
В одной конторе соискателю на позицию Senior C# developer выдали тестовое задание: отсортировать файл со строками определенного формата.
Требования такие:
Формат строки: число, точка, пробел, далее любые символы до конца строки.
Порядок сортировки — сначала сортируем текстовой части строки, потом по числу если текстовые части совпадают.
Кодировка — UTF-8.
Размер файла — 100гб - гарантированно больше объема ОП.
Должно отработать за 1 час на машине проверяющего, вряд ли там будет супер-быстрый SSD и огромное количество оперативной памяти.
Как и многие другие программисты, узнав о таком тестовом задании, я возмутился. Внешнюю сортировку слиянием практически всех проходили в ВУЗе, но практически никто никогда не писал её. Задача очень непрактическая и непонятно какие навыки проверяет. Так мне казалось.
Эта задача вызвала бурные обсуждения о способах её решения. Многие программисты, причисляющие себя к рангу senior, предложили использовать базы данных, ибо не барское это дело - вручную писать алгоритмы сортировки. Некоторые даже попытались сделать решение на Apache Spark. Однако никто до конца задачу не решил, ибо мало кому удалось отсортировать в нужном порядке даже 10ГБ файл менее чем за 15 минут без SSD.
Я подумал, что стоит решить задачу до конца с помощью программирования, и тоже причислить себя к рангу senior developer.
В первую очередь я написал генератор тестового файла, который генерирует нужное количество строк из исходного файла. В качестве исходного взял первый том Войны и Мира, так как там есть как русские, так и английские символы.
Код генератора
var source = (from l in File.ReadLines("source.txt")
where !string.IsNullOrEmpty(l)
from s in l.Split(new[] { '.', '?', '!', '[', ']' }, StringSplitOptions.RemoveEmptyEntries | StringSplitOptions.TrimEntries)
where s.Length > 10
select s).ToList();
Random rand = new();
using (var f = File.CreateText(file))
{
f.AutoFlush = false;
while(f.BaseStream.Position < maxSize)
{
var n = rand.Next();
f.Write(n);
f.Write(". ");
f.WriteLine(source[rand.Next(source.Count)]);
}
}
return 0;Для начала решил сгенерировать 10ГБ, чтобы не ждать час на каждом тестовом прогоне. Кроме того файл такого размера не помещается в кэши операционной системы и операции чтения-записи доходят до диска, что дает представление о реальном быстродействии на больших объемах.
Самое простое работающее решение
Все началось со статьи на хабре о внешней сортировке. Сразу отбросил идею нескольких прогонов для объединения блоков, так как это привело бы к дополнительным затратам на запись. Весь код разделил на две фазы — разбиение исходного файла на отдельные блоки (чанки, от английского chunk) и сортировка строк в блоках, слияние блоков в один файл.
Код разбиения:
var count = 0;
var tempFiles =
File.ReadLines(file)
.Select(s => new Item(s, s.IndexOf('.')))
.Chunk(chunkSize)
.Select(chunk =>
{
Array.Sort(chunk, comparer);
var tempFileName = Path.ChangeExtension(file, $".part-{count++}" + Path.GetExtension(file));
File.WriteAllLines(tempFileName, chunk.Select(x => x.Line));
return tempFileName;
}).ToList();Код слияния:
try
{
var mergedLines = tempFiles
.Select(f => File.ReadLines(f).Select(s => new Item(s, s.IndexOf('.'))))
.Merge(comparer) // IEnumerable<IEnumerable<T>> -> IEnumerable<T>
.Select(x => x.Line);
File.WriteAllLines(Path.ChangeExtension(file, ".sorted" + Path.GetExtension(file)), mergedLines);
}
finally
{
tempFiles.ForEach(File.Delete);
}Для того, чтобы удобнее писать код, определил тип, содержащий строку и позицию точки в строке и компаратор для этого типа:
public record struct Item(string Line, int DotPosition);
public record Comparer(StringComparison StringComparison) : IComparer<Item>
{
public int Compare(Item x, Item y)
{
var spanX = x.Line.AsSpan();
var spanY = y.Line.AsSpan();
var xDot = x.DotPosition;
var yDot = y.DotPosition;
var cmp = spanX[(xDot + 2)..].CompareTo(spanY[(yDot + 2)..], StringComparison);
if (cmp != 0) return cmp;
return int.Parse(spanX[..xDot]) - int.Parse(spanY[..yDot]);
}
}"Сердце" всего алгоритма внешней сортировки - слияние итераторов:
public static IEnumerable<T> Merge<T>(this IEnumerable<IEnumerable<T>> sources, IComparer<T> comparer = default)
{
var enumerators = (from source in sources
let e = source.GetEnumerator()
where e.MoveNext()
select e).ToList();
while (enumerators.Count > 0)
{
var min = enumerators.MinBy(e => e.Current, comparer)!;
yield return min.Current;
if (!min.MoveNext())
{
min.Dispose();
enumerators.Remove(min);
}
}
}Почему я не использовал async\await? Ведь сейчас все программисты C# втыкают async\await на автомате. Конечно я тоже так сделал сначала, но потом убрал.
Во-первых для асинхронных итераторов сложнее написать Merge. Во-вторых код с async\await медленнее работал. async\await несет дополнительные расходы на переключение контекста, продолжения вызывают всю цепочку асинхронных методов. Это может быть выгодно когда нам надо распараллелить ожидание, но в этом коде никаких параллельных ожиданий нет. Все операции происходят последовательно.
Первый запуск
Запустил сортировку слиянием, размер чанка - 1М строк или около 157Мб, время работы - 15:30, пятнадцать с половиной минут! В час для 100Гб уложиться не выйдет.
Что по вашему тормозило в этом коде больше всего? Напишите свой вариант в комментариях, прежде чем разворачивать спойлер и читать дальше.
Тайминг
SplitSort done in 00:04:59.2942000
Merge done in 00:10:32.1238153Диспетчер задач показывал, что во время сортировки ресурсы компьютера задействуются очень мало:
")

Оптимизируем слияние
Дольше всего выполняется не чтение или запись, а поиск минимального элемента во время слияния. Этот код я честно написал сам, не подсматривая в готовые решения. Гораздо эффективнее будет отсортировать итераторы один раз, а далее поддерживать их отсортированность после вызова .MoveNext(), даже на StackOverflow предлагают такой вариант.
Лучше всего подойдет двоичная (она же бинарная) куча. Она имеет минимальный элемент в корне и позволяет восстановить отсортированность за O(logN), где K - количество элементов в куче (у нас равно числу чанков). Естественно это я не сам придумал, а подсмотрел в интернете.
Методы работы с кучей
public static void Heapify<T>(this Span<T> heap, int index, IComparer<T> comparer)
{
ArgumentNullException.ThrowIfNull(comparer);
var min = index;
while (true)
{
var leftChild = 2 * index + 1;
var rightChild = 2 * index + 2;
var v = heap[index];
if (rightChild < heap.Length && comparer.Compare(v, heap[rightChild]) > 0)
{
min = rightChild;
v = heap[min];
}
if (leftChild < heap.Length && comparer.Compare(v, heap[leftChild]) > 0)
{
min = leftChild;
}
if (min == index) break;
var temp = heap[index];
heap[index] = heap[min];
heap[min] = temp;
index = min;
}
}
public static void BuildHeap<T>(this Span<T> heap, IComparer<T> comparer)
{
ArgumentNullException.ThrowIfNull(comparer);
for (int i = heap.Length / 2; i >= 0; i--)
{
Heapify(heap, i, comparer);
}
}Код метода слияния:
public static IEnumerable<T> Merge<T>(this IEnumerable<IEnumerable<T>> sources, IComparer<T> comparer = default)
{
var heap = (from source in sources
let e = source.GetEnumerator()
where e.MoveNext()
select e).ToArray();
var enumeratorComparer = new EnumeratorComparer<T>(comparer ?? Comparer<T>.Default);
heap.AsSpan().BuildHeap(enumeratorComparer);
while (true)
{
var min = heap[0];
yield return min.Current;
if (!min.MoveNext())
{
min.Dispose();
if (heap.Length == 1) yield break;
heap[0] = heap[^1];
Array.Resize(ref heap, heap.Length - 1);
}
heap.AsSpan().Heapify(0, enumeratorComparer);
}
}
private record EnumeratorComparer<T>(IComparer<T> comparer) : IComparer<IEnumerator<T>>
{
public int Compare(IEnumerator<T>? x, IEnumerator<T>? y)
{
return comparer.Compare(x!.Current, y!.Current);
}
}Остальной код программы не изменился. Время работы:
SplitSort done in 00:04:27.8391844
Merge done in 00:02:11.4364005Значительно лучше, но до заветного часа на 100ГБ еще очень далеко. Тут стоит обратить внимание, что из-за кэша файловой системы время работы может варьироваться +\-15%
Код по ссылке https://github.com/gandjustas/HugeFileSort/tree/heapsort
Оптимизируем разбиение
Фазы разбиения и слияния выполняют одинаковое количество чтения-записи, создают одинаковое количество объектов типа string, но фаза разбиения использует в 2,5 раз больше памяти и запуск под отладчиком показывает множество сборок мусора.
Все дело во времени жизни объектов. В фазе слияния объект строки живет от чтения из чанка до записи в результирующий файл. Когда считывается следующая строка из чанка предыдущая уже превратилась мусор. Мусор убирается в нулевом поколении сборщика, это происходит быстро и память не растет.
В фазе разбиения объекты строк живут от чтения из исходного файла до записи в чанк. Большинство объектов строк переживает несколько сборок мусора, что создает повышенную активность сборщика и увеличивает потребляемую память.
Мы не можем уменьшить время жизни строк на фазе разбиения. Но их можно вообще не создавать! Можно прочитать из файла блок символов, разделить по символу перевода строки и использовать вместо строк тип ReadOnlyMemory<char>, который предоставляет ту же функциональность. ReadOnlyMemory<char> это структура (не требует аллокаций в управляемой куче), которая представляет из себя ссылку на массив, смещение и длину.
Код разбиения без аллокаций:
List<string> tempFiles = new();
List<Item> chunk = new();
using (var reader = File.OpenText(file))
{
var chunkBuffer = new char[chunkSize];
var chunkReadPosition = 0;
var eos = reader.EndOfStream;
while (!eos)
{
// Читаем из файла весь буфер
var charsRead = reader.ReadBlock(chunkBuffer.AsSpan(chunkReadPosition));
eos = reader.EndOfStream;
var m = chunkBuffer.AsMemory(0, chunkReadPosition + charsRead);
// Заполняем список строк ReadOnlyMemory<char> для сортировки
int linePos;
while ((linePos = m.Span.IndexOf(Environment.NewLine)) >= 0 || (eos && m.Length > 0))
{
var line = linePos >= 0 ? m[..linePos] : m;
chunk.Add(new Item(line, line.Span.IndexOf('.')));
m = m[(linePos + Environment.NewLine.Length)..];
}
chunk.Sort(comparer);
// Записываем строки из отсортированного списка во временный файл
var tempFileName = Path.ChangeExtension(file, $".part-{tempFiles.Count}" + Path.GetExtension(file));
using (var tempFile = File.CreateText(tempFileName))
{
foreach (var (l, _) in chunk)
{
tempFile.WriteLine(l);
}
}
tempFiles.Add(tempFileName);
if (eos) break;
chunk.Clear();
//Отсток буфера переносим в начало
m.CopyTo(chunkBuffer);
chunkReadPosition = m.Length;
}
}Можно было бы оставить код в функциональном стиле, но тогда код получился бы более неуклюжим из-за необходимости передачи флага конца файла.
В структурах данных заменил string наReadOnlyMemory<char>и больше ничего не изменилось.
Время работы при размере чанка в 100М символов, 161Мб на диске:
SplitSort done in 00:03:50.6780519
Merge done in 00:02:19.5627238Удалось выиграть еще 30 сек и сократить расход памяти на фазе разбиения со 600 до 250 мегабайт. Как говорится Allocation is cheap… until it is not (статья от другом, но заголовок подходит).
К сожалению на этом все простые оптимизации кончились, а суммарное время работы все еще не позволит уложиться в час.
Как сравнивать строки
Для многих программистов сравнение строк это все еще посимвольное, а для тех кто пришел из С — побайтное сравнение. Но примерно с 2000 года все используют юникод. Юникод это не просто два байта на символ и кодировки переменной длины, вроде UTF8, это еще правила сравнения, нормализации и подсчета символов. Кто еще не в курсе - посмотрите доклад Plain Text Дилана Битти на NDC. Это один из лучших докладов за всю историю конференций.
Сравнение юникодных строк описано в стандарте Unicode Collation Algorithm (UCA). Это очень сложный алгоритм, который опирается на таблицы весов символом для разных культур. Этот алгоритм реализован в операционной системе (CompareStringW, CompareStringEx в Windows и CompareString из libSystem.Globalization.Native.so в Linux).
Конечно можно от этого всего отказаться и сравнивать строки посимвольно, это ускорит сортировку почти на минуту, так как .NET не использует системные API для этого. Достаточно указать StringComparison.Ordinal в Comparer. Кроме того, отказ от UCA позволяет использовать поразрядные (radix) алгоритмы сортировки, которые должны работать быстрее обычных. Но изменит порядок сортировки и фактически является оптимизацией под один частный случай. Не будет простых способов вернуться к UCA без потери быстродействия.
Один из шагов UCA — получение ключа сортировки (sort key) для строк — простого массива байт, который можно использовать для побайтного сравнения. Оказывается в .NET есть функция получения ключа сортировки строк CompareInfo.GetSortKey. То есть мы можем получить эти байты и потом сравнивать их. Если дописать в конец полученного массива байты числа, стоящего в начале, то мы можем всю сортировку свести к сортировке байтовых массивов.
Скоро 15 лет как я программирую на .NET и я узнал о наличии ключей сортировки строк и соответствующих классов только когда решал эту задачу.
Пытаемся оптимизировать сортировку
Для начала добавим получение ключей и сортировку по ним в методы разбиения и слияния:
List<string> tempFiles = new();
List<Item> chunk = new();
using (var reader = File.OpenText(file))
{
var keyBuffer = new byte[chunkSize * 2]; //Буфер для ключей
var chunkBuffer = new char[chunkSize];
var chunkReadPosition = 0;
var eos = reader.EndOfStream;
while (!eos)
{
// Читаем из файла весь буфер
var charsRead = reader.ReadBlock(chunkBuffer.AsSpan(chunkReadPosition));
eos = reader.EndOfStream;
var m = chunkBuffer.AsMemory(0, chunkReadPosition + charsRead);
var key = keyBuffer.AsMemory();
// Заполняем список строк ReadOnlyMemory<char> для сортировки
int linePos;
while ((linePos = m.Span.IndexOf(Environment.NewLine)) >= 0 || (eos && m.Length > 0))
{
var line = linePos >= 0 ? m[..linePos] : m;
var s = line.Span;
var dot = line.Span.IndexOf('.');
int x = int.Parse(s[..dot]);
s = s[(dot + 2)..];
var keyLen = culture.CompareInfo.GetSortKey(s, key.Span); // Получаем ключ
BinaryPrimitives.WriteInt32BigEndian(key[keyLen..].Span, x); // Добписываем число в конец ключа, чтобы старшый байт был с меньшим индексом
keyLen += sizeof(int);
chunk.Add(new Item(line, key[..keyLen]));
m = m[(linePos + Environment.NewLine.Length)..];
key = key[keyLen..];
}
chunk.Sort(comparer);
// Записываем строки из отсортированного списка во временный файл
var tempFileName = Path.ChangeExtension(file, $".part-{tempFiles.Count}" + Path.GetExtension(file));
using (var tempFile = File.CreateText(tempFileName))
{
foreach (var (l, _) in chunk)
{
tempFile.WriteLine(l);
}
}
tempFiles.Add(tempFileName);
if (eos) break;
chunk.Clear();
//Остаток буфера переносим в начало
m.CopyTo(chunkBuffer);
chunkReadPosition = m.Length;
}
}При слиянии нам также надо получать ключи:
try
{
var mergedLines = tempFiles
.Select(f => File.ReadLines(f).Select(s => // Читаем построчно все файлы
{
var m = s.AsMemory();
var dot = s.IndexOf('.'); // Находим в строках точку
int x = int.Parse(s.AsSpan(0, dot));
// Получаем ключ того, что находится после точки с пробелом
var key = new byte[s.Length * 2 + sizeof(int)];
var keyLen = culture.CompareInfo.GetSortKey(m[(dot + 2)..].Span, key);
// Дописываем число в конец
BinaryPrimitives.WriteInt32BigEndian(key.AsSpan(keyLen), x);
return new Item(m, key);
}))
.Merge(comparer); //Слияние итераторов IEnumerable<IEnumerable<T>> в IEnumerable<T>
using var sortedFile = File.CreateText(Path.ChangeExtension(file, ".sorted" + Path.GetExtension(file)));
foreach (var (l, _) in mergedLines)
{
sortedFile.WriteLine(l);
}
}
finally
{
tempFiles.ForEach(File.Delete);
}Компаратор теперь очень простой:
public record struct Item(ReadOnlyMemory<char> Line, ReadOnlyMemory<byte> Key);
public class Comparer : IComparer<Item>
{
public int Compare(Item x, Item y)
{
return x.Key.Span.SequenceCompareTo(y.Key.Span);
}
}Результаты ожидаемо хуже:
SplitSort done in 00:04:09.5091207
Merge done in 00:03:02.5646277Мы проиграли 40 секунд на слиянии из-за получения ключей и 10 секунд на разбиении и сортировке. Сортировка ключей оказалась эффективнее, чем сортировка строк, но накладные расходы на получение ключей убили весь выигрыш.
Зато теперь можно применить поразрядную (Radix) сортировку ключей. Я написал два варианта поразрядной сортировки - Radix Quick Sort aka Multi-key QuickSort (просто перевел на C# алгоритм описанный в статье) и Counting Radix Sort (в основном скопировал код отсюда). К сожалению оба варианта проиграли стандартному Array.Sort(Код этих сортировок в статье не привожу, чтобы не забивать объем, но вы сможете найти его в исходниках вместе с бенчмарками по ссылке в конце статьи). Скорее всего потому, что сравнение блоков памяти методом SequenceCompareTo оптимизируется с помощью SIMD и работает гораздо быстрее, чем ручной код сравнения по разрядам.
Код по ссылке https://github.com/gandjustas/HugeFileSort/tree/sort-key
На этом месте я устал и лег спать.
А что если сохранять ключи?
С этой мыслью я проснулся на следующий день.
Во-первых сохраняя ключи во временном файле мы можем не получать ключ сортировки через API в фазе слияния.
Во-вторых нам вообще даже не надо декодировать символы в фазе слияния, мы можем просто сохранять нужное количество байт в выходном файле.
В-третьих, спустившись на уровень файловых потоков (
FileStreamвместоStreamReader) мы сможем эффективнее управлять буферизацией.
Я сделал бенчмарк, где сравнил все способы построчного чтения файлов, где сравнил File.ReadLines, StreamReader, FileStream и различные варианты буферизации, а также модный молодежный PipeReader. Победил, ожидаемо, FileStream, как самый низкоуровневый инструмент. Кроме того если вы будете читать или записывать данные большими блоками, то выгодно отключать встроенную буферизацию .NET, а если маленькими, то указывать большой размер буфера (код бенчмарков по ссылке в конце статьи).
Много кода
Фаза разбиения
public void SplitSort()
{
using var stream = new FileStream(file, FileMode.Open, FileAccess.Read, FileShare.Read, 0, FileOptions.SequentialScan);
fileSize = stream.Length;
List<SortKey> chunk = new();
var keyBuffer = new byte[maxChunkSize];
var readBuffer = new byte[maxChunkSize];
var remainingBytes = 0;
var charBuffer = new char[1024];
var eof = false;
while (!eof)
{
var bytesRead = stream.ReadBlock(readBuffer, remainingBytes, maxChunkSize - remainingBytes, out eof);
int chunkSize = remainingBytes + bytesRead;
if (!eof)
{
var lastNewLine = readBuffer.AsSpan(0, bytesRead).LastIndexOf(NewLine);
if (lastNewLine >= 0) chunkSize = lastNewLine + NewLine.Length;
remainingBytes = remainingBytes + bytesRead - chunkSize;
}
chunk.AddRange(ParseChunk(chunkSize, readBuffer, keyBuffer, charBuffer));
//Сортируем и записываем чанки на диск
chunk.Sort(comparer);
WriteChunk(chunk);
chunk.Clear();
//Остаток буфера переносим в начало
if (remainingBytes > 0) readBuffer.AsSpan(chunkSize, remainingBytes).CopyTo(readBuffer.AsSpan());
}
}Функция чтения строк и получения ключей сортировки
private IEnumerable<SortKey> ParseChunk(int byteCount, byte[] readBuffer, byte[] keyBuffer, char[] charBuffer)
{
var readPos = 0;
var key = keyBuffer.AsMemory();
while (byteCount > 0)
{
var linePos = readBuffer.AsSpan(readPos, byteCount).IndexOf(NewLine);
if (linePos == -1) linePos = byteCount;
if (charBuffer.Length < linePos) charBuffer = new char[linePos];
// Надо обязательно вызывать именно эту перегрузку, потому что остальные аллоцируют память
var lineLen = encoding.GetChars(readBuffer, readPos, linePos, charBuffer, 0);
var line = charBuffer.AsMemory(0, lineLen);
var s = line.Span;
var dot = s.IndexOf('.');
var x = int.Parse(s[0..dot]);
var keyLen = culture.CompareInfo.GetSortKey(s[(dot + 2)..], key.Span, compareOptions);
BinaryPrimitives.WriteInt32BigEndian(key[keyLen..].Span, x);
keyLen += sizeof(int);
var lineSize = linePos + NewLine.Length;
yield return new SortKey(readBuffer.AsMemory(readPos, lineSize), key[..keyLen]);
key = key[keyLen..];
readPos += lineSize;
byteCount -= lineSize;
maxLineSize = Math.Max(maxLineSize, lineSize);
maxKeyLength = Math.Max(maxKeyLength, keyLen);
}
}Функция записи чанка на диск
void WriteChunk(List<SortKey> chunk)
{
// Записываем строки из отсортированного списка во временный файл
var tempFileName = Path.ChangeExtension(file, $".part-{tempFiles.Count}.tmp");
using var stream = new FileStream(tempFileName, FileMode.Create, FileAccess.Write, FileShare.None, BufferSize, FileOptions.SequentialScan);
Span<byte> buffer = stackalloc byte[sizeof(int)];
foreach (var (line, key) in chunk)
{
BinaryPrimitives.WriteInt32LittleEndian(buffer, line.Length);
stream.Write(buffer);
stream.Write(line.Span);
BinaryPrimitives.WriteInt32LittleEndian(buffer, key.Length);
stream.Write(buffer);
stream.Write(key.Span);
}
tempFiles.Add(tempFileName);
}Фаза слияния
public void Merge()
{
var mergedLines = tempFiles
.Select(ReadTempFile) // Читаем построчно все файлы, находим в строках точку
.Merge(comparer); //Слияние итераторов IEnumerable<IEnumerable<T>> в IEnumerable<T>
string sortedFileName = Path.ChangeExtension(file, ".sorted" + Path.GetExtension(file));
using var sortedFile = new FileStream(sortedFileName, FileMode.Create, FileAccess.Write, FileShare.None, BufferSize, FileOptions.SequentialScan);
sortedFile.SetLength(fileSize);
foreach (var (l, _) in mergedLines)
{
sortedFile.Write(l.Span);
}
}Чтение временного файла
private IEnumerable<SortKey> ReadTempFile(string file)
{
using var stream = new FileStream(file, FileMode.Open, FileAccess.Read, FileShare.Read, BufferSize, FileOptions.SequentialScan);
var maxBlockSize = maxLineSize + maxKeyLength + sizeof(int) * 2;
var readBuffer = new byte[Math.Max(BufferSize, maxBlockSize)];
var bytesRemaining = 0;
var eof = false;
while (!eof)
{
var bytesRead = stream.ReadBlock(readBuffer, bytesRemaining, readBuffer.Length - bytesRemaining, out eof);
if (bytesRead == 0) eof = true;
var mem = readBuffer.AsMemory(0, bytesRemaining + bytesRead);
while (mem.Length > maxBlockSize || (eof && mem.Length > 0))
{
var lineSize = BinaryPrimitives.ReadInt32LittleEndian(mem.Span);
mem = mem[sizeof(int)..];
var line = mem[..lineSize];
mem = mem[lineSize..];
var keyLen = BinaryPrimitives.ReadInt32LittleEndian(mem.Span);
mem = mem[sizeof(int)..];
yield return new SortKey(line, mem[..keyLen]);
mem = mem[keyLen..];
}
mem.CopyTo(readBuffer);
bytesRemaining = mem.Length;
}
}Из 25 строк кода в самом начале, написанных даже без классов и метода Main, всё превратилось в 150 строк без учета конструктора и полей класса.
Результаты забега при установке размера чанка в 100М байт. Так как теперь вместе со строками записываются ключи размер одного временного файла на диске составляет 180МБ.
SplitSort done in 00:04:12.8286312
Merge done in 00:03:05.3477665Результат приблизительно равен предыдущему, но это при учете что теперь мы пишем и читаем не 10Гб временных файлов, а 18гб. В таск менеджере заметно, что быстродействие теперь сильно упирается в диск.
Если быстродействие сильно упирается в диск, то нужно данные сжать. Так мне говорила бабушка прочитал в книге по базам данных. Завернем FileStream в BrotliStream при записи и чтении временных файлов. Brotli — это новый алгоритм сжатия, который пока еще приходит в веб и другие аспекты разработки. Подробнее можно прочитать на википедии.
Результаты забега со сжатием
SplitSort done in 00:04:28.3044728
Merge done in 00:00:36.4300613В сумме меньше 5 минут. Суммарный объем временных файлов на диске сократился до 970МБ, то есть почти в 20 раз. Это понятно, так как в файлах очень много повторяющихся строк. Возможно на других текстовых файлах результат будет не настолько выдающимся, но все равно написанные человеком или chatGpt тексты будут хороши сжиматься.
Код по ссылке https://github.com/gandjustas/HugeFileSort/tree/sort-key-with-compression
Быстродействие теперь упирается не в диск, а в процессор. И это хорошо. Диск у нас один, а процессоров зачастую больше.
Распараллеливание
Сейчас программа выполняется последовательно:
Чтение чанка (нагружает диск и не использует процессор)
Парсинг строк и получение ключей (нагружает процессор в основном)
Сортировка (сильно нагружает процессор)
Сжатие данных (сильно нагружает процессор)
Запись (сильно нагружает диск)
Было бы неплохо пункты 1 и 5 выполнять параллельно с 2-4.
Заведем пять отдельных потоков для каждой задачи. Для передачи чанков между потоками воспользуемся библиотекой System.Threading.Channels.
readToParse = Channel.CreateBounded<(byte[], int)>(1); // Буфер и размер
parseToSort = Channel.CreateBounded<(List<SortKey>, byte[], byte[])>(1); // Список ключей, буфер строк и буфер ключей
sortToCompress = Channel.CreateBounded<(List<SortKey>, byte[], byte[])>(1)); // Список ключей, буфер строк и буфер ключей
compressToWrite = Channel.CreateBounded<(byte[], int)>(1); // Сжатые данные и размер
parserThreads =
Enumerable
.Range(0, degreeOfParallelism)
.Select(_ => Task.Run(ParallelParser)).ToArray();
sorterThreads =
Enumerable
.Range(0, degreeOfParallelism)
.Select(_ => Task.Run(ParallelSorter)).ToArray();
compressThreads =
Enumerable
.Range(0, degreeOfParallelism)
.Select(_ => Task.Run(ParallelCompressor)).ToArray();
writerThread = Task.Run(ParallelWriter);Нам нужен ограниченный канал с емкостью в одно сообщение. Если сообщение уже есть в очереди, то есть получатели заняты обработкой предыдущего, то отправитель будет висеть в ожидании освобождения канала. Таким образом нагрузка будет автоматически балансироваться.
Метод SplitSort изменим так, чтобы он мог работать как в синхронном режиме, так и в параллельном
using var stream = new FileStream(file, FileMode.Open, FileAccess.Read, FileShare.Read, 0, FileOptions.SequentialScan);
fileSize = stream.Length;
List<SortKey>? chunk = null;
byte[]? keyBuffer = null;
char[]? charBuffer = null;
var readBuffer = pool!.Rent(maxChunkSize);
var remainingBytes = 0;
var eof = false;
while (!eof)
{
var bytesRead = stream.ReadBlock(readBuffer, remainingBytes, maxChunkSize - remainingBytes, out eof);
int chunkSize = remainingBytes + bytesRead;
if (!eof)
{
var lastNewLine = readBuffer.AsSpan(0, bytesRead).LastIndexOf(NewLine);
if (lastNewLine >= 0) chunkSize = lastNewLine + NewLine.Length;
remainingBytes = remainingBytes + bytesRead - chunkSize;
}
var oldBuffer = readBuffer;
if (degreeOfParallelism > 0)
{
await readToParse.Writer.WriteAsync((readBuffer, chunkSize));
readBuffer = pool.Rent(maxChunkSize);
}
else
{
chunk ??= new();
chunk.AddRange(ParseChunk(chunkSize, readBuffer,
keyBuffer ??= pool.Rent(maxChunkSize),
charBuffer ??= new char[1024]));
//Сортируем и записываем чанки на диск
chunk.Sort(comparer);
WriteChunk(chunk);
chunk.Clear();
}
//Осаток буфера переносим в начало
if (remainingBytes > 0) oldBuffer.AsSpan(chunkSize, remainingBytes).CopyTo(readBuffer.AsSpan());
}
if (degreeOfParallelism == 0)
{
if (readBuffer != null) pool.Return(readBuffer);
if (keyBuffer != null) pool.Return(keyBuffer);
}Если параметр degreeOfParallelism равен нулю, то код будет выполнятся последовательно, как и раньше. Если degreeOfParallelism >= 1, то после чтения чанка он отправится в readToParse канал и основной поток сразу же начнет читать второй чанк.
Очевидно в таком случае одним буфером для строк и ключей обойтись не получится, буферы придется каждый раз выделять новые. Чтобы не забить всю память таким образом я сразу применил ArrayPool. Ничего сложного нет: вместо оператора new вызываем метод Rent, а когда перестали пользоваться - вызываем Return.
ParallelParser, ParallelSorter и ParallelWriter выглядят так:
private async Task ParallelParser()
{
var charBuffer = new char[1024];
await foreach (var (readBuffer, chunkSize) in readToParse.Reader.ReadAllAsync())
{
var keyBuffer = pool!.Rent(maxChunkSize);
var chunk = ParseChunk(chunkSize, readBuffer, keyBuffer, charBuffer).ToList();
await parseToSort.Writer.WriteAsync((chunk, readBuffer, keyBuffer));
}
}
private async Task ParallelSorter()
{
await foreach (var item in parseToSort.Reader.ReadAllAsync())
{
item.Item1.Sort(comparer);
await sortToCompress.Writer.WriteAsync(item);
}
}
private async Task ParallelWriter()
{
await foreach (var (buffer, bufferLength) in compressToWrite.Reader.ReadAllAsync())
{
var tempFileName = Path.ChangeExtension(file, $".part-{tempFiles.Count}.tmp");
using (var tempFile = new FileStream(tempFileName, FileMode.Create, FileAccess.Write, FileShare.None, 0, FileOptions.SequentialScan))
{
await tempFile.WriteAsync(buffer.AsMemory(0, bufferLength));
}
pool!.Return(buffer);
tempFiles.Add(tempFileName);
}
}Они построены по простому принципу - читаем сообщения из канала пока они не кончатся, на каждое сообщение выполняем свое действие и отправляем дальше.
ParallelCompressor построен по тому же принципу, но содержит больше кода. Уберу его под спойлер.
Код ParallelCompressor
private async Task ParallelCompressor()
{
var buffer = new byte[1024]; //Buffer with margin
var outputSize = BrotliEncoder.GetMaxCompressedLength(maxChunkSize * 2);
await foreach (var (chunk, readBuffer, keyBuffer) in sortToCompress.Reader.ReadAllAsync())
{
using var encoder = new BrotliEncoder(4, 22);
var output = pool!.Rent(outputSize);
var dest = output.AsMemory();
var compressed = 0;
foreach (var sk in chunk)
{
if (sk.Length > buffer.Length)
{
buffer = new byte[sk.Length];
}
sk.Write(buffer, 0);
var source = buffer.AsMemory(0, sk.Length);
while (true)
{
var r = encoder.Compress(source.Span, dest.Span, out var bytesConsumed, out var bytesWritten, false);
compressed += bytesWritten;
if (bytesConsumed > 0) source = source[bytesConsumed..];
if (bytesWritten > 0) dest = dest[bytesWritten..];
if (r == OperationStatus.Done) break;
if (r == OperationStatus.InvalidData || r == OperationStatus.NeedMoreData)
{
throw new InvalidOperationException();
}
var old = output;
outputSize *= 2;
output = pool.Rent(outputSize);
old.CopyTo(output, 0);
pool.Return(old);
dest = output.AsMemory(compressed);
}
}
while (true)
{
var r = encoder.Flush(dest.Span, out var bytesWritten);
compressed += bytesWritten;
if (r == OperationStatus.Done) break;
if (r == OperationStatus.InvalidData || r == OperationStatus.NeedMoreData)
{
throw new InvalidOperationException();
}
var old = output;
outputSize *= 2;
output = pool.Rent(outputSize);
old.CopyTo(output, 0);
pool.Return(old);
dest = output.AsMemory(compressed);
}
outputSize = compressed * 11 / 10;
await compressToWrite.Writer.WriteAsync((output, compressed));
pool.Return(readBuffer);
pool.Return(keyBuffer);
}
}Из отсортированного списка строк и ключей записываем все в энкодер, а он периодически отдает нам блок упакованных данных. В конце надо вызвать Flush. Все осложняется тем, что метод может выполниться частично и сказать, что для продолжения недостаточно места в целевом буфере. Тогда надо выделить буфер побольше и перенести туда данные из старого.
В конце код завершения параллельной обработки: завершаем очереди и ждем завершения потоков.
readToParse.Writer.Complete();
await parserThread;
parseToSort.Writer.Complete();
await sorterThread;
sortToCompress.Writer.Complete();
await compressThread;
compressToWrite.Writer.Complete();
await writerThread;Запускаем с размером чанка в 200 мегабайт.
SplitSort done in 00:02:21.4203828
Merge done in 00:00:39.0610435Три минуты в сумме, есть шанс уложиться в час для 100Гб.
Посмотрим в таск менеджер:
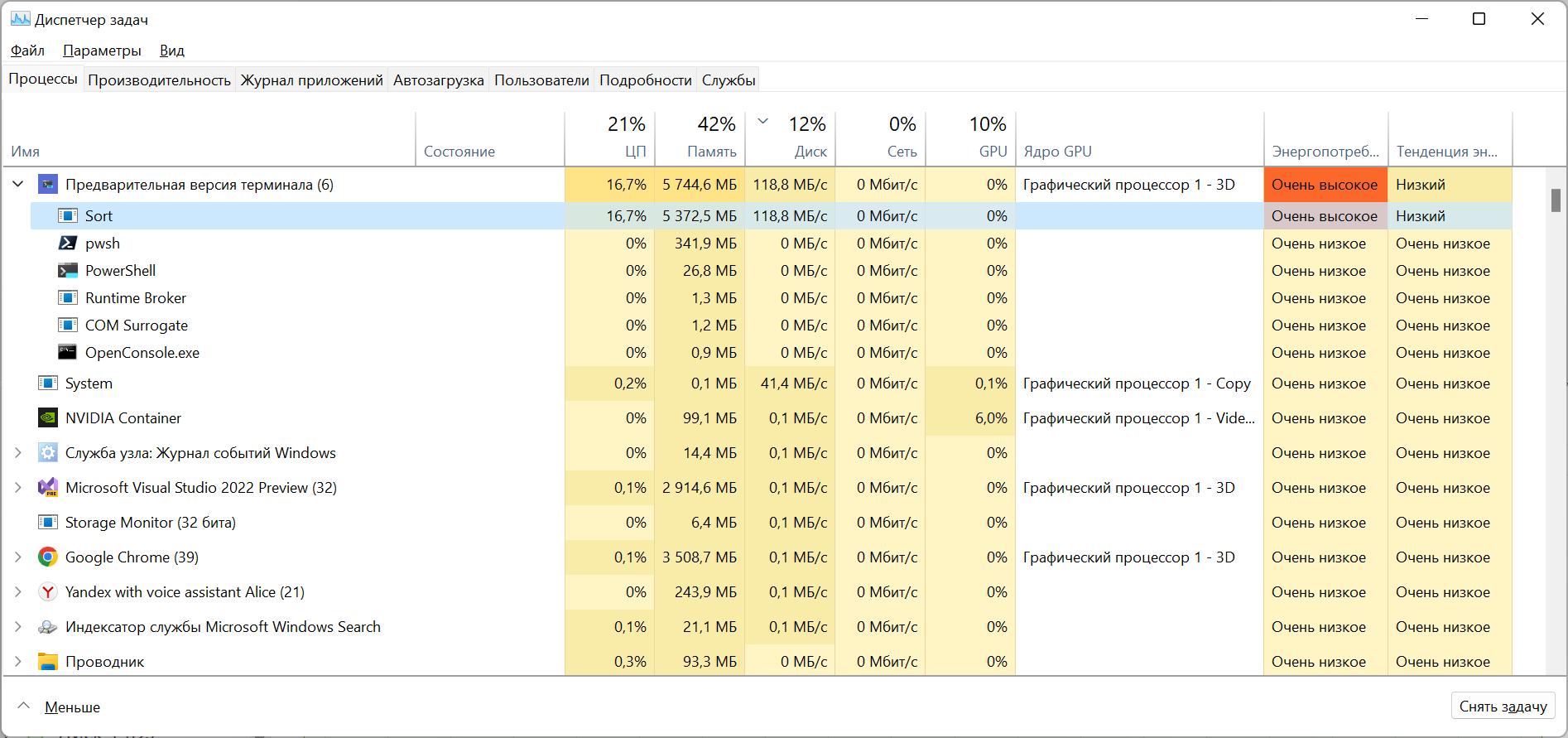
Потребление памяти выросло с 400Мб до 5,3Гб, это уже много. Почему так?
Когда код выполнялся последовательно для всех операцию использовался один набор буферов - для чтения данных, для ключей, список для сортировки и буфер для временного файла. Когда мы перешли в параллельный вариант у нас таких наборов как минимум количеству потоков + количеству каналов и свободных мест в них.
Такова, к сожалению, цена параллельности. Очень редко можно распараллелить обработку данных, не повышая размер используемой оперативной памяти.
Нагрузка на диск получилась небольшая, стоит добавить еще потоков для парсинга, сортировки и сжатия данных, то есть увеличить степень параллелизма (dop). Но это увеличит затраты памяти. Можно уменьшать размер чанка при повышении степени параллелизма.
// Значения по умолчанию
dop = Environment.ProcessorCount / 4;
chunkSize = 200 / int.Max(dop, 1);Финальный прогон с дефолтными параметрами (dop=4, chunkSize=50)
SplitSort done in 00:00:53.8610345
Merge done in 00:00:39.7727140Итого 1:40 (не более 1:50 за несколько прогонов).
Код со всеми бенчмарками по ссылке.
Заключение
Я очень сильно ошибся, думая что задача сортировки 100Гб файла простая. Для её решения нужно много знаний алгоритмов, библиотек, навык оптимизации программ и написания параллельного кода. А самое главное эта задача хорошо показывает способен ли программист преодолевать технические трудности и решать задачу до конца, а не пытаться найти короткий путь и опустить руки, если такого пути нет.
PS
❯ .\Sort.exe ..\..\..\..\100gb.txt
SplitSort done in 00:11:35.9023876
Merge done in 00:20:16.3989011Комментарии (136)

sci_nov
03.02.2023 12:15+3Надо сказать убийственное задание... Интересно, у них самих-то есть решение, укладывающееся в требуемые рамки?

LordDarklight
03.02.2023 13:25+2Наверняка есть. Вон автор заморочился и в итоге уложился чуть больше, чем за 30 мин. Хотя у автора тестовый стенд не хилый - а что там у интервьюеров за тестовое железо не известно - вдруг там жалкий Core i3 и 8Gb памяти (специально, чтобы не выезжать за счёт высокого производительного железа) - так там решение автора может за 1 часа и не уложиться! А интервьюеры хотели увидеть какой-то ещё более хитрый алгоритм - дабы тут есть куда копать ещё! Впрочем, может они на таком объёме и не тестируют вовсе - им важнее сделать грубую оценку на малом объёме и глянуть на сам код. Даже если алгоритм во времени не уложится - важно то, как программист мыслил, какую алгоритмическую архитектуру выстраивал. А мелкая оптимизация - ну у многих это может занимать месяцы анализа профилированной статистики и вытачивания узких мест.
Интересно - это тестовое задание для оффлайн решения, или надо было "на месте" у интервьюеров сделать за пару часиков (ну ладно - может часов за 8). Скорее всего для оффлайн - всё-таки тут даже тестовый прогон на полном объёме - это около часа (а то и больше) - на месте такую задачу можно решить только если заранее нечто подобное (очень близко по объёму данных) уже решать и отлично, на 5+ владеть пулом технологий! Впрочем когда ищут именно таких специалистов на з/п от полуляма деревянных - то могут и откровенно жестить и требовать решения "здесь и сейчас" за пару часиков - решат только те, кто 100% подобные задачи уже не раз решал! Но это поиск очень узкого и очень профессионального программиста - наверное же не синьор
помидорразработчик на ступеньку повыше - всякие лиды и архитекторы
gandjustas Автор
03.02.2023 13:30Упирается в основном в диск. Если запустить на ssd, то можно большой прирост получить даже на слабом железе.

vkni
03.02.2023 20:19SSD всего лишь в несколько раз медленнее оперативной памяти. Так что это читерство в некотором смысле. Ну примерно такое же, как взять сервер с большим кол-вом RAM (скажем, у меня есть доступ к нескольким серверам с > 100Гб оперативки).
gandjustas Автор
03.02.2023 23:56на сервере с > 100гб ОП отсортируйте файл в 200гб, возьмите размер чанка 400+ и dop=4+

klirichek
04.02.2023 17:22+1У SSD ещё быстрый рандомный доступ. По сути можно просто отммапить файл и дальше сортировать "как будто в памяти", без всяких слияний.
С HDD такое не прокатит из-за медленных seek.

codecity
04.02.2023 10:20Были некие хитро-выдуманные решения без учета особенностей сортировки строк.

h1pp0
03.02.2023 12:35+5Для чтения 100 Гб со скоростью 100 Мб/с (близко к скорость типичного HDD) потребуется почти полчаса. У вас SplitSort занял 11 минут, в три раза быстрее. Мне кажется, что тут что-то не так.
Также на одном из скриншотов вы показали, что у вас 64 Гб RAM. Не уверен, что при таком размере памяти тестирование на 100 Гб имеет смысл. Может быть хотя бы 500 Гб? Или запустить на машине с меньшим количеством памяти.

screwer
03.02.2023 12:42Современные диски на плоских файлах запросто выдают 200мб/с. Гигабайт за 5с, 100гб за 500с или 8,5 минут.
gandjustas Автор
03.02.2023 12:47Чтение линейное. Скорость примерно 170мб/сек, примерно 10гб/мин. Кроме того кэш диска около 2-3гб. То есть последние 2-3 Гб не пишутся на диск сразу, а первые 2-3 Гб могут реально не читаться с диска.
gandjustas Автор
03.02.2023 12:50У меня нет машины с меньшим количеством памяти.
На 100гб с dop=4 съело около 20гб оперативки. На машине с меньшим количеством ядер dop будет меньше и оперативки съест пропорционально меньше.
h1pp0
03.02.2023 12:54+2Кеш для чтения с диска не учитывается в потреблении памяти программой, но всё равно ускоряет работу. Не очень знаком с Windows кешами, если ошибся, прошу прощения.
gandjustas Автор
03.02.2023 12:58+1Не учитывается. Виндоус умеет префетчить. Если вы читаете файл линейно, то Виндоус будет читать с диска в кэш в фоне без участия процессора. То есть в некоторых сценариях суммарный io может отказаться выше пропускной способности диска.
screwer
03.02.2023 14:17+2Все умеют префетчить. И без участия процессора диска работает с доисторических времён (все помнят PIO и UDMA настройки в биосе?).
Пропускная способность сата3 600мб/сек, что гарантировано выше любого современного ХДД.
Да, часть данных может застрять в дисковом кеше, под который отводится вся неиспользуемая память. Но на больших файлах этот кеш будет активно вымываться.
h1pp0
03.02.2023 19:28Это я к тому, что если узким местом является размер системного кеша, то просто потребления памяти программой недостаточно. А на вашей системе слишком много RAM.
Представьте, что первая половина была "как бы в памяти", а с диска читалась только вторая.
gandjustas Автор
03.02.2023 19:33Размер системного кэша не является узким местом Обычно кэш заканчивается на 2-3 гб и дальше идет честная работа с диском.

Meloman19
03.02.2023 20:36Тут точно не скажешь. Эта виндовая служба любит отжирать под 80-100% от свободного места в оперативке под кэш (у меня прям сейчас 18 из 20Гб свободного съело). Правда, что оно туда кладёт - фиг его знает.
gandjustas Автор
03.02.2023 23:41Эти цифры по результатам забегов. Независимо от размеров чанков чтение шло именно с диска после обработки 2-3 гб исходного файла.

blind_oracle
03.02.2023 21:37Современные ОС под дисковый кеш отдают всю доступную оперативку и быстро evict-ят эти страницы если они для дела нужны, так что если памяти 16Гб то кеш может быть сильно больше 2-3Гб.
gandjustas Автор
03.02.2023 23:41Эти цифры по результатам забегов. Независимо от размеров чанков чтение шло именно с диска после обработки 2-3 гб исходного файла.

BlackSCORPION
05.02.2023 12:58Столько лет живу и только недавно осознал что существует кэш чтения с диска ) Парсил 15Гб surefire репортов, надо было проанализировать статистику падения тестов, и очень удивился что после первого запуска маленькой программы на Java, последующие запуски занимают пару секунд. Ведь у меня диск даже читать с такой скоростью не способен, up to 3500 )

adeshere
03.02.2023 13:13+11Не уверен, что я достаточно внимательно прочитал статью, т.к. задача от меня крайне далекая (как и язык), и в код я даже не лазил. Но я так и не понял: а зачем сортировать 100-Гб файл? Почему нельзя сделать короткие хэши, оставив от каждой строки по несколько символов, и сгенерировать относительно небольшой временный файл, который будет содержать три поля:
1) короткий (не уникальный!) ключ сортировки текстовой части, сгенерированный по началу этого текста.
2) число, которое стояло в начале строки
3) номер строки в исходном файлеПричем, построение такого ключа - это самая важная и
самая творческая задача всей операции.
Так как эффективность сортировки почти полностью зависит от того, насколько удачно мы эту задачу решим.
А именно, тут надо достичь компромисса между длиной этого ключа (как можно меньше) и максимальным размером блока записей с одинаковым ключом. При этом уникальность ключей совершенно не обязательна! Нет никакой проблемы, если ключ будет одним и тем же для нескольких записей. Однако очень важно, чтобы максимальное число записей с одинаковым ключом для любого ключа было не очень большим. Попросту говоря, нам гораздо лучше иметь на весь файл всего 100 разных ключей, но чтобы каждый такой ключ "метил" 1/100 исходного файла, чем чтобы ВСЕ ключи, кроме одного, были уникальными и метили только одну запись, но зато этот единственный не-уникальный ключ метил половину записей в файле.
Ради построения такого ключа я бы при получении задания не поленился и уточнил примерную длину и характер строк в исходном файле: упорядочены ли они, сколько там символов, насколько там типичны почти одинаковые блоки и т.д., чтобы эти ключи как-то оптимизировать, если это возможно.
Понятно, что пп.1-3 делаются за один проход по исходному файлу, причем чтение будет последовательное и достаточно быстрое
На втором шаге сортируем наш tmp-файл любым способом. Возможно, он вообще в ОП влезет (если строки очень-очень длинные были). Но это по-любому должно быть намного быстрее, чем сортировка исходного файла - просто за счет его размера.
На третьем шаге формируем промежуточный частично отсортированный полный файл. Для этого у нас в нашем отсортированном tmp-файле есть номера исходных строк. Это будет второй полный проход по исходному файлу - правда, теперь уже с чтением нужной строки из рандомного места, а не с последовательным.
Ну и заключительный шаг - это сортировка тех блоков, внутри которых наш первоначальный ключ сортировки текстовых строк совпадает. Да, тут уже придется честно сравнивать строки. Но если хорошо подобрать компромиссную длину ключа, то размер этих блоков должен быть не очень большим, правда? И сортироваться они будут достаточно быстро.
P.S. Извините, если велосипед написал. Но мне показалось, что решение в статье хотя и эффективное, но достаточно сложное. А может, сперва стоило все же попробовать какую-нибудь элементарщину типа описанной? Или мое предложение заведомо не сработает? Это не стеб, мне правда интересно, так как я такие задачки никогда не решал и рассуждаю сугубо теоретически.
UPD: забыл уточнить, что мое решение будет работать только для строк фиксированной длины. Иначе с рандомным поиском нужной строки по ее номеру может возникнуть проблема. Но в статье сказано про строки "определенного формата", что на такую одинаковость как бы слегка намекает...
gandjustas Автор
03.02.2023 13:29+6Интересная идея.
Это похоже на поразрядную сортировку, только мы сначала сортируем по префиксы, так чтобы индекс префиксов влез в память, а потом сортируем в строки в рамках совпадающих префиксов, потом пишем результирующий файл.
Вижу несколько слабых мест:
Первое это то, что такая сортировка не заработает если все строки одинаковы. Как вообще гарантировать что блок сортируемых строк с одним префиксом влезет в память?
Второе это нелинейное чтение исходного файла при формировании результата. Я делал вариант своей программы, когда ее сохранял строки в промежуточном файле, а сохранял только их смещение и длину в исходном (ветка only-keys). Я результата для 10гб не дождался.
От нелинейного чтения скорость падает на порядок

vadimr
03.02.2023 17:27+5Достаточно вместо номера строки держать в ключе её смещение в файле, и проблем с переменной длиной не будет.
В общем, эта задача очень напоминает индекс нодлиста в фидонете, что заставляет предположить в её авторе фидошника :)
gandjustas Автор
03.02.2023 19:34+1Я делал такое решение https://github.com/gandjustas/HugeFileSort/tree/only-keys
Можете запустить и сравнить производительность.
adeshere
03.02.2023 21:40+3что заставляет предположить в её авторе фидошника :)
Как говорил Андрей Миронов, если Вы ясновидящий, предупреждать надо ;-)
Да, я застал ФИДО
но только и исключительно как тупой пользователь этих благ. Конкретнее говоря, я там искал партнеров, чтобы оптом купить походную пилу-цепь: они тогда только появились и в розницу было дорого, а оптом выходило кратно дешевле. Спасибо Андрею Ч., который все это организовал! (Кстати, он до сих пор регулярно организует так называемый ММБ - спортивное ориентирование на два дня и сто километров, которое дважды в год собирает от 1000 до 2000 участников).
А вообще, по моим скромным воспоминаниям, среди пользователей этих эх туристов (в том числе и IT-шников) было значительно больше, чем просто IT-шников (не-туристов).Но может быть и аберрация личного восприятия, ведь тогда и экраны были зеленее, и клавиатуры щелкали громче, и подставка для кофе из компьютера выезжала быстрее.
P.S. Интересно, а какой процент современных IT-шников знает, для чего те компьютеры комплектовались подставкой для кофе? ;-))))
vadimr
03.02.2023 21:50+1Наши люди :)
Но я первоначально имел в виду человека, который придумал эту задачу.
adeshere
03.02.2023 17:50+1Первое это то, что такая сортировка не заработает если все строки одинаковы.
Разумеется. Вот поэтому я и написал, что было бы здорово получить какую-то априорную инфу про эти строки сразу при при получении тестового задания. По крайней мере, я бы попытался задать этот вопрос
Как вообще гарантировать что блок сортируемых строк с одним префиксом влезет в память?
Гарантировать - никак. Есть только шанс, вероятность которого, опять-таки, зависит от содержания текстов. Но если мы вдруг действительно этот шанс выиграем - то прирост скорости сортировки будет очень серьезный.
Но даже если не влезет, то мы все равно имеем альтернативу между сортировкой 100ГБ и 10ГБ. Мне почему-то кажется, что второе должно быть заметно быстрее ;-)От нелинейного чтения скорость падает на порядок
Разумеется. Это один из главных вопросов моего варианта.
Я исхожу из того, что любая сортировка, выходящая за размер ОП, определенно потребует такого нелинейного чтения на каком-то этапе. Либо из одного большого файла, либо из множества маленьких. Ведь в итоге нам в любом случае придется переставлять строки, которые в исходном файле были весьма далеки друг от друга.
Конечно, при слиянии файлов они оба читаются последовательно. Но ведь таких слияний придется делать довольно много (каждую запись придется прочитать логарифм раз, причем чтение всегда идет сразу из минимум двух разных файлов, и на каком-то этапе каждый из них перестает помещаться в ОП). Если эти файлы вдруг окажутся на одной пластине, то головки буду дергаться не хуже, чем при рандомном чтении из одного мегафайла...
С другой стороны если наш большой файл раскидан по множеству пластин (дисковая подсистема сообразила, что мы собираемся замутить рандомный доступ, либо ей кто-то это каким-то способом подсказал) то, на мой непросвещенный взгляд, время доступа вроде бы должно уменьшаться пропорционально числу пластин? В общем, тут было бы интересно послушать специалиста.
Но в целом я совершенно согласен, что аргумент про рандомное чтение очень веский. Вопрос лишь в том, ставит ли он автоматически крест на идее такой сортировки или все-таки нет. Ведь и альтернатива - совсем не безупречное O(N).
gandjustas Автор
03.02.2023 19:47+1Разумеется. Вот поэтому я и написал, что было бы здорово получить какую-то априорную инфу про эти строки сразу при при получении тестового задания. По крайней мере, я бы попытался задать этот вопрос
Нет априорной инфы, в этом и суть задачи. Оптимизация под частные случаи тоже так себе идея.
Но даже если не влезет, то мы все равно имеем альтернативу между сортировкой 100ГБ и 10ГБ. Мне почему-то кажется, что второе должно быть заметно быстрее ;-)
Но вы все равно сортируете N строк, только для ключа берете не всю строку, а часть. Такая оптимизация на практике не сильно полезна, так как сравнение векторов оптимизируется SIMD (по крайней мере в .NET) и обычная быстрая сортировка выигрывает у поразрядной.
Я исхожу из того, что любая сортировка, выходящая за размер ОП, определенно потребует такого нелинейного чтения на каком-то этапе.
Если вы посмотрите внимательно мой код - там нет нелинейных чтений. В этом и есть фишка алгоритма слияния, что он не требует рандомных чтений файлов. Во времена когда алгоритм придумывали еще не было префетчингов и реальное перемещение головки чтения-записи выполнялось за наблюдаемое глазом время.
Конечно, при слиянии файлов они оба читаются последовательно.
Только не оба файла, а все сразу. Сегодня у нас много памяти и мы удержать в памяти элементы из десятков и даже сотен тысяч файлов. Для сортировки 100гб (даже 500гб или 1ТБ) не требуется попарное слияние. Но даже при попарном слиянии все чтения и записи будут линейными
С другой стороны если наш большой файл раскидан по множеству пластин
Много пластин это из далекого-далекого детства. Сейчас подавляющее большинство дисков с одной пластиной, изредка с двумя. Описанная вами схема может быть в RAID 5 или 6 (не помню точно), но они очень непопулярны и вы скорее найдёте рейд-массивы где данные тупо дублируются.
vadimr
03.02.2023 20:47+1В этом и есть фишка алгоритма слияния, что он не требует рандомных чтений файлов. Во времена когда алгоритм придумывали еще не было префетчингов и реальное перемещение головки чтения-записи выполнялось за наблюдаемое глазом время.
Это верно, но тогда у компьютера было много независимых устройств внешней памяти (дисков и лент). Алгоритм слияния изначально рассчитан на то, что каждый из кусков записывается на отдельный диск или ленту. В случае одного диска рандомные перемещения головки всё-таки будут, но не в пределах одного файла, а между файлами.
adeshere
03.02.2023 20:50Много пластин это из далекого-далекого детства.
Спасибо за ликбез! Не знал. Я последний раз в этой теме копался примерно тогда же (с разницей в несколько лет), когда увидел свой первый персональный компьютер. Кстати, про него на днях написали вот в этой статье на Хабре. Он там на фото 1.
Оптимизация под частные случаи тоже так себе идея.
Ну я-то скорее оптимизировал под достаточно общий случай. Но вот в некоторых крайних случаях (все строки одинаковые и др.) мой алгоритм будет ужасен ;-)
Если вы посмотрите внимательно мой код - там нет нелинейных чтений.
(...)
Только не оба файла, а все сразу.Да, конечно, тут я криво выразился. Я сперва хотел порассуждать про крайний случай попарных слияний, чтобы пояснить идею, а потом уже обобщать на слияние n файлов сразу. Но на самом деле это не важно. Ведь если у нас есть n небольших файлов на одной пластине, и нам надо поочередно взять по одной записи из каждого такого файла, то головки будут поочередно дергаться к каждому из этих файлов. Так как в кэше они, по условиям задачи, не помещаются. То есть несмотря на последовательное чтение каждого отдельного файла, у нас фактически будет то же самое чтение из рандомно расположенных мест на диске.
Так вот, мой вопрос сводился к тому, будет ли разница в скорости чтения
а) n таких записей из n разных файлов, и
б) при чтении тех же самых n записей из разных мест одного файла?
Интуиция мне подсказывает, что это может зависеть от настроек кэширования диска, но в общем случае принципиальной разницы быть не должно. Или нет?А ведь прежде, чем проводить сортировку слиянием, нам еще надо каждый из этих n файлов рассортировать внутри себя... Так что какого-то однозначного выигрыша у алгоритма с предварительной сортировкой ключей я тут пока не вижу. Особенно если с ключами нам повезло, так что они влезли в ОП и рассортировалсь "бесплатно"
gandjustas Автор
03.02.2023 23:51+1Ну я-то скорее оптимизировал под достаточно общий случай. Но вот в некоторых крайних случаях (все строки одинаковые и др.) мой алгоритм будет ужасен ;-)
Если вы хотите посоревноваться, то нужно сделать не хуже стандартного Array,Sort в среднем случае, то есть на случайных входных данных.
Ведь если у нас есть n небольших файлов на одной пластине, и нам надо поочередно взять по одной записи из каждого такого файла, то головки будут поочередно дергаться к каждому из этих файлов.
Это немного не так работает. Чтение в рамках одного диска контроллер выстраивает последовательно в рамках движения головок ( для HDD). Например вы заказываете чтение секторов 15, 8445, 2 (в любой последовательности), контроллер диска вам заполнит память для секторов 2, 15. 8445 именно в такой последовательности.
А ОС умеет делать pefetch: видя что вы читаете файл последовательно она в очередь чтения с диска ставит следующие сектора файла, независимо от того будете вы читать их или нет. Если вы перемещаете указатель чтения\записи файла (fseek), то весь префетч идет нафиг. И это работает для любого количества открытых файлов.
Поэтому есть разница - читать последовательно N файлов (работает prefetch), или читать рандомно из N мест одного файла. Первое будет быстрее.
Кроме того в моем коде при чтении из N промежуточных файлов используется большой прикладной буфер и реальное чтение доходит до диска один из 10 раз.
А ведь прежде, чем проводить сортировку слиянием, нам еще надо каждый из этих n файлов рассортировать внутри себя...
Они сортируются в памяти прежде чем записать на диск
adeshere
05.02.2023 02:02+1Если вы хотите посоревноваться,
Спасибо за дружеский троллинг ;-) Я ведь написал, что я тут совсем-совсем крокодилмимо, и не претендую на работающее решение - для меня это скорее тренировка ума из серии Занимательные задачки. Один только
мой глюк
про перестановку строк (вместо перестановки указателей) уже однозначно показывает степень моей некомпетентности. Хотя справедливости ради,
в очень далеком DOS-прошлом
когда я сам писал сортировку за неимением подходящей функции в стандартной библиотеке, я все же сообразил, что сортировать нужно именно указатели, и даже сумел эмулировать их на фортране, где такого инструмента тогда еще не было. Но вот сейчас 100ГБ-файлы, заполнившие мою ОП в голове, вытеснили это знание куда-то в глубокий свопинг ;-)
Это я к тому говорю, что Вы не зря потратили свои силы на разбор моих ошибок: есть надежда, что я смогу чему-то на них научиться. Хотя конечно, умный человек пользуется для этого чужими ошибками... Возможно, и мои тоже кому-нибудь пригодятся?
Но в целом, довольно неожиданно (и приятно), что некоторые сугубо абстрактные идеи, появившиеся у меня "из первых принципов" (без малейших знаний предметной области), оказались не совсем уж бредовыми.
Так что спасибо за предложение, но я совсем не горю желанием войти в историю, как провокатор, вынудивший Вас всерьез (на уровне, близком к коду) разбирать нелепости моих предложений. Вы же не хотите заслужить репутацию человека, который конфеты у детей отбирает ;-) За проведенный здесь час я узнал про разные технические нюансы много больше, чем мог бы раскопать в интернете при самостоятельном обучении ;-) Спасибо еще раз за статью и индуцированное ей обсуждение, полезное и интересное для читателей с самым разным уровнем погружения в тему.
adeshere
03.02.2023 21:10Но вы все равно сортируете N строк, только для ключа берете не всю строку, а часть. Такая оптимизация на практике не сильно полезна, так как сравнение векторов оптимизируется SIMD (по крайней мере в .NET) и обычная быстрая сортировка выигрывает у поразрядной.
Я, видимо, плохо описал свою идею. Если бы речь шла только об экономии на операции сравнения, то игра, вероятно, не стоила бы свеч (ведь потом все равно придется сортировать внутри блоков). Точнее, такая оптимизация была бы, наверно, полезна, но лишь для для некоторых наборов данных.
Но мне сперва показалось (прошу прощения, если я не прав - язык я не знаю, и код не читал), что в процессе сравнения Вы больше одного раза переставляете строки. Поэтому второй (или даже первый) краеугольный камень моей оптимизации состоит в том, чтобы избежать лишних манипуляций с длинными строками. Мое предложение сводится к тому, чтобы прочитать эти длинные строки один раз (последовательно) в самом начале работы, а затем основную часть операций проделать с гораздо более короткими эквивалентами этих строк. И получить выигрыш грубо за счет того, что эти новые строки намного короче. (Кстати, никто не мешает эти короткие строки отсортировать именно с помощью Вашего эффективного алгоритма вместо одной из стандартных библиотечных быстрых сортировок).
А уже на заключительном этапе, когда нам надо сгенерировать итоговый файл из длинных отсортированных строк, снова лезем в эти 100Гб и кошмарим диск и процессор ;-)
Как я понял из обсуждения, идея в целом получилась рабочая, но, конечно же, не бесплатная. Так как выигрыш в ходе основной сортировки потом аукнется необходимостью сортировки записей внутри блоков с одинаковым значением ключа у всех записей. И вот если в этот момент нам навстречу радостно выбежит наихудший возможный случай, то вся заранее выполненная работа окажется пустой тратой времени.
Впрочем, большого проигрыша тут тоже не должно быть, если, конечно, эту внутриблочную сортировку выполнять с помощью Вашего алгоритма, эффективно справляющегося именно с этой задачей?
gandjustas Автор
03.02.2023 23:52+2Но мне сперва показалось (прошу прощения, если я не прав - язык я не знаю, и код не читал), что в процессе сравнения Вы больше одного раза переставляете строки.
Переставляются только указатели на строки.

edo1h
05.02.2023 15:57А уже на заключительном этапе, когда нам надо сгенерировать итоговый файл из длинных отсортированных строк, снова лезем в эти 100Гб и кошмарим диск и процессор ;-)
это будет очень медленно.
для каждой строкой длиной в десятки байт вам нужен поиск места на диске, время которого на hdd грубо 10 мс, это время последовательного чтения 10 мегабайт.
то есть случайное чтение для переборки файла в нужном порядке оказывается на 5 порядков медленнее первоначального линейного!

Stavr666
05.02.2023 16:14Описанная вами схема может быть в RAID 5 или 6 (не помню точно), но они очень непопулярны
Raid 5/6 - это буквально любой SAN, программный или аппаратный. Т.е. все prod-сервера, включая бэкэнд облачного стораджа.

kuznetsovkd
04.02.2023 12:32+1Тоже вчера про это думал, но всё это упирается в простую истину - это не более чем попытка написать свою базу данных. Скорее всего это выйдет быстрее чем загнать всё в готовое решение так как будет чуть меньше ненужных телодвижений, но в конечном итоге всё упрётся в неэффективность такого решения из-за разности скорости последовательного и выборочного чтения.
И вот тут даже сверх быстрый ssd потеряет в своей производительности потому что его максимальная скорость достигается только во время последовательного чтения.
Из всего этого есть простой вывод, что стоить таблицы и создавать ключи выгодно только в том случае когда вы собираете данные, а если нужно работать с уже готовыми данными - вариантов не много.

thesame
04.02.2023 14:40Я начал думать примерно также: сначала, на первом проходе, мы строим индекс, который потом сортируем, а потом, используя индекс, читаем строки и пишем их в нужном порядке в выходной файл, дополнительно сортируя строки с одинаковым ключом. Проблема в том, что для сравнительно коротких строк (50-80 символов в строке) размер индекса будет сравнимым с исходным файлом. Я заложился на то, что индекс содержит - первые четыре байта строки (uint32), смещение от начала файла (uint64), длина строки (допустим, максимум 65535 - uint32), crc32 (uint32). Итого - 20 байт. Если средняя длина строки - от 250 байт и память 8 Гб, то максимум за 2 прохода мы получим количество необходимых блоков (уникальных ключей) и их размеры.
А вот дальше начинается самое интересное: нам надо как-то выбрать количество и размеры входных и выходных буферов, чтобы минимизировать количество операций чтения-записи на диск. Тут я слегка подзавис... Пока, навскидку, надо сначала найти ключи, для которых выходные блоки будут с 1) максимальным количеством строк и 2) максимальным объемом, потом отсортировать эти ключи, чтобы строки с ними попадали в минимальное количество входных блоков... после первой итерации отсортировать оставшиеся ключи...
В-общем, интуитивно все кажется понятным и простым, но при реализации, боюсь, возникнут нюансы. :) Интересно было бы посмотреть это все на какой-нибудь модели (если будет время).

kisskin
04.02.2023 23:18+20. 4 байта строки
1.1. если храните смещение, то длину строки не нужно. если длину, то смещение не нужно, но расчет смещение будет занимать заметное время. Допустим 8 байт.
1.2. длина строки (допустим, максимум 65535) это 2 байта
2. цифры до точки. 2 байта
Итого 8 или 14 байт. Если считать строки как досовый формат в 80 символов, то экономия в 5-10 раз, если как типичные предложения 400 символов, то экономия в 30-50 раз. И предположительно, можно будет легко отсортировать в памяти без всяких выкрутасов.Да, я не понял, а зачем crc32?
kisskin
04.02.2023 20:50+1Тоже сразу о таком варианте подумал. И строки можно не фиксированной длины, если сохранять значение их длины.

{kind=link}
LordDarklight
03.02.2023 13:22+9Далеко не первая статья на Хабре, посвящённая оптимизации сортировки. Но , наверное, первая, где и объёмы задачи хоть немного достойные BigData (хотя 100Гб это это ещё очень и очень условный BigData - тут бы хотя бы на порядок объёмы поднять - вот тогда точно будет BigData - и даже ещё вполне моделируемый в домашних условиях). Впрочем 100Гб - это не 100Мб - и тут уже начали проявляться всякие тонкие места работы с действительно большими данными, и началась соответствующая оптимизация.
Собственно в этой статье больше внимания как раз уделено как раз тонкостям обработки больших данных, чем оптимизации самой сортировки (где автор взял типовую реализацию). Это и хорошо и плохо. Но скорее хорошо - это более практическая задача, чем копания в тонкостях того, как ещё можно было бы оптимизировать алгоритм сортировки чанка под подставновку задачи. Этим эта статья хорошо себя противопоставляет предыдущую похожую статью, ссылку на которую хорошо было бы привести в начале - там акцентировали то, что ввод-вывод не узкое место и даже не добрались до распараллеливания - а в текущей статье автор как раз вывел это в узкое место - но понятно - объёмы данных то совсем иные.
К сожалению, в статье не нашлось места каким-то продвинутым логическим алгоритмам оптимизации сортировки и слияния - нет ни хешей, ни словарей, ни бинарных деревьев, ни статистических гистограмм. Хотя применение техники ключей сравнения тут многого стоят и, для решения задачи этого оказалось достаточно - цель то с лихвой досигнута.
Так же за боротом остались и нюансы аллоцирования непрерывных пространств памяти - в первую очередь для файлов - что тоже важно при работе с большими данными.
Ну и жалко, что автор так и не привёл описание тестового стенда - хотя с со скриншотов таскменеджера можно частино узнать что тестовая машина не хилая - 64Gb ОЗУ, 3.6Гц камень (под бустом аж до 4.75Гц - интересно это с каким охлаждением такой разгон в многопоточном приложении) с 8 ядрами. Тестовый диск то хоть HDD (хотя система вероятно на SSD стоит, интересно - временные фалы точно на HDD создаются - но наверное да - вроде бы в том же каталоге, где и исходный файл).
ОЗУ , конечно, распараллеленное приложение жрёт немеренно. Это и хорошо и плохо - с одной стороны при такой нагрузке на остальные ресурсы экономить память смысла нет, с другой - в серверном исполнении, при числе ядер от сотни общая нагрузка на ЦП уже будет не такая большая (всё упрётся уже, скорее всего в ввод-вывод), но тут уже две стратегии возможны:
Оставляем ресурсы ЦП для других задач - если это универсальный сервер с распаренными сервисами для многих - тогда и памяти им тоже бы лучше оставить побольше (хотя тут уже гибкое управление памятью нужно)
Либо наоборот - берём всё что есть - тогда можно сэкономить на операциях ввода-вывода и чанках - просто перенеся все файлы в память - коли всё влезет (ну или столько, сколько влезет). Постепенно высвобождая уже обработанную память (выделяя на её месте новые буферы - если все не влезли).
Хотя, при БигДата скорее всего не стоит рассчитывать на выделение памяти сразу подовсё. Как и при БигДата - скорее всего данные будут подавать и возвращаться (и даже скорее всего временно буферизироваться) на отдельных микросервисах - и эти операции заметно просядут по производительности. И тут нужна будет уже дополнительная оптимизация, чтобы сократить операции ввода вывода.
В любом случае статья получилась очень хорошая - автору большой респект
gandjustas Автор
03.02.2023 13:39+1Предыдущую стать не читал, спасибо за ссылку, посмотрю, может чего добавлю.
Алгоритмическая оптимизация получилась в итоге одна - с использованием кучи для слияния. Все остальное не помогло, встроенная в .net сортировка достаточно хороша (в исходниках есть бенчмарки)
Также можно считать оптимизацией алгоритма формирование одного массива - ключа сортировки. Этот подход можно обобщить на любое количество ключей.
Расход памяти, если придется на практике сортировать такие объемы, зависит от степени параллелизма. Хочется быстро - сожрёт пару десятков Гб, хочется малый расход памяти - запускаем последовательно, сожрёт не более суммарного размера ключей и строк в чанке.
Над способами уменьшить расход в параллельном случае много думал, но вариантов не придумал совсем.
LordDarklight
03.02.2023 15:21+1Над способами уменьшить расход в параллельном случае много думал, но вариантов не придумал совсем.
Способов знаю только два:
Ужимать сами данные в памяти - тут нужна хорошая функция построения весовоых коэффициента, и применения сжатия данных
Увеличивать повторное использование памяти - лично я не смог понять почему так быстро растёт память - при чанках в 50мб и где-то 32 потоках как возникают объёмы расхода памяти в более чем в 10 раз больше в среднем на поток.
gandjustas Автор
03.02.2023 15:35+1В какой момент ужимать? Строки нам нужны в несжатом виде чтобы получить ключ, ключи нам нужны в несжатом виде чтобы сортировать. Сразу после сортировки данные ужимаются.
Память и так повторно используется за счет пула. В дебаггере показывает 9 буферов при dop=1. Объем может расти по следующим причинам: gc неохотно освобождает страницы для ОС, возможно за счет пиннига объектов для вызовов gc плохо освобождает память, память съедает BrotliEncoder, он реализован в неуправляемом коде.
Возможно все-таки последний запуск был при чанках по 100мб, потому что замеры я вставлял уже после написания статьи и код мог слегка отличаться.
Я думаю надо реализовать программу на языке без GC и сравнить результаты. Сам планирую это сделать на Rust.
gandjustas Автор
03.02.2023 13:50+1Прочитал статью по ссылке, в целом она верная, но не полная.
Чтение данных редко оказывается узким местом, а вот запись часто. Операции в памяти можно распараллелить, а io нет. Поэтому в простых задачах io не будет узким местом, а сложных - будет.
screwer
03.02.2023 14:25тестовая машина не хилая - 64Gb ОЗУ, 3.6Гц камень (под бустом аж до 4.75Гц
Что тут "нехилого" ?
Мой домашний комп, самый обычный, куплен в начале 2017, имеет 4 ядра на 4,5ггц (7700к + настройка в биосе, обходящая ограничение турбобумста). 64гб.
Рабочий комп, собран в 2019. Имеет 6 ядер на 5ггц (8700к из 2017года + небольшой разгон)
Дома есть несколько двухпроцессорных серверов на БУ зионах. Сейчас стоимость процессоров + матплаты + памяти вряд-ли превышает 50тр.. Т.е.дешевле среднего нового ноутбука. А это 36 ядер на 3,3 и 256гб оперативки.

aamonster
03.02.2023 13:39+1А в статье точно описана сортировка слиянием? Потому как то, что автор "отбросил идею нескольких прогонов для объединения блоков" выглядит как переход к совершенно другому алгоритму (причём с ограничением на размер данных, хотя и куда более мягкому, чем размер оперативной памяти).
P.S. Спасибо за ключи сортировки юникодных строк, может пригодиться.
gandjustas Автор
03.02.2023 13:45Точно сортировка и именно слиянием. Просто изначально алгоритм описывался когда объем памяти был такой, что уместить все итераторы было невозможно.
В нашем случае даже при 10 000 чанков мы можем все итераторы уместить в памяти.
Можно считать это оптимизацией для частного случая, но этот частный случай на практике встречается чуть чаще, чем всегда.

astypalaia
03.02.2023 14:22Хорошее задание. Надо взять на заметку. Абсолютно бессмысленное с практической точки зрения (в смысле никто не скажет, что компания за бесплатно хочет решить техническую проблему), но сможет много поведать о кандидате - с разных точек зрения. Соискатели, держитесь!

lrrr11
03.02.2023 16:21+1были ли попытки сравнить производительность с GNU sort или чем-то таким? А ещё оптимизация чтения с диска, чтобы не возникало лишних аллокаций в ядре ОС - это вообще кроличья нора. Вот советую почитать, чтобы оценить ее глубину: https://itnext.io/modern-storage-is-plenty-fast-it-is-the-apis-that-are-bad-6a68319fbc1a
gandjustas Автор
03.02.2023 19:49Пока не пытался гоняться с кем-то. Цель была решить задачу на моем железе с таким запасом, чтобы и более слабое железо тоже могло потянуть.
Статью прочитал, но, увы, не понял. Она про какие-то технологии, которыми я не владею. Да и для этой задачи обычных синхронных вызовов чтения\записи файла вполне достаточно на любой ОС.

mixsture
03.02.2023 16:53+2При абсолютной неясности о тестовом стенде — также абсолютно неясно в какую сторону оптимизировать алгоритм. Толи можно активно размещать вспомогательные данные в памяти, толи нет. Толи там хороший проц и доступны сильные сжатия, толи нет. Толи там дисковая подсистема с запасом мощности, толи нет. Толи мы можем заранее покопаться в данных, выделить высокоселективные части данных, остальные выкинуть, толи нет.
Такие абстрактные задачи плохи тем, что всегда можно подобрать набор оборудования и внешних факторов, на котором текущий подход провалится, а соседний заработает.gandjustas Автор
03.02.2023 20:00Не очень понимаю что вы хотите сказать.
Вы хотите найти условия, при которых мой подход сработает плохо, но при этом вы можете придумать подход, который при этих же условиях сработает лучше?
Предложите этот подход. Чтобы он был в среднем не хуже того, что я описал, не изменяя условия задачи.

event1
03.02.2023 17:11+1await foreach (var (buffer, bufferLength) in compressToWrite.Reader.ReadAllAsync()) { var tempFileName = Path.ChangeExtension(file, $".part-{tempFiles.Count}.tmp");Кажется, два потока могут создать временные файлы с одинаковым именем.
В целом — крутая статья и крутое решение.
gandjustas Автор
03.02.2023 19:50+1Конечно может. Поэтому поток писателя один. Да и писать в параллель много файлов на один диск не выглядит здравой идеей.
Meloman19
03.02.2023 18:35Если сортировка строк подразумевает именно сортировку по коду каждого символа, то вроде как UTF-8 можно напрямую как массив байт сортировать - выйдет то же самое. Так можно избавится от лишних преобразований в string.
gandjustas Автор
03.02.2023 19:58А если не подразумевает, то что вы делать будете?
В условиях не было сказано какая должна быть сортировка, поэтому может быть любая юникодная.
Meloman19
03.02.2023 20:24То это уже другая задача. В рамках этой можно и массивы сравнить.
Я не говорю, что вы неправильно делаете. Просто указываю на интересный момент.

DirectoriX
03.02.2023 23:43Поскольку это задача на собеседовании, то
В условиях не было сказано какая должна быть сортировка
— не аргумент, потому что задание всегда можно уточнить. Если ответят, что без разницы — вы как автор кода вольны использовать любую, в том числе и побайтовую, в том числе в порядке, обратном алфавитному (потому что это абсолютно корректная сортировка, а «по возрастанию» нигде не сказано). А на простой аргументНе будет простых способов вернуться к UCA без потери быстродействия.
есть простой ответ: новые ограничения = новая, другая задача.gandjustas Автор
04.02.2023 00:44Слушайте, ну не получилась бы такая интересная статья если бы все свелось к Ordinal сортировке.

joeblack3108
03.02.2023 19:50Для работы с файлами таких размеров есть Memory-Mapped Files https://learn.microsoft.com/en-us/dotnet/standard/io/memory-mapped-files Уже давно с ними не работал, но раньше разница была значительной
gandjustas Автор
03.02.2023 19:51Вы можете попробовать сделать свое решение на этих файлах. Возможно у вас получится быстрее. Правда непонятно какой это даст выигрыш при сортировке строк.

Rusrst
03.02.2023 20:09О да, в них ещё в книге системное программирование для windows рассказывали, как же давно это было...
aamonster
04.02.2023 01:53Разница могла стать значительной при неудачном алгоритме работы с файлами – поскольку слой работы с ними отдаётся откуп системе (в разработку которой вложена уйма труда). Если нормально оптимизировать файловый ввод/вывод – разницы быть не должно.

DBalashov
05.02.2023 07:46Я кстати и на MMF пробовал делать этот вариант задания, получалось прилично медленее (~в 1.5-2 раза), чем с обычными файлами

Powercore
03.02.2023 19:52В этой конторе наверно всему дают это задание. Мой рекорд 1гб за 85 секунд на i5 ноуте с ssd. Памяти почти не жрет, алгоритм простой, сортирует диском, работает со строками любой длинны. Для серверного решения где везде сейчас твердотелы - пойдет.
gandjustas Автор
03.02.2023 19:56Можете название конторы озвучить?
1Гб это величина, которая влезает в ОП полностью, поэтому на таком объеме эффекты чтения с диска не проявятся.
Powercore
03.02.2023 20:02Если честно я не помню название. Это было два года назад. 1 гб я сгенерировал сегодня просто на бенчмарк глянуть. Можно и 10 и 100 гб сделать и прогнать, не принципиально. Были идеи как улучшить используя хэш деревья, но я забил.
vkni
03.02.2023 20:29А просто mmap и qsort работают на NVME SSD? Ну если строки сделать одной и той же длины в памяти.
DBalashov
05.02.2023 00:40Мой результат:
Исходный файл: 1 GB
Строк: ~19 млн (~ 55 символов в строке)
Использование памяти: 550 MB в пике
Время: ~24 сек разделение на партишены + 18 сек на слияние = ~42 секi7 (11й серии) с nvme SSD. Кода было значительно меньше, чем у топикстартера. span'ы не использовал, при чтении находил индекс разделителя и сохранял в памяти, а после использовал string.Compare с StringComparison.Ordinal и overload с указанием индекса начала сравнения и длины
Слияние сделал с помощью SortedSet<T>. Оффер получил, год там проработал :)Powercore
05.02.2023 09:12Как здорово что мне оффер не прислали :) алгоритм по сути такой же как у меня.
vadimr
03.02.2023 20:14Для достижения наиболее высокой производительности на таком объёме сортируемых данных надо делать всё на массивах в статической памяти, никаких динамических структур.
А для начала надо уточнить, что в понимании заказчика значит “отсортировать файл”. Является ли файл с построенным индексом отсортированным, или надо его непременно переписать в другой последовательный файл?
Ну и очень многое зависит от характера данных, как верно заметили выше.
Powercore
03.02.2023 21:04На входе файл где в каждой строке идет: xxxxxx. Yyyyyyyy, где xxxxxx - произвольное число, yyyyyyyyy - произвольный текст. Сортировка сначала по тексту потом по числу. Результат - отсортированный файл.
vadimr
03.02.2023 21:05Речь о том, как распределены значения этих строк. И что мы, кстати, оптимизируем по времени – матожидание или наихудший случай?
Powercore
03.02.2023 21:27Случайно они распределены. Например в первой строке «23412. Хорошая погода», во второй: «12. Четыре с боку наших нет» и тд
vadimr
03.02.2023 21:47Это удобный для оптимизации вариант. А если строки различаются где-нибудь в сотом символе, или большинство из них вообще одинаковые - будет неудобный.
gandjustas Автор
04.02.2023 00:32Для достижения наиболее высокой производительности на таком объёме сортируемых данных надо делать всё на массивах в статической памяти, никаких динамических структур.
Почему?
Является ли файл с построенным индексом отсортированным, или надо его непременно переписать в другой последовательный файл?
Надо переписать
Ну и очень многое зависит от характера данных, как верно заметили выше.
Характер данных - случайный
vadimr
04.02.2023 08:43На управление памятью уходит много процессорного времени.
Случайный - это недостаточно точный ответ в данном случае. Надо понимать распределение.
gandjustas Автор
04.02.2023 14:00Много это сколько? По сравнению с сортировкой и сжатием данных, не говоря уже о времени чтения-записи
vadimr
04.02.2023 14:07У вас, судя по вашему профилированию, ввод-вывод загружен где-то на одну треть или менее. Это результат, который можно попробовать значительно улучшить. Думаю, что где-то от 25% до 50% процессорного времени занимает управление памятью. А может быть и больше.
gandjustas Автор
04.02.2023 16:48ваша оценка завышена на порядок, возможно на два
вы можете показать свой вариант со статической памятью, который работает на 50% быстрее.

Dart55
03.02.2023 22:53Если дописать в конец полученного массива байты числа, стоящего в начале, то мы можем всю сортировку свести к сортировке байтовых массивов.
Разве это будет правильно работать "most significant digit (MSD) or least significant digit (LSD)" [b, ba, c, d, e, f, g] [1, 10, 2, 3, 4, 5, 6, 7, 8, 9]
gandjustas Автор
04.02.2023 00:00да, главное записывать число, чтобы в начале шел страшный байт, а потом младший.
в .NET это делается функцией
BinaryPrimitives.WriteInt32BigEndian

gchebanov
03.02.2023 23:30+1Т.к все строки из небольшого пула, можно засунуть их в небольшую структуру данных и отсортировать потом.
Написал на плюсах, сейчас посмотрю сколько работает, на 10Gb всего 100 секунд cpu time. Так как исходные строки длинные (avg=231), их таким образом мало (всего 463'523'186 у меня), можно попробовать поместить в память, у меня это tuple<u64,u32,fixed_string<10>> (24 байта) на строчку (это 10% от данных). Продублировал числовой ключ в строке что бы вывод был побыстрее.
P.S.
код итого 24 минуты. В любом случае явно упирается в диск.gandjustas Автор
04.02.2023 00:30Это все потому что у вас вместе с N*logN операций в памяти появились также N*logN операций с диском.
Файл вы читаете не UTF8 и UCA не используете
gchebanov
04.02.2023 01:44По диску только 2(3) прохода, NlogN+NlogM только в памяти. NlogN операций с диском я бы не дождался и за 10 часов. 100Gb*2/(170Mib/s) - это уже 20 минут.
Сравниваю действительно побайтово, у файлов от автора явно какие-то проблемы с кодировкой, source.txt вообще в cp1251. Забавно что сравнение с учетом utf вообще не повлияет на скорость, так как сравниваться будет очень маленькое число уникальных строк (
all_keys=16137) Место для компаратора тут, поленился скачивать библиотеку только из-за того что это ни на что не повлияет.gandjustas Автор
04.02.2023 01:56string_view при сравнении у вас обращается к области памяти в mm-файле. А это, видимо, создаёт обращения к диску. Не каждый раз конечно, но порядок обращений O(N * logN).
Никаким други способом я не могу объяснить такое время работы. Кстати посмотрите прямо в таск менеджере количество байт ввода-вывода для процесса. Если превышает объем файла, то это плохо.
gchebanov
04.02.2023 02:00изначально действительно было так
map<string_view, u64> all_keys;И в мапчике лежали вьюхи на случайные (скорее всего в пределах первых мегабайт, но всё равно) части диска, сейчас происходит копирование.
map<string, u64, less<>> all_keys; auto get_key(string_view key) {Аргумент
get_keyэто линейное чтение с диска.Так какая проблема с временем работы? Это просто два прохода по 100 Gb, сколько просили столько получили. Так еще и ядро не нагружено.
P.S.
На10Gbчуть быстрее выходит, это правда, в 1.4 раза от линейной интерполяции100Gb, тут наверняка кеширование смазывает картину.gandjustas Автор
04.02.2023 02:17Запустил на своем компе на 10 ГБ файле:
total_proc=184067 ms. total_output=398044 ms.Общее время 6:37
Учитывая что не UTF8 и не UCA - хороший результат.
.NET код из ветки https://github.com/gandjustas/HugeFileSort/tree/reduced-allocations при Ordinal (посимвольном) сравнении показал результат:
SplitSort done in 00:02:02.1302621 Merge done in 00:01:22.2265601Общее время 3:25
Это при том что он пишет и читает в два раз больше, но линейно.
gchebanov
04.02.2023 02:29vec_keys.emplace_back(key);
в этот момент происходит аллокация и копирование т.к.vector<string> vec_keys.
Всё сортировка занимает миллисекунды, т.к тут только 16к элементов.
gchebanov
04.02.2023 02:30page faults для линейного чтения mmap файла это нормальное дело.
gandjustas Автор
04.02.2023 02:39Суммарно около 7M page faults, что примерно 28гб поднимает с диска.
gandjustas Автор
04.02.2023 02:31нелинейное чтение с диска у вас тут:
sort(idx.begin(), idx.end(), [&] (u64 i, u64 j) { return vec_keys[i] < vec_keys[j]; // TODO add utf-8 compare });gchebanov
04.02.2023 02:34https://en.cppreference.com/w/cpp/string/basic_string/basic_string
смотреть 10 конструктор.
Везде где есть string - это строка в куче.
Здесь сортируется 16к строк в памяти, за ~5ms.gandjustas Автор
04.02.2023 02:38Тогда не ясно почему так долго сортируется.у меня сортировка вместе с записью на диск вы выполняется быстрее чем построение индекса у вас.
gchebanov
04.02.2023 02:40Попробуйте -O2.
gandjustas Автор
04.02.2023 02:43Я не умею в cmake, студия как-то сама собрала. Залейте проект с нужными флагами компилятора, utf8 и uca, чтобы сравнивать яблоки с яблокамм
gchebanov
04.02.2023 02:50add_compile_options("-O2")
Скорее всего где-то можно выбрать Release вместо Debug.
gchebanov
04.02.2023 04:33можно сравнивать, скорость не изменилась (сортировка теперь вместо 5ms 30ms), разве что теперь форсится Release. Ну и я предполагаю что все строки разные с точки зрения сортировки всегда записаны каким-то одним образом, (по сути нет нормализации).
gandjustas Автор
05.02.2023 00:34На 10Гб
total_output=95482 ms.1:35
На 100ГБ
total_output=1.55993e+06 ms. sys=1559841 ms.26 минут, скушал 30+ гб.
В принципе даже на 100Гб накладные расходы на mm файлы невелики оказались
Расход памяти вызывает опасения, если все строки будут разными, то превысит доступный объем ОП.
gchebanov
05.02.2023 23:13если все строки будут разными
Ну естественно, это не же не внешнаяя сортировка.С другой стороны странно, должен был ровно 10 есть, может испортил что.
sergileon
04.02.2023 00:00+1Интересно, а нельзя просто бором решить?) Переносим число до пробела в конец строки, задача свелась к сортировке строк. По первому символу добавляем в бор. Если всё совпало, переходим к следующему символу, текущий хранитьтне обязательно, если не совпало, "что-то делаем", например создаём файлы по текущей букве. Количество созданных файлов не превысит количество строк в исходном.
gandjustas Автор
04.02.2023 00:03Если просто число перенести, то порядок сортировки сломается.
на входе:
2. Строка 12. СтрокаПосле переноса будет
Строка .2 Строка .12Сортировка строк расположит их в порядке:
Строка .12 Строка .2Я пробовал это делать.
И число разворачивал тоже, тоже не работает как надо
aamonster
04.02.2023 01:57+1Надо не разворачивать, а добивать слева нулями до заданной длины.
Но не факт, что это даст выигрыш. Возможно, упростит код.
gandjustas Автор
04.02.2023 01:59В случае ключей сортировки конечно даст, так как сравнение simd-оптимизированное
gandjustas Автор
04.02.2023 00:52Посимвольная сортировка, она же radix сортировка не дает результат соответствующий культуре. Посмотрите раздел "Как сравнивать строки"
gchebanov
04.02.2023 02:07+1Конечно можно, только числу надо лидирующих нулей забацать, тогда лексикографическое совпадет с числовым сравнением. Проблема в том что в условиях внешней памяти для бора захочется случайный доступ - а его нет в случае hdd.
codecity
04.02.2023 00:02+1Некоторые даже попытались сделать решение на Apache Spark
Можно все-же полюбопытствовать - в чем проблема такого решения?
gandjustas Автор
04.02.2023 00:41наверное в том, что медленно
codecity
04.02.2023 10:10Насколько медленно? Кто-то проводил измерения или просто такие предположения?
gandjustas Автор
04.02.2023 14:01Час заняло без uca

aborouhin
05.02.2023 02:44Любопытно было бы на этой задаче протестировать Polars. Про него как раз пишут, что шустрее Spark, и тоже позволяет работать с датафреймами, не влезающими в память, в отличие от Pandas.

Tzimie
04.02.2023 09:29+1А интервьюер такой: а вот и не верно. Лампочек тринадцать. У меня ещё одна вс кармане. Вы нам не подходите)
vadimr
04.02.2023 11:53+3По некотором размышлении, я пришёл к выводу, что эту задачу нельзя эффективно решить, не обусловив среднюю (и максимальную) длину строки.
Можно выделить три принципиально разные ситуации:
1) Длина строки составляет примерно от нескольких десятков символов до сотен миллионов символов. Тогда можно играть на том, чтобы вместо самих строк сортировать сначала ключи в виде их начальных частей, как предлагал уважаемый@adeshere (при условии, что начальные части настолько же разные, как и сами строки).
2) Длина строки недостаточна для выделения ключа, отличающегося от самой строки. Одновременно это означает, что, скорее всего, имеется очень большое количество одинаковых строк.
3) Длина строки такова, что даже несколько строк или, в пределе, одна-единственная строка, не влезает в оперативную память. Если при этом строки различаются только в последних символах, то их эффективное сравнение само по себе представляет нетривиальную задачу.

PsyHaSTe
05.02.2023 18:36Спасибо за статью, однако один вопрос не дает покоя:
try { var mergedLines = tempFiles .Select(f => File.ReadLines(f).Select(s => new Item(s, s.IndexOf('.')))) .Merge(comparer) // IEnumerable<IEnumerable<T>> -> IEnumerable<T> .Select(x => x.Line); File.WriteAllLines(Path.ChangeExtension(file, ".sorted" + Path.GetExtension(file)), mergedLines); } finally { tempFiles.ForEach(File.Delete); }Я ведь правильно понимаю, что мы несмотря на такую запись ни в какой момент времени не вычитываем файлы целиком в память? По идее в памяти будут N буферов файлов открытых на чтение и одного файла открытого на запись, вся остальная работа будет с дисками. Если так, то кажется можно ощутимо поднять производительноть максимально увеличив размеры буферов.
P.S. ради интереса можно попробовать наивную реализацию на расте написать, получится ли выиграть что-то. По идее там сразу в диск упирание произойдет. По крайней мере там такие штуки как раз можно писать не включая мозг, но получая производительность отличного уровня и без мемори футпринта.
gandjustas Автор
05.02.2023 18:53Правильно. В финальном варианте есть разная оптимизация буферов чтения/записи , везде выбран размер буфера в 1мб, чтобы не съедать слишком много памяти при слиянии 1000чанков.
Если говорить про это вариант кода, то там сложно настроить буфер, так как у StreamReader есть своя буферизация, а у FileStream своя.

ShurikEv
05.02.2023 23:44Странное совпадение, но решение такой задачи разбирали на Ютубе более года назад https://www.youtube.com/live/B9v7pdfhUYw?feature=share
nkretov
Кажется что лучше оставаться просто человеком разумным и грузить такие недоцсв в sqlite и делать дальше с данными все что хочется в среде которая для этого и была создана.
gandjustas Автор
Попробуйте, напишите сколько времени это заняло
Ivan22
как люди разумные, само собой разумеем что файл уже лежит в клауде AWS на S3
gandjustas Автор
На что это влияет?
Ivan22
на скорость загрузки в snowflake через external stage
9982th
Для десятигигобайтного файла:
Я позволил себе небольшую вольность в интерпретации условий и считаю, что в самих строках нет точек, и соответственно точку можно использовать как разделитель. Этого нет в тексте задачи, но так написан код генерации тестового файла.
ЦПУ и диск использует активно, RAM в пике меньше двух гигабайт, с диска читает (и пишет) порядка двадцати. Работает в один поток, так что с процессором помощнее возможно есть какие-то шансы на час для 100 Гб, но только с хорошим SSD.
gandjustas Автор
Интересно использует ли sqlite UCA? И как я понимаю order by в отсутвие индексов делается в памяти. На 100гб это заработает вообще?
edo1h
ну как минимум постгрес умеет сортировать со выгрузкой промежуточных данных на диск.
кишки не смотрел, думаю, что устроено примерно как в этой статье.