
Этой ночью представят новую версию Kubernetes. Среди значимых улучшений релиза:
возможность создавать тома из снапшотов, которые находятся в разных пространствах имен;
поддержка OpenAPI v3 для команды
kubectl explain;выравнивание ресурсов CPU в NUMA-кластере с учетом расстояния между узлами.
Также в Kubernetes 1.26 появится первая фича «Фланта», которая принята как Kubernetes Enhancement Proposal (KEP), а не просто как pull request.

Для подготовки статьи использовалась информация из таблицы Kubernetes enhancements tracking, конкретные issues, KEPs и pull requests, CHANGELOG-1.26, а также обзор Sysdig.
Всего в новом релизе 39 изменений. Из них:
16 новых функций (alpha);
10 продолжают улучшаться (beta);
12 признаны стабильными (stable);
1 устарела.
Примечание
Мы сознательно не переводим названия фич на русский. Они в основном состоят из специальной терминологии, с которой инженеры чаще встречаются в оригинальной формулировке.
KEP от «Фланта»: Auth API to get self user attributes
Архитектор Kubernetes-платформы Deckhouse Максим Набоких в Slack’е разработчиков K8s указал на сложности, с которыми приходится сталкиваться при аутентификации:
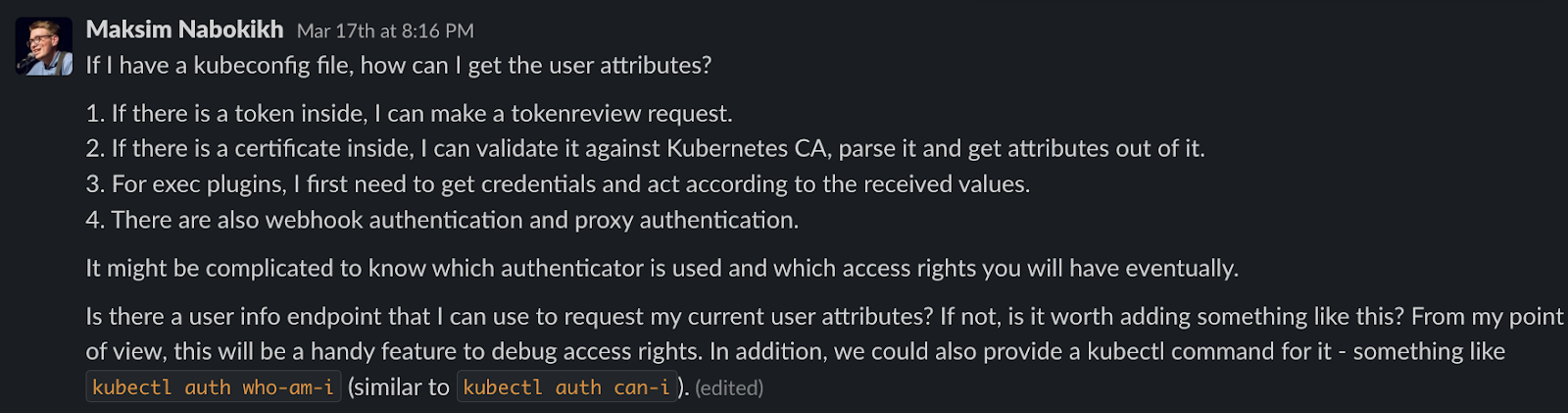
Сейчас в Kubernetes нет ресурса, который бы напрямую представлял пользователя и его атрибуты. Их невозможно получить из kubeconfig-файла. Вместо этого K8s использует аутентификаторы, чтобы получить данные из токена, сертификата X.509, от OIDC-провайдера или внешнего вебхука. Все эти инструменты расширяют возможности аутентификации, но ограничивают возможности для отладки процесса. Зачастую сложно понять, какой аутентификатор используется, и какие права доступа будут выданы пользователю.
Разработчики K8s, ответственные за направление аутентификации и авторизации, одобрили предложенное Максимом решение:

Улучшение Auth API to get self user attributes добавляет в группу authentication.k8s.io новый API endpoint — SelfSubjectReview. С его помощью можно увидеть атрибуты текущего пользователя после завершения процесса аутентификации. Делается это с помощью команды kubectl auth who-am-i.
Команда формирует POST-запрос. Пример:
POST /apis/authentication.k8s.io/v1alpha1/selfsubjectreviews{
"apiVersion": "authentication.k8s.io/v1alpha1",
"kind": "SelfSubjectReview"
}В ответ API-сервер заполняет статус атрибутами и возвращает его пользователю:
{
"apiVersion": "authentication.k8s.io/v1alpha1",
"kind": "SelfSubjectReview",
"status": {
"userInfo": {
"name": "jane.doe",
"uid": "b6c7cfd4-f166-11ec-8ea0-0242ac120002",
"groups": [
"viewers",
"editors",
"system:authenticated"
],
"extra": {
"provider_id": ["token.company.dev"]
}
}
}
}Есть разные форматы вывода — от сокращенного к более подробному. Формат выбирается через флаги. Пример простейшего вывода:
ATTRIBUTE VALUE
Username jane.doe
Groups [system:authenticated]С дополнительными атрибутами:
ATTRIBUTE VALUE
Username jane.doe
UID b79dbf30-0c6a-11ed-861d-0242ac120002
Groups [students teachers system:authenticated]
Extra: skills [reading learning]
Extra: subjects [math sports]Также с помощью флагов можно сразу конвертировать вывод в JSON- или YAML-формат.
Новая фича крайне полезна, когда в Kubernetes-кластере используется сложный процесс аутентификации, и администратор хочет получить полную userInfo после того, как все механизмы аутентификации выполнены.
Узлы
Dynamic resource allocation
Kubernetes становится всё более востребованным для управления новыми типами рабочих нагрузок и сред. Например, в пакетной обработке (batch processing) и граничных вычислениях (edge computing). Однако Pod’ам с такими нагрузками бывает недостаточно только лишь ресурсов процессора, памяти и хранилища — того, что сейчас может предложить K8s. Иногда нужен доступ к ресурсам специального оборудования типа аппаратных акселераторов. Их можно использовать, например, чтобы сжимать, распаковывать, шифровать и расшифровывать данные. Акселераторы могут устанавливаться в географически удаленном дата-центре, а их ресурсы запрашиваться по мере необходимости.
KEP добавляет API, в котором описаны новые типы ресурсов для Pod’ов. Эти ресурсы могут:
подключаться по сети;
распределяться между несколькими контейнерами или Pod’ами;
инициализироваться несколько раз, в разных Pod’ах;
создаваться на основе пользовательских параметров, которые определяют требования к ресурсам и их инициализации.
В API добавляются новые объекты: ResourceClaimTemplate и ResourceClass, а в настройки Pod’а — поле resourceClaims.

Новые типы ресурсов (оборудования) будут поддерживаться с помощью аддонов, предоставляемых вендорами. Таким образом отпадает необходимость в доработке самого Kubernetes. Нововведение не повлияет на существующий механизм запроса ресурсов: планировщик K8s будет так же координировать распределение собственных ресурсов — RAM, CPU, томов, — а также ресурсов, которыми управляют аддоны.
Improved multi-numa alignment in Topology Manager
Компонент kubelet’а TopologyManager предоставляет политики, с помощью которых можно настраивать выравнивание ресурсов на одном или нескольких NUMA-узлах (Non-Uniform Memory Architecture). Однако TopologyManager не учитывает расстояние между NUMA-узлами — важный показатель, который влияет на производительность приложений, критичных к задержкам.
Расстояние — относительная величина; варьируется в диапазоне от 10 (локальный доступ) до 254 (максимальное расстояние). Оптимальная локализация получается, когда для рабочей нагрузки минимизированы и число NUMA-узлов, и расстояние между ними.
Существующее ограничение может значительно снижать производительность требовательных к задержкам приложений в кластерах NUMA — например, если TopologyManager решает выровнять ресурсы между сильно распределенными узлами.
Новая фича добавляет две ключевых опции:
разрешает
TopologyManager’у во всех его политиках предпочитать набор NUMA-узлов с наименьшим расстоянием между ними;вводит новый флаг
topology-manager-policy-options, с помощью которого можно «заставлять»TopologyManager’а учитывать расстояние.
Подробнее о логике расчета и учета среднего расстояния между NUMA-узлами — в «Деталях реализации».
О других улучшениях, связанных с NUMA, читайте в наших обзорах релизов 1.25 (CPU Manager policy: socket alignment) и 1.23 (CPUManager policy option to distribute CPUs across NUMA nodes).
Kubelet evented PLEG for better performance
Kubelet управляет Pod'ами узла и приводит их состояние, которое описано в PodSpec. Для этого kubelet должен реагировать на изменения как в спецификации Pod'а, так и в состоянии контейнера. В первом случае он отслеживает изменения спецификаций Pod'а из нескольких источников. Во втором — периодически опрашивает среду выполнения контейнеров. Текущая частота опроса, жестко заданная по умолчанию, — раз в 1 секунду.
Периодически большое количество запросов вызывает скачки в загрузке процессора (даже когда нет изменений спецификации или состояния), снижает производительность и надежность из-за перегруженности среды выполнения контейнера. Всё это ограничивает масштабируемость kubelet’а.
Улучшение модернизирует подход, предложенный в KEP’е Kubelet: Pod Lifecycle Event Generator (PLEG). Предыдущее улучшение изменяло работу уже устаревшего dockershim, новое меняет работу CRI.
Согласно новому подходу, kubelet получает актуальные данные о состоянии Pod'а по модели List/Watch. В частности, прослушивает потоковые события сервера gRPC из CRI, которые необходимы для генерации событий жизненного цикла Pod'а — то есть не опрашивает среду выполнения. Тем самым уменьшается необязательное использование ресурсов CPU kubelet’ом, как и нагрузка на CRI.
cAdvisor-less, CRI-full container and pod stats
Чтобы собирать статистику контейнеров — например, потребление CPU и RAM, — в K8s используется cAdvisor. Улучшение переносит часть этой функциональности на CRI.
Существует два основных API, которые клиенты используют для сбора статистики о запущенных контейнерах и модулях: суммарный API и /metrics/cadvisor. kubelet отвечает за реализацию суммарного API, а cAdvisor — за выполнение /metrics/cadvisor. Сейчас CRI API не предоставляет достаточно метрик, чтобы заполнить все поля для любого endpoint'а, однако используется для заполнения некоторых полей суммарного API. Это приводит к путанице в происхождении метрик, дублированию работы cAdvisor'а и CRI, а в итоге — к общему снижению производительности.
Улучшение подразумевает отказ от использования cAdvisor для сбора статистики на уровне контейнера и Pod'а и перенес этой функции в CRI. Для этого:
в CRI API добавляются необходимые метрики, чтобы заполнять поля
podиcontainerв суммарном API непосредственно из CRI;CRI транслирует требуемые метрики для заполнения полей
podиcontainerв/metrics/cadvisor.
Stable-фичи
Kubelet credential provider (#2133) — расширяемый механизм плагинов, с помощью которого kubelet может динамически получать учетные данные из реестра контейнеров любого облачного провайдера. До этого в K8s были только встроенные механизмы для реестров Azure, Elastic и Google.
Graduate to CPUManager to GA (#3570) — компонент kubelet’а, который помогает распределять рабочие нагрузки, назначая выделенные CPU контейнерам конкретного Pod’а. Подробнее о CPU Manager — в нашем переводе.
Graduate DeviceManager to GA (#3573) — возможность для kubelet’а использовать ресурсы внешних устройств с помощью плагинов, которые разрабатывают поставщики. Среди таких устройств, кроме процессора и памяти, — GPU, NIC, FPGA, InfiniBand, хранилища.
Приложения
Allow StatefulSet to control start replica ordinal numbering
Цель этого улучшения — разрешить миграцию StatefulSet’а между пространствами имен, между кластерами, а также разбивать его на сегменты без простоев в работе приложения.
У существующих подходов к миграции есть недостатки:
Резервное копирование и восстановление, когда делается резервная копия приложения, и оно создается в другом месте. Это вызывает простой приложения на время от момента удаления старого StatefulSet'а и до момента создания нового.
Миграция на уровне Pod'ов. Использование
--cascade=orphanпри удалении StatefulSet'а сохраняет Pod'ы. Это позволяет оператору приложения (application operator) удалять и перепланировать их по отдельности. Но поскольку Pod'ы эфемерны, требуется эмулировать поведение StatefulSet'а и перепланировать Pod'ы при их повторном запуске.
Сейчас StatefulSet из N реплик неявно нумерует Pod'ы от 0 до N-1. При развертывании Pod'ы создаются по порядку, от Pod’а 0 к Pod’у N-1. Удаляются же от N-1 к 0. Такое поведение ограничивает сценарий миграции, когда оператор приложения хочет уменьшить количество Pod'ов в исходном StatefulSet'е и увеличить в целевом.
Конечным порядковым номером (N-1) можно управлять с помощью поля replicas. Нововведение позволяет первому порядковому номеру StatefulSet’а начинаться с любого натурального числа k. То есть StatefulSet-контроллер может управлять сегментами (slices) StatefulSet’а в диапазоне [k, N+k-1]. Это позволяет разделять StatefulSet между исходным и конечными сегментами по порядковому номеру k.
Для реализации фичи в манифест StatefulSet’а добавляется новое поле spec.ordinals.start, в котором указывается стартовый номер для реплик, контролируемых StatefulSet’ом.
Функция полезна, например, для случаев миграции StatefulSet’а между кластерами и между пространствами имен. В сочетании с грамотным использованием PodDistruptionBudgets это гарантирует плавную миграцию реплик без простоя.
PodHealthyPolicy for PodDisruptionBudget
Pod Disruption Budget (PDB) выполняет две задачи:
Обеспечивает максимально возможные ограничения на спланированное прерывание работы Pod’ов, чтобы сохранить доступность части из них.
Предотвращает потерю данных, блокируя удаление Pod'ов до тех пор, пока любые данные, уникальные для удаляемого Pod'а, не будут скопированы или распределены между другими Pod'ами.
PDB не дает возможности указать, как обрабатывать Pod'ы в состоянии Running. Из-за этого у пользователей, которые хотят убедиться, что доступно только минимальное количество Pod'ов, могут возникнуть проблемы. Например, Pod'ы, которые находятся в состоянии Running, но еще не Ready, не могут быть удалены, даже если общее количество Pod'ов превышает пороговое значение PDB. Это может блокировать сервисы вроде Cluster Autoscaler и бесполезно нагружать узлы. Для тех, кто применяет PDB, чтобы предотвратить потерю данных, такой алгоритм может быть критичным. Вдобавок API может использоваться не по назначению.
В этом улучшении добавляется поле podHealthyPolicy. Пользователи могут указывать, что Pod'ы «здоровы» и, следовательно, попадают под ограничения Pod Disruption Budget, либо их следует рассматривать как уже отключенные, и поэтому могут быть проигнорированы PDB. Новые статусы для Pod’ов: status.currentHealthy, status.desiredHealthy и spec.unhealthyPodEvictionPolicy.
Beta-фичи
Retriable and non-retriable Pod failures for Jobs (#3329) — улучшение, альфа-версия которого появилась в предыдущем релизе K8s. Помогает учитывать нежелательные причины перезапуска Job’а и, если нужно, завершать его досрочно, игнорируя параметр backoffLimit.
Stable-фичи
Job tracking without lingering Pods (#2307) — позволяет Job’ам быстрее удалять неиспользуемые Pod’ы, чтобы освободить ресурсы кластера. Подробнее — в обзоре 1.22.
Хранилище
Provision volumes from cross-namespace snapshots
Пользователи могут создавать тома (volumes) из снапшотов. Однако это работает только для VolumeSnapshot в том же пространстве имен: нельзя создать PVC (persistent volume claim) в целевом пространстве имен, если VolumeSnapshot находится в другом.
С этим улучшением пользователи получают возможность создавать тома из снапшотов, которые находятся в разных пространствах имен. Фича устраняет ограничения, которые мешали пользователям и приложениям выполнять фундаментальные задачи вроде сохранения контрольной точки базы данных, когда приложения находятся в одном пространстве имен, а службы — в другом.
API PersistentVolumeClaim теперь может обрабатывать VolumeSnapshot с несколькими пространствами имен в качестве источника данных, а также расширяет возможности CSI external provisioner. Чтобы применять только разрешенные VolumeSnapshot’ы из других пространств имен, используется ReferenceGrant CRD.
Ниже — пример, в котором необходимо пробросить том из пространства имен prod в пространство имен test. Чтобы воспользоваться новой функциональностью, нужно выполнить два шага:
В пространстве имен
prodсоздать ресурсReferenceGrant. С его помощью можно ссылаться наVolumeSnapshot foo-backupвprodиз любогоPersistentVolumeClaimвtest:
apiVersion: gateway.networking.k8s.io/v1alpha2
kind: ReferenceGrant
metadata:
name: bar
namespace: prod
spec:
from:
- kind: PersistentVolumeClaim
namespace: test
to:
- group: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
name: foo-backupВ пространстве имен
testсоздатьPersistentVolumeClaim foo-testing, который ссылается наVolumeSnapshot foo-backupвprodкак на источник данных:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: foo-testing
namespace: test
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Mi
dataSourceRef2:
apiGroup: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
name: foo-backup
namespace: prod
volumeMode: FilesystemКак только CSI provisioner обнаружит, что в VolumeSnapshot указано непустое пространство имен — dataSourceRef2, он проверит все ReferenceGrants в PersistentVolumeClaim.spec.dataSourceRef2.namespace, чтобы узнать, открыт ли доступ к снапшоту. Если доступ есть, том будет создан.
Beta-фичи
Non-graceful node shutdown (#2268) — возможность заранее активировать функцию принудительного отключения Pod’ов для случаев, когда Node Shutdown Mananger не срабатывает. Подробнее о фиче — в обзоре 1.24.
Retroactive default StorageClass assignment (#3333) ослабляет требования к порядку взаимодействия между вновь созданным и не привязанным PVC и StorageClass’ом по умолчанию. PV-контроллер может назначать SC по умолчанию любому не привязанному PVC с атрибутом pvc.spec.storageClassName=nil.
Stable-фичи
vSphere in-tree to CSI driver migration (#1491) — миграция со встроенного в кодовую базу K8s плагина хранилища vSphere на CSI-драйвер.
Azure file in-tree to CSI driver migration (#1885) — то же самое, но для хранилища Azure.
Allow Kubernetes to supply pod's fsgroup to CSI driver on mount (#2317) — предоставляет CSI-драйверу fsGroup Pod’ов в виде явного поля, чтобы изменять политику владения томом сразу во время монтирования. Подробнее — в обзоре 1.23.
Планировщик
Pod scheduling readiness
Pod'ы считаются готовыми к планированию сразу после того, как созданы. Планировщик Kubernetes ищет узлы для размещения всех ожидающих Pod'ов. Однако в реальности некоторые Pod'ы могут долго оставаться в состоянии miss-essential-resources («отсутствие необходимых ресурсов»). Эти Pod'ы сбивают с толку планировщик и компоненты типа Cluster Autoscaler.
У Pod’ов, планирование которых временно приостановлено, нет специальной метки. Из-за этого планировщик тратит на них время (циклы). Определяя эти Pod’ы как незапланированные, он пытается запланировать их снова, что тормозит планирование остальных Pod’ов и снижает общую производительность процесса.
В улучшении дорабатывается API и механика — так, чтобы пользователи или оркестраторы могли понимать, когда Pod полностью готов для планирования. В Pod API добавляется новое поле .spec.schedulingGates со значением по умолчанию nil. Pod'ы, у которых значение этого поля не равно nil, будут «припаркованы» во внутреннем пуле unschedulablePods планировщика. Он обработает их, когда поле изменится на nil.
Beta-фичи
Take taints/tolerations into consideration when calculating PodTopologySpread skew (#3094) улучшает механизм распределения Pod’ов по узлам, в том числе skew-процесс. Теперь планировщик может учитывать свойства taints и tolerations при обработке ограничений на распространение топологии. Подробнее — в обзоре 1.25.
Сеть
Minimizing iptables-restore input size
У вызова iptables-restore есть ограничение: если требуется указать какое-либо правило в цепочке iptables, нужно указывать каждое правило этой цепочки. Чтобы увеличить производительность режима kube-proxy iptables в больших кластерах, предлагается исключить из iptables-restore правила, которые не изменялись.
Улучшение позволяет отслеживать, какие объекты Service и EndpointSlice изменились с момента последнего вызова iptables-restore, и выводить только цепочки, специфичные для этих объектов. В случае сбоя частичного вызова iptables-restore kube-proxy поставит в очередь еще одну синхронизацию и повторно выполнит полный iptables-restore. Также kube-proxy всегда будет выполнять полную повторную синхронизацию при изменении лейблов узлов, связанных с топологией, и по крайней мере один раз за каждый iptablesSyncPeriod.
Beta-фичи
Proxy Terminating Endpoints (#1669) оптимизирует работу kube-proxy при обработке endpoint’ов, чтобы улучшить возможности управления трафиком и общую надежность Kubernetes.
Expanded DNS configuration (#2595) расширяет возможности для настройки DNS. Теперь в Kubernetes можно применять больше путей поиска DNS и увеличить список этих путей, чтобы поддерживать новые функции DNS-сервисов. Подробнее — в обзоре 1.22.
Stable-фичи
Support of mixed protocols in Services with type=LoadBalancer (#1435) дает возможность пользователям открывать свои приложения по одному IP-адресу, но через разные протоколы уровня L4 с помощью LoadBalancer’а облачного поставщика.
Tracking Terminating Endpoints (#1672) позволяет отслеживать, действительно ли завершается endpoint без необходимости просмотра связанных с ним Pod’ов.
Service Internal Traffic Policy (#2086) разрешает маршрутизацию трафика внутренних сервисов на локальные узлы и endpoint’ы, которые чувствительны к топологии.
Reserve Service IP Ranges For Dynamic and Static IP Allocation (#3070) жестко закрепляет определенный диапазон IP-адресов для статической и динамической раздачи, чтобы уменьшить вероятность конфликтов при создании сервисов со статическими IP. Подробнее — в обзоре 1.24.
API
CEL for Admission Control
Улучшение предоставляет новый способ контроля доступа без необходимости задействовать вебхуки. В основе — функция проверки CRD, которая появилась в 1.23 и добавила поддержку языка CEL как альтернативу вебхукам. Новая фича предлагает конкретное практическое применение CEL.
В группу admissionregistration.k8s.io вводится новый ресурс: ValidatingAdmissionPolicy. Он содержит CEL-выражения для проверки политики доступа и объявляет, как политика может быть сконфигурирована для использования. Пример:
apiVersion: admissionregistration.k8s.io/v1alpha1
kind: ValidatingAdmissionPolicy
metadata:
name: "replicalimit-policy.example.com"
spec:
paramSource:
group: rules.example.com
kind: ReplicaLimit
version: v1
matchConstraints:
resourceRules:
- apiGroups: ["apps"]
apiVersions: ["v1"]
operations: ["CREATE", "UPDATE"]
resources: ["deployments"]
denyReason: Invalid
validations:
- name: max-replicas
expression: "object.spec.replicas <= params.maxReplicas"
messageExpression: "'object.spec.replicas must be no greater than ' + string(params.maxReplicas)"
# ...другие поля, связанные с правилом...Улучшение не предназначено для полной замены вебхуков, так как они могут поддерживать возможности, которые не подходят для встроенной реализации.
Aggregated Discovery
Об операциях, которые поддерживает сервер API Kubernetes, сообщается через набор небольших документов, разделенных по группам в соответствии с номером версии. Все клиенты API Kubernetes, такие, например, как kubectl, должны отправить запрос каждой группе, чтобы «обнаружить» доступные API. Это вызывает множество запросов к кластерам и, как следствие, — задержки и троттлинг. Когда в API добавляются новые типы, их нужно извлекать заново, что приводит к дополнительному потоку запросов.
Улучшение предлагает централизовать механизм «обнаружения» в двух агрегированных документах, чтобы клиентам не нужно было отправлять множество запросов API-серверу для извлечения всех доступных операций.
Чтобы сократить поток запросов, предлагается ограничиться двумя endpoint'ами: /api и /apis. В запросы к этим двум endpoint'ам клиенты должны включить параметр as=APIGroupDiscoveryList в поле Accept. Сервер вернет агрегированный документ APIGroupDiscoveryList со всеми доступными API и их версиями.
Beta-фичи
Kube-apiserver identity (#1965) предоставляет механизм, с помощью которого контроллеры могут идентифицировать kube-apiserver'ы в кластере по их ID.
CLI
OpenAPI v3 for kubectl explain
Open API v3 расширяет возможности API Kubernetes: пользователи могут получить доступ к таким атрибутам как nullable, default, полям валидации oneOf, anyOf и так далее. Поддержка Open API v3 в Kubernetes достигла бета-версии в 1.24.
Сейчас CRD определяют свои схемы в формате OpenAPI v3. Для обслуживания документа /openapi/v2, который использует kubectl, приходится преобразовывать формат v3 в v2. Процесс сопровождается потерями данных: kubectl explain при взаимодействии с CRD может выдавать неточную информацию или вообще не показывать некоторые поля. Преобразование v3 в v2 вызывает ошибки, например, при попытке использовать kubectl explain c полями типа nullable. В результате kubectl ничего не отображает.
Предложено усовершенствовать kubectl explain:
изменить источник данных с OpenAPI v2 на Open API v3;
заменить ручной вариант
kubectl explainнаgo/template;предоставить разные форматы вывода, включая простой текст и markdown.
Чтобы получить данные в виде простого текста, можно использовать привычный синтаксис:
kubectl explain podsДля «сырых» данных в JSON-формате, понадобится флаг:
kubectl explain pods --output openapiv3Для вывода в HTML и markdown — флаги --output html и --output md.
Beta-фичи
Kubectl events (#1440) — команда, которая расширила возможности логирования событий в K8s и решила проблему ограничености kubectl get events.
Разное
Kubernetes component health SLIs
Понятие Service Level Agreement (SLA), или уровень обслуживания, включает в себя две составляющих, которые актуальны и для Kubernetes.
Service Level Objectives (SLO) — цели уровня обслуживания;
Service Level Indicator (SLI) — индикаторы уровня обслуживания.
Если есть возможность настроить и анализировать SLI, можно формировать SLO.
Сейчас данные проверки работоспособности компонентов K8s отображаются в неструктурированном формате. Они обрабатываются и интерпретируются агентами систем мониторинга, а также kubelet’ом. После этого, если необходимо, агенты выполняют дальнейшие действия. При таком процессе создавать доступные SLO нелегко, так как для анализа данных о работоспособности и их преобразования в SLI чаще всего требуется внешний агент.
Улучшение позволяет отправлять данные SLI в структурированном виде и последовательно — так, чтобы агенты мониторинга могли использовать эти данные с более высокими интервалами очистки и создавать SLO и алерты на основе этих SLI.
В компоненты Kubernetes добавляется новый endpoint /metrics/sli, который возвращает данные SLI в формате Prometheus. Таким образом, Kubernetes получает стандартный формат для запроса данных о состоянии его компонентов (бинарников и т. п.). Вместе с этим отпадает необходимость в Prometheus exporter’е.
В alpha-версии планируется реализовать возврат статусов в одном из форматов: Success, Error, Pending — для одного из типов: livez, readyz, healthz.
Предлагается использовать две метрики:
gauge («индикатор») — показывает текущий статус healthcheck’а;
counter («счетчик») — запись совокупных подсчетов для каждого healthcheck’а.
С помощью этой информации можно проверить состояние внутренних компонентов Kubernetes. Например:
kubernetes_healthcheck{name="etcd",type="readyz"}И создать алерт, который оповещает, когда что-то идет не так:
kubernetes_healthchecks_total{name="etcd",status="error",type="readyz"} > 0Extend metrics stability
Порядок стабилизации метрик первоначально был введен для защиты значимых метрик от проблем при использовании в downstream’е. Метрики могут быть alpha или stable. Гарантировано стабильны только stable-метрики.
С этим улучшением появляются дополнительные классы стабильности — в первую очередь, чтобы синхронизировать этапы стабилизации метрик с этапами стабилизации релизов Kubernetes. Такая необходимость стала очевидной с появлением проверки готовности новых фич к production (production readiness review process) и обратной связи от рецензентов, которые сообщали о том, что иногда метрики упускают из виду и путают с событиями.
К полям метрик предлагается добавить дополнительные статусы:
Internal— метрики для внутреннего использования (т. е. класс метрик, которые не соответствуют релизам) или низкоуровневые метрики, которые обычный K8s-оператор не понимает или не может на них реагировать должным образом.Beta— более зрелая стадия метрики с большими гарантиями стабильности, чемalphaилиinternal, но менее стабильная, чемstable.
Также предлагается изменить семантическое значение alpha-метрики таким образом, чтобы она представляла собой начальную стадию улучшения, предложенного в KEP, а не весь класс метрик без гарантий стабильности.
Host network support for Windows pods
Windows поддерживает всё необходимое, чтобы контейнеры могли использовать сетевое пространство имен узла. Нововведение предлагает добавить эту функциональность в Kubernetes и уравнять в сетевых возможностях Pod’ы Windows с Pod'ами Linux.
Сейчас для ПК с Windows можно установить hostNetwork=true, но это ничего не изменит (если только в Pod’е нет контейнеров hostProcess).
В кластерах с большим количеством сервисов узлам Windows может не хватать портов. Например, небольшому количеству Pod'ов необходимо предоставить доступ ко многим портам: тогда лучше было бы использовать сеть use host вместо nodePorts. А чтобы предоставить доступ ко многим портам во многих Pod'ах, вместо функции CNI hostPort лучше использовать hostNetwork=true.
Для реализации нововведения планируется обновить kubelet. Это позволит заполнить необходимые поля CRI API при запуске в Windows. При настройке изолированной среды для Pod’ов, в которых указано hostNetwork=true, среде выполнения контейнеров (containerd) можно будет указать сетевое пространство имен узла.
Beta-фичи
Reduction of Secret-based Service Account Tokens (#2799) избавляет от необходимости использовать токен из секрета с учетными данными для доступа к API. Данные передаются напрямую из TokenRequest API и монтируются в Pod с помощью защищенного тома.
Signing release artifacts (#3031) усиливает защиту ПО, развернутого в Kubernetes, от атаки на цепочку поставок (supply chain attack). В beta-версии фичи появилась возможность подписывать стандартные для Kubernetes артефакты релиза — бинарники и образы. Подробнее — в обзоре 1.24.
Stable-фичи
Support for Windows privileged containers (#1981) — поддержка привилегированных контейнеров, у которых те же права на доступа к хосту, что и у процессов, запущенных непосредственно на хосте.
Устаревшие фичи
Dynamic Kubelet Configuration (#281) позволяла развертывать новые конфигурации kubelet через API Kubernetes в рабочем кластере.
Pull request от «Фланта» в Vertical Pod Autoscaler
Помимо KEP’а в код K8s принято еще одно улучшение от нашего инженера — Дениса Романенко. Фича добавила в Cluster Autoscaler (VPA) возможность подсчета реплик в DaemonSet’ах, чтобы предотвратить массовый однократный перезапуск Pod’ов. (NB: pull request не связан с релизом 1.26.)
Некоторые из удаленных фич
В 1.26 больше не поддерживаются:
CRI v1alpha2.
containerd v1.5 и более ранние версии. Необходимо обновить containerd как минимум до v1.6.0.
Flow control API: вместо
flowcontrol.apiserver.k8s.io/v1beta1нужно использоватьflowcontrol.apiserver.k8s.io/v1beta2.HPA API: вместо
autoscaling/v2beta2—autoscaling/v2.Механизм встроенной аутентификации, ориентированный на конкретных провайдеров, удален из
client-goиkubectl. Нужно использовать независимый механизм.Режим
userspaceв kube-proxy больше не поддерживается для Linux и Windows.Встроенная интеграция хранилищ OpenStack.
Встроенный драйвер GlusterFS.
Обновления в зависимостях Kubernetes
etcd 3.5.5.
Go 1.19.3.
cri-tools 1.25.0.
grpc 1.49.0.
P.S.
Читайте также в нашем блоге:

Fitrager
Я только на 1.24.8 все обновил. Слишком быстро они делают новые релизы.