
Привет, Хабр! Это продолжение статьи о нашем опыте распознавания подписей. В ней мы рассказывали о первой итерации нашего алгоритма распознавания, полагающегося на поиск контуров прямоугольника, в котором должна была располагаться подпись. Запущенный на бою алгоритм успешно обрабатывал немногим меньше 80% документов. Однако мы на этом не остановились, так как одним из предъявляемых к нам требований была отметка в 95%.
Анализ проблемы
Для поиска проблем, из-за которых мы не смогли достичь нужного процента распознавания подписей, мы взяли несколько десятков боевых примеров документов. Внимательно просмотрев эти документы, мы пришли к выводу о том, что в большинстве случаев алгоритм отрабатывает не корректно из-за ложноположительных или ложноотрицательных срабатываний.
Ложноположительные срабатывания чаще всего происходили из-за лишних артефактов на скане документа. Например, помятой бумаги или пролитой жидкости в область подписи на документе.
Основными причинами ложноотрицательных срабатываний были:
плохое качество скана, из-за чего не удавалось схватить контуры прямоугольника для подписи
очень своеобразные подписи клиентов, из-за которых не удавалось отличить контуры прямоугольника от контуров подписи
Для решения первой проблемы мы пытались играть с параметрами размывания по Гауссу (усилили размытие) и поисков контуров по алгоритму Кэнни. И это даже сработало. Как правило, контуры различных артефактов были тонкие и нечеткие, поэтому после более сильного размытия алгоритм перестал на них натыкаться, и количество ложноположительных срабатываний резко упало. Но из-за такого подхода увеличилось число ложноотрицательных срабатываний. Это произошло, так как алгоритм из-за усиленного размытия начал распознавать контуры на меньшем количестве сканов документов разной степени качества. Решить эту проблему в рамках алгоритма распознавания по прямоугольнику нам не удалось, поэтому мы решили создать еще один и заставить их работать в связке.
Распознавание подписи по QR-коду
Когда мы искали, на чем базировать новый алгоритм, мы решили еще раз взглянуть на шаблон документа, с которым мы работаем.

Рассмотрев его по внимательнее, мы поняли, что помимо прямоугольника для подписи у нас есть еще два статичных объекта на документе, за которые мы можем зацепиться. Это лого нашей организации и QR-код. Оба этих объекта имеют фиксированный размер и место расположение относительно прямоугольника. Поэтому мы решили пойти по следующему маршруту: сначала сделать поиск лого компании и QR-кода, от которых уже можно найти и определить точные размеры и месторасположение прямоугольника для подписи. Начали мы с поиска прямоугольника относительно QR-кода. Для определения прямоугольника относительно QR-кода мы использовали заранее подготовленную маску. Наш новый алгоритм и маска выглядят следующим образом:
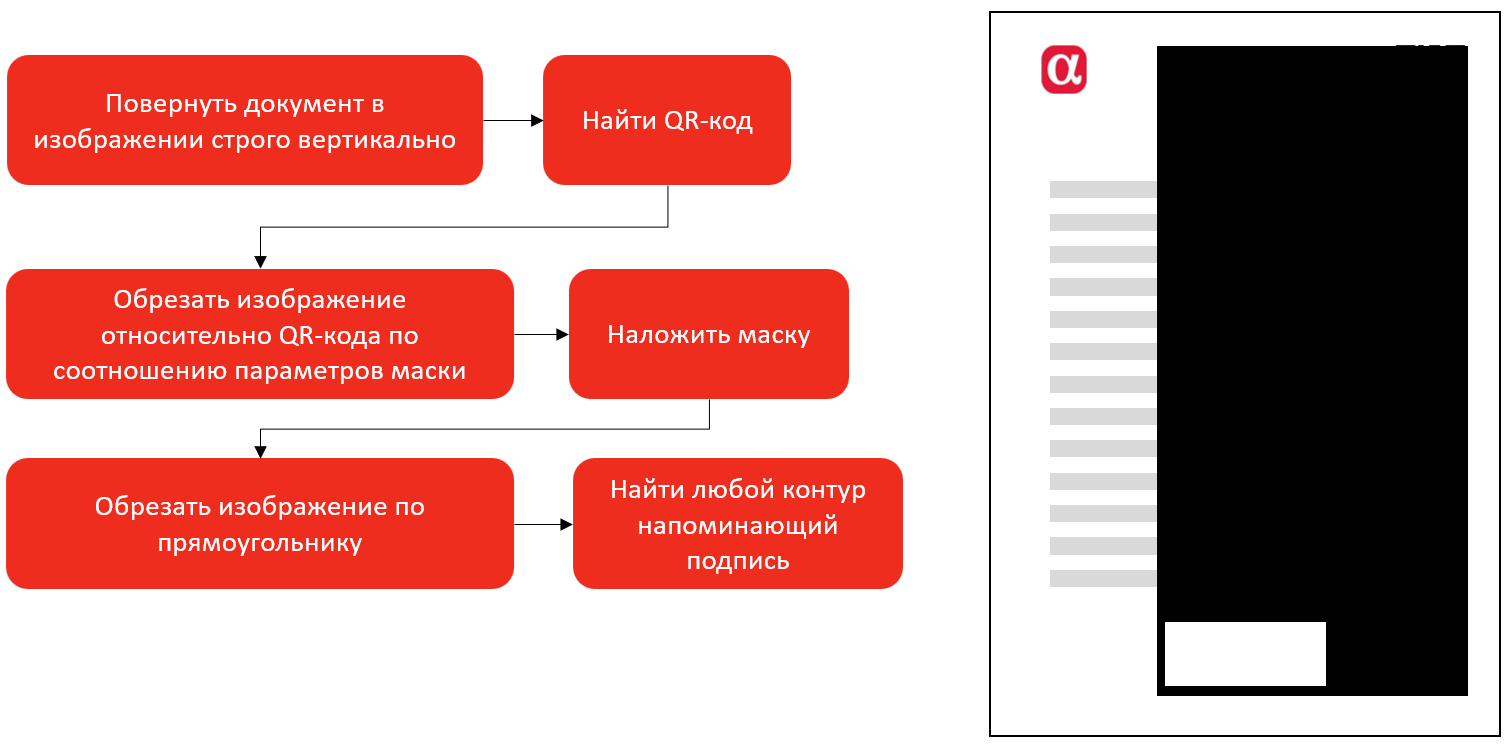
Маска представляет собой обычное черное изображение с абсолютно прозрачной областью, которая расположена в месте, где должен находиться прямоугольник для подписи.
Данный алгоритм начинал работать в случае, если алгоритму распознавания по прямоугольнику не удалось распознать наличие подписи на документе. Шаги «Повернуть документ в изображении строго вертикально», «Обрезать изображение по прямоугольнику» и «Найти любой контур, напоминающий подпись» в этой статье мы опустим, так как они описаны в первой части.
Найти QR-код
На этом шаге мы ищем QR-код на документе. Для этого мы используем ZXing.Net библиотеку.
/// <summary>
/// Возвращает данные о QR-коде
/// </summary>
/// <param name="inputUMat">Входное изображение</param>
/// <returns>Данные о QR-коде</returns>
public static Result GetQrCode(UMat inputUMat)
{
var cropRect = new Rectangle(0, 0, inputUMat.Size.Width, inputUMat.Size.Height / 3);
using (var crop = new UMat(inputUMat, cropRect))
{
using (Image image = RecognitionHelper.ConvertToImage(crop.Imencode()))
{
using (var bitmap = (Bitmap)image)
{
var reader = new BarcodeReader();
return reader.Decode(bitmap);
}
}
}
}
Как видно выше, перед поиском QR-кода мы сначала немного обрезаем изображение. Мы можем делать это так как нам точно известно, что QR-код расположен в верхней правой половине скана документа.
Обрезать изображение относительно QR-кода по соотношению параметров маски
Для корректного наложения маски на изображение, соотношение ширины и высоты маски должно быть таким же, как и у изображения. Данный шаг нужен для выделения части изображения, подходящего под соотношение сторон маски. Чтобы это было проще сделать мы подогнали размеры маски следующим образом:
ширина маски равна ширине QR-кода, умноженного на 3
высота маски равна высоте QR-кода, умноженного на 6
/// <summary>
/// Возвращает изображение, обрезанное для наложения маски
/// </summary>
public static UMat CropImageForMask(UMat inputUMat, Result qrCode)
{
Rectangle qrArea = qrCode.BoundingRectangle();
var resultRectangle = new Rectangle(
qrArea.X - qrArea.Width * 2,
qrArea.Y,
qrArea.Width * 3,
qrArea.Height * 6);
return new UMat(inputUMat, resultRectangle);
}
/// <summary>
/// Возвращает минимальный прямоугольник, охватывающий Barcode
/// </summary>
/// <param name="barcode">Barcode</param>
/// <returns>Минимальный прямоугольник, охватывающий Barcode</returns>
public static Rectangle BoundingRectangle(this Result barcode)
{
Rectangle rectangle = barcode.ResultPoints.BoundingRectangle();
if (barcode.BarcodeFormat != BarcodeFormat.QR_CODE)
return rectangle;
const double ratio = 1.15;
var qrCodeWidth = (int)Math.Round(rectangle.Width * ratio);
var qrCodeHeight = (int)Math.Round(rectangle.Height * ratio);
int qrCodeX = rectangle.X - (qrCodeWidth - rectangle.Width) / 2;
int qrCodeY = rectangle.Y - (qrCodeHeight - rectangle.Height) / 2;
return new Rectangle(qrCodeX, qrCodeY, qrCodeWidth, qrCodeHeight);
}
/// <summary>
/// Возвращает минимальный прямоугольник, охватывающий все точки <paramref name="points"/>
/// </summary>
/// <param name="points">Точки</param>
/// <returns>Минимальный прямоугольник, охватывающий все точки <paramref name="points"/></returns>
public static Rectangle BoundingRectangle(this IEnumerable<ResultPoint> points)
{
var maxX = float.MinValue;
var minX = float.MaxValue;
var maxY = float.MinValue;
var minY = float.MaxValue;
foreach (ResultPoint point in points)
{
if (maxX < point.X)
maxX = point.X;
if (minX > point.X)
minX = point.X;
if (maxY < point.Y)
maxY = point.Y;
if (minY > point.Y)
minY = point.Y;
}
var location = new Point((int)minX, (int)minY);
var size = new Size((int)(maxX - minX), (int)(maxY - minY));
return new Rectangle(location, size);
}
Наложить маску
На данном шаге мы накладываем заранее подготовленную маску сверху на изображение, полученную на предыдущем шаге. Это делается для того чтобы получить изображение, на котором не будет ничего кроме прямоугольника для подписи.
/// <summary>
/// Накладывает маску на изображение
/// </summary>
public static UMat ApplyMask(UMat imageForMask, UMat mask)
{
using (var resizeMask = new UMat())
{
mask.Resize(resizeMask, imageForMask.Size);
using (var grayMask = new UMat())
{
resizeMask.CvtColor(grayMask, ColorConversion.Bgr2Gray);
var result = new UMat();
imageForMask.BitwiseAnd(imageForMask, result, grayMask);
return result;
}
}
}
Ресурсы потребляемые алгоритмом распознавания по QR-коду
Разработка данного решения велась на компьютере со следующей конфигурацией:
CPU |
Intel(R) Core(TM) i7-6700 CPU @ 3.40GHz 3.40 GHz |
Видеоадаптер |
Intel(R) HD Graphics 530 |
Оперативная память |
16,0 ГБ |
Тип системы |
64-разрядная операционная система, процессор x64 |
Посмотрим на потребляемые ресурсы, используя изображение с указанными параметрами:
|
Ширина
|
1251 пикселей |
Высота |
1776 пикселей |
Горизонтальное разрешение |
150 точек на дюйм |
Вертикальное разрешение |
150 точек на дюйм |
Глубина цвета |
24 |
Размер |
306 КБ |
После однократного прогона такого изображения через алгоритм мы получаем такие результаты:

Как видно из рисунка, результаты прогона не слишком сильно отличаются от результатов в первой части статьи. Из значимых изменений – выросло потребление памяти. Это связанно с тем, что новый алгоритм имеет большее количество шагов, связанных с обработкой изображения, каждый из которых создает свое новое изображение как результат своей работы. А также он работает с маской, которая также является изображением и требует дополнительной памяти.
Теперь прогоним это же изображение, но уже 10 раз и посмотрим на результат:

Потребление памяти в сравнении с одиночным запуском выросло. Мы решили прогнать это изображение 100 раз, а затем 1000 раз и посмотреть на результат. Результаты отличались от представленных выше не более, чем на 1%, что можно считать допустимой погрешностью.
Результат алгоритма распознавания подписи по QR-коду
Вторая итерация функционала по распознаванию подписи включала два алгоритма «Распознавание подписи по прямоугольнику» и «Распознавание подписи по QR-коду». Так как это был наша 1-й подобный опыт в области распознавания, мы решили сохранять в БД каждый документ, с которым работал наш алгоритм со старта работы 1-й итерации. Отправив в бой новый алгоритм, мы также натравили его на исторические данные в БД. Из 80 тыс. исторических документов, алгоритм успешно отработал на чуть более чем 73.5 тыс. документов. Это около 92% документов.
Распознавание подписи по лого
Результаты второй итерации алгоритма распознавания все еще были не достаточными, так как на нужно было успешно отрабатывать на 95% сканов документов. Изучив документы, по котором алгоритм отработал не успешно, мы пришли к выводу, что основная проблема заключалась в недостаточно хорошем качестве QR-кода. Поэтому было принято решение еще улучшить алгоритм. Для улучшения мы решили дополнить решение алгоритмом распознавания по лого.

Как видно из рисунка, алгоритмы распознавания подписи по лого и QR-коду практически не отличаются. В этом алгоритме есть два значимых отличия. Во-первых, вместо QR-кода мы работаем с лого организации. Во-вторых, если QR-код мы искали с помощью специально библиотеки, то лого мы ищем как самый большой квадрат в верхней левой части документа.
При поиске лого мы задаем ограничения по минимальным размерам квадрата равные 4% относительно сторон изображения. Это делается для того, чтобы найденный нами квадрат точно был больше букв на документе, что позволяет нам предполагать, что это лого компании.
Итоги работы функционала распознавания подписи
Последняя, на момент написания статьи, 3-я итерация функционала распознавания подписи представляет собой сочетание работы 3-х алгоритмов.

Каждый следующий алгоритм начинает работать, если предыдущий не смог найти подпись на документе. Таким образом мы считаем, что документ не подписан, если все три алгоритма выдали отрицательный результат.
При анализе потребляемых ресурсов мы не заметили значительных изменений.

3-я итерация алгоритма потребляет примерно столько же памяти сколько и предыдущая. Мы наблюдаем это из-за того, что после работы каждого алгоритма мы высвобождаем используемые им ресурсы. Небольшие отклонения в кол-ве памяти можно считать допустимыми погрешностями.
В таком виде мы запустили функционал в бою, а также натравили его на исторические данные. По успешно распознанным документам перед нами была представлена следующая картина:
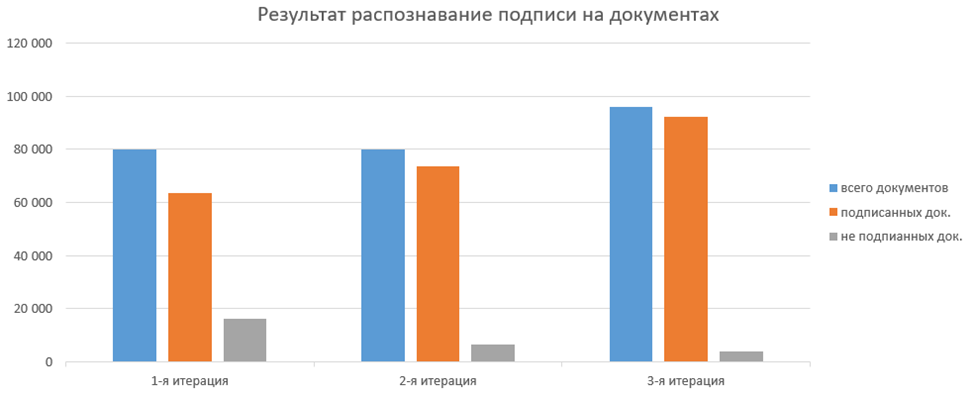
Между 2-ой и 3-ей итерациями прошло некоторое кол-во времени, поэтому на 3-ей итерации общее количество документов выросло. Однако несмотря на это, из рисунка, хорошо видно, что процент распознавания вырос. В 3-й итерации алгоритма он составил 96%, что является для нас хорошим результатом.
На момент написания статьи, через 3-ю итерацию алгоритма прошло более 2 055 000 документов. Из них подпись была найдена в 1 774 238 случаях.
Задача по распознаванию подписи была для очень интересным опытом. В рамках нее у нас появились компетенции в команде по работе в области распознавания объектов на изображениях, а также понимание имеющихся в открытом доступе инструментов, с помощью которых это распознавание можно осуществлять. На этом мы заканчиваем серию статей о нашем опыте на данную тему. Спасибо за внимание, Хабр!
Комментарии (3)

LeonardPowers
27.12.2022 17:51Перемудрили. То, что это работает - здорово. Но имхо можно лучше:
1) Берему условный surf, можно с модификациями.
2) Строим модель логотипа.
3) Ищем с помощью Ransaca гомографию для лого на искомом документе.
4) Так как подпись в одном и том же месте - по гомографию лого находим точные координаты подписи.
5) Детектируем курвы подписи с помощью алгоритма Хаффа (или чем вы делали?)
Всё. Вы великолепны. И работать будет даже если изображение не просто повернуто, а у него изменена перспектива.
И никакие повороты, маски, секции не нужны.
P.S. И да, даже EmguCv не нужен, так как есть либы на чистом dotNet, с описанным выше алгоритмами. Например Accord.Net, жаль, что поддержка аккорда кончилась(

GetcuReone Автор
27.12.2022 19:15Спасибо за совет, учтем в будушем. Но как уже упомяналось в 1-й части статьи, такая задача была нам в новинку. У нас в принципе не было компетенций в области работы с изображениями. Поэтому что удалось узнать в кратчайшие сроки, на том и базировали фанкционал распознавания подписи
ZombieDe
Очень ждала вторую часть стать! Статья оказалась столь же интересной и познавательной,как предыдущая. Хорошо проделанная работа и ,главное, отличный результат!