

Предыстория
Все началось с того, что мне стало трудно находить нужную информацию, файлы. Чем больше файлов и папок у меня образовывалось, тем больше времени уходило на поиски нужного. Я понял, что каждый раз искать в бесконечных списках файлов и папок, особенно с условием вложенности это не вариант для больших объемов данных.
Что касается поиска по названию файла, то количество символов, указанных в названии ограниченно и слова при поиске должны быть в строго определенной последовательности. Тем более, если система индексирует другие, не нужные для поиска файла (системные файлы, файлы проектов), то поиск выдает много "мусора".
Поиск по содержанию файла даёт не самый релевантный результат. Может выдать бесполезные результаты с содержанием содержащие ключевые слова, но не относящиеся к тому, что действительно необходимо найти.
Более того по содержанию можно искать только текстовые файлы.
Структура содержания информации
Структура папок представляется собой в виде дерева. Мне это не нравится, потому что каждая папка может содержать только определенные файлы, если не учитывать копирование и ссылки.
Так же это можно представить с примером из реальной жизни, для того, чтобы найти зелёное свежее яблоко сорт "Девственный". Необходимо найти отдел с фруктами, затем отдел с яблоками, затем ищем зеленные, затем сорт, ну там ещё их на свежие, не свежие фасуют в этом воображаемом примере и наконец найти нужное apple.
Усложняется ещё все и тем, что я не помню есть ли там вообще яблоки, и если есть, то хранятся ли они в отделе фрукты.
А почему бы об этом просто не попросить прихвостня(они уже у всех есть, правда?) - «Принеси мне зелёное свежее яблоко».
Как сразу становится удобно!
В общем, всем этим я хочу сказать, что поиск нужной информации в папках хорош, если папок немного и если помнить какие папки существуют, а не перебирать все подряд.
А вот если мы не знаем существуют ли яблоки вообще, то спрашиваем прихвостня:
- Яблоки есть?
- Есть, господин! Сотни, игрушечные, красные, гнилые....
- Мне нужно свежее яблоко.
- Понял! Есть красное свежее яблоко "Сирота", красное свежее яблоко "Курага",....
- А что насчёт зелёного свежего яблока.
- Есть! Зелёное свежее яблоко "Пух-тибидух" и Зелёное свежее яблоко "Девственный".
- В таком случае, принеси мне, пожалуй, Зелёное свежее яблоко "Девственный".
- Да, сэр.
Вот последняя фраза как раз таки и стала названием приложения. Как ответ на команду пользователя - "Yes Sir".
Возвращаясь к яблокам. Заметили, что в первом случае нужно искать яблоки не пойми где, а во втором мы задаём уточняющие условия к запросу?
 приходится обходить все узлы. А в случае графа(теги) можно получить результат, в лучше случае за проход по единственному узлу.")
Приведу пример более реалистичный. Есть папка с музыкой и подпапки для разделения на жанры. Но что если в какой-то момент мне захочется послушать французскую музыку не зависимо от жанра. Вот тут то и вся проблемность древовидной структуры папок вылазит. Можно конечно, как советовали на форумах, создавать отдельные папки под язык произведения и кидать ссылки, но опять папки...
А вот, что произойдет, если каждому файлу установить теги с жанром, языком, ну и конечно что это музыка, песня.
В этом случае возможно группировать, сортировать музыку гораздо гибче. Например, скомбинировав 3 тега: французская, русская, рок можно получить то, чего стандартными средствами Windows не возможно, ну или я чего-то не знаю.
Попытки найти готовое решение
Первой идеей было воспользоваться "тегированием" файлов, папок. Таким образом можно искать информацию комбинируя теги, не зависимо от порядка слов. И лучшими приложениями для этого, могу выделить XYplorer и Tagging for windows. Первая из себя представляет отдельный файловый менеджер с опцией тегирования. Второе приложение - дополнение к стандартному файловому менеджеру. Однако они позволяют искать файлы только на ПК и конечно нельзя написать как в Гугл поисковике запрос близкий к пользователю, а алгоритм уже бы сам выбрал из запроса теги и отсортировал информацию по приоритету. В последствии удалил обе, они подвисали и крашились частенько (возможно дело в моих надстройках Windows, не хочу делать анти пиар этих отличных программ).
Визуальный поиск
В попытках найти оптимальный способ поиска доходило до странного. Я больше визуал и поэтому загружал изображения более менее подходящее по теме информации в социальную сеть ВКонтакте, а саму информацию сохранял в комментариях под изображениями. Это дало некоторый прирост в скорости поиска и пользоваться можно с любого устройства. Но как вы, наверное, понимаете долго это продолжаться не могло. В конечном итоге я стал задумываться а к какой информации относится это изображение, на котором рельсы - означает адреса знакомых или желаемые места для путешествия... Ну а уж то, что под одним изображением образуется портянка из информации без возможности вложенности - это фиаско, бро.
Желаемый функционал
Я подумал, что было бы отлично разработать приложение, которое бы подходило по таким критериям:
Можно использовать с любого устройства без возможности подключения к интернету.
Поиск личной информации настолько быстро, насколько это возможно.
Поиск должен быть простым как Google Search.
Возможность сохранить всю текстовую информацию в текстовый файл.
Выбор технологий
1. По первому пункту из желаний было решено разработать веб приложение, так как с любого устройства, на котором есть браузер, можно получить к нему доступ. Данные хранятся в localstorage браузера, но при открытии сайта сразу выгружаются в переменную для обеспечения лучшей скорости.
Для синхронизации данных с другим устройством, браузером я взял базу данных mysql от 000webhost бесплатно, но потом перестал использовать из-за ограничений на объем. Сейчас единственный способ для обновления пользовательских данных - импорт и экспорт файла. Однако я делаю это очень редко, т.к. в основном пользуюсь только со смартфона. Что касается офлайн режима - я использовал serviceworking. Необходимо только один раз зайти на сайт, чтобы все ресурсы сайта загрузились и дальше использовать полностью офлайн из браузера.
2. Быстрый поиск.
Раз поиск должен осуществляться подобно Гугл поисковику, то нужно чтобы каждое слово из запроса проверять на существующий из уже созданного блока информации. Таким блоком у меня выступает объект с ключами: уникальное название блока, действие(показать информацию, открыть ссылку...), содержимое, теги.
Итак, по ключу "теги" у нас будет храниться массив из символов(слов) для конкретного блока информации.
Сразу возьмём пример блока.
Название: как создать сайт.
Действие: показать информацию.
Содержимое: берём html, добавляем js и украшаем css.
Теги: создание сайта, веб программирование, верстка.
Массив из тегов формируется из текстов полученных с полей ввода для тегов и названия. Каждое слово это тег, разделять можно запятой и пробелом. Была идея конечно сделать как на Ютубе, теги как словосочетания, но я решил остановиться на более широкой выдаче по ключевым словам. Из примера блока выше массив тегов будет таким: ["как", "создать", "сайт", "создание", "сайта", "веб", "программирование", "верстка"].
Теперь самое важное - определиться как будет происходить поиск. Первое, что пришло в голову это брать каждое слово из поискового запроса и сравнивать с каждым словом из тега каждого блока. В голову как пришло, так и ушло, это отвратительная идея. Следующей идеей было создание объекта, в котором каждый тег это отдельный ключ, а значение это массив из индексов блоков.
3. Итак, при вводе запроса проверяется есть ли слово в хранилище тегов, если да, то блок добавляется в массив на отображение.Теперь нужно отсортировать по приоритету. Чем выше результат в выдаче, тем более он подходит запросу. Это я реализовал с помощью количества ключевых слов в запросе, чем больше слов из запроса содержится в массиве тегов блока, тем более блок приоритетнее.
4. И насчёт сохранение в файл совсем кратко. Можно сохранять и импортировать файл в виде json.Так же мой опыт с использованием ВКонтакте как поисковик по изображениям дал мне идею для возможности добавлять изображение к каждому блоку при желании.
Итоги
В результате я сделал то, чем пользуюсь уже больше года. Как веб, так и ПК версия оказались очень полезными. Использую для работы и личной жизни. Скорость поиска, которую я в итоге получил меня многократно выручала, когда нужно было найти что-то очень быстро.
Ответвление в другие проекты
Веб приложение мне настолько понравилось, что я захотел написать программу для исполнения программ по команде от запроса пользователя на ПК. Вдохновлённый голосовыми помощниками, я создал программу, которая ищет и исполняет файлы. А поиск соответственно так же подобен веб поисковику. Особенность в том, что можно перетащить файл/файлы напрямую в программу и алгоритм автоматически установит теги исходя из названия файла и папок, в которых он содержится. Но это тема другого поста, если этот окажется интересным.
Послесловие
Буду рад любым комментариям. Узнать ваше мнение по поводу идеи. Полная ли это ерунда. Или, в чем я почти не сомневаюсь, есть уже приложения с подобной реализацией.
Спасибо!
Ссылка на проект: https://eugeniouglov.000webhostapp.com/yessir/#main
Комментарии (26)



Urub
26.12.2022 16:09Интересно, какая личная информация может занимать столько места ?

eugeniouglov Автор
27.12.2022 13:56????
Urub
27.12.2022 15:51если мы отбросим фото, аудио и видео (по которым поиска нет), то что остается ?
например у меня нет такого объема личной инфы, чтобы по ней делать поиск )eugeniouglov Автор
28.12.2022 11:35Если файлы легче найти без поиска, то действительно в этом нет необходимости. В моем случае файлов было настолько много, что сортировать по папкам уже не имело смысла. А что касается поиска, то мне легче вбить запрос на поиск как в Гугл и ловить наиболее подходящие результаты в первом наборе выдачи
Urub
28.12.2022 12:04вот я и спрашивал, а что это за информация такая, которой так много ?
не могу представить, у меня, например, такой нет )eugeniouglov Автор
28.12.2022 17:41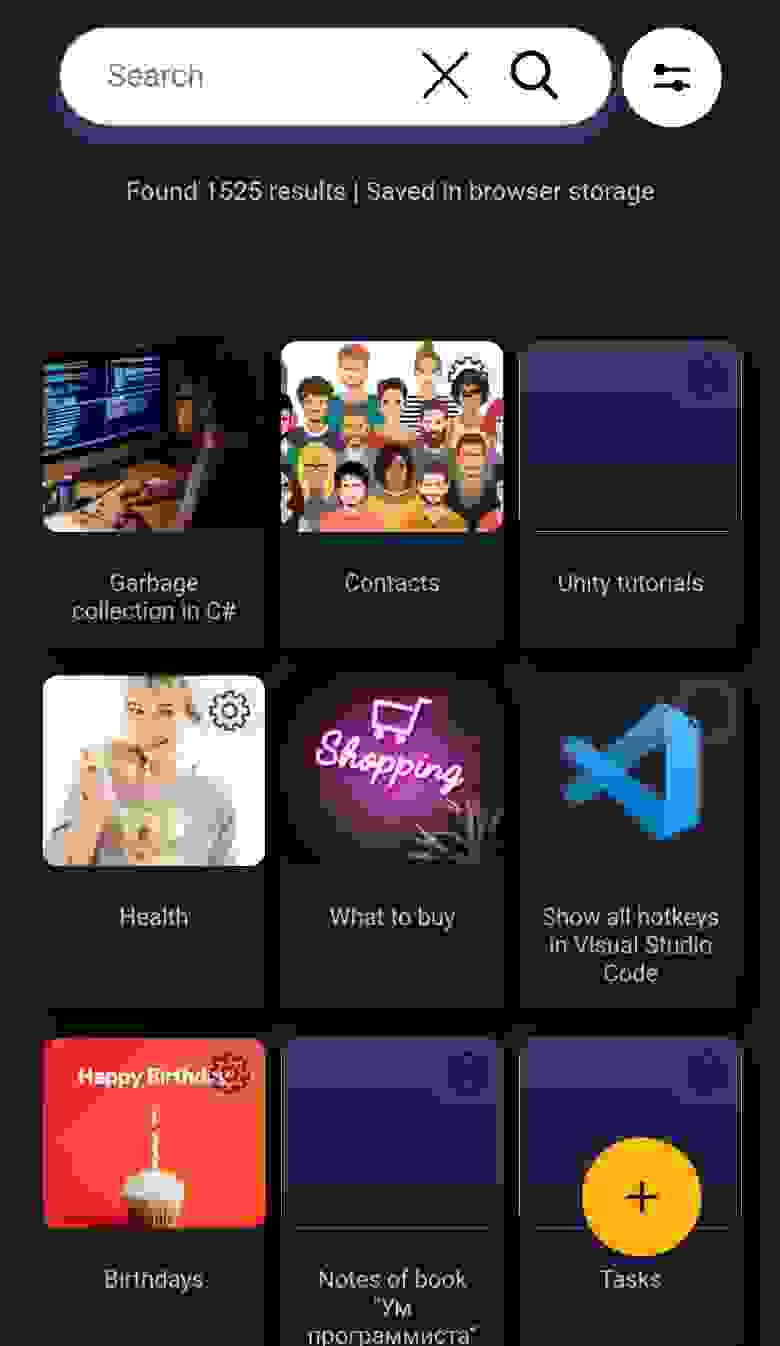
Любая заметка, туториал у меня отправляется в это приложение. Надеюсь - мозг не пострадает от такой откровенной лени)


Gar02b
26.12.2022 17:50+1Архивариус 3000. Десктопное приложение, индексирующее, по-моему, вообще всё. Веб-морда тоже есть.
Один недостаток: он только виндовый, а под Linux работает не очень, порой слетают индексы.

aleksey4uk
26.12.2022 17:51+1Однажды столкнулся с подобной проблемой, но только с важной информацией по linux, node и т.д. Принял решение, что проще создать собственный ресурс, где будет актуальная версия всем моих заметок и статей (Установки, настройки и т.п). Думаю с подобным рано или поздно сталкивается каждый программист. Сделал простой сайт на реакт, добавил туда ноду и postgres. На одном из популярном серверном хостинге купил не дорогой сервер и доменное имя. В итоге имею площадку для своих нужд, доступ ко всем актуальным статьям и платформу для каких-то pet проектов.

ivymike
27.12.2022 22:57На маке встроенный поиск вполне норм
eugeniouglov Автор
28.12.2022 11:47Видел поиск на маке действительно хорош и установить теги по дефолту можно.
Но есть ли там поиск как в Гугл, чтобы даже незнакомый с тегами пользователь мог бы вбить запрос и получить наиболее релевантный результат?
Например, по запросу: "Покажи адрес подруги".
Выдало бы: "Адрес дома Кати", "Адрес Маши", "Все адреса друзей",
а в последних рядах выдачи: "Адреса родственников" и тд.

Gryphon88
28.12.2022 12:02Можете еще раз пояснить, откуда берутся теги? Ручное тегирование, как в XYplorer, или как-то иначе?
eugeniouglov Автор
28.12.2022 17:24Да, ручное плюс автоматически из имени файла создаются. Где каждое слово это отдельный тег.
В ПК версии ещё плюс каждая папка в пути к файлу - тоже тег.
mcsimm
Был когда-то давно персональный поиск Яндекса, для поиска на компе, индексировал офисные форматы, музычку и т.д. Сейчас, вероятно, проект закрыт - не слышал давно про него.
KrivisKrivaitis
У Гугла то же был, пользовался обоими.
v1000
кстати да, глассная штука. в свое время позволила найти нужную информацию. вообще, это планировала сделать в свое время Майкрософт в новой версии файловой системы, если я не ошибаюсь.
Akr0n
Да, причем была довольно легковесная и приятная программа, без рекламы браузеров и т.п. вещей. Скорее всего, она и сейчас заведется и будет работать.
Fahrain
Не заведётся - и яндексовский и гугловский лезут домой за чем-то им нужным, а там давно уже ничего нет. Так что даже если найти старый дистрибутив - поиск не работает.
И на 2022 год мы имеем из локальных поисковиков только elastic search, который смогут завести не только лишь все...
Akr0n
Странно, мне помнится, что использовал ее чисто офлайн.
Fahrain
Ну я несколько лет назад пытался их запустить, когда МС окончательно поиск в проводнике доломало. Яндексовский - даже не устанавливается, гугловский - какие-то из версий всё-таки установить можно, но они не запускают индексацию вообще никак и, соответственно, тоже пользоваться нельзя.
Сейчас я вынужденно пользуюсь DocFetcher (Elastic search - это всё-таки немного перебор!) и это, по сути, единственный локальный поисковик по документам, который дожил до 2022 года. Больше ничего нет - все альтернативы умерли в районе 2010-2014 годов и больше не обновляются.
Akr0n
Архивариус 3000, я так понимаю, до сих пор работоспособен. Хотя и не обновляется с 2018 года.
Fahrain
Ну вот всё, что можно нагуглить - такое же: не обновляется кучу лет. При этом интерфейсы уже давно не соответствуют современности, часть форматов может не парсить из-за изменений в них, да и в целом все альтернативы локальным гугло/яндекс поисковикам (я ими пользовался в своё время) - редкостное неюзабельное нечто. Ну т.е. вроде как-то работает, но что качество поиска, что отображение результатов - ужас-ужас и пользоваться можно только от безысходности.
Spinoza0
Была ещё "ищейка" для компа, не помню автора