
Вступление
В чем прелесть XML? Он реализован под все платформы, «человекочитаемый», для него созданы схемы данных (условно человекочитаемые). Открывая 25-мегабайтный файл в браузере сразу замечаешь недостатки этого текстового формата, и начинаешь задумываться. Делаем мы это, конечно, не часто, но все же — чем бы заменить XML?
Добавление самопальных бинарных контейнеров в проект заканчивается провалом, когда к вам приходят партнеры и просят подключить их к этому каналу данных. Google Protobuf поначалу выглядит хорошо, но вскоре понимаешь, что это не замена для XML, не хватает функциональности. BSON в 5 раз медленнее Protobuf, уступает в компактности и для него не реализованы схемы данных.
Разработаем же еще один бинарный формат.
USDS 1.0
USDS (или $S) — Universal serialized data structures — универсальные сериализованные структуры данных, бинарный формат, способный полностью заменить XML и JSON. Основные отличия:
- Вместо текстовых тегов/ключей используются целые числа. Соотношение «Имя» — «Целочисленный идентификатор» задается отдельно, в «Словаре». Словарь может быть прикреплен к документу USDS или может быть передан отдельно.
- Нет закрывающих тегов, как в XML;
- Документы USDS формируются строго по схеме, которая также задается в Словаре. Поддерживаются полиморфизм и опциональные поля.
- Числовые значения в документе USDS хранятся в бинарном виде (не как текст).
Допустим, мы задокументировали этот формат и создали первую версию библиотеки для работы с ним. Есть ли профит? Бенчмарк расставит все по своим местам:

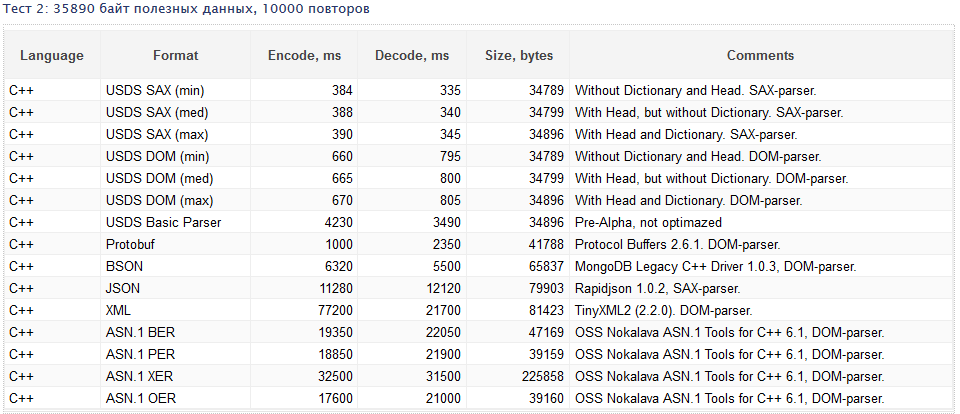
Что-то в этом уже есть, хотя работы еще не мало: Basic Parser всегда будет уступать Google Protobuf, но не на столько же.
Пример использования
Хоть формат и бинарный, использовать его не сложнее, чем XML. Посмотрим, как это будет выглядеть на С++ (а в далеком светлом будущем и на других языках).
Шаг 1: составляем Словарь
Как было сказано выше, документ USDS строится только по схеме, которая может выглядеть так:
USDS DICTIONARY ID=1000000 v.1.0
{
1: STRUCT internalObject
{
1: UNSIGNED VARINT varintField;
1: UNSIGNED VARINT varintField;
2: DOUBLE doubleField;
3: STRING<UTF-8> stringField;
4: BOOLEAN booleanField;
} RESTRICT {notRoot;}
2: STRUCT rootObject
{
1: INT intField;
2: LONG longField;
3: ARRAY<internalObject> arrayField;
}
}
Все правила построения схемы можно посмотреть здесь. Библиотека USDS Basic Parser пока что поддерживает далеко не все элементы схемы, но пример выше — рабочий. Сохраняем схему в текстовый файл, или вставляем прямо в исходный код, что дальше?
Шаг 2: инициализируем парсер:
Так или иначе, схема данных оказалась в массиве «text_dictionary», скормим его парсеру:
BasicParser* clientParser = new BasicParser();
clientParser->addDictionaryFromText(text_dictionary, strlen(text_dictionary), USDS_UTF8);
Парсер готов генерировать бинарные USDS документы. Если вам необходимо только декодировать бинарники, то инициализация словарем не требуется: парсер автоматически вытащит словарь прямо из бинарного документа USDS.
Шаг 3: создаем бинарный документ:
Алгоритм ничем не отличается от работы с любым другим DOM-парсером: добавляем несколько корневых объектов, инициализируем их значениями, генерируем выходной массив данных.
UsdsStruct* tag = clientParser->addStructTag("rootObject");
tag->setFieldValue("intField", 1234);
tag->setFieldValue("longField", 5000000000);
...
BinaryOutput* usds_binary_doc = new BinaryOutput();
clientParser->encode(usds_binary_doc, true, true, true);
const unsigned char* binary_data = usds_binary_doc->getBinary();
size_t binary_size = usds_binary_doc->getSize();
Особенности работы с массивами опущены, вы можете посмотреть их отдельно, скачав исходный код примера.
Шаг 4: декодирование бинарного документа:
Для чистоты эксперимента создадим отдельный объект парсера, не будем его инициализировать словарем и посмотрим, разберет ли он наш бинарный документ:
BasicParser* serverParser = new BasicParser();
serverParser->decode(binary_data, binary_size);
int int_value = 0;
long long long_value = 0;
tag->getFieldValue("intField", &int_value);
std::cout << "\tintField = " << int_value << "\n";
tag->getFieldValue("longField", &long_value);
std::cout << "\tlongField = " << long_value << "\n";
Обратите внимание, что «Сервер» заранее ничего не знает о схеме данных, но спокойно получил бинарник, нашел в нем поля по их текстовым именам и корректно преобразовал их в значения переменных С++. Именно эта функция недоступна в Google Protobuf и ASN.1.
Вы можете существенно ускорить программу, если будете инициализировать поля по их числовым идентификаторам (ID, совпадают с теми, что указаны в Словаре), смотрите исходный код примера.
Человекочитаемость
Это действительно очень важная функция: вы не можете прочитать посторонний бинарный пакет Google Protobuf или ASN.1 (кроме XER), а иногда очень хочется. При использовании BSON можно преобразовать любой пакет данных в JSON, что уже неплохо. Не отстает от него и USDS:
std::string json;
serverParser->getJSON(USDS_UTF8, &json);
std::cout << "JSON:\n" << json << "\n";
Сервер не только получил произвольный бинарный документ, но и смог преобразовать его в JSON. Ту же операцию можно было выполнить и на стороне «Клиента»: сформировать DOM-объект и сразу преобразовать его в JSON, который также строго соответствует схеме данных.
В планы разработки USDS заложен редактор документов USDS с полноценным GUI. В ближайшем будущем в USDS Basic Parser будет реализована конвертация между XML, JSON и USDS в любом направлении.
Заключение
Зачем я опубликовал сырой продукт (Pre-Alpha), который настоятельно не рекомендуется использовать в проектах? Мне важен ваш отклик:
- чего не хватает в продукте?
- нужен ли он вообще?
- понятно ли написана документация и исходный код?
Источники:
Страница проекта: USDS 1.0
Скачать библиотеку и исходный код примера можно здесь.
Исходный код библиотеки доступен здесь.
Комментарии (97)

TimsTims
09.11.2015 12:56+9Ждем картинки про новый стандарт

Zashibis
09.11.2015 13:43Вам какие именно картинки нужны?
vlivyur
09.11.2015 13:46+14
Zashibis
09.11.2015 13:48Есть 14 моделей жигулей. Зачем создавать новые модели, когда и существующие ездят?

FractalizeR
09.11.2015 14:48+1Для того, чтобы удовлетворить эго покупателя, который жаждет всего самого передового, например. Я думаю, при принятии решения о покупке «новой модели Х» это, часто, самый главный аргумент.
Ну, разумеется, новые модели иногда экономичнее, поддерживают новые стандарты, дают больше комфорта, и т.д. Но все же в программировании нас волнует немного другое, как правило.Zashibis
09.11.2015 15:14Да, в программировании нас интересуют новые функции, более высокая производительность, более компактные форматы. Это я и предлагаю в USDS.
FractalizeR
09.11.2015 15:31+10новые функции, более высокая производительность, более компактные форматы
Не подумайте, что я не уважаю ваше начинание. То, что вы придумали новый формат и инструменты для него — замечательно. Однако…
В чем прелесть XML? Он реализован под все платформы, «человекочитаемый», для него созданы схемы данных (условно человекочитаемые)
Вам не удалось ни одной прелести XML повторить в вашей работе, не так ли? И у меня возникает вопрос, не произошла ли подмена тезиса? Вы собирались создать альтернативу XML, а получился конкурент для protobuf, messagepack и их друзей.
Ведь XML — это не только XML, как формат передачи данных. Это еще и XML Schema, DTD и куча сопутствующих технологий. Я не уверен, что у вас получился конкурент существующему стеку.
Человекочитаемость запланирована через Редактор, с GUI, без предварительного обучения, а не через «парсер»
Человекочитаемость протокола — это возможность его чтения человеком из сырого вида, без предварительного преобразования. Например, HTTP 1.x — в основном человекочитаемый. А вот HTTP 2.x — уже нет, поскольку он бинарный. И если у меня есть WireShark, это все равно не означает, что HTTP 2.x стал для меня человекочитаемым.

bromzh
09.11.2015 15:46+1Плохой пример. Модели авто — это как версии софта. Есть несколько видов кузова (хэчбек/седан/универсал — это lite/standart/ultimate в софте). Но обычно каждые n лет эти модели обновляются и становятся лучше (для софта — это мажорный релиз). У кого есть средства для покупки авто/софта — те обновляются. Остальные остаются на старом.
А стандарты — это как запчасти. Если бы они все были более-менее стандартными, то всё было бы легче. Однако в жизни запчасть от одной марки не подходит для другой. Например, у некоторых машин колесо крепится на 4 болта, у некоторых на 5, у некоторых на 6. Было бы намного легче, если бы стандарт был 1, тогда бы было проще заменять колёса. А новый стандарт выглядит как попытка какого-нибудь производителя навязать свою точку зрения, что колесо с 8 болтами уж точно станет стандартом. При этом, большинство машин не приспособлены для таких колёс. Да и готовые колёса не подойдут к машине с 8-ю креплениями.
Текущие форматы справляются со своими задачами, зачем плодить новые сущности?Zashibis
09.11.2015 16:01Все очевидно, новые форматы справляются с теми же задачами лучше (или умирают), даже JSON зачем-то сделали, хотя уже был XML.
bromzh
09.11.2015 16:50+2JSON взлетел, потому что парсер js есть в каждом браузере. Так что на стороне фронтенда он автоматом поддерживается. Как и xml.
А парсер нового формата нужно как минимум внедрить во все браузеры. Включить парсер для нового неизвестного формата в стандарт ES никто не согласится. Загружать же библиотеку, чтобы прочитать данные многим будет влом, так как есть уже готовые json и xml + gzip, чего хватает с головой.

lair
09.11.2015 13:41+10бинарный формат, способный полностью заменить XML и JSON
Нельзя, просто нельзя сравнивать бинарные форматы и текстовые. У них и задачи разные, и, как следствие, характеристики.
И нет, вы не можете заменить json, потому что основное преимущество json — дешевый парсинг в браузере.
И человекочитаемости у вас потому же нет, потому что человекочитаемость через специально обученный парсер — это неудобно, особенно когда ты пытаешься на лету понять, что происходит. А если документ некорректный, что тогда скажет парсер?Zashibis
09.11.2015 13:47-10Добрый день!
Если формат станет популярным, то его обязательно встроят в браузеры, я буду работать в этом направлении. И как у любого бинарного формата — его парсинг будет дешевле, чем JSON.
Человекочитаемость запланирована через Редактор, с GUI, без предварительного обучения, а не через «парсер». И да, вы выдающая личность, если загружаете JSON из сетевог кабеля непосредственно в мозг :)
Если документ некорректный, парсер выдаст вам ту часть, что смог распарсить, и объяснит на каком месте он запнулся. Мало чем отличается от анализа битых JSON и XML.lair
09.11.2015 13:53+12Если формат станет популярным, то его обязательно встроят в браузеры, я буду работать в этом направлении.
В существующие на данный момент — тоже?
Человекочитаемость запланирована через Редактор,
Это не человекочитаемость.
И да, вы выдающая личность, если загружаете JSON из сетевог кабеля непосредственно в мозг :)
Да нет, я беру любой http-сниффер, и дальше могу свободно читать и писать.
Мало чем отличается от анализа битых JSON и XML.
Битые JSON и XML я могу открыть в произвольном текстовом редакторе и разбираться, что случилось. С бинарным файлом это сложнее на порядок.Zashibis
09.11.2015 15:16-4Да, в существующие браузеры тоже встроят, если проект будет успешен. Подсветку синтаксиса JSON там тоже не сразу реализовали.
Снифферы трафика умеют отображать огромное количество бинарных форматов, вероятность отображения пакетов USDS в человекочитаемом виде не нулевая.
Вы открываете JSON и XML в редкторе, который скачали и установили себе на компьютер (стандартный блокнот разумеется не подходит). Значит для вас не будет проблемой скачать и установить редактор для USDS.lair
09.11.2015 15:21+3Подсветку синтаксиса JSON там тоже не сразу реализовали.
Речь не про подсветку синтаксиса, а про поддержку в JS.
Снифферы трафика умеют отображать огромное количество бинарных форматов
Я вот что-то не уверен в этом заявлении относительно, скажем, фиддлера. Скажем, поддержки protobuf я там не нашел (хотя, возможно, плохо искал).
Вы открываете JSON и XML в редкторе, который скачали и установили себе на компьютер (стандартный блокнот разумеется не подходит).
… и в стандартном блокноте тоже. Понятно, что на своем рабочем компьютере я пользуюсь для этих целей другим ПО, но я знаю, что я могу это сделать на любом компьютере, где есть хотя бы какой-нибудь текстовый редактор.
Значит для вас не будет проблемой скачать и установить редактор для USDS.
Я не хочу ставить еще один редактор.Zashibis
09.11.2015 15:25Проблема protobuf в том, что его невозможно распарсить, не имея специально скомпилированного парсера, именно поэтому вы и не нашли его. В USDS эта проблема решена, если вы читали статью — то знаете как.
Если вы скачаете для работы пакет библиотек USDS, то там же получите и редактор, я об этом позабочусь :)lair
09.11.2015 15:27+1Если вы скачаете для работы пакет библиотек USDS, то там же получите и редактор, я об этом позабочусь
Спасибо, я против. Мне еще лишнего софта не хватало, особенно учитывая, что «пакет библиотек» я планирую ставить нюгетом.

HDDimon
09.11.2015 15:38+1>> не имея специально скомпилированного парсера
выше я описал что это неверно. парсер можно собирать на лету.Zashibis
09.11.2015 15:44Я не думаю, что профайлер сможет обратиться к серверу, загрузить динамическую схему и отрисовать документ. Только если профайлеру руками отдельно скормить эту самую динамическую схему.

vedenin1980
09.11.2015 14:38Если формат станет популярным, то его обязательно встроят в браузеры
Проблема тут в том что это замкнутый круг, бинарный формат не станет так же популярным как текстовый, пока его редактор не будет по умолчанию в каждой IDE, каждом браузере, каждой операционке, каждом текстовом редакторе и каждой кофемашине. А непопулярный формат на фиг никому поддерживать не нужно, ну и программистам неудобно переключаться в некоторый отдельный редактор чтобы поработать с файлом бинарного формата. В тех же браузерах, многие хотели бы заменить JavaScript на свой любимый язык программирования, но проблема замкнутого круга…
И как у любого бинарного формата — его парсинг будет дешевле, чем JSON
Время парсинг мало когда играет роль, JSON хорошо сжимается браузерными компрессорами/архиваторами, даже при чтении с диска чаще ДЕШЕВЛЕ разархивировать архивированный файл на лету и парсить в памяти, чем читать не архивированный файл с диска. Для чтения из сети вообще время парсинга редко критично, узким горлышком как правило будет получение данных, а не параллельный парсинг в памяти. Бинарный формат хорош для сериализации/десериализации объектов на диск, для записи в базу данных, но универсальность и стандартность для всех языков и платформ нафиг не нужна в большинстве случаев, все равно сериализированный объект Java не откроется в Net, но так как с большой вероятностью будет передача через сеть в архивированном виде, JSON прекрасно тут работает.Zashibis
09.11.2015 15:19В описанном вами замкнутом круге всегда появляются исключения, некоторые вещи выстреливают. Оставим же шанс USDS :)
Время парсинга на стороне браузера действительно роли не играет, вы распарсите JSON за 0.1 секунду, а USDS за 0.01с, а потом скрипт будет выполняться 2 секунды — кого вообще волнует парсинг?
Зато ваш сервер сможет обслуживать в несколько раз больше пользователей, потому что на формирование миллиона JSON он потратит 10 секунд, а на тот же миллион USDS он потратит 1 секунду.vedenin1980
09.11.2015 16:04Не сможет, потому что обслужить миллион запросов в секунду он не сможет просто потому что у него не хватит портов, не говоря уже о затратах на поддержание каналов и передачу данных. Если данные статические и сервер не лазиет в базу данных, файлы и т.п., то никто не мешает заранее закешировать JSON'ы популярных ответов, если сервер берет данные из базы данных, то время формирования JSON'ов вообще никакой роли не играет.
Учитывая кеширование популярных запросов на стороне сервера, обращение к базе данных для получения данных и поддержку сетевых соединения, время на формирование JSON'a в 99.9% случаев значения не имеет. Тем более по своему опыту миллион JSON'ов нормальный сервер с быстрой JSON библиотекой сформирует намного быстрее чем за 1 секунду. Та же монга работает с бинарным JSON'ом и в целом сохраняет миллионы JSON объектов в секунду не особо напрягаясь и не считая поддержки соединений, индексов и запросов.
vedenin1980
09.11.2015 16:57+1Зато ваш сервер сможет обслуживать в несколько раз больше пользователей
Простите, но вы понимаете что бинарные и текстовые протоколы существуют уже лет 50 и над ними работали миллионы инженеров (в том числе и над вопросами где использовать текстовый и где использовать бинарный протокол)? Вы правда верите, что если бы это было правдой кто-то сейчас использовал бы json, html или xml вместо бинарных протоколов (при том что когда появился html, xml и json сервера были в десятки или сотни раз слабее)? То есть вы уверены, что идея «а давайте вместе текстового протокола используем бинарный» настолько уникальна и никому не приходила в голову, что вы с ней захватите мир?Zashibis
09.11.2015 17:21-5Да, я часто вижу, как используют текстовые форматы там, где просятся бинарные. Я вижу почему так делают — существующие бинарные форматы в большинстве своем ущербны, либо в их разработку вложили недостаточно ресурсов. В этих комментариях привели несколько реализаций бинарных форматов, но они не выстрелили и я вижу основные блокеры. Сложно сказать, чем занимались «миллионы» инжинеров последние 50 лет, если мы до сих пор используем текстовые форматы.

novar
09.11.2015 13:58+5А ещё есть EBML, «при создании которого стояла задача создать аналог XML для двоичных данных». EBML мы встречаем повсеместно в виде MKV-файлов.
Zashibis
09.11.2015 15:08По вашей же ссылке: «Очень важной особенностью формата является наличие «значений по умолчанию» для многих элементов»
Эта особенность есть и у protobuf, и у USDS. Даже в XSD можно объявить опциональные поля, что сократит размер документов.TimsTims
09.11.2015 16:48+3Тогда чем USDS лучше и зачем нужен еще один «стандарт» который захватит мир?
Zashibis
09.11.2015 16:57Он значительно быстрее текстовых форматов, компактнее и немного быстрее BSON и всех его клонов (в том числе EBML), и превосходит по функциональности «самые бинарные» protobuf и ASN.1. Я провел анализ большинства существующих форматов, прежде чем изобретать очередной велосипед и взял лучшие моменты от каждого, плюс предложил некоторые новшества.

grossws
10.11.2015 00:05+1компактнее и немного быстрее BSON
В случае BSON и не гнались за компактностью. Он появился в рамках mongodb и возможность in-place update была куда важнее, чем компактность.

OlegMax
09.11.2015 16:53+1Вот уже люди задумались и даже предложили Efficient XML Interchange (EXI) Format.
boolivar
09.11.2015 19:46Была уже подобная разработка: habrahabr.ru/post/248147
Zashibis
10.11.2015 09:20+1Вы уж простите, но Tree совершенно не «подобная» разработка. Вы конечно же читали и эту статью и ту, что по вашей ссылке, и понимаете о чем я говорю.


markhor
09.11.2015 21:10+1Мда, вспомнилось, чем отличается обсуждение нового проекта на западной площадке и на российской. Англосакс: «Wow! It can be useful to me.» Русский: «Да нафига ты это написал, это никому не надо и т.п.»
Жалко что-ли? :) Я к примеру тоже ощутил ущербность protobuf и согласен с автором. Даже если этот формат не выстрелит — заманчиво применить его у себя в специфических нишах, где он реально судя по тестам может дать профит. Собственно, именно по этой причине я вижу автор его и написал.
У меня такой вопрос, под Linux работает? Python обертку хочется, чтобы поиграться с внутренностями. Я даже готов ее сам создать, благо опыт богатый в этом.Zashibis
10.11.2015 09:24Да, когда я публиковал описание формата на англоязычных ресурсах, люди реагировали чуть добрее.
Для Linux сейчас не получится скомпилировать, в одном классе присутствует виндовая «MultiByteToWideChar», но планируется ее вырезать (UTF-8 в UTF-16 можно и без нее сконвертировать). Я вам отправлю сообщение в личку, когда поправлю, но ждите не раньше нового года.
dtestyk
09.11.2015 21:30Была статья про убийцу json....
Даже решил свой запилить, но если для бинарного формата важна производительность, для текстового человекочитаемость и краткость.
некоторые примеры:
называется CLS(Contexted Lists and Sets)Zashibis
10.11.2015 09:25Вы правда считаете ваш пример «человекочитаемым»? Данный «убийца» вымрет не родившись.
dtestyk
10.11.2015 10:51Несомненно, но поскольку это довольно субъективно, решил отложить идею.
А почему вы не считаете его человекочитаемым?Вот, какими требованиями руководствовался:- запись данных в новом формате для большинства вариантов использования должна быть короче аналогичной в существующих
- синтаксис должен быть интуитивно понятным
- формат не должен поддерживать бинарные данные, достаточно обычного юникода
- возможность экранирования
- возможность записи в одну строку
Zashibis
10.11.2015 11:06Согласен, «читаемость» субъективна. Что касается вашего примера и моего мнения: когда я впервые увидел JSON, я понял его сразу (имея опыт с XML), не обращаясь к документации (но читал документацию, чтобы писать собственные JSON).
Глядя на ваш формат я затрудняюсь разобрать примерно 30% кода. Также есть сомнения, что он компактнее JSON, количество спецсимволов примерно такое же.
grossws
09.11.2015 23:43Что-то вспомнился старый добрый ASN.1 в представлении DER.
grossws
09.11.2015 23:45+2Увидел, что в таблицах бенчмарков есть ASN.1, но почему-то нет нормального бинарного DER. Как-то странно, что самого популярного и вполне быстрого варианта просто нет…
Zashibis
10.11.2015 09:28Да, к большому моему сожалению библиотека OSS, которую я использовал для тестирования ASN.1, падала при попытке работы с DER, поэтому он не был включен в бенчмарк.
Сама по себе OSS не показатель производительности ASN.1, она уж больно медленная. Ребята, которые ее писали, очень любят деньги, и похоже периодически проверяют наличие лицензии на вашем ПК.

JC_Piligrim
10.11.2015 01:36+4А чем плох Apache Thrift для этих целей?
У него поддержка практически всех популярных языков есть уже в настоящем, а не в некоем светлом будущем.Zashibis
10.11.2015 09:31-2Apache Thrift — это скорее генератор API. Вы, конечно, можете прокидывать его пакеты через HTTP, но уж больно геморойно это будет.
Второй недостаток — тот же что и у Protobuf и ASN.1: имея бинарный пакет вы не можете его «просмотреть по-человечески» без специально скомпилированного парсера.jrip
10.11.2015 14:41+2Вы похоже вообще не понимаете что такое Apache Thrift и видимо поэтому написали какую-то полную фигню.
>Apache Thrift — это скорее генератор API
Это вообще что значит?
Вообще, в нем есть либы для большинства популярных языков, а также генератор кода реализации конкретной версии протокола, который задается через специальный язык структур.
>Вы, конечно, можете прокидывать его пакеты через HTTP, но уж больно геморойно это будет.
В стандартных либах для большинства языков есть реализация для того чтобы «не геморойно» «прокидывать» через HTTP
А также есть и бинарный транспорт, а еще можно и свой сверху нафигачить, какой захочется.
>Второй недостаток
Да вот нифига, в небинарной версии там json, немного привыкнув можно сразу понимать что происходит.
И чего вы ставите в недостаток то, что в вашем протоколе как бы как минус также есть?

ionsphere
10.11.2015 08:26+2Или такой вариант github.com/Microsoft/bond?
Zashibis
10.11.2015 09:36-1Это еще один клон Apache Thrift, Protobuf и ASN.1, о чем они прямо и говорят на своем сайте. USDS принципиально отличается от них тем, что вы можете опционально поместить схему прямо в бинарный документ.
lair
10.11.2015 11:43+3Вообще-то, в бонде вы это тоже можете. Более того, в нем есть tagged-протоколы, где документ самоописан.
Zashibis
10.11.2015 12:37Смотрю ссылку. Подскажите, они умеют смешивать схему с данными, или посылать схему отдельно по запросу? Из докмента это не совсем понятно.
lair
10.11.2015 12:40+2(а) у них есть tagged-протокол, при котором схема не нужна, документ самоописывается
(б) в случае untagged-протоколов для десериализации нужна схема. Эта схема точно так же может быть сохранена в и получена из бинарного потока (еще она может быть получена из самого класса, кстати). Дальше вы можете делать с ней что угодно: класть в поток перед документом, хранить в БД, передавать отдельным запросом — что хотите.Zashibis
10.11.2015 12:42-1(а) tagged-протоколы мало кому интересны, они медленные, большие, годятся только для отладки. Моя библиотека тоже умеет генерить JSON для отладки.
(б) Что подразумевается под «потоком»? Я хочу сохранить бинарный докумнет на диск в один файл, в нем будут и данные и схема, и это потом распарсится?lair
10.11.2015 13:40+1tagged-протоколы мало кому интересны, они медленные, большие, годятся только для отладки.
Видимо, MS так не считает: два их протокола (CompactBinary и FastBinary) — tagged.
Я хочу сохранить бинарный докумнет на диск в один файл, в нем будут и данные и схема,
Не надо мыслить «файлами», мыслите бинарными потоками. Сначала кладете схему, потом кладете данные. Когда читаете — в обратном порядке.Zashibis
10.11.2015 13:53Когда читаете — в обратном порядке.
Т.е. вторая сторона должна заранее знать, что я в определенные байтики поместил схему, или парсер Bond сам разберется, что схема в потоке есть и найдет где именно она лежит?lair
10.11.2015 13:54Если вы используете untagged-протокол, то да, вы должны заранее договориться со второй стороной о правилах передачи схемы.
Zashibis
10.11.2015 14:03Тогда это похоже на решение protobuf с динамическими схемами, которое было описано выше в каментах. Решение в Bond даже лучше, чем у протобуфа, т.к. является частью стандарта.
В USDS второй стороне будет проще, т.к. парсер сам найдет схему данных в бинарном докуенте (при условии что ее туда вообще положили).lair
10.11.2015 14:06В USDS второй стороне будет проще, т.к. парсер сам найдет схему данных в бинарном докуенте (при условии что ее туда вообще положили).
Вопрос в том, каков процент таких ситуаций, чтобы оправдать использование USDS вместо bond.Zashibis
10.11.2015 14:13Отслеживание трафика профайлером, редактирование конфигов в формате USDS, СУБД может передавать вам результаты SQL запросов в формате USDS: в начале документа схема, далее тонны данных (я плакал глядя на исходный код ODBC-драйвера).
У USDS есть и режим полной бинарности, когда вы не светите схему никому, и везде используются предварительно скомпилированные парсеры (как в protobuf, Bond и т.д.).lair
10.11.2015 14:35На вопрос «каков процент» это все не отвечает. Я искренне считаю, что в половине этих случаев tagged-протокол прекрасно устроит.
(а уж конфиги-то вообще не надо хранить в бинарном виде, зло это)

kefirfromperm
10.11.2015 09:14+4Я очень много работаю с XML. Я люблю его и ненавижу. Итак, чтобы была полноценная замена нужно:
1. Схема +
2. Человекочитаемость +-
3. DOM +
4. SAX — 5. StAX — 6. XPath — 7. XSLT -Zashibis
10.11.2015 09:43SAX в USDS будет реализован очень не скоро, уж больно геморойная тема. Вы конечно можете взять классы InputBuffer/OutputBuffer из моего исходного кода, вооружиться документом «бинарная структура USDS» и писать значения из своих классов непосредственно в бинарный массив, но это прям сакс-хардкор будет.
StAX — крутая штука, я уже думал о ней, надо реализовать обязательно, золотая середина между DOM и SAX.
XPath и XSLT — в далеком светлом будущем, либо может найдуться активисты :)

AllexIn
10.11.2015 12:02+3Добавление самопальных бинарных контейнеров в проект заканчивается провалом, когда к вам приходят партнеры и просят подключить их к этому каналу данны
Воспользуюсь я вашим форматом. Придет ко мне партнер и попросит подключить к моему каналу с данными…
И чем это будет отличаться от подключения к самопальному бинарному контейнеру?Zashibis
10.11.2015 12:39Тем, что вы дадите им ссылку на сайт продукта и предложите скачать библиотеку, которая не имеет внешних зависимостей и реализована под большинство языков (ах светлое будущее!).
Таки ваш собственный «контейнер» с очень большой вероятностью будет завязан на внушительную часть вашего же исхдного кода.
Взглянем на protobuf2: это изначально не было самостоятельным продуктом, его выделили. В результате для компиляции он тащит еще очень большой объем гугловых библиотек.AllexIn
10.11.2015 12:50Парсер для любого(тем более бинарного) формата пишется за вечер.
и я доверия испытываю больше к своему решению, чем к никому неизвестному формату.
Сейчас можно продвинуть какой-то формат, если он будет реально революционные идеи в себе содержать. Ваш же формат, хоть и может быть удобен для каких-то задач, по факту ничего интересного, что заставило бы его использовать не несет.
ИМХО с вероятностью 99.9 не взлетит.Zashibis
10.11.2015 12:52-3Странно что я потратил на сырую пре-альфу два месяца. Наверное я что-то делаю не так :)
AllexIn
10.11.2015 12:55+1Вы делаете универсальный формат.
Очевидно, что если я буду делать парсер для своего сервиса и своего формата, я буду делать специфичный парсер заточенный под мой формат учитываяющий его специфику. И займет это минимум времени. Универсальность нужна библиотекам, но не нужна конкретным продуктам.Zashibis
10.11.2015 12:58-1Написать хороший парсер под свой собственный проект — две недели, плюс столько же на тестирование и неделя на документирование.
AllexIn
10.11.2015 13:31+2Хм. Скажем у меня есть сервис погоды и должен он отдавать погоду в определенных аэропортах.
Как же будет выглядеть бинарный формат для этого дела?
Наверное нам понадобится поддержка массивов, структур, строковых переменных и числ целых и с плавающей точкой.
Как же в итоге будут выглядеть сами данные?
Примерно вот так:
int PackageSizePos = Package.WriteInt(PACKAGE_SIZE);//пишем сначала 0, а в конце построения перезаписываем размером всего пакета Package.WriteInt(PROTOCOL_VERSION); //ну чтобы не ломалось ничего при смене версии Package.WriteInt(WEATHER_INFO); //WEATHER_INFO - константа, которая определяет тип содержимого Package.WriteInt(WEATHER_PROTOCOL_VERSION); Package.WriteString("SVO"); //Погода для аэропорта Шереметьево Package.WriteInt(Data.size()); //Количество периодов за которые есть информация for (unsigned int block = 0; block<Data.size(); block++){ Package.WriteDouble(Data[block].Date);//Дата и время на которое указана инфа Package.WriteFloat(Data[block].Temperature); Package.WriteFloat(Data[block].Humidity); Package.WriteFloat(Data[block].WindDirection); Package.WriteFloat(Data[block].WindSpeed); } Package.WriteInt(PackageSizePos,Package.size()+sizeof(int));//Пишем размер пакета + добавляем размер контрольки, которой еще нет Package.WrinteInt(CalcCRC(Package,Package.size()));//Пишем контрольную сумму в конце
Хм. А как же все это будет читать партнер?
Ну примерно так:
if (Package.ReadInt()!=Package.size()) return ERROR_INCORRECT_PACKAGE; if (Package.ReadInt(Package.size()-sizeof(int))!=CalcCRC(Package,Package.size()-sizeof(int))) return ERROR_INCORRECT_PACKAGE; if (Package.ReadInt()!=PROTOCOL_VERSION) return ERROR_UNSUPPORTED_VERSION; switch(Package.ReadInt()){ case WEATHER_INFO: return processWeatherPackage(Package); }; return ERROR_UNSUPPORTED_PACKAGE_DATA; unsigned int processWeatherPackage(Package) { if (Package.ReadInt()!=WEATHER_PROTOCOL_VERSION) return ERROR_UNSUPPORTED_DATA_VERSION; std::string Code = Package.ReadString(); if (!checkCode(Code)) return ERROR_INCORRECT_PACKAGE; unsigned int BlocksCount = Package.ReadInt(); if (BlocksCount>MAX_BLOCKS_COUNT) return ERROR_INCORRECT_PACKAGE; Ports[Code].resize(BlocksCount); for (unsigned int block = 0; block<BlocksCount; block++){ Ports[Code].Data[block].Date = Package.ReadDouble(); Ports[Code].Data[block].Temperature = Package.ReadFloat(); Ports[Code].Data[block].Humidity = Package.ReadFloat(); Ports[Code].Data[block].WindDirection = Package.ReadFloat(); Ports[Code].Data[block].WindSpeed = Package.ReadFloat(); } return OK; }
Сколько я это писал? Минут 20. Задача совершенно с потолка, только сейчас ее придумал.
Да, придется тестировать. Но все тестирование будет сводиться к проверке, что не валидные данные придти не могут. Неделя на тестирование? Пфф. Ерунда.
Тем более что единственное что нужно будет, это перенести уже работающий код(ведь мы же делаем версию для платформы партнера, а не с нуля пишем). то есть по сути, написать методы чтения стандартных переменных. И всё. Все валидации будут уже в нашем коде и их надо буедт просто перенести.
Что тут две недели писать?
Для более сложных задач будет тоже самое. Я писал бинарный парсер для протокола, который имел 40(сорок) версий и нужно было не отваливаться на старой версии, а поддерживать их все. И даже для этого я писал код пару дней всего лишь.Zashibis
10.11.2015 14:00-4Только ваш C# потом не распарсится на Java, С++ и других языках, которые используются у партнеров.
AllexIn
10.11.2015 14:20+2Это еще почему?
Ну и это не шарп. :)Zashibis
10.11.2015 14:36-3Возьмем вот этот метод:
Package.WriteString(«SVO»);
Это либо стандартная библиотека какого-то языка, что мешает парсить докумнет на других языках, либо ваша самописная, которая не входит в срок 1 вечер.AllexIn
10.11.2015 14:47+3void cPackage::WriteString(const std::string& str ) { WriteInt(str.size()); if (str.size()>0) WriteRaw(str.c_str(),str.size()); } std::string cPackage::ReadString() { int Size = ReadInt(); std::string Result = ""; if (Size()>0){ Result.reserve(Size); for (int i = 0; i<Size; i++) Result+=ReadChar(); } return Result; }
Уф. Минут пять писал.
А это, между прочим, самый сложный тип из всех.
AllexIn
10.11.2015 14:50+1которая не входит в срок 1 вечер.
А вообще, я про это и говорил:
«Тем более что единственное что нужно будет, это перенести уже работающий код(ведь мы же делаем версию для платформы партнера, а не с нуля пишем). то есть по сути, написать методы чтения стандартных переменных. И всё. „
Весь вечер и будет состоять из времени потраченного на написания класса cPackage для нужной платформы. Причем, по факту, 90% этого вечера будет заниматься настройка девелоперского окружения. Ибо методы чтения и записи в поток для примитивных типов пишется за десятки минут. Если уже не написаны 1000 раз до этого.Zashibis
10.11.2015 14:58-1У вас все еще нет обработки ошибок, юнит-тестов, работы с BigEndian.
А если вы возьмете тот же Protobuf, то все вопросы будут решены бустрее чем за 1 вечер.AllexIn
10.11.2015 15:06+3У вас все еще нет обработки ошибок, юнит-тестов, работы с BigEndian.
А у вас? :)
У меня код написанный за 25 минут в общей сложности прямо в браузере. А у вас два месяца потрачено и где это всё? Тем же BigEndian в коде и не пахнет.
Разве что у вас обработка ошибок есть в зачаточном состоянии. Ну так и у меня базовая обработка ошибок сделана.
Давайте проще. Подождем и через два месяца посмотрим, что в вашем проекте изменится.
jrip
10.11.2015 14:34+5Т.е. вы придумали некий очередной формат, сделали его реализацию только на с++ и громко заявили что это полоценная замена XML? :D

HDDimon
А в чем коренные отличия от protobuf?
NeoCode
Присоединяюсь к вопросу. И в чем в protobuf вам не хватает функциональности?
Zashibis
Во-первых, сам бинарный формат немного отличается:
Во-вторых, софт чуть другой, у protobuf есть только генератор парсеров. У USDS дополнительно предусмотрена бибилотека Basic Parser, которой можно скормить текстовое или бинарное описание словарей. Basic Parser всегда будет медленнее, чем сгенерированные парсеры, но она будет полезна для многих решений.
HDDimon
1. В чем приемущество?
2. тип данных только в тэге? на сколько это быстрее/медленее protobuf?
3. в protobuf есть возможно указать версию самого protobuf 2/3 или расширить схему версией. Тем более если вы расширяете схему, то сервер продолжит работать по старой схеме, то есть обратная совместимость сохраняется
4. в protobuf есть возможность формирования dynamic message — это когда схема на стороне сервера может изменяться. То есть первым сообщением сервер вам отдает динамическую схему. на основании данной схемы вы создаете файловый дескриптор из которого может вытащить дескрипторы полей для декодирования бинарных данных.
Zashibis
1a. Предполождим вам пришло сообщение в формате protobuf: какое именно там сообщение? У протобуфа нет идентификаторов сообщений. Какая версия протокола у клиента? Протобуф вам это также не сообщит. в USDS вся эта информация есть в первых 10 байтах.
1b. У вас есть файл, внутри которого protobuf: вы не можете открыть его редактором с GUI и внести правки, вы не можете сконвертировать его в XML или JSON (хотя может быть вы скомпилировали редактор и конвертор под свою схему данных, но это мало эффективно). В USDS эта проблема решена.
2. Тег может иметь тип данных «структура», в этом случае указываются типы для полей. Быстрее/медленнее смотрите в статье, бенчмарк реальный приведен.
3. В USDS в первых 10 байтах указывается: что это USDS, версия USDS, идентификатор вашщей схемы данных, версия вашей схемы данных (версия протокола). Один парсер умеет работать сразу с несколькими версиями вашей схемы, даже если между схемами нет обратной совместимости.
4. Можно ссылку на это?
HDDimon
В официальных доках я этой информации не встречал, но может посмотреть на этот снипет
Спасибо за ответы.
Zashibis
Вот я тоже очень удивился, ни разу не встречал такой инфы :)
Судя по вашей ссылке, это действительно кто-то реализовал динамическую генерацию парсера по схеме, автору респект. Если Google добавит это в свой стандарт — это будет успех.
HDDimon
мы активно используем динамические схемы protobuf в текущем проекте. Очень удобно получается.