

О теме повторной передачи сообщений в Kafka было написано достаточно много статей, например, на Habr [1], в том числе в англоязычных источниках [2].
В данной статье хотелось бы дополнительно прояснить возможности использования фреймворка SPRING в части интеграции с Apache Kafka, а также заострить внимание на обработке повторов.
Разработчики Kafka, судя по релизной политике, стали внедрять функционал, который предусматривает приоритизацию настроек Kafka в части надёжности иногда даже в ущерб доступности (prioritizes durability over availability).
К сожалению, систему с надёжной и гарантированной доставкой сложно представить без повторов. Kafka имеет множество настроек, которые позволяют настраивать её в ту или иную сторону в зависимости от ТЗ. Для новичков перед прочтением рекомендуется ознакомится с основными понятиями, присущими этой платформе, например здесь [3]
В Kafka данные обрабатываются вполне надёжно, и сама по себе Kafka обладает высокой степенью доступности, предполагая обработку миллионов сообщений в секунду.
В Kafka есть два уровня, которые непосредственно влияют на доступность:
Управляющий уровень (control plane), который в свою очередь ответственен за:
- управление метаданными;
- обработку ситуаций, когда один из серверов Kafka недоступен;
- обеспечение информацией о том, сколько серверов Kafka сейчас доступно;Уровень данных (data plane), который отвечает за:
- обработку и передачу данных;
- обработку синхронизации метаданных с управляющего уровня.
Исторически так сложилось, что Kafka использует Apache Zookeeper кластер для обмена с целью обеспечения функциональности на управляющем уровне. Zookeeper нужен для обеспечения согласованности состояния кластера Kafka, его конфигурации. Начиная с версии 2.8, в Kafka появился ранний доступ к протоколу KRaft, в котором заявлен новый протокол согласования метаданных. На Хабре довольно подробно уже описывались детали настройки и использования Kafka без Zookeeper [4].
Можно отметить, что в KRaft режиме синхронизации метаданных выполняется без привлечения стороннего сервиса, поэтому восстановление после отказа происходит гораздо быстрее, что положительно влияет на общую доступность кластера Kafka. На данный момент в версии Kafka 3.3.1 KRaft режим заявлен как production ready.
Рассмотрим параметры, которые влияют на доступность на уровне данных. Существует огромное количество других настроек в Kafka, которые могут повлиять на надежность и доступность. Важнейшими из них являются min.insync.replicas и настройка acks.
В Kafka данные хранятся в топиках, и каждый топик состоит обычно из нескольких партиций (partitions) или по-русски, разделов, распределённых между брокерами внутри одного кластера. Разделы могут быть реплицированы среди брокеров, обеспечивая копию каждой записи, которая сохранена физически как лог, сохранённый на множестве брокеров.

Количество копий патриции называют фактор репликации. Фактор репликации одинаковый среди всех разделов в топике. Именно за счёт репликации данных обеспечивается устойчивость к потере данных при выводе из строя одного или нескольких брокеров Kafka. Например, вывод из строя брокера означает потерю данных, если лог не реплицированный, в случае если фактор репликации равен 1.
У каждого раздела есть «лидер», то есть брокер, который работает с клиентами. Именно лидер работает с продюсерами (Producer) и в общем случае отдаёт сообщения консьюмерам (Consumer). К лидеру осуществляют запросы фолловеры (Follower) - брокеры, которые хранят реплику всех данных партиций. Kafka различает фолловеров, которые поддерживают добавление новых записей и тех которые, которые этого не делают.
ISR — это набор реплик раздела, который считается «синхронизированным» (в состоянии in-sync). Ну и, соответственно, конфигурация на стороне брокера min.insync.replicas задаёт число реплик, которые должны быть синхронизированы, чтобы можно было продолжить запись. Эту конфигурацию (min.insync.replicas) можно задать и на уровне раздела.

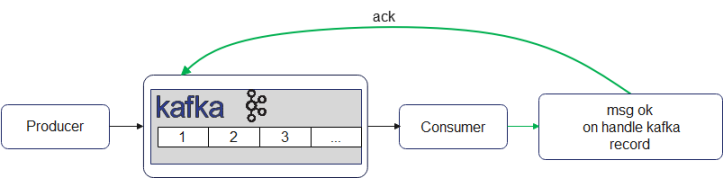
Когда передатчик пытается послать некоторые записи лидеру, он должен ждать от брокера подтверждения (ack сокращённо от acknowledgement), что записи была добавлены.
Существует настройка для продюсеров, которая позволяет выбирать, когда брокер отправляет подтверждение:
Значение acks |
Описание |
acks=0 |
Передатчик не ждёт подтверждения от брокера. Передатчик не повторяет отправку сообщений. Сообщения могут теряться. Низкая надежность. |
acks=1 |
Передатчик ждёт подтверждения от брокера лидера раздела. Как только сообщение записано, отправляется подтверждение. Компромиссная настройка между задержкой, пропускной способностью и надёжностью. |
acks=all |
Передатчик ждёт подтверждения от всех брокеров ISR, которые записали сообщения в лог. Эта настройка влияет на задержу записи. |
Комбинация настроек min.insync.replicas и acks позволяет гибко выбирать режим работы кластера в соответствии с поставленными задачами:
Acks |
min.insync.replicas |
Надежность |
Доступность |
Латентность |
Пропускная способность |
1 |
любое |
Худшая |
Лучшая |
Лучшая |
Хорошая |
all |
1 |
Хорошая |
Лучшая |
Худшая |
Хорошая* |
all |
2 |
Хорошая |
Хорошая |
Худшая |
Хорошая* |
all |
3 |
Лучшая |
Худшая |
Худшая |
Хорошая* |
Хорошая* - сравнимая с хорошей, или лучше
Согласно результатам из [5] для большинства проектов комбинация параметров min.insync.replicas=3 с acks=all является разумным выбором.
Обработка ошибок в Kafka на стороне приёмника отдаётся на откуп разработчику. По умолчанию, если не конфигурировать специальным образом обработку ошибок, то ошибочные сообщения, которые могут возникнуть в обработчике приёмника, могут приводить к многократным повторам и обработку исключительной ситуации до тех пор, пока соответствующий приёмник не установит указатель в актуальное значение, послав брокеру ответ – ack.
1. Блокирующие повторы (Blocking Retries)

Обработка повторов в таком случае, на приёмной стороне блокирует обработчик приёмника (Consumer-а), так как ошибочные сообщения блокируют основной поток сообщений для обработки. Такая стратегия обработки сообщений из Kafka называется «блокирующие повторы». Если количество попыток для повторов кончилось, то ошибочная запись попадает в DLT топик. В случае, если обработчик успешно обработает запись, приёмник уведомляет брокера, что готов к приёму нового сообщения, посылая ack.
2. Неблокирующие повторы (Non-Blocking Retries)
В последних версиях Spring Kafka, начиная с 2.7.0, существует возможность повторно отправлять сообщения, обработанные с исключениями в специальный топик для повторов. Цель этого (этих) топиков - организовать отдельную обработку сообщений, которые по той или иной причине не смогли быть обработаны прежде. Такая стратегия обработки сообщений из Kafka называется «неблокирующие повторы».

Если обработка сообщения происходит с ошибкой в обработчике (handler1), то сообщение перенаправляется в retry топик, который работает по back Off стратегии, настроенной в конфигурации. При сбое отправке сообщения, консьюмер пытается выполнить повторную доставку в retry топик согласно той же back Off стратегии, заданной в конфигурации повторов. Если количество заданных попыток вышло, то такие сообщения попадают в ремонтную очередь DLT (на иллюстрации топик base-topic-dlt), так называемый топик недоставленных сообщений.
Выгода от использования «неблокирующих повторов» очевидна, ведь благодаря повторной обработке в отдельных топиках не прерывается обработка реального потока данных.
Для того чтобы сконфигурировать неблокирующие повторы в Spring Kafka, начиная с версии 2.7.0, в самом простом случае можно добавить аннотацию @RetryableTopic к методу приёмника, аннотированного @KafkaListener
@RetryableTopic(attempts = 5, autoCreateTopics = "false",
topicSuffixingStrategy = TopicSuffixingStrategy.SUFFIX_WITH_INDEX_VALUE,
exclude = {MyExcludeException.class, NullPointerException.class}, traversingCauses = true,
dltProcessingFailureStrategy = DltStrategy.NO_DLT,
backoff = @Backoff(delay = 1000, multiplier = 2, maxDelay = 5000))
@KafkaListener(topics = "my-annotated-topic")
public void processMessage(MyPojo message) {
// ... message processing
}С такой конфигурацией, если первая попытка обработки сообщения заканчивается ошибкой, то сообщение с 1 секундной задержкой посылается в топик my-annotated-topic-retry-0.
Когда вторая попытка обработки сообщения заканчивается с ошибкой, то сообщение с 2 секундной задержкой будет послано в топик my-annotated-topic-retry-1. Следующая попытка получить сообщение произойдёт в топике my-annotated-topic-retry-2, my-annotated-topic-retry-3 и т.д., это произойдёт с задержкой 4, 8 и т.д. секунд соответственно. Обработка сообщения заканчивается на попытке 5, где обработка сообщения просто заканчивается, так как указана стратегия DltStrategy.NO_DLT. Но обычно для ремонтной очереди указывается отдельный обработчик, добавляя к методу аннотацию @DltHandler
@DltHandlerpublic void processDltMessage(MyPojo message) {
// ... message processing, persistence, etc
}Стратегии отсрочек настраиваются через реализации интерфейса BackOffPolicy.
Существуют следующие стратегии отсрочки вызовов:
Fixed Back Off
No Back Off
Exponential Back Off
Random Exponential Back Off
Uniform Random Back Off
Custom Back Off
Важно заметить, что только со стратегией FixedBackOffPolicy и No BackOff возможна конфигурация не блокирующих повторов с помощью одного топика для повторов. В других случаях придётся создавать топики вручную (если указан параметр autoCreateTopics = "false")
При разработке стратегии повторов можно указать, на какие исключения мы будем пытаться делать повторы, а на какие ошибки не будет повторной обработки.
Например, довольно логично что NPE и другие неисправимые ошибки, которые мы можем встретить при обработке в приёмнике, например, из-за невалидных записей, не должны попадать в цепочку повторов, так как запись будет обработана аналогичным образом. Напротив, ошибки, связанные с интеграциями с внешними компонентами, сетевые ошибки и прочие контролируемые исключения могут успешно быть отправлены в цепочку retry топиков для повторной обработки. С помощью опционального параметра include / exclude можно задавать списки исключений, которые используются для явного различения тех исключений, на обработку которых по неблокрующей стратегии можно тратить время, а некоторые исключения, описанные в поле exсlude, лучше сразу передать в топик DLT.
Имеется также возможность программно конфигурировать неблокирующие повторы через определение бина RetryTopicConfiguration в своем конфигурационном классе
@Bean
public RetryTopicConfiguration myRetryTopic(KafkaTemplate<String, MyOtherPojo> template) {
return RetryTopicConfigurationBuilder
.newInstance()
.excludeTopic("excluded-topic")
.notRetryOn(MyDontRetryException.class)
.create(template);
}
В этом примере задаётся конфигурация, в которой мы не обрабатываем записи, при обработке которых генерируется исключение MyDontRetryException. Эта конфигурация будет действовать на все топики, за исключением топика «excluded-topic».
У неблокирующих повторов тем не менее есть и недостаток. Невозможно достоверно гарантировать порядок сообщений при неблокирующих повторах.
3. Блокирующие и неблокирующие повторы
Начиная с версии 2.8.4, в Spring Kafka есть возможность конфигурирования как блокирующих, так и не блокирующих повторов. Например, есть возможность задавать исключения, которые возможно будут приводить к повторным ошибкам и в других записях, например, DatabaseAccessException, поэтому есть возможность делать обработку таких записей повторно без вызова неблокирующих повторов и перенаправления записей в retry топик. Это позволяет гибко настраивать стратегии повторов в зависимости от требований системы. Для того, чтобы сконфигурировать и блокирующие, и неблокирующие повторы, необходимо переопределить методы класса RetryTopicConfigurationSupport в вашем конфигурационном классе, помеченном аннотацией@Configuration.
@EnableKafka
@Configuration
public class MyRetryTopicConfiguration extends RetryTopicConfigurationSupport {
//
@Override protected void configureBlockingRetries(BlockingRetriesConfigurer blockingRetries)
{
blockingRetries.retryOn(MyBlockingRetriesException.class, MyOtherBlockingRetriesException.class).backOff(new FixedBackOff(3000, 3));
}
@Override protected void manageNonBlockingFatalExceptions(List<Class<? extends Throwable>> nonBlockingFatalExceptions) {
nonBlockingFatalExceptions.add(MyNonBlockingException.class);
}
//
}Kafka является достаточно сложной системой, которая обладает довольно внушительным набором параметров для конфигурирования. Использование Spring Kafka значительно уменьшает количество boilerplate кода, который необходим в противном случае, при конфигурировании при помощи нативной библиотеки Kafka. Отмечено также удобство и гибкость в конфигурировании обработки ошибок и различных типов повторов.
Источники: