

В этом посте мы начнём реализацию с нуля GPT всего в
60 строках numpy. Во второй части статьи мы загрузим в нашу реализацию опубликованные OpenAI веса обученной модели GPT-2 и сгенерируем текст.Примечание:
- Для понимания этого поста нужно разбираться в Python, NumPy и обладать начальным опытом в обучении нейросетей.
- В этой реализации отсутствует большая часть функциональности; это сделано намеренно, чтобы максимально упростить её, при этом сохранив целостность. Моя задача — создание простого, но завершённого технического введения в GPT как обучающего инструмента.
- Понимание архитектуры GPT — всего лишь небольшая (хотя и жизненно важная) часть более масштабной темы больших языковых моделей (LLM). [Масштабное обучение, сбор терабайтов данных, обеспечение быстрой работы модели, оценка производительности и подстройка моделей под выполнение необходимых человеку задач — дело всей жизни для сотен инженеров и исследователей, работа которых потребовалась, чтобы превратить LLM в то, чем они являются сегодня; одной лишь архитектуры недостаточно. Архитектура GPT просто оказалась первой архитектурой нейросетей, обладающей удобными свойствами масштабирования, высокой параллелизации на GPU и качественного моделирования последовательностей. Настоящим секретным ингредиентом становится масштабирование данных и модели (как обычно), а GPT именно это и позволяет нам делать. Возможно, трансформер просто выиграл в аппаратную лотерею и рано или поздно какая-то другая архитектура сбросит его с трона.]
- Весь код из этого поста выложен в github.com/jaymody/picoGPT.
Что такое GPT?
GPT расшифровывается как Generative Pre-trained Transformer. Этот тип архитектуры нейросети основан на трансформере. Статья How GPT3 Works Джея Аламмара — прекрасное высокоуровневое введение в GPT, которое вкратце можно изложить так:
- Generative: GPT генерирует текст.
- Pre-trained: GPT обучается на множестве текстов из книг, Интернета и так далее
- Transformer: GPT — это нейронная сеть, содержащая в себе только декодирующий трансформер.
Большие языковые модели (Large Language Model, LLM) наподобие GPT-3 компании OpenAI, LaMDA компании Google и Command XLarge компании Cohere по своему строению являются всего лишь GPT. Особенными их делает то, что они 1) очень большие (миллиарды параметров) и 2) обучены на множестве данных (сотни гигабайтов текста).
По сути, GPT генерирует текст на основании промпта (запроса). Даже при этом очень простом API (на входе текст, на выходе текст), хорошо обученная GPT способна выполнять потрясающие задачи, например, писать за вас электронные письма, составить резюме книги, давать идеи подписей к постам в соцсетях, объяснить чёрные дыры пятилетнему ребёнку, писать код на SQL и даже составить завещание.
Это было краткое описание GPT и их возможностей. А теперь давайте углубимся в подробности.
Ввод и вывод
Сигнатура функции GPT выглядит примерно так:
def gpt(inputs: list[int]) -> list[list[float]]:
# вводы имеют форму [n_seq]
# выводы имеют форму [n_seq, n_vocab]
output = # бип-бип, магия нейронной сети
return outputВвод
Вводом является последовательность целых чисел, представляющих собой токены некоторого текста:
# целые числа обозначают токены в нашем тексте, например:
# текст = "not all heroes wear capes":
# токены = "not" "all" "heroes" "wear" "capes"
inputs = [1, 0, 2, 4, 6]Мы определяем целочисленное значение токена на основании вокабулярия токенизатора:
# индекс токена в вокабулярии обозначает целочисленный идентификатор этого токена
# например, целочисленный идентификатор для "heroes" будет равен 2, так как vocab[2] = "heroes"
vocab = ["all", "not", "heroes", "the", "wear", ".", "capes"]
# имитация токенизатора, выполняющая токенизацию по пробелу
tokenizer = WhitespaceTokenizer(vocab)
# метод encode() выполняет преобразование str -> list[int]
ids = tokenizer.encode("not all heroes wear") # ids = [1, 0, 2, 4]
# мы видим реальные токены при помощи сопоставления вокабулярия
tokens = [tokenizer.vocab[i] for i in ids] # tokens = ["not", "all", "heroes", "wear"]
# метод decode() выполняет обратное преобразование list[int] -> str
text = tokenizer.decode(ids) # text = "not all heroes wear"Вкратце:
- У нас есть строка.
- Мы используем токенизатор, чтобы разбить её на части меньшего размера, называемые токенами.
- Далее мы применяем вокабулярий, чтобы сопоставить токены с целочисленными значениями.
На практике используются более сложные методы токенизации, чем простое разбиение по пробелам, например, Byte-Pair Encoding или WordPiece, но принцип остаётся тем же:
- Существует
vocab, сопоставляющий токены строк с целочисленными индексами - Есть метод
encode, выполняющий преобразованиеstr -> list[int] - Есть метод
decode, выполняющий преобразованиеlist[int] -> str
Вывод
Выводом является 2D-массив, в котором
output[i][j] — это прогнозируемая вероятность модели того, что токен в vocab[j] является следующим токеном inputs[i+1]. Например:vocab = ["all", "not", "heroes", "the", "wear", ".", "capes"]
inputs = [1, 0, 2, 4] # "not" "all" "heroes" "wear"
output = gpt(inputs)
# ["all", "not", "heroes", "the", "wear", ".", "capes"]
# output[0] = [0.75 0.1 0.0 0.15 0.0 0.0 0.0 ]
# на основе одного "not" модель с наибольшей вероятностью прогнозирует слово "all"
# ["all", "not", "heroes", "the", "wear", ".", "capes"]
# output[1] = [0.0 0.0 0.8 0.1 0.0 0.0 0.1 ]
# на основе последовательности ["not", "all"] модель с наибольшей вероятностью прогнозирует слово "heroes"
# ["all", "not", "heroes", "the", "wear", ".", "capes"]
# output[-1] = [0.0 0.0 0.0 0.1 0.0 0.05 0.85 ]
# на основе полной последовательности ["not", "all", "heroes", "wear"] модель с наибольшей вероятностью прогнозирует слово "capes"Чтобы получить прогноз следующего токена для всей последовательности, мы просто берём токен с наибольшей вероятностью в
output[-1]:vocab = ["all", "not", "heroes", "the", "wear", ".", "capes"]
inputs = [1, 0, 2, 4] # "not" "all" "heroes" "wear"
output = gpt(inputs)
next_token_id = np.argmax(output[-1]) # next_token_id = 6
next_token = vocab[next_token_id] # next_token = "capes"Взятие токена с наибольшей вероятностью в качестве окончательного прогноза часто называют greedy decoding (жадным декодированием) или greedy sampling (жадным сэмплированием).
Задача прогнозирования следующего логичного слова в тексте называется языковым моделированием. Поэтому можно назвать GPT языковой моделью.
Генерировать одно слово — это, конечно, здорово, но как насчёт генерации целых предложений, абзацев и так далее?
Генерация текста
Авторегрессивная
Мы можем генерировать законченные предложения, итеративно запрашивая у модели прогноз следующего токена. На каждой итерации мы добавляем спрогнозированный токен к вводу:
def generate(inputs, n_tokens_to_generate):
for _ in range(n_tokens_to_generate): # цикл авторегрессивного декодирования
output = gpt(inputs) # прямой проход модели
next_id = np.argmax(output[-1]) # жадное сэмплирование
inputs = np.append(out, [next_id]) # добавление прогноза к вводу
return list(inputs[len(inputs) - n_tokens_to_generate :]) # возвращаем только сгенерированные id
input_ids = [1, 0] # "not" "all"
output_ids = generate(input_ids, 3) # output_ids = [2, 4, 6]
output_tokens = [vocab[i] for i in output_ids] # "heroes" "wear" "capes"Этот процесс прогнозирования будущего значения (регрессия) и добавление его обратно во ввод («авто») и стал причиной того, что модель GPT иногда называют авторегрессивной.
Сэмплирование
Мы можем добавить генерированию стохастичности (случайности), выполняя сэмплирование не жадным образом, а из распределения вероятностей:
inputs = [1, 0, 2, 4] # "not" "all" "heroes" "wear"
output = gpt(inputs)
np.random.choice(np.arange(vocab_size), p=output[-1]) # capes
np.random.choice(np.arange(vocab_size), p=output[-1]) # hats
np.random.choice(np.arange(vocab_size), p=output[-1]) # capes
np.random.choice(np.arange(vocab_size), p=output[-1]) # capes
np.random.choice(np.arange(vocab_size), p=output[-1]) # pantsЭто не только позволяет нам генерировать разные предложения по одному вводу, но и повышает качество выводов по сравнению с жадным декодированием.
Также часто используются техники наподобие top-k, top-p и temperature для изменения распределения вероятностей перед сэмплированием из него. Это ещё больше увеличивает качество генераций и добавляет гиперпараметры, с которыми можно экспериментировать для получения разного поведения генераций (например, повышение «температуры» увеличивает рискованность модели, делая её более «творческой»).
Если вы хотите почитать анализ других техник сэмплирования для управления генерациями языковых моделей, рекомендую Controllable Neural Text Generation Лиллиан Венг.
Обучение
Мы обучаем GPT как любую другую нейросеть — при помощи градиентного спуска с учётом некоей функции потерь. В случае GPT мы берём потерю перекрёстной энтропии для задачи языкового моделирования:
def lm_loss(inputs: list[int], params) -> float:
# метки y - это просто input, сдвинутый на 1 влево
#
# inputs = [not, all, heros, wear, capes]
# x = [not, all, heroes, wear]
# y = [all, heroes, wear, capes]
#
# разумеется, у нас нет метки для inputs[-1], поэтому мы исключаем её из x
#
# поэтому для N вводов у нас будет N - 1 примеров пар для языкового моделирования
x, y = inputs[:-1], inputs[1:]
# прямой проход
# все распределения вероятностей спрогнозированных следующих токенов на каждой позиции
output = gpt(x, params)
# потеря перекрёстной энтропии
# мы берём среднее по всем N-1 примерам
loss = np.mean(-np.log(output[y]))
return loss
def train(texts: list[list[str]], params) -> float:
for text in texts:
inputs = tokenizer.encode(text)
loss = lm_loss(inputs, params)
gradients = compute_gradients_via_backpropagation(loss, params)
params = gradient_descent_update_step(gradients, params)
return paramsДля понятности мы добавили аргумент
params ко вводу gpt. При каждой итерации цикла обучения мы выполняем этап градиентного спуска для обновления параметров модели, делая нашу модель всё лучше и лучше в моделировании языка с каждым новым фрагментом текста, который она видит. Это крайне упрощённая структура обучения, однако она демонстрирует процесс в целом.Обратите внимание, что мы не используем явным образом размеченные данные. Создавать пары input/label можно и просто из сырого текста. Это называется self-supervised learning (самообучением).
Это означает, что мы можем очень просто масштабировать объём данных обучения, всего лишь показывая модели как можно большее количество сырых текстов. Например, GPT-3 была обучена на 300 миллиардах токенов текста из Интернета и книг:
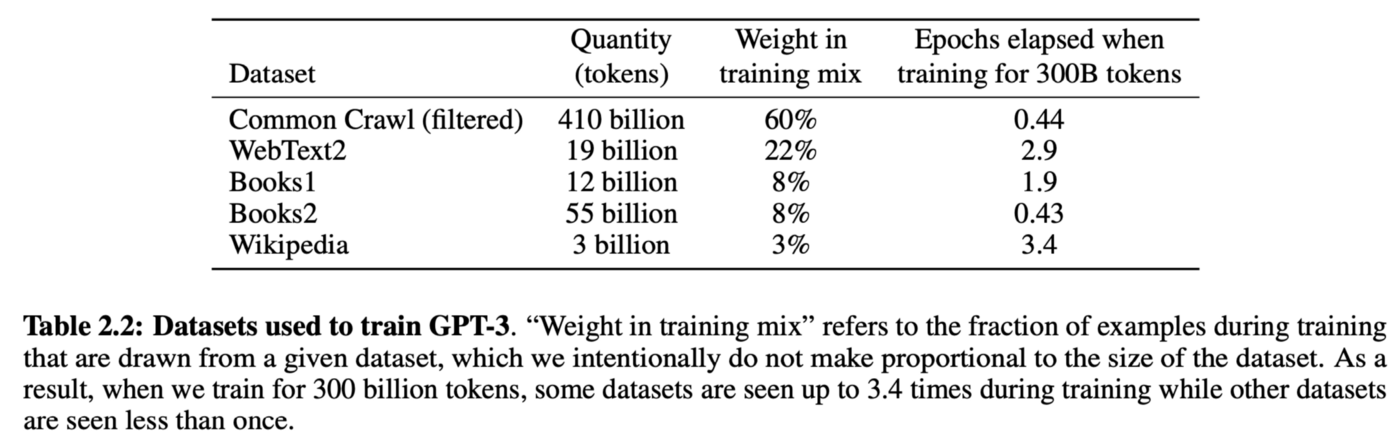
Таблица 2.2 из статьи о GPT-3
Чтобы учиться на всех этих данных, нам нужна модель существенно бОльших размеров, поэтому GPT-3 имеет 175 миллиардов параметров, а вычислительные затраты на её обучение приблизительно составляют $1-10 миллионов. [Однако после статей про InstructGPT и Chinchilla мы осознали, что на самом деле необязательно обучать столь огромные модели. Оптимально обученная и подстроенная на основе инструкций GPT с 1,3 миллиардами параметров может превзойти GPT-3 с 175 миллиардами параметров.]
Этот этап самообучения называется pre-training (предварительным обучением), поскольку мы можем повторно использовать веса «предварительно обученных» моделей для дальнейшего обучения модели для следующих задач, например, для определения токсичности твита.
Обучение модели на углублённых задачах называется fine-tuning (подстройкой), поскольку веса модели уже были предварительно обучены пониманию языка и всего лишь подстраиваются под конкретную задачу.
Стратегия «предварительное обучение на общей задаче + подстройка на конкретной задаче» называется трансферным обучением.
Промптинг
В принципе, исходная GPT просто использовала преимущества предварительного обучения модели трансформера для трансферного обучения, аналогично BERT.
И только после появления научных статей о GPT-2 and GPT-3 мы осознали, что предварительно обученная модель GPT сама по себе способна выполнять любую задачу просто после создания промпта и выполнения авторегрессивного языкового моделирования, без необходимости подстройки. Это называется in-context learning (обучением в контексте), поскольку для выполнения задачи модель использует только контекст промпта. Обучение в контексте может быть без примеров (zero shot), с одним (one shot) или несколькими (few shot) примерами:

Иллюстрация 2.1 из научной статьи про GPT-3
Разумеется, можно использовать GPT в качестве чат-бота, а не заставлять её выполнять «задачи». История беседы передаётся в модель в качестве промпта, возможно, с каким-то предварительным описанием, например «Ты чат-бот, веди себя хорошо». Если изменить промпт, можно даже придать чат-боту черты личности.
Разобравшись со всем этим, можно, наконец, перейти к реализации!
Подготовка
Клонируйте репозиторий для этого туториала:
git clone https://github.com/jaymody/picoGPT
cd picoGPTТеперь давайте установим зависимости:
pip install -r requirements.txtУчтите, что если вы работаете на Macbook с M1, то прежде чем выполнять
pip install, нужно будет заменить в requirements.txt tensorflow на tensorflow-macos. Этот код тестировался на Python 3.9.10.Краткое описание каждого из файлов:
-
encoder.pyсодержит код BPE Tokenizer компании OpenAI, взятый напрямую из её репозитория gpt-2. -
utils.pyсодержит код для скачивания и загрузки весов модели GPT-2, токенизатора и гиперпараметров. -
gpt2.pyсодержит саму модель GPT и код генерации, которые можно запускать как скрипт на Python. -
gpt2_pico.py— это то же самое, что иgpt2.py, но с меньшим количеством строк. Зачем? А почему бы и нет.
Мы заново реализуем
gpt2.py с нуля, так что удалим его и воссоздадим как пустой файл:rm gpt2.py
touch gpt2.pyДля начала вставим в
gpt2.py следующий код:import numpy as np
def gpt2(inputs, wte, wpe, blocks, ln_f, n_head):
pass # TODO: реализовать это
def generate(inputs, params, n_head, n_tokens_to_generate):
from tqdm import tqdm
for _ in tqdm(range(n_tokens_to_generate), "generating"): # цикл авторегрессивного декодирования
logits = gpt2(inputs, **params, n_head=n_head) # прямой проход модели
next_id = np.argmax(logits[-1]) # жадное сэмплирование
inputs = np.append(inputs, [next_id]) # добавляем прогноз к вводу
return list(inputs[len(inputs) - n_tokens_to_generate :]) # возвращаем только сгенерированные id
def main(prompt: str, n_tokens_to_generate: int = 40, model_size: str = "124M", models_dir: str = "models"):
from utils import load_encoder_hparams_and_params
# загружаем encoder, hparams, и params из опубликованных open-ai файлов gpt-2
encoder, hparams, params = load_encoder_hparams_and_params(model_size, models_dir)
# кодируем строку ввода при помощи BPE tokenizer
input_ids = encoder.encode(prompt)
# убеждаемся, что не вышли за пределы максимальной длины последовательности нашей модели
assert len(input_ids) + n_tokens_to_generate < hparams["n_ctx"]
# генерируем id вывода
output_ids = generate(input_ids, params, hparams["n_head"], n_tokens_to_generate)
# декодируем id обратно в строку
output_text = encoder.decode(output_ids)
return output_text
if __name__ == "__main__":
import fire
fire.Fire(main)Опишем каждую из четырёх частей:
- Функция
gpt2— это сам код GPT, который мы должны реализовать. Можно заметить, что наряду сinputsсигнатура функции содержит дополнительные параметры:-
wte,wpe,blocksиln_f— параметры модели. -
n_head— гиперпараметр, который нужно передавать во время прямого прохода.
-
- Функция
generate— это алгоритм авторегрессивного декодирования, который мы видели ранее. Для простоты мы пользуемся жадным сэмплированием.tqdm— это шкала прогресса, помогающая визуализировать процесс декодирования, один за другим генерирующего токены. - Функция
mainвыполняет следующие задачи:- Загружает токенизатор (
encoder), веса модели (params) и гиперпараметры (hparams) - Кодирует промпт ввода в ID токенов при помощи токенизатора
- Вызывает функцию generate
- Декодирует ID вывода в строку
- Загружает токенизатор (
-
fire.Fire(main)просто превращает наш файл в приложение CLI, чтобы мы могли запускать наш код следующим образом:python gpt2.py "здесь какой-то промпт"
Давайте присмотримся к
encoder, hparams и params. Выполним в ноутбуке или интерактивной сессии Python следующее:from utils import load_encoder_hparams_and_params
encoder, hparams, params = load_encoder_hparams_and_params("124M", "models")При этом в
models/124M скачаются необходимые файлы модели и токенизатора, а в наш код загрузятся encoder, hparams и params.Encoder
encoder — это BPE tokenizer, используемый GPT-2:>>> ids = encoder.encode("Not all heroes wear capes.")
>>> ids
[3673, 477, 10281, 5806, 1451, 274, 13]
>>> encoder.decode(ids)
"Not all heroes wear capes."При помощи вокабулярия токенизатора (хранящегося в
encoder.decoder) мы можем узнать, как выглядят реальные токены:>>> [encoder.decoder[i] for i in ids]
['Not', 'Ġall', 'Ġheroes', 'Ġwear', 'Ġcap', 'es', '.']Обратите внимание, что иногда токены — это слова (например,
Not), иногда это слова, но с пробелом в начале (например, Ġall (Ġ обозначает пробел), иногда это часть слова (например, слово capes разделено на Ġcap и es), а иногда это знаки препинания (например, .).BPE удобен тем, что может кодировать любую произвольную строку. Если он встречает то, чего нет в вокабулярии, то просто разбивает это на подстроки, которые понимает:
>>> [encoder.decoder[i] for i in encoder.encode("zjqfl")]
['z', 'j', 'q', 'fl']Также мы можем проверить размер вокабулярия:
>>> len(encoder.decoder)
50257Вокабулярий, а также слияния байтовых пар, определяющие способ разбиения строк, получаются обучением токенизатора. Когда мы загружаем токенизатор, то загружаем уже обученный вокабулярий и слияния байтовых пар из каких-то файлов, которые были скачаны вместе с файлами модели, когда мы выполнили
load_encoder_hparams_and_params. См. models/124M/encoder.json (вокабулярий) и models/124M/vocab.bpe (слияния байтовых пар).Гиперпараметры
hparams — это словарь, содержащий гиперпараметры модели:>>> hparams
{
"n_vocab": 50257, # количество токенов в вокабулярии
"n_ctx": 1024, # максимально возможная длина последовательности ввода
"n_embd": 768, # размерность эмбеддингов (определяет "ширину" сети)
"n_head": 12, # количество голов внимания (n_embd должно делиться на n_head)
"n_layer": 12 # количество слоёв (определяет "глубину" сети)
}Мы будем использовать эти символы в комментариях к коду, чтобы показать внутреннюю структуру. Также мы будем использовать
n_seq для обозначения длины последовательности ввода (например, n_seq = len(inputs)).Параметры
params — это вложенный json-словарь, содержащий обученные веса модели. Узлы листьев json — это массивы NumPy. Если мы выведем params, заменив массивы на их shape, то получим следующее:>>> import numpy as np
>>> def shape_tree(d):
>>> if isinstance(d, np.ndarray):
>>> return list(d.shape)
>>> elif isinstance(d, list):
>>> return [shape_tree(v) for v in d]
>>> elif isinstance(d, dict):
>>> return {k: shape_tree(v) for k, v in d.items()}
>>> else:
>>> ValueError("uh oh")
>>>
>>> print(shape_tree(params))
{
"wpe": [1024, 768],
"wte": [50257, 768],
"ln_f": {"b": [768], "g": [768]},
"blocks": [
{
"attn": {
"c_attn": {"b": [2304], "w": [768, 2304]},
"c_proj": {"b": [768], "w": [768, 768]},
},
"ln_1": {"b": [768], "g": [768]},
"ln_2": {"b": [768], "g": [768]},
"mlp": {
"c_fc": {"b": [3072], "w": [768, 3072]},
"c_proj": {"b": [768], "w": [3072, 768]},
},
},
... # повторяем для n_layers
]
}Всё это загружается из исходного чекпоинта tensorflow компании OpenAI:
>>> import tensorflow as tf
>>> tf_ckpt_path = tf.train.latest_checkpoint("models/124M")
>>> for name, _ in tf.train.list_variables(tf_ckpt_path):
>>> arr = tf.train.load_variable(tf_ckpt_path, name).squeeze()
>>> print(f"{name}: {arr.shape}")
model/h0/attn/c_attn/b: (2304,)
model/h0/attn/c_attn/w: (768, 2304)
model/h0/attn/c_proj/b: (768,)
model/h0/attn/c_proj/w: (768, 768)
model/h0/ln_1/b: (768,)
model/h0/ln_1/g: (768,)
model/h0/ln_2/b: (768,)
model/h0/ln_2/g: (768,)
model/h0/mlp/c_fc/b: (3072,)
model/h0/mlp/c_fc/w: (768, 3072)
model/h0/mlp/c_proj/b: (768,)
model/h0/mlp/c_proj/w: (3072, 768)
model/h1/attn/c_attn/b: (2304,)
model/h1/attn/c_attn/w: (768, 2304)
...
model/h9/mlp/c_proj/b: (768,)
model/h9/mlp/c_proj/w: (3072, 768)
model/ln_f/b: (768,)
model/ln_f/g: (768,)
model/wpe: (1024, 768)
model/wte: (50257, 768)Показанный ниже код преобразует представленные выше переменные tensorflow в словарь
params.Для справки вот shape
params, где числа заменены на hparams, которые они означают:{
"wpe": [n_ctx, n_embd],
"wte": [n_vocab, n_embd],
"ln_f": {"b": [n_embd], "g": [n_embd]},
"blocks": [
{
"attn": {
"c_attn": {"b": [3*n_embd], "w": [n_embd, 3*n_embd]},
"c_proj": {"b": [n_embd], "w": [n_embd, n_embd]},
},
"ln_1": {"b": [n_embd], "g": [n_embd]},
"ln_2": {"b": [n_embd], "g": [n_embd]},
"mlp": {
"c_fc": {"b": [4*n_embd], "w": [n_embd, 4*n_embd]},
"c_proj": {"b": [n_embd], "w": [4*n_embd, n_embd]},
},
},
... # повторяем для n_layers
]
}Вероятно, вы захотите возвращаться к этому словарю, чтобы проверять shape весов в процессе реализации нашей GPT. Для согласованности имена переменных в нашем коде будут соответствовать ключам этого словаря.
Базовые слои
Прежде чем мы приступим к самой архитектуре GPT, давайте реализуем часть самых базовых слоёв сети, не специфичных конкретно для моделей GPT.
GELU
Для нелинейности (функция активации) выбора GPT-2 используется GELU (Gaussian Error Linear Units), альтернатива ReLU:
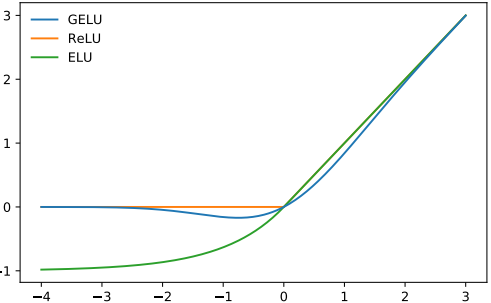
Рисунок 1 из научной статьи о GELU
Она аппроксимируется следующей функцией:
def gelu(x):
return 0.5 * x * (1 + np.tanh(np.sqrt(2 / np.pi) * (x + 0.044715 * x**3)))Как и ReLU, GELU обрабатывает ввод поэлементно:
>>> gelu(np.array([[1, 2], [-2, 0.5]]))
array([[ 0.84119, 1.9546 ],
[-0.0454 , 0.34571]])Использование GELU в моделях-трансформерах популяризировала BERT, и я думаю, её продолжат применять ещё долго.
Softmax
Старый добрый softmax:
def softmax(x):
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)Для числовой стабильности мы используем
трюк с max(x).Softmax применяется для преобразования множества вещественных чисел (от
softmax для последней оси ввода.>>> x = softmax(np.array([[2, 100], [-5, 0]]))
>>> x
array([[0.00034, 0.99966],
[0.26894, 0.73106]])
>>> x.sum(axis=-1)
array([1., 1.])Нормализация слоёв
Нормализация слоёв стандартизирует значения так, чтобы они имели среднее значение 0 и дисперсию 1:
где
def layer_norm(x, g, b, eps: float = 1e-5):
mean = np.mean(x, axis=-1, keepdims=True)
variance = np.var(x, axis=-1, keepdims=True)
x = (x - mean) / np.sqrt(variance + eps) # нормализуем x, чтобы иметь mean=0 и var=1 по последней оси
return g * x + b # масштабируем и смещаем с параметрами gamma/betaНормализация слоёв гарантирует, что вводы для каждого слоя будут находиться в согласованном интервале, что должно ускорить и стабилизировать процесс обучения. Как и при Batch Normalization, нормализированный вывод затем масштабируется и смещается при помощи двух изучаемых векторов gamma и beta. Небольшой член epsilon в делителе используется, чтобы избежать ошибку деления на ноль.
По разным причинам в трансформере используется не batch norm, а норма слоёв. Различия между разными методиками нормализации описаны в этом замечательном посте.
Мы применяем нормализацию слоёв для последней оси ввода.
>>> x = np.array([[2, 2, 3], [-5, 0, 1]])
>>> x = layer_norm(x, g=np.ones(x.shape[-1]), b=np.zeros(x.shape[-1]))
>>> x
array([[-0.70709, -0.70709, 1.41418],
[-1.397 , 0.508 , 0.889 ]])
>>> x.var(axis=-1)
array([0.99996, 1. ]) # учитываем тонкости работы с плавающей запятой
>>> x.mean(axis=-1)
array([-0., -0.])Линейность
Стандартное матричное умножение + перекос:
def linear(x, w, b): # [m, in], [in, out], [out] -> [m, out]
return x @ w + bЛинейные слои часто называют проекциями (поскольку они проецируют из одного векторного пространства в другое).
>>> x = np.random.normal(size=(64, 784)) # input dim = 784, batch/sequence dim = 64
>>> w = np.random.normal(size=(784, 10)) # output dim = 10
>>> b = np.random.normal(size=(10,))
>>> x.shape # shape до линейного проецирования
(64, 784)
>>> linear(x, w, b).shape # shape после линейного проецирования
(64, 10)Продолжение: https://habr.com/ru/post/717644/
Комментарии (32)

java3000
00.00.0000 00:00+12может стоит некий величественный вокабулярий таки обозвать простым словарём?

PatientZero Автор
00.00.0000 00:00+4Тогда как отличать его от словаря (dictionary) Python?

nochkin
00.00.0000 00:00+1Разговорный назвать просто "словарь".
Питоновский либо называть "Python-словарь" или вообще оставить "dict"/"Python dict", так как читатели обычно в курсе.

Eugeeny
00.00.0000 00:00+2ах, если бы только у этого слова был однозначный перевод на русский (словарный запас)

atomlib
00.00.0000 00:00Тут три довода оставить:
- Термин уже устоялся в некоторых областях лингвистики в значении «словарный запас».
- Помогает немедленно понять, что значит переменная
vocabбез необходимости что-то пояснять или запоминать. - Указывает на конкретную сущность в проекте, которую спутать будет с человеческим словарным запасом или структурами данных Пайтона будет невозможно.

MAXH0
00.00.0000 00:00+4Если коротенько, то сколько стоит запустить такое на локальном компьютере? Как идет расчет цены? И возможен ли обмен предобученными сетями среди локальных пользователей?

celen
00.00.0000 00:00+6Скачал и запустил модель поиграться. Получилось примерно так:
Я: Alan Turing theorized that computers would one day become
GPT2: the most powerful machines on the planet.
The computer is a machine that can perform complex calculations, and it can perform these calculations in a way that is very similar to the human brain.(Первое предложение не связано со вторым, но сама мысль подана складно)
Я: one two three four five
GPT2: six seven eight nine ten eleven twelve thirteen fourteen fifteen sixteen seventeen eighteen nineteenth twentieth twenty-first twenty-first twenty-second twenty-third twenty-fourth twenty-fifth twenty-six twenty-seventh
(Окей, считать оно умеет)
Я: eleven plus twelve equals
GPT2: one. The first two numbers are the number of the first two numbers. The third number is the number of the third number. The fourth number is the number of the fourth number. The
(Ну, не очень умеет. Зато похоже знает Монти Пайтон и Священый Грааль)
Я: To be, or not to be, that is the question.
GPT2: The question is, what is the difference between a "good" and a "bad" person?
(Шекспира модель явно не читала)
Я: When machines take over the world, the first thing they will
GPT2: do is to create a new world.
The next thing they will do is to create a new world.
The next thing they will do is to create a new world.(Три раза пересоздадут мир!)
Я: A cowboy walks into a bar
GPT2: and a woman walks in. "I'm going to have to go to the hospital," she says. "I'm going to have to go to the hospital."
(Да, юмор моделям не очень дается)
Я: Einstein's theory of relativity states that
GPT2: the universe is a continuous, continuous, and continuous universe.
The theory of relativity states that the universe is a continuous, continuous, and continuous universe. Einstein's theory of relativity states that the...(Вообще модель любит повторить несколько раз то, что хочет сказать)
Ответ генерируется примерно 30 секунд, но я поленился настраивать CUDA и оно генерируется на процессоре. Переобучать пока не пробовал. В целом довольно забавная штука, пытаюсь разобраться в ней поглубже.

irony_iron
00.00.0000 00:00+3года в 4 человек тоже повторяет одно и то же слово пытаясь высказать мысль, тут главное читать его ответы детским голосом

bogdart
00.00.0000 00:00+1И еще имейте в виду, что это gpt2, релизнутая в феврале 19 года. С тех пор модели сильно продвинулись и их ответы куда комплекснее. Но их на процессоре уже не покрутишь.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

support917
00.00.0000 00:00А зачем машин лернинг, ИИ, нейронные сети, "перекрестная энтропия" (хаха))) и тп для достижения такого простого результата?
С генерацией текста без смысла (генерация рефератов) прекрасно справляются алгоритмы в виде лапшичного кода, да и работают они в 1000 раз быстрее.

divanus
00.00.0000 00:00-1Вот я поэтому и спрашиваю. Все-таки надо озвучить цель: хотим вас читатели научить "этой штуке" ... ... x, y, z.

avdosev
00.00.0000 00:00Так фича в том, что никому не нужны рефераты без смысла, рефераты с кучей воды, но с вкраплениями смысла гораздо полезнее
support917
00.00.0000 00:00Заслуга скрипта в статье в том, что он строки типа "the bond length of the oxygen molecule is" дополнит не "корова утекла ими и Вася", а чем-то более естественными. А именно: "the bond length of the oxygen molecule is the length of the oxygen molecule", и генерация дополнения займет почти минуту на среднем домашнем ПК.
Но смысла там 0, просто правильная игра слов, - это задолго до нейронок имело реализации. Так что именно из примера в статье мне не понятно, в чем профит от "нейросети".
Еще немного примеров вывода:
Input: the сow says
Output: the сow says : "I'm not sure if you're aware of the fact that the Russian government has been using the internet to spread disinformation and disinformation about the US and its allies. The US government hasInput: the color of sun at the 12 pm is
Output: the color of sun at the 12 pm is the same as the color of the moon at the 12 pm. The moon is the brightest star in the skyavdosev
00.00.0000 00:00+1Но смысла там 0, просто правильная игра слов, — это задолго до нейронок имело реализации. Так что именно из примера в статье мне не понятно, в чем профит от "нейросети".
так скрипт и не позиционируется как очень крутая nlp модель, на текущий момент её можно считать если не устаревшей, то как минимум точно не передовой, смотрите gpt-3/chatgpt и аналоги, там уже результат гораздо интереснее.
support917
00.00.0000 00:00К gpt-3 нет вопросов, в чем прорыв понятно и видно. Там к лингвистике добавляется "память" и семантика знаний из специализированных сайтов, наполняемых живыми людьми (вики, стаковерфлоу и тп). Это как-бы следующая версия поисковых систем.
Вот только реализация закрыта и никто не знает, сколько % профита дает нейросеть и машинлернинг, а сколько обычный рукописный алгоритм.
avdosev
00.00.0000 00:00Смотрите открытые реализации ruGPT3 — узнаете сколько % дает машин лернинг
спойлер, но есть нюансы, аналог GPT-3 сделать еще достаточно просто, то аналог ChatGPT — не тривиальная задача, нужен не только адекватный большой датасет, но еще и люди, которые его улучшат и дообучат для решения задач обычного человека.100%

IvaYan
00.00.0000 00:00А зачем машин лернинг, ИИ, нейронные сети, "перекрестная энтропия" (хаха))) и тп для достижения такого простого результата?
С генерацией текста без смысла (генерация рефератов) прекрасно справляются алгоритмы в виде лапшичного кода, да и работают они в 1000 раз быстрее.
Может стоит сравнивать и оценивать не по учебной реализации, а по полноценной? Эта реализация на NumPy, так в реальном мире так не делают. Есть PyTorch, который оптимизирован именно под конкретные задачи, работает с GPU и так далее.
Ну и резальтат ооочень зависит от того, какой корпус использовался для обучения. Вот, из самой статьи:
Например, GPT-3 была обучена на 300 миллиардах токенов текста из Интернета и книг:
Что-то я сомневаюсь, что модель на NumPy обучалась так же.
Так что реализация из статьи годится чтобы анализировать и понять, как, в общих чертах, работают такие модели. И не более.

PsihXMak
00.00.0000 00:00Целую ночь пытался разобраться в устройстве GPT и нейросетей в целом. Я правильно понимаю, что сохранять у себя в нейронах результаты диалога они не могут? Т.е. нужно в каждом запросе передавать нейросетке текст всего предыдущего разговора?
Это прям печаль. Я думал, что они могут обучаться в процессе выполнения...
ramiil
00.00.0000 00:00Дообучение возможно, но не в этом примере. Я пытаюсь понять, как его добавить, но знаний не хватает.
IvaYan
00.00.0000 00:00+1Целую ночь пытался разобраться в устройстве GPT и нейросетей в целом.
Целая ночь это мало. Тут на месяцы и годы счет идти должен. И попробуйте взять сети попроще. Разбираться в нейросетях по GPT это то же самое что выяснять как работает авиация по Airbus 380. В принципе, возможно, но если начать с этажерок братьев Райт, будет проще.
Я правильно понимаю, что сохранять у себя в нейронах результаты диалога они не могут?
В общем случае после внедрения модели, в процессе эксплуатации её веса не меняются.
Я думал, что они могут обучаться в процессе выполнения...
Для обучения помимо размеченных входных данных (которые не всегда есть где взять в случае пользовательского ввода) нужно еще накапливать градиенты для слоев сети. А на это нужны вычислительные ресурсы и память. Дорого выходит всегда в таком режиме работать.
PsihXMak
00.00.0000 00:00Тут на месяцы и годы счет идти должен.
Мне не интересна разработка ИИ. Но вот как прикладной инструмент я бы его использовал.
в процессе эксплуатации её веса не меняются
Для меня нейросети всегда представлялись аналогом мозга человека, где и память и вычисления происходят в одном месте. Но, чем больше углубляюсь в тему, тем больше понимаю, на сколько это далеко от истины.
Теперь нейросеть в моём представлении это большая функция-чёрный ящик, куда мы закидываем параметры и на выходе получаем результат, который мы ожидали бы получить в нашем человеческом понимании.
DistortNeo
00.00.0000 00:00+2В случае нейронных сетей некоторым аналогом кратковременной памяти могут выступать значения на промежуточных слоях в рекурретных моделях. Но долговременная память (веса слоёв) остаются неизменными.
На нынешнем этапе развития процесс обучения (оптимизация весов — формирование памяти) и процесс инференса (собственно работа нейросети) разнесены. Некоторые модели нейронных сетей позволяют делать дообучение со сравнительно небольшими вычислительными затратами. Но об обучении нейронной сети в процессе эксплуатации речи пока не идёт.
IvaYan
00.00.0000 00:00+1Для меня нейросети всегда представлялись аналогом мозга человека, где и память и вычисления происходят в одном месте. Но, чем больше углубляюсь в тему, тем больше понимаю, на сколько это далеко от истины.
Если поначалу говорили, что нейронные сети основаны на работе мозга и некоторые их разновидности действительно вдохновлены его устройством, то сейчас уже не так. Более того, есть некоторая тенденция отказа от термина "нейронная сеть" в пользу "модель глубокого обучения", вероятно в том числе чтобы не создавать путаницу с нейронами мозга.

DolboCoder
00.00.0000 00:00-1Для Win7 и таких как я ) кто Питона еще не нюхал и хочет посмотреть его на ЭТОМ примере:::
https://www.python.org/downloads/windows/
ставим Питон 3.8.10 последний для Вин7 с установщиком. ( потом можно до 8.13 проапить руками) Пара минут уходит. Ну и я поставил как люблю, в папку C:\Python38. Потом еще и пути же писать.
Сразу ставим https://confluence.atlassian.com/get-started-with-sourcetree/install-sourcetree-847359094.html
Это модуль Git - с прибабахами. На русском бесплатный. Регистрация простая. С облаком можно для начала не заморачиваться, чисто локальную папку указать куда качать.
Теперть PATH !!!
Возможно он и прописался у вас при установке. Но Вин7 с ним не дружит. Кста: я сам не сразу допер, что
git clone https://github.com/jaymody/picoGPT писать в CMD или FARе.идем в CMD
распечатываем СУЩЕСТВУЮЩИЕ пути (они тут [маты] одной строкой)C:>PATH
PATH=C:\Python38;C:\Python38\Scripts;C:\Users\A\AppData\Local\Atlassian\SourceTree\git_local\bin;и! копируем, все что там есть в блокнот++
Смотрим есть ли там такое как у меня. И если нету, то добавляем.
C:\Users\A\AppData\Local\Atlassian\SourceTree\git_local\bin //= путь к Git. Его можно посмотреть в СоурсТрии/инструменты/настройки/Git самый низ.
Там же кстати на первой вкладке указываем, куда закачивать файлы : у меня C:\Python\picoGPTв CMD вставляем
C:>PATH C:\Python38;C:\Python38\Scripts;C:\Users\A\AppData\Local\Atlassian\SourceTree\git_local\bin;
или как там у вас.И вот только теперь вы можете давать ТУТ команды типа ::
git clone https://github.com/jaymody/picoGPT
CD C:\Python\picoGPT
C:\Python\picoGPT>pip install -r requirements.txtНО ОНИ работать не будут! Пишите так:::
git clone http://github.com/jaymody/picoGPT
CD C:\Python\picoGPT
C:\Python\picoGPT>pip install pipwin && pipwin install -r requirements.txtввот теперь в бой ))
PsihXMak
00.00.0000 00:00Эх, не лёгок путь новичка. Прям вспоминаю, через сколько таких подводных камней прошёл.
Можно ещё добавить, что там всего одна команда:
python gpt2.py "Alan Turing theorized that computers would one day become" --n_tokens_to_generate 40 --model_size "124M" --models_dir "models"Что делает каждый атрибут, думаю, будет понятно после прочтения статьи и описания из гита.
ramiil
00.00.0000 00:00Только ещё нюансы, что с 3.8 может не заработать, ибо требуется версия питона, совместимая с определенной версией transformers.
Так же, может потребоваться установка Visual Studio, обычно этого требует модуль regex 2017.4.5.
Я переписал пару функций, что-бы не запускать скрипт для обработки каждого промпта, а один раз запустить, и давать запросы как к чат-боту, ибо работа на проце довольно медленна, и генерация пары предложений может занять до минуты. Я добавил генерацию не N токенов, а N предложений, что вызывает глюки ,если в выводе нет точки(она считается маркером конца предложения. Так же, я добавил корявую реализацию top-p сэмплинга (что делает вывод в ответ на один и тот же промпт разнообразным), что-бы ускорить генерацию длинных предложений, я добавил окно в 40 токенов, которое сдвигается по массиву токенов по мере их генерации. Это всё улучшения чисто пользовательские, и не затрагивают работу нейросети или модель. Вот кодdebug = False def generate(inputs, params, n_head, sentence_n): while True: logits = gpt2(inputs[-40:], **params, n_head=n_head)[-1] # model forward pass #Sort of top-p sampling s = logits.argsort()[-20:][::-1] slice = [x for x in s if ((1/logits[s[0]])*logits[x]>0.92)] next_id = np.random.choice(slice) # Debug output to see which token network choose if debug: print() for index in slice: if next_id == index: print('V', index, logits[index], encoder.decode([index])) else: print(' ', index, logits[index], encoder.decode([index])) #next_id = np.argmax(logits[-1]) # greedy sampling inputs = np.append(inputs, [next_id]) # append prediction to input if inputs[-1]==13: sentence_n-=1 if sentence_n < 0: break print(encoder.decode([inputs[-1]]), end='', flush=True) print() if __name__ == "__main__": from utils import load_encoder_hparams_and_params model_size = "1558M" models_dir = "models" encoder, hparams, params = load_encoder_hparams_and_params(model_size, models_dir) while True: prompt = input('>') if prompt == '': continue # encode the input string using the BPE tokenizer t = time.time() input_ids = encoder.encode(prompt) # make sure we are not surpassing the max sequence length of our model #assert len(input_ids) + n_tokens_to_generate < hparams["n_ctx"] # generate output ids output_ids = generate(input_ids, params, hparams["n_head"], 3) # Max number of sentences is 5 # decode the ids back into a string encoder.decode(output_ids) print(time.time() - t)Если вдруг кто знает, как файн-тюнить такую модель - прошу подсказать.
ramiil
Примеры вывода, нам нужны примеры!
avdosev
а они есть в оригинале