
В рамках крупнейшего проекта мы представляем Deep Lake - озеро данных для глубокого обучения. Deep Lake более чем в 2 раза производительнее по сравнению с предыдущим поколением и превосходит все другие загрузчики данных. Давайте узнаем больше о возможностях Deep Lake.
Краткое содержание
Один из трех ML-проектов обречен на неудачу из-за отсутствия надежной организации данных. Проекты страдают от некачественной информации, неполного использования вычислительных ресурсов и значительных трудозатрат, необходимых для создания и поддержки больших объемов данных. Традиционные озера данных ликвидируют разрозненность информации для решения аналитических задач, обеспечивают принятие решений на основе данных, повышают операционную эффективность и снижают организационные расходы. Однако большинство из этих преимуществ недоступны при выполнении рабочих задач глубокого обучения, таких как обработка естественного языка (NLP), обработка звука, компьютерное зрение, сельское хозяйство, здравоохранение, мультимедиа, робототехника/автомобили, а также вертикали безопасности и охраны. Поэтому организации часто прибегают к разработке собственных систем.
Deep Lake сохраняет преимущества ванильного озера данных и позволяет в 2 раза быстрее проводить итерации моделей глубокого обучения, не тратя время на создание сложной инфраструктуры.
Deep Lake хранит сложные данные, такие как изображения, видео, аннотации, вложения и табличные данные, в виде тензоров и быстро передает их по сети в Tensor Query Language, браузерный механизм визуализации и фреймворки глубокого обучения без ущерба для использования GPU. По мере того как глубокое обучение стремительно захватывает традиционные вычислительные конвейеры, хранение наборов данных в Deep Lake скоро станет новой нормой.
За кулисами Activeloop
В 2016 году, до создания компании, я начал свою докторскую диссертацию в лаборатории коннектомики Принстонского института нейронаук. Мне довелось стать свидетелем перехода от гигабайтных к терабайтным, а затем к петабайтным массивам данных, чтобы всего за несколько лет достичь сверхчеловеческой точности в реконструкции нейронных связей внутри мозга. Наша задача заключалась в том, чтобы понять, как оптимизировать и снизить стоимость в 4-5 раз, переосмысливая способы хранения данных, их передачи из хранилища в компьютер, какие модели использовать, как их компилировать и масштабировать. Несмотря на то, что развитие отрасли шло медленно, мы заметили, как аналогичные схемы стали повторятся в гораздо большем масштабе.
Мы основали компанию Activeloop (ранее известную как Snark AI) в составе группы Y Combinator Summer 2018, чтобы помочь организациям более эффективно внедрять решения на основе глубокого обучения. С нашей помощью была создана большая языковая модель для патентов в юридическом технологическом стартапе и потоковые конвейеры данных для решения петабайтных масштабов задач машинного обучения в AgriTech. Путем проб и ошибок в общении с сотнями компаний мы выяснили, что все эти замечательные базы данных, хранилища и озера (к которым присоединяются lakehouses [новая открытая архитектура, сочетающая в себе лучшие элементы озер и хранилищ данных]) отлично справляются с аналитическими нагрузками, но не очень подходят для приложений глубокого обучения. Потребность в хранении неструктурированных данных, таких как аудио, видео и изображения, с годами резко возросла (более 90% данных сегодня генерируется в неструктурированном виде). Поэтому мы осознали, что создание базы данных для ИИ, решения по ее хранению, является для нас подходящей задачей.
В 2020 году мы выложили в открытый доступ формат датасета под названием "Hub", который позволил хранить изображения, видео и аудио в виде фрагментированных массивов на объектных хранилищах и связанный с фреймворками глубокого обучения, такими как PyTorch или Tensorflow. Мы сотрудничали с командами из Google AI, Waymo, Оксфордского университета, Йельского университета и других групп глубокого обучения (deep learning), чтобы понять все тонкости надежной инфраструктуры данных для dl-приложений.
В 2021 году проект с открытым исходным кодом стал трендом №1 в Python и №2 во всех репозиториях GitHub и даже был назван одним из 10 лучших пакетов python ML. На момент написания этого поста у него 4,8 тыс. звезд, 75+ контрибьюторов и +1 тыс. членов сообщества. Он используется в производстве как в исследовательских институтах, так и в стартапах и публичных компаниях.
Мы также выпустили управляемую версию Activeloop, которая позволяет визуализировать датасеты, контролировать версии и запрашивать их, а также передавать потоки данных в системы глубокого обучения. Помимо предоставления доступа к 125+ наборов данных машинного обучения, она позволяет обмениваться частными подборками и сотрудничать при создании и поддержке датасетов в разных организациях. Конечно, я не могу не гордиться тем, что наша небольшая команда с ограниченными ресурсами добилась успеха за столь короткое время, однако инновации в отрасли развиваются с ошеломляющей скоростью.
Большие фундаментальные модели завоевывают лидерство
За несколько лет глубокое обучение достигло сверхчеловеческих показателей точности в приложениях, применяемых в различных отраслях. Выявление рака по рентгеновским снимкам, анатомическая реконструкция нейронных клеток человека, сложные игры, такие как Dota или Go, вождение автомобилей, анфолдинг [разворачивание] белков, диалоговое взаимодействие, подобное человеческому, генерация кода и даже реалистичные изображения, которые захватили интернет (чтобы сделать идеальную подсказку, потребовалось около 40 слов, зато ИИ создал потрясающее изображение в заголовке этого поста). Такую скорость обеспечивают три фактора: (1) новые архитектуры, такие как Transformers, (2) огромные вычислительные возможности с помощью GPU или TPU, а также большой объем датасетов, таких как ImageNet, CommonCrawl и LAION-400M.
Мы в Activeloop твердо уверены, что подключение моделей глубокого обучения к цепочке создания ценности в ближайшие пять лет приведет к фундаментальным изменениям в мировой экономике. В то время как инноваторы в первую очередь фокусировались на моделях и вычислительном оборудовании, поддержание или оптимизация сложной инфраструктуры данных оставались на втором плане. В дилемме "построить или купить" организации (за неимением варианта "купить") постоянно создают трудноуправляемые внутренние решения. Все это привело нас к решению о выборе следующей ступени развития компании - Deep Lake.

Введение в Deep Lake, озеро данных для глубокого обучения
Что такое Deep Lake?
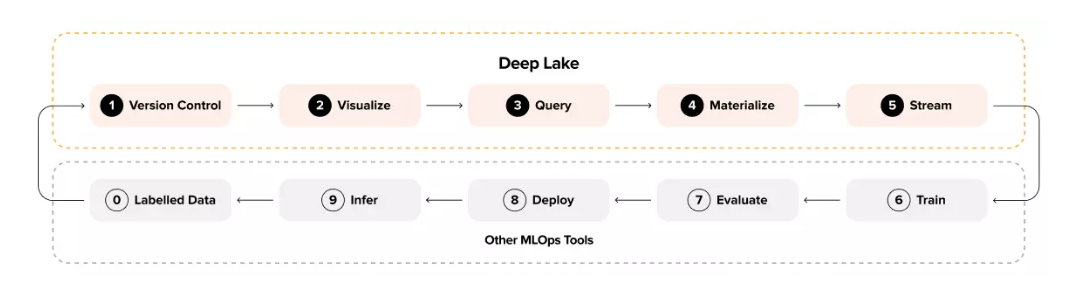
Deep Lake - это ванильное озеро данных для глубокого обучения, но с одним ключевым отличием. Deep Lake хранит сложные данные, такие как изображения, аудио, видео, аннотации, вложения и табличные данные, в виде тензоров и быстро передает данные по сети в Tensor Query Language, браузерный механизм визуализации или фреймворки глубокого обучения без ущерба для использования GPU.
Deep Lake обладает ключевыми характеристиками, которые делают его оптимальной платформой хранения данных для приложений глубокого обучения, включая:
Масштабируемая и эффективная система хранения данных, способная обрабатывать большие объемы сложных данных в виде столбцов.
Механизм запросов и визуализации, полностью поддерживающий мультимодальные типы данных
Нативная [встроенная] интеграция с фреймворками глубокого обучения и эффективная потоковая передача данных к моделям и обратно
Бесшовное соединение с инструментами MLOps.
Цикл машинного обучения с Deep Lake
Вот пять фундаментальных основ Deep Lake.
Контроль версий: Git для данных
Визуализация: Механизм визуализации в браузере
Запрос: Быстрые запросы с помощью языка Tensor Query
Материализация: Формат, присущий глубокому обучению
Поток: Загрузчики потоковых данных
Мы подробно обсуждаем эти возможности в Deep Lake White Paper и освещаем принцип их работы в Academic Paper.
Deep Lake и структура загрузчика данных
Загрузчики данных являются одним из значимых узких мест в конвейерах машинного обучения (Mohan et al., 2020), и мы создали Deep Lake специально для решения этой проблемы.

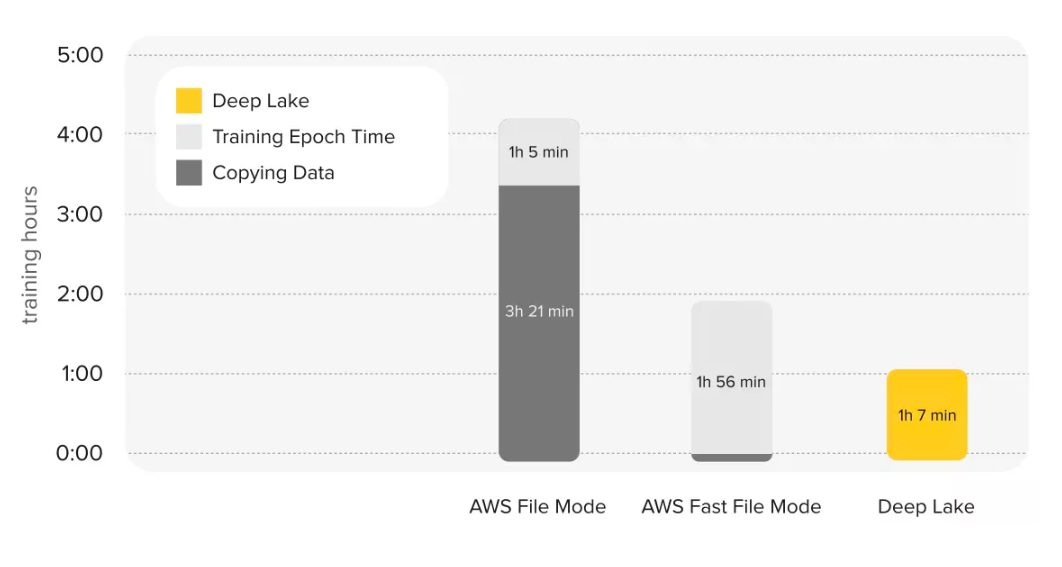
Мы благодарны Офейдис (Ofeidis), Кидански (Kiedanski) и Тассиуласу (Tassiulas) из Йельского института сетевых наук (Yale Institute For Network Science), которые потратили много времени на проведение независимого, обширного исследования и бенчмаркинга загрузчиков данных с открытым исходным кодом. Исследование показало, что третья основная итерация нашего продукта, Deep Lake, не только в 2 раза быстрее предыдущей версии, но и превосходит другие загрузчики данных при различных сценариях.
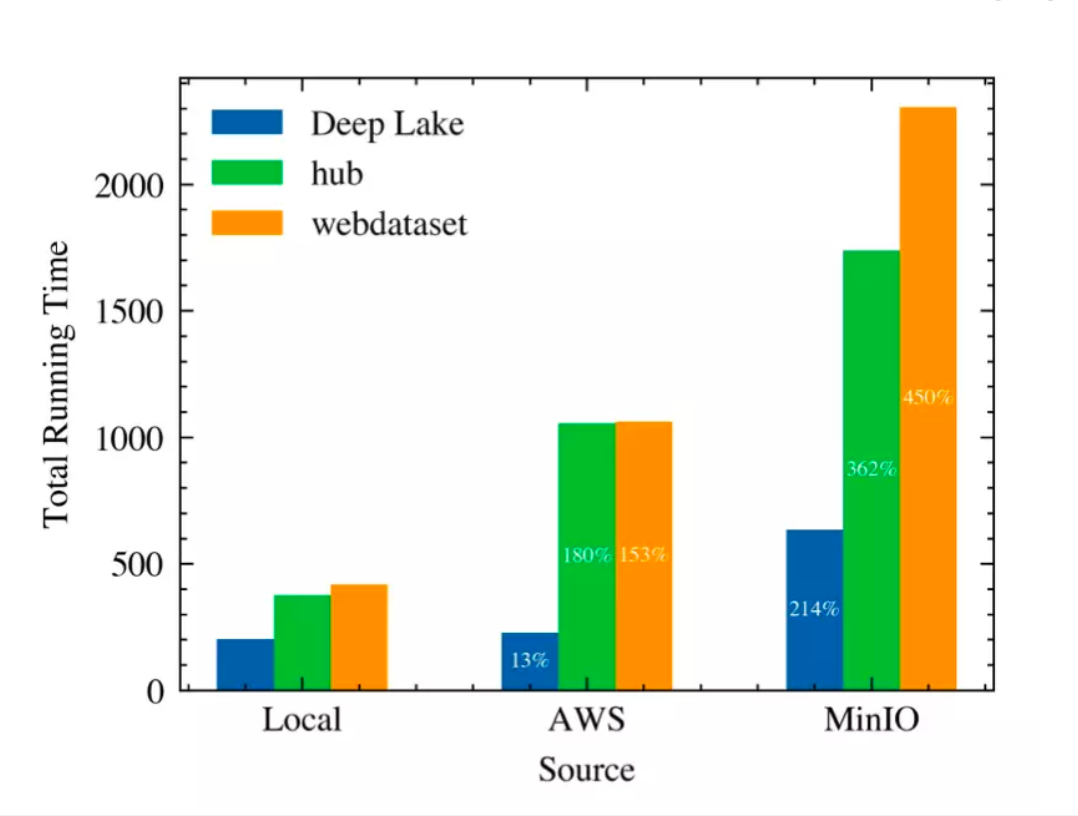
*Сравнение производительности Activeloop Hub, Deep Lake и Webdataset при загрузке данных из разных локаций: Local, AWS и MinIO. (Ofedis et al. 2022)
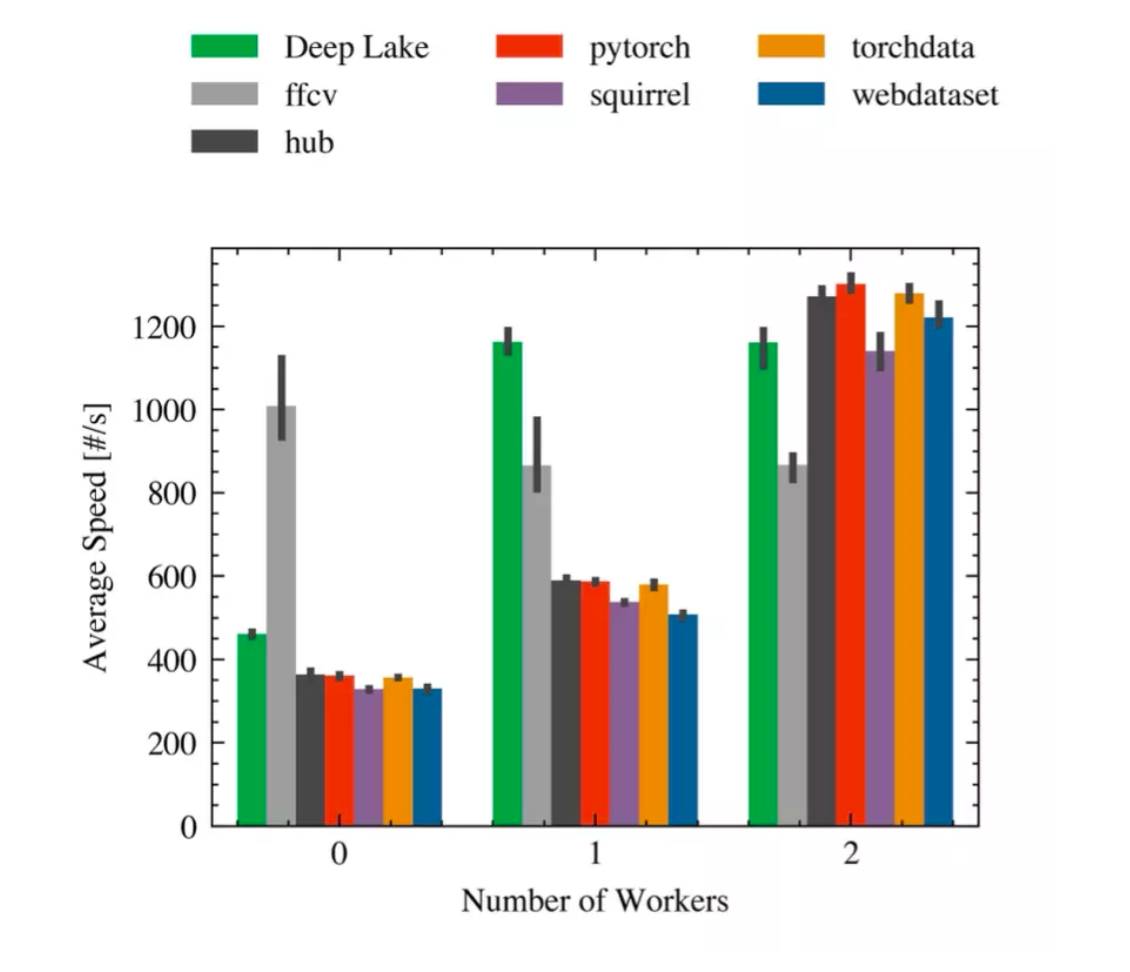
Скорость в зависимости от количества воркеров для RAN- DOM на одном GPU. (Ofedis et al. 2022) *.
Обоснование некоторых архитектурных решений Deep Lake
Естественно, потребовалось много размышлений и итерационных циклов, чтобы прийти к тому, как устроена архитектура Deep Lake – и вот несколько соображений, которыми мы руководствовались.
Какое место занимает Deep Lake в MLOps?
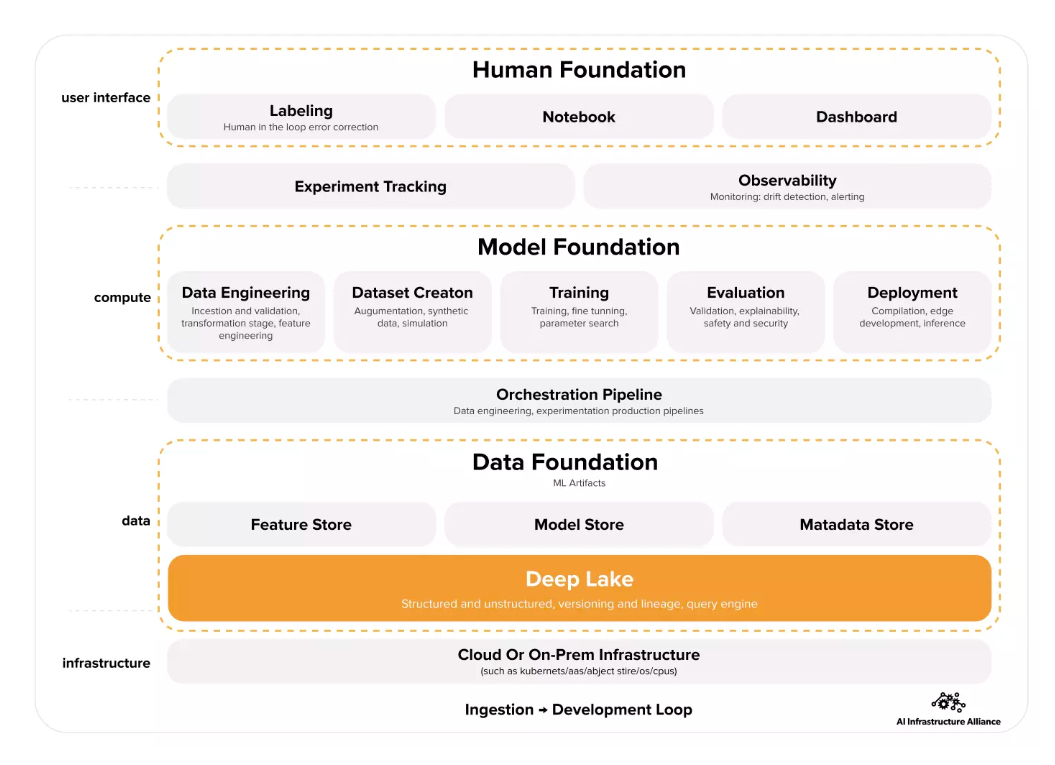
По мере появления на рынке многочисленных инструментов MLOps для покупателей становится трудно разобраться в этой области. Мы сотрудничали с Альянсом инфраструктуры искусственного интеллекта для разработки новой схемы MLOps, которая обеспечивает четкий обзор всех инструментов. Схема идет снизу вверх от инфраструктуры к интерфейсу с человеком и слева направо – от сбора данных к разработке. В этой модели Deep Lake приобретает важную роль надежного источника данных.
Почему мы переименовали Hub в Deep Lake?
Изначально Hub был формой фрагментированных массивов, которая естественным образом развивалась вместе с контролем версии, потоковым механизмом и возможностями запросов. Наше широкопрофильное сообщество с открытым исходным кодом - пользователи из компаний, стартапов и научных кругов – сыграло важную роль при улучшении продукта. В процессе работы нам все чаще казалось, что данное название является слишком общим описанием (или, как выразился один из членов нашей команды, "Hub сейчас есть у всех"). Часто оно вызывало путаницу с хабами датасетов. Для внутреннего пользования мы называли его "deep lake (глубокое озеро)" (или называли его в честь самых глубоких озер в мире). Было приятно видеть, что такие люди, как А. Пинхасси (A. Pinhassi), тоже рассуждают в этом же направлении. Однажды, называя инструмент, мы создали "deeplake" вместо "hub", что было как нельзя кстати (хотя наш отдел маркетинга был не в восторге из-за свежезаказанных атрибутов с брендингом Hub).

Существует ли Deep Lakehouse, и где он применяется?
Формат включает в себя версионирование, а линия наследования полностью с открытым исходным кодом. Движки запросов, потоковой передачи и визуализации собраны на C++ и пока что имеют закрытый исходный код. Тем не менее, они доступны через интерфейс Python для всех пользователей. Будучи приверженцами принципов open-source, мы планируем выкладывать в открытый доступ высокопроизводительные движки по мере их коммодитизации.

Работает ли Deep Lake с инструментами Modern Data Stack и MLOps?
Назначение Deep Lake Airbyte позволяет получать датасет из огромного количества источников данных. Что касается MLOps, мы сотрудничаем с W&Bs, Heartex LabelStudio, Sama, CleanLab, AimStack и Anyscale Ray, чтобы обеспечить бесшовную интеграцию, о которой мы расскажем в последующих статьях блога.

Что будет дальше с Deep Lake?
По мере развития Deep Lake мы будем постоянно оптимизировать производительность, добавим кастомный сэмплер данных, субтайловые запросы для построения сложных датасетов в релизе 3.1.0, поддержку TensorFlow и транзакций ACID, запланированных в релизе 3.2.0 (следите за нашим репо на GitHub, чтобы не пропустить).
Мы считаем, что следующий шаг в исследованиях ИИ - это захват текста, аудио, изображений и видео с помощью больших мультимодальных фундаментальных моделей. Просто подумайте о том, сколько дней потребовалось, чтобы добраться до Dall-E, и как много времени прошло от этой вехи до Stable Diffusion или Make-A-Video от Meta AI. Наличие надежной инфраструктуры данных станет необходимым условием для передачи этих моделей в руки клиентов. Поскольку глубокое обучение быстро захватывает традиционные вычислительные конвейеры, хранение датасетов в Deep Lake становится нормальным явлением.
Вы можете окунуться в Deep Lake (да, мы продолжим каламбурить на тему воды), попробовав Colab "Начало работы с Deep Lake", а также ознакомившись с нашим новым загрузчиком данных и механизмом запросов на C++ (Alpha) в этом Colab.
Совсем скоро состоится открытое занятие «Elasticsearch как NoSQL хранилище документов», на котором участники:
Изучат классификацию NoSQL СУБД.
Узнают про отличительные черты Elasticsearch и его применимости к разным задачам.
Узнают, почему Elasticsearch – одних из наиболее популярных инструментов для создания поисковых датасетов в современном мире.
Поймут, чем так хорош Elasticsearch.
v1000
надеюсь, с добавлением синтаксического сахара? (сарказм)