
Привет, Хабр! Меня зовут Олег, я работаю в «Лаборатории Касперского» и занимаюсь созданием нашей собственной операционной системы KasperskyOS. Если еще точнее, я — Lead Software Development Engineer in Test в подразделении, которое занимается контролем качества. Задача нашего отдела — проверять качество ядра ОС, ее компонентов и продуктов на их основе. Важную роль здесь играет непосредственно написание и прогон тестов.

В этой статье расскажу о нашей модульной обвязке для PyTest, которая позволяет запускать тесты продуктов на разном железе. Фокус в том, что тесты при этом остаются простыми, а на сдачу мы получаем трассируемость от требований к результатам прогонов тестов, написанных по данным требованиям. В итоге у нас фактически получилась замкнутая система CI/CD с наглядным качеством кода.
Как и у любой компании, которая хочет выпускать релизы регулярно, у нас есть система CI/CD. В рамках этого процесса наш отдел принимает участие в планировании, разработке кода, сборке, тестировании и, разумеется, выпуске релизов.
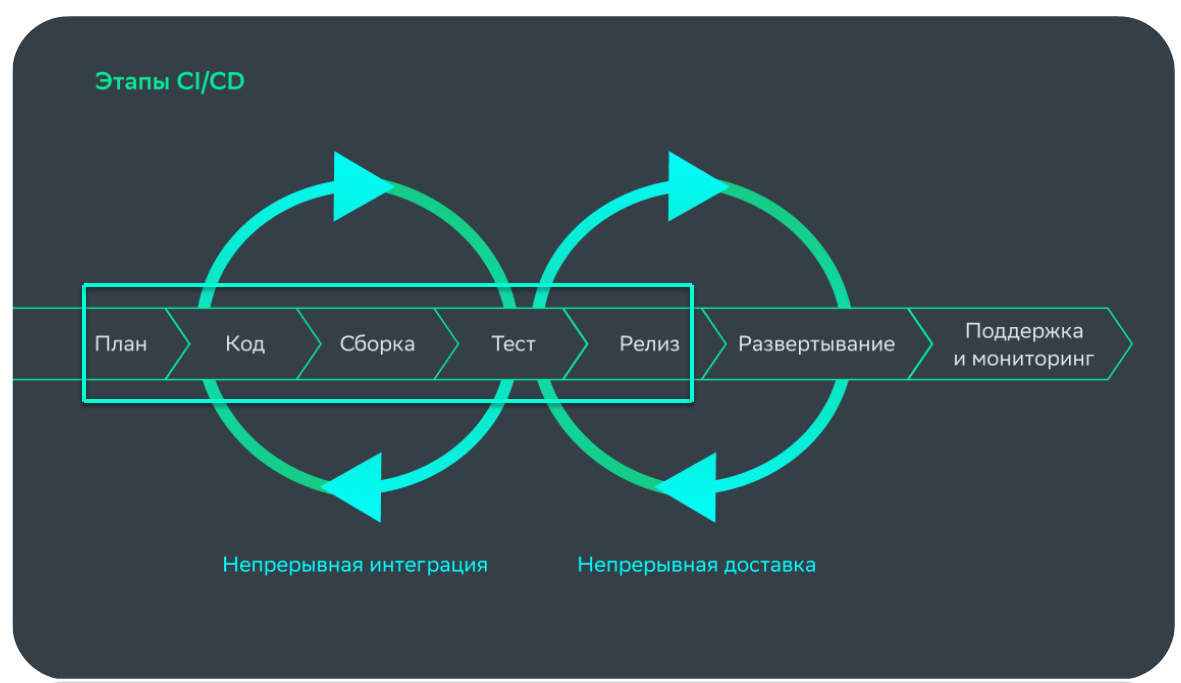
С точки зрения затронутых файлов процесс разработки у нас состоит из трех больших частей.
Первая — сборка самого ядра системы и SDK для разработчиков.
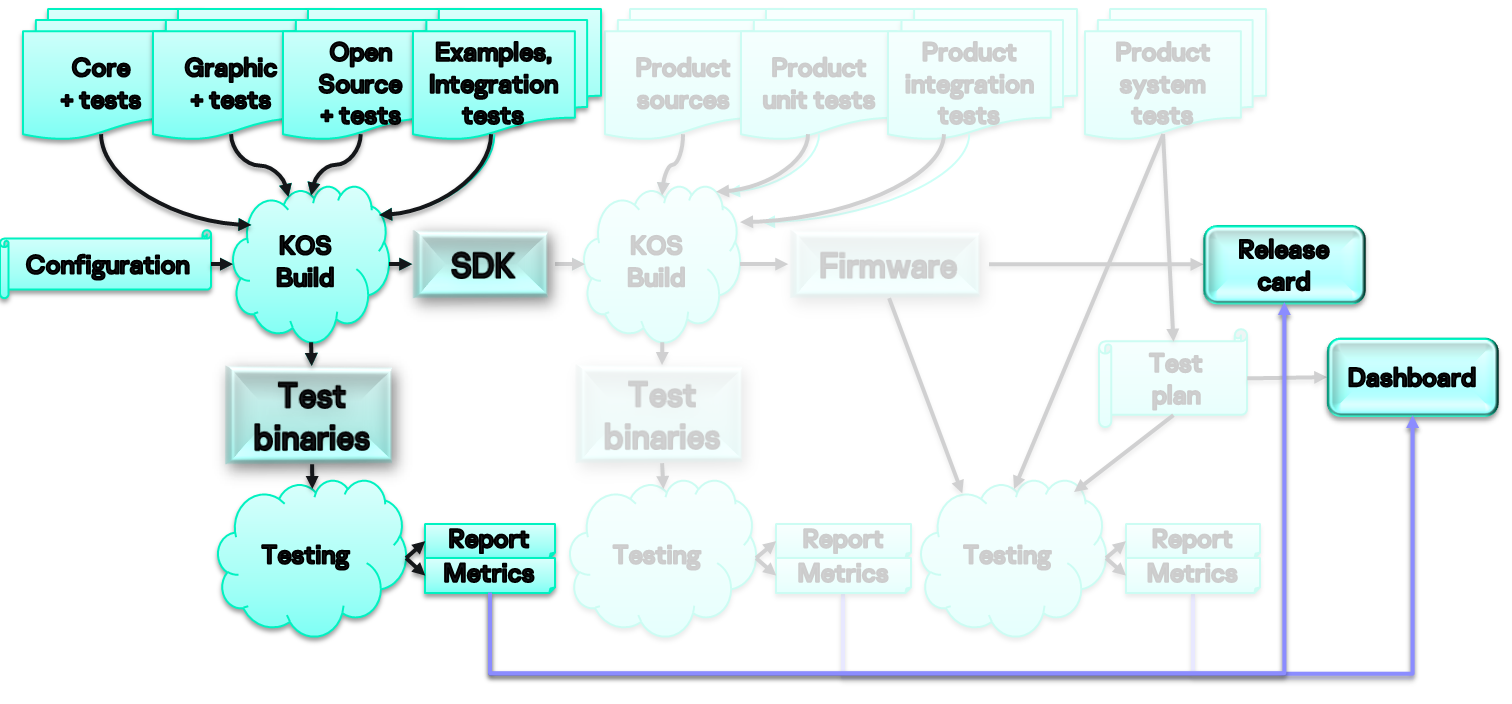
В эту часть входят исходники ядра, различных подсистем (графической, файловой, дисковой и т. п.), в том числе опенсорсные модули, а также тесты к ним и многое другое. На основе конфигурационного файла мы запускаем сборку под конкретное железо и на выходе получаем SDK для разработчиков и тестовые бинарники, которые можно загрузить на целевое железо.
В рамках тестовой сессии мы загружаем бинарники с нашей ОС на железо и в результате получаем отчеты о тестировании и метрики, которые публикуются на дашборде (для всеобщего обозрения) и в описании релиза. Метрики — важная часть нашей работы. Если они укладываются в заданные рамки, это свидетельствует об определенном уровне качества релиза.
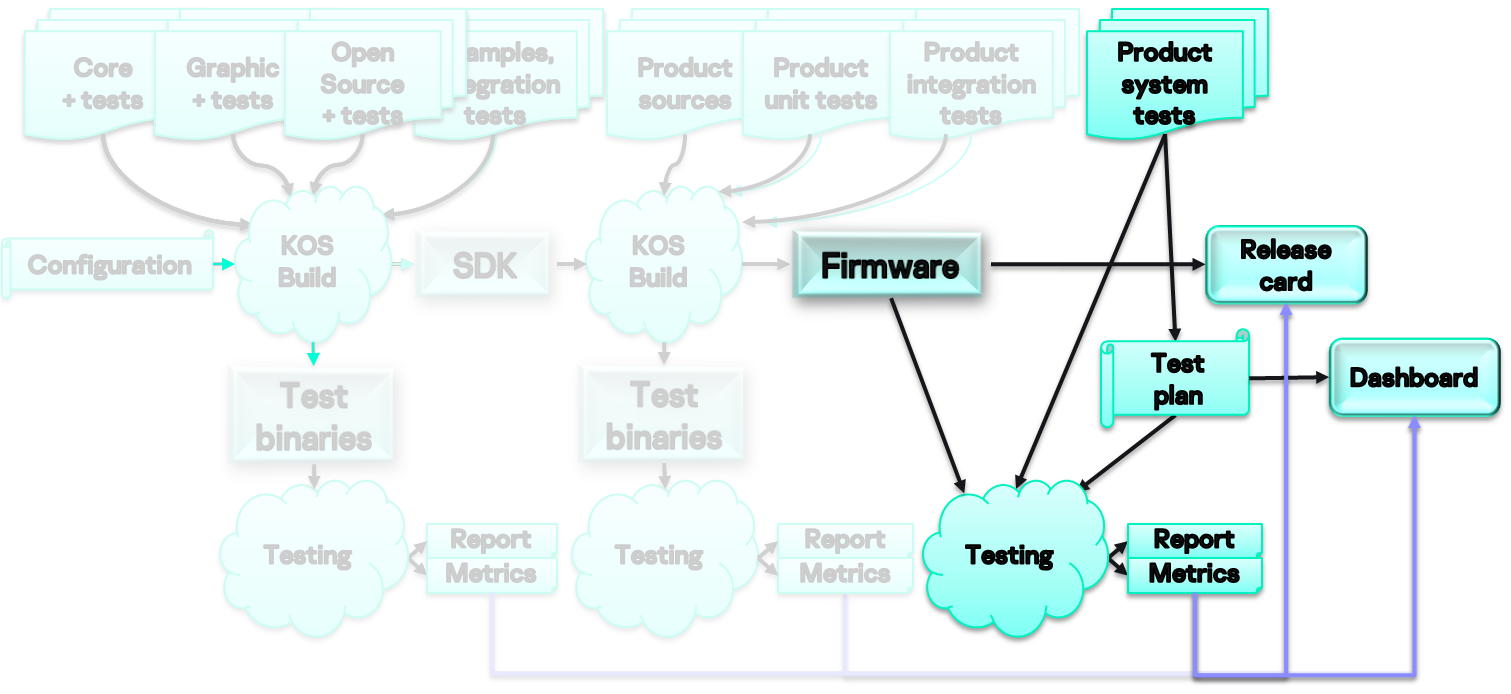
В рамках второй части на основе полученного SDK, используя продуктовые исходники, юнит-тесты к ним, интеграционные тесты и т. п., собираем прошивку для устройства, например мобильного телефона.

На этом шаге у нас появляются тестовые бинарники, которые мы можем задеплоить, запустить, проверить и прилинковать к карточке релиза или на дашборд.
Третья часть касается развития продукта. По требованиям аналитиков рождаются задачи для разработчиков, а заодно мы пишем по ним более высокоуровневые системные тесты, группируем их в тест-планы, запускаем тестовые сессии на готовых прошивках (релиз-кандидатах). В результате снова имеем отчеты и метрики.
У нас есть широкий диапазон решений на разной архитектуре — под мобильные устройства, сетевое оборудование, x86, x64, arm, risk и т. п. Чтобы проверять код на этом зоопарке железа, необходимо собрать парк тестовых стендов.
Стенды у нас есть разнообразные, но типовой выглядит так:
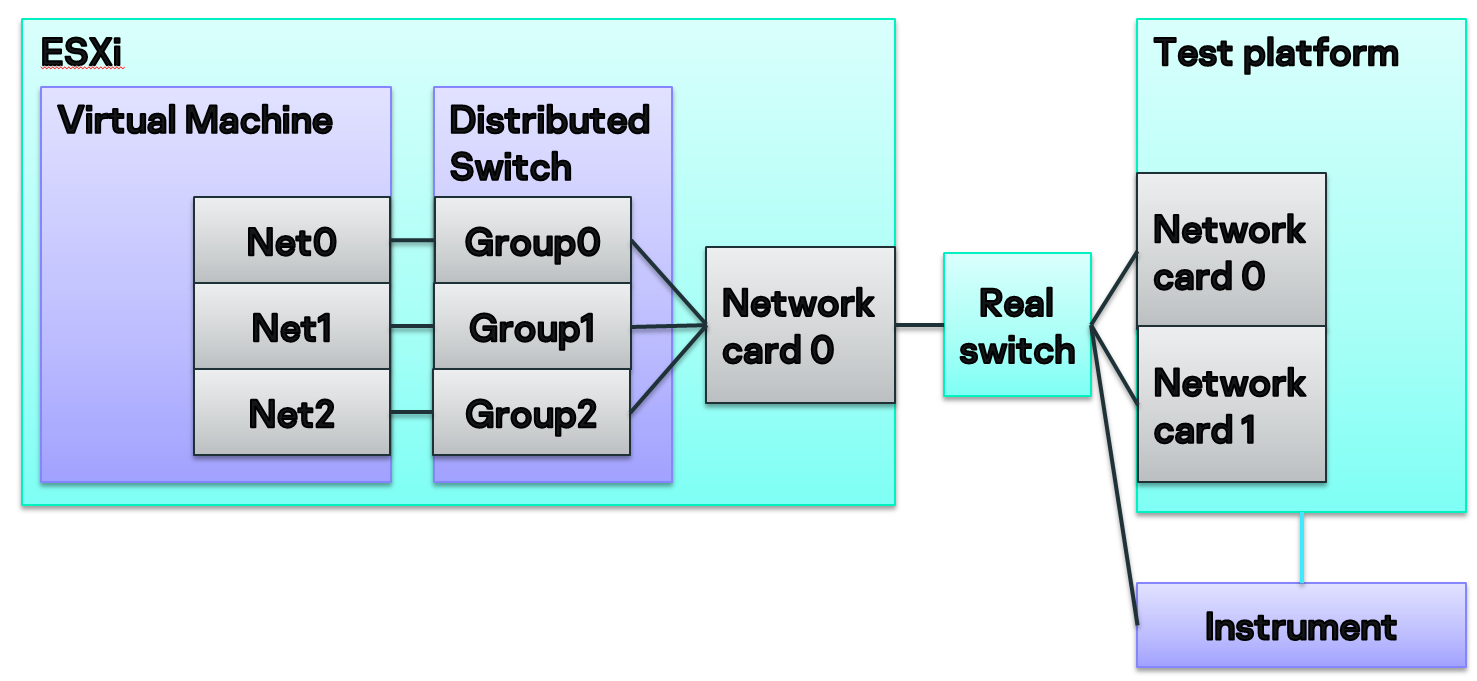
Есть сервера, на которых развернута система ESXi. Внутри — виртуалки, которые можно при помощи технологии distributed switch связывать с розетками сетевого коммутатора. Так мы можем подключать виртуальные сетевые карты на этих виртуалках к реальному железу в серверной.
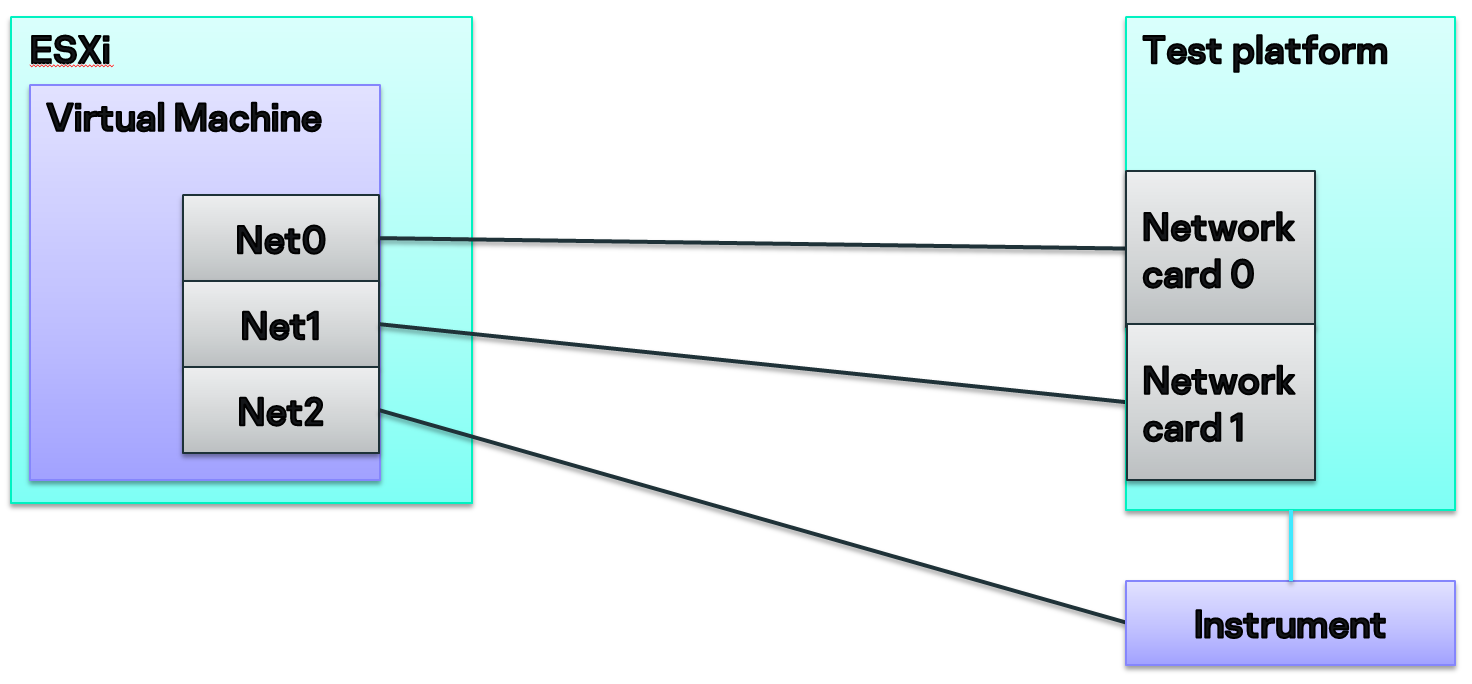
Мы можем не только подключать железо к виртуалке, но и окружать его различными инструментами. К примеру, рядом с мобильным телефоном мы можем поставить аппаратный эмулятор базовой станции, который умеет подключаться по 3G/4G. А для сетевого шлюза разместить какой-нибудь крафтер пакетов, позволяющий проверять трафик.
На этапе разработки инструмента мы определились с требованиями.
Выбирая язык, на котором можно это реализовать, мы вспомнили, что у нас есть радиоинженеры и инженеры-электронщики, которым предстоит ковыряться с тестами. Им нужен был легкий язык, который предоставлял бы большое количество библиотек на все случаи жизни, упрощающих написание тестов. Поэтому мы взяли Python.
А в качестве движка, который будет запускать тесты, нам подошел PyTest. Это хороший отлаженный инструмент. В нем есть много удобных механик, например нативная поддержка фикстур и конфигурирования тестов, параметризация, а также множество хуков, которые позволяют нам обрабатывать различные события в рамках тестовой сессии.
Нам не хватало только конфигуратора, который на основе конфигурационных файлов предоставлял бы под тесты готовое окружение. Но мы очень любим нетривиальные задачи с нестандартными условиями (и вам такие дадим — приходите к нам в команду KasperskyOS :)), поэтому написали его сами.
Общая схема тестовой сессии и работы этого конфигуратора должна выглядеть следующим образом.
Примерная схема, как должен выглядеть наш конфигуратор:
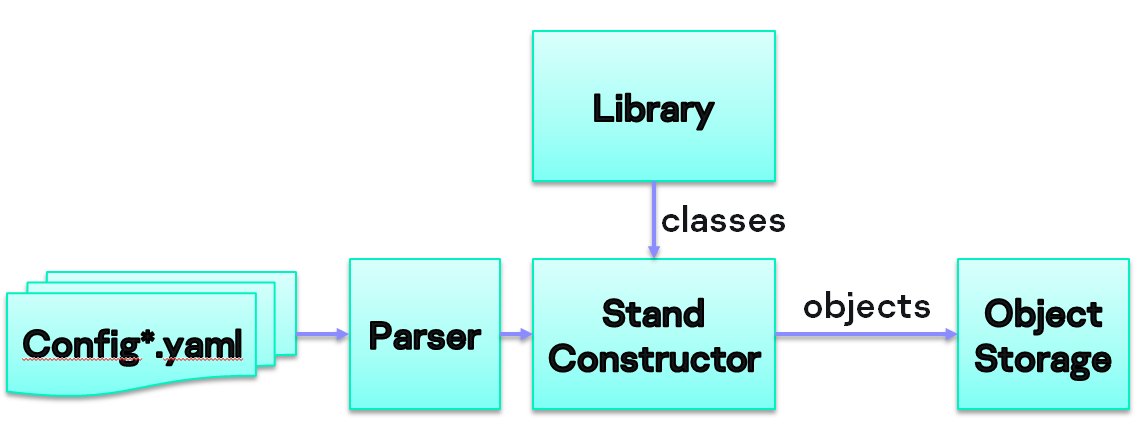
Конфигуратор читает файлы, парсит их, ищет классы, которые описаны в конфигурационных файлах, создает объекты и складывает их в хранилище.
Каким должен быть конфигурационный файл, на который опирается работа конфигуратора?
Пример конфигурации на YAML. В этом файле описан стенд — машина с некоторой ОС типа KasperskyOS. Указано, откуда брать образ для деплоя, что это будет Google Test и еще некоторые параметры — тайм-аут запуска, самого теста и паттерны, по которым мы сможем определить, что тест начался и закончился.

А вот таким образом может выглядеть конфигурация стенда на основе эмулятора QEMU:

Здесь описана машина типа QEMU. Поскольку qemu предоставляет возможность эмулировать разные архитектуры — x86, x64, ARM, ARM64 и т. п., все это будет доступно. Чтобы прокинуть дополнительные параметры, мы указываем, что в нашем стенде будут дисплей и тачскрин типа qemu.
Еще один пример с Raspberry Pi:

Здесь в конфигурационном файле указано, через какой интерфейс осуществляется деплой, что за консоль (telnet) и как к ней подключаться, чтобы читать логи. Также описаны bootloader типа uboot и возможность управлять питанием по протоколу SNMP (розетка 14).
Перед запуском каждого теста на железе у нас должна выполняться некоторая общая логика — цепочка фикстур.

Простая фикстура может выглядеть следующим образом:

В ней достаточно позвать фикстуру stand и с помощью метода get_elements_by_type вытащить все элементы типа machine из хранилища. Никто не мешает здесь же добавить метод reboot (и реальная машина будет перезагружена).
Мы можем стандартизировать железо, которое участвует в тестах, — создать корневые классы, от них унаследовать специфику конкретных машин, например Raspberry Pi, QEMU, контроллер SemPro5 и другие девелопмент-киты.

А так как у нас реализован общий интерфейс, всеми этими машинами мы сможем пользоваться в тестах обезличенно.
Мы получаем такой интерфейс класса машин.

Из интересно здесь есть метод deploy, power_on и power_off. Можно получить объект bootloader.
Наконец мы подошли к тому, как будут выглядеть тесты. Для примера возьмем тест, который проверяет, что наше решение загрузилось:

Как я уже рассказал, перед тестом выполняется логика, которая манипулирует железом и вспомогательными инструментами. Но тест выглядит так же, как если бы мы просто писали на PyTest. Мы вызываем нужную фикстуру, и дальше не имеет значения, на железе выполняется тест или нет. Все легко.
Тесты мы запускаем в нашей CI/CD. Так выглядит запуск на конвейере:

Мы восстанавливаем виртуальное окружение, все настраиваем, подтягиваем зависимости и затем вызываем PyTest, пробрасывая ему необходимые параметры — указываем конфигурационные файлы, список тестов, которые нужно запустить, и т. п. В примере выше в одном из конфигурационных файлов описано железо, на котором это все будет выполняться.
У нас может быть много агентов, к которым подключено разное железо. И какое именно железо используется, мы узнаем, только когда будет выделен агент. Мы пишем для всех агентов конфигурационные файлы и уже в момент запуска тестовой сессии из переменных подтягиваем имена и выбираем конкретный конфигурационный файл. Иными словами, всю железную специфику мы можем вынести в один файл, а всю софтовую — во второй.
В какой-то момент набор конвейеров для PR в master репозитория инструмента был таким:

Здесь видно, что запускаются юнит-тесты, сессии на QEMU, Posix, Raspberry Pi и т. п. Так у нас появляется система CI. Но в этот момент она еще неполная.
Тестов у нас много. Самые простые — это большие системные тесты. Мы сперва деплоим на железо образ операционной системы, затем уже запускаем тесты на python.
Юнит-тесты для различного железа пишут разработчики. Они могут взять фреймворк, типа google test или k-test (это внутренний фреймворк «Лаборатории Касперского» для тестов на языке C). Для запуска эти тесты достаточно развернуть на железе, а дальше просто парсить вывод, по которому мы можем понять, какие именно тесты запускались и какой в них результат. Дальше мы можем сформировать файл j-unit с отчетом.

Для каждого низкоуровневого фреймворка нам нужно выбирать свой парсер. И это мы можем описать в конфигурационном файле. В итоге тест на Python (который запускает конкретный тест на железе) будет выглядеть очень просто. Достаточно вызвать два метода — parse_result и assert_result.
Заранее мы не можем знать, из чего будет состоять тест и какие файлы будут в него входить. Разработчики, которые создают юнит-тесты, могут взять любой фреймворк и реализовать на нем только часть теста, могут добавить какие-то голые утилиты и даже протокол обмена между отдельными частями. Поэтому мы создали общий формат описания, по которому можно будет понять, что все это — действительно тест.
В инструмент, который собирает операционную систему, мы внедрили генератор, создающий такие файлики, то есть разработчику даже не нужно задумываться, как их писать. Он создает описание, как собирать тест, и из него можно вытащить весь контекст. Получаем своего рода интерфейс между разработчиком и тестовой инфраструктурой.

Наши тесты не обязательно запускаются на одной железке. В них может участвовать несколько железок с разными версиями операционной системы, которые как-то друг с другом взаимодействуют. Это востребовано, например, в нашем проекте промышленных контроллеров для энергетики. В одном таком контроллере стоит сразу три вычислителя. Поэтому в рамках теста нам необходимо деплоить образы операционных систем на три машины сразу. Такие тесты мы запускаем, используя одну и ту же механику на Python. Если же нам нужно запустить один и тот же тест на разных образах операционной системы, то мы используем фикстуру perametrizer.
Эта фикстура работает достаточно просто — мы достаем конфиги, из них извлекаем образы.
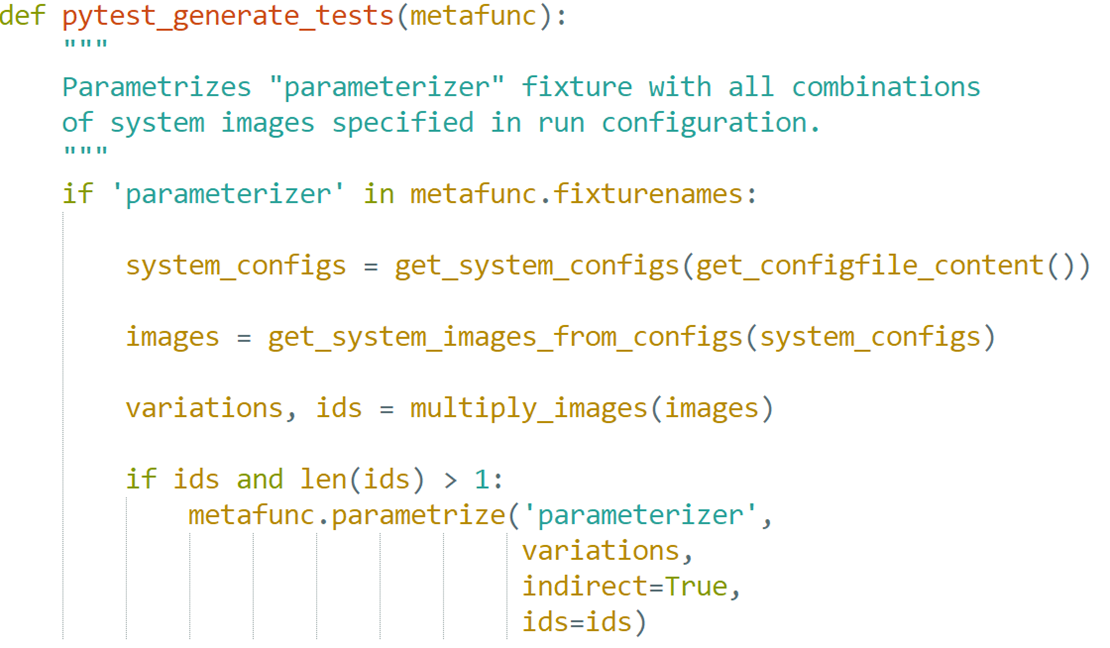
После этого повторяем эту фикстуру списком найденных образов. Таким образом, тест повторится столько раз, сколько образов укажем в конфигурационном файле.
Остается обсудить только запуск тестовых сессий и публикацию результатов тестов. Для этого мы тоже разработали небольшой инструмент, который в шутку назвали распределяющей шляпой. Его задача — просканировать билдовую директорию, в которой собирались тесты, по интерфейсным конфигам понять, где они лежат, запаковать их в архивы и перенести во временное хранилище. Инструмент триггерит тестовый бэкенд, который выдает задания тестовым агентам. После того как тесты отработали, результаты тестов возвращаются в хранилище, и оттуда мы их можем вытащить в тестовый план или на дашборд.

Таким образом, у нас замыкается кольцо запуска и публикации результатов тестов. В этот момент появляется трассируемость от требований к результатам прогонов тестов, которые были написаны по этим требованиям. Мы придерживаемся secure development life cycle. Все это происходит в TFS и Azure DevOps. Все требования, тестовые планы и прогоны сохраняются там же. Так наши менеджеры стали чуть более счастливыми.
Мы дали попользоваться нашей распределяющей шляпой разработчикам C++, которые занимаются драйверами и подобными вещами. И этот инструмент им очень понравился, потому что дает возможность разрабатывать локально, а потом в один клик с собственного компа запускать тестовую сессию на том парке железа, который стоит в серверной. Выходит очень удобно.
Вот так в какой-то момент выглядела статистика работы джобы, которая исполняется на железе.
Естественно, все происходящее логируется.
Итого мы разработали инструмент, который предоставляет удобный интерфейс для разработчиков. Теперь они знают, что происходит с тестом, — он автоматически подхватывается на конвейере и запускается на нужном железе. Мы предоставили интерфейс для него внутри Python, который полезен не только нашим тестировщикам, но и разработчикам C++. Так у нас получилась замкнутая система CI и немного CD, в рамках которой мы можем доказывать качество нашего кода.
Узнать больше о том, чем еще занимаются SDET`ы в «Лаборатории Касперского», вы можете на нашем грядущем митапе «Автотесты для огромных инфраструктур». Мои коллеги расскажут о своих успешных практиках: как оптимизировали инфраструктуру автотестирования для наших мобильных приложений, используя десктопы с GPU и Docker, а также как вылечили долгое обнаружение багов при ночных прогонах, развернув l2-тесты в kubernetes. Посмотреть полную программу и зарегистрироваться для участия в митапе можно здесь.
В этой статье расскажу о нашей модульной обвязке для PyTest, которая позволяет запускать тесты продуктов на разном железе. Фокус в том, что тесты при этом остаются простыми, а на сдачу мы получаем трассируемость от требований к результатам прогонов тестов, написанных по данным требованиям. В итоге у нас фактически получилась замкнутая система CI/CD с наглядным качеством кода.
Процесс тестирования
Как и у любой компании, которая хочет выпускать релизы регулярно, у нас есть система CI/CD. В рамках этого процесса наш отдел принимает участие в планировании, разработке кода, сборке, тестировании и, разумеется, выпуске релизов.
С точки зрения затронутых файлов процесс разработки у нас состоит из трех больших частей.
Первая — сборка самого ядра системы и SDK для разработчиков.
В эту часть входят исходники ядра, различных подсистем (графической, файловой, дисковой и т. п.), в том числе опенсорсные модули, а также тесты к ним и многое другое. На основе конфигурационного файла мы запускаем сборку под конкретное железо и на выходе получаем SDK для разработчиков и тестовые бинарники, которые можно загрузить на целевое железо.
В рамках тестовой сессии мы загружаем бинарники с нашей ОС на железо и в результате получаем отчеты о тестировании и метрики, которые публикуются на дашборде (для всеобщего обозрения) и в описании релиза. Метрики — важная часть нашей работы. Если они укладываются в заданные рамки, это свидетельствует об определенном уровне качества релиза.
В рамках второй части на основе полученного SDK, используя продуктовые исходники, юнит-тесты к ним, интеграционные тесты и т. п., собираем прошивку для устройства, например мобильного телефона.
На этом шаге у нас появляются тестовые бинарники, которые мы можем задеплоить, запустить, проверить и прилинковать к карточке релиза или на дашборд.
Третья часть касается развития продукта. По требованиям аналитиков рождаются задачи для разработчиков, а заодно мы пишем по ним более высокоуровневые системные тесты, группируем их в тест-планы, запускаем тестовые сессии на готовых прошивках (релиз-кандидатах). В результате снова имеем отчеты и метрики.
Тестовый стенд
У нас есть широкий диапазон решений на разной архитектуре — под мобильные устройства, сетевое оборудование, x86, x64, arm, risk и т. п. Чтобы проверять код на этом зоопарке железа, необходимо собрать парк тестовых стендов.
Стенды у нас есть разнообразные, но типовой выглядит так:
Есть сервера, на которых развернута система ESXi. Внутри — виртуалки, которые можно при помощи технологии distributed switch связывать с розетками сетевого коммутатора. Так мы можем подключать виртуальные сетевые карты на этих виртуалках к реальному железу в серверной.
Мы можем не только подключать железо к виртуалке, но и окружать его различными инструментами. К примеру, рядом с мобильным телефоном мы можем поставить аппаратный эмулятор базовой станции, который умеет подключаться по 3G/4G. А для сетевого шлюза разместить какой-нибудь крафтер пакетов, позволяющий проверять трафик.
Инструмент для запуска тестовых сессий
Базовые требования
На этапе разработки инструмента мы определились с требованиями.
- Инструмент должен предоставлять стандартную логику подготовки окружения к тесту. В эту логику должен входить деплой на машине, инициализация инструментов управления, настройка и приборка после него (набор общих фикстур).
- Инструмент должен предоставлять набор библиотек для управления тестовыми стендами, которые можно (пере)использовать в разных тестах (как кубики конструктора).
- Инструмент должен обладать системой конфигурирования, потому что стенды у нас разные, а тесты мы хотим делать одинаковые.
- Тесты должны быть кросс-платформенными (по возможности). Если тест проверяет определенную функциональность, нам должно быть неважно, на каком стенде эта проверка запускается. Если стенд удовлетворяет условиям теста, мы должны прогнать на нем тест. То есть мы должны предоставить тесту какую-то абстракцию и уметь ее конфигурировать.
Общая схема работы инструмента
Выбирая язык, на котором можно это реализовать, мы вспомнили, что у нас есть радиоинженеры и инженеры-электронщики, которым предстоит ковыряться с тестами. Им нужен был легкий язык, который предоставлял бы большое количество библиотек на все случаи жизни, упрощающих написание тестов. Поэтому мы взяли Python.
А в качестве движка, который будет запускать тесты, нам подошел PyTest. Это хороший отлаженный инструмент. В нем есть много удобных механик, например нативная поддержка фикстур и конфигурирования тестов, параметризация, а также множество хуков, которые позволяют нам обрабатывать различные события в рамках тестовой сессии.
Нам не хватало только конфигуратора, который на основе конфигурационных файлов предоставлял бы под тесты готовое окружение. Но мы очень любим нетривиальные задачи с нестандартными условиями (и вам такие дадим — приходите к нам в команду KasperskyOS :)), поэтому написали его сами.
Конструктор стенда
Общая схема тестовой сессии и работы этого конфигуратора должна выглядеть следующим образом.
- Конфигуратор создает набор объектов.
- PyTest производит поиск тестов.
- PyTest строит деревья запуска фикстур для них.
- Фикстуры извлекают из хранилища необходимые им объекты.
- Фикстуры вызывают методы этих объектов, которые настраивают окружение.
- Фикстуры возвращают подготовленные объекты. Дальше все попадает в PyTest.
- Производится тест.
- Финализаторы фикстур производят приборку. Поскольку это железо, нам надо правильно освободить ресурсы и т. п.
- Генерируются отчеты, которые мы можем прикрепить к карточке релиза.
Примерная схема, как должен выглядеть наш конфигуратор:
Конфигуратор читает файлы, парсит их, ищет классы, которые описаны в конфигурационных файлах, создает объекты и складывает их в хранилище.
Каким должен быть конфигурационный файл, на который опирается работа конфигуратора?
- Он должен позволять описывать железо стенда (в виде дерева).
- Должна быть понятна архитектура стенда.
- Инструмент должен позволять описывать свойства составных частей.
- Формат должен быть популярен (готовый парсер) — мы долго не думали, взяли YAML.
Пример конфигурации на YAML. В этом файле описан стенд — машина с некоторой ОС типа KasperskyOS. Указано, откуда брать образ для деплоя, что это будет Google Test и еще некоторые параметры — тайм-аут запуска, самого теста и паттерны, по которым мы сможем определить, что тест начался и закончился.
А вот таким образом может выглядеть конфигурация стенда на основе эмулятора QEMU:
Здесь описана машина типа QEMU. Поскольку qemu предоставляет возможность эмулировать разные архитектуры — x86, x64, ARM, ARM64 и т. п., все это будет доступно. Чтобы прокинуть дополнительные параметры, мы указываем, что в нашем стенде будут дисплей и тачскрин типа qemu.
Еще один пример с Raspberry Pi:
Здесь в конфигурационном файле указано, через какой интерфейс осуществляется деплой, что за консоль (telnet) и как к ней подключаться, чтобы читать логи. Также описаны bootloader типа uboot и возможность управлять питанием по протоколу SNMP (розетка 14).
Общие фикстуры
Перед запуском каждого теста на железе у нас должна выполняться некоторая общая логика — цепочка фикстур.
- Фикстура Stand читает конфигурационный файл и создает все объекты.
- Parametrize позволяет запускать один и тот же тест много раз, но, например, для образов с разными ОС.
- Machine управляет машиной, например ребутит ее при необходимости.
- System деплоит образы на машины (необязательно KasperskyOS, мы можем создавать две тестовые сессии для сравнения, например времени выполнения одних и тех же задач на KasperskyOS и Android).
- Solution и App — это наша специфика. Как я говорил, у нас может тестироваться мобильный телефон, и тогда приложением для него будет калькулятор или книга с контактами. А может тестироваться сетевой шлюз, а приложением будет фильтр пакетов, который на нем работает.
Простая фикстура может выглядеть следующим образом:
В ней достаточно позвать фикстуру stand и с помощью метода get_elements_by_type вытащить все элементы типа machine из хранилища. Никто не мешает здесь же добавить метод reboot (и реальная машина будет перезагружена).
Пример семейства классов Machine
Мы можем стандартизировать железо, которое участвует в тестах, — создать корневые классы, от них унаследовать специфику конкретных машин, например Raspberry Pi, QEMU, контроллер SemPro5 и другие девелопмент-киты.
А так как у нас реализован общий интерфейс, всеми этими машинами мы сможем пользоваться в тестах обезличенно.
Общий интерфейс семейства классов Machine
Мы получаем такой интерфейс класса машин.
Из интересно здесь есть метод deploy, power_on и power_off. Можно получить объект bootloader.
Как выглядят тесты
Наконец мы подошли к тому, как будут выглядеть тесты. Для примера возьмем тест, который проверяет, что наше решение загрузилось:
Как я уже рассказал, перед тестом выполняется логика, которая манипулирует железом и вспомогательными инструментами. Но тест выглядит так же, как если бы мы просто писали на PyTest. Мы вызываем нужную фикстуру, и дальше не имеет значения, на железе выполняется тест или нет. Все легко.
Тесты мы запускаем в нашей CI/CD. Так выглядит запуск на конвейере:
Мы восстанавливаем виртуальное окружение, все настраиваем, подтягиваем зависимости и затем вызываем PyTest, пробрасывая ему необходимые параметры — указываем конфигурационные файлы, список тестов, которые нужно запустить, и т. п. В примере выше в одном из конфигурационных файлов описано железо, на котором это все будет выполняться.
У нас может быть много агентов, к которым подключено разное железо. И какое именно железо используется, мы узнаем, только когда будет выделен агент. Мы пишем для всех агентов конфигурационные файлы и уже в момент запуска тестовой сессии из переменных подтягиваем имена и выбираем конкретный конфигурационный файл. Иными словами, всю железную специфику мы можем вынести в один файл, а всю софтовую — во второй.
В какой-то момент набор конвейеров для PR в master репозитория инструмента был таким:
Здесь видно, что запускаются юнит-тесты, сессии на QEMU, Posix, Raspberry Pi и т. п. Так у нас появляется система CI. Но в этот момент она еще неполная.
Тестов у нас много. Самые простые — это большие системные тесты. Мы сперва деплоим на железо образ операционной системы, затем уже запускаем тесты на python.
Юнит-тесты для различного железа пишут разработчики. Они могут взять фреймворк, типа google test или k-test (это внутренний фреймворк «Лаборатории Касперского» для тестов на языке C). Для запуска эти тесты достаточно развернуть на железе, а дальше просто парсить вывод, по которому мы можем понять, какие именно тесты запускались и какой в них результат. Дальше мы можем сформировать файл j-unit с отчетом.
Для каждого низкоуровневого фреймворка нам нужно выбирать свой парсер. И это мы можем описать в конфигурационном файле. В итоге тест на Python (который запускает конкретный тест на железе) будет выглядеть очень просто. Достаточно вызвать два метода — parse_result и assert_result.
Общий описатель теста
Заранее мы не можем знать, из чего будет состоять тест и какие файлы будут в него входить. Разработчики, которые создают юнит-тесты, могут взять любой фреймворк и реализовать на нем только часть теста, могут добавить какие-то голые утилиты и даже протокол обмена между отдельными частями. Поэтому мы создали общий формат описания, по которому можно будет понять, что все это — действительно тест.
В инструмент, который собирает операционную систему, мы внедрили генератор, создающий такие файлики, то есть разработчику даже не нужно задумываться, как их писать. Он создает описание, как собирать тест, и из него можно вытащить весь контекст. Получаем своего рода интерфейс между разработчиком и тестовой инфраструктурой.
Параметризация
Наши тесты не обязательно запускаются на одной железке. В них может участвовать несколько железок с разными версиями операционной системы, которые как-то друг с другом взаимодействуют. Это востребовано, например, в нашем проекте промышленных контроллеров для энергетики. В одном таком контроллере стоит сразу три вычислителя. Поэтому в рамках теста нам необходимо деплоить образы операционных систем на три машины сразу. Такие тесты мы запускаем, используя одну и ту же механику на Python. Если же нам нужно запустить один и тот же тест на разных образах операционной системы, то мы используем фикстуру perametrizer.
Эта фикстура работает достаточно просто — мы достаем конфиги, из них извлекаем образы.
После этого повторяем эту фикстуру списком найденных образов. Таким образом, тест повторится столько раз, сколько образов укажем в конфигурационном файле.
Распределяющая шляпа
Остается обсудить только запуск тестовых сессий и публикацию результатов тестов. Для этого мы тоже разработали небольшой инструмент, который в шутку назвали распределяющей шляпой. Его задача — просканировать билдовую директорию, в которой собирались тесты, по интерфейсным конфигам понять, где они лежат, запаковать их в архивы и перенести во временное хранилище. Инструмент триггерит тестовый бэкенд, который выдает задания тестовым агентам. После того как тесты отработали, результаты тестов возвращаются в хранилище, и оттуда мы их можем вытащить в тестовый план или на дашборд.
Таким образом, у нас замыкается кольцо запуска и публикации результатов тестов. В этот момент появляется трассируемость от требований к результатам прогонов тестов, которые были написаны по этим требованиям. Мы придерживаемся secure development life cycle. Все это происходит в TFS и Azure DevOps. Все требования, тестовые планы и прогоны сохраняются там же. Так наши менеджеры стали чуть более счастливыми.
Отладка на стендовой ферме
Мы дали попользоваться нашей распределяющей шляпой разработчикам C++, которые занимаются драйверами и подобными вещами. И этот инструмент им очень понравился, потому что дает возможность разрабатывать локально, а потом в один клик с собственного компа запускать тестовую сессию на том парке железа, который стоит в серверной. Выходит очень удобно.
Вот так в какой-то момент выглядела статистика работы джобы, которая исполняется на железе.
Естественно, все происходящее логируется.
Итого мы разработали инструмент, который предоставляет удобный интерфейс для разработчиков. Теперь они знают, что происходит с тестом, — он автоматически подхватывается на конвейере и запускается на нужном железе. Мы предоставили интерфейс для него внутри Python, который полезен не только нашим тестировщикам, но и разработчикам C++. Так у нас получилась замкнутая система CI и немного CD, в рамках которой мы можем доказывать качество нашего кода.
Узнать больше о том, чем еще занимаются SDET`ы в «Лаборатории Касперского», вы можете на нашем грядущем митапе «Автотесты для огромных инфраструктур». Мои коллеги расскажут о своих успешных практиках: как оптимизировали инфраструктуру автотестирования для наших мобильных приложений, используя десктопы с GPU и Docker, а также как вылечили долгое обнаружение багов при ночных прогонах, развернув l2-тесты в kubernetes. Посмотреть полную программу и зарегистрироваться для участия в митапе можно здесь.