

Если вы следили за мнениями специалистов в data science и прогностической аналитики, то, скорее всего, сталкивались с рекомендациями использовать машинное обучение. Как рекомендует Джеймс Ходсон в Harvard Business Review, умнее всего будет стремиться к решению самой лёгкой задачи, а затем масштабировать процессы на более сложные операции.
Недавно мы обсуждали платформы machine-learning-as-a-service (MLaaS). Основной вывод из современных тенденций прост: машинное обучение становится более доступным для средних и мелких бизнесов, постепенно превращаясь в массовый товар. Ведущие поставщики (Google, Amazon, Microsoft и IBM) предоставляют API и платформы для выполнения основных операций ML без собственной инфраструктуры и большого опыта в data science. На первых этапах самым умным шагом будет выбор такого гибкого и экономного подхода. С ростом возможностей аналитики можно изменять структуру команды для ускорения её работы и расширения арсенала аналитики.
В этот раз мы поговорим о структуре команд data science и их сложности.
Команды, формируемые для обработки данных
Самые успешные data-driven-компании решают сложные задачи data science, включающие в себя исследования, использование различных моделей ML, специализированных на различных аспектах процесса принятия решений или применение множества сервисов с поддержкой ML. В случае крупных организаций, команды data science могут выполнять поддержку различных структурных подразделений и работать в рамках их конкретных областей аналитических интересов. Очевидно, что специализированные команды data science, собранные под решение конкретных задач, могут сильно отличаться друг от друга.
Краткое описание ролей в data science
Для примера давайте рассмотрим команду data science Airbnb. Чтобы глубже понять, как компания создаёт свою культуру, вы можете посмотреть этот доклад дата-саентиста Airbnb Мартина Дэниела или прочитать пост бывшего руководителя отдела DS, но если вкратце, то в компании применяются три основных принципа.
Эксперимент. Поиск способов использования данных в новых проектах при помощи сложившегося процесса «изучение-планирование-тестирование-измерение».
Демократизация данных. Масштабирование команды data science на всю компанию и даже на клиентов.
Измерение влияния. Оценка степени участия команд DS в процессе принятия решений и признание их заслуг.
Эти три принципа довольно часто применяются техническими руководителями, поскольку они позволяют принимать решения на основе данных. Однако для их соблюдения у вас должна быть чёткая стратегия и понимание того, из кого состоят эти команды и как они встроены в организационные структуры.
Для успешной обработки данных критически важно иметь подходящих сотрудников. Каких людей вам стоит искать?
Роли в команде data science
Давайте поговорим о спектре навыков дата-саентистов. К сожалению, в последнее время понятие «дата-саентист» расширилось и стало слишком размытым. После того, как data science привлекла внимание бизнеса, не выработалось консенсуса о том, каким спектром навыков должен обладать дата-саентист. Дата-саентист и заместитель редактора KDNuggets Мэттью Майо говорит следующее: "Когда я слышу выражение «дата-саентист», то обычно представляю единорога, но потом вспоминаю, что их не существует, и что реальные дата-саентисты выполняют в организациях множество разнообразных ролей, с разным уровнем деловых, технических, коммуникативных, личностных и функциональных навыков."
И это правда. «Единорогов» найти сложно, но можно вырастить их из людей, имеющих нишевый опыт в data science. Наша компания при найме специалистов по машинному обучению учитывает следующие навыки data science:
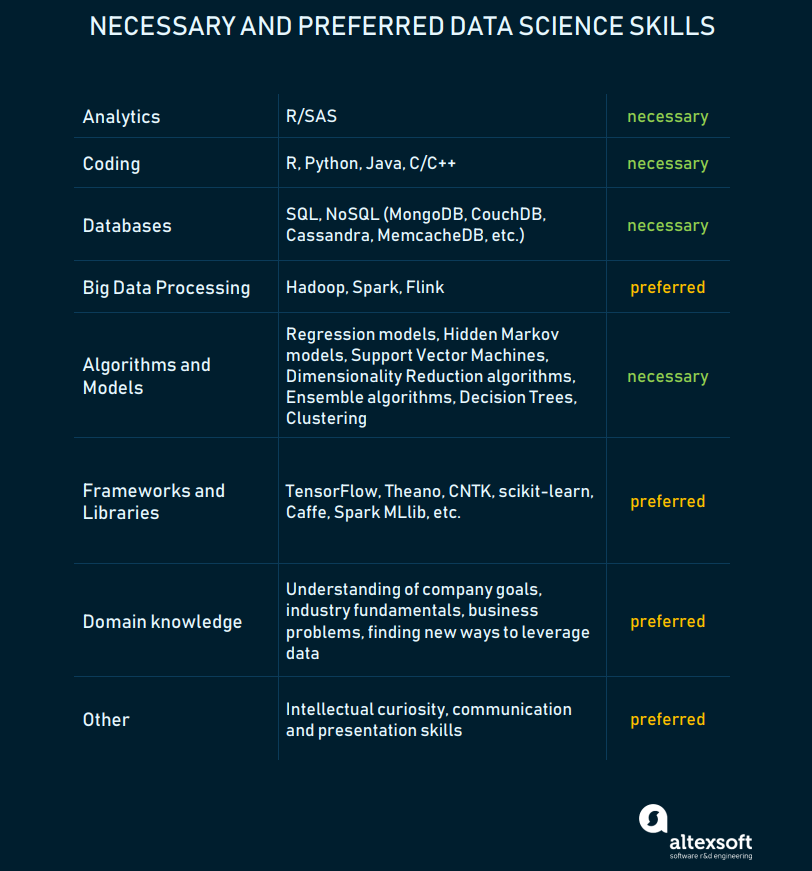
Спектр навыков дата-саентиста
Как будет показано ниже, в экосистеме data science существует множество ролей, а в Интернете представлено множество классификаций. Мы расскажем об одной из них, описанной Майклом Хохстером из Stitch Fix. Майкл разделяет дата-саентистов на два типа: тип A и тип B.
Тип A означает Analysis (анализ). Этот человек — статистик, он разбирается в данных, необязательно имея большие знания в программировании. Дата-саентисты типа A выполняют очистку данных, прогнозирование, моделирование, визуализацию и так далее.
Тип B означает Building (разработка). Эти люди используют данные в продакшене. Они превосходные разработчики ПО, имеющие опыт в создании систем рекомендаций, персонализации и так далее.
Один специалист редко относится к какой-то одной категории, но понимание этих двух функций в data science поможет вам разобраться в ролях, которые описаны ниже.
Помните, что даже профессионалы с этим гипотетическим набором навыков имеют свои сильные стороны, которые следует учитывать при распределении ролей в команде. В большинстве случаев, после найма сотрудника следует обучение в зависимости от его квалификации.
Однако люди и их роли — это две разные вещи. Например, если вы используете интегрированную модель команды, один человек может сочетать в себе несколько ролей. Так что можно не обращать внимания на то, сколько реальных специалистов у вас есть, и описать сами роли. Разумеется, многие из навыков между разными ролями могут пересекаться.
Chief Analytics Officer/Chief Data Officer. В нашей технической статье о машинном обучении мы обобщённо рассмотрели эту важнейшую руководящую роль. CAO, «бизнес-переводчик», ликвидирует пробел между data science и опытом в предметной области, действуя и как визионер, и как технический руководитель. Лучше понять его предназначение можно, взглянув на показанную ниже визуализацию.
Предпочтительные навыки: data science и аналитика, навыки программирования, знания предметной области, навыки лидера и визионера
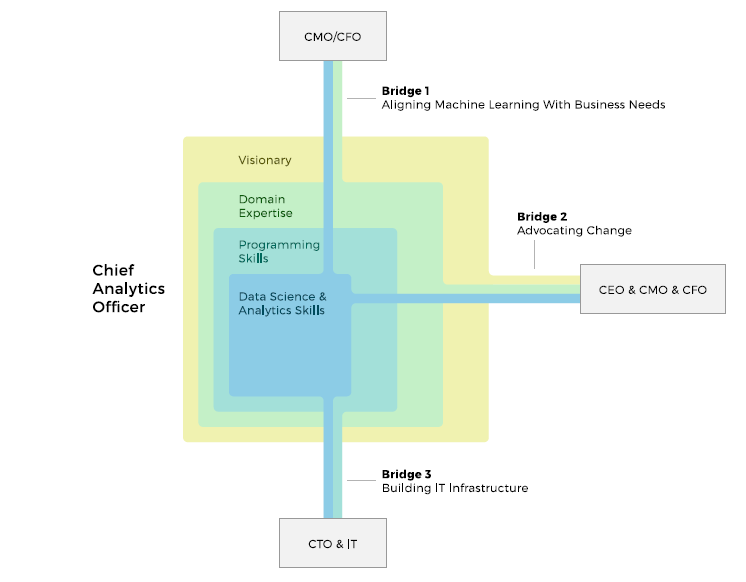
Роль Chief Analytics Officer
Аналитик данных. Эта роль подразумевает работу по сбору данных и их интерпретации. Аналитик обеспечивает релевантность и подробность всех собираемых данных, а также интерпретирует результаты аналитики. Некоторые компании, например, IBM и HP, также требуют, чтобы аналитики данных имели навыки визуализации для преобразования пугающих чисел в осязаемые выводы в графиках.
Предпочтительные навыки: R, Python, JavaScript, C/C++, SQL
Бизнес-аналитик. По сути, бизнес-аналитик осуществляет функции CAO, но на операционном уровне. Под этим подразумевается преобразование ожиданий бизнеса в анализ данных. Если вашему основному дата-саентисту не хватает знаний в предметной области, бизнес-аналитик ликвидирует этот пробел.
Предпочтительные навыки: визуализация данных, business intelligence, SQL
Дата-саентист (не «единорог» data science). Чем занимается дата-саентист? (Будем считать, что вы не охотитесь на «единорогов».) Дата-саентист — это человек, решающий задачи бизнеса при помощи техник машинного обучения и data mining. Если это кажется слишком расплывчатым, то роль можно сузить до подготовки и очистки данных с дальнейшим обучением и оценкой модели.
Как работает подготовка данных в машинном обучении
Предпочтительные навыки: R, SAS, Python, Matlab, SQL, noSQL, Hive, Pig, Hadoop, Spark
Чтобы не запутаться и сделать поиск дата-саентиста менее утомительным, его должность часто разбивается на две роли: инженер машинного обучения и журналист данных.
Инженер машинного обучения сочетает навыки разработки ПО и моделирования, определяя, какую модель использовать и какие данные должны использоваться для каждой модели. Также его сильной стороной являются вероятности и статистика. Всё, что касается обучения, мониторинга и обслуживания модели — задача инженера ML.
Предпочтительные навыки: R, Python, Scala, Julia, Java
Объяснение роли инженера ML за двенадцать минут
Журналисты данных помогают разбираться в выводимых данных, перенося их в нужный контекст. Также они занимаются формулированием задач бизнеса и превращением результатов аналитики в наглядные истории. Хотя им и требуется опыт в кодинге и статистике, они должны уметь презентовать идею владельцам бизнеса и быть представителями команды обработки данных для тех, кто не умеет работать со статистикой.
Предпочтительные навыки: SQL, Python, R, Scala, Carto, D3, QGIS, Tableau
Архитектор данных. Эта роль критически важна для работы с большими объёмами данных (да, с Big Data). Однако если вы не пользуетесь исключительно облачными платформами MLaaS, она также критически важна в хранении данных, создании архитектуры баз данных, централизации данных и обеспечении целостности между различными источниками. Также архитектор отвечает за производительность в крупных распределённых системах и больших массивах данных.
Предпочтительные навыки: SQL, noSQL, XML, Hive, Pig, Hadoop, Spark
Дата-инженер. Инженеры реализуют, тестируют и поддерживают инфраструктурные компоненты, проектируемые архитекторами данных. В реальности роль инженера и архитектора может сочетаться в одном человеке. Спектры их навыков очень близки.
Предпочтительные навыки: SQL, noSQL, Hive, Pig, Matlab, SAS, Python, Java, Ruby, C++, Perl
Чтобы подробнее узнать об дата-инжиниринге в целом, посмотрите это видео с объяснениями:
Что такое дата-инжиниринг?
Инженер приложений/визуализации данных. По сути, эта роль необходима только в специализированной модели data science. В остальных случаях доставку результатов data science в приложениях, с которыми взаимодействуют конечные пользователи, обеспечивают разработчики ПО из ИТ-отделов. И с большой вероятностью инженер приложений или другие разработчики из отделов фронтенда будут заниматься и визуализацией данных для конечных пользователей.
Предпочтительные навыки: программирование, JavaScript (для визуализации), SQL, noSQL.
Сбор и определение масштабов команды
Первоначальной проблемой при найме сотрудников в data science, наряду с общим дефицитом специалистов, являются высокие зарплатные ожидания. Согласно O’Reilly Data Science Salary Survey 2017, медианная базовая зарплата за год составляла $90 тысяч, а на момент обновления этой статьи в США этот показатель достиг $112774. Эти числа сильно варьируются от географического положения, конкретных технических навыков, размеров организации, гендера, отрасли и образования. Если вы решили нанимать опытных специалистов в аналитике, возникнут и дополнительные сложности с их привлечением и удержанием.
Без сомнения, большинство дата-саентистов стремится работать в компании, где можно решать интересные задачи, но не каждая компания похожа на Facebook, Netflix или Amazon. Однако потребность в выполнении задач, связанных с данными, заставляет организации привлекать дата-саентистов на должности начального уровня. Таким образом, найм сотрудника с широкими познаниями, образованием в точных науках и опытом работы с данными, как советует Дэниел Танкеланг — многообещающий выбор на начальных уровнях использования машинного обучения. Такой подход подразумевает переход на дальнейших этапах к сильным и более узким специалистам. Они заменяют рудиментарные алгоритмы новыми и развивают системы на регулярной основе.
Ещё один способ решения проблемы дефицита специалистов и ограничений бюджета — разработка доступных платформ машинного обучения, которые будут привлекать новых людей из ИТ и обеспечат возможность дальнейшего масштабирования. Даже если найм опытных дата-саентистов невозможен, некоторые организации могут обойти это препятствие, наладив связи с образовательными учреждениями. В США есть около десятка программ Ph.D., делающих упор на data science, и множество буткемпов с курсами длительностью около года.
Как интегрировать команду data science в свою компанию
В процессе роста команды data science вместе с потребностями компании возникает необходимость в создании совершенно нового отдела, который нужно организовать, контролировать и отслеживать, а также управлять им. Это масштабное организационное изменение означает, что у новой группы должны быть установленные роли и обязанности, в то же время связанные с другими проектами и подразделениями. Как же интегрировать дата-саентистов в компанию?
Мы возьмём за основу ключевые типы классификации Accenture и подробнее расскажем о структуре команды.
Децентрализованная
Это наименее координируемый вариант, при котором аналитическая работа используется в организации спорадически, а ресурсы выделяются под каждую функцию группы. Такое часто происходит в компаниях, когда опыт в data science возникает органическим образом. Структурные подразделения наподобие продуктовых команд или функциональные подразделения на определённом этапе выявляют внутреннюю потребность в аналитике. Они начинают нанимать дата-саентистов или аналитиков, способных удовлетворить эту потребность. Иногда дата-саентист может быть единственным человеком с опытом анализа данных в кросс-функциональной продуктовой команде.

Децентрализованная реализация.
Децентрализованная модель лучше всего подходит для компаний, не намеревающихся превращаться в data-driven-компанию. Также эта модель может применяться на ранних этапах операций data science для кратковременного прогресса в демонстрационных проектах с использованием расширенной аналитики.
Эта модель обладает следующими недостатками:
- Часто приводит к стремлению к созданию бункеров данных (silo), отсутствию стандартизации аналитики и децентрализованной отчётности.
- Проблемой становится процесс найма. Когда менеджеры нанимают в свою команду дата-саентиста, им сложно провести с ним качественное собеседование. Они чётко представляют, допустим, типичные роли, обязанности и навыки разработчиков ПО, однако в data science им они неизвестны. Поэтому это вызывает у них сложности.
- Проблематично и управление карьерным путём дата-саентиста. Менеджеры команд совершенно чётко понимают, как повышать разработчика ПО, однако дальнейшие шаги для дата-саентистов могут вызывать вопросы. Та же проблема возникает и при создании плана индивидуального развития.
- Часто встречаются низкие стандарты качества и недооценка накопленного в этой сфере опыта. Дата-саентисты должны получать знания при менторстве других дата-саентистов. Поскольку в этой модели такая возможность отсутствует, дата-саентисты могут остаться без помощи. Обычно это приводит к отсутствию улучшений в накопленном опыте, что зачастую снижает качество данных и качество продукта в целом.
Функциональная
Большинство аналитиков работает в одном функциональном подразделении, где аналитика наиболее важна. Часто это отдел маркетинга или снабжения. Из этого следует низкий уровень координации или полное её отсутствие, а опыт не используется стратегически в рамках всей компании.
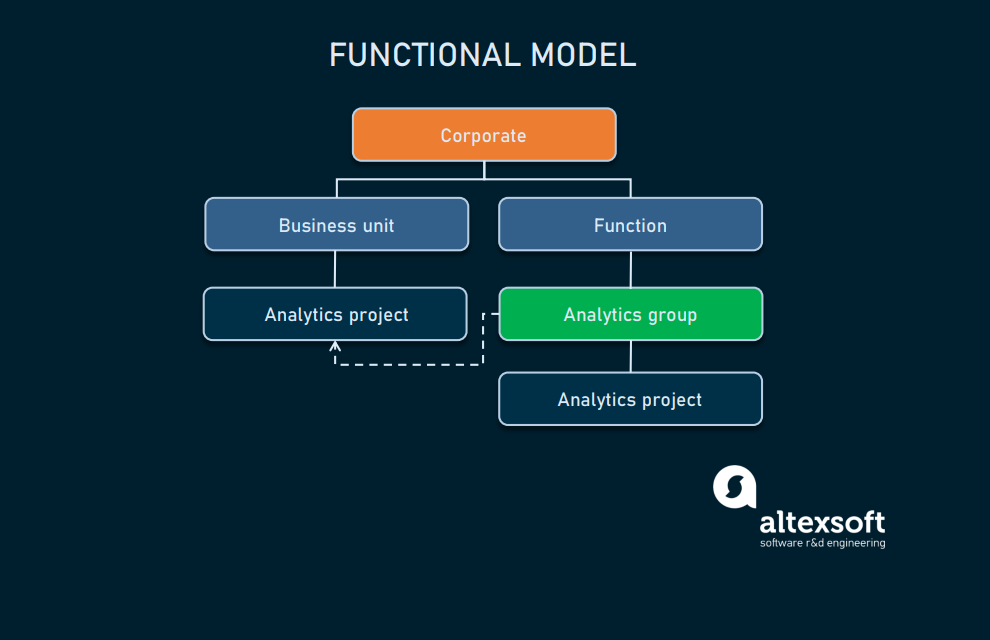
Функциональная реализация
Функциональная модель лучше всего подходит для организаций, только встающих на путь аналитики. У них нет потребности анализировать данные от каждой точки, а значит, не так много аналитических процессов, чтобы создавать отдельную и централизованную команду data science для всей организации.
Недостатки функциональной модели таятся в её централизованной природе.
- Команда оторвана от проблем компании в целом. При такой модели аналитика в основном сосредоточена на функциональных потребностях, а не на нуждах всей компании. Подобная неосведомлённость может привести к изолированию аналитики и к её выпадению из контекста.
- Низкий уровень единства из-за отсутствия менеджера данных. Так как аналитическая команда в этом случае подчинена конкретному подразделению, она отправляет отчёты непосредственно главе этого подразделения. Из-за этого может и не быть непосредственного менеджера data science, понимающего специфику своей команды.
Консультационная
При такой структуре команда аналитиков работает как одна группа, но из задача в организации заключается в консультировании, то есть разные отделы могут «нанимать» её под конкретные задачи. Разумеется, это означает практически полное отсутствие распределения ресурсов — специалист или доступен, или нет.
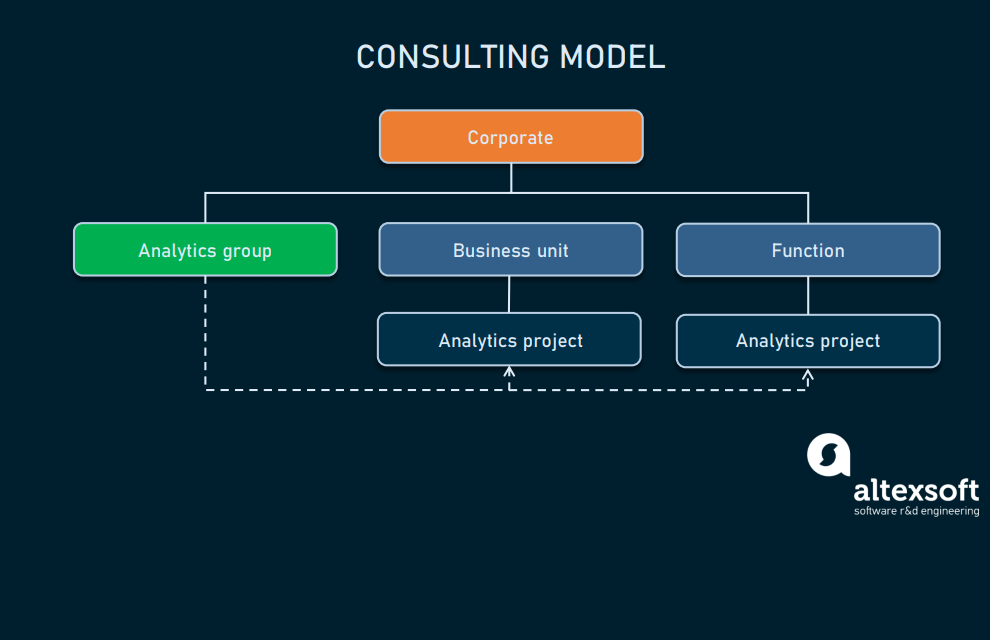
Консультационная реализация
Консультационная модель лучше всего подходит для компаний малого и среднего бизнеса, у которых время от времени возникают задачи data science мелкого или среднего масштаба. поскольку все члены команды DS подчиняются и отчитываются одному менеджером команды DS, для малого и среднего бизнеса управление такой командой DS становится проще и дешевле.
Однако всегда есть недостатки.
- Во-первых фундаментальным изъяном такой модели может стать низкое качество данных. Поскольку дата-саентисты не могут применять свой наработанный опыт в каждой из задач, они могут пожертвовать качеством в угоду потребностям бизнеса, требующего быстрых решений.
- Кроме того, существует ловушка низкой мотивации. Так как дата-саентисты не вовлечены полностью в создание продукта и принятие решений, у них практически нет заинтересованности в результате.
- Серьёзным недостатком консультационной модели является неопределённость. Дедлайны не определены, потому что дата-саентисты не полностью знакомы с источниками данных и с контекстом их появления. Долговременные и сложные проекты едва ли реализуемы, поскольку для достижения хороших результатов специалисты иногда годами работают над одним набором задач.
- Также непонятен способ расстановки приоритетов. По-прежнему сложно определить, как менеджер data science расставляет приоритеты и распределяет задачи между дата-саентистами, а также каким целям нужно отдавать предпочтение.
Централизованная
Такая структура наконец-то позволяет использовать аналитику в стратегических задачах — одна команда data science работает на всю организацию в разнообразных проектах. Это не только даёт команде DS долговременное финансирование и улучшенное управление ресурсами, но и стимулирует к карьерному росту. Единственный недостаток здесь заключается в опасности превращения функции аналитики в функцию поддержки.
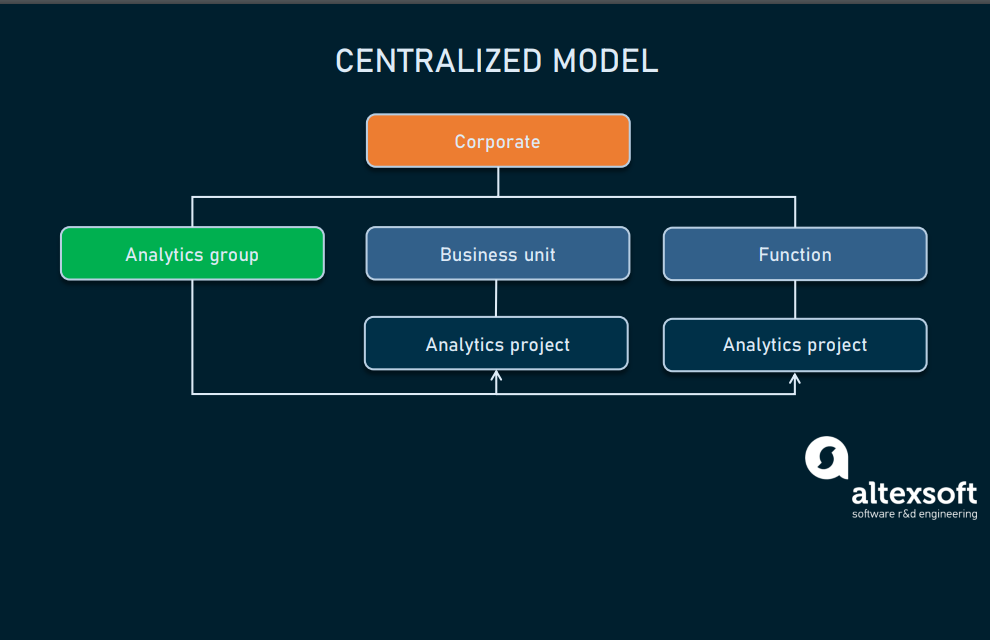
Централизованная реализация
Один из наилучших сценариев для создания централизованной команды таков: потребность в аналитике и количество аналитиков быстро растут, требуя срочного распределения этих ресурсов. Введением централизованного подхода компания показывает, что считает данные стратегической концепцией и что она готова создать отдел аналитики на одном уровне с отделом продаж или маркетинга.
Как всегда, у этой модели есть свои недостатки.
- Есть большая вероятность изоляции и возникновения разделения между командой аналитиков данных и направлениями бизнеса. Так как команда аналитиков данных не участвует в обычных операциях отделов, приносящих выгоду бизнесу, она может не быть знакома с их потребностями и проблемами. Это может привести к узкой применимости рекомендаций, которые могут оставаться неиспользованными и незамеченными.
- Это приводит к сложностям в осознанном взаимодействии в продуктовой команде. После того, как команда аналитиков найдёт способ решения проблемы, она предлагает решение продуктовой команде. Самая большая проблема здесь в том, что это решение может не помещаться в дорожную карту продукта. Таким образом, может возникнуть конфликт. Один из способов решения заключается в создании команды, которая будет оценивать, проектировать и реализовывать предложенное решение. Однако эта альтернатива требует много усилий, времени и денег.
Иногда централизованную модель называют Center of Excellence. И это нормально, всегда существуют уникальные сценарии. Однако мы будем придерживаться классификации Accenture, потому что она кажется более детализированной и подчёркивает различия между централизованной моделью и Center of Excellence.
Center of Excellence (CoE)
Если вы выберете этот вариант, то всё равно получите централизованный подход с единым центром координации, однако дата-саентисты будут размещены в разных подразделениях организации. Это самая сбалансированная структура — работа аналитиков хорошо координируется, однако специалисты не будут перемещаться из структурных подразделений.
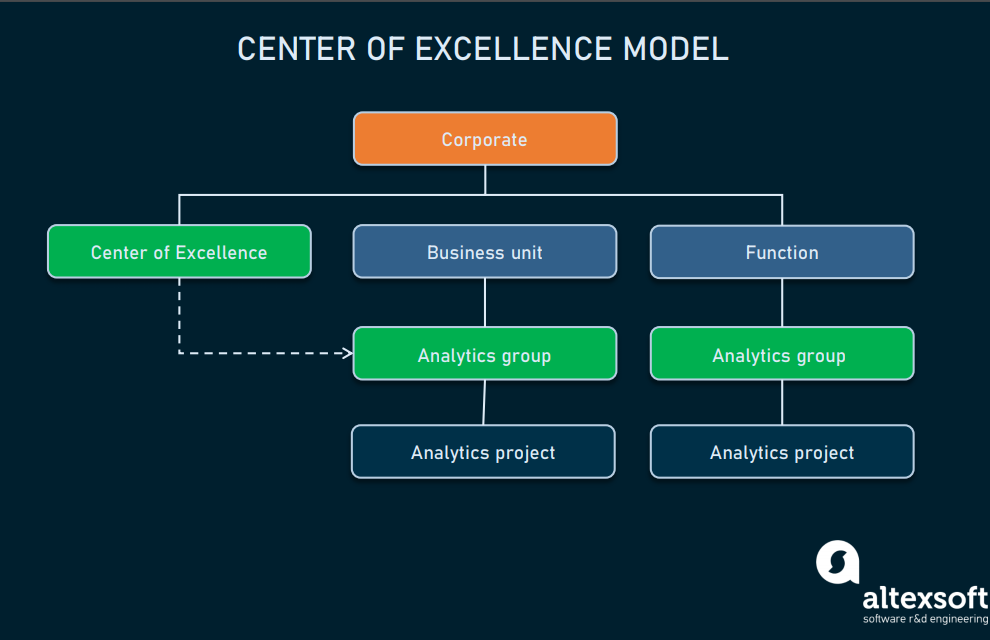
Реализация Center of Excellence
Благодаря своим хорошо сбалансированным связям, этот подход применяется всё активнее, особенно в организациях корпоративного уровня. Лучше всего он подходит компаниям с корпоративной стратегией и тщательно проработанной дорожной картой обработки данных.
Однако даже такой глубоко ориентированный на данные подход имеет свои недостатки.
- Хотя он сбалансирован, в нём отсутствует единая централизованная группа, сосредоточенная на решении задач корпоративного уровня. Каждая аналитическая группа решает задачи в рамках своих подразделений.
- Ещё один недостаток заключается в отсутствии отдела инноваций — группы специалистов, в первую очередь сосредоточенных на самых современных решениях и долговременных проектах обработки данных, а не на повседневных нуждах.
Федеративная
Эта модель релевантна, когда в компании есть растущий спрос на аналитиков. В ней используется своего рода «спецназ» — аналитическая группа, работающая из центральной точки и решающая сложные кроссфункциональные задачи. Остальные дата-саентисты распределены как в модели Center of Excellence. По сути, федеративная модель сочетает в себе подходы к координации и децентрализации модели CoE, однако с сохранением «передового» отдела.
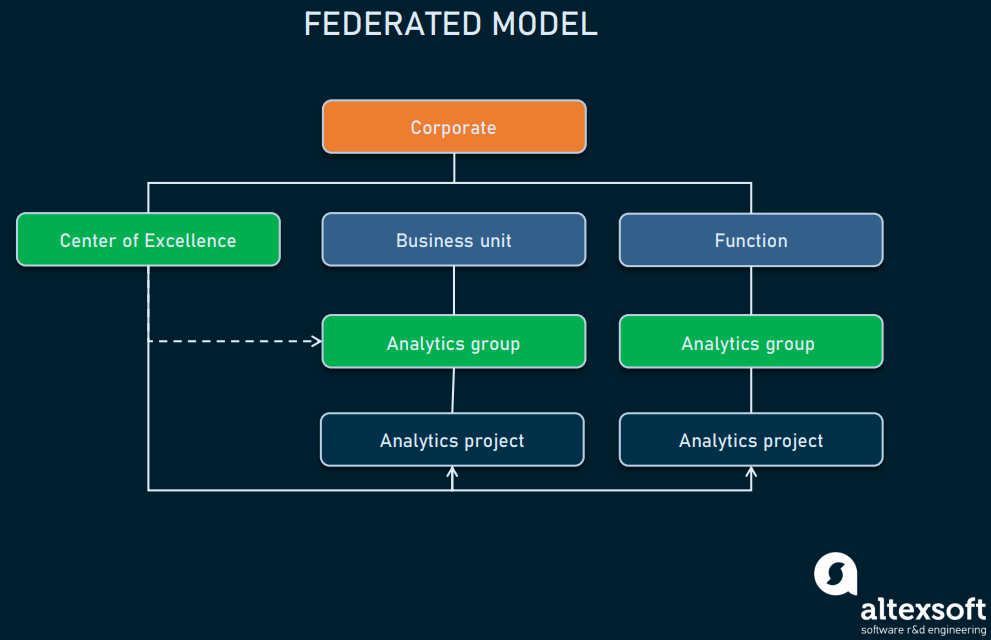
Федеративная реализация
Федеративную модель лучше всего использовать компаниям, в которых аналитические процессы и задачи имеют систематическую природу и требуют ежедневных обновлений. Такой подход может служить и для целей корпоративного уровня, например, корпоративного дизайна дэшборда, и для аналитики конкретной функции с различными типами моделирования.
На первый взгляд, федеративная модель идеальна, однако имеет некоторые недостатки.
- Затраты на найм и удержание сотрудников. Так как эта модель подразумевает наличие отдельного специалиста для каждой продуктовой команды и центрального управления данными, она может быть дорогостоящей. Следовательно, в своём чистом виде такой подход не является идеальным для компаний, находящихся на ранних этапах внедрения аналитики.
- Кроссфункциональность может создать конфликтную среду. В ней может недоставать равенства власти между всеми руководителями команд, что может приводить к отставанию от дедлайнов и к сомнительным результатам из-за постоянных конфликтов между руководителями команд подразделений и руководством CoE.
Демократическая
Эта модель — ещё один способ восприятия культуры работы с данными. При демократической модели все в организации имеют доступ к данным при помощи инструментов BI или порталов данных. Это означает, что её можно комбинировать с любой другой описанной выше моделью. Можно использовать федеративный подход с CoE и специалистами по аналитике в каждом подразделении, и в то же время сделать инструменты BI доступными для каждого, кто заинтересован в использовании данных для своих задач, что отлично с точки зрения освоения культуры работы с данными.
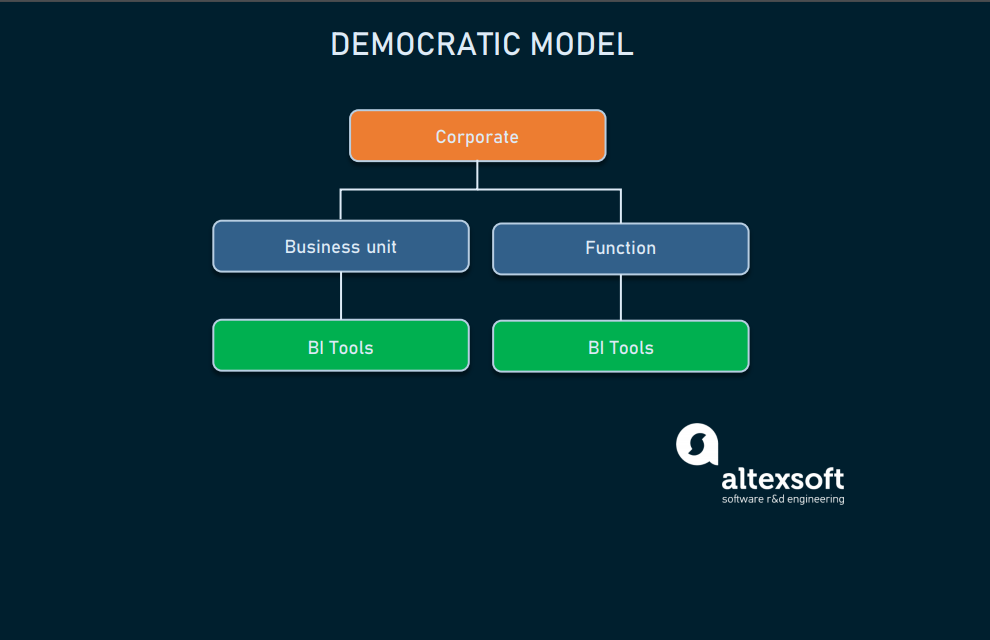
Демократическая реализация
Члены продуктовых команд, например, менеджеры продуктов и разработки, дизайнеры и инженеры получают доступ к данным напрямую, без привлечения дата-саентистов.
Каковы же недостатки?
- Компания, интегрирующая такую модель, обычно много инвестирует в инфраструктуру data science, инструментарий и обучение.
- Вам просто нужно больше людей, чтобы избегать ситуаций, когда дата-инженер занят настройкой дэшборда BI для другого торгового представителя вместо того, чтобы заниматься своей работой по дата-инжинирингу.
Помните о том, что ваша модель может меняться и эволюционировать в зависимости от потребностей бизнеса: сегодня вам может быть достаточно дата-саентистов, находящихся в своих функциональных подразделениях, а завтра необходимостью становится Center of Excellence.
Дополнительные рекомендации по построению высокопроизводительной команды data science
Ищите таланты внутри компании. Ещё до того, как начинать задумываться о найме на роли data science специалистов извне, оцените ресурсы, уже имеющиеся в компании. Узнайте, есть ли у вас сотрудники, желающие двигаться в этом направлении. Определите их навыки в data science, пробелы, которые нужно закрыть, и вложитесь в их обучение.
Меньше нанимайте людей на каждую должность, сосредоточьтесь на понимании того, какие роли может выполнять один специалист по данным. В стартапах и малых организациях обязанности могут и не быть чётко очерчены.
Взращивайте кроссфункциональные связи. Дизайнеры, маркетологи, менеджеры продуктов и инженеры должны тесно сотрудничать с командой DS.
Практикуйте встраивание. Как говорилось выше, для рекрутинга и удержания специалиста по data science требуются дополнительные действия. Одно из них — это встраивание, перевод дата-саентистов в бизнес-подразделения, чтобы они выполняли централизованную отчётность, лучше взаимодействовали и ощущали себя частью большой организации. Здесь подходят федеративная, CoE или даже децентрализованная модели.
Перед наймом команды создайте командную среду. Это значит, что менеджеры продуктов должны осознавать различия между ПО и результатами обработки данных, иметь адекватные ожидания и понимать, в чём отличия в отчётной документации и дедлайнах. Менеджеры продуктов должны иметь достаточно технических знаний для понимания этой специфики. Или же вы можете начать искать дата-саентистов, которые сразу же могут занять эту должность.
Самое важное, что нужно знать
Если вы спросите специалистов по data science из нашей компании о текущем состоянии AI/ML в разных отраслях, то они, скорее всего, скажут о двух основных проблемах: 1. Руководителей бизнеса всё ещё нужно убеждать, что разумное ROI для вложений в ML существует. 2. Если они знают это и понимают возможные выгоды и запросы рынка, то у них может недоставать технических навыков и ресурсов для реализации продуктов.
Эти барьеры в основном возникают из-за уровня цифровой культуры в организациях. Эффективные процессы работы с данными вынуждают высшее руководство осваивать горизонтальные способы принятия решений. Руководители с доступом к аналитике будут иметь больше независимости в принятии решений на основании данных, в то время как высшее руководство будет контролировать стратегию. Это снижает трудозатраты на управление и устраняет риски принятия «инстинктивных» решений. По сути, смена культурной парадигмы определяет конечный успех data-driven-бизнеса. Как пишет McKinsey, создать культуру сложнее всего, а с остальным можно справиться.
CyaN
Есть и отечественный вариант: Модель компетенций команды цифровой трансформации (ranepa.ru)