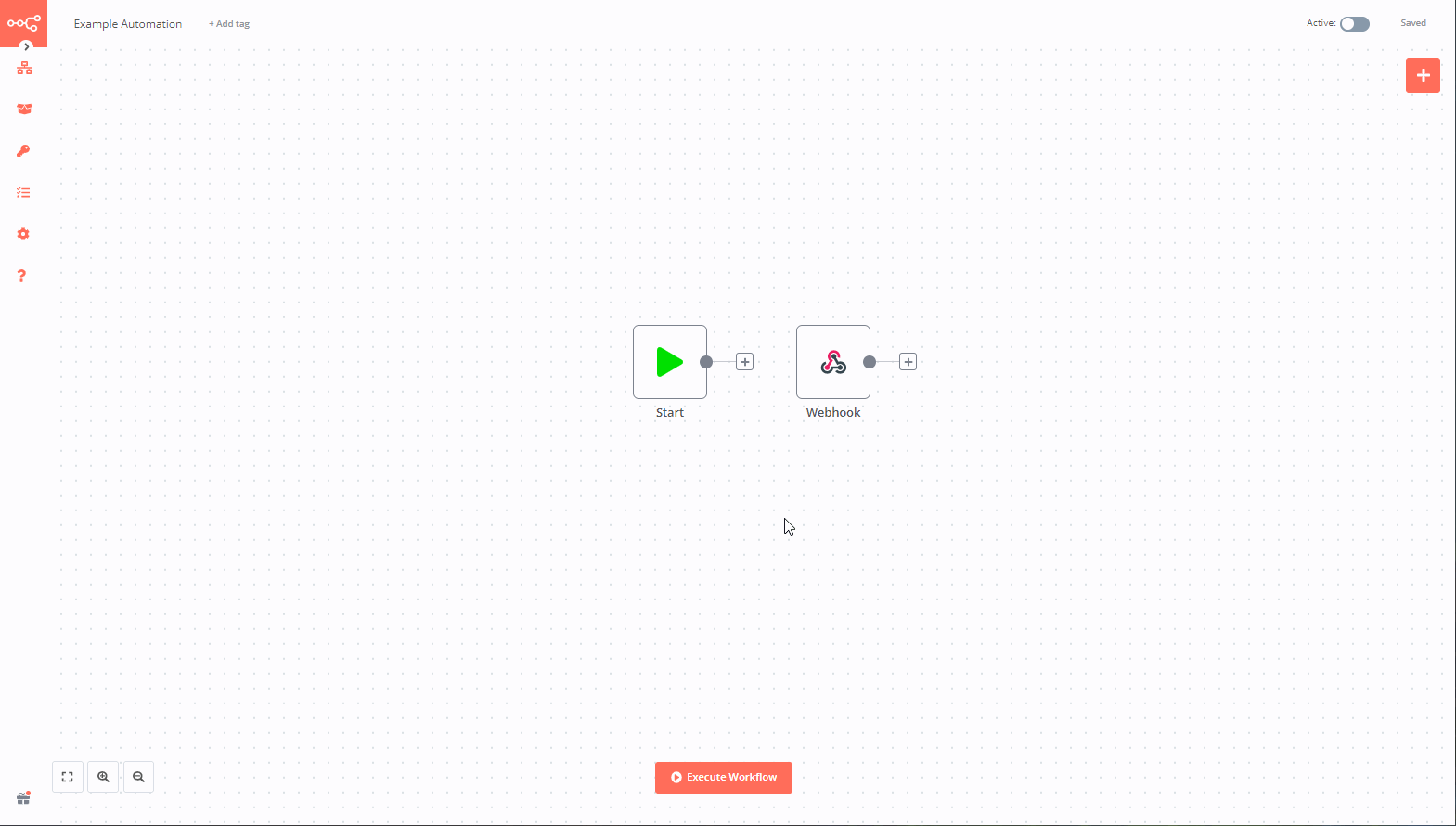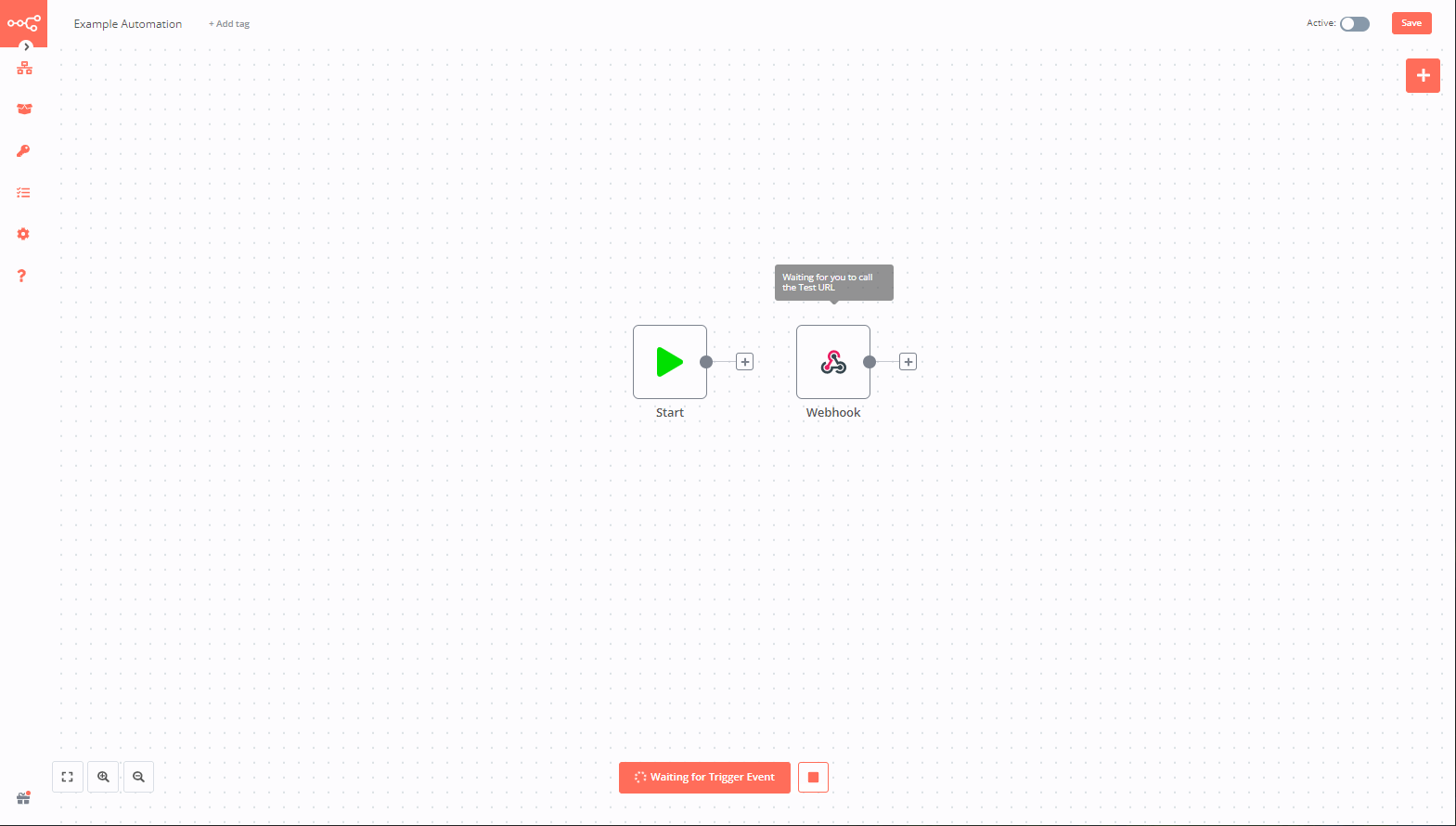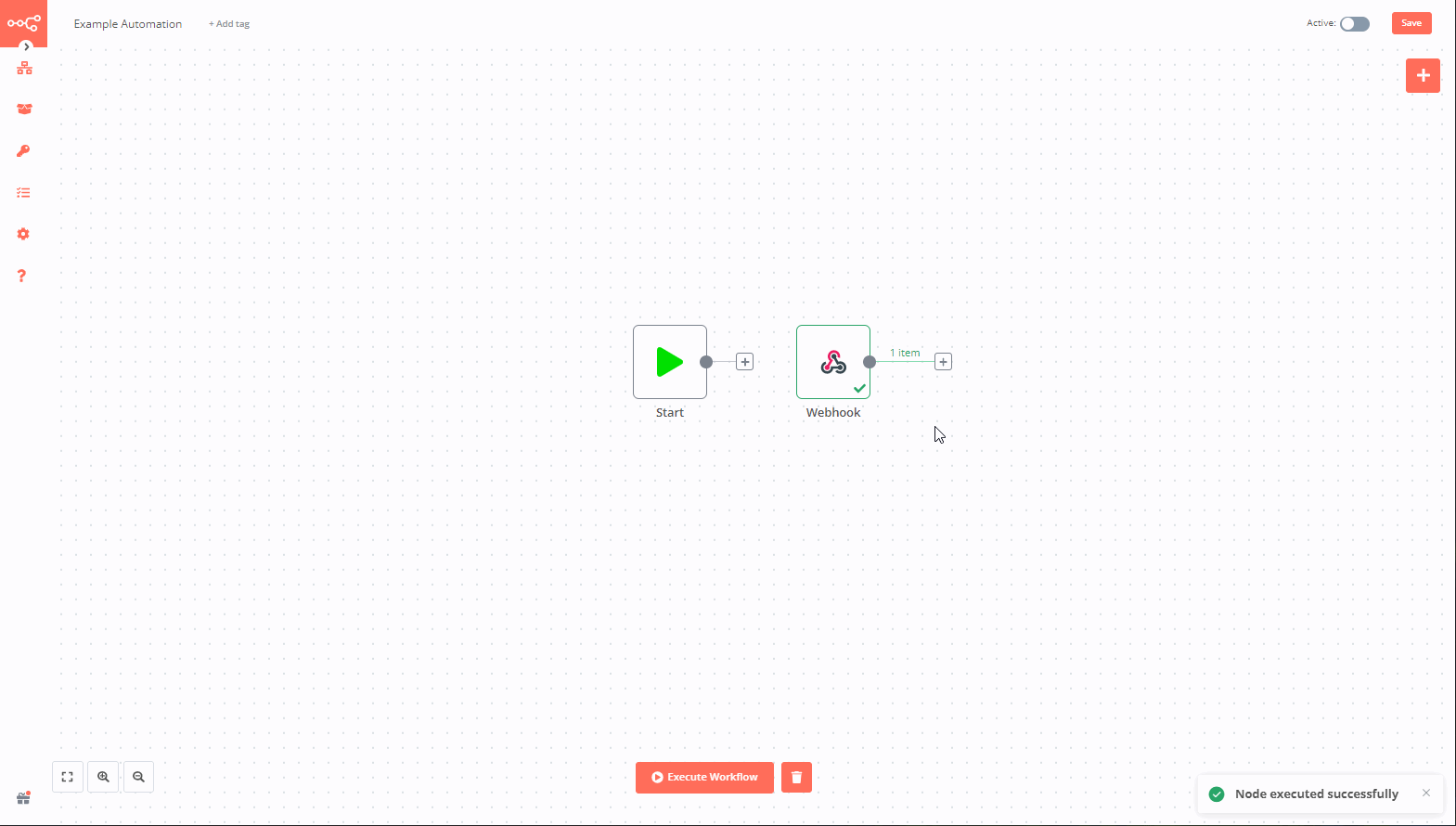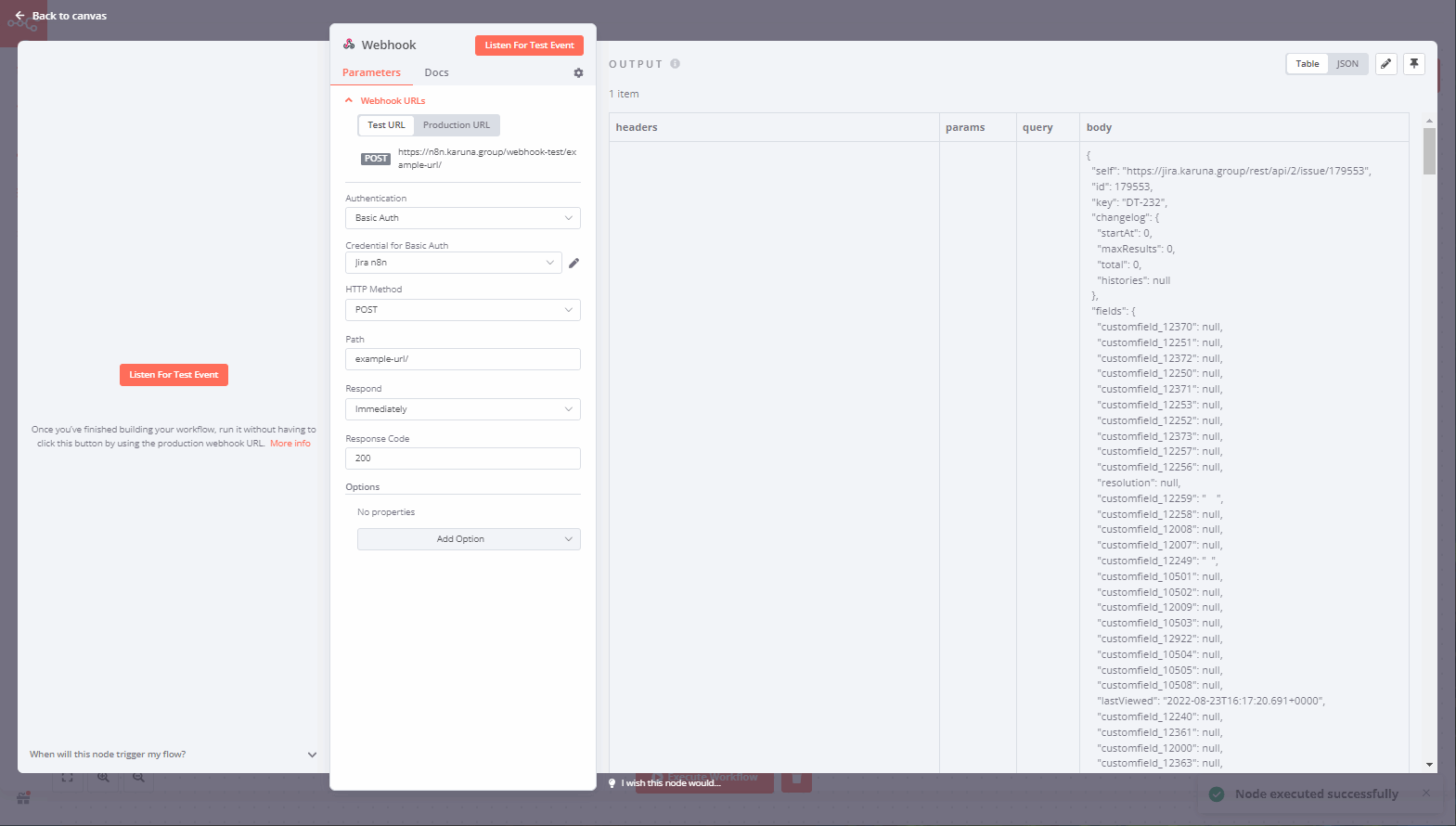
Открыв ноду, вы увидите справа набор полученных данных, который уже записался в две доступные для использования переменные.
Тут нужно сделать небольшое отступление к тому, что принцип работ n8n примерно такой же, как в программировании. Каждый элемент WorkFow, нода — это как функция. У неё есть входящие аргументы, есть данные, которые она возвращает, и есть доступ к данным в глобальной зоне видимости.
Когда мы получаем данные через ноду вебхука, они идут на её выход. Ретурнятся этой нодой. Эти данные всегда доступны через глобальную область видимости. Каждая нода имеет свой ключ в глобальной зоне видимости, по этому ключу можно будет найти её данные.
3. Выполнение целевого действия
Поскольку пример должен быть хоть сколько-то конкретным, поступим так же, как в Hello World: отправим запрос в Slack. Но чтобы показать это не через готовую ноду интеграции со Slack, сделаем это через произвольный HTTP Request.
Для этого нам потребуется документация по Slack API — https://api.slack.com/methods/chat.postMessage
Стоит на основе документации собрать примерный JSON, который мы будем отправлять. Погнали:

Из списка регулярных нод выбираем HTTP Request.
Далее выбираем, какой тип запроса будем отправлять и куда.
(Надо бы, конечно, ещё и Credentials указать, но опять-таки на гифке я ими светить не буду).
После чего меняем тип отправляемых данных на Raw Parameters. Это нужно, чтобы работать над всем JSON’ом сразу, а не над каждым ключом-значением по отдельности.
В Body Parameters переключаемся из Fixed на Expression, что позволяет нам работать с переменными в теле отправляемого запроса.
Вставляем в Body Parameters нашу JSON заготовочку.
И вот теперь — самая большая магия. Когда мы только добавили новую ноду, ей ещё неоткуда взять данные, кроме как из глобальной области видимости. Поэтому мы протягиваем стрелочку из предыдущей ноды к текущей. Это значит, что данные, которые предыдущая нода выдала по итогам своей работы, эта нода получает в качестве входящего аргумента Input Data.
Возвращаемся в редактирование тела запроса, добавляем переменные и просто выбираем данные из JSON’a, которые нужно использовать.
Можем тестить!
4. Проверка целевого действия
А вот теперь можно нажать кнопку Execute WorkFlow, чтобы проверить, как будут работать обе ноды, вместе взятые. Хотя, если вам лень повторять всё с нуля, можно просто нажать на Execute node над целевой нодой, тогда она постарается произвести действие на основе имеющихся данных.
Мне интересней было показать, как работают вместе сразу несколько нод.

Вуаля, данные в целевую систему доставлены.
5. Что дальше?
Дальше вы можете обработать ошибки, разветвить ваш WorkFlow на выполнение разных действий в зависимости от того, всё ли пошло по плану или нет. Выполнить какие-то пост целевые действия, например передвинуть задачу в статус Complete или как-то отметить в системе, породившей триггер, что нужные действия по этому триггеру выполнены. В общем, всё, на что хватит вашей фантазии.
Однако вместо того, чтобы продолжать развивать конкретно эту автоматизацию, я лучше расскажу вам, что ещё тулза умеет делать.
Автоматизируем без кода или все таки с кодом?
Для тех, кто дочитал до этого момента, должен признаться: в заголовке я немного не договорил: в n8n можно писать код на JS. Иногда это сильно проще, чем конструировать пачку из 5-10 нод, которые сделают то же самое.
Подозреваю, что это сделано через банальный eval()

Единственное, что у вашей кастомной функции будет только 1 входящий аргумент. Но у неё всё также есть доступ к любым данным в автоматизации через глобальную область видимости по ключу нод.
(У некоторых готовых нод входящих аргументов может быть несколько, например, у Merge).
Работа с данными
Первый банальный вопрос, который может прийти в голову, касается работы с массивами объектов.
Вот, скажем, сходил я куда-то по API, а оно мне выплюнуло под 200 сущностей: как я буду их итерировать в этом вашем n8n?
Ответ — легко. В этом вам поможет нода Item List. Указываем ей поле массива, и она бьёт его на итемы.

На входе в ноду был 1 элемент, например, полученный по API, а на выходе из ноды имеем, скажем, 377 элементов. Которые мы потом можем условиями разбить на два отдельных потока, а потом вернуть в 1 общий с помощью ноды Merge.
На схеме WorkFlow это выглядит вот так:

Мы отправили запрос, получили кучу данных в едином ответе, разбили эту кучу на два потока, проверили некие данные в одном из потоков, потом смешали всё обратно для получения финальной выборки данных, с которыми надо что-то сделать.
Перед целевым действием с каждым элементом списка мы используем ноду SplitInBatches. А чтобы не обвалить API, принимающие наши запросы по RateLimit, добавляем перед каждым обращениям к этим API - Wait.

Писать далее про функциональность инструмента можно ещё долго, но в целом, я надеюсь, картинка уже начала складываться. Чем описывать каждую готовую ноду и интеграцию, лучше попытаться уловить самую суть этого инструмента.
Всё, что мы делаем в n8n — процедуры обработки данных, взаимодействие с сервисами по API, обработка ошибок, взаимодействие с базами данных, кешем, брокерами сообщений — делается точно так же, как в программировании. По сути мы и занимаемся программированием, просто без кода и разработчиков.
Или мы становимся в таком случае разработчиками?
Пожалуй, это уже риторический вопрос. Пойдём дальше.
Область применимости
Официально сами разработчики инструмента говорят, что его основные области применения это:
Межсистемные интеграции.
BackEnd прототипирование.
Автоматизации бизнес процессов.
Экономия на ресурсах разработчиков.
За ~ полгода применения инструмента в Каруне мы активно использовали его для межсистемных интеграций и автоматизации бизнес процессов.
Суммарно мы связали с его помощью 7 систем:
Таск трекер (Jira)
Мессенджер (Slack)
Систему учёта кадров для HR
Систему ведения кандидатов для рекрутинга
Сервис отправки e-mail
AirTable
GitLab.
И не планируем на этом останавливаться. На основе действий и событий в любой из этих систем мы можем совершать действия в любой другой системе.

Некоторые из этих интеграций были не сильно сложнее, чем Hello World примеры выше, а некоторые были крайне масштабными. Но они в свою очередь принесли и гораздо больше ценности. Например, одна из бизнес команд больше не ставит задачи коллегам вручную, теперь это происходит полностью автоматически.
Отчасти инструмент действительно помогает экономить ресурсы разработчиков. Так, например, пока лид команды Go размышлял на Habr “Заменит ли no-code программистов?”, мы уже отжали у его команды целый интеграционный сервис и полностью перевели его на n8n. И прямо сейчас отжимаем второй, высвобождая ресурсы его команды от их поддержки на написание новых статей на Habr, на разработку более ценных для бизнеса задач.
А вот что не входит в область применимости инструмента, это всё, где пользователям требуется интерфейс. Как только они говорят, что вот у них есть гугл табличка, и они хотели бы работать не с ней, а в новой системе с интерфейсом — забудьте про n8n. Тут вам потребуется что-то другое. У нас такие задачи уходят либо в продуктовые команды, либо, если там нужно что-то накостылить в крайне сжатые сроки — к сервисной WordPress команде.
Подводные камни и выученные уроки
Тестовое окружение. Скорее всего, вы удивитесь тому, насколько в вашей инфраструктуре мало тестовых окружений ключевых сервисов и инструментов, которые разрабатывали не вы. Поэтому, как можно раньше задавайте вопрос: а есть ли тестовый стенд или песочница на проде для тестирования предстоящей интеграции?
Чтобы не столкнуться с тем, что вы уже изучили API нужного инструмента, начали писать автоматизацию, и тут выясняется…
Техдолг. Как и с разработкой, после того, как вы решите проблему, вы, скорее всего, поймёте, что решили её неоптимально, и неплохо бы провести рефакторинг, решить немного техдолга, и вот это всё.
Не спешите заниматься преждевременной оптимизацией. Скорее всего, вы не принесёте этим никакой пользы бизнесу, и лучше заняться этим, как только вы получите в работу новую задачу, связанную с тем же сервисом/интеграцией.
Прозрачность. Бизнес понятия не имеет, что вы можете автоматизировать, а что нет. Поэтому вам стоит быть проактивными. Если вы видите какую-либо возможность для автоматизации — говорите об этом бизнесу. Со временем его нейронка осознает и выучит, что можно, а что нет.
Уведомите о своих возможностях всех, чтобы разные коллеги (бизнес-аналитики, проектные менеджеры, архитекторы, солютион менеджеры и т.д.), ответственные за решение проблем в бизнесе, знали, что у них появилась новая опция, как эти самые проблемы решать.
Почему бы просто не написать код?
Всё описанное — это, конечно, классно и весело, но зачем так запариваться, если можно просто написать немного кода, который будет делать то же самое?

Лично для меня как ответственного за инжиниринг процессов и их автоматизацию в Каруне одна из самых важных вещей — это:
Скорость
Я прикидывал, сколько бы времени у меня заняло создать новый репозиторий под новый сервис, подтащить джентльменский набор любимых фреймворков, написать некую кор часть про всякую там инициализацию, роутинг запросов. Поднять Vault, начать подтягивать из него credentials для авторизаций, установить либы для работы с требуемыми сервисами, написать наконец-то бизнес логику, обернуть в докер, отдать админам для разворачивания в прод.
В n8n автоматизацию я за это время успею сделать раз 5-6. Никакого Core писать не надо. Он уже есть — сразу как сервис развёрнут. Никаких зависимостей тащить не надо, они уже вшиты в коробку. Vault или аналог не нужен, он там свой. Либы для интеграций вшиты в коробку. Я просто открываю инструмент и попадаю на экран создания нового WorkFlow. Никакого деплоя, оркестрации, просто начни работать и приносить ценность.
Я как специалист могу не думать о лишнем и сконцентрировать своё внимание на главном — решении бизнес проблем. А высвободившееся время тратить на более глубокий и скрупулезный анализ поступающих заказов.
Низкий порог вхождения
Решать бизнес задачи через n8n может начать Project Manager или Бизнес-Аналитик, которые никогда в своей жизни кода не писали, но уже пару лет просто работают в IT и представляют, что к чему. Особенно, когда объяснять нюансы коллегам сильно дольше, чем просто “пойти и сделать”.
А если у вас есть техлиды сервисов, например, главный Jira Admin, или админ ERP системы, они с удовольствием научатся юзать этот инструмент так, чтобы у него появились “голова и руки” — и через них можно решать ценные для бизнеса задачи, которые раньше были Out of Scope. Научатся пользоваться этим инструментом — и для них откроется целый мир возможностей.
Вероятно, далеко не все задачи и интеграции они будут решать самостоятельно, и кое-где вам всё-таки придётся прийти им на помощь и написать пару строчек волшебного кода, но это просто капля в море.
Надёжность
Вы можете рассматривать каждую отдельную автоматизацию как независимый микросервис. Если она перестанет работать — с остальными ничего не случится. А сам n8n можно легко горизонтально масштабировать по мере роста.
Автодокументация
Правильно называем каждую node в вашем Automated WorkFlow. Делаем скриншот, вставляем его в документацию. Всё. Проще некуда. На этих скриншотах будет достаточный уровень детализации, чтобы обсуждать изменения как с бизнесом, так и с инженерами.
Возможно, для некоторых представителей бизнеса это будет слишком глубокое погружение, но, как правило, это работает.
Итого
Надеюсь, я хотя бы смог вас этим заинтересовать, и у вас появилось желание развернуть тулзу локально и поиграть с ней самостоятельно.
Мне было куда важнее показать, что этот инструмент — не просто очередная модная игрушка на рынке, а вполне рабочая тулза для применения в живой IT компании, которая позволяет приносить ценность и автоматизировать процессы.
Если же вам хочется больше деталей, конкретных решенных кейсов, примеров обработок ошибок, и так далее, и тому подобное — пишите, отвечу в комментариях, или накатаем с коллегами отдельный материал.