

Компьютерное зрение (computer vision, CV) — подраздел искусственного интеллекта, использующий алгоритмы машинного обучения и глубокого обучения для распознавания и интерпретации объектов на изображениях и видео. CV сосредоточено на воссоздании аспектов сложности зрительной системы человека, позволяя компьютерам определять и анализировать предметы на фотографиях и видео точно так же, как это делают люди.
За последние годы в области компьютерного зрения произошёл существенный прогресс, благодаря прорывам в искусственном интеллекте и инновациям в глубоком обучении и нейронных сетях компьютеры превзошли людей в различных задачах, связанных с распознаванием объектов. Одним из движущих факторов эволюции компьютерного зрения является объём генерируемых сегодня данных, которые применяются для обучения и совершенствования CV.
В этой статье мы сначала рассмотрим способы применения моделей компьютерного зрения в реальном мире, чтобы понять, почему нам нужно создавать более качественные модели. Затем мы перечислим шесть способов совершенствования моделей компьютерного зрения при помощи улучшения обработки данных. Но для начала давайте вкратце обсудим различия между моделями компьютерного зрения и машинного обучения.
Чем модели компьютерного зрения отличаются от моделей машинного обучения?
Машинное обучение — это методика, позволяющая компьютерам учиться анализу и реакциям на входные данные на основании прецедентов, созданных предыдущими действиями. Например, если мы берём абзац текста, чтобы научить алгоритм оценивать эмоциональный настрой автора, то эта задача относится к сфере машинного обучения. Входные данные в моделях машинного обучения могут принимать множество разных форм: текст, изображения и так далее.
Модели компьютерного зрения — это подмножество моделей машинного обучения, в них входными данными являются визуальные данные. Задача моделей компьютерного обучения — научить компьютеры распознавать паттерны в визуальных данных аналогично тому, как это делают люди. Например, алгоритм, использующий в качестве входных данных для предсказания результатов (скажем, классификатор кошек и собак) изображения и видео, является моделью компьютерного зрения.
Компьютерное зрение всё чаще применяется для автоматизированного контроля, удалённого мониторинга и автоматизации процессов или действий. Оно быстро нашло применение в различных отраслях и стало неотъемлемым компонентом технического прогресса и цифровой трансформации. Давайте вкратце рассмотрим несколько примеров того, как компьютерное зрение проделало свой путь в реальный мир.
Применение моделей компьютерного зрения в реальном времени
Компьютерное зрение оказывает огромное влияние на компании в различных отраслях: в здравоохранении, розничной торговле, безопасности, автомобилестроении, логистике, сельском хозяйстве и многих других. Давайте рассмотрим некоторые из них:
Здравоохранение
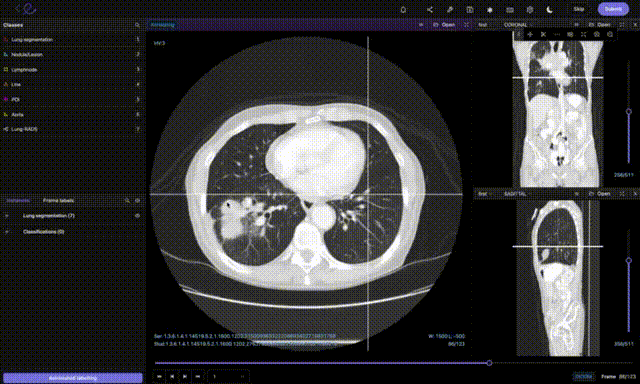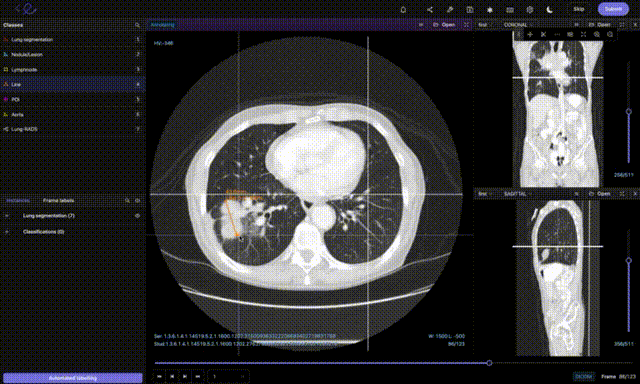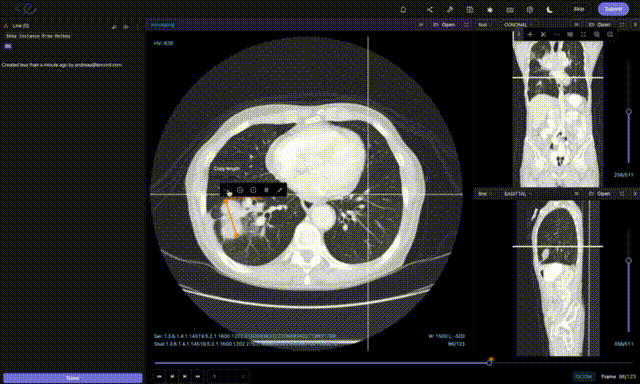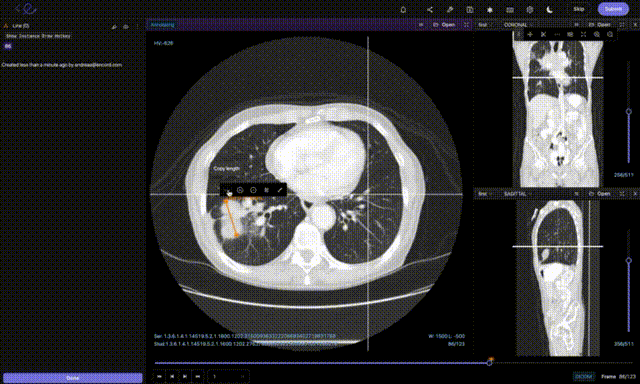
Одним из самых ценных источников информации являются данные медицинской визуализации. Однако с ними не всё так просто: без нужных технологий врачам приходится тратить часы на ручную проверку данных пациентов и выполнение административных задач. Благодаря недавним подвижкам в сфере компьютерного зрения отрасль здравоохранения для упрощения своей работы начала использовать решения для автоматизации. Медицинская визуализация сильно выиграла от классификации изображений и распознавания объектов, поскольку они позволяют врачам получить независимое мнение и помогают выявлять на изображениях вызывающие беспокойство аспекты. Например, при анализе снимков КТ (компьютерной томографии) и МРТ (магнитно-резонансной томографии).
Компьютерное зрение также играет важную роль в улучшении выздоровления пациентов, от построения моделей машинного обучения и проверки радиологических снимков с той же степенью точности, что и живые врачи (снижая при этом время выявления заболеваний) до создания алгоритмов глубокого обучения, повышающих разрешение снимков МРТ. Проводимый моделями анализ помогает врачам выявлять опухоли, внутренние кровотечения, закупоренные кровеносные сосуды и другие угрозы для жизни. Процесс автоматизации также повысил точность, поскольку машины теперь способны распознавать детали, невидимые человеческому глазу. Среди прочих примеров использования компьютерного зрения в здравоохранении — выявление рака, цифровая патологическая анатомия, анализ рентгеновских снимков и движений.
Автомобилестроение
Растущий спрос на перевозки ускорил технологический прогресс в автомобилестроении, в авангарде которого идёт компьютерное зрение. Интеллектуальные транспортные системы стали жизненно важной областью для повышения безопасности транспорта, эффективности парковки и потенциальных сфер применения беспилотного вождения.
Беспилотные автомобили являются очень сложными системами. однако благодаря компьютерному зрению инженеры способны быстро создавать, тестировать и повышать надёжность машин, делая свой вклад в прогресс в области распознавания и классификации объектов (например, дорожных знаков, пешеходов, светофоров и другого транспорта), предсказания движений и многих других.
В системах Parking Guidance and Information (PGI) компьютерное зрение уже широко используется для визуального распознавания занятости парковочных мест, потому что это более дешёвая альтернатива дорогим системам на основе датчиков, требующим периодического техобслуживания.
Модели компьютерного зрения полезны не только вне автомобилей, например, при парковке, анализе трафика и мониторинге состояния дорог, но и при мониторинге здоровья и внимания водителя, проверке состояния ремней безопасности и многом другом.
Производство
В производственной отрасли компьютерное зрение помогает в автоматизации контроля качества, снижении угроз безопасности и в повышении эффективности производства.
Одним из примеров является выявление дефектов. Ручное выявление дефектов в изделиях крупносерийного производства бывает не только затратным, но и неточным: точность в 100% гарантировать невозможно. Модели глубокого обучения могут использовать камеры для более эффективного анализа и выявления макро- и микродефектов на производственной линии в реальном времени.
Многие компании используют компьютерное зрение и для автоматизации сборочных линий. Модели машинного обучения можно использовать для управления работой роботов и людей, распознавания и отслеживания компонентов изделий и повышения стандартов упаковки.
Наряду с рассмотренными нами отраслями, компьютерное зрение применяется во множестве других сфер, особенно там, где данные изображений и видео можно использовать для автоматизации монотонных задач и повышения эффективности. Так как всё больше компаний начинает использовать искусственный интеллект, можно ожидать, что компьютерное зрение станет движущей силой для многих отраслей. Ниже мы расскажем о шести способах улучшения моделей и эффективного их создания, полезных для инженеров машинного обучения, дата-саентистов и команд, занимающихся разработкой компьютерного зрения.
Шесть способов улучшить модели компьютерного зрения
Создание решений, готовых к использованию в продакшене, может занять месяцы и даже годы.
Выбор массива данных — первый пункт для создания модели машинного обучения, а качество массива существенного влияет на результаты, которых сможет достичь модель. Именно поэтому если решение, над которым работала ваша команда, не выдаёт нужных результатов или вы хотите их улучшить, то вам первым делом стоит обратить внимание на массив данных.
Вот шесть способов улучшения работы с массивом данных и создания более качественных моделей компьютерного зрения:
- Создавайте массив данных с эффективной разметкой
- Выберите подходящий инструмент аннотирования
- Задействуйте конструирование признаков
- Применяйте выбор признаков или снижение размерности
- Будьте внимательны к отсутствующим данным
- Используйте конвейеры данных
1. Создавайте массив данных с эффективной разметкой
Данные — важный компонент, а результаты, которых можно ожидать от точности модели, сильно зависят от передаваемых ей данных. Существует соблазн сразу перейти к интересному этапу разработки проектов машинного обучения, но при этом вы перестанете контролировать установленные требования к аннотированию данных, стратегии создания массивов данных и так далее. Вы стремитесь сразу же увидеть результаты, однако пропуск первого шага обычно препятствует созданию надёжной модели, приводя к потере времени, энергии и ресурсов.
Чтобы у команды был качественный размеченный массив данных, необходимо эффективным образом разметить сырые курируемые данные. Массив данных должен содержать всю информацию, которая хотя бы отдалённо может быть полезной для проекта. Это гарантирует, что инженеры не будут ограничены в выборе и создании модели, поскольку чётко будет задан тип информации, присутствующей в обучающих данных. Чтобы иметь возможность сразу же приступить к работе, важно заранее определить аннотации, которые нужно извлекать. Это не только даст аннотаторам чёткие требования, но и гарантирует согласованность массива данных. Прочный фундамент проекта можно заложить, создав массив данных с эффективной разметкой.
2. Выберите подходящий инструмент аннотирования
При создании своего массива данных критически важно использовать подходящий инструмент аннотирования, а подходящим будет тот инструмент, функции которого соответствуют вашим задачам и целям. Например, если вы работаете с массивом данных изображений или видео, то вам нужно выбрать инструмент аннотирования, специализирующийся в обработке изображений или видео. Он должен иметь функции, позволяющие легко размечать данные, сохраняя качество массива данных.
Например, если возможности инструмента аннотирования видео оптимизированы для разметки видео, он позволяет пользователям загружать видео любой длины и в широком ассортименте форматов. В других инструментах аннотаторам видео сначала приходится сокращать видео, а иногда и переходить на другие платформы в зависимости от формата видео, которые им нужно аннотировать. Это пример того, что самое главное заключается в выборе подходящего под ваши задачи инструмента аннотирования.

Аналогично, пользователи, желающие аннотировать изображения, в подходящем инструменте могут выполнять потоковую передачу аннотаций непосредственно к загрузчикам данных: это повышает эффективность процесса аннотирования изображений, а также экономит много времени, которое пришлось бы потратить на не очень ценные части процесса разработки.
3. Задействуйте конструирование признаков
Признаки — фундаментальные элементы массивов данных. Модели компьютерного зрения используют для обучения признаки из массива данных, а качество признаков в массиве определяет качество результатов работы алгоритма машинного обучения.
Конструирование признаков — это процесс выбора, обработки и преобразования массива данных в признаки, которые можно использовать для создания алгоритмов машинного обучения, например, обучения с учителем. Это более широкое понятие, чем предварительная обработка данных, он включает в себя методики в диапазоне от простой очистки данных до преобразования данных с целью создания новых переменных и паттернов с признаками, которые раньше были невыявленными. При создании этих признаков цель заключается в подготовке входных данных массива, которые совместимы с алгоритмом машинного обучения.
Ниже приведён список нескольких распространённых методик разработки, которые вы можете использовать. Некоторые из приведённых стратегий могут быть более эффективными с отдельными моделями компьютерного зрения, а другие могут быть применимы во всех ситуациях:
- Imputation — это методика восстановления отсутствующих данных. Существует два типа imputation: числовое и категорическое.
- One-hot encoding — этот тип кодирования присваивает уникальное значение каждому возможному случаю.
- Log transform — используется для превращения асимметричного распределения в нормальное или менее асимметричное. Это преобразование применяется для обработки запутывающих данных, благодаря чему данные становятся более приближенными к обычному применению.
- Handling outliers (обработка выбросов): удаление, замена значений, ограничение, дискретизация — вот некоторые из методик работы с выбросами в массиве данных. Некоторые модели подвержены выбросам, поэтому обрабатывать их необходимо.
4. Применяйте выбор признаков или снижение размерности
Наличие слишком большого количества признаков, не влияющих на предсказательную силу модели, может привести к переобучению, слишком высоким вычислительным затратам и повышенной сложности модели. Такие признаки можно выявить, поскольку обычно они имеют низкую дисперсию или сильно коррелируют с другими признаками. Чтобы удалить из массива данных дублируемые переменные, можно использовать или выбор признаков (feature selection) или снижение размерности (dimensionality reduction) (при помощи Principal Component Analysis — PCA).
Процесс выбора признаков рекомендуется использовать, если у вас есть глубокое понимание каждого признака. Только в этом случае вы можете устранять признаки, воспользовавшись знанием предметной области или просто изучив, как и почему получается каждая переменная. После этого можно использовать другие методики, например, выбор признаков на основании модели. В частности, популярной методикой выбора признаков с обучением является критерий Фишера — он возвращает ранг переменных в порядке убывания. Затем переменные можно выбирать в зависимости от обстоятельств.
Альтернативной и одной из самых эффективных методик снижения количества признаков является снижение размерности при помощи PCA. Оно проецирует данные высокой размерности на меньшую размерность (меньшее количество признаков), сохраняя при этом максимальную часть исходной дисперсии. Вы можете указать количество признаков, которые нужно оставить, или задать величину дисперсии в процентах. PCA определяет минимальное количество признаков, которое можно учесть для переданной дисперсии. Эта методика имеет недостаток — требует множество математических вычислений, что усложняет её объяснимость, потому что после PCA вы не сможете интерпретировать признаки.
5. Будьте внимательны к отсутствующим данным
Если вы работаете с бенчмарковыми массивами данных, для учёта отсутствующих данных будет достаточно использовать простые методики imputation: так как это «самые лучшие» массивы данных, редко случается, что в них отсутствуют данные. Однако при работе с крупными или специализированными массивами данных необходимо осознать причину отсутствия данных, прежде чем применять методики их восполнения.
В целом существует три типа отсутствующих данных:
- Полностью отсутствующие случайным образом (Missing Completely at Random, MCAR) — MCAR подразумевает, что причина отсутствия данных не связана с ненаблюдаемыми данными, то есть вероятность отсутствия значения данных не зависит от любого наблюдения в массиве данных. В этом случае наблюдаемые значения и отсутствующие наблюдения генерируются из одного распределения. MCAR создаёт надёжные значения без перекосов. Она приводит к потере силы не из-за плохой структуры, а из-за отсутствия данных.
- Отсутствующие случайным образом (Missing at Random, MAR) — MAR более распространены, чем MCAR. В них, в отличие от MCAR, отсутствующие и наблюдаемые данные не получаются из того же распределения.
- Отсутствующие неслучайным образом (Missing Not at Random, MNAR) — анализ MNAR выполнять трудно, поскольку на распределение отсутствующих данных влияют и наблюдаемые, и ненаблюдаемые данные. В этой ситуации нет необходимости симуляции случайной части, её можно просто опустить.
6. Используйте конвейеры данных
Если вы хотите создать сложную модель компьютерного зрения или если сложен массив данных, то упрощение обработки данных при помощи конвейера данных может помочь в оптимизации процесса. Эти конвейеры данных обычно создаются при помощи SDK (Software Development Kit), позволяющих легко разрабатывать рабочий процесс конвейеров данных.
Конвейеры данных упрощают процесс аннотирования, валидации, обучения моделей и аудита, а также облегчают доступ к данным для команды. Это ускоряет процедуру обработки данных и делает сложные модели более объясняемыми, а также помогает в автоматизации любого этапа процесса. Например, функция автоматизации платформы позволяет управлять конвейерами данных, она работает как операционная система для массива данных, а её API собирают и упрощают конвейеры данных для команды, позволяя не только эффективно управлять данными и их качеством, но и масштабировать их. Существует множество платформ для создания конвейеров данных, поэтому очень важно тестировать эти функции и подбирать их под собственный процесс компьютерного зрения.
Кроме этого, существует множество других критериев, которые влияют на улучшение модели. Для улучшения алгоритмов и моделей требуется больше технических знаний, наблюдений и понимания потребностей бизнеса; поэтому хорошей опорной точкой является максимально эффективная работа с данными.
Вот ещё несколько методик улучшения моделей:
- Настройка гиперпараметров
- Собственная функция потерь (чтобы распределять приоритеты метрик в соответствии с потребностями бизнеса)
- Новые оптимизаторы (чтобы превзойти показатели стандартных оптимизаторов наподобие ReLu)
- Предварительно обученные модели
В представленном ниже разделе «Дополнительное чтение» есть ресурсы по этим методикам улучшения моделей. После того, как вы убедились, что данные соответствуют требованиям проекта и используемой модели, стоит подумать над более углублённым улучшением модели.
dimnsk
статья от капитана ?
кажется у вас есть опыт и вы можете писать не такие очевидные вещи ?