
В связи с этим юбилеем мы предлагаем вашему вниманию перевод интервью с основателем языка Бьёрном Страуструпом.
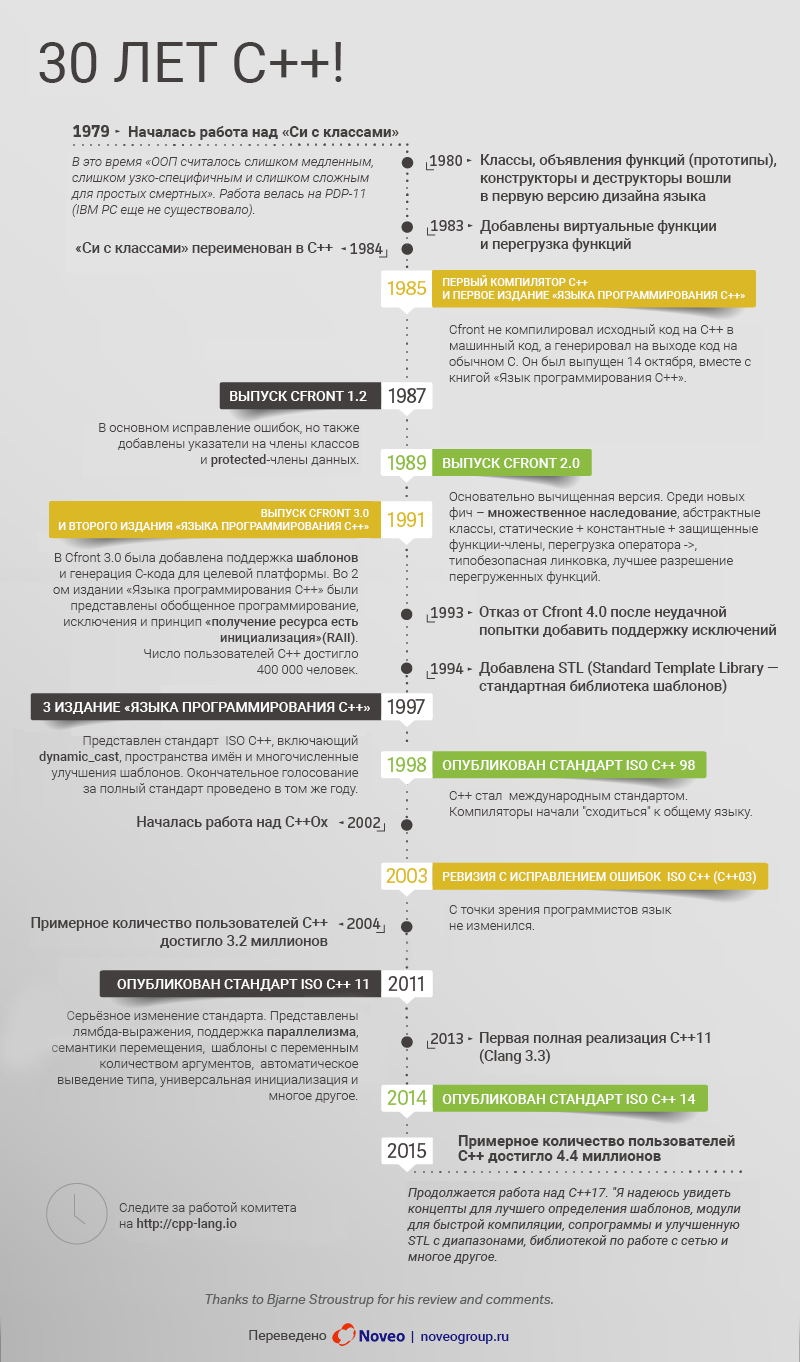
Ровно 30 лет назад состоялся релиз CFront 1.0 и первый выпуск книги «Язык программирования C++». Было ли важным выпустить их в один и тот же день?
Я не знаю, было ли это важным, но в то же время это было хорошей идеей. О том, какой день станет удачным для релиза, меня спрашивали и AT&T (компания, продающая компилятор), и Addison-Wesley (издатель книги). Я назвал 14 октября, поскольку должен был выступать на конференции Ассоциации по вычислительной технике США и мог бы представить его там.
Это сделало вас дважды автором и, возможно, потребовало вдвое больше работы. Но помогло ли написание книги разработать более хороший язык?
Это была необходимая книга. Крошечное, но постоянно растущее сообщество нуждалось в ней. Мысль написать эту книгу пришла даже не в мою голову. Эту идею мне подал Ал Ахо, впоследствии мой сосед в Bell Labs (Bell Labs — компания, как и AT&T). Я абсолютно недооценил объём работ над «Языком программирования С++». Писать на совершенно новую тему очень сложно. Я узнал многое о языке, пытаясь объяснить его людям. Я изменял С++, и объяснение становилось проще благодаря тому, что сам язык становился более логичным или более функциональным. Написание инструкции – очень хороший способ проектирования.

Вы помните, что чувствовали в тот понедельник, 14 октября 1985 года, когда представили свой семинар «Введение в C++»?
Нет, не помню. На самом деле, из того, что происходило в 1980-х, я помню сравнительно немного. Я был тогда очень занят. В период с 1979 по 1991 число программистов, использующих С++, удваивалось каждые 7,5 месяцев. Такой рост порождает очень большое количество работы. Сегодня количество пользователей С++ достигает 4.4 миллионов (согласно исследованию JetBrains). Это был важный для меня день, но единственное, что я помню, – это как я получал на руки первую копию моего первого издания.
Как вы тогда видели С++? Каким представляли его будущее?
Конечно, я не предполагал такого невероятного, временами взрывного роста языка. Я сконцентрировался на его улучшении, изучал написание библиотек, улучшал компилятор и объяснял, как всем этим пользоваться.
С другой стороны, многое, что мы видим в С++ сегодня, уходит корнями в те дни. Классы, объявление функций (прототипы функций), конструкторы и деструкторы были частью самой первой версии. Пару лет спустя я добавил встраиваемые функции и перегруженный оператор присваивания. Тогда же появилось различие между инициализацией и присваиванием. Общая перегрузка операторов возникла позднее (1983 или около того), тогда же, когда и виртуальные функции. Люди часто забывают, что параметризованные типы данных были внедрены с самого начала. Я использовал Cfront с заголовком <generic.h>. В течение пары лет я думал, что для обобщённого программирования макросов будет достаточно. Я очень ошибался, зато был прав, считая, что нужно использовать параметризованные типы и функции с (другими) типами. Результатом этого стали шаблоны (1988).
Основной идеей было обогатить язык возможностями, которые позволят пользователям стоить мощные, красивые и эффективные абстракции. Это противоречит идее поддержки абстракций, специфичных для приложений, в самом языке. С++ по сей день использует базовую модель вычислительной машины из языка С, что позволяет создавать портируемые программы, эффективно и целесообразно использующие аппаратное обеспечение. Мы также работаем над постепенным улучшением С++ для поддержки построения эффективных абстракций.
Большая часть попыток разработать хороший язык программирования терпит неудачу. Каково было чувствовать, что всё больше и больше программ вокруг вас написаны на языке, созданном вами? И что, по вашему мнению, стало причиной такого успеха?
Радостно – и в то же время страшновато. Приятно чувствовать, что ты разработал что-то полезное для стольких людей, но это и огромная ответственность, особенно с развитием языка. Если мы добавляли удачные и полезные возможности — мы делали этот мир лучше, но стоило ошибиться — и вред был бы очень большим. И всё же я думаю, что доработка С++ была чередой улучшений. Не все идеи были удачными, но большая часть оказалась очень полезной для большинства, а провалы не были фатальными. С каждым годом С++ становился всё лучше. Сейчас С++ несравнимо более полезен, чем релиз 1.0, выпущенный в 1980. Мы можем писать более красивый код, и он работает быстрее (даже если учесть разницу в быстродействии оборудования).
Причина успеха? Их было много. Чтобы добиться успеха, язык должен быть достаточно хорошим во всём, что нужно пользователям, и при этом не должен быть провальным ни в чём. Недостаточно быть лучшим в мире в одной-двух вещах. В своей основе С++ был и остаётся нацеленным на критические задачи в системах, где производительность и доступ к оборудованию имеют критическое значение (так называемое системное программирование), и особенно системах, где необходимо управление сложностью. Во-вторых, С++ постоянно эволюционировал в соответствии с проблемами окружающего мира, он рос. Он никогда не был «башней из слоновой кости». В конце концов, мне кажется важным, что С++ никогда не жил за счёт рекламы: я давал относительно скромные обещания и сдерживал их.
Вы посвятили С++ большую часть жизни, и продолжаете активно работать над ним по сей день. Что стало причиной такой самоотдачи? Не хотелось ли вам начать работу над новым языком программирования?
Я неоднократно пытался выбраться из разработки С++, но он всегда затягивал меня обратно. Я чувствую, что работа над С++ — мой главный шанс сделать что-то стоящее. Таким образом, С++ — мой главный инструмент для исследования и разработки. Уроки, выученные мной и другими членами сообщества С++, внедряются в язык и библиотеки, где они могут помочь уже миллионам людей.
Конечно, я мечтал о создании нового, более совершенного языка программирования, но нужно очень много времени, чтобы пройти путь от набора идей до полезного инструмента. Сложно соревноваться с С++ на его поле, а большая часть моих интересов – это то, в чём С++ хорош. Кроме того, большинство новых языков терпит неудачу. Очень просто сделать ошибку, разрабатывая что-либо с нуля. Успешные большие системы, как правило, вырастают из более мелких работающих систем.
Что изменилось за 30 лет? Что осталось прежним?
Модель машины и стремление к большей поддержке абстракций остаются неизменными и такими же важными, как и всегда. Это же можно сказать и о внимании, которое уделяется статической (времени компиляции) системе типов данных.
Использование исключений и шаблонов было значительно усовершенствовано, и теперь мы можем писать намного более красивый и функциональный код. И то, и другое появилось как возможные направления развития С++ в документе, который я написал для журнала IEEE Software в 1996 году. Исключения вместе с конструкторами и деструкторами стали основой безопасного управления ресурсами (RAII). Шаблоны способствовали успешному развитию библиотеки STL Алекса Степанова и его идей обобщённого программирования. Буквально в этом году мы разработали прямую языковую поддержку концептов, чтобы дополнить возможности шаблонов С++.

В конце 1980-х люди были помешаны на использовании иерархии классов. Меня же больше интересовало соединение различных стилей программирования в гармоничное целое. В первом издании своей книги я (преднамеренно) не употреблял термин «объектно-ориентированное программирование», а также давал выступления с названиями в духе «С++ — это не просто объектно-ориентированный язык программирования». Позже публика проявила огромный интерес к шаблонному и мета-программированию, иногда забывая, что самое простое решение – часто самое лучшее. Я до сих пор ищу способ передать своё понимание элегантного программирования, основанного на синтезе особенностей языка и возможностей библиотек.
Ещё одна вещь, которая, по моему мнению, будет иметь большое значение в течение нескольких следующих лет – разработка гайдлайнов для инструментов и библиотек. Это поможет сообществу С++ намного быстрее осваивать новые возможности. Один совершенно новый аспект – это то, что мы сможем устранить висячие указатели, открывая возможности для программирования, абсолютно безопасного с точки зрения типов и управления ресурсами. В частности, мы устраняем все утечки ресурсов без сборщика мусора (потому что мы не производим мусора), так что нам не придётся сталкиваться с потерями производительности, хотя безопасность увеличивается. И мы не ограничиваем область применения С++.
Я надеюсь, что всё это поможет решить проблему, существовавшую в С++ всегда: недостаток обучения и понимания С++ даже среди людей, его использующих. С самого начала существовала тенденция описывать С++ как странную версию чего-то ещё. Например, до сих пор иногда говорят, что С++ — это «несколько новых фич, добавленных к С» или «небезопасный Java, в котором не хватает некоторых современных возможностей». Это наносит огромный вред распространению С++. Моя новая книга «Обзор С++» тоже может помочь. Я рассказываю всё о С++ и его стандартной библиотеке на довольно высоком уровне, при этом на меньшем количестве страниц, чем в книге Брайана Кернигана и Денниса Ритчи «Язык программирования Си» (также известна как K&R). Моя книга рассчитана скорее на уже состоявшихся программистов, чем на новичков.
Через несколько дней комитет по С++ соберётся на Гавайских островах, чтобы обсудить работу над следующей крупной версией С++. Как, по вашему мнению, будет выглядеть С++17?
Думаю, более полное представление о том, на что будет похож С++17, у меня появится после собрания, которое состоится на следующей неделе в Коне [Гавайские острова]. Но я настроен (спокойно) и оптимистично. С++11 был большим достижением по сравнению с С++98, и я надеюсь, что С++17 будет таким же большим шагом вперёд по сравнению с С++11.
Например, я надеюсь увидеть:
- концепты (уже есть спецификация ISO TS) для лучшего определения шаблонов
- модули для более быстрой компиляции
- улучшенный STL с диапазонами (предложение Эрика Ниблера)
- сопрограммы (предложение Гора Нишанова)
- библиотеку по работе с сетью (предложение Криса Колхоффа)
- лучшую поддержку многозадачного и параллельного программирования
- и многое другое!
Перевод: http://blog.noveogroup.ru/post/132140074527/
Оригинал: http://cpp-lang.io/30-years-of-cpp-bjarne-stroustrup/
Комментарии (57)

xenohunter
03.11.2015 16:57+3Однако, 4.4 миллиона — это примерно треть населения Москвы. Много же людей пишут на C++!
Было бы интересно узнать, сколько приблизительно вообще профессиональных программистов в мире.


Mikanor
03.11.2015 17:02+9Легендарный язык, на котором можно написать свою карманную вселенную и тут же ее уничтожить, параллельно уничтожив несколько параллельных реальностей.
Наверное самый холиварный язык в мире. И конечно же явления суть описана его автором:
«Есть всего два типа языков программирования: те, на которые люди всё время ругаются, и те, которые никто не использует.»
Bjarne Stroustrup.
П.С. Модули уже дайте а? Такой классный подарок будет.

JKornev
03.11.2015 17:06+4Поздравляю коллег! Лично я ни разу не пожалел что выбрал C\C++ как основные языки разработки

zencd
03.11.2015 17:20Всегда воспринимал С++ как нечто что было всегда, неизменным. Просто никогда не задумывался об этой стороне… А он, оказывается, развивался, не всё сразу построилось так как сейчас воспринимается привычным.
Интересно, почему ООП считалось медленным? В случае С++ весь overhead — только виртуальные функции (+1 операция на lookup), да и никто ведь в здравом уме не будет делать 100% функций виртуальными. Или за-за оверхеда по памяти так считалось?
EndUser
03.11.2015 19:14Как я понимаю, это идёт из времён, «когда машины были большими, а программы маленькими», до эры «купите побольше оперативки и процессор поновее».
Когда бизнес систематически не платил за нефункциональные требования типа скорости софта и другие оптимизации, но платит за обновление вычислительного парка, сформировался эффект оптового производства железа, цена транзакции удешевилась за счёт быстрого железа, что нынче можно спрашивать «нужно ли волноваться из-за оверхеда».
MacIn
03.11.2015 19:16+3Да нет, оверхед здесь побольше. Таблицы VMT, само создание/уничтожение классов. Сейчас этот overhead относительно мал, но давайте посмотрим на ресурсы персоналок в начале 90х… Начиная от набора регистров и до объема памяти.

yatagarasu
03.11.2015 20:02Были времена, когда доступ к памяти выполнялся за десятки тактов, да и сейчас не всегда за один.

Bas1l
04.11.2015 02:25+4Ну вот в числодробилках всяких типа моделирования гидродинамики ООП до сих пор считается медленным. Я видел проект, в котором все было сделано через шаблоны, не было ни одной виртуальной функции. Легко прикинуть. К примеру, у вас система из дискретной равномерной сетки, N*M*L узлов, на каждой итерации надо обработать каждый узел, всего I итераций. В простейшем случае состояние узла на следующей итерации зависит от состояния его ближайших соседей (и его самого) на предыдущей итерации, положим 27 штук соседей ( включая сам узел). Итого получается вложенный цикл из 27*N*M*L*I итераций. Каждое из этих чисел N,M,L,I легко может быть порядка 1000 или 10000 (и это еще очень скромно). Итого 10^13-10^17 итераций. Если у вас в цикле будут вызовы виртуальных функций, то, скорее всего, вы это заметите. Конечно, зависит от того, что еще считается в цикле. В алгоритме, который я пробовал и имею в виду, добавление модного слоя абстракции в этом вложенном цикле на некоторые сущности через динамический полиморфизм сразу стоило 20% времени выполнения.

semenyakinVS
04.11.2015 15:43А зачем ООП вообще нужно для моделирования узлов регулярной сетки? Тем более зачем нужны виртуальные функции?
Bas1l
05.11.2015 01:51+4О, это просто. Вот посмотрите, к примеру, на диаграмму классов уже упомянутого проекта с lattice-boltzmann method. Дело в возможности включать разную физику и численные методы. Можно обходить 15 ближайших узлов, можно 19, можно 27. Можно использовать разные разностные схемы. Можно моделировать однофазный поток, можно многофазный. Если многофазный, то с есть разные методы его моделирования (даже в рамках этого численного метода). Можно включать турбулентность, можно выключать. Можно использовать разные геометрии и граничные условия. В параллельном случае можно использовать разные топологии связей. И т.п. И так у вас набегает 2986 классов, хотя программа все еще, по сути, это вложенные четыре цикла с парой сложений и умножений внутри. К счастью, все комбинации классов обычно можно разрешать статически, поэтому можно обойтись статическим полиморфизмом.
semenyakinVS
05.11.2015 02:10-2И так у вас набегает 2986 классов, хотя программа все еще, по сути, это вложенные четыре цикла с парой сложений и умножений внутри
Похоже на оверинжениринг. Шаблонные функции с массивом флагов для настройки разных параметров алгоритма, как по мне, должно быть достаточно. Зачем ООП?Bas1l
05.11.2015 03:29+5Ну как минимум у вас есть возможность подставлять в шаблонные параметры (класса или пусть и функции) не функцию за функцией, а группы функций (классы), что уменьшает число шаблонных параметров на порядок. Ну и в целом это метод борьбы со сложностью. Можно сгруппировать функции семантически; данные, интересные нескольким функциям, можно добавить в класс. Какие-то поля сделать приватными, чтоб никто их больше не видел и вы точно знали, что за пределами класса о них думать не надо. Делегировать что-то другому классу (конечно, можно делегировать просто разным функциям, но так у вас близкие функции уже сгруппированы, и понять делегирование намного проще). Или, к примеру, если у вас даже с классами шаблонных параметров функции или класса много, вы можете группировать какие-то из них в классы дальше. Приватные поля для кеширования сразу легко вводить и т.п. Короче, все, что пишут в книжках по ООП.
semenyakinVS
05.11.2015 10:24+1Бывает и такое!.. Подумал лучше — и понял, что порол какую-то полную чушь. Из-за глубоко укоренившейся привычки что ООП это иногда медленно, не смог принять для себя гипотезу об оптимальной виртуальности и сразу отбросил возможную объектную реализацию (именно из-за того, что помнил об оверхедах, а не из-за удобства проектирования… а ведь мне показалось что наоборот… беда).
Конечно, если бы виртуальные функции работали быстрее, объектная реализация была бы предпочтительнее. Не прав, приношу свои извинения.
P.S.: Попробовал прикинуть в коде как бы выглядела реализации без ООП — бр-р-р. Как вообще имитация полиморфизма может быть сделана без виртуальных функций? На свич-кейсах как-то не очень хорошо (вроде, по быстродействию это не будет давать весомого преимущества). Делать по гриду под каждый тип и выбирать на основе какой-то индексной таблицы — много памяти, да и тоже не совсем ясно как… Как такое делают на практике?

incogn1too
04.11.2015 06:59-9Типобезопасность и исключения дают ощутимый overhead.

vladon
04.11.2015 10:39+7Типобезопасность даёт оверхед только на времени компиляции.
incogn1too
04.11.2015 11:13-9То-то потоки на столько медленнее printf-ов.

VoidEx
04.11.2015 12:17+3Ну а шаблонный std::sort быстрее нешаблонного с компаратором вида void (*)(void const *, void const *)

0xd34df00d
04.11.2015 15:31+2Нет, не медленнее. Хотя бы потому, что printf'у или scanf'у надо format string ещё разобрать, а в (простых) случаях для потоков это знание зашито в дерево вызова.
Вот локали тормозят, это да.
Lol4t0
04.11.2015 12:26+4В случае С++ весь overhead — только виртуальные функции (+1 операция на lookup)
* На этапе компиляции — это барьер для оптимизаций. Вы не можете встраивать через виртуальные функции
* На этапе выолпнения — проблемы с фетчингом кода. Я даже не знаю, сможет ли в таком случае отработать branch prediction, или будет полная останвка конвеера
Ну и да обычно это не важно


MTonly
03.11.2015 20:38Не оч. удачная инфографика: сразу неочевидно, к какому из событий относится каждый из относительно больших фрагментов блеклого текста — расположенному над ним или сбоку от него, или это вообще «заметки на полях», к конкретным событиям не привязанные. И, да, было бы здорово видеть SVG- или HiDPI-вариант.
gurinderu
03.11.2015 20:43+4Интересно, а Линус Торвальдс праздновал этот день или для него это день траура?
semenyakinVS
03.11.2015 21:21С праздником, любимый язык! Я тебя никогда не брошу и, если понадобиться, буду бороться за тебя до конца!


Andrey2008
04.11.2015 00:38+6А мы, кстати, в честь 30-летия Cfront проверили. Публикация статьи запланирована на четверг.
Andrey2008
05.11.2015 11:08+1А вот и сама статья: К тридцатилетию первого C++ компилятора: ищем ошибки в Cfront.

mapron
04.11.2015 07:29+4Всего в мире сейчас более 19 млн разработчиков,
источник: www.3dnews.ru/912876
Т.е. если верить оценке JetBrains в 4,4 миллиона С++-программистов, каждый четвертый программист в мире знает С++?
Как думаете, насколько адекватна эта оценка? Я думаю, все же тех, для кого этот язык основной, на порядок меньше.
Сам С++ изучаю с 14 лет (т.е. уже 12 лет), из них 4 года — работаю С++-разработчиком. И все еще думаю, что не знаю его =)
С нетерпением из новых стандартов жду модулей.
mapron
04.11.2015 07:32Насчет фразы про «большой шаг после С++98», подумалось
-С++98 — «мажорная» версия, первый стандарт, вроде как 1.0
-С++03 — апдейт, фиксы, вроде 1.1
-С++11 — долго-долго пилили, много-много фич, похоже на версию 2.0
-С++14 — быстро приняли, залатали недостатки 11-го, можно назвать 2.1
-С++17 — модули, сеть, filesystem, аспекты, что там еще получится — попахивает 3.0?Lol4t0
04.11.2015 12:28+2Нет,
-С++98 — «мажорная» версия, первый стандарт, вроде как 1.0
-С++03 — апдейт, фиксы, вроде 1.1
— а с выходом С++11 перешли на модель релизов Google Chromemapron
04.11.2015 16:41Увы, тоже не совсем точное решение. Про автообновление стандарта везде и всюду каждые 6 недель пока можно только мечтать :D
Ну а если серьезно, Вы не считаете, что набор запланированных изменений в 14 был куда меньше? Просто мне кажется, обрадовались, что 14 релиз удалось «быстро выпустить», в срок, и теперь опять раскатали губу на много всего. Да даже 1 или две фичи из планируемого в 17 — будет в 10 раз круче 14 апдейта, как мне кажется (одни модули чего стоят!).
p.s. я знаю про декларируемую схему работы, на хабре даже картинку постили.

voischev
04.11.2015 10:03По такому поводу хочется включить, всем известную, песню группы «Сектор Газа» :)


BloodJohn
04.11.2015 11:47+3Страуструп — легенда.
Книжку его прочитал от корки до корки.
На экзамене преподавателю объяснял разницу типов связей между классами и объектами.
И хотя сейчас на нем не пишу, но желаю долгих лет языку и его создателю.

PsyHaSTe
06.11.2015 18:27Жалко, что не было вопросов о его отношении к «убийцам», типа раста. Считает ли он, что они его вскоре заменят, или что плюсам нет конкуренкции, и все эти расты — игры в песочнице… Было бы интересно узнать мнение такого человека по подобному вопросу.
yatagarasu
06.11.2015 21:09А на расте можно писать библиотеки для всех остальных языков?
yatagarasu
06.11.2015 21:39И сам отвечу на свой вопрос, да вроде как можно вызывать раст функции из с кода. https://doc.rust-lang.org/book/ffi.html#calling-rust-code-from-c
Так что потенциал есть, но как-то мало документации про это.

webhamster
09.11.2015 07:54+1Не увидел в обещаниях нормальных utf8- строк. До сих пор считается, что строки не нужны?
DrLivesey
C++ наше многое. Пошел отмечать.