
Привет, Хабр! Меня зовут Никита Летов, я тимлид бэкенд-разработки мобильного приложения Росбанка для физических лиц. Этот пост входит в серию постов по разработке бэкенд-микросервисов на Java и Spring и является адаптацией моего доклада с JPoint 2022.
Также хочу предупредить, что данный пост не cookbook и не предоставляет идеально приготовленное решение какой-либо бизнес-проблемы. Это разбор одной технологии, которая при правильном использовании может помочь вам в решении реальной проблемы. А может и не помочь — всё зависит от ее природы.

Если вам лень читать и вы рветесь в бой, то вот тут лежит проект со всеми материалами, docker-compose.yml со всей инфраструктурой (kafka, postgres), тестами (gatling projects) и мониторингом (Grafana, Prometheus, exporters). Используя этот проект, вы можете поисследовать разные решения и понаблюдать за производительностью их работы. Если будут сложности или вопросы по проекту — добро пожаловать в комментарии, постараюсь всем помочь и ответить на вопросы.
Ну а теперь к делу. Как почти любой доклад на конференции или статья на Хабре начинаются с горящей проблемы, так и моя история началась с «менеджера трат», который вы наверняка видели в своем любимом банковском приложении.
")
После разработки сервиса, тестирования (в том числе и нагрузочного) и развертывания его на пилотную группу мы столкнулись с тем, что суммы, которые собирает менеджер, расходятся с реальностью, что делает его, по факту, бесполезным.

На самом деле, с математикой тут все в порядке и проблема кроется в другом.
Начинаем разбираться. Есть микросервис pfm-app потребляющий сообщения из топика Kafka, продюсером которых является репликатор Debezium из таблицы БД другого микросервиса operation-history-app. События из истории бывают как минимум 4 видов — Холд/Расхолд/Списание/Бонусы. Каждое из них несет в себе конкретную сумму и у каждого вида сообщения свой уникальный UID. При этом ключей сообщений кафки, соответствующих определённому пользователю, нет.
Сервис менеджера трат обрабатывает батчами данные сообщения, собирает пачки по пользователям и начинает процессить — записывать в таблицу PostgreSQL данные о сумме трат в определенной категории в определенный месяц. И на этапе процессинга все начинает рушиться, когда два консьюмера сервиса получают события о тратах одного пользователя и начинают обрабатывать их параллельно. Как же это вышло?
Схема, я думаю, в целом ясна. При создании таких приложений часто забывают о параллельности и многопоточности, а для разработчика картина мира выглядит вот так:

Как же это работает на самом деле? В OpenShift крутится не один, а несколько под сервиса, а данные дополнительно приходят из REST-потоков. И самое интересное начинается, когда несколько потребителей (под или consumer-ов внутри одной поды, подключенных к разным kafka partition) или потоков, созданных для REST-запросов, пытаются создавать/обновлять/удалять одну и ту же запись в базе данных.

Что же мы получаем? Правильно: конфликты и перезаписи.
Для наглядной демонстрации проблемы создадим простой сервис, единственной целью которого будет учет лайков, поставленных слушателями участникам конференции. Лайки будут собираться по названию доклада.
Сервис будет состоять из
Слушателя кафки
Код слушателя
public class LikesConsumer implements Consumer<Likes> {
private final SpeakerMessageProcessor messageProcessor;
@Override
public void accept(Likes likes) {
log.warn("Message received {}", likes);
messageProcessor.processOneMessage(likes);
}
}Процессора
Код процессора
public class SpeakerMessageProcessor {
private final SpeakerService speakerService;
public void processOneMessage(Likes likes) {
speakerService.addLikesToSpeaker(likes);
}
}Единственного сервиса
Код сервиса
public class SpeakerService {
private final SpeakersRepository speakersRepository;
private final HistoryRepository historyRepository;
private final StreamBridge streamBridge;
/**
* Method for adding likes to speaker by ID or TalkName.
*
* @param likes DTO with information about likes to be added.
*/
public void addLikesToSpeaker(Likes likes) {
if (likes.getTalkName() != null) {
speakersRepository.findByTalkName(likes.getTalkName()).ifPresentOrElse(speaker -> {
saveMessageToHistory(likes, "RECEIVED");
speaker.setLikes(speaker.getLikes() + likes.getLikes());
speakersRepository.save(speaker);
log.info("{} likes added to {}", likes.getLikes(), speaker.getFirstName() + " " + speaker.getLastName());
}, () -> {
log.warn("Speaker with talk {} not found", likes.getTalkName());
saveMessageToHistory(likes, "ORPHANED");
});
} else {
log.error("Error during adding likes, no IDs given");
saveMessageToHistory(likes, "CORRUPTED");
}
}
/**
* Method for creating task to add likes to speaker.
* Produces the message with DTO to kafka, for future processing.
*
* @param likes DTO with information about likes to be added.
*/
public void createTaskToAddLikes(Likes likes) {
streamBridge.send("likesProducer-out-0", likes);
}
/**
* Method for saving message to history.
* Produces the message with DTO to kafka, for future processing.
*
* @param likes DTO with information about likes to be added.
*/
private void saveMessageToHistory(Likes likes, String status) {
try {
historyRepository.save(HistoryEntity.builder()
.talkName(likes.getTalkName())
.likes(likes.getLikes())
.status(status)
.build());
} catch (RuntimeException ex) {
log.warn("Failed to save message to history.", ex);
}
}
}REST-контроллера (запускающего ту же задачу, что процессор сообщений)
Код контроллера
public class SpeakerController {
private final SpeakerService service;
@PostMapping("/addlikes")
public ResponseEntity<String> updateSpeaker(@RequestBody Likes likes) {
try {
service.addLikesToSpeaker(likes);
return new ResponseEntity<>("Likes successfully added.", HttpStatus.ACCEPTED);
} catch (Exception ex) {
log.warn("Exception in controller:", ex);
return new ResponseEntity<>(ex.getMessage(), HttpStatus.CONFLICT);
}
}
}Репозиториев спикеров и истории сообщений
Код репозиториев
public interface SpeakersRepository extends JpaRepository<SpeakerEntity, Long> {
Optional<SpeakerEntity> findByTalkName(String talkName);
}
public interface HistoryRepository extends JpaRepository<HistoryEntity, Long> {
}DTO и Entity
Код DTO и Entity
@Table(name = "speakers")
public class SpeakerEntity {
@Id
private Long id;
@Column(name = "firstname")
private String firstName;
@Column(name = "lastname")
private String lastName;
@Column(name = "talkname")
private String talkName;
private int likes;
@CreationTimestamp
@Column(updatable = false, nullable = false)
private LocalDateTime created;
@UpdateTimestamp
@Column(nullable = false)
private LocalDateTime updated;
}
@Table(name = "history")
public class HistoryEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "talkname")
private String talkName;
private int likes;
private String status;
@CreationTimestamp
@Column(updatable = false, nullable = false)
private LocalDateTime created;
}
public class Likes {
@JsonProperty("talkName")
private String talkName;
@JsonProperty("likes")
private int likes;
}Вроде бы выглядит всё просто и логично, и по идее должно работать, не так ли? Давайте проверим: запустим сервис и прогоним пару тестов по тысяче сообщений гатлингом в кафку и в контроллер. Сценарии гатлинга вы можете посмотреть в проекте по ссылке выше.
По итогам прогона тестов мы хотели бы увидеть, что John Doe получит 2к лайков, но вместо этого получилось… то что получилось, а именно 851.

Почему так получилось? Ведь «…согласно специальной теории относительности Эйнштейна, невозможно сказать в абсолютном смысле, что два разных события происходят одновременно, если эти события разделены в пространстве…». Шутка :) На самом деле, у нас начинается гонка, в которой выигрывает последний.

На примере выше три события начались и закончились в разное время, а по факту в базу записалось только одно. В нашем случае 5 вместо 9.
Как решить проблему?
Первое, что может прийти в голову начинающему разработчику при возникновении гонки, — синхронизация потоков. Это не поможет, потому что у нас есть несколько инстансов сервиса и сообщения прилетают из разных мест (Consumer + Rest Controller). Последовательное чтение сообщений строго из одной партиции Kafka — интересный вариант, но это снизит производительность. Управление ключами сообщений Kafka — еще интереснее, но может ли producer ставить необходимые ключи? И как это применить в случае прихода сообщений по REST?
Также надо понимать, кто управляет кафкой и можем ли мы создавать дополнительные временные топики, к примеру. А еще у нас есть REST-запросы, которые Tomcat также распараллелит. А если запустить сервис только в режиме работы единственной поды, отключить горячий DR и синхронизировать потом потоки… нет, странный вариант.
Что же будем делать? Вот вам несколько вариантов:

Подсказка – в какой-то степени все варианты верны, но надо их использовать комплексно.
Давайте для начала вспомним, что такое транзакция вообще. В Spring она обозначается как @Transactional.
Транзакция – это группа последовательных операций с базой данных, которая представляет собой логическую единицу работы с данными. Транзакция может быть выполнена либо целиком и успешно, соблюдая целостность данных и независимо от параллельно идущих других транзакций, либо не выполнена вообще. Тогда она не должна произвести никакого эффекта.
Вроде бы это может нам помочь. Посмотрим, как работает транзакция в Spring. Мы аннотируем метод и пытаемся его вызвать (на самом деле вызываем прокси, в который обернут наш метод). Transaction Advisor создает транзакцию, и затем выполняется бизнес-логика. Затем она возвращается в Transaction Advisor, который принимает решение о коммите или роллбэке. В итоге все возвращается в прокси и дальше идет return. Важно, что транзакция распространяется только в threadLocal.

В нашем примере мы поставим @Transactional перед методом addLikesToSpeaker, ведь логично, что именно этот метод содержит в себе основную логику работы. В этой точке потоки будут вызывать транзакцию. Запускаем наш тест на две тысячи лайков. Результат будет еще хуже:

Думаем дальше. Разберем два основных свойства транзакции — Isolation level и Propagation.
Изоляция
Изоляция – это третья буква в аббревиатуре ACID. Изоляция означает, что параллельные транзакции не должны влиять друг на друга. Степень этого влияния определяется уровнемизоляции. Существует четыре уровня — Read Uncommitted, Read Committed, Repeatable Read и Serializable. Read Uncommitted недоступен в Postgres и оставлен только для совместимости. По факту он работает, как Read Committed, поэтому начнем сразу с него.
Read Committed
Представим, что две транзакции собираются изменить данные в таблице. Обе транзакции считывают (select) данные, обе совершают update. Но считывают только данные, которые были закоммичены. Выходит, что пока одна транзакция не закоммитилась, вторая будет считывать те же данные, что и первая. Соответственно, и обновлять данные будет те же самые; в итоге в таблице окажутся только данные от последней закоммиченной транзакции. Выглядит это примерно так:

У нас начинается транзакция 1. Она делает какой-то select по id, получает результат (в нашем случае 5) и делает апдейт (прибавляет 3). По ее мнению, в итоге в БД должно быть 8.
Представим, что до коммита транзакции 1 начинается транзакция 2. Она делает аналогичный select и получает тот же результат, потому что транзакция 1 еще не закоммичена. В своем апдейте вторая транзакция прибавляет к 5 еще 8. Получается 13. Но затем транзакция 1 все-таки коммитится, и в итоге мы получаем 8 — по итогам двух транзакций это неверный результат.
С этой же проблемой мы и столкнулись, когда установили в «менеджере трат» уровень всех транзакций как TRANSACTION_READ_COMMITTED.
Repeatable Read
Repeatable Read должен решать проблему неповторяющихся чтений.

Начинается все так же, как и в первом случае. Транзакция 1 коммитится после выполнения транзакции 2. Затем происходит попытка закоммитить транзакцию 2, и мы получаем ошибку «Could not serialize access due to concurrent update».
Похоже, что это подходящий вариант. Но возникает exception, поэтому нужно подумать о @Retryable. Выставим число попыток побольше, потому что конкурентность будет большая:
@Retryable(max attempts = 15) // Это кстати довольно много. По-хорошему, должно хватать 1-3 попыток.Запустим два теста на 2000 лайков:

Почти 100%, но все-таки нет. Ошибки «Could not serialize access due to concurrent update» не избежать. Посмотрим в мониторинге, что там с потоками:

200 (!!!) потоков попытались обновить одну entity. Это многовато. Если вы сталкиваетесь с таким количеством потоков в проде, значит, скорее всего, что-то не так. Попробуем уменьшить конкурентность на REST. Не сразу вызывать обновление, а через метод createTaskToAddLikes:
public void createTaskToAddLikes(Likes likes) {
streamBridge.send("likesProducer-out-0", likes);
}
@PostMapping("/addlikes")
public ResponseEntity<String> updateSpeaker(@RequestBody Likes likes) {
try {
service.createTaskToAddLikes(likes);
return new ResponseEntity<>("Likes successfully added.", HttpStatus.ACCEPTED);
} catch (Exception ex) {
log.warn("Exception in controller:", ex);
return new ResponseEntity<>(ex.getMessage(), HttpStatus.CONFLICT);
}
}Он также будет отправлять сообщения в очередь Kafka, где у нас выставлено пять партиций и пять сборщиков, которые разбирают лаг:
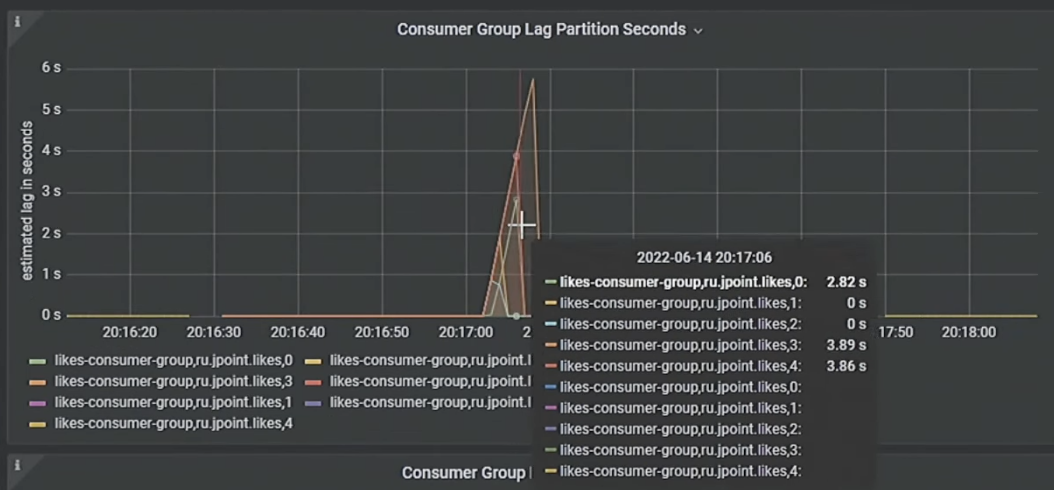
Запускаем тест. Ура, мы добились 100%:

Снизив конкурентность, мы уменьшили количество ошибок. Напоследок отмечу, что Repeatable Read в Postgres также решает проблему фантомного чтения.
Serializable
Serializable, в свою очередь, решает проблему аномалий сериализации. Здесь нет нужды использовать явные блокировки, потому что чтение и запись мониторит БД. Если база заметит, что две транзакции читают одну и ту же запись, а потом куда-то что-то пишут (неважно куда), одну из транзакций база закоммитить не позволит. Таким образом, транзакции могут обновлять данные так, чтобы ничего не пересекалось, то есть последовательно.

В нашем примере этот уровень изоляции будет вести себя так же, как Repeatable Read. Запускаем первый тест на 1000 лайков:

Почему 993, а не 1000? Дело в том, что метод saveMessageToHistory…
private void saveMessageToHistory(Likes likes, String status) {
try {
historyRepository.save(HistoryEntity.builder()
.talkName(likes.getTalkName())
.likes(likes.getLikes())
.status(status)
.build());
} catch (RuntimeException ex) {
log.warn("Failed to save message to history.", ex);
}…вызывается внутри транзакции. Соответственно, при любых связанных исключениях будет откатываться вся транзакция. Чтобы решить эту проблему, обратимся к еще одному свойству транзакции – распространению (propagation).

Для начала нас интересует уровень Required. Если в методе caller, где мы вызываем транзакцию, она уже есть, то мы просто ее переиспользуем и в конце принимаем решение о коммите или откате. Если не было транзакции, мы создаем новую.
Что еще нужно знать об уровнях распространения? Nested невозможен в JPA-диалекте, потому что здесь нельзя создать save point. Nested, в отличие от Required New, создает некий save point. Если вы, например, обновляете огромный батч данных, то вам не придется в случае ошибки откатывать всё, а можно будет откатиться только до save point.
Не будем изобретать велосипед и смешивать подходы. Чтобы нужный приватный метод аннотировать транзакцией, просто вынесем его в отдельный класс. Вынесем отдельный сервис и создадим новую транзакцию. Неважно, откатится она или нет, главное, что она не повлияет не предыдущую транзакцию, а та — на неё:
public class HistoryService {
private final HistoryRepository historyRepository;
/**
* Method for saving message to history.
* Produces the message with DTO to kafka, for future processing.
*
* @param likes DTO with information about likes to be added.
*/
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void saveMessageToHistory(Likes likes, String status) {
try {
historyRepository.save(HistoryEntity.builder()
.talkName(likes.getTalkName())
.likes(likes.getLikes())
.status(status)
.build());
} catch (RuntimeException ex) {
log.warn("Failed to save message to history.", ex);
}
}
}Перезапускаем наш тест с двумя попытками повтора. Интересно, что в истории записалось больше 2000 событий, а лайков при этом меньше:

Все дело в retry — повторная попытка захватывает не только событие, но и сохранение истории. Она будет перезаписана, потому что идемпотентность тут не предусмотрена.
Что мы можем сделать? Создадим метод @Recover, который будет вызываться в случае падения, и в нем не будет записываться история.
@Recover
public void addLikesToSpeakerRecover(Exception ex, Likes likes) {
if (likes.getTalkName() != null) {
speakersRepository.findByTalkName(likes.getTalkName()).ifPresentOrElse(speaker -> {
log.info("Adding {} likes to {}", likes.getLikes(), speaker.getFirstName() + " " + speaker.getLastName());
speaker.setLikes(speaker.getLikes() + likes.getLikes());
}, () -> {
log.warn("Speaker with talk {} not found", likes.getTalkName());
saveMessageToHistory(likes, "ORPHANED");
});
} else {
log.error("Error during adding likes, no IDs given");
saveMessageToHistory(likes, "CORRUPTED");
throw new SQLException()
}
}Если вы смотрели запись доклада, то заметили, что в данном месте я допустил ошибку, из-за которой Recover метод не работал. Дело в том, что в докладе я использовал в аргументе RuntimeException, коим получаемый нами SQLException не является, так как расширяет только базовый класс Exception.
Блокировки
Еще один вариант разрулить транзакции — это блокировки. Существует оптимистическая и пессимистическая блокировка.
Оптимистическая блокировка
Эта блокировка работает на уровне приложения, а не базы данных. В Spring она реализуется легко, с помощью @Version над полем entity. Результат сохраняется как @Version, и с его учетом идет апдейт. Если result set = 0 и нет подходящей записи в базе данных, мы получаем exception.

Здесь нам даже не нужны транзакции, всю эту логику мы можем убрать. Но при этом нужно настроить retry: поставим max attempts = 10. Теперь выберем подходящее поле для аннотации. Идеальный кандидат — поле @UpdateTimestamp. При каждом сохранении оно будет обновляться, и проблем быть не должно.
@Version
@UpdateTimestamp
@Column(nullable = false)
private LocalDateTime updated;Запустим снова наш тест:

События приходят, а лайки не добавляются. Это происходит, потому что мы убрали save и транзакцию. Соответственно, save() надо вернуть. Учтите это, если занимаетесь рефакторингом подобного сервиса. В случае с оптимистическими блокировками и Retry мы снова должны подбирать количество попыток в зависимости от уровня конкуренции. Чем он выше, темы выше вероятность ошибок и, соответственно, больше повторов потребуется для обработки всех данных. Ниже мы рассмотрим варианты оптимизации с целью уменьшения конкуренции.
Пессимистическая блокировка
Эта блокировка работает на уровне базы данных, через блокировку строки. Запросы выглядит следующим образом:

Попробуем это реализовать в Spring. Нам потребуется аннотация @Lock.
@Lock(LockModeType.PESSIMISTIC_WRITE)
Optional<SpeakerEntity> findByTalkName(String talkName);Для теста попробуем бросить одно сообщение. Сразу получим исключение: «No transaction in progress». Ведь ранее мы убрали транзакции из кода. Обычно разработчики сразу идут с этим в гугл и попадают на Stack Overflow, где рекомендуют установить @Transactional на репозиторный метод.

У ответа рейтинг 200, давайте попробуем.
@Transactional
@Lock(LockModeType.PESSIMISTIC_WRITE)
Optional<SpeakerEntity> findByTalkName(String talkName);В нашем случае тесты работают, исключений нет, но лайки неправильно обновляются, опять имеем недосчет.

Транзакция коммитится на выходе из связанного метода — в нашем случае findByTalkName:
@Transactional
@Lock(LockModeType.PESSIMISTIC_WRITE)
Optional<SpeakerEntity> findByTalkName(String talkName);Вся транзакция, соответственно, закоммитится на выходе из него и отпустит @Lock. Проблема не решена, но 200 баллов на StackOverflow есть :)

На самом деле, завершать транзакцию нужно позже, после апдейта, и @Transactional должен висеть в другом месте. Здесь мы коммитим транзакцию на выходе из метода addLikesToSpeaker:
@Transactional
public void addLikesToSpeaker(Likes likes) {
if (likes.getTalkName() != null) {
speakersRepository.findByTalkName(likes.getTalkName()).ifPresentOrElse(speaker -> {
saveMessageToHistory(likes, "RECEIVED");
log.info("Adding {} likes to {}", likes.getLikes(), speaker.getFirstName() + " " + speaker.getLastName());
speaker.setLikes(speaker.getLikes() + likes.getLikes());
}, () -> {
log.warn("Speaker with talk {} not found", likes.getTalkName());
saveMessageToHistory(likes, "ORPHANED");
});
} else {
log.error("Error during adding likes, no IDs given");
saveMessageToHistory(likes, "CORRUPTED");
}
}При использовании блокировок стоит переключиться на уровень изоляции Read Committed. А то при Serializable, например, блокировки корректно не сработают.

Отлично, 2000 сообщений и лайков!
Производительность всех рассмотренных решений можно сравнить по графику ниже. Вы также можете попробовать сами развернув у себя проект и попробовать другие решения.

Видим, что пессимистическая блокировка сработала быстрее всех, за счет устранения конкуренции между блокировками. Недостаток в том, что она больше остальных нагружает процессор из-за создания длинной очереди. Но если все запросы перевести в Kafka, то аномальной нагрузки не возникнет. До поры до времени – клиентская база то растет :)
Теперь представим, что другая команда решила добавить при сохранении сообщений проверку на наличие пользователя в БД и переиспользовала наш запрос с пессимистической блокировкой:
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void saveMessageToHistory(Likes likes, String status) {
try {
speakersRepository.findByTalkName(likes.getTalkName()).ifPresent((x) -> {
historyRepository.save(HistoryEntity.builder()
.talkName(likes.getTalkName())
.likes(likes.getLikes())
.status(status)
.build());
});
} catch (RuntimeException ex) {
log.warn("Failed to save message to history.", ex);
}
}Что же здесь страшного? Все работает, пока все подключения в БД не кончатся :P У нас тут дедлок. А возник он как раз из-за того, что, используя Propagation.REQUIRES_NEW, мы останавливаем текущую транзакцию, не снимая блокировку, и пытаемся еще раз из новой транзакции эту блокировку установить. И ждем, ждем...
В этом главная опасность пессимистических блокировок: они могут породить дедлоки. Серебряной пули здесь тоже нет, учитывайте это в собственных задачах.
Timeout против дедлоков
Разорвать дедлок можно с помощью такого замечательного свойства, как timeout:

Что нужно знать о таймаутах:
Таймаут, объявленный в транзакции, распространяется только на запросы в БД и пропагируется в виде @QueryHint(javax.persistence.timeout) только на запросы внутри текущей транзакции. То есть таймаут, установленный на транзакции, никогда не выбросит вас из метода, если вы не обращаетесь с запросом в БД.
В момент вызова транзакционного метода фиксируется дедлайн.
В запросы попадет не весь указанный таймаут, а дельта, оставшаяся до дедлайна.
Таймаут не пропагируется на новые созданные транзакции, также не будет выброшено исключения из suspended транзакции.
В случае срабатывания таймаута будет выброшено исключение и должен быть произведен откат транзакции.
Как выглядят возможные исключения:
org.springframework.transaction.TransactionTimedOutException: Transaction timed out: deadline was Sat Jun 11 00:53:14 MSK 2022 — запрос был запущен, когда дедлайн уже наступил.
org.hibernate.TransactionException: transaction timeout expired (org.springframework.orm.jpa.JpaSystemException: transaction timeout expired) — Hibernate попытался закоммитить транзакцию, а дедлайн уже настал.
org.springframework.dao.QueryTimeoutException: could not extract ResultSet; root cause: org.postgresql.util.PSQLException: ERROR: canceling statement due to user request — если время выполнения запроса превысило таймаут.
Какие еще проблемы решает @Transactional
Представим, что мы получили сообщение из Kafka, обработали его и должны закоммитить. Проходит обработка в рамках транзакции, данные появляются, и вы должны закоммитить offset.

Но случается ООМ. Что делаем дальше, коммит или роллбэк? Наверно, роллбэк. Сообщение снова появится в лаге топика. Идемпотентную обработку в нашем примере с ходу прикрутить не получится, так как сообщения не имеют никаких уникальных идентификаторов. Однако мы можем передвинуть транзакцию на более низкий уровень, и если исключение возникнет в момент сдвига оффсета, менеджер транзакции это увидит и откатит её. Количество попыток для consumer (BackOff) тоже нужно при этом настроить.
В коде это реализуется несложно. Если у нас есть Consumer, мы просто аннотируем метод accept() @Transactional:
public class LikesConsumer implements Consumer<List<Likes>> {
private final SpeakerMessageProcessor messageProcessor;
@Override
@Transactional
public void accept(List<Likes> likes) {
log.warn("Message received {}", likes);
messageProcessor.processBatchOfMessages(likes);
}Если используете подход через StreamConfing и определяете Bean Consumer, то достаточно аннотировать его, и все методы в нем станут транзакционными.
public class StreamsConfig {
private final SpeakerMessageProcessor messageProcessor;
@Transactional
@Bean
Consumer<Likes> likesConsumer() {
return (value) -> {
log.info("Consumer Received : " + value);
messageProcessor.processOneMessage(value);
};
}
}Накладные расходы при использовании @Transactional
Что происходит, когда мы запускаем метод, помеченный @Transactional? Сначала JPATransactionManager оборачивает наш метод, затем он запускает логику, коммитит ее или в случае возникновения исключения откатывает.
speakerService.addLikesToSpeaker(likes);
private final JPATransactionManager transactionManager;
try {
// begin a new transaction if expected
// (depending on the current transaction context and/or propagation mode setting)
transactionManager.begin(..);
addLikesToSpeaker(likes) // the method invocation, EntityManager works.
transactionManager.commit(..);
} catch(Exception e) {
transactionManager.rollback(..); // initiate rollback if code fails
throw e;Возьмем простой transactional метод, который выводит два сообщения в лог и даже в БД не идет:
@GetMapping("/test")
@Transactional
public ResponseEntity<String> testTransaction() throws InterruptedException {
log.warn("Thread {} started", Thread.currentThread().getId());
log.warn("Thread {} finished the work", Thread.currentThread().getId());
return new ResponseEntity<>("Test passed!", HttpStatus.OK);
}
}Запустим и посмотрим логи:

Как видим, даже на таком простом методе создаются некоторые микрозадержки. В больших масштабах это может создать оверхэд. Поэтому всегда стоит задумываться, а нужна ли вам транзакция в конкретном месте.
Но самое страшное, на самом деле, не здесь. Давайте в конфиге уменьшим maximum pool size до 1, а таймаут до 5, установим sleep на 8 секунд и запустим программу:
@GetMapping("/test")
@Transactional
public ResponseEntity<String> testTransaction() throws InterruptedException {
log.warn("Thread {} started", Thread.currentThread().getId());
Thread.sleep(millis:8000);
log.warn("Thread {} finished the work", Thread.currentThread().getId());
return new ResponseEntity<>("Test passed!", HttpStatus.OK);
}В итоге у нас один тред запустился, а второй уже упал с ошибкой:

Кто же забрал connection, если мы даже не ходили в БД? При создании транзакции из hikari pool всегда забирается одно соединение, чтобы проставить auto-commit = false. Ведь решение о коммите фактически будет приниматься в менеджере транзакции. При большой конкурентности нехватка соединений может стать проблемой. Исправить это можно, отключив auto-commit вручную.

В завершение добавлю пару советов, как сократить накладные расходы при использовании @Transactional:
Не стоит ставить @Transactional там, где будет происходить обработка только на сервисном уровне.
Запуск метода, помеченного @Transactional, при определенных условиях может взять соединение из пула соединений с БД и не отпускать его до выхода из метода.
Используйте propagation = NEVER там, где не хотите допустить использование транзакции (например, при параллельной разработке).
Разносите логику работы с БД и внутреннюю логику сервиса по разным методам/сервисам, особенно походы во внешние системы или длительные вычислительные операции.
Оптимизация при процессинге
Когда вы получаете много сообщений и в итоге запускаете много транзакций, легко можете получить большой оверхэд на БД.

Например, для нашего сервиса можно написать следующий метод агрегации пришедших сообщений, объединяющий их по названию доклада.
public void processBatchOfMessages(List<Likes> likes) {
var accumulatedLikes = likes.stream()
.filter(Objects::nonNull)
.filter(x -> x.getTalkName() != null)
.filter(x -> !x.getTalkName().isEmpty())
.collect(Collectors.groupingBy(Likes::getTalkName))
.values().stream()
.map(likesListTalkName -> likesListTalkName.stream().reduce(new Likes(), (x, y) -> Likes.builder()
.talkName(y.getTalkName())
.likes(x.getLikes() + y.getLikes())
.build()))
.collect(Collectors.toList());
log.info("Aggregated Likes: {}", accumulatedLikes);
try {
var futures = accumulatedLikes.stream()
.map(like -> CompletableFuture.runAsync(() -> speakerService.addLikesToSpeaker(like)))
.toArray(CompletableFuture[]::new);
CompletableFuture.allOf(futures).join();
} catch (CompletionException ex) {
log.error("Something went wrong during batch processing.:", ex);
}
}Это сильно ускоряет работу. Такой метод можно запустить в несколько потоков; например, по трем пользователям параллельно. @Transactional позволяет сохранить эти операции внутри метода.
Решение без блокировок / ретраев и тюнинга изоляции.
А есть ли решение без блокировок и прочей суеты с изоляцией транзакции? Решение есть всегда, и здесь одним из них является распределение сообщений о событиях в партициях кафки при помощи ключей. Kafka message keys.

Сообщения с одинаковыми ключами всегда будут попадать в одну и ту же партицию топика, а значит, читать эти сообщения будет только один-единственный Consumer. И если ключ будет соответствовать пользователю, то мы будем иметь гарантию, что по одному пользователю параллельно не будет вычитано более одного сообщения. А значит, конкурентность отсутствует, и транзакции или блокировки могут быть вовсе не нужны.
При получении сообщений из разных источников имеет смысл перекладывать все полученные сообщения в некоторый буферный топик, добавляя к каждому сообщению ключ, и затем вычитывать их из этого топика, правильно настроив BackOffPolicy. В таком случае вы на уровне сервиса избавляетесь от конкурентности и гарантируете обработку всех сообщений. Главный нюанс такого подхода — асинхронная обработка: если внешняя система требует от вас произвести процессинг сообщения в реальном времени, то такой подход вам может не подойти.
Выводы
Для грамотного управления транзакциями необходимо:
определиться, нужны ли вам транзакции и/или блокировки в коде, возможно ли избавиться от конкуренции на этапе получения сообщений.
правильно расставить в коде аннотацию @Transactional только там, где это необходимо;
выбрать уровень изоляции, на котором вы будете работать с БД внутри одного проекта;
разобраться, где нужна новая транзакция, а когда следует продолжать текущую;
определиться с использованием блокировок и их типом, предусмотреть дедлоки;
предусмотреть таймауты транзакций;
оптимизировать код с целью уменьшения количества вызовов транзакционных методов и запросов в БД;
предусмотреть идемпотентную обработку данных при повторах.
Еще раз привожу ссылку на проект GitHub. В ветке afterTalk содержатся все изменения, написанные в liveTime.
Комментарии (7)

GerrAlt
23.12.2022 22:46+4Я что-то не понял, или проблему с лайками можно было починить просто написав вызов sql запроса навроде
UPDATE speakers SET likes = likes + <сколько_добавить> WHERE id = <кому>?

funca
24.12.2022 00:17-1Это старая тема для отдельного доклада, поставил лайк). Здесь результат будет зависеть от уровня изоляции транзакций, с рисками поймать dead lock при конкурентных апдейтах одной и той же строки. Подробнее, например, тут https://blog.pjam.me/posts/atomic-operations-in-sql/ .
Вообще мне показалось, что предложенное в статье решение это вариация на те же самые грабли, просто хорошо закопанные в Java. Но мне понравился сам подход автора, с проверками каждой своей гипотезы на стенде. Я чаще вижу когда начинающие разработчики удовлетворяются только мысленными экспериментами и собиранием потом граблей в продакшене.

oxff
24.12.2022 06:49В данном случае и пессимистическая блокировка на уровне строки (SELECT ... FOR UPDATE) не всегда помогает, если нужно обновлять несколько строк в одной транзакции. Нужно чётко следить за порядком строк, чтоб не нарваться на deadlock.
Надёжнее вынести код в хранимую процедуру PL/pgSQL и использовать блокировку критической секции кода при помощи pg_advisory_xact_lock() и т.п. Это как synchronized только в Postgres. В итоге имеем простейшую хранимку в пару строчек и транзакционную @Procedure в Repository спринга.

Kazzman
24.12.2022 11:29А что на счет application (advisory) lock в бд?
И на сколько часто случается, что по одному клиенту приходит столько сообщений, что происходит гонка?

hyragano
25.12.2022 14:32Спасибо за статью. С точки зрения рассмотрения нюансов решения проблем в конкурентной обработки и использования транзакций - отлично, но с точки зрения проблемы вопрос: почему не рассматривали что-то а-ля CQRS или labmda подхода?
maxzh83
Пока читал до этого раздела, думал о том, нафига вообще все это нужно (транзакции, блокировки и т.д.). Ощущение было, что сами себе придумали трудности и сами героически их решили. В kafka ключи и группы потребителей не просто так придумали, они ровно для этого.
Понятно, что статья прежде всего обучающая, но, возможно, стоит сразу написать про этот способ. Горячие головы, не дочитав, могут погибнуть в неравном бою с блокировками.
Ildar92
Тоже шел писать про это. Самой проблемы в целом не существует, если знать об этой особенности Кафки. Особенно, если учесть, что это базовые знания для Кафки.
Но в целом да. Многие не умеют пользоваться Propagation и Isolation level-ами должным образом