

В последние годы наблюдается огромный прогресс в серии YOLO, в настоящее время в ней используются как модели обнаружения объектов без привязки, так и модели обнаружения объектов на основе привязки. Вместо того, чтобы сосредоточиться исключительно на архитектурных изменениях, YoloR выбирает новый маршрут. Он черпает вдохновение в том, как люди сочетают неявные знания с явными знаниями для решения новых задач. Предлагаемые методы значительно улучшают производительность Обнаружение объектов YoloR модели, в результате которых они будучи на ~ 88% ????быстрее и лучше (???? 57,3% на Набор для тестирования COCO) с минимальными дополнительными затратами.
Что мы узнаем из в этой статьи?
Что такое YoloR? Что нового!!
Интуиция, лежащая в основе YoloR, и как она работает.
Архитектурные изменения и различия между моделями YoloR.
Сравнительный анализ выводов моделей YoloR.
Содержание
Кто авторы YoloR?
Авторами YoloR являются Цзянь-Яо Ван, Я-Хау Йех, и Хун-Юань Марк Ляо. Вместе с Алексеем Бошовским, эти четыре автора были вовлечены в разработку CSPNet, YoloV4 (2020), Масштабированный -YoloV4 (2020), и YoloV7 (2022). YoloV4 это была статья, получившая признание критиков, к которой Масштабирование-YoloV4 внесены дальнейшие улучшения. Масштабирование-YoloV4 был “документом по улучшению архитектуры”. YoloR (2021) основан на Масштабирование-YoloV4 моделирует и имеет собственный подход к дальнейшему улучшению результатов.

Стоит ли изучать YoloR?
Авторы статьи YoloR используют подход “по неизведанным дорогам” для дальнейшего совершенствования серии Yolo. Эмпирические и сравнительные результаты, опубликованные авторами, показывают, что новый подход имеет определенную обоснованность. Кроме того, YoloR-D6 (2021 – 57,3%) работает лучше, чем (лучший) Модель YoloV7-E6E (2022 - 56,8%) в наборе разработчиков COCO для тестирования.
Это не опускает значимость YoloV7. Например, в этом сравнении карты проверки YoloV7 с YoloR и другими моделями вы можете увидеть превосходство YoloV7.
Оба они являются отличными документами, в которых используются различные методы улучшения и которые заслуживают доверия.
Новый YOLOR (масштабируемый на основе YOLOv4) лучше, чем новые ConvNeXT, SWIN, Detr, YOLOX, PP-YOLOv2, YOLOv5, EfficientDet ...https://t.co/YFim1oKXfI https://t.co/NgO9wtRzwY https://t.co/IelcU2Bmnw
SWIN настолько медленный, что для его отображения на графике требуется логарифмическая шкала задержек ... pic.twitter.com/xAgU1gnWiT- Алексей Бочковский (@alexeyab84) 14 января 2022 г.
Как упоминалось выше, в серии YOLO теперь представлены модели без привязки и на основе привязки
???? Знаете ли вы, что первая модель Yolo, выпущенная в 2016 году, также была моделью обнаружения объектов без привязки?
Весь механизм обнаружения без привязки был привлечен к общему вниманию двумя другими моделями. Эта честь принадлежит Обнаружение объектов FCOS модель, которая подходит к проблеме с точки зрения прогнозирования на пиксель, аналогично сегментации. И, CenterNet, который моделирует объект как единую точку.
Наконец, мы приходим к Модель обнаружения объектов без привязки YoloX (2021), выпущенный примерно в то же время, что и YoloR. YoloX был хорош, но не так хорош, как YoloR. YoloX обеспечивает результаты, не уступающие другим современным моделям (SOTA).
⚡ Вы можете быть удивлены, узнав, что текущая архитектура SOTA с точки зрения обнаружения в реальном времени YoloV6, модель обнаружения объектов без привязки.
Что такое YoloR?
Как нам известно, серия Yolo в первую очередь решает проблему обнаружения объектов. Эта статья ничем не отличается в этом аспекте. YoloR означает “вы изучаете только одно представление: объединенную сеть для нескольких задач”. Во второй части названия говорится о чем-то новом и неизученном в других версиях Yolo.
Авторы YoloR стремились создать:
“Единая сеть, которая может генерировать единое представление для одновременного выполнения различных задач”.
Их цель - создать единую модель, способную изучать общие представления. Затем каждая подсеть может использовать эти представления для создания подходящих подпредставлений для решения задачи. Задачей может быть классификация, обнаружение, оценка положения, отслеживание объекта и т. Д.
Истоки YoloR лежат в проблеме, с которой столкнулись во время многозадачного совместного обучения в сети. При обучении одной модели, которая может решать несколько задач, т.Е. Совместной оптимизации, Каждая подсеть стремится тянуть веса в направлении, подходящем для себя. Это часто приводит к плохой генерации общих функций, в результате чего итоговая общая производительность будет хуже, чем при обучении нескольких моделей по отдельности.
Мы углубимся, чтобы понять значение “объединенной сети” в следующих разделах.
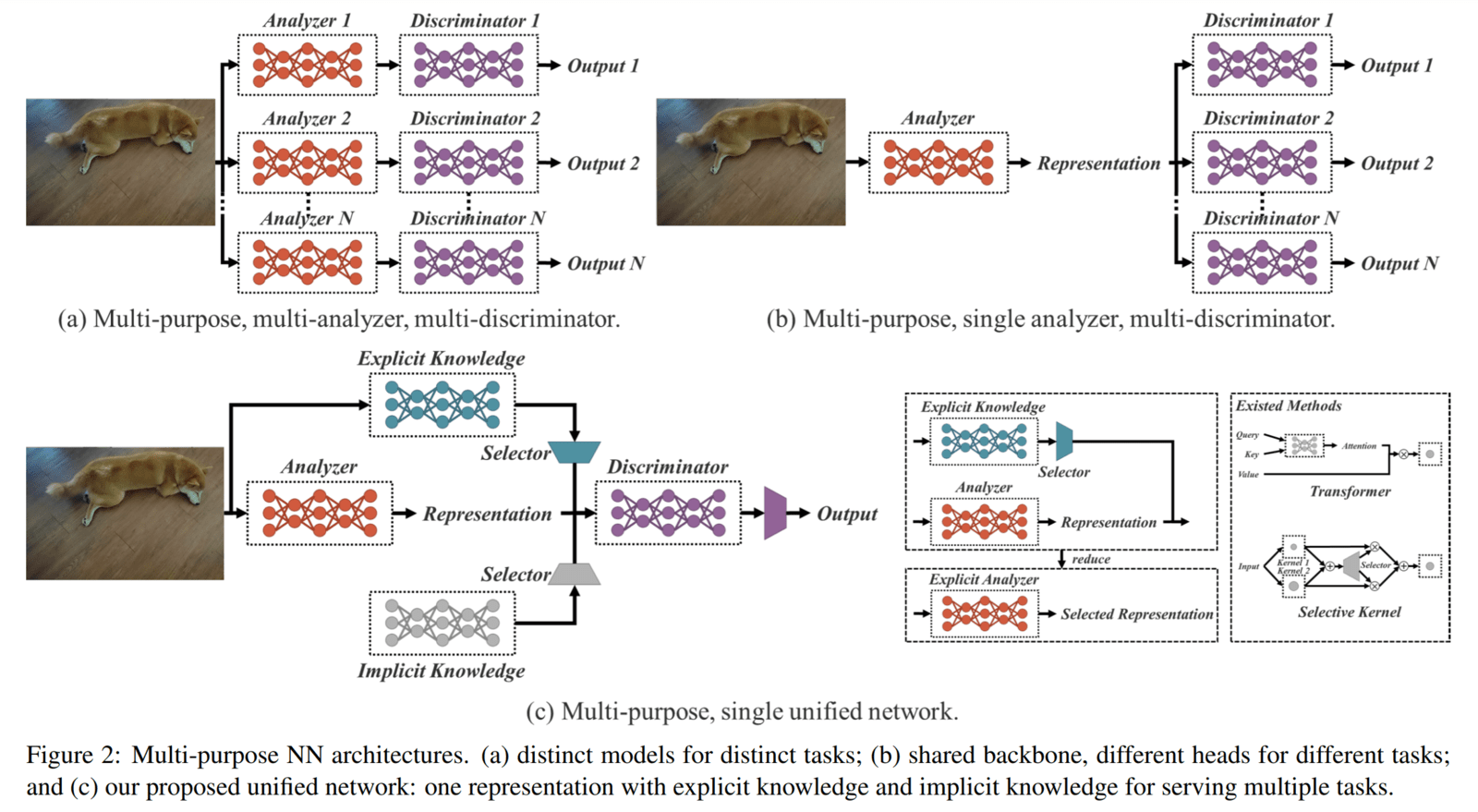
Ссылаясь на изображение выше:
На рисунке 2 (a): у нас есть несколько отдельных сетей для каждой задачи.
На рисунке 2 (b): у нас есть типичная архитектура многозадачной сети.
На рисунке 2 (c): предлагаемая архитектура унифицированной сети (сочетающая явные и неявные знания) , которая генерирует одно унифицированное представление для обслуживания нескольких задач.
Чем отличается YoloR?

Авторы YoloR (успешно) берут на себя новое направление, не исследованное в других статьях серии Yolo, для улучшения моделей.
Люди полагаются на свои физические чувства и прошлый опыт, чтобы понять окружающую их среду. За эти годы мы создали огромную базу данных знаний и опыта, полученных в результате регулярного обучения (явные знания) или подсознательно (неявные знания), хранящихся в нашем мозгу. Эти два типа знаний, явные и неявные, в сочетании эффективно помогают нам жить (функционировать) с легкостью.
Вдохновение для YoloR исходит от того, как люди эффективно комбинируют информацию, полученную из окружающей среды, со своими прошлыми знаниями и опытом для обработки данных, ранее невидимых.
Основное внимание в этой статье уделяется:
“... создать единую сеть, которая может кодировать и комбинировать неявные и явные знания, точно так же, как мозг может учиться на обычном и подсознательном обучении”.
В моделях обнаружения объектов YoloR неявные знания, закодированные сетью, используются для выравнивания в пространстве ядра и уточнения прогнозирования. При дополнении неявными знаниями представления, генерируемые сетями, могут использоваться для решения проблем, с которыми сталкиваются многозадачные сети.
Для обнаружения объектов YoloR использует предопределенные привязки, аналогичные Scaled-YoloV4.
YoloR – единая сеть
В предыдущих разделах использовались новые термины, такие как “объединенная сеть” и “явное и неявное знание”.В этом разделе я объясню эти моменты и что они означают в контексте нейронных сетей.
Что подразумевается под явным и неявным знанием?
С психологической точки зрения теория, лежащая в основе “различных типов знаний”, обширна. Однако, с точки зрения статьи, следующее - это все, что вам нужно знать:
Явные знания: знания, которые легко сформулировать, записать и поделиться с другими, известны как явные знания. Это может быть кодифицировано и оцифровано в книгах, документах, отчетах, записках и т. Д.
Неявные и неявные знания: знания, полученные из опыта, труднее выразить и они глубоко укоренились в мозге. Личная мудрость, проницательность, интуиция и опыт зависят от контекста, и их сложнее извлечь и кодифицировать. Например, навыки, приобретенные на работе, которые можно перенести на другие должности / рабочие места, то есть знания, полученные из опыта. Это относится к знаниям, полученным в подсознательном состоянии.
На самом деле неявное знание отличается от неявного знания, но в документе YoloR они считаются одним целым.
Как люди понимают и изучают новые вещи?
Статья YoloR начинается с того, что задается сложный вопрос, который также является источником вдохновения для статьи.
Люди росли / развивались на протяжении веков, воспринимая окружающую среду и используя проактивные меры, которые предостерегали от каких-либо событий
Опыт и интуиция являются неотъемлемыми частями человеческого знания. Без них может быть трудно “разобраться” или “отреагировать” на новую среду. Мы ежедневно функционируем на высоком уровне с легкостью, используя информацию об окружающей среде от наших органов чувств и знания / опыт / интуицию, хранящиеся в нашем мозге.
Когда мы сталкиваемся с новой ситуацией или проблемой, мы в значительной степени полагаемся на наш прошлый опыт и информацию, полученную из окружающей среды, чтобы понять, интерпретировать и реагировать наилучшим образом. В конечном счете, мы можем сказать, что получили больше знаний (нового опыта), которые теперь являются частью нашей базы данных.

Возьмите приведенное выше изображение в качестве примера. Люди могут с легкостью анализировать его с разных точек зрения. Мы можем легко классифицировать и отвечать на различные вопросы по одним и тем же данным.
Это не совсем верно для нейронных сетей. CNN, обученный классификации “что это?”, будет отлично работать (с некоторой погрешностью) при классификации приведенного выше изображения. Тем не менее, если мы изменим задачу на “где она?”, Модель либо бесполезна, либо нуждается в переподготовке или обучении в условиях многозадачности.
Причина в том, что функции, изученные (для одной задачи) и извлеченные из обученной модели CNN, плохо адаптируются к другим проблемам. И мы используем сеть только для извлечения объектов. Тем не менее, неявные знания, которыми изобилует сеть, игнорируются.
Неявное знание обученной модели можно рассматривать как ее способность понимать и решать, где искать, что, как и какие функции извлекать и комбинировать для создания значимых представлений функций.
Точно так же, как люди применяют наш прошлый опыт для понимания и решения новой проблемы, в этой статье авторы пытаются закодировать неявные знания нейронных сетей, чтобы их можно было использовать для множества новых задач.
Какое отношение все это имеет к нейронным сетям? Как мы их соотносим?
С точки зрения CNN, объекты, извлеченные из мелких слоев, Которые образуют ребра, углы, кривые и т. Д., В Значительной Степени Связаны с вводом. Извлеченные функции часто называют явными знаниями, поскольку они получены непосредственно из входных данных. Напротив, функции, полученные из более глубоких слоев, известны как неявные знания.
Функции, извлеченные с помощью модели, становятся все более и более сложными и их труднее интерпретировать. Информация была глубоко закодирована в многомерном пространстве, которое может понять и использовать только сеть.
“В этой статье мы называем знания, которые непосредственно соответствуют наблюдению, явными знаниями. Что касается знаний, которые подразумеваются в модели и не имеют ничего общего с наблюдением, мы называем это неявным знанием ”.
Чтобы понять это, давайте рассмотрим другой пример. Предположим, вам дана сетевая фигура, и вам нужно найти количество параметров.
Когда вы впервые смотрите на сеть, вы понимаете, что раньше не видели структуры такого типа. Тем не менее, вы распознаете основные компоненты / уровни сети. Сначала вы извлекаете из диаграммы важную информацию, такую как количество узлов на уровне, количество слоев, соединений и т. Д. Затем вы начнете вычислять количество параметров для каждого узла / слоя, потому что вы понимаете шаги, которые необходимо выполнить, и методологию, которую следует использовать для решения проблемы.
Две вещи:
Мы наблюдали и извлекали информацию из проблемы — это явное знание.
Мы использовали наши прошлые знания - неявные знания; объединили его с текущим наблюдением, чтобы решить проблему.

Надеюсь, к этому моменту вы понимаете концепцию явных и неявных знаний, интуицию статьи и то, как она связана с нейронными сетями.
Возникает вопрос: “Но как это выглядит на самом деле?”
Явные знания моделируются (изучаются) нейронной сетью, которая принимает входные данные и выдает выходные данные. Это может быть любая архитектура (YOLOv3, EfficientDet и т. Д.).
Неявные знания - В этой статье авторы представили три метода, которые мы можем использовать для моделирования неявных представлений. Мы рассмотрим это в следующих разделах, где мы рассмотрим все три метода моделирования (не волнуйтесь, это проще, чем кажется) и как объединить их с сетью явных знаний.
Архитектура YoloR
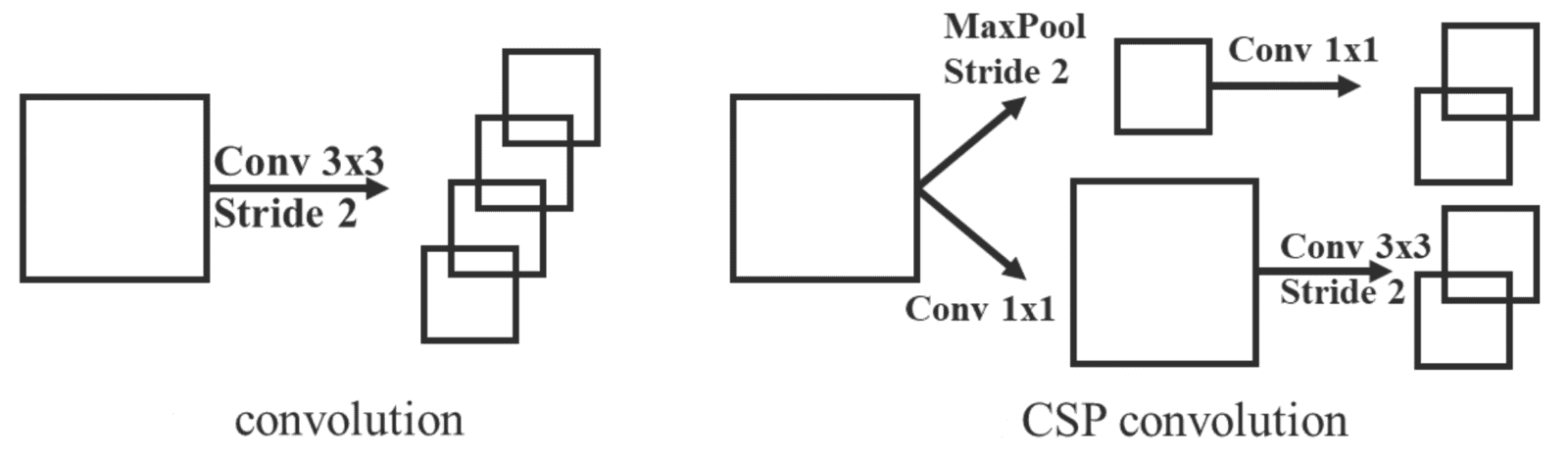
Как упоминалось ранее, модели YoloR построены на масштабируемой архитектуре Yolov4. Авторы берут масштабированный YoloV4-P6 в качестве базовой модели.

Сначала создается облегченная версия: YoloV4-P6-light, путем изменения следующего:
Основа сети для уменьшения размера входных данных и количества параметров.
Значительное сокращение глубины и выходных каналов каждой магистральной ступени. Соответственно, каналы в шейке модели также обновлены.

В моделях YoloR в качестве базовой архитектуры используется модель Yolov4-P6-light. Авторы представили в документе 4 варианта модели: P6, W6. E6 и D6.
YoloR-P6 создается простым изменением функции активации с Mish на SiLU.
YoloR-W6 использует архитектуру YoloR-P6 и изменяет количество каналов, используемых в каждой магистральной ступени и, следовательно, в горловине.
YoloR-E6 создается путем масштабирования каналов YoloR-W6 в 1,25 раза и изменения всех модулей понижающей дискретизации с пошаговой свертки на свертку CSP.
Наконец, YoloR-D6 представляет собой коллективную модель всех вышеуказанных изменений с увеличенной глубиной основных этапов.
Как моделировать неявные знания?
До сих пор мы только и говорили о моделировании сети явных знаний. Далее давайте обсудим методы моделирования неявных знаний.

В документе YoloR представлены три метода, с помощью которых мы можем моделировать неявные знания.
Вектор / матрица / тензор (z): использование вектора z в качестве предшествующего неявного знания и непосредственно в качестве неявного представления.
Нейронная сеть (Wz): используйте вектор z в качестве предшествующего неявного знания, затем используйте весовую матрицу W для выполнения линейной комбинации или нелинейности, которая может использоваться как неявное представление.
Матричная факторизация (Z T c): используйте несколько векторов в качестве априорных неявных знаний, и эти неявные априорные основы Z и коэффициент c будут формировать неявное представление.
Все упомянутые представления используют обучаемые параметры и обновляются вместе с параметрами модели во время обратного распространения.
Как сочетаются явные и неявные знания?
Авторы используют три типа операторов для объединения явных и неявных знаний: сложение, умножение и конкатенация.
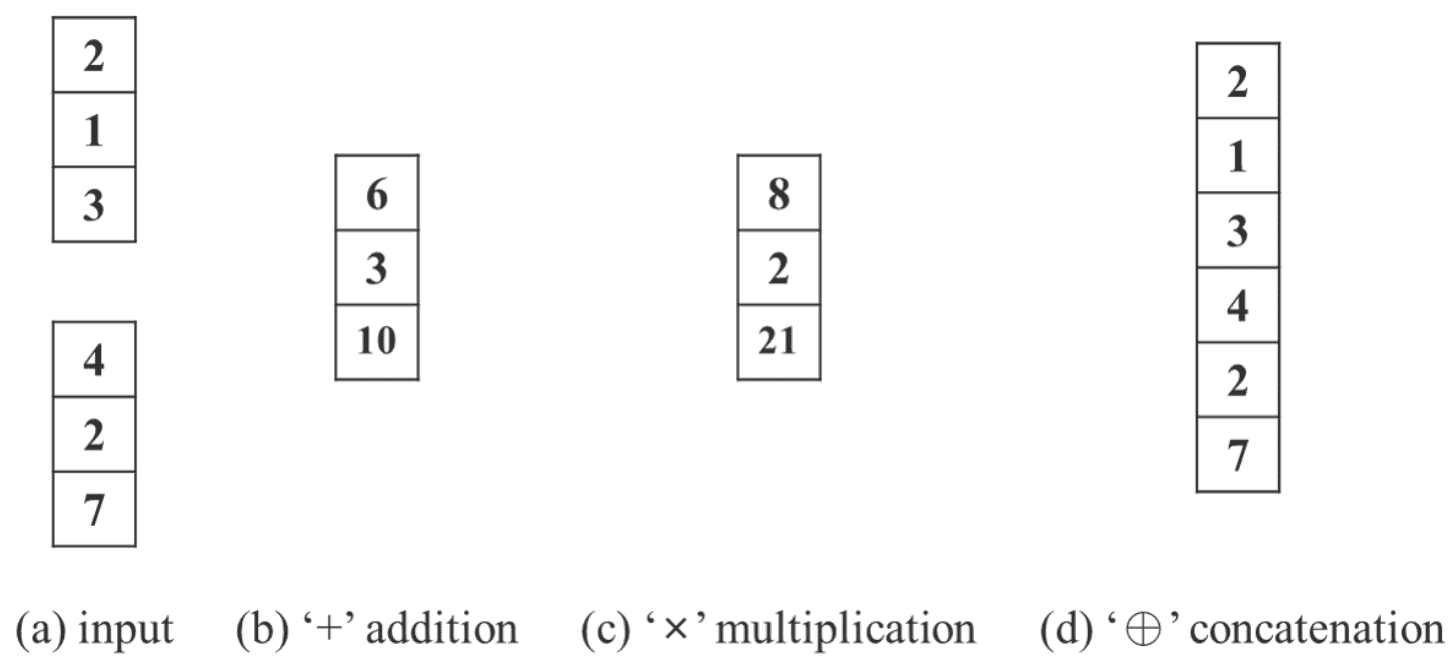
В частности, в YoloR:
Неявные знания моделируются с использованием векторно-матричного представления.
Для объединения с явным знанием используются операторы сложения и умножения.
Полная архитектура YoloR-P6
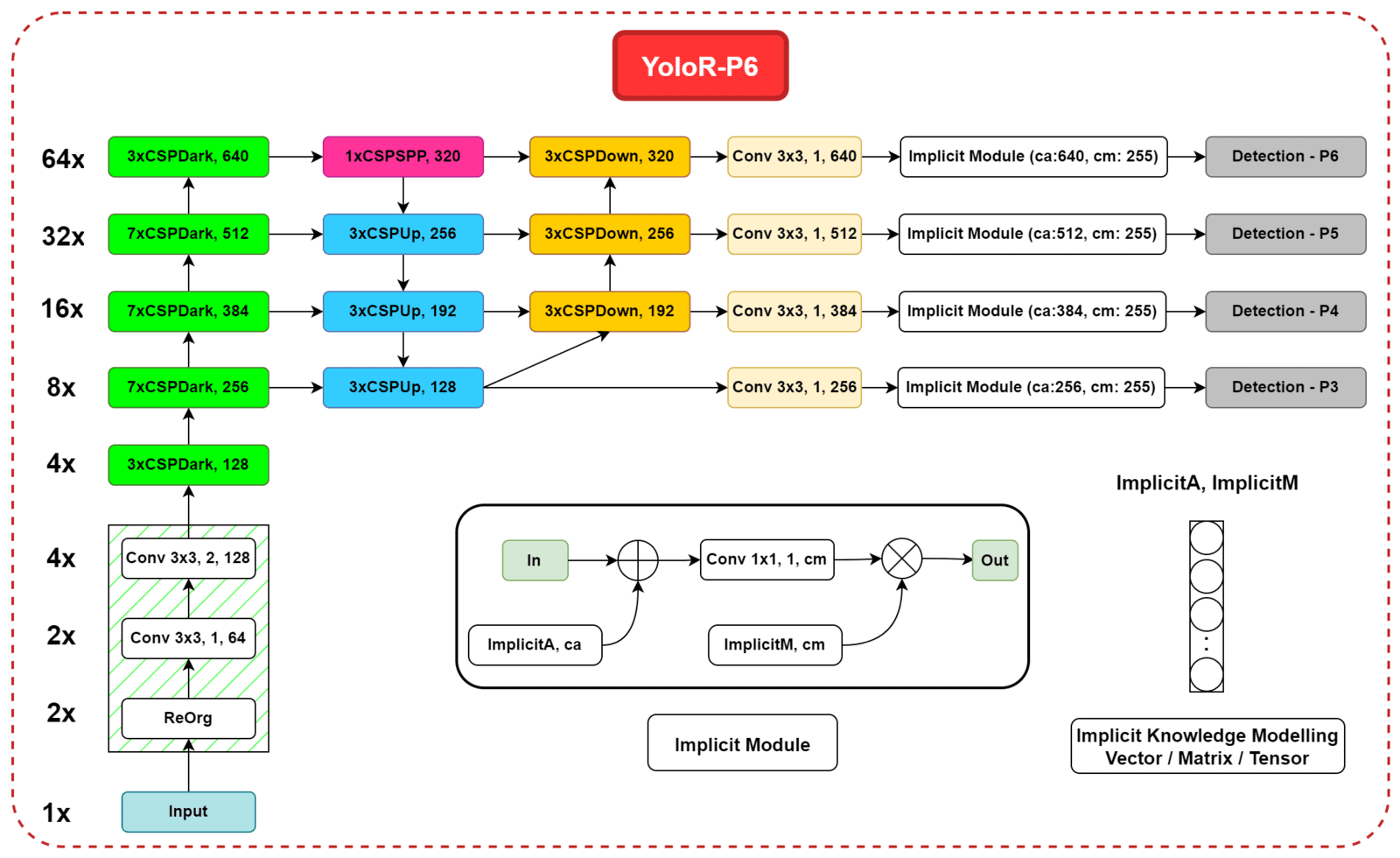
В моделях YoloR неявные знания были смоделированы с использованием обучаемых векторных представлений.
Используются два неявных представления:
Первое - помочь с проблемой смещения пространства ядра. Он сочетается с явным знанием с использованием оператора сложения: ImplicitA.
Второй предназначен для уточнения прогноза, объединенный с использованием оператора умножения: ImplicitM.
Примечание: ConvСлой перед CSPDownблоками также присутствует в масштабированных YoloV4-P6 и YoloV4-P6-light. Он был добавлен на эту диаграмму, чтобы продемонстрировать ввод и размещение двух неявных представлений
Код для инициализации представления тензора неявных знаний (paper branch)

Сочетание с явным знанием

Как неявные знания полезны в сети?
Как вы, возможно, уже догадались, важнейшая часть этого исследования заключается в том, как мы можем эффективно создавать неявную базу знаний в нейронных сетях. В этом разделе мы рассмотрим некоторые сценарии, упомянутые авторами в статье, чтобы понять, как неявные знания могут быть применены к различным задачам.
Допустим, у нас есть представление неявных знаний для “k” задачи как набор постоянных тензоров.
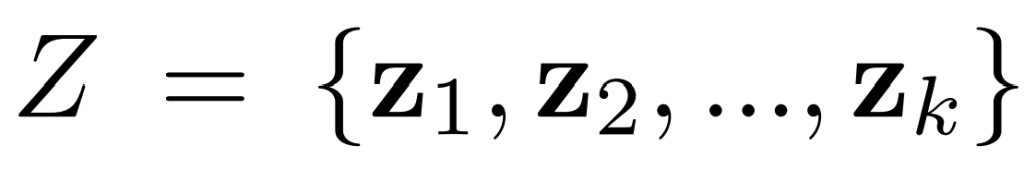
Использование для уменьшения пространства коллектора

Возьмем приведенное выше изображение в качестве эталона. Давайте предположим, что волновая плоскость синего цвета находится в трехмерном пространстве, и мы спроецировали точки (квадраты, ромбы, треугольники) на 2d (это хорошее представление). Допустим, что z1и z2из нашего неявного набора представлений предназначены для классификации и постановки задач оценки с помощью векторов (0, 1)и(1, 0), соответственно.
Учитывая задачу классификации и точки в 2D-пространстве, ясно, что если бы мы могли каким-то образом спроецировать точки на ось y, мы могли бы легко классифицировать их все. В приведенном выше примере мы можем взять внутреннее произведение вектора проекции (от 3D до 2D) и неявного представленияz1, чтобы уменьшить размерность пространства многообразий и эффективно решить задачу.
Использование в выравнивании пространства ядра
В многозадачных и многоголовочных нейронных сетях рассогласование пространства ядра является распространенной проблемой.

Это можно легко понять, взяв пример сетей пирамид объектов. В FPN прогнозы делаются на разных уровнях. Функции с более высокого и более низкого уровней объединяются таким образом, что усовершенствованные семантически сильные функции могут быть объединены с грубыми и семантически слабыми функциями с помощью нисходящего пути и боковых соединений.
")
Объекты одного и того же класса могут присутствовать в разных масштабах. Из-за непрерывного смешивания и извлечения объектов представление подпространства похожих объектов на разных уровнях может больше не отображаться в похожие местоположения в пространстве ядра. В качестве примера возьмем рисунок (а) Без выравнивания похожие объекты больше не проецируются в одно и то же пространство. Это может быть проблематично.
Чтобы справиться с этой проблемой, мы можем выполнять сложение и умножение выходных объектов и неявное представление. Это позволяет переводить, поворачивать и масштабировать пространство ядра для выравнивания каждого выходного пространства ядра нейронных сетей. Это позволяет выровнять представление в подпространстве похожих объектов с разных уровней (рисунок (b) с выравниванием). Вот как мы можем использовать (постоянные) неявные представления (векторы), чтобы помочь с рассогласованием пространства ядра.
Авторы упоминают, что этот метод может быть полезен при обработке знаний для интеграции больших и малых моделей и обработки переноса домена с нулевым выстрелом.

Формулировка неявных знаний в унифицированных сетях
В этом разделе мы обсудим, как неявные знания могут быть сформулированы в нейронных сетях. Целевая функция любого обычного сетевого обучения может быть представлена следующим образом:

Где символы представляют:
x: Наблюдение
theta θ: параметры нейронной сети
:θ f работа нейронной сети
epsilon ε:термин ошибки
y: цель заданной задачи
Во время обучения цель состоит в том, чтобы свести к минимуму ошибки, чтобы сделать вывод нейронной сети как можно ближе к цели. Это просто более простой способ сказать, что мы хотим, чтобы наблюдения, принадлежащие одной и той же цели, были сопоставлены (предпочтительно) с одним и тем же местоположением в подпространстве решений. Но при этом мы создаем сеть, которая хороша для моделирования пространства решений, дискриминирующего только для одной задачи ti и инвариантного к другим потенциальным задачам T = {t1, t1, ...., tn}.
Авторы утверждают, что это проблематично, потому что для создания нейронной сети общего назначения нам необходимо получить представления, которые могут обслуживать все задачи, относящиеся к T.

Для этого нам нужно (б) ослабить порог ошибки ε, чтобы каждая задача могла найти требуемую информацию.
Но ослабление порога ошибки может создать математические проблемы. Мы не смогли бы использовать простые операции, такие как argmax.
Вместо этого мы можем смоделировать порог ошибки ε (c), чтобы найти решения для различных задач. Это означает, что мы хотим, чтобы наша сеть генерировала более общие представления подпространства (в основном, узнайте, как ослабить термин ошибки).
Выдержка из статьи:
“Для обучения предлагаемых унифицированных сетей мы используем явные и неявные знания вместе, чтобы смоделировать термин ошибки, а затем использовать его для руководства процессом обучения многоцелевой сети”.
Соответствующее уравнение для обучения выглядит следующим образом:

Где,
: im и ε ex ε Операции, которые моделируют явные и неявные ошибки из наблюдения x и скрытого кода z.
g: специфичная для конкретной задачи операция, которая объединяет или выбирает информацию из явных и неявных знаний.
Формулировка может быть упрощена до:

Оператор star * указывает на возможные способы объединения f и g.
Как это работает на этапе обучения и вывода?
На этапе обучения авторы предполагают, что модель не имеет предварительных неявных знаний и не влияет на явные представления f θ(x). Исходное значение берется из нормального распределения с параметрами (µ, σ). При объединении с использованием оператора умножения мы используем µ = 1, а для двух других - µ = 0. Дисперсия поддерживается очень близкой к нулю (0,02). z - обучаемый тензор, обученный с использованием алгоритма обратного распространения.
Во время вывода, поскольку неявное знание не имеет отношения к наблюдению x, независимо от того, насколько сложна неявная модель g, ее можно свести к набору постоянных тензоров до выполнения фазы вывода. Другими словами, формирование неявной информации практически не влияет на вычислительную сложность алгоритма.
Эксперименты на бумаге
Авторы решили применить неявные знания к трем аспектам:
Выравнивание функций для FPN
Уточнение прогноза
-
Многозадачное обучение
Обнаружение объектов
Классификация изображений с несколькими метками
Встраивание функций.
В документе используется YoloV4-CSP в качестве базовой модели. Все гиперпараметры обучения сравниваются с настройкой по умолчанию Scaled-YoloV4.

Авторы представили различные исследования абляции, в которых они эмпирически доказывают, что использование неявных знаний в сочетании с сетью явных знаний помогает улучшить результаты. Вы можете просмотреть их в документе. Выделялись следующие:
-
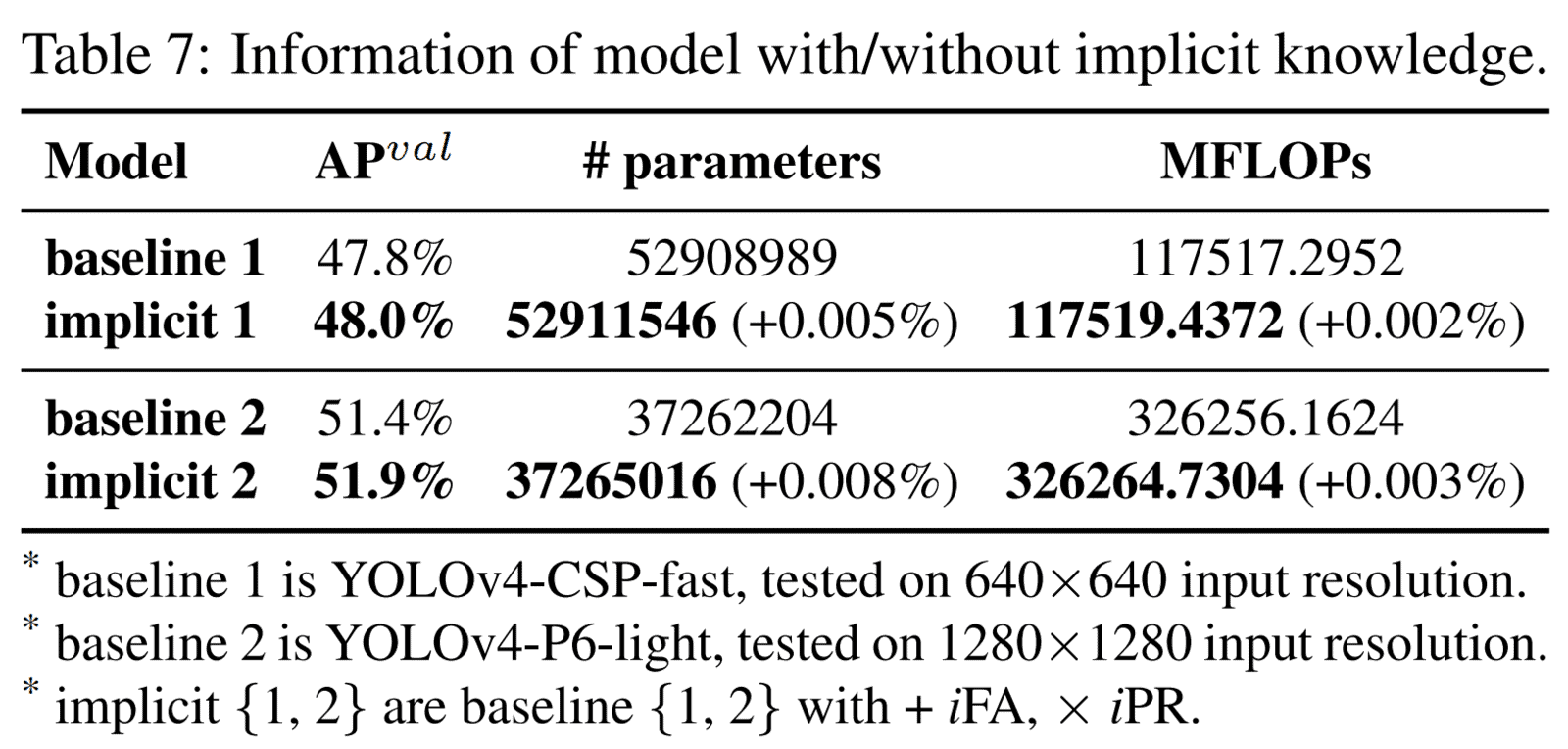
Анализ неявных моделей: сообщается, что количество параметров и вычислений увеличилось менее чем на одну десятитысячную в модели с неявным знанием. Это может значительно улучшить производительность модели, а процесс обучения может быть быстрым и правильным.
-
Результаты многозадачности: Как подчеркивалось в предыдущих разделах, многозадачное обучение является сложным и часто может приводить к ухудшению результатов. В документе YoloR авторы представили результаты для двух сценариев многозадачного обучения: совместное обнаружение и классификация (JDC) и совместное обнаружение и внедрение (JDE).

Возьмём результаты для JDC в качестве примера; при обучении в условиях многозадачности цифры указывают на значительное снижение производительности. Напротив, общий показатель индекса значительно увеличился, когда сила представления была увеличена путем введения неявного представления в каждую ветвь задачи. Производительность метрик, таких как AP val, AP 50 val и AP S val, превосходит производительность однозадачной обучающей модели.
В заключительном эксперименте сообщалось об обучении и точной настройке модели обнаружения объектов с использованием неявных знаний для выравнивания объектов и уточнения прогнозирования. Результаты взяты из “бумажной” ветки репозитория GitHub. (Лучший) новый набор чисел упоминается в основной ветке, но их веса недоступны.

Примечание: Предоставляются четыре другие модели.
-
В основной ветке:
YoloR-CSP
YoloR-CSP-X
-
В бумажной ветке (небольшие модели ~ 18 МБ):
YoloR-S4S2D
YoloR-S 4 DWT
В разделе ссылок приведу дополнительные сведения, предоставленные автором.
Вывод об обнаружении объектов YoloR
Теперь давайте перейдем к самой интересной части этой статьи: выполнению выводов на видео с использованием YoloR. Наряду с этим мы также сравним результаты между моделями YoloR и YoloV7.

Настройка кода YoloR PyTorch
В загрузках мы предоставили готовый к использованию блокнот Colab, который вы можете использовать для выполнения собственных тестов вывода. Мы также предоставили записную книжку jupyter, содержащую все инструкции и шаги, необходимые для локального запуска моделей Yolor.
Клонируйте “бумажную” ветку репозитория YoloR.
git clone -b paper https://github.com/WongKinYiu/yolor.git
-
По умолчанию для кода требуется PyTorch <=1.7.1, но мы можем запустить его с последними версиями с некоторыми незначительными изменениями. Источником ошибки являются аргументы, переданные модулю Upsample.
В detect.py , в строке 30 измените логическое значение с
half= True наhalf = FalseНайдите
attempt_load(...)нужную функцию вmodels/experimental.pyскрипте. Добавьте следующий код после строки 140 (внутри цикла for).
if instance(m, nn.Upsample):
m.recompute_scale_factor = NoneЭто все изменения, необходимые для запуска YoloR с последней версией PyTorch.
Загрузите следующие веса, предоставленные в выпусках GitHub, внутри (создайте новый) папки “веса” в клонированном репозитории.
yolor-p6-paper-541.pt
yolor-w6-paper-555.pt
yolor-e6-paper-564.pt
yolor-d6-paper-573.pt
Из файла README (ветка paper) загрузите файлы весов weights для YoloR-S 4 DWT и YoloR-S 4 S2D по предоставленным ссылкам на диск.
Для запуска модели YoloR-S 4 DWT требуется дополнительная установка. Откройте терминал в клонированном репозитории и выполните следующие команды:
git clone https://github.com/fbcotter/pytorch_wavelets
cd pytorch_wavelets
pip install -r requirements.txt
pip install .
cd ..Чтобы запустить вывод, используйте следующую команду:
python detect.py --weights {weight_file_path} --source {source_video_path} --img-size {640|1280} --device {0 | cpu} --project {save root folder path} --name {save folder name} --exist-ok Аргументы командной строки следующие
–source: путь к видеофайлу. Это также может быть изображение или путь к каталогу, содержащему несколько изображений и видео.
–weights: Путь к файлу весов.
-img–size: размер кадра, на котором выполняется вывод (зависит от модели).
–device: вычислительное устройство. Мы можем указать процессор или одну цифру от 0 до 3, указывающую, какой графический процессор использовать.
–project: корневая папка сохранения
–name: имя выходного каталога
Вот и все.
Сравнение моделей YoloR
В этом разделе сначала мы сравним скорость вывода между двумя легковесными моделями на процессоре и графическом процессоре.
Показатели проверки для двух моделей следующие:

Две модели очень похожи друг на друга. За исключением различий в первых 3 основных уровнях, остальная архитектура остается такой же.

Где,
DWT – дискретное вейвлет-преобразование
S2D - Пространственный в глубину (реорганизация)

Выполнить команду:
python detect.py --weights weights\{yolor-ssss-dwt.pt | yolor-ssss-s2d.pt} --source videos\video_1.mp4 --img-size 640 --device {0 | cpu} --project inference_tests --name small_models --exist-okИз таблицы показателей мы можем видеть, что обе модели имеют очень сопоставимые показатели, а скорость вывода на GPU одинакова, но на ???? CPU скорость вывода DWT в 2 раза выше, чем у модели S2D.
Далее давайте запустим вывод для всех 4 основных вариантов YoloR.
Из видео легко заметить, что все большие модели (подготовленные для размера 1280) лучше, чем меньшие версии (как и должно быть). В более крупных версиях модели могут правильно распознавать автомобиль с правой стороны поперек стойки как один, а также обнаружение пропущенной собаки или обнаружение собаки как сумки (с самого начала).
Еще одно сравнение между самой маленькой и самой большой моделью
Мы ясно видим превосходство самой большой модели над облегченным вариантом.
YoloR vs YoloV7 - Сравнение качества вывода и обнаружения
Как упоминалось ранее, команда, стоящая за YoloR и YoloV7, одна и та же. Таким образом, мы можем ожидать, что YoloV7 будет, по крайней мере, на одном уровне, если не лучше, чем YoloR.
Первое сравнение между YoloR-S4-Dwt и YoloV7-tiny на GPU.
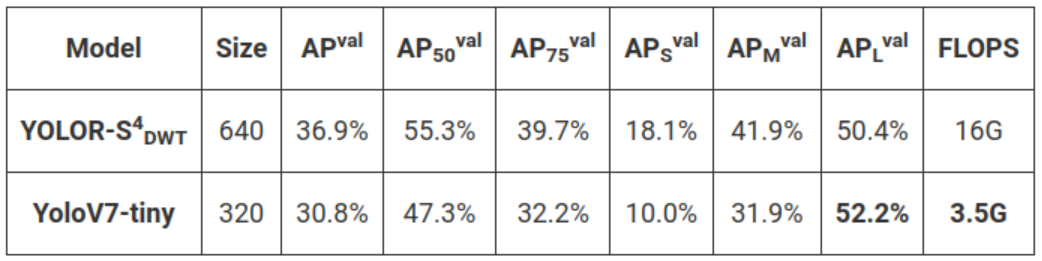
Размер кадра: 640 для обеих моделей
YoloV7-tiny намного меньше, чем YoloR-S4-DWT. Модель YoloV7-tiny распознает аляскинского маламута (собаку) как корову. Но скорость вывода крошечной модели в ~ 2,4 раза больше, чем у YoloR-S4-DWT.
Далее у нас есть результаты вывода больших моделей.

Сначала мы сравниваем YoloR-E6 с вариантом YoloR-E6 для видео YoloV7-E6, который больше, чем V7-E6.
Помимо незначительных различий в пороге классификации, результаты обнаружения обеих моделей очень близки друг к другу. Но с точки зрения скорости вывода YoloV7-E6 является явным победителем.
Затем мы сравнили результаты лучших моделей: YoloR-D6 и YoloV7-E6E
Это интересно, потому что обе модели действительно близки друг к другу с точки зрения того, что они являются SOTA в категории обнаружения объектов в реальном времени. Их точность обнаружения людей, легковых автомобилей, грузовиков и автобусов близка. Но они оба допустили одну и ту же ошибку, приняв бензонасос за грузовик. Я полагаю, что это ограничение связано с набором данных, используемым для обучения. Масштаб и ориентация объектов, снятых с высоты, отличаются от тех, которые видны с приблизительно выровненной поверхности.
Мы получаем аналогичные результаты на другой видеозаписи с беспилотника, где припаркованные автомобили распознаются как сотовые телефоны.
Из приведенных выше результатов мы можем частично заключить, что YoloR и YoloV7 находятся в прямой конкуренции друг с другом. Хотя YoloV7 может показаться лучшим вариантом для последующего изучения, вклад YoloR не следует воспринимать легкомысленно.
После разработки YoloR авторы создали YoloV7, что объясняет, почему YoloV7 имеет лучшую скорость вывода и (те же или лучшие) результаты, чем модели YoloR.
В настоящее время YoloV5, YoloV6 и YoloV7 конкурируют друг с другом за лучшую модель обнаружения объектов в реальном времени.
???? Заинтригован этим? Мы тоже были. Мы также провели сравнительный анализ YoloV5, YoloV6 и YoloV7, чтобы помочь вам лучше понять разницу между новыми моделями и выбрать лучшую для вашего проекта.
Краткие сведения
YoloR - 9-я модель обнаружения объектов в серии Yolo. Авторы использовали подход Yolo и во многих отношениях улучшили алгоритм обнаружения объектов.
В этой статье???? мы рассмотрели полный список тем, связанных с YoloR. Подводя итог.
Мы начали с создания YoloR place во всей серии Yolo.
Углубленное изучение фундаментального различия между YoloR и другими моделями серии Yolo.
Глубоко погрузитесь в базовую интуицию YoloR, используя несколько примеров для лучшего понимания.
Поисковый путь к пониманию ключевых архитектурных изменений в YoloR и того, как новые дополнения вписываются в архитектуру.
Исследовал полезность неявных знаний в нейронных сетях.
Наконец, мы изучили ключевые результаты, опубликованные в статье, и сравнили YoloR с моделями друг с другом и YoloV7.
Список литературы
GitHub – YoloR
Проблемы с GitHub – Как мне использовать модель YoloR-SSSS-DWT?
Проблемы с GitHub – Чем отличаются ImplicitA и ImplicitC в layers.py

flass
Эту статью, судя по всему, писала нейросеть. Учитывая, что это перевод, вероятность равна 1.
dimanosov007 Автор
Похоже на то, они тут пользуются специфичной терминологией, бумагой называют статью по YOLOR в arxiv. Да и сравнивают в основном только документацию и объясняют поход который реализовали авторы YOLOR. Вскоре у них должна выйти статья по обучению на своем dataset YOLOR.