
JavaScript сегодня стал одним из наиболее предпочтительных языков для веб-скрейпинга (web scraping). Его способность извлекать данные из SPA (Single Page Application) [одностраничное приложение] повышает его популярность. Разработчики могут с легкостью автоматизировать свои задачи при помощи таких библиотек, как Puppeteer и Cheerio, которые доступны в JavaScript.
В этой статье мы обсудим различные библиотеки для веб-скрейпинга в JavaScript, их преимущества и недостатки, определим лучшие из них, а в конце обсудим некоторые различия между Python и JavaScript с точки зрения веб-скрейпинга.

Веб-скрейпинг с помощью Node.js
Прежде чем приступить к изучению данного руководства, давайте познакомимся с некоторыми основами веб-скрейпинга.
Что такое веб-скрейпинг?
Веб-скрейпинг - это процесс извлечения данных с одного или нескольких сайтов с помощью HTTP-запросов к серверу для получения доступа к необработанному (raw - "сырому") HTML определенной веб-страницы и последующего преобразования его в нужный вам формат.
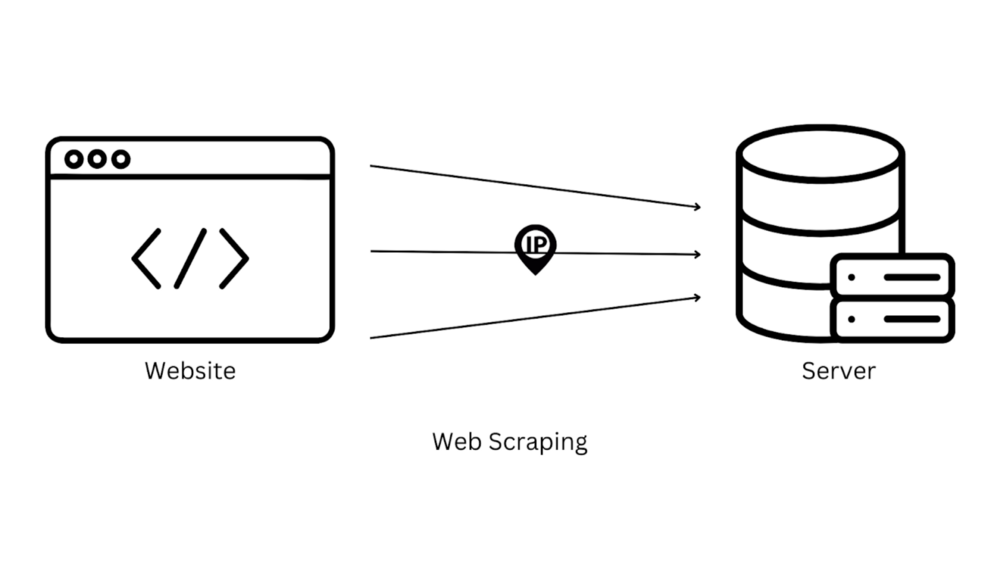
Существуют различные области применения веб-скрейпинга:
SEO (Search Engine Optimization — оптимизация под поисковые системы) - Веб-скрейпинг может применяться для скрейпинга результатов поиска Google, которые могут быть использованы для различных целей, таких как мониторинг SERP (Search Engine Results Page — страница с результатами поиска), отслеживание ключевых слов и т.д.
Мониторинг новостей - Веб-скрейпинг позволяет получить доступ к большому количеству статей из различных СМИ, которые можно использовать для отслеживания текущих новостей и событий.
Лидогенерация - Веб-скрейпинг помогает извлечь контактные данные человека, который может стать вашим потенциальным клиентом.
Сравнение цен - Веб-скрейпинг может быть использован для сбора информации о ценах на товары от нескольких онлайн-продавцов для сравнения цен.
Лучшие библиотеки для веб-скрейпинга в Node.js
Лучшими библиотеками для веб-скрейпинга представленными в Node.js являются:
Unirest
Axios
SuperAgent
Cheerio
Puppeteer
Playwright
Nightmare
Давайте поочередно обсудим вышеперечисленные библиотеки для веб-скрейпинга.
HTTP КЛИЕНТ
HTTP клиент библиотеки используются для взаимодействия с серверами сайтов путем отправки запросов и получения ответов. В следующих разделах мы обсудим несколько библиотек, которые можно использовать для выполнения HTTP-запросов.
Unirest
Unirest - это легковесная библиотека HTTP-запросов, доступная на нескольких языках, созданная и обслуживаемая Kong. Она поддерживает различные HTTP-методы, такие как GET, POST, DELETE, HEAD и т.д., которые могут быть легко добавлены в ваши приложения, благодаря чему ее предпочитают применять для несложных юзкейсов.
Unirest - одна из самых популярных библиотек JavaScript, которая может быть использована для извлечения ценных данных, доступных в интернете.
Давайте рассмотрим на примере, как это можно сделать. Прежде чем начать, я полагаю, что вы уже настроили свой проект Node.js с рабочим каталогом.
Во-первых, установите Unirest JS, выполнив следующую команду в терминале проекта.
npm i unirest Теперь мы запросим целевой URL-адрес, чтобы извлечь необработанные HTML-данные.
const unirest = require("unirest");
const getData = async() => {
try{
const response = await unirest.get("https://www.reddit.com/r/programming.json")
console.log(response.body); // HTML
}
catch(e)
{
console.log(e);
}
}
getData();Вот как можно создать базовый скрейпер с помощью Unirest.
Преимущества:
Поддерживаются все методы HTTP, включая GET, POST, DELETE и т.д.
Она очень быстрая для задач веб-скрейпинга и может без проблем справиться с большой нагрузкой.
Она позволяет передавать файлы через сервер наиболее простым способом.
Axios
Axios - это HTTP клиент на основе промисов как для Node.js, так и для браузеров. Axios широко используется сообществом разработчиков благодаря разнообразию методов, простоте и активному сопровождению. Она также поддерживает различные фичи, такие как отмена запросов, автоматические преобразования для JSON-данных и т.д.
Вы можете установить библиотеку Axios, выполнив приведенную ниже команду в терминале.
npm i axiosСделать HTTP-запрос с помощью Axios очень просто.
const axios = require("axios");
const getData = async() => {
try{
const response = await axios.get("https://books.toscrape.com/")
console.log(response.data); // HTML
}
catch(e)
{
console.log(e);
}
}
getData(); Преимущества:
Она может перехватывать HTTP-запрос и изменять его.
Она имеет большую поддержку сообщества и активно обслуживается его основателями, что делает ее надежным вариантом для выполнения HTTP-запросов.
Она может преобразовывать данные запроса и ответа.
SuperAgent
SuperAgent - еще одна легковесная HTTP клиент библиотека как для Node.js, так и для браузера. Она поддерживает множество высокоуровневых фич HTTP клиента. Она имеет тот же API, что и Axios, и поддерживает как синтаксис промиса, так и синтаксис async/await для обработки ответов.
Вы можете установить SuperAgent, выполнив следующую команду.
npm i superagentВы можете сделать HTTP-запрос используя async/await с помощью SuperAgent следующим образом:
const superagent = require("superagent");
const getData = async() => {
try{
const response = await superagent.get("https://books.toscrape.com/")
console.log(response.text); // HTML
}
catch(e)
{
console.log(e);
}
}
getData();Преимущества:
SuperAgent может быть легко расширена с помощью различных плагинов.
Она работает как в браузере, так и в узле.
Недостатки:
Меньшее количество фич по сравнению с другими HTTP клиент библиотеками, такими как Axios.
Документация представлена не очень подробно.
Библиотеки для парсинга сайтов
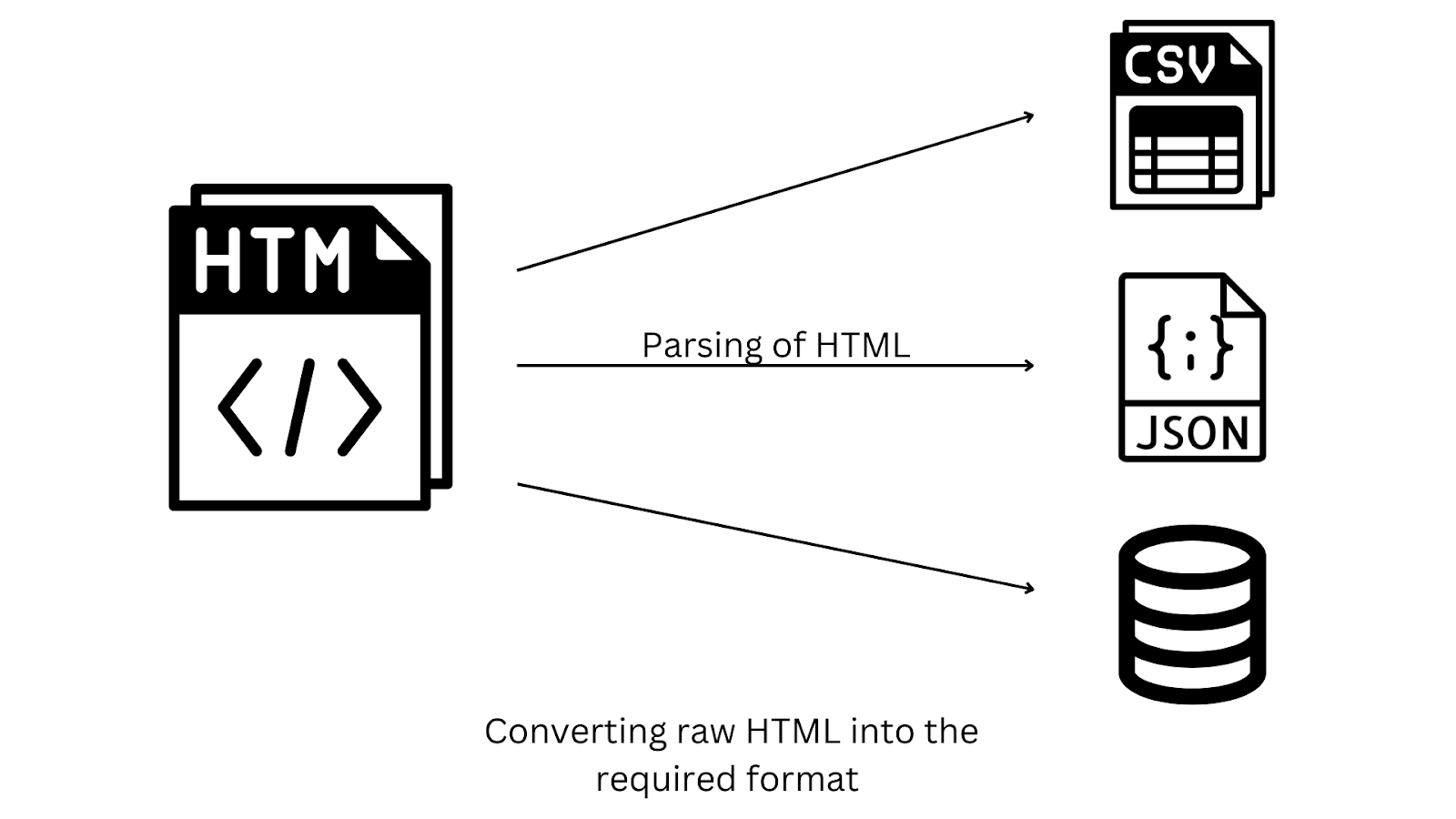
Библиотеки для парсинга сайтов используются при извлечении необходимых данных из необработанного HTML- или XML-документа. В JavaScript существуют различные библиотеки для парсинга сайтов, включая Cheerio, JSONPath, html-parse-stringify2 и др. В следующем разделе мы рассмотрим Cheerio, самую популярную библиотеку для парсинга в JavaScript.
Cheerio
Cheerio - это легковесная библиотека для парсинга в интернете, основанная на мощном API jQuery, которая может использоваться для того, чтобы парсить и извлекать данные из HTML и XML документов.
Cheerio отличается молниеносной скоростью парсинга, манипулирования и рендеринга HTML, поскольку работает с простой последовательной моделью DOM. Это не интернет-браузер, поскольку он не может производить визуальный рендеринг, применять CSS и выполнять JavaScript. Для скрейпинга SPA (Single Page Applications) нам нужны полноценные инструменты автоматизации браузера, такие как Puppeteer, Playwright и т.д., о которых мы поговорим чуть позже.
Давайте соскрейпим название книги на изображении ниже.
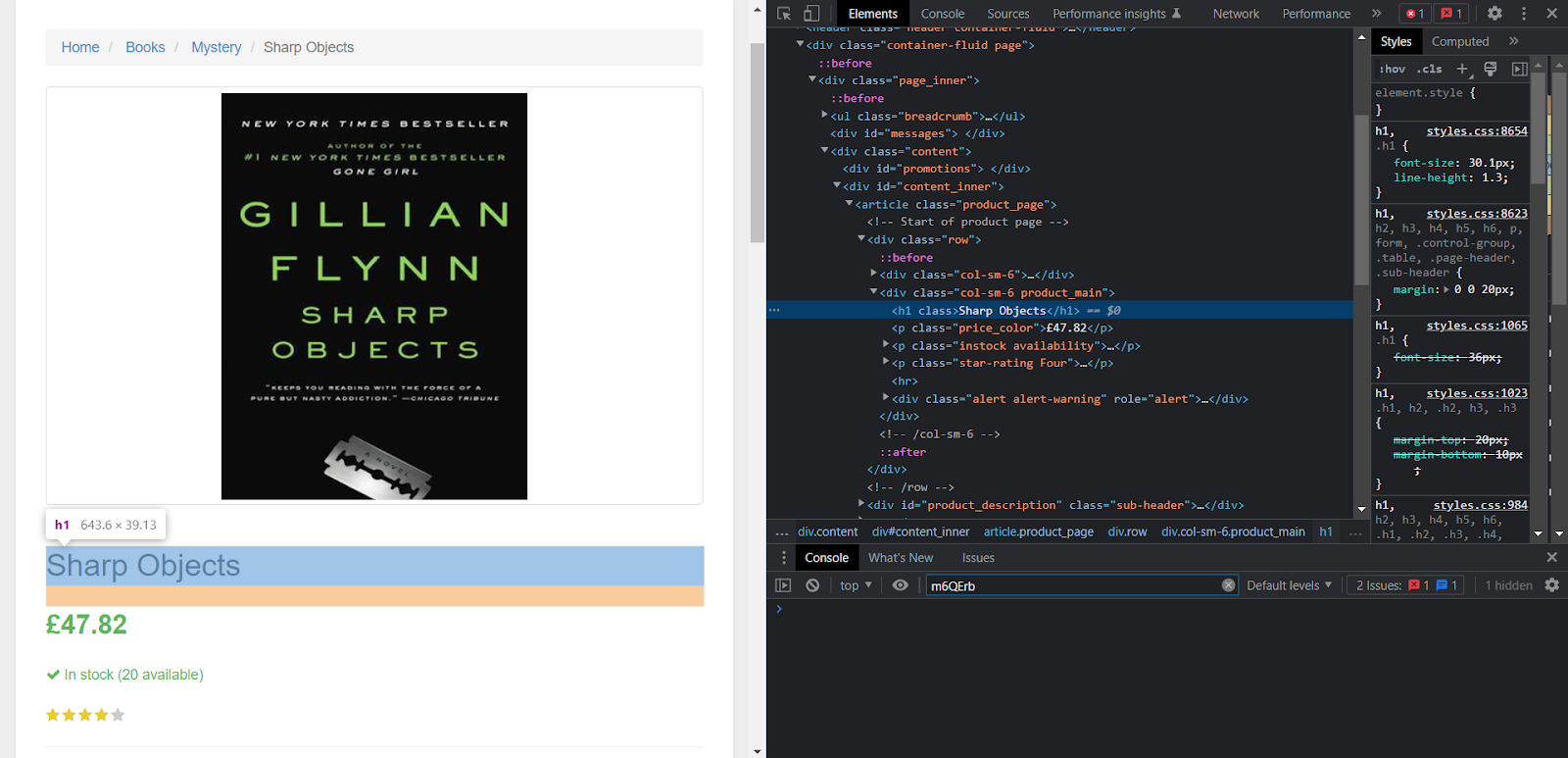
Сначала мы инсталлируем библиотеку Cheerio.
npm i cheerioЗатем мы можем извлечь заголовок, выполнив приведенный ниже код.
const unirest = require("unirest");
const cheerio = require("cheerio");
const getData = async() => {
try{
const response = await unirest.get("https://books.toscrape.com/catalogue/sharp-objects_997/index.html")
const $ = cheerio.load(response.body);
console.log("Book Title: " + $("h1").text()); // "Book Title: Sharp Objects"
}
catch(e)
{
console.log(e);
}
}
getData(); Процесс полностью аналогичен тому, что мы делали в разделе Unirest, но с небольшим отличием. В приведенном выше коде мы загрузили извлеченный HTML в константу Cheerio, а затем использовали CSS-селектор заголовка для извлечения необходимых данных.
Преимущества:
Быстрее, чем любая другая библиотека для парсинга в интернете.
Cheerio имеет очень простой синтаксис и похож на jQuery, что позволяет разработчикам легко выполнять скрейпинг веб-страниц.
Cheerio можно использовать или интегрировать с различными библиотеками веб-скрейпинга, такими как Unirest и Axios, что может стать отличным комбинированным решением для скрейпинга сайта.
Недостатки:
Она не может работать с Javascript.
Headless (безголовые) браузеры

В настоящее время разработка веб-сайтов стала гораздо совершеннее, и разработчики предпочитают содержать на них более динамичный контент, что возможно благодаря JavaScript. Но этот контент, созданный с помощью JavaScript, недоступен при веб-скрейпинге с помощью простого HTTP-запроса GET.
Единственный способ соскрейпить динамический контент - использовать headless-браузеры. Давайте поговорим о библиотеках, которые могут помочь в скрейпинге такого содержимого.
Puppeteer
Puppeteer - это библиотека Node.js, разработанная компанией Google, которая предоставляет высокоуровневый API, позволяющий управлять браузерами Chrome или Chromium.
Особенности, связанные с Puppeteer JS:
Puppeteer можно использовать для лучшего контроля над Chrome.
Она может генерировать скриншоты и PDF-файлы веб-страниц.
Ее можно использовать для скрейпинга веб-страниц, которые используют JavaScript при динамической загрузке содержимого.
Давайте соскрейпим все названия книг и ссылки на них на этом сайте.
Но сначала мы инсталлируем библиотеку puppeteer.
npm i puppeteerТеперь мы подготовим сценарий для скрейпинга необходимой информации.
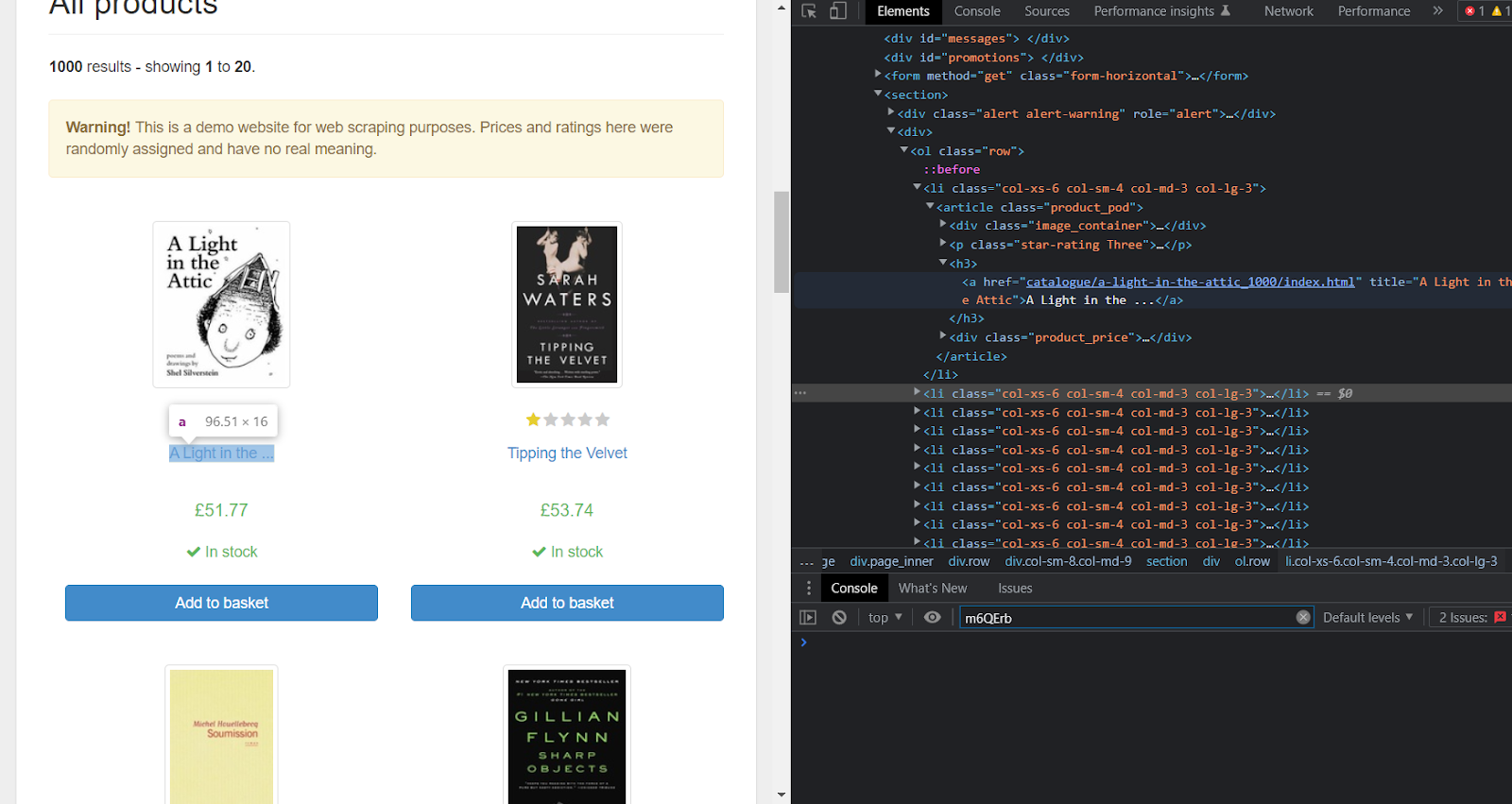
Напишите следующий код в вашем js-файле.
const browser = await puppeteer.launch({
headless: false,
});
const page = await browser.newPage();
await page.goto("https://books.toscrape.com/index.html" , {
waitUntil: 'domcontentloaded'
}) Пошаговое объяснение:
Сначала мы запустили браузер в headless-режиме, установленном на false, благодаря чему можно видеть, что именно происходит.
Затем мы создали новую страницу в headless-браузере.
После этого мы перешли к нашему целевому URL и подождали, пока HTML полностью загрузится.
Теперь мы выполним парсинг HTML.
let data = await page.evaluate(() => {
return Array.from(document.querySelectorAll("article h3")).map((el) => {
return {
title: el.querySelector("a").getAttribute("title"),
link: el.querySelector("a").getAttribute("href"),
};
});
});Функция page.evalueate() выполнит javascript в контексте текущей страницы. Затем, document.querySelectorAll() выберет все элементы, которые идентифицируются с тегами h3 статьи. document.querySelector() - сделает то же самое, но при этом выберет только один HTML-элемент.
Отлично! Теперь выведем данные и закроем браузер.
console.log(data)
await browser.close(); Это даст вам 20 заголовков и ссылок на книги, представленных на веб-странице.
Преимущества:
Мы можем выполнять различные действия на веб-странице, например, нажимать на кнопки и ссылки, перемещаться между страницами, прокручивать веб-страницу и т.д.
С ее помощью можно делать скриншоты веб-страниц.
Функция evaluate() в puppeteer JS помогает выполнять Javascript.
Вам не нужен внешний драйвер для запуска тестов.
Недостатки:
Для ее работы потребуется очень высокая загрузка процессора.
В настоящее время она поддерживает только веб-браузеры Chrome.
Playwright
Playwright - это фреймворк автоматизации тестирования для автоматизации веб-браузеров Chrome, Firefox и Safari с API, аналогичным Puppeteer. Она [библиотека] была разработана той же командой, которая работала над Puppeteer. Как и Puppeteer, Playwright может работать в режимах headless и non-headless, что делает ее подходящим для широкого спектра задач - от автоматизации задач до веб-скрейпинга или веб-краулинга.
Основные различия между Playwright и Puppeteer
Playwright совместима с браузерами Chrome, Firefox и Safari, в то время как Puppeteer поддерживает только Chrome.
Playwright предоставляет широкий спектр опций для управления браузером в режиме headless.
Puppeteer ограничен только Javascript, в то время как Playwright поддерживает различные языки, такие как C#, .NET, Java, Python и т.д.
Давайте установим Playwright прямо сейчас.
npm i playwrightТеперь мы подготовим базовый скрипт для скрейпинга цен и наличия товара на складе с того же сайта, который мы использовали в рубрике "Puppeteer".

Синтаксис очень похож на Puppeteer.
const browser = await playwright['chromium'].launch({ headless: false,});
const context = await browser.newContext();
const page = await context.newPage();
await page.goto("https://books.toscrape.com/index.html"); Функция newContext() создаст новый контекст браузера.
Теперь мы подготовим наш парсер.
let articles = await page.$$("article");
let data = [];
for(let article of articles)
{
data.push({
price: await article.$eval("p.price_color", el => el.textContent),
availability: await article.$eval("p.availability", el => el.textContent),
});
} Затем закроем браузер.
await browser.close();Преимущества:
Поддерживает несколько языков, таких как Python, Java, .Net и Javascript.
Она быстрее, чем любая другая библиотека автоматизации браузеров.
Она поддерживает несколько браузеров, таких как Chrome, Firefox и Safari на одном API.
Документация хорошо написана, что делает ее легкой для изучения и использования разработчиками.
Nightmare JS
Nightmare - это высокоуровневая библиотека, спроектированная как средство автоматизации интернет-браузинга, веб-скрейпинга и различных других задач. Она использует фреймворк Electron (похожий на Phantom JS, но в два раза быстрее), который предоставляет ей headless-браузер, делая ее эффективной и простой в эксплуатации. Применяется преимущественно для тестирования пользовательского интерфейса и краулинга.
Может использоваться для имитации действий пользователя, таких как переход на сайт, нажатие кнопки или ссылки, ввод текста и т.д. с помощью API, который обеспечивает плавное выполнение действий для каждого блока сценария.
Установите Nightmare JS, выполнив следующую команду.
npm i nightmareТеперь мы будем искать результаты "Serpdog" на duckduckgo.com.
const Nightmare = require('nightmare')
const nightmare = Nightmare()
nightmare
.goto('https://duckduckgo.com')
.type('#search_form_input_homepage', 'Serpdog')
.click('#search_button_homepage')
.wait('.nrn-react-div')
.evaluate(() =>
{
return Array.from(document.querySelectorAll('.nrn-react-div')).map((el) => {
return {
title: el.querySelector("h2").innerText.replace("\n",""),
link: el.querySelector("h2 a").href
}
})
})
.end()
.then((data) => {
console.log(data)
})
.catch((error) => {
console.error('Search failed:', error)
}) В приведенном выше коде сначала мы объявили экземпляр Nightmare. Затем перешли на поисковую страничку Duckduckgo.
Затем мы использовали метод type(), чтобы ввести Serpdog в поисковое поле, и отправили форму, кликнув по кнопке поиска на главной странице с помощью метода click(). Мы заставим наш скрейпер дождаться загрузки результатов поиска, после чего извлечем результаты поиска, присутствующие на веб-странице, с помощью их CSS-селекторов.
Преимущества:
Быстрее, чем Puppeteer.
Для работы программы требуется меньше ресурсов.
Недостатки:
У нее нет хорошей поддержки сообщества, как у Puppeteer. Кроме того, в Electron существуют некоторые невыявленные проблемы, которые могут позволить вредоносному веб-сайту выполнить код на вашем компьютере.
Другие библиотеки
В данном разделе мы рассмотрим некоторые альтернативы ранее рассмотренным библиотекам.
Node Fetch
Node Fetch - это легковесная библиотека, которая предоставляет Fetch API в Node.js, позволяя эффективно выполнять HTTP-запросы в среде Node.js.
Особенности:
Позволяет использовать промисы и асинхронные функции.
Реализует функциональность Fetch API в Node.js.
Простой API, который регулярно поддерживается, легкий в использовании и понимании.
Вы можете инсталлировать Node Fetch, выполнив следующую команду.
npm i node-fetchВот как можно использовать Node Fetch для веб-скрейпинга.
const fetch = require("node-fetch")
const getData = async() => {
const response = await fetch('https://en.wikipedia.org/wiki/JavaScript');
const body = await response.text();
console.log(body);
}
getData(); Osmosis
Osmosis - это библиотека веб-скрейпинга, используемая для извлечения HTML или XML документов с веб-страницы.
Особенности:
Не имеет больших зависимостей, таких как jQuery и Cheerio.
Имеет чистый интерфейс, похожий на промис.
Быстрый парсинг и небольшой объем занимаемой памяти.
Преимущества:
Поддерживает ретраи (повторные попытки) и перенаправляет лимиты (ограничения).
Поддерживает один и несколько прокси-серверов.
Поддерживает отправку форм, сессионные куки и т.д.
Подходит ли Node.js для веб-скрейпинга?
Да, Node.js подходит для веб-скрейпинга. Он имеет различные мощные библиотеки, такие как Axios и Puppeteer, благодаря чему является предпочтительным выбором для извлечения данных. Кроме того, простота извлечения данных с веб-сайтов, использующих JavaScript для загрузки динамического контента, позволила ему стать значимым средством для выполнения задач веб-скрейпинга.
В конце концов, большая поддержка сообщества, которой обладает Node.js, никогда не подведет вас!
Заключение
В этом руководстве мы узнали о различных библиотеках в Node.js, которые могут быть использованы для скрейпинга, а также познакомились с их преимуществами и недостатками. Я надеюсь, что этот учебник дал вам полный обзор веб-скрейпинга с помощью Node.js.
Спасибо за прочтение!
Дополнительные ресурсы
Я подготовил полный список блогов для скрейпинга Google на Node.js, который может дать вам представление о том, как собирать данные с продвинутых сайтов, таких как Google.
Перевод статьи подготовлен в преддверии старта курса JavaScript Developer. Professional. По ссылке ниже вы сможете узнать о курсе подробнее, а также зарегистрироваться на бесплатный урок.
return
Зачем-то привели примеры того, как разными либами просто получить контент, с таким же успехом бы еще курл дали.
Сравнивать axios и puppeteer очень странно и если у вас на курсах такая же каша-мала, то это очень грустненькие курсы. Текста много, а толку от него совсем мало.
savostin
Зато они "могут работать в узле".
До настоящего скрепинга еще ой как далеко, в статье простое получение контента и парсинг. Ни проблем с получением, ни с парсингом, ни с масштабированием, ни с индексацией полученного контента, ни с кешированием, обходом блокировки, распараллеливания, сесии/куки/воркеры. Детсад короче ;)