
Привет! Меня зовут Александр Пронин, я занимаюсь тестированием более пяти лет, последние полгода из которых — в QIWI, проект ContactPay. Мы делаем платежную систему для международного рынка, она состоит из микросервисов, которые написаны на Python и живут в Google Cloud. Проект существует на рынке более двух лет, на данный момент среди наших клиентов уже есть компании-единороги.

Придя в этот стартап, я столкнулся с особенностями здешней атмосферы: все гибко, быстро, часто меняются цели, и в угоду этому результат иногда получается не совсем корректным. Мне свежим взглядом со стороны было легко подметить те места, особенно в тестировании, решив которые, можно было бы добиться лучших результатов для нашей компании.
Так что в этом посте мы рассмотрим изменения процессов тестирования и доставки новых фич, проделанные нами за полгода, с точки зрения того, как в ContactPay это было раньше, что изменили и к каким результатам это привело.
Flow новых фич
Начнем с самого общего: это флоу релиза любой новой фичи от изначальной задумки до доставки пользователю.
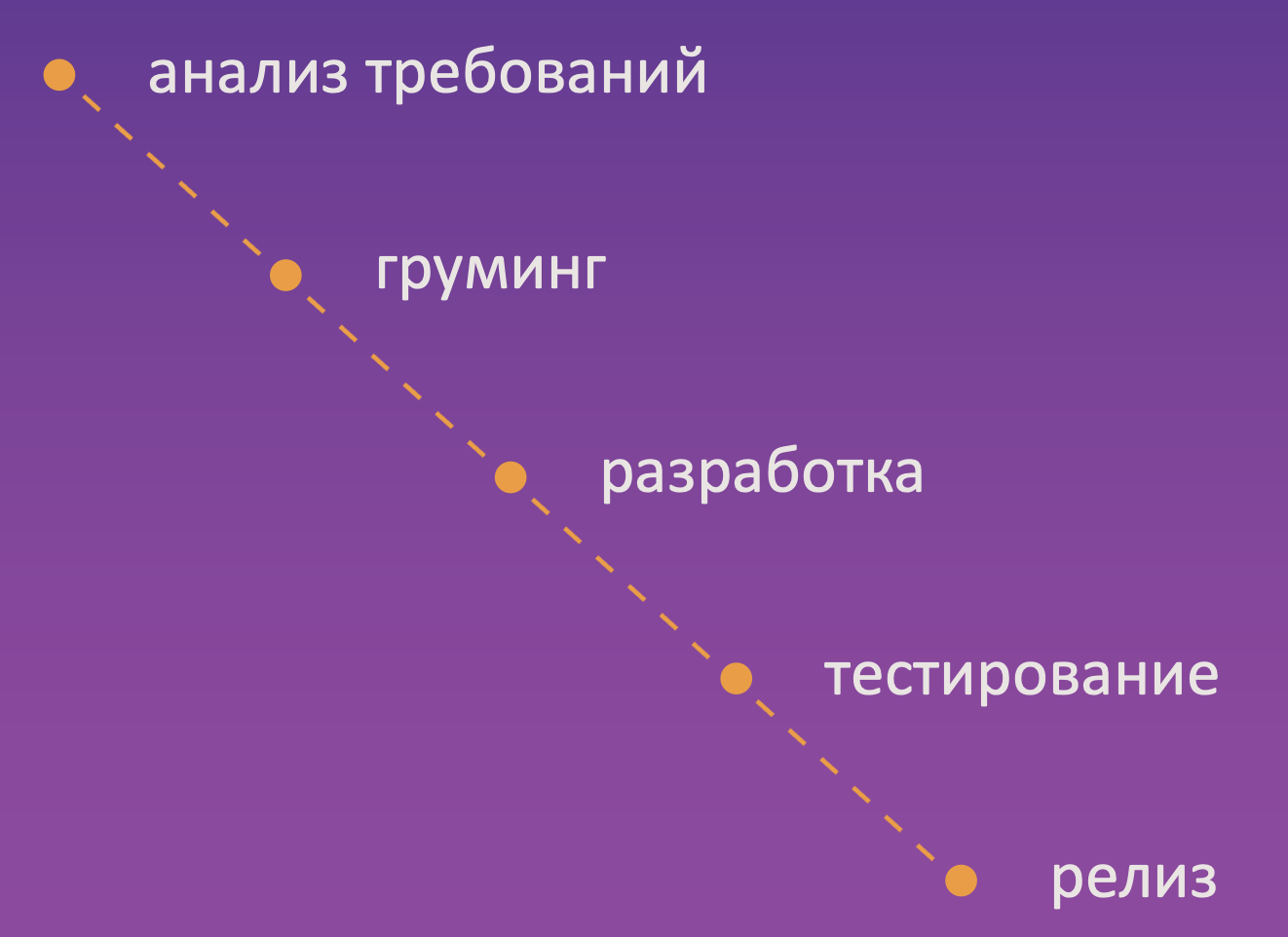
Как это было раньше: приходила приоритетная задача от нашего продакт-менеджера, либо из бэклога или техдолга. По ней расписывались требования, затем они декомпозировались на отдельные задачи на разработку, шла имплементация, эти задачи приходили в тестирование. Тестировщики изучали требования, понимали, как проверять, затем тестировали.
Далее иногда проводилось демо перед заказчиком фичи, и случалось так, что на демо фича работала не совсем так, как он этого хотел. Дабы решить этот момент, немного погрузимся в теорию тестирования.
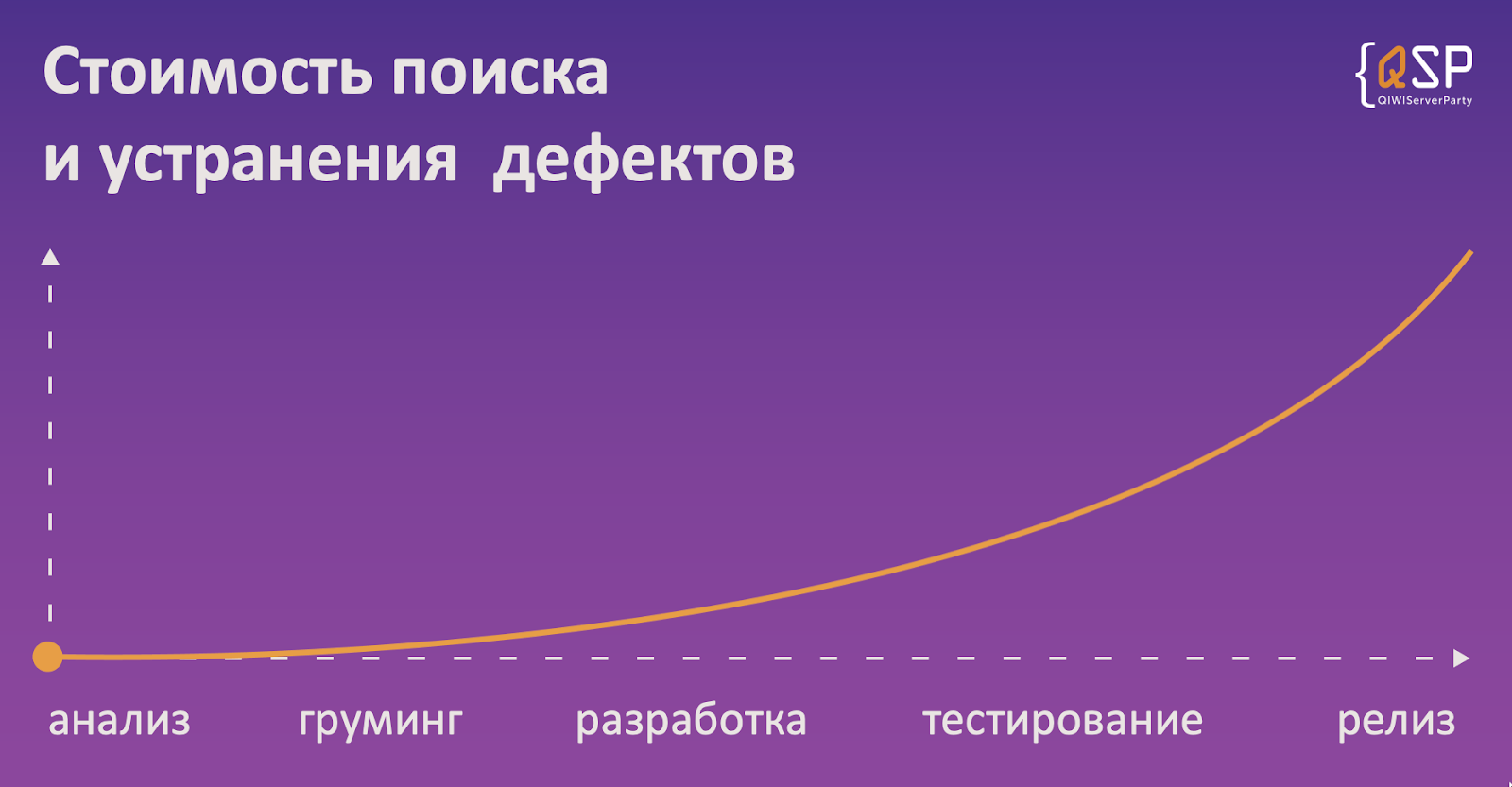
Это график зависимости стоимости исправления дефекта от времени. Его можно найти буквально прямо на первых страницах книги “Foundations of Software Testing”. Весь смысл в том, что это кривая, возрастающая по экспоненте. Как видите, на этапе тестирования стоимость исправления дефектов является почти максимальной, хуже только в продакшене, но до этого в финтехе лучше не доводить.
Принято считать, что в основном все дефекты рождаются именно в ходе разработки. Если бы это было так, то график выглядел бы следующим образом, намного красивее, приятнее и удобнее.

Но вернемся к реальности.
Почему во время тестирования стоимость исправления дефектов максимальная? Потому что дефекты могут закрадываться не только на этапе разработки, но и ранее. И самые опасные дефекты — те, которые были допущены во время написания требований.
Рассмотрим самый крайний случай такого дефекта, когда он был найден уже после тестирования. Тогда нам придется откатиться на самое начало, переписать эти требования, поставить новые задачи на разработку, имплементировать их, снова протестировать. Отсюда и берется этот огромный промежуток потраченного времени. Но есть подходы в тестировании, позволяющие избежать этого: можно начать тестировать фичу заблаговременно.
Например, shift-left testing – такой подход к тестированию, при котором тестировщики вовлекаются в жизненный цикл продуктового инкремента на более ранних этапах, чем раньше, тем лучше.

К слову, есть еще и shift-right testing, при котором тестирование откладывается, наоборот, к моменту продакшена, но это характерно больше для индустрии развлечений. Нам же в финтехе важно проверять фичу заблаговременно.
Мы ввели shift-left testing в нашем проекте совместно с ревью задач аналитики. Теперь общий флоу новых фич выглядит так.
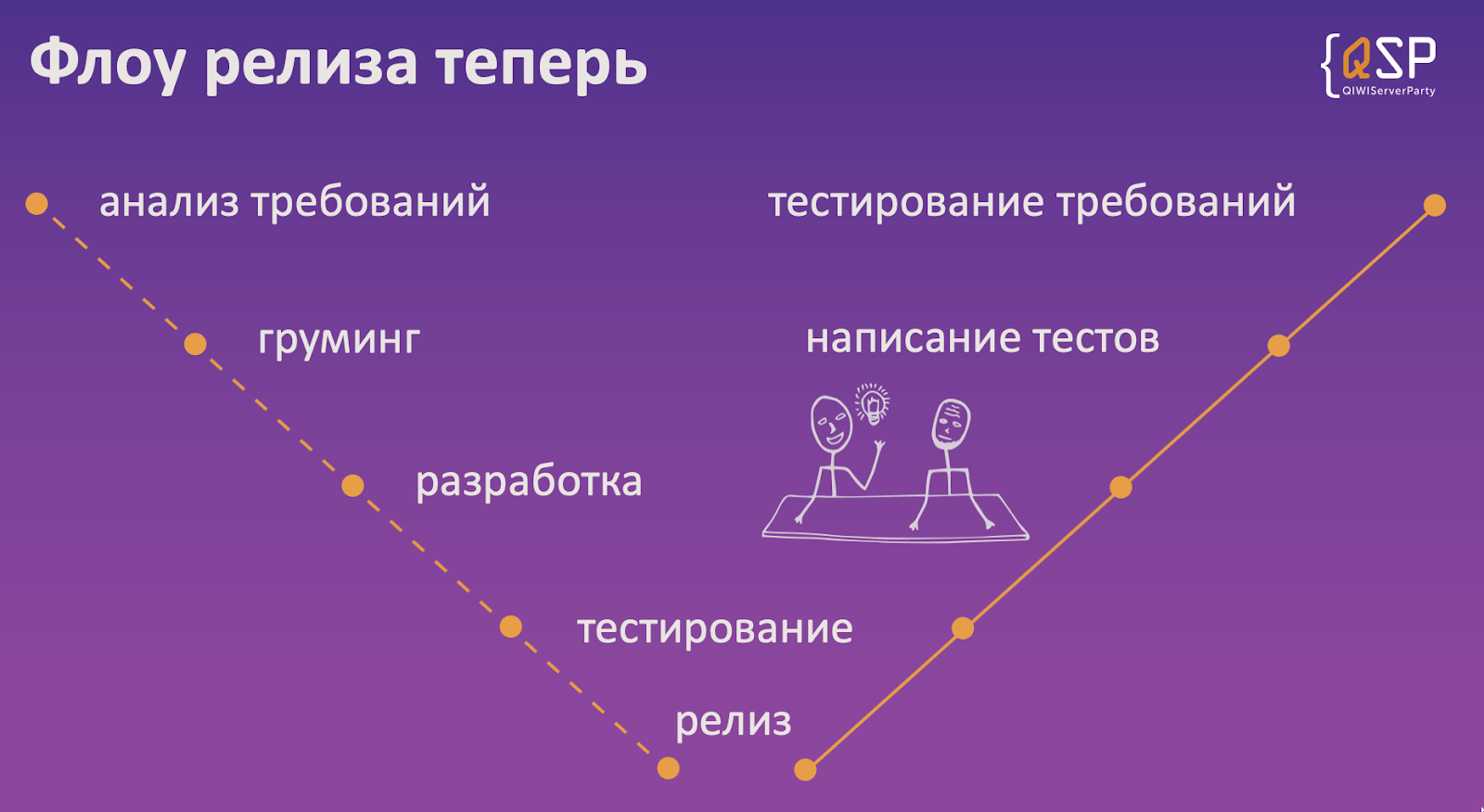
V-модель тестирования
Требования ревьювятся теперь не только разработчиками, но и самим заказчиком фичи и тестировщиками. Последние на этом этапе подмечают список самых критических проверок, без которых ее нельзя было бы допустить в продакшн, и разные граничные условия, raсe condition’ы, интеграционные моменты в плане взаимодействий наших микросервисов друг с другом и всего нашего продукта с другими платежными системами.
Кроме этого, тестировщики также участвуют в этапе груминга. Здесь этот список критических проверок обогащается, затем пишется ряд мануальных тест-кейсов, по которым фича будет проверяться. В этап разработки мы пока не внедрились, но на счет этого ведутся разные переговоры, эксперименты. Если сработает, напишу об этом отдельный пост.
Так вот, потом идет этап активного предрелизного тестирования, до которого,
во-первых, доходит уже меньше багов, потому что они были выловлены заранее,
во-вторых, уже есть список готовых мануальных тест-кейсов, по которым фичу можно проверить.
Это сокращает этап тестирования, и время доставки фич в прод ускоряется.
Документация
Рассмотрим разные аспекты тестирования более подробно, как на них повлиял shift-left testing и не только. Начнем с самого вкусненького в тестировании – с тестовой документации.

Раньше в ContactPay с ней обстановка была такая: у тестировщиков не было ни времени, ни возможности (да и желания), чтобы ее заполнять. Когда тикеты приходили в QA, тестировщикам приходилось выяснять, как их тестировать. Они с этим вопросом шли к разработчикам, тратя свое время и время последних. Выясняли, как тестировать, проверяли и отправляли фичу в релиз, следом приходила следующая пачка тикетов. Времени пополнять документацию совершенно не было. Кроме того, отсутствие документации еще и замедляло онбординг новых QA.
С введением shift-left testing и рядом экспериментов мы пришли к гибкой документации, как мы ее называем.
На этапе анализа требований тестировщики подмечают этот список критических проверок простым комментарием в Jira к тикету аналитики, далее после груминга список обогащается, и создается мануальный тест-кейс. Каждый тестировщик делает это в том инструменте, в котором ему удобнее (в основном — Notion).
Вот как оно выглядит.

После релиза тест-кейсы заносятся в нашу систему менеджмента тест-кейсов в виде, удобном для будущей автоматизации. Обычно после релизов у команды тестирования появляется время, чтобы покрыть автотестами эту новую функциональность.
Таким образом, теперь важная информация у нас всегда под рукой, тестировщики не тратят время, чтобы выяснить, как проверить фичу. Тест-кейсы в нашей TMS (система хранения и менеджмента тесткейсов) уже адаптированы для нашей будущей автоматизации и, кроме того, наличие тестовой документации ускоряет онбординг новых QA.
Релизы
Теперь, не отходя далеко от темы релизов, рассмотрим их в контексте релиза каждого отдельного микросервиса. Раньше в ContactPay они планировались каждые две-три недели, релиз собирался только тогда, когда все тикеты на разработку были протестированы на нашем тестинг-окружении. Если наглядно, то вот.
Релиз собирался, ехал на стейджинг, и там все эти тикеты проверялись еще раз. Так как релиз был сильно растянут по времени, то в него пытались регулярно запихнуть как можно больше задач, приходилось черри-пикать протестированный код в релизную ветку или, наоборот, исключать какой-то низкоприоритетный.
Это вызывало проблемы с миграциями схемы бд и делало время доставки фич в продакшн слабо предсказуемыми. И мы подумали: а смысл вообще проверять все эти тикеты дважды, если можно протестить один раз на стейджинге? Решили попробовать собирать новые релизы регулярно, буквально каждый понедельник, из master’а, неважно, фичи проверены на тестинге или нет, все они едут на стейджинг и тестируются уже там.

Такой подход, конечно, ускоряет релизы, но зачастую введение новой функциональности затрагивает изменения сразу в нескольких отдельных микросервисах. Дабы не ждать, когда все они соберутся на стейджинге, чтобы проверить функциональность, мы проводим так называемое отложенное тестирование. Для этого мы определяем отсутствие влияния новой функциональности в рамках каждого отдельного релиза на старую, в основном с помощью регрессии нашими end-to-end автотестами, и релиз этого микросервиса отправляется в продакшн буквально с частицей новой фичи, но пока с выключенным фичафлагом.
И теперь релизы выглядят вот так, их доставку стало проще прогнозировать.

А их качество гарантируют наши end-to-end автотесты.
Автотесты
А с ними в ContactPay ситуация раньше была такой: запускались они всегда по требованию: «вот у нас релиз на стейджинге, вроде уже готов к продакшену, давайте-ка прогоним автотесты».
Запуск этих прогонов, фикс автотестов, анализ результатов выполнял всегда один и тот же тестировщик. Делалось это все на локальной машине этого тестировщика.

На вид, конечно, ужасный bus-фактор, и дабы его избежать, мы настроили автоматический запуск автотестов в нашей CI-системе (TeamCity), и алерты нам в Slack при любых событиях прогона автотестов.
Теперь любой член команды, у которого есть доступ к проекту в TeamCity, может туда зайти, посмотреть на результаты автотестов, даже запустить их вручную (но это делать необязательно, потому что все события репортятся нам в Slack), и вся команда оперативно получает об этом информацию.

Есть и обратная сторона: так как мы тестируем платежный шлюз, здесь важно оперативно получать информацию обо всех негативных сценариях, которые происходят. Система сбора метрик об этих событиях настроена не только на продакшн, но и на обе наши тестовые среды, дабы в пассивном режиме проверять ее функциональность в том числе.
И с автоматизацией прогона автотестов их частота, конечно, увеличилась и алерты возросли в разы, стало уже непонятно, какие из них были от ручного тестирования, а какие – от автоматического. Все это триггерило дежурного разработчика, поэтому понадобилось инвестировать дополнительное время в то, чтобы ввести признак, однозначно определяющий алерты от автотестов, дабы отфильтровать их и перенаправить в другие каналы алертинга.
QA tools
Конечно, не автотестами едиными, в основном новую функциональность мы тестируем с помощью наших инструментов тестирования. Так как наш платежный шлюз это API, то у нас есть коллекция Postman со списком запросов ко всем endpoint’ам. Она настроена для удобного переключения между различными средами (тестинг, стейджинг, прод) и между различными тестовыми сценариями (позитивными, негативными и не только). Разнообразие этих сценариев обеспечивает наш Mock-service. Он, как и все наши сервисы, написан на Python, и раньше его поддержкой занимались разработчики. Но у них перестало хватать времени на это, и мы в команде тестирования решили попробовать взять его поддержку в свои руки. Так как мы (тестировщики) и являемся конечными пользователями этого сервиса, то нам лучше знать о том, как он должен работать. Кроме того, нам внутри в рамках одной команды проще договориться о его функциональностях.

Я уверен, для большинства команд в стартапах поддержка утилит тестирования средствами QA – этап пройденный, но для нас это стало настоящим достижением, потому что это повышает экспертизу тестировщиков в разработке, что позволяет при анализе найденных дефектов анализировать сам код приложения, код пулл-реквестов, и указывать причины дефекта в конкретной строчке этого кода. Это позволяет разработчику быстрее понять проблему и ее исправить.
Виды тестирования
Их очень много, конкретно в нашем проекте используется вот этот набор.

По большей части мы занимаемся анализом требований, тест-дизайном, описываем кейсы и вручную их проверяем. После этого иногда есть время, чтобы покрыть их автотестами. Также с релизом первого публичного сервиса ContactPay – личного кабинета для мерчантов, потребовалось еще активное тестирование безопасности и нагрузки.
Так как команда стартапа относительно небольшая, то тестировщику в ней приходится совмещать сразу несколько видов тестирования. Но даже в такой атмосфере, если конкретные виды тестирования закреплять за конкретным тестировщиком, неизбежна рутина. Чтобы ее избежать, мы стараемся постоянно меняться ролями в тестировании: например, в этом спринте я занимался анализом требований и тест-дизайном, ручным тестированием, а в следующем спринте я буду покрывать новую функциональность автотестами.
Все эти перестановки мы регулярно обсуждаем на наших QA-синках, на них также регулярно делимся знаниями и опытом и в синхронном режиме проводим ревью тест-кейсов, кода автотестов и мок-сервиса.
Таким образом, у тестировщиков повышается вовлеченность, так как нет рутины, это обеспечивает профессиональный рост в разных областях тестирования, улучшает bus-фактор в QA-команде и как side-эффект позитивно влияет на найм новых тестировщиков. Каждое собеседование замечаем, как они с интересом слушают о том, как мы тестируем в ContactPay.
Что в итоге
Подведем итоги тех best practices, которые мы применили за последние полгода и которые позволили заметно сократить наш time-to-market.
Это, конечно, shift-left testing, его легко запомнить визуально по V-model.
Автотесты загоняем в CI.
Релизы отдельных сервисов делаем регулярно и проводим отложенное тестирование, чтобы проверить отсутствие impact’а на старую функциональность.
В команде тестирования регулярно меняемся ролями тестирования.
Стараемся самостоятельно поддерживать наши инструменты.
Думаю, у многих из вас, скорее всего, есть идеи, как можно улучшить процессы в ваших проектах, либо попробовать что-то новое в реальной жизни, но эти идеи часто откладываются из-за более приоритетных задач, каких-то проблем или из-за того, что в голове представляется, как в первое время это будет неудобно, непривычно, и поэтому время реализации может оттягиваться бесконечно долго.
Находите подходы, позволяющие это время сократить, и, конечно, улучшайте time-to-market в работе и в реальной жизни????.
Комментарии (6)


savinser
30.11.2022 08:14+1@XanderPro какой у вас размер команды ? и сколько тестировщиков в команде ?

Belisckner
30.11.2022 14:22Отличная статья, спасибо!
У вас роли тестирования совпадают с видами? Не увидел какие именно роли есть
Также, правильно ли понял, что у вас отсутствуют фиче ветки, а вся разработка ведётся в стейдже и там же проверяется/исправляется, но под флагами?
И в день релиза стейдж расскатывается на прод, но неготовые фичи спрятаны за флагами (то что они спрятаны и не влияют на остальное проверяют автотесты)
А флаги с фиксами доедут в следующем релизе, всё так?XanderPro Автор
30.11.2022 14:40+1Роли ратируем в команде тестирования. Обычно это анализ требований -> ручное -> покрытие автотестами. Иногда добавляется нагрузочное и секьюрити.
Да, разработка ведётся в мастере, из него собирается релизная ветка (в рамках каждого сервиса)
В день релиза релизная ветка деплоится на прод. Частичные реализации фич скрыты под флагами - разработка ведётся так, что сохранять обратную совместимость - новый код ничего не импактит, пока не будет явно активирован.
vershovadt
выглядит довольно эффективно конечно