
Думаете, Apple Silicon Air и iMac выглядят совсем уж "не серьезно" для задач обработки многотерабайтных данных? Я сам так и думал, к счастью, реальность оказалась намного интереснее. Давайте посмотрим на топовые Apple Silicon M1 iMac и M2 Air на примерах работы с данными спутниковой интерферометрии (мое хобби и, порой, работа).
Ниже есть ссылки на образы Docker, так что все результаты легко воспроизвести на разных операционных системах и устройствах.
Введение
Лет 20 лет назад я работал над своей мастерской диссертацией, посвященной вычислительной интерферометрии и голографии (в нелинейных оптических средах), месяцами проводя все вычисления на простеньком десктопе той поры. Сегодня же программы спутниковой интерферометрии требуют минимум 16-32 GB RAM и наличия видеоускорителя для самых простых задач, а для сложных и половины терабайта памяти и недель вычислений порой оказывается недостаточно. И я писал на С в те времена, и современный софт написан на C, так что есть причины удивиться. Вот я и удивился — настолько, что начал участвовать в разработке открытого пакета спутниковой интерферометрии GMTSAR. Занимался я этим в свободное время на стареньком Apple MacBook Pro 2013 8 GB RAM Intel 2 cores 512 GB SSD, поскольку мой основной ноутбук помощнее (тоже прошка, 15") приказал долго жить в период ковида и замену я долго не мог подобрать. А дальше я, наконец-то, выбрал новый компьютер — обзавелся Apple Silicon iMac 16 GB RAM 2 TB SSD, и это на порядок ускорило разработку и работу с софтом. Разница оказалась столь разительна, что ей хочется поделиться на примерах решения реальных задач, вместо очередных "синтетических тестов" производительности.
К слову, через неделю-другую использования iMac меня ждало небольшое потрясение — компьютер вдруг тихонько загудел на несколько секунд. Быстрая проверка показала, что это включились кулеры — а я был уже уверен, что в спецификации что-то схитрили или напутали и кулеров в нем вовсе нет, ведь не могут же они не включаться и быть не слышны на тех задачах, что я на нем считаю. Оказалось, кулеры есть — но включаются редко и тихо на малых оборотах, не сравнить с воем реактивного истребителя Intel MacBook Pro.
Про спутниковую интерферометрию
Спутниковая интерферометрия это просто классический пример "числодробительных" задач. В самом деле, если оптическая интерферометрия просто регистрирует результат интерференции — так называемую интерференционную картину, то спутниковая интерферометрия вовсе не нуждается в наличии какой-либо интерференции и обрабатывает просто отраженный от поверхности планеты сигнал от излучения спутникового радара. Идея в том, чтобы вычислить результат интерференции так, как будто разновременные снимки сделаны в один и тот же момент времени — так мы получаем реально не существующую чисто вычислительную интерференционную картину, в которой, тем не менее, закодирована информация о мельчайших смещениях земной поверхности (вплоть до долей миллиметра). Серии снимков одной и той же территории, сделанные в разные дни, месяцы и годы, позволяют построить огромное количество интерферограмм, по одной интерферограмме для каждой упорядоченной пары снимков. При этом для вычисления интерферограмм нам нужно учесть влияние эффекта Доплера, разницу положения спутников на орбите в моменты съемки, влияние рельефа, состояние атмосферы (приводящее к задержке прохождения волны), выполнить пространственную фильтрацию данных и еще посчитать много всего. Да и сами данные имеют немалый размер — каждый SLC снимок в zip-архиве занимает около 5 GB для спутников Sentinel-1 (и впятеро больше для планируемых спутников нового поколения), при этом исходные данные имеют разрешение ~4x15m — такой размер пиксела намного превосходит оптическое разрешение снимка, поэтому после обработки данные загрубляются до разрешения 15m и менее (типичное разрешение равно 60m).
Очевидно, что для таких вычислений нужны мощные рабочие станции и серверы. Кластеры здесь мало применимы — объемы передачи данных между нодами оказываются настолько гигантскими, что все вычисления необходимо проводить на одном хосте. Или… может быть, нужен всего лишь Air Apple Silicon?
Технологии
Этот раздел заполнен техническими терминами и деталями реализации, если вы не разработчик Big Data, то смело можете переходить к следующему разделу!
В настоящий момент, пакет PyGMTSAR использует часть бинарных утилит из состава GMTSAR, написанных на С — именно они и обуславливают минимальные требования по необходимой памяти. В то же время, наиболее ресурсоемкая обработка стэка интерферограмм целиком написана на Python. Для оценки размеров данных — для интервала 6 лет это 1000 интерферограмм, размер каждой интерферограммы и коррелограммы порядка 1 GB, для каждой интерферограммы выполняются операции удаления тренда (множественная регрессия и гауссова фильтрация) и используется взвешенный (по значениям корреляции) метод наименьших квадратов для временных серий каждого пиксела для вычисления смещений.
Для вычислений использованы такие "классические" пакеты как numpy (операции над массивами, линейная алгебра и много всего еще), scipy (научные вычисления, включая ту же линейную алгебру и прочее), pandas (работа с табличными данными), joblib (управление параллельным выполнением вычислительных задач в отдельных процессах и потоках) плюс "широко известные в узких кругах" пакеты Dask и distributed (распределенные параллельные вычисления), dask_image (распределенная параллельная обработка двумерных растров), shapely (пространственный анализ и системы координат) и прочие.
Пакет dask_ml, предлагающий машинное обучение для Dask, оказался совершенно никчемным — это медленная и очень нестабильная обертка для scikit-learn (к примеру, dask_ml крэшится на простейшей линейной регрессии на всего лишь единицах миллионов значение, а на меньшем количестве значений просто "тормозит"), вдобавок, пакет вовсе не совместим с dask (как ни странно, вообще не умеет работать с delayed и lazy данными).
joblib позволяет управлять параллельным выполнением внешних программ плюс обеспечивает корректное высвобождение памяти, так что порой он необходим и для использования Dask distributed операций, которые часто не освобождают занятую память при прерывании операции из-за ошибки или пользователем.
dask_image умеет параллельно вычислять свертки и прочие растровые операции на распределенных растрах, используя блоковую модель данных с перекрытиями. несмотря на все сложности реализации, пакет просто работает, что приятно.
Для работы с форматом блочных бинарных данных NetCDF единственная библиотека, совместимая с Dask distributed и корректно работающая с "ленивыми" (lazy) большими данными, это h5netcdf. Поддерживается разбиение данных на блоки произвольного размера, компрессия многомерных блоков данных и многое другое, единственная сложность — нет возможности сохранить файл с данными, размер которых меньше размера заданного блока. Таким образом, слишком маленькая интерферограмма не может быть сохранена при стандартном размере блока (что можно решить увеличением разрешения), а при малом размере блока не эффективна работа с большими интерферограммами. Выбранный по умолчанию размер блока 512 это компромисс между этими двумя факторами.
Ну и, конечно, Docker — для предоставления доступа к готовым к использованию образам. Docker все еще достаточно "сырой" продукт, как будет показано ниже, зато предоставляемая возможность передачи и хранения на DockerHub сжатых образов плюс их легкий запуск на многих операционных системах с помощью Docker Desktop очень удобны (и доверие пользователей к Docker Hub выше, чем к торрентам). Самым фантастическим багом в Docker, с которым я столкнулся, стали перепутанные потоки вывода — при параллельном запуске шелл скрипта в образе, собранном на arm64 хосте для архитектуры amd64 с помощью QEMU, поток вывода stdout идет в stderr — как Docker вообще работает, при таких-то багах, для меня загадка (для решения указанной проблемы пришлось в коде PyGMTSAR добавить workaround, то есть "костыль"). Также размер контейнера зачастую заметно превышает размер хранимых в нем данных (понятно почему, конечно), так что нужно его выбирать с запасом. Docker решает задачу распространения сложного ПО в удобном для использования виде (обеспечивая доступность), плюс позволяет получить ожидаемый результат (обеспечивая воспроизводимость), поскольку используемые библиотеки и их зависимости часто меняются и далеко не всегда пребывают в работоспособном состоянии (поэтому докер-файлы приходится регулярно обновлять6 заменяя одни "костыли" на другие), и более того, иногда и вовсе можно получить результат, далекий от ожидаемого. При совместном использовании CI-тестов (контролируют работоспособность "сейчас") и Docker образов (содержат "снимки" выбранных состояний) процесс разработки становится предсказуемым, а использования — комфортным.
Приятно было обнаружить, что DockerHub позволяет выкладывать образы размером 50 GB даже на бесплатном тарифном плане. Возможно, это далеко не предел для DockerHub — ведь заявлен и вовсе не ограниченный размер образов, но это предел размера файла на iCloud, где я дублирую все датасеты.
iCloud оказался оптимальным выбором для расшаривания больших файлов — в нем нет платы за трафик, как на Google Cloud Buckets и других сервисах, поддерживаются достаточно большие файлы, а еще штатными средствами можно получить прямую ссылку для скачивания непосредственно из консоли! Благодаря такой возможности я могу скачивать датасеты с iCloud в CI тестах, Google Colab ноутбуках и так далее. Увы, но все остальные клауд провайдеры борются с прямым скачиванием как только могут (когда-то я использовал обходные пути для прямого скачивания с Google Drive, но довольно быстро все они перестали работать).
Ноутбуки на Google Colab
Бесплатные инстансы Google Colab отлично подходят для ознакомления с примерами различных вычислительных задач, предоставляя 12 GB RAM и 2 ядра процессора. Только низкая скорость дисковых операций на Google Colab порой шокирует — при активном использовании диска работа занимает часы вместо минут на Apple Silicon устройствах, так что дисковые операции типа кэширования данных необходимо исключать. Непосредственно вычисления мой старый Intel MacBook Pro 13" выполняет примерно равноценно Google Colab (8 GB RAM vs 12 GB RAM, 2 CPU core hyper-threading vs 2 CPU core) — то Apple Silicon оказывается на порядок быстрее.
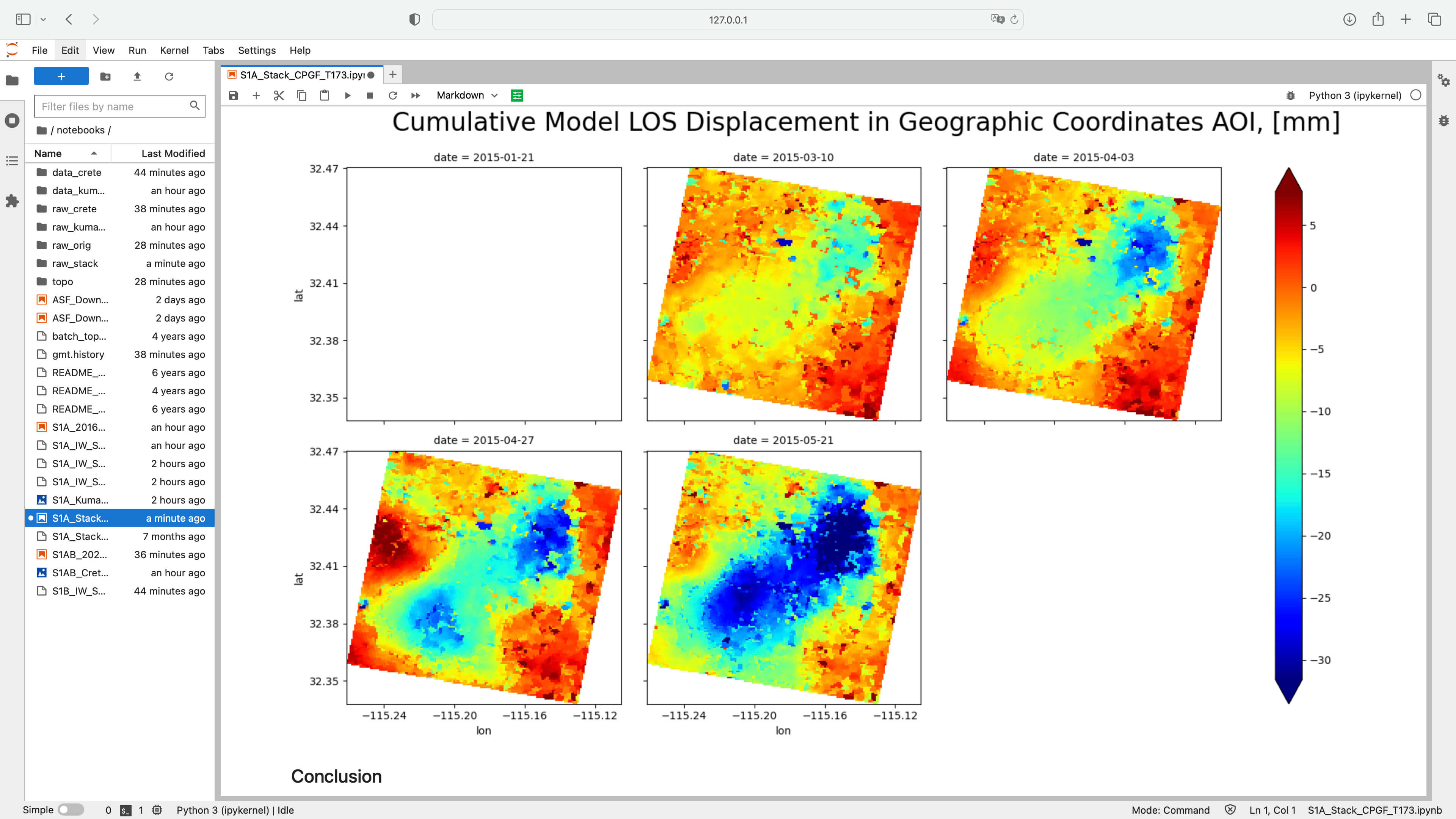
В ноутбуке dataset S1A_Stack_CPGF_T173 обрабатывается серия из 9 интерферограмм и можно проверить работу как только быстрых ядер процессоров Apple Silicon (ограничивая число используемых ядер от 1 до 4х), так и всех ядер вместе, сравнивая с результатами на 2х ядерных хостах Google Colab. Больше примеров доступно на странице проекта PyGMTSAR GitHub.
Докер-образы для всех

При минималистичных требованиях 4 GB RAM 2 CPU cores для запуска контейнера даже мой старый ноутбук 2014 года (8 GB RAM 2 CPU cores hyper-threading) способен легко и быстро выполнить все примеры. Оптимизация кода для обработки больших сцен в высоком разрешении пошла на пользу проекту — типовые вычисления теперь требуют лишь ресурсов среднего смартфона. На Apple Silicon при использовании от одного до четырех потоков выполнения скорость обработки данных в полтора-два раза превосходит возможности мощных рабочих станций и серверов, а при использовании всех ядер возможности примерно уравниваются. Очевидно, это связано с тем, что тестируемые Apple Silicon платформы предлагают набор из 4х быстрых и 4х медленных ядер.
Набор примеров в образах amd64/arm64 размером менее 1.5 GB доступен на DockerHub по ссылке mobigroup/pygmtsar Там же указано, какой размер контейнера необходим для запуска одного, нескольких или всех примеров. Так можно обрабатывать и терабайты исходных данных — при условии стандартного для задач интерферометрии разрешения выходных данных 60 метров на пиксел.
Докер-образы для экспертов

Это пример серьезной задачи, обычно требующей рабочей станции уровня Intel/AMD 512 GB RAM и 32 CPU cores для запуска консольных бинарных утилит (подробнее смотрите обсуждение разработчиков в гитхаб-тикете Feature: Option to divide snaphu unwrapping into tiles #478). Как оказалось, еще большие задачи и даже в интерактивный среде JupyerLab Python можно решать на Apple Silicon устройствах — в обсуждении по ссылке показано, что на Air Apple Silicon можно за аналогичное время обработать вдвое большую задачу, нежели это удалось на указанной рабочей станции. Я использую алгоритмы и код, адаптированные к ресурсам Apple Silicon устройств, и на мощной рабочей станции можно выполнить вычисления многократно быстрее — и все же результат говорит сам за себя, ведь один ноутбук Air фактически заменил две таких рабочих станции.
Пример обработки в максимально доступном разрешении 15 метров набора из 34 интерферограмм для 2 "сшитых" вместе спутниковых сцен и всех 3 файлов в каждой сцене (subswaths) доступен в виде докер-образов amd64/arm64 на 50 GB и в виде отдельного датасета для скачивания, все инструкции доступны на странице DockerHub mobigroup/pygmtsar-large Размер каждого грида в радарных координатах больше 25000 x 25000 пикселов (а после проецирования в географические координаты еще вдвое больше) — таким образом, одна интерферограмма плюс сопутствующая коррелограмма "весят" 3 GB, а все результаты занимают около 100 GB.
CI тесты на GitHub Actions

При минималистичных требованиях PyGMTSAR к памяти не составляет сложностей сделать скрипты и для GitHub Actions Если посмотреть время выполнения тестов, к примеру, на MacOS, то тест GMTSAR занимает около 50 минут, в то время как значительно расширенный вариант этого же теста PyGMTSAR выполняет примерно 20 минут — что более чем соответствует ожидаемому распараллеливанию на 3 ядра (согласно спецификации GitHub Actions для MacOS). На Apple Silicon устройствах время выполнения теста составляет 8.5 минут на iMac и Air, что соответствует 8 vs 3 CPU cores.
Выводы
Приятно осознавать, что время было потрачено не зря — я имею в виду как время на написание интерферометрического пакета PyGMTSAR, так и время на выбор ноутбука Apple Air M2. В самом деле, сейчас я могу решать весьма масштабные задачи спутниковой интерферометрии, используя указанную комбинацию ПО и "железа". В отличие от "прошек" на Intel, Air не шумит по ночам, обрабатывая все эти данные — у него и кулеров-то нет. Управление оперативной памятью на Apple Silicon сделано прекрасно — фактически, можно запускать задачи, требующие больше оперативной памяти, чем ее физически доступно, не замечая использования файла подкачки.
Apple Silicon iMac M1 в топовой конфигурации (с двумя вентилляторами) практически равне по производительности топовому же бескулерному Air M2, а больший объем памяти последнего позволяет комфортнее работать, например, с 16 GB RAM Docker контейнером. На практике, в плане производительности Air M2 вовсе "не страдает" от отсутствия кулеров даже на вычислительно тяжелых задачах. Курьезно, но факт — больше всего ноутбук нагревается от игры Sims 4 жены, явно из-за двойной нагрузки и на процессор и на видео акселератор. При использовании только CPU наличие кулера существенной роли не играет.
Скорость чтения и записи встроенного SSD составляет около 3 GB/s, несколько быстрее на Air M2, нежели на iMac M1 (замерял Blackmagic Disk Speed Test и консольным dd в два потока), как показывают все тесты, этого вполне хватает, чтобы полностью загружать процессор и память для обсуждаемых задач. Жаль, что доступный размер диска ограничен 2 TB — видимо, производитель хочет продавать больше MabBook Pro, в то время как реально для большинства задач целиком и полностью хватит Air.
И пару слов про встроенный Wi-Fi адаптер. Раз уж я занялся загрузкой и скачиванием Docker-образов на 50 GB на DockerHub, то для удобства заказал USB-C адаптер Ethernet и замерил скорость передачи данных по Wi-Fi и через адаптер на Air, расположенном примерно в метре от типового Wi-Fi роутера (предоставлен оператором при подключении "оптики"). Разницы практически нет — скорость передачи и приема в обоих случаях составляет около 500-600 Mb/s. У меня подключен базовый тариф интернет с обещанными "до 500 Mb/s" (максимальный тариф в Чиангмае предлагает 2 Gb/s и не дорого, но я не смог придумать, зачем мне столько), так что большего я и не ждал.
На мой взгляд, сегодня главное ограничение Apple Silicon связано с тем, что часть программ еще не доступны или работают в нативном режиме не очень стабильно. Например, только начиная с Python 3.10 прекратились самопроизвольные крэши Jupyter ноутбуков, Blender работает только в альфа версии и так далее. Если же нужный софт доступен и работает стабильно — то скорость его работы превосходит мои ожидания.
Post Scriptum
Я рассказал об одной, но далеко не единственной задаче обработки больших данных из тех, которые успешно решаю на своих Apple Silicon Air и iMac. Например, для обработки дампа карты OpenStreetMap (его размер уже давно «перевалил» за терабайт) я создал открытый проект OpenStreetMap Public Dataset on Google BigQuery Platform, позволяющий разделить данные OpenStreetMap на тематические слои и загрузить в базу данных с поддержкой пространственных типов данных. Так как этот проект спонсирован компанией Google Inc., то код нацелен именно для использования с Google BigQuery, хотя для других проектов я использую практически этот же код совместно с PostgreSQL/PostGIS. И эта задача выполняется отлично как в однопоточном, так и в многопоточном режимах.
-
Также смотрите
- Мои статьи на Хабре
- Теоретические и практические статьи и посты на LinkedIn
- Геологические модели и код на GitHub
- YouTube канал с геологическими моделями
- Геологические модели в виртуальной/дополненной реальности (VR/AR)
-
Docker образы на DockerHub
Попробуйте сверхбыстрый хостинг в России от AdminVPS
Комментарии (10)

RocketMen
07.12.2022 11:24+2Хоть я и не занимаюсь работой с большими данными а только постигаю науку о данных, мой air m1 меня только радует, аналогичная работа на i5 десятой серии g была куда менее приятной, вечно шумел кулер да и разряжался за 5 часов, макбук же стабильно 8-10 без режима экономии.

N-Cube Автор
07.12.2022 16:47Я первый день решил протестировать Air M2 самым простым способом - работал на нем «до упора» над обычными своими вычислительными задачами, чтобы понять, на сколько его батареи хватит. Так вот, меня хватило меньше, чем батареи ноутбука - а ведь я еще его не раз за день оставлял считать что-нибудь в перерывах от работы. Понятно, можно найти задачи, чтобы и быстрее разрядить - но прошки на интеле при обычной работе за день раза два заряжать приходилось, да еще шумят и греются куда больше.

screwer
07.12.2022 13:26+1Ничего не понял...
Это пример серьезной задачи, обычно требующей рабочей станции уровня Intel/AMD 512 GB RAM и 32 CPU cores для запуска консольных бинарных утилит (подробнее смотрите обсуждение разработчиков в гитхаб-тикете Feature: Option to divide snaphu unwrapping into tiles #478). Как оказалось, еще большие задачи и даже в интерактивный среде JupyerLab Python можно решать на Apple Silicon устройствах — в обсуждении по ссылке показано, что на Air Apple Silicon можно за аналогичное время обработать вдвое большую задачу, нежели это удалось на указанной рабочей станции. Я использую алгоритмы и код, адаптированные к ресурсам Apple Silicon устройств, и на мощной рабочей станции можно выполнить вычисления многократно быстрее — и все же результат говорит сам за себя, ведь один ноутбук Air фактически заменил две таких рабочих станции
Вы утверждаете, что ноутбук Air с 16гб рам и кодом на питоне оказался эквивалентен двум рабочим станциям с 512гб рам и кодом на Си ?
N-Cube Автор
07.12.2022 16:41+3Именно так, притом я это доказал, а не просто утверждаю. Бинарная утилита sbas_parallel из GMTSAR требует терабайт оперативки там, где Python код в PyGMTSAR обходится 16 GB RAM в докер контейнере (и 8 GB без контейнера). Докер образ в статье указан, ссылка на обсуждение разработчиков GMTSAR тоже - все легко проверить.

v1000
И это они ещё «настоящие» серверные решения не выпустили.
YMA
Когда полностью контролируешь экосистему (весь софт и железо) и не надо тащить за собой legacy - возможности расширяются неимоверно.
N-Cube Автор
Когда на Air такие результаты доступны, то что ждать от "домашнего" 20тиядерного Mac Studio M1, а мак про и вовсе впору с многопроцессорный сервером сравнивать для вычислительных задач - когда не нужны терабайт памяти, чтобы полностью нагрузить 40-80 ядер процессора. Я уже присматривался к Studio, но после покупки iMac M1 понял, что Air M2 мне хватит для всех задач, да еще - наконец-то - ноутбук можно легко носить с собой. Новый Air сам легкий, а еще не нужен больше "кирпич" зарядного устройства, достаточно современного зарядка для смартфона (ватт на 65 есть мелкие и легкие, да и без него не проблема - в любом кафе или отеле найдется usb-c зарядник) - так что эти соображения "перевесили".
house2008
Сравнивал MacBook Pro 16" на M1 с 16 Гб оперативной и Mac Studio на M1 с 64 Гб оперативкой, так в целом задачи идут вровень, а вот задачи с I/O на макбуке в несколько раз быстрее чем на студии потому что на ноуте ssd распаян на материнке. Условно распаковка архива 20 Гб (Xcode) на макбуке занимает 5 минут, на студии около 20 минут.
N-Cube Автор
Ничего себе разница… В прошках на M2 обещают раза в полтора большую скорость оперативки, так что будет еще интереснее.