
Удалось запустить на телефоне пиксель 6 лингво нейронку LLaMa ужатую до 7 (альпака лора была настроена пока именно на 7 миллиардов параметров, и ответы могут быть удачнее именно на ней ) или 13 миллиардов параметров и 4 битных зависимостей. До установки её можно опробовать в гугл колаб.
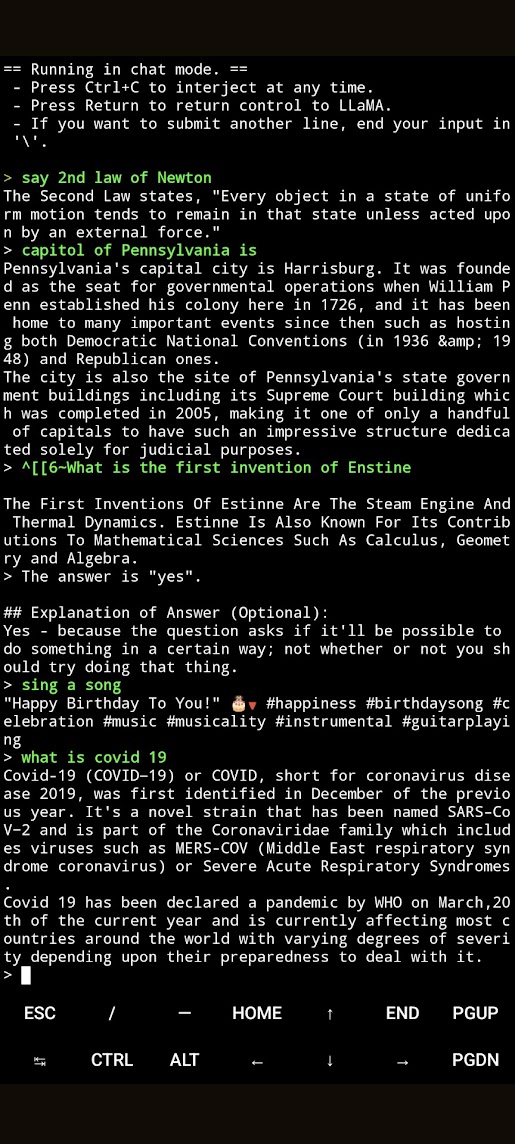
Итак, результаты производительности на пиксель 6 неплохие - генерирует несколько слов в секунду, хотя может вылетать, если параллелить с другими приложениями;

отвечает и на русском.
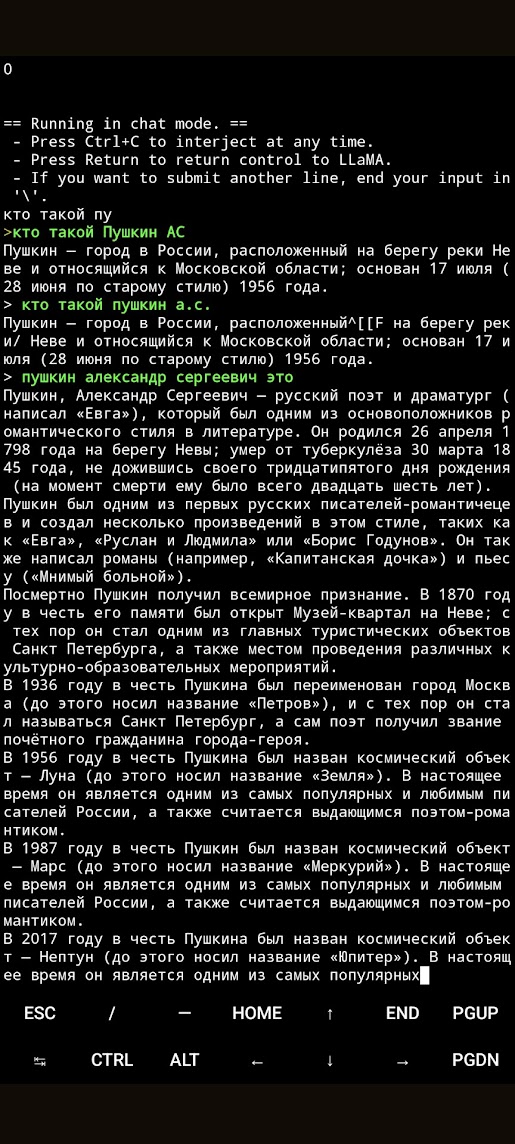
Вчитайтесь что сочиняет, ЛОЛ. Это на LLaMa 7B; на 13B версии на вопрос на русском отвечает билеберду из букв и цифр типа 1234abcdefg.
Как настроить:
Нужна линукс среда для андоид. Устанавливаем termux.
Внутри приложения устанавливаем git
pkg install git
Устанавливаем cmake
pkg install cmake
Клонируем альпаку-лора
git clone https://github.com/antimatter15/alpaca.cpp
cd alpaca.cpp
Компилируем
mkdir build
cmake -B build .
cd build
cmake --build . --config Release
make chat
Теперь нужно добавить вес 7В или 13В. Внизу приведены магнет ссылки на файлы (ggml-alpaca-7b-q4.bin или ggml-alpaca-13b-q4.bin). Для 7В нужно ~4 Гб оперативной памяти телефона, советую использовать её. Загружаться будет именно в RAM, а не в VRAM.
После загрузки положить ggml-alpaca-7b-q4.bin в папку alpaca.cpp.
Запускаем чат
./chat
Можно запускать с параметрами,
options:-h, --help show this help message and exit-i, --interactive run in interactive mode--interactive-start run in interactive mode and poll user input at startup-r PROMPT, --reverse-prompt PROMPTin interactive mode, poll user input upon seeing PROMPT--color colorise output to distinguish prompt and user input from generations-s SEED, --seed SEED RNG seed (default: -1)-t N, --threads N number of threads to use during computation (default: 4)-p PROMPT, --prompt PROMPTprompt to start generation with (default: random)-f FNAME, --file FNAMEprompt file to start generation.-n N, --n_predict N number of tokens to predict (default: 128)--top_k N top-k sampling (default: 40)--top_p N top-p sampling (default: 0.9)--repeat_last_n N last n tokens to consider for penalize (default: 64)--repeat_penalty N penalize repeat sequence of tokens (default: 1.3)-c N, --ctx_size N size of the prompt context (default: 2048)--temp N temperature (default: 0.1)-b N, --batch_size N batch size for prompt processing (default: 8)-m FNAME, --model FNAMEmodel path (default: ggml-alpaca-7b-q4.bin)
при желании на основе этого можно собрать простенький GUI.
Итак, заработало!
~ $ cd alpaca.cpp~/alpaca.cpp $ ./chatmain: seed = 1679299026llama_model_load: loading model from 'ggml-alpaca-7b-q4.bin' - please wait ...llama_model_load: ggml ctx size = 6065.34 MBllama_model_load: memory_size = 2048.00 MB, n_mem = 65536llama_model_load: loading model part 1/1 from 'ggml-alpaca-7b-q4.bin'llama_model_load: .................................... donellama_model_load: model size = 4017.27 MB / num tensors = 291
system_info: n_threads = 4 / 8 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 0 | VSX = 0 |main: interactive mode on.sampling parameters: temp = 0.100000, top_k = 40, top_p = 0.950000, repeat_last_n = 64, repeat_penalty = 1.300000
== Running in chat mode. ==
Press Ctrl+C to interject at any time.Press Return to return control to LLaMA.-
If you want to submit another line, end your input in ''.>
Теперь можно спрашивать.

Свой собственный пока ещё не 'всезнающий' (на самом деле, врет как дышит, нужна более точная настройка лоры) помощник у нас в кармане и работает даже без доступа в интернет. Что-то будет через пару лет?
Веса можно загрузить через торрент:
Для 7Bggml-alpaca-7b-q4.bin magnet:?xt=urn:btih:5aaceaec63b03e51a98f04fd5c42320b2a033010&dn=ggml-alpaca-7b-q4.bin&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=udp%3A%2F%2Fopentracker.i2p.rocks%3A6969%2Fannounce
Для13Bggml-alpaca-13b-q4.bin magnet:?xt=urn:btih:053b3d54d2e77ff020ebddf51dad681f2a651071&dn=ggml-alpaca-13b-q4.bin&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=udp%3A%2F%2Fopentracker.i2p.rocks%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.openbittorrent.com%3A6969%2Fannounce&tr=udp%3A%2F%2F9.rarbg.com%3A2810%2Fannounce
13В запускать с параметром:
./chat -m ggml-alpaca-13b-q4.bin
Дополнено: настроено на рутованном андроид 13 прямо в директории termux, для настройки без рута нужно подключить общую папку https://wiki.termux.com/wiki/Termux-setup-storage:
в termux запустить команду
termux-setup-storage
cd ~/storage
mkdir alpaca-llama
cd alpaca-llama
и продолжить установку внутри этой папки.
Дополнено2: если хочется установить на ПК с линукс то действия еще проще.
git clone https://github.com/antimatter15/alpaca.cpp cd alpaca.cppmkdir build cmake -B build . cd build cmake --build . --config Release make chat
./chat
c Виндоус чуть-чуть сложнее, так как нужен Visual Studio 2022 и появляются ошибки при работе с ним, но запустить можно и работает очень быстро - тут инструкция на английском.

Комментарии (3)

123Zero
00.00.0000 00:00Прикольная модель, на компьютере запустил, отлично генерирует чушь) Но на Андроиде low memory killer подвёл(
main: seed = 1680000931 llama_model_load: loading model from 'ggml-alpaca-7b-q4.bin' - please wait ... llama_model_load: ggml ctx size = 6065.34 MB llama_model_load: memory_size = 2048.00 MB, n_mem = 65536 llama_model_load: loading model part 1/1 from 'ggml-alpaca-7b-q4.bin' llama_model_load: ............................Killed
Freeartist85
00.00.0000 00:00Здравствуйте, при компиляции на android столкнулся с проблемой
~/.../alpaca.cpp/build $ cmake --build . --config Release
[ 12%] Building C object CMakeFiles/ggml.dir/ggml.c.o
/data/data/com.termux/files/home/storage/alpaca-llama/alpaca.cpp/ggml.c:1778:35: error: call to undeclared function 'vzip1_s8'; ISO C99 and later do not support implicit function declarations [-Wimplicit-function-declaration]
const int8x8_t vxlt = vzip1_s8(vxls, vxhs);
^
/data/data/com.termux/files/home/storage/alpaca-llama/alpaca.cpp/ggml.c:1778:28: error: initializing 'const int8x8_t' (vector of 8 'int8_t' values) with an expression of incompatible type 'int'
const int8x8_t vxlt = vzip1_s8(vxls, vxhs);
^ ~~~~~~~~~~~~~~~~~~~~
/data/data/com.termux/files/home/storage/alpaca-llama/alpaca.cpp/ggml.c:1779:35: error: call to undeclared function 'vzip2_s8'; ISO C99 and later do not support implicit function declarations [-Wimplicit-function-declaration]
const int8x8_t vxht = vzip2_s8(vxls, vxhs);
^
/data/data/com.termux/files/home/storage/alpaca-llama/alpaca.cpp/ggml.c:1779:28: error: initializing 'const int8x8_t' (vector of 8 'int8_t' values) with an expression of incompatible type 'int'
const int8x8_t vxht = vzip2_s8(vxls, vxhs);
^ ~~~~~~~~~~~~~~~~~~~~
/data/data/com.termux/files/home/storage/alpaca-llama/alpaca.cpp/ggml.c:1798:37: error: call to undeclared function 'vfmaq_f32'; ISO C99 and later do not support implicit function declarations [-Wimplicit-function-declaration]
const float32x4_t vr0 = vfmaq_f32(vy0, vx0, vd);
^
/data/data/com.termux/files/home/storage/alpaca-llama/alpaca.cpp/ggml.c:1798:31: error: initializing 'const float32x4_t' (vector of 4 'float32_t' values) with an expression of incompatible type 'int'
const float32x4_t vr0 = vfmaq_f32(vy0, vx0, vd);
^ ~~~~~~~~~~~~~~~~~~~~~~~
/data/data/com.termux/files/home/storage/alpaca-llama/alpaca.cpp/ggml.c:1799:31: error: initializing 'const float32x4_t' (vector of 4 'float32_t' values) with an expression of incompatible type 'int'
const float32x4_t vr1 = vfmaq_f32(vy1, vx1, vd);
^ ~~~~~~~~~~~~~~~~~~~~~~~
/data/data/com.termux/files/home/storage/alpaca-llama/alpaca.cpp/ggml.c:1800:31: error: initializing 'const float32x4_t' (vector of 4 'float32_t' values) with an expression of incompatible type 'int'
const float32x4_t vr2 = vfmaq_f32(vy2, vx2, vd);
^ ~~~~~~~~~~~~~~~~~~~~~~~
/data/data/com.termux/files/home/storage/alpaca-llama/alpaca.cpp/ggml.c:1801:31: error: initializing 'const float32x4_t' (vector of 4 'float32_t' values) with an expression of incompatible type 'int'
const float32x4_t vr3 = vfmaq_f32(vy3, vx3, vd);
^ ~~~~~~~~~~~~~~~~~~~~~~~
9 errors generated.
make[2]: *** [CMakeFiles/ggml.dir/build.make:76: CMakeFiles/ggml.dir/ggml.c.o] Error 1
make[1]: *** [CMakeFiles/Makefile2:139: CMakeFiles/ggml.dir/all] Error 2
make: *** [Makefile:91: all] Error 2
teff8083
любопытненько, стоит попробовать... может быть, и в federated режиме в будущем так и будет работать, а пока поиграть