

По данным CDC (Центры по контролю и профилактике заболеваний США), “по оценкам, 1 из 25 взрослых водителей (18 лет и старше) сообщают о засыпании во время вождения ...”. В статье сообщается: “... сонное вождение стало причиной 91 000 дорожно-транспортных происшествий ...”.Чтобы помочь в решении таких проблем, в этом посте мы создадим систему обнаружения сонливости водителя и оповещения, используя API-интерфейс Mediapipe для решения Face Mesh на Python. Эти системы оценивают бдительность водителя и при необходимости предупреждают водителя.
Обнаружение сонливости водителя с помощью MediaPipe в Python [TL; DR]
Непрерывное вождение может быть утомительным и изматывающим. Автомобилист может поникнуть и, возможно, задремать из-за бездействия. В этой статье мы создадим систему обнаружения сонливости водителя для решения такой проблемы. Для этого мы будем использовать решение Face Mesh от Mediapipe на python и соотношение сторон глаз. Наша цель - создать надежное и простое в использовании приложение, которое обнаруживает и предупреждает пользователей, если их глаза закрыты в течение длительного времени.
В этом посте мы:
Узнаем, как определять ориентиры для глаз с помощью конвейера решения Mediapipe Face Mesh на python.
Представим и продемонстрируем технику соотношения сторон глаза (EAR).
Создадим веб-приложение для обнаружения сонливости водителя с помощью streamlit.
Используем streamlit-webrtc, чтобы помочь передавать видео / аудио потоки в реальном времени по сети.
Развернем его в облачной службе.
Содержание
-
Обнаружение ориентиров с помощью сетки граней MediaPipe в Python
Пошаговое руководство по коду обнаружения сонливости водителя на Python
Что такое сонное вождение?

Непрерывное вождение может быть утомительным и изматывающим. CDC определяет вождение в состоянии сонливости как опасное сочетание вождения и сонливости или усталости. Из-за отсутствия активного движения тела у водителя могут начать слипаться глаза, он может чувствовать сонливость и в конечном итоге заснуть за рулем.
Наша цель - создать надежное приложение для обнаружения сонных водителей, которое обнаруживает и предупреждает пользователей, если их глаза закрыты в течение длительного времени.
Наш подход к системе обнаружения сонливости водителя
Как работает система обнаружения сонливости водителя?
Имея в виду приведенный выше пример, для создания такой системы нам нужно:
Доступ к камере.
Алгоритм для определения лицевых ориентиров.
Алгоритм для определения того, что представляет собой “закрытые веки. ”
Решение:
Для пункта 1: Мы можем использовать любую камеру, способную к потоковой передаче. В демонстрационных целях мы будем использовать веб-камеру.
Для пункта 2: Мы будем использовать предварительно построенный конвейер решения Mediapipe Face Mesh на python.
Для пункта 3: Мы будем использовать простой, но надежный Соотношение сторон глаз (EAR) метод, представленный в Обнаружение моргания глаз в реальном времени с использованием лицевых ориентиров.
(Мы подробно обсудим пункты 2 и 3 позже в этом посте.)
В приведенной выше статье авторы описали свой подход к Обнаружение мигания. Моргание глаз - это быстрое действие закрытия и повторного открытия. Для этого авторы используют классификатор SVM для обнаружения моргания глаз как шаблона значений EAR в коротком временном окне.
Как мы можем обнаружить сонливость?
Мы не стремимся обнаруживать “мигания”, а скорее закрыты глаза или нет. Для этого нам даже не нужно будет выполнять какое-либо обучение. Мы воспользуемся простым наблюдением, “Наши глаза закрываются, когда мы чувствуем сонливость”.
Чтобы создать систему обнаружения сонливости водителя, нам нужно только определить, остаются ли глаза закрытыми в течение непрерывного интервала времени.
Чтобы определить, закрыты глаза или нет, мы можем использовать Соотношение сторон глаз (EAR) формула:
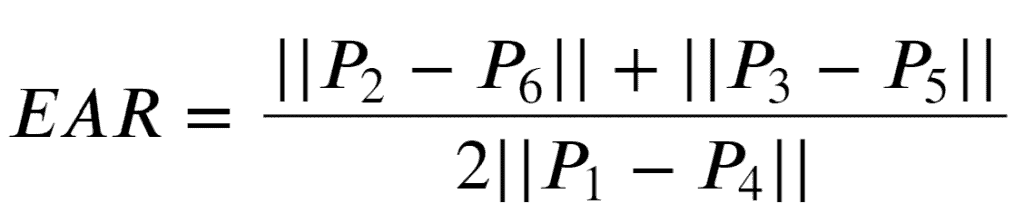
Формула EAR возвращает единственную скалярную величину, которая отражает уровень открытия глаз.

Наш алгоритм для системы обнаружения сонливости водителя выглядит следующим образом:
“Мы будем отслеживать значение EAR в нескольких последовательных кадрах. Если глаза были закрыты дольше, чем заданная продолжительность, мы включим сигнал тревоги ”.

-
Сначала мы объявляем два пороговых значения и счетчик.
EAR_thresh: Пороговое значение для проверки, находится ли текущее значение EAR в пределах диапазона.D_TIME: Переменная счетчика для отслеживания количества времени, прошедшего с текущимEAR < EAR_THRESH.WAIT_TIME: Чтобы определить, прошло ли время с
EAR < EAR_THRESHпревышает допустимый предел.
При запуске приложения мы записываем текущее время (в секундах) в переменную
t1и считайте входящий кадр.Далее мы предварительно обрабатываем и передаем
frameв решение Mediapipe Face Mesh на python.Мы извлекаем соответствующие (Pi) ориентиры для глаз, если какие-либо ориентиры доступны. В противном случае выполните сброс
t1иD_TIME (D_TIMEтакже сбрасывается здесь, чтобы сделать алгоритм согласованным).Если обнаружения доступны, вычислите среднее EAR значение для обоих глаз с использованием извлеченных ориентиров для глаз.
Если текущая
EAR < EAR_THRESH, добавьте разницу между текущим временемt2иt1ДляD_TIME. Затем сбросьтеt1для следующего кадра какt2.Если в
D_TIME >= WAIT_TIME, мы поднимите тревогу или переходите к следующему кадру.
Обнаружение ориентиров с помощью сетки граней MediaPipe в Python
Чтобы узнать больше о Mediapipe, ознакомьтесь с нашим вводный урок по Mediapipe, где мы подробно рассмотрим различные компоненты Mediapipe.
Mediapipe описывает Конвейер лицевой сетки как:
“Наш конвейер ML состоит из двух моделей глубокой нейронной сети в реальном времени, которые работают вместе: детектор, который работает с полным изображением и вычисляет местоположение лица, и 3D-модель ориентира лица, которая работает с этими местоположениями и прогнозирует приблизительную 3D-поверхность с помощью регрессии. Точная обрезка лица значительно снижает потребность в обычных дополнениях к данным, таких как аффинные преобразования, состоящие из поворотов, перевода и изменения масштаба. Вместо этого это позволяет сети использовать большую часть своих возможностей для координации точности прогнозирования. Кроме того, в нашем конвейере посевы также могут быть сгенерированы на основе ориентиров лица, идентифицированных в предыдущем кадре, и только когда модель ориентира больше не может идентифицировать присутствие лица, вызывается детектор лица для перемещения лица ”.

Красный прямоугольник указывает на обрезанную область в качестве входных данных для модели ориентира, красные точки представляют 468 ориентиров в 3D, а зеленые линии, соединяющие ориентиры, иллюстрируют контуры вокруг глаз, бровей, губ и всего лица.
Mediapipe - отличный инструмент, который упрощает создание приложений. Вас также может заинтересовать другое наше сообщение в блоге, где мы используем решение Face Mesh для создания фильтров Snapchat и Instagram с помощью Mediapipe.
Как указано выше, конвейер решения для сетки лиц возвращает 468 точек ориентира на лице.
На рисунке ниже показано расположение каждой из точек.

Источник: canonical_face_model_uv_visualization
Примечание: Изображения, снятые камерой, переворачиваются по вертикали. Итак, ориентиры (на изображении выше) в глазу (области) слева от вас предназначены для правого глаза и наоборот.
Поскольку мы фокусируемся на обнаружении сонливости водителя, из 468 точек нам нужны только точки ориентиров, относящиеся к областям глаз. Области глаз имеют 32 точки ориентира (по 16 точек в каждой). Для вычисления EAR нам требуется всего 12 точек (по 6 для каждого глаза).
Используя приведенное выше изображение в качестве эталона, выбраны следующие 12 ориентиров:
Для левого глаза:
[362, 385, 387, 263, 373, 380]Для правого глаза:
[33, 160, 158, 133, 153, 144]
Выбранные ориентиры расположены в порядке: P 1, P 2, P 3, P 4, P 5, P 6
Обратите внимание, что указанные выше точки не являются координатами. Они обозначают позицию индекса в выходном списке, возвращаемом решением face mesh. Чтобы получить координаты x, y (и z), мы должны выполнить индексацию в возвращенном списке.
Как упоминалось в описании конвейера, модель сначала использует распознавание лиц вместе с моделью распознавания лицевых ориентиров. Для распознавания лиц конвейер использует модель BlazeFace, которая имеет очень высокую скорость вывода.
Распознавание лиц - очень горячая тема в области компьютерного зрения. Чтобы помочь нашим читателям легко ориентироваться в пространстве, мы создали очень подробное руководство по распознаванию лиц, в котором сравниваются гиганты в этом пространстве.
Демонстрация конвейера с лицевой сеткой
Давайте посмотрим, как мы можем выполнить простой вывод с использованием сетки лиц и нанести на график точки ориентира лица.
import cv2
import numpy as np
import matplotlib.pyplot as plt
import mediapipe as mp
mp_facemesh = mp.solutions.face_mesh
mp_drawing = mp.solutions.drawing_utils
denormalize_coordinates = mp_drawing._normalized_to_pixel_coordinates
%matplotlib inlineПолучаем ориентиры (указательные) точки для обоих глаз.
# Landmark points corresponding to left eye
all_left_eye_idxs = list(mp_facemesh.FACEMESH_LEFT_EYE)
# flatten and remove duplicates
all_left_eye_idxs = set(np.ravel(all_left_eye_idxs))
# Landmark points corresponding to right eye
all_right_eye_idxs = list(mp_facemesh.FACEMESH_RIGHT_EYE)
all_right_eye_idxs = set(np.ravel(all_right_eye_idxs))
# Combined for plotting - Landmark points for both eye
all_idxs = all_left_eye_idxs.union(all_right_eye_idxs)
# The chosen 12 points: P1, P2, P3, P4, P5, P6
chosen_left_eye_idxs = [362, 385, 387, 263, 373, 380]
chosen_right_eye_idxs = [33, 160, 158, 133, 153, 144]
all_chosen_idxs = chosen_left_eye_idxs + chosen_right_eye_idxsДавайте продемонстрируем API обнаружения ориентиров на образце изображения:
# load the image
image = cv2.imread(r"test-open-eyes.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # convert to RGB
image = np.ascontiguousarray(image)
imgH, imgW, _ = image.shape
plt.imshow(image)
Рекомендуемый способ инициализации объекта Face Mesh graph - использовать контекстный менеджер “with”. Во время инициализации мы также можем передавать такие аргументы, как:
static_image_mode: Следует ли рассматривать входные изображения как пакет статических и, возможно, несвязанных изображений или видеопоток.max_num_faces: Максимальное количество обнаруживаемых лиц.refine_landmarks: Следует ли дополнительно уточнять координаты ориентиров вокруг глаз и губ и другие выходные ориентиры вокруг радужной оболочки.min_detection_confidence: Минимальное значение достоверности([0.0, 1.0])для распознавания лиц, которое считается успешным.min_tracking_confidence: Минимальное значение достоверности([0.0, 1.0])для лицевых ориентиров, которые будут считаться успешно отслеженными.
# Running inference using static_image_mode
with mp_facemesh.FaceMesh(
static_image_mode=True, # Default=False
max_num_faces=1, # Default=1
refine_landmarks=False, # Default=False
min_detection_confidence=0.5, # Default=0.5
min_tracking_confidence= 0.5, # Default=0.5
) as face_mesh:
results = face_mesh.process(image)
# Indicates whether any detections are available or not.
print(bool(results.multi_face_landmarks))Когда вы смотрите на аргументы конвейера, появляется интересный параметр min_tracking_confidence. Как упоминалось выше, это помогает в непрерывном отслеживании ориентиров. Таким образом, в промежутках между кадрами, вместо того, чтобы пытаться непрерывно обнаруживать лица, мы можем только отслеживать движение обнаруженного лица. Поскольку алгоритмы отслеживания, как правило, быстрее алгоритмов обнаружения, это дополнительно помогает повысить скорость вывода.
Отслеживание объектов - увлекательная область компьютерного зрения, и в последнее время в этой области были достигнуты большие успехи. Если вы хотите узнать больше об этой теме, не волнуйтесь, мы вас позаботимся. У нас есть для вас серия статей, в которых четко объясняется, как работает отслеживание объектов?
Хорошо, на данный момент у нас есть подтверждение того, что конвейер произвел некоторые обнаружения. Следующая задача - получить доступ к обнаруженным ориентирам. Мы знаем, что конвейер может обнаруживать несколько лиц и предсказывать ориентиры по всем обнаруженным лицам. results.multi_face_landmarksОбъект представляет собой список. Каждый индекс содержит определения ориентиров для лица. Максимальная длина этого списка зависит от max_num_faces параметра.
Чтобы получить первую обнаруженную точку ориентира (единственного обнаруженного лица), мы должны использовать .landmarkатрибут. Вы можете думать об этом как о списке словарей.Этот атрибут содержит значения нормализованных координат каждой обнаруженной точки ориентира.
Давайте посмотрим, как получить доступ к координатам первой ориентирной точки первого обнаруженного лица.
landmark_0 = results.multi_face_landmarks[0].landmark[0]
print(landmark_0)
landmark_0_x = landmark_0.x * imgW
landmark_0_y = landmark_0.y * imgH
landmark_0_z = landmark_0.z * imgW # according to documentation
print()
print("X:", landmark_0_x)
print("Y:", landmark_0_y)
print("Z:", landmark_0_z)
print()
print("Total Length of '.landmark':", len(results.multi_face_landmarks[0].landmark))
Получаем следующий вывод:
x: 0.5087572336196899
y: 0.5726696848869324
z: -0.03815639764070511
X: 254.37861680984497
Y: 429.5022636651993
Z: -19.078198820352554
Total Length of '.landmark': 468Давайте визуализируем обнаруженные ориентиры. Мы построим следующее:
Все обнаруженные ориентиры с помощью
drawing_utils.Все ориентиры для глаз.
Выбранные ориентиры для глаз.
Для визуализации мы определим вспомогательную функцию.
def plot(
*,
img_dt,
img_eye_lmks=None,
img_eye_lmks_chosen=None,
face_landmarks=None,
ts_thickness=1,
ts_circle_radius=2,
lmk_circle_radius=3,
name="1",
):
# For plotting Face Tessellation
image_drawing_tool = img_dt
# For plotting all eye landmarks
image_eye_lmks = img_dt.copy() if img_eye_lmks is None else img_eye_lmks
# For plotting chosen eye landmarks
img_eye_lmks_chosen = img_dt.copy() if img_eye_lmks_chosen is None else img_eye_lmks_chosen
# Initializing drawing utilities for plotting face mesh tessellation
connections_drawing_spec = mp_drawing.DrawingSpec(
thickness=ts_thickness,
circle_radius=ts_circle_radius,
color=(255, 255, 255)
)
# Initialize a matplotlib figure.
fig = plt.figure(figsize=(20, 15))
fig.set_facecolor("white")
# Draw landmarks on face using the drawing utilities.
mp_drawing.draw_landmarks(
image=image_drawing_tool,
landmark_list=face_landmarks,
connections=mp_facemesh.FACEMESH_TESSELATION,
landmark_drawing_spec=None,
connection_drawing_spec=connections_drawing_spec,
)
# Get the object which holds the x, y, and z coordinates for each landmark
landmarks = face_landmarks.landmark
# Iterate over all landmarks.
# If the landmark_idx is present in either all_idxs or all_chosen_idxs,
# get the denormalized coordinates and plot circles at those coordinates.
for landmark_idx, landmark in enumerate(landmarks):
if landmark_idx in all_idxs:
pred_cord = denormalize_coordinates(landmark.x,
landmark.y,
imgW, imgH)
cv2.circle(image_eye_lmks,
pred_cord,
lmk_circle_radius,
(255, 255, 255),
-1
)
if landmark_idx in all_chosen_idxs:
pred_cord = denormalize_coordinates(landmark.x,
landmark.y,
imgW, imgH)
cv2.circle(img_eye_lmks_chosen,
pred_cord,
lmk_circle_radius,
(255, 255, 255),
-1
)
# Plot post-processed images
plt.subplot(1, 3, 1)
plt.title("Face Mesh Tessellation", fontsize=18)
plt.imshow(image_drawing_tool)
plt.axis("off")
plt.subplot(1, 3, 2)
plt.title("All eye landmarks", fontsize=18)
plt.imshow(image_eye_lmks)
plt.axis("off")
plt.subplot(1, 3, 3)
plt.imshow(img_eye_lmks_chosen)
plt.title("Chosen landmarks", fontsize=18)
plt.axis("off")
plt.show()
plt.close()
returnТеперь, чтобы отобразить обнаружения, нам просто нужно выполнить итерацию по списку обнаружений.
# If detections are available.
if results.multi_face_landmarks:
# Iterate over detections of each face. Here, we have max_num_faces=1,
# So there will be at most 1 element in
# the 'results.multi_face_landmarks' list
# Only one iteration is performed.
for face_id, face_landmarks in enumerate(results.multi_face_landmarks):
_ = plot(img_dt=image.copy(), face_landmarks=face_landmarks)
Метод соотношения сторон глаза (EAR)
В предыдущем разделе мы обсудили шаги для пункт 2 нашего решения. В этом разделе мы обсудим Пункт 3:Формула соотношения сторон глаз, представленная в статье Обнаружение моргания глаз в реальном времени с использованием лицевых ориентиров.
Мы будем использовать решение Mediapipe Face Mesh для обнаружения и извлечения соответствующих ориентиры в области глаз (Точки P1 – P6 на изображении ниже).
После получения соответствующих точек Соотношение сторон глаза (EAR) вычисляется между высотой и шириной глаза.
EAR в основном остается постоянным, когда глаз открыт, и приближается к нулю, в то время как закрытие глаза является частично человеком, а поза головы нечувствительна. Соотношение сторон открытого глаза имеет небольшие различия у разных людей. Он полностью инвариантен к равномерному масштабированию изображения и повороту лица в плоскости. Поскольку моргание выполняется обоими глазами синхронно, EAR обоих глаз усредняется.
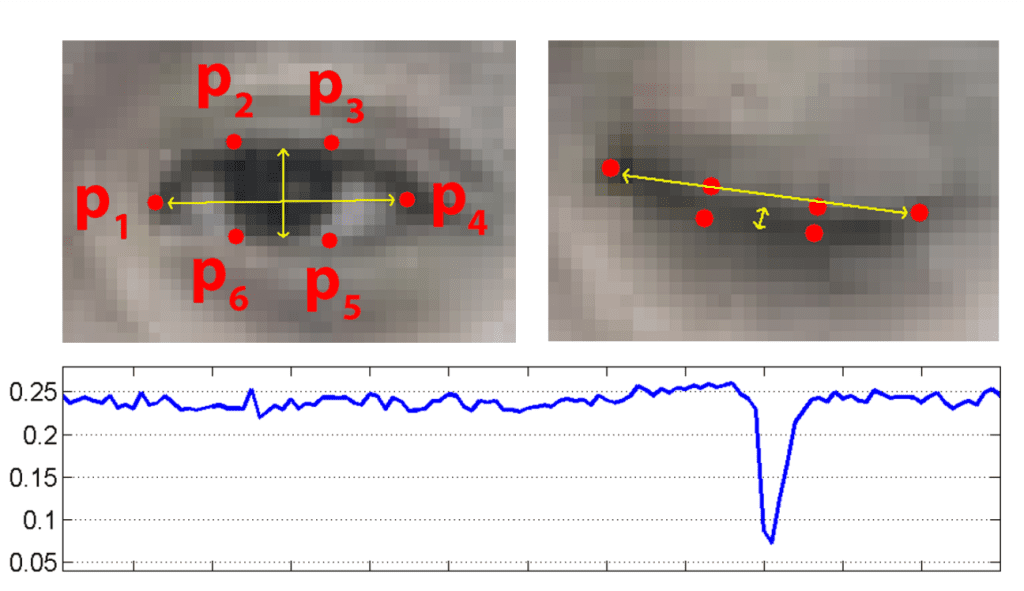
Наверх: Открывайте и закрывайте глаза с ориентирами Pi.
Снизу: Соотношение сторон глаз, построенное для нескольких кадров видеоряда. Присутствует одно мигание.
Во-первых, мы должны рассчитать соотношение сторон глаз для каждого глаза:
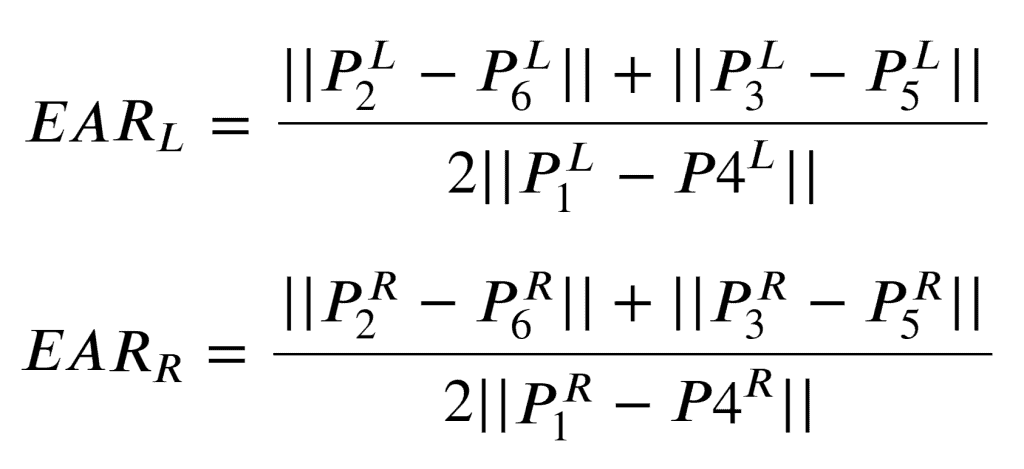
|| указывает норму L2 и используется для вычисления расстояния между двумя векторами.
Для вычисления окончательного значения EAR авторы предлагают усреднить два значения EAR.

В общем, среднее значение. Значение EAR находится в диапазоне [0.0, 0.40]. Значение EAR быстро уменьшается во время действия “закрытие глаз”.
Теперь, когда мы знакомы с формулой EAR, давайте определим три необходимые функции: distance(…), get_ear(…), and calculate_avg_ear(…).
def distance(point_1, point_2):
"""Calculate l2-norm between two points"""
dist = sum([(i - j) ** 2 for i, j in zip(point_1, point_2)]) ** 0.5
return distФункция get_ear(...) принимает атрибут .landmark в качестве параметра. В каждой позиции индекса у нас есть нормализованный объект ориентира. Этот объект содержит нормализованные x, y и z.
def get_ear(landmarks, refer_idxs, frame_width, frame_height):
"""
Calculate Eye Aspect Ratio for one eye.
Args:
landmarks: (list) Detected landmarks list
refer_idxs: (list) Index positions of the chosen landmarks
in order P1, P2, P3, P4, P5, P6
frame_width: (int) Width of captured frame
frame_height: (int) Height of captured frame
Returns:
ear: (float) Eye aspect ratio
"""
try:
# Compute the euclidean distance between the horizontal
coords_points = []
for i in refer_idxs:
lm = landmarks[i]
coord = denormalize_coordinates(lm.x, lm.y,
frame_width, frame_height)
coords_points.append(coord)
# Eye landmark (x, y)-coordinates
P2_P6 = distance(coords_points[1], coords_points[5])
P3_P5 = distance(coords_points[2], coords_points[4])
P1_P4 = distance(coords_points[0], coords_points[3])
# Compute the eye aspect ratio
ear = (P2_P6 + P3_P5) / (2.0 * P1_P4)
except:
ear = 0.0
coords_points = None
return ear, coords_pointsНаконец, определена функция calculate_avg_ear(...):
def calculate_avg_ear(landmarks, left_eye_idxs, right_eye_idxs, image_w, image_h):
"""Calculate Eye aspect ratio"""
left_ear, left_lm_coordinates = get_ear(
landmarks,
left_eye_idxs,
image_w,
image_h
)
right_ear, right_lm_coordinates = get_ear(
landmarks,
right_eye_idxs,
image_w,
image_h
)
Avg_EAR = (left_ear + right_ear) / 2.0
return Avg_EAR, (left_lm_coordinates, right_lm_coordinates)Давайте протестируем формулу EAR. Мы рассчитаем среднее значение EAR для ранее использованного изображения и другого изображения, где глаза закрыты.
image_eyes_open = cv2.imread("test-open-eyes.jpg")[:, :, ::-1]
image_eyes_close = cv2.imread("test-close-eyes.jpg")[:, :, ::-1]
for idx, image in enumerate([image_eyes_open, image_eyes_close]):
image = np.ascontiguousarray(image)
imgH, imgW, _ = image.shape
# Creating a copy of the original image for plotting the EAR value
custom_chosen_lmk_image = image.copy()
# Running inference using static_image_mode
with mp_facemesh.FaceMesh(refine_landmarks=True) as face_mesh:
results = face_mesh.process(image).multi_face_landmarks
# If detections are available.
if results:
for face_id, face_landmarks in enumerate(results):
landmarks = face_landmarks.landmark
EAR, _ = calculate_avg_ear(
landmarks,
chosen_left_eye_idxs,
chosen_right_eye_idxs,
imgW,
imgH
)
# Print the EAR value on the custom_chosen_lmk_image.
cv2.putText(custom_chosen_lmk_image,
f"EAR: {round(EAR, 2)}", (1, 24),
cv2.FONT_HERSHEY_COMPLEX,
0.9, (255, 255, 255), 2
)
plot(img_dt=image.copy(),
img_eye_lmks_chosen=custom_chosen_lmk_image,
face_landmarks=face_landmarks,
ts_thickness=1,
ts_circle_radius=3,
lmk_circle_radius=3
)Результат:

Как можем заметить, значение EAR при открытых глазах равно 0,28 и (близко к нулю) 0,08, когда глаза закрыты.
Пошаговое руководство по коду обнаружения сонливости водителя на Python
В предыдущих разделах были рассмотрены все необходимые компоненты для создания приложения для обнаружения сонливости водителя. Теперь мы начнем создавать наше web-приложение streamlit, чтобы сделать это приложение доступным для всех, кто использует web-браузер.
Сразу же возникает проблема: streamlit не предоставляет никаких компонентов, которые могут передавать потоковое видео из интерфейса в серверную часть и обратно во внешний интерфейс.Это не проблема, если мы хотим использовать приложение только локально. Существуют обходные пути, при которых мы можем использовать OpenCV для подключения к некоторым IP-камерам, но мы не будем использовать этот подход здесь.
Для нашего приложения мы будем использовать компонент streamlit с открытым исходным кодом: streamlit-webrtc. Это позволяет пользователям обрабатывать и передавать видео / аудио потоки в реальном времени по защищенной сети с streamlit.
Давайте начнем.
Сначала мы создадим drowsy_detection.py скрипт (доступен в разделе загрузки). Этот скрипт будет содержать все функции и классы, необходимые для обработки входного фрейма и отслеживания состояния различных объектов.
1) Импорт необходимых библиотек и функций:
import cv2
import time
import numpy as np
import mediapipe as mp
from mediapipe.python.solutions.drawing_utils import _normalized_to_pixel_coordinates as denormalize_coordinates2) Далее мы определим необходимые функции. Мы определили 3 функции, то есть, distance(…),get_ear(…) иcalculate_avg_ear(…) .
Новые:
get_mediapipe_app(…):Для инициализации объекта решения Mediapipe Face Mesh.plot_eye_landmarks(…):Эта функция отображает обнаруженные (и выбранные) ориентиры для глаз.plot_text(…):Эта функция используется для отображения текста на видеокадрах, например, значения EAR.
def distance(point_1, point_2):
...
...
return dist
def get_ear(landmarks, refer_idxs, frame_width, frame_height):
...
...
return ear, coords_points
def calculate_avg_ear(landmarks, left_eye_idxs, right_eye_idxs, image_w, image_h):
...
...
return Avg_EAR, (left_lm_coordinates, right_lm_coordinates)
def get_mediapipe_app(
max_num_faces=1,
refine_landmarks=True,
min_detection_confidence=0.5,
min_tracking_confidence=0.5,
):
"""Initialize and return Mediapipe FaceMesh Solution Graph object"""
face_mesh = mp.solutions.face_mesh.FaceMesh(
max_num_faces=max_num_faces,
refine_landmarks=refine_landmarks,
min_detection_confidence=min_detection_confidence,
min_tracking_confidence=min_tracking_confidence,
)
return face_mesh
def plot_eye_landmarks(frame, left_lm_coordinates,
right_lm_coordinates, color
):
for lm_coordinates in [left_lm_coordinates, right_lm_coordinates]:
if lm_coordinates:
for coord in lm_coordinates:
cv2.circle(frame, coord, 2, color, -1)
frame = cv2.flip(frame, 1)
return frame
def plot_text(image, text, origin,
color, font=cv2.FONT_HERSHEY_SIMPLEX,
fntScale=0.8, thickness=2
):
image = cv2.putText(image, text, origin, font, fntScale, color, thickness)
return image3) Далее мы определим VideoFrameHandler класс. В этом классе мы напишем код для алгоритма, рассмотренного выше. В этом классе определены два метода: __init__() и. process(...)
Давайте рассмотрим их один за другим.
class VideoFrameHandler:
def __init__(self):
"""
Initialize the necessary constants, mediapipe app
and tracker variables
"""
# Left and right eye chosen landmarks.
self.eye_idxs = {
"left": [362, 385, 387, 263, 373, 380],
"right": [33, 160, 158, 133, 153, 144],
}
# Used for coloring landmark points.
# Its value depends on the current EAR value.
self.RED = (0, 0, 255) # BGR
self.GREEN = (0, 255, 0) # BGR
# Initializing Mediapipe FaceMesh solution pipeline
self.facemesh_model = get_mediapipe_app()
# For tracking counters and sharing states in and out of callbacks.
self.state_tracker = {
"start_time": time.perf_counter(),
"DROWSY_TIME": 0.0, # Holds time passed with EAR < EAR_THRESH
"COLOR": self.GREEN,
"play_alarm": False,
}
self.EAR_txt_pos = (10, 30)Сначала мы создаем
self.eye_idxsсловарь. Этот словарь содержит выбранные нами позиции указателей ориентиров для левого и правого глаза.Две цветовые переменные
self.REDиself.GREENиспользуются для окрашивания точек ориентира, значения EAR и переменнойDROWSY_TIMEcounter в зависимости от условия.Затем мы инициализируем решение для лицевой сетки Mediapipe.
Наконец, мы определяем
self.state_trackerсловарь. Этот словарь содержит все переменные, значения которых постоянно меняются. В частности, он содержит start_time иDROWSY_TIMEпеременные, имеющие решающее значение для нашего алгоритма.Наконец, мы должны определить координатную позицию, в которой мы будем печатать текущее среднее значение EAR на
frame.
Далее давайте рассмотрим метод process(...):
def process(self, frame: np.array, thresholds: dict):
"""
This function is used to implement our Drowsy detection algorithm.
Args:
frame: (np.array) Input frame matrix.
thresholds: (dict) Contains the two threshold values
WAIT_TIME and EAR_THRESH.
Returns:
The processed frame and a boolean flag to
indicate if the alarm should be played or not.
"""
# To improve performance,
# mark the frame as not writeable to pass by reference.
frame.flags.writeable = False
frame_h, frame_w, _ = frame.shape
DROWSY_TIME_txt_pos = (10, int(frame_h // 2 * 1.7))
ALM_txt_pos = (10, int(frame_h // 2 * 1.85))
results = self.facemesh_model.process(frame)
if results.multi_face_landmarks:
landmarks = results.multi_face_landmarks[0].landmark
EAR, coordinates = calculate_avg_ear(landmarks,
self.eye_idxs["left"],
self.eye_idxs["right"],
frame_w,
frame_h
)
frame = plot_eye_landmarks(frame,
coordinates[0],
coordinates[1],
self.state_tracker["COLOR"]
)
if EAR < thresholds["EAR_THRESH"]:
# Increase DROWSY_TIME to track the time period with
# EAR less than the threshold
# and reset the start_time for the next iteration.
end_time = time.perf_counter()
self.state_tracker["DROWSY_TIME"] += end_time - self.state_tracker["start_time"]
self.state_tracker["start_time"] = end_time
self.state_tracker["COLOR"] = self.RED
if self.state_tracker["DROWSY_TIME"] >= thresholds["WAIT_TIME"]:
self.state_tracker["play_alarm"] = True
plot_text(frame, "WAKE UP! WAKE UP",
ALM_txt_pos, self.state_tracker["COLOR"])
else:
self.state_tracker["start_time"] = time.perf_counter()
self.state_tracker["DROWSY_TIME"] = 0.0
self.state_tracker["COLOR"] = self.GREEN
self.state_tracker["play_alarm"] = False
EAR_txt = f"EAR: {round(EAR, 2)}"
DROWSY_TIME_txt = f"DROWSY: {round(self.state_tracker['DROWSY_TIME'], 3)} Secs"
plot_text(frame, EAR_txt,
self.EAR_txt_pos, self.state_tracker["COLOR"])
plot_text(frame, DROWSY_TIME_txt,
DROWSY_TIME_txt_pos, self.state_tracker["COLOR"])
else:
self.state_tracker["start_time"] = time.perf_counter()
self.state_tracker["DROWSY_TIME"] = 0.0
self.state_tracker["COLOR"] = self.GREEN
self.state_tracker["play_alarm"] = False
# Flip the frame horizontally for a selfie-view display.
frame = cv2.flip(frame, 1)
return frame, self.state_tracker["play_alarm"]Здесь,
Мы начнем с установки
.writeableфлага в массиве frame NumPy равнымFalse. Это помогает повысить производительность. Таким образом, вместо отправки копииframeв каждую функцию, мы отправляем ссылку наframe.Далее мы инициализируем некоторые константы положения текста с учетом текущих размеров кадра.
Входные
frameданные, передаваемые этому методу, будут в формате RGB. Это единственная требуемая предварительная обработка. Модель Mediapipe принимает этотframeкак входные данные. Выходные данные собираются вresultsобъекте.
С этого момента код отражает блок-схему алгоритма, которую мы обсуждали выше.
1-я проверка if заключается в том, чтобы определить, доступны ли какие-либо обнаружения или нет. Если True,
calculate_avg_ear(…)функция вычисляет среднее значение EAR. Эта функция также возвращает текущее положение денормализованных координат для выбранных ориентиров.plot_eye_landmarks(…)Графики этих денормализованных координат.Следующим на очереди является 2-я if-проверка, чтобы определить, является ли текущий
EAR < EAR_THRESH. Если True, мы записываем разницу между current_time (end_time) и start_time . ЗначениеDROWSY_TIMEсчетчика увеличивается на основе этой разницы. Затем мы сбрасываемstart_timeзначениеend_time. Это помогает, отслеживая время между текущим и следующим кадром (еслиEARоно все еще меньшеEAR_THRESH).3-я проверка if заключается в том, чтобы определить, является ли
DROWSY_TIME >= WAIT_TIME.WAIT_TIMEПороговое значение содержит значение допустимого времени с закрытыми глазами.Если 3-е условие истинно, мы устанавливаем состояние
play_alarmлогического флагаTrueравным .Если выполняются 1-е и 2-е условия
False, сбросьте переменные состояния. СостояниеCOLORпеременной также изменяется в зависимости от вышеуказанных условий. Цвет текста для печатиEARиDROWSY_TIMEна рамке зависит отCOLORсостояния.Наконец, мы возвращаем обработанный кадр и значение переменной
play_alarmсостояния.
На этом завершается drowsy_detection.py сценарий.
Далее мы создадим streamlit_app.py сценарий. Этот файл содержит компоненты пользовательского интерфейса нашего веб-приложения, такие как компоненты слайдера (для настройки пороговых значений) и кнопки, используемые в нашем приложении. Он также включает в себя код, связанный с библиотекой streamlit-webrtc.
(Этот скрипт и остальные ресурсы доступны в разделе загрузка кода.)
import os
import av
import threading
import streamlit as st
from streamlit_webrtc import VideoHTMLAttributes, webrtc_streamer
from audio_handling import AudioFrameHandler
from drowsy_detection import VideoFrameHandler
# Define the audio file to use.
alarm_file_path = os.path.join("audio", "wake_up.wav")
# Streamlit Components
st.set_page_config(
page_title="Drowsiness Detection | LearnOpenCV",
page_icon="https://learnopencv.com/wp-content/uploads/2017/12/favicon.png",
layout="centered",
initial_sidebar_state="expanded",
menu_items={
"About": "### Visit www.learnopencv.com for more exciting tutorials!!!",
},
)
st.title("Drowsiness Detection!")
col1, col2 = st.columns(spec=[1, 1])
with col1:
# Lowest valid value of Eye Aspect Ratio. Ideal values [0.15, 0.2].
EAR_THRESH = st.slider("Eye Aspect Ratio threshold:", 0.0, 0.4, 0.18, 0.01)
with col2:
# The amount of time (in seconds) to wait before sounding the alarm.
WAIT_TIME = st.slider("Seconds to wait before sounding alarm:", 0.0, 5.0, 1.0, 0.25)
thresholds = {
"EAR_THRESH": EAR_THRESH,
"WAIT_TIME": WAIT_TIME,
}
# For streamlit-webrtc
video_handler = VideoFrameHandler()
audio_handler = AudioFrameHandler(sound_file_path=alarm_file_path)
# For thread-safe access & to prevent race-condition.
lock = threading.Lock()
shared_state = {"play_alarm": False}
def video_frame_callback(frame: av.VideoFrame):
frame = frame.to_ndarray(format="bgr24") # Decode and convert frame to RGB
frame, play_alarm = video_handler.process(frame, thresholds) # Process frame
with lock:
shared_state["play_alarm"] = play_alarm # Update shared state
# Encode and return BGR frame
return av.VideoFrame.from_ndarray(frame, format="bgr24")
def audio_frame_callback(frame: av.AudioFrame):
with lock: # access the current “play_alarm” state
play_alarm = shared_state["play_alarm"]
new_frame: av.AudioFrame = audio_handler.process(frame,
play_sound=play_alarm)
return new_frame
ctx = webrtc_streamer(
key="driver-drowsiness-detection",
video_frame_callback=video_frame_callback,
audio_frame_callback=audio_frame_callback,
rtc_configuration={"iceServers": [{"urls": ["stun:stun.l.google.com:19302"]}]},
media_stream_constraints={"video": {"width": True, "audio": True},
video_html_attrs=VideoHTMLAttributes(autoPlay=True, controls=False, muted=False),
)Мы начинаем с импорта необходимых библиотек и двух специальных классов, которые мы создали,
VideoFrameHandlerиAudioFrameHandler. Я скоро расскажу о функциональностиAudioFrameHandlerкласса.Затем мы объявляем компоненты на основе streamlit, такие как конфигурации страницы, заголовок и два ползунка (
EAR_THESHиWAIT_TIME). Мы передадим эти значения методу VideoHandler’s process(...).Далее мы инициализируем два экземпляра пользовательского класса:
video_handlerиaudio_handler.Затем мы инициализируем блокировку потока
shared_stateобъект словаря. Объект dictionary содержит только одну пару ключ-значение, тоplay_alarmесть логический флаг. Его значение зависит отplay_alarmлогического значения, возвращаемого методом .process(...) класса VideoFrameHandler .(Изменяемый)
shared_stateсловарь используется для передачи информации о состоянии между двумя функциями:video_frame_callbackиaudio_frame_callback.Функция video_frame_callback определена для обработки входных видеокадров. Он получает по одному кадру за раз от внешнего интерфейса.
Аналогично,
audio_frame_callbackфункция используется для обработки и возврата пользовательских звуковых кадров, таких как звуковой сигнал.Наконец, мы создаем компонент streamlit-webrtc
webrtc-streamer. Он будет обрабатывать безопасную передачу кадров данных между пользователем и сервером.
И на этом завершается streamlit_app.py сценарий.
Примечание: video_frame_callback получает VideoFrame объект (некоторого размера) и audio_frame_callback получает AudioFrameобъект (некоторой длины). Существует одно ограничение для streamlit-webrtc. Пользователь должен предоставить разрешение для веб-камеры и микрофона, чтобы приложение работало. На момент написания этого сообщения нет способа получать и возвращать только видеокадры со случайными аудиоданными (при выполнении условия).
Единственным оставшимся скриптом является audio_handling.py файл, который содержит AudioFrameHandler класс. Здесь мы не будем рассматривать код, но мы предоставим суть функциональности, выполняемой этим классом. Мы обсудим, как обрабатывается каждый аудиокадр.
В
audio_frame_callbackфункции, которую мы определили выше, при каждой временной метке мы получаем audio frame некоторой длины, формы, frame_rate, каналов и т. Д.Например, допустим, входной audio frame имеет длину 20 мс. Теперь есть проблема, потому что наш файл alarm / sound может иметь любую продолжительность. И мы не можем отправить весь звуковой сигнал за один раз. Если мы сжмем и отправим его, звук будет просто коротким всплеском шума.
Решение состоит в том, чтобы разбить звуковой файл будильника на сегменты длиной 20 мс. Затем, если
play_alarmфлагTrueустановлен, продолжайте возвращать нарезанные сегменты файла тревоги один за другим, пока мы не отправим последний сегмент.Один из способов взглянуть на это решение таков: при разговоре мы не втискиваем все, что хотим сказать, скажем, за 20 мс, но это распределяется на некоторое время (> 20 мс). В каждом случае мы произносим только часть всего нашего предложения. Полное предложение включает в себя все эти мельчайшие компоненты, которые были распределены во времени и неоднократно соединялись вместе.
В
audio_frame_callbackфункции.process(...)метод вызывается каждый раз с другим входным аудио сегментом.Свойства этого аудио сегмента могут отличаться в разных подключениях и браузерах.
.prepare_audio(…)Функция вызывается на первом входном audio frame для решения этой проблемы.В зависимости от свойств входного audio frameзвуковой файл сигнала тревоги обрабатывается и соответственно разделяется на сегменты.
Затем, в зависимости от
play_soundлогического флага, мы либо возвращаем нарезанные сегменты звукового файла сигнала тревоги, либо изменяем амплитуду (обычно, громкость) входного аудио сегмента на -100. Он гасит всю входную звуковую волну и обеспечивает эффект тишины.
На этом завершается финал audio_handling.py сценарий.
Проверьте наше развернутое приложение в потоковом облаке.Следующее видео представляет собой запись экрана развернутого приложения.
Summary
В этом посте нашей целью было создать простое и полезное приложение для обнаружения сонливости водителя с использованием Mediapipe на Python. Мы начали с определения постановки задачи и определения соответствующего варианта использования. Затем мы предложили эффективное, быстрое и простое в реализации решение на python. Для решения мы использовали конвейер Face Mesh от Mediapipe и формулу соотношения сторон глаз. Компонент пользовательского интерфейса веб-приложения построен с использованием Streamlit и streamlit-webrtc. Наконец, мы демонстрируем наше веб-приложение, развернутое в облачном сервисе.
Это всего лишь одно из возможных решений. Другим возможным решением является использование некоторого алгоритма (может быть, того же конвейера сетки лиц), извлечение областей глаз из кадра и передача их через классификатор, основанный на глубоком обучении. Мы продемонстрируем больше таких приложений в наших будущих статьях. На данный момент читатель должен изучить и освоить вышеперечисленные варианты.
Код на Github
victor30608
В статье Яндекса "Как мы разработали устройство для контроля внимания водителей. Опыт Яндекс.Такси" хорошо описывается в комментариях, почему этот подход не работает в реальности. Я решал задачу определения засыпания на устройствах, которые эксплуатируются в метро и в автобусах. Нейросетевой анализатор состояния глаз даёт точность в разы лучше + это более контролируемый механизм относительно EAR.
dimanosov007 Автор
Интересная статья, как по мне она больше описывает проблемы подбора железа. Но комментарии действительно очень хороши. Спасибо, за ссылку!
P.S. ссылка на оригинал приведена, в разделе Автор оригинала: Vaibhav (кликабельная ссылка на оригинал)