
Наступают времена, когда офисному сотруднику недостаточно знать Word и Excel в качестве минимального обязательного базиса программных продуктов. No‑code/Low‑code платформы и продукты — вот что незаметно становится обязательным для владения каждым. Эти платформы есть самый быстрый на сегодня способ без изучения языков программирования овладеть навыками использования искусственного интеллекта, машинного обучения, анализа big data, причём очень бигдата — на сотни миллионов строк.
Платформа Knime — один из таких инструментов. На первый взгляд это улучшенный Excel+BI. Но, когда посмотришь поглубже его возможности, то, очевидно — это обязательный инструмент будущего, по крайней мере для тех кто не являясь программистом хочет получить навыки как у программиста. Для простоты — Knime это «графическое» программирование. Берёшь квадратики, размещаешь в виде бизнес‑процесса, соединяешь их между собой и оп! — уже провёл анализ маркетингового плана или парсинг сайтов конкурентов или анализ рекламных текстов с помощью NLP. Или, даже строишь приборную доску управления производственного предприятия будучи простым менеджером/инженером. Или ведёшь обработку научных данных.
Knime позволяет, конечно, и код писать, причём на трёх языках Python, Java, R, но это не обязательно. Бизнес‑процессы знаешь, рисуешь? Вперёд!
Разумеется, при работе с огромными массивами данных, требования к компьютерным ресурсам возрастают. И что делать, если вам доступен простенький офисный или домашний компьютер? Или, если вы видите что аренда облачного ресурса на месяц дороже, чем купить компьютер с 64Гб оперативной памяти и процессором гоняющим Atomic Heart или Hogwartz Legacy на среднемалках?
И опять всё вам доступно и бесплатно доступно. Ниже пойдёт описание как решалась задача обработки сотни миллионов строк исходных данных на бюджетном компьютере. На её примере вы можете сделать прикидки какой объём данных сможет осилить ваш компьютер.
Итак.
Возникла необходимость обрабатывать порядка 75 000 файлов XML в каталогах на локальном компьютере.
Размеры файлов от 1 Кб до 121Мб.
Из одного файла могут извлекаться от одной строки до 6,4 миллионов строк.
В итоге суммарное количество строк в одной таблице составило около 225 миллионов строк.
Используемый компьютер — домашний десктоп со следующими характеристиками:
процессор AMD Athlon 3000G (2 ядра, 4 потока);
оперативная память 16Гб, в том числе 2Гб зарезервированы под графическую обработку;
графической карты нет, все расчёты выполняет процессор;
бюджетная материнская плата Gigabyte A520M DS3H;
хранение информации на nvme SSD Netac, сохранение конечных файлов на HDD 5400 об/мин;
разгон процессора и оперативной памяти не производился;
операционная система — Windows.
Как видите, компьютер обычный офисный и слабый для обработки таких объёмов данных.
С другой стороны, какими бы мощными не были ваш компьютер, сервер или облако, жизнь всегда подкидывает задачи на грани возможностей имеющейся техники.
И вот опять умение выжимать из имеющегося всё возможное актуально.
Задача состояла в том чтобы:
построчно считать файлы в таблицу;
обработать строки (вынести теги xml и тела тегов в отдельные колонки, а также в отдельные колонки вывести имена параметров xml и их значения).
Цель: Подготовить массив данных из xml для машинного обучения.
Какие проблемы надо было решить на низко производительном компьютере:
1) обработать массив в несколько сотен миллионов строк;
2) избежать вылетов из-за переполнения памяти;
3) отнять часть ресурсов компьютера у Knime, чтобы без зависаний и торможений позволить выполнять за компьютером другую работу, пока обрабатывались данные в Knime.
Теперь рассказ как этого удалось добиться.
На представленной вам картинке вы видите организацию рабочего потока в knime-workflow
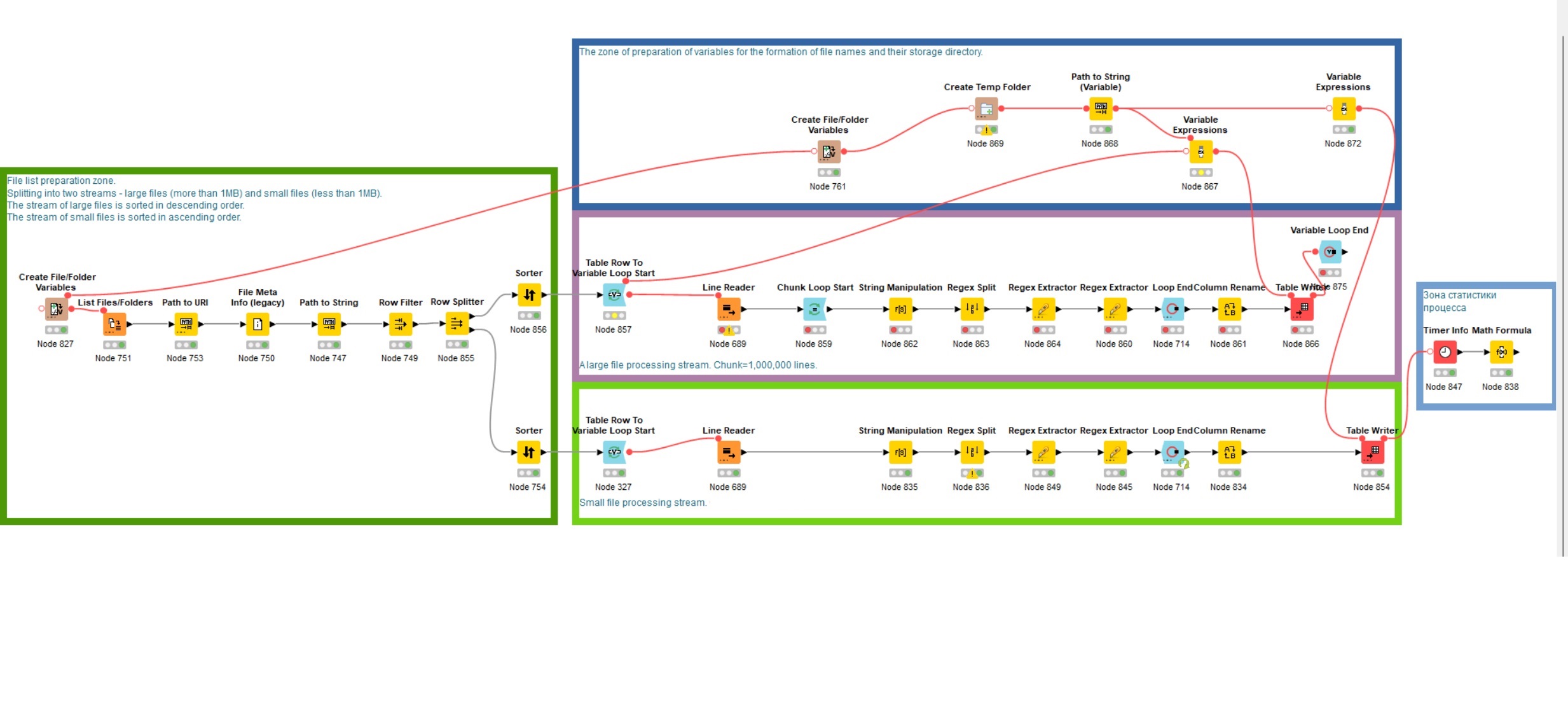
Вручную задаются ноды (те самые квадратики) с каталогами с файлами‑источниками и временный каталог для хранения результатов.
При чтении файлов происходит их фильтрация по типу и регулярным выражениям, применяемым к пути и именам файлов.
Считывание файлов происходит в узле Line Reader.
Считывание и обработка списка файлов ведётся в одном потоке.
Обработка файлов построчно разделена на два потока — поток файлов большого размера (от 1Мб, отсортированы по убыванию) и поток файлов малого размера (до 1Мб, отсортированы по возрастанию).
Размеры файлов в двух потоках разнонаправлены. Два потока и разнонаправленность дали увеличение производительности на одном процессоре более чем в 2 раза по сравнению с однопотоковой обработкой.
Разделение файлов на два потока по границе в 1Мб мною сделано условно на примере моих данных. Вам же стоит попробовать сделать разделение на основе медианы размеров файлов. Главная цель, чтобы разнонаправленные потоки создали равномерную загрузку компьютера.
Настройка Knime Preferences — Maximum Working threads for all nodes на примере обработки порядка двух миллионов строк даёт следующие расклады затрат времени:
3 треда — 1 минута.
24 треда — 1,065 минуты.
100 тредов — 0,7 минуты.
Попытка включить в нодах режим Job manager вместо default на streaming привела только к ухудшению производительности и удлинению общего времени исполнения. Видимо, причина в том, что не все ноды в линии умеют работать в таком режиме.
Попытка включить в workflow режим Table Backend в положение Columnar Backend вместо default привела только к ухудшению производительности и удлинению общего времени исполнения. Видимо, причина в том, что режим Columnar Backend эффективен в случаях, когда в таблицах много столбцов и мало строк. А у меня ситуация другая — в таблице не более двух десятков столбцов и сотни миллионов строк.
Параметр knime.ini
‑Dknime.compress.io
установлен в NONE для уменьшения потерь времени на сжатие временных данных. Памяти в 16Гб уже достаточно.
После считывания всех файлов в строки одной таблицы, поток нод с большими файлами заключен в цикл из нод Chunk Loop Start и Loop End, так как обработка строк порциями показала себя быстрее, чем обработка одной таблицы в 225 миллионов строк в один проход. Выигрыш примерно до 2х крат по времени.
Рекомендую пробовать разные chunk на своих компьютерах, поскольку, chunk снижает вероятность вылета Knime на компьютерах с малой памятью.
Chunk в 100 000 строк обычно себя оправдывает, но иногда лучше работает chunk в 1 миллион строк, особенно на сотнях миллионов строк данных. Видимо, потому что сокращается количество итераций и связанных с этим операций.
Общий ориентир при определении размера chunk — желательно, чтобы цикл исполнялся за несколько десятков итераций.
Если число итераций цикла достигает нескольких тысяч повторений, то вероятность вылета Knime повышается.
Таким образом, на миллионы строк в таблице хорош chunk в 100 000 строк (при этом chunk в 1 000 000 работает не хуже), а для таблицы в сотни миллионов строк — chunk в 1 000 000 строк надёжнее.
Ранее ноды Run Garbage Collector вставлялись мною специально, так как их применение исключило вылеты Knime из‑за переполнения памяти. Эти ноды сработали уже на оперативной памяти в 16Гб и позволили процессу доходить до конца. Успешное прохождение процесса стало гарантированным.
С ними можете на компьютере с работающим процессом Knime выполнять другую работу. При этом, Knime может подвисать, но не останавливать работу, а подвисания всего компьютера редки и кратки.
Но это оправдывало себя на примерах в миллионы строк.
Но в примерах на сотни миллионов строк ноды сбора мусора стали приводить к регулярным зависаниям Knime и переключения между другими программами. Видимо, причина в том, что нода Run Garbage Collector не очень хорошо понимает, что есть мусор, а что пока ещё нужные временные данные, и удаляла их, из‑за чего Knime тратил ресурс компьютера на восстановление ситуации.
Работа с нодами Garbage Collector замедлила работу процесса в 7 раз как минимум, чем без них.
По ходу работы объём оперативной памяти был увеличен до 80Гб. К сожалению, не сохранил замеры, в чем выразилось изменение производительности по сравнению с 16Гб. Но субъективно ничем особо лучше не стало. Памяти Knime всё равно хочет больше.
Было поставлено принудительное ограничение размера кучи до 8Гб (при памяти в 16Гб) и до 50Гб сейчас при памяти 80Гб. Это ограничение работает постоянно. В диспетчере задач Windows также был понижен приоритет процесса Knime до «ниже среднего», а в «Задать сходство» оставлены для knime только 3 потока из 4. Это ограничение не сохраняется при перезагрузке компьютера. Ограничения введены сознательно, чтобы пользоваться компьютером без зависаний и тормозов во время вычислений Knime.
Нода Variable Expression служит для формирования имён выходных файлов в цикле, вставляя в имя файла номер итерации цикла.
Ноды Chunk Loop Start и Loop End занимают очень много времени.
Chunk Loop Start, похоже, для каждого chunk создаёт пустую таблицу на заданное количество строк, а потом заполняет её данными из обрабатываемой таблицы. Кажется не очень оптимальным вместо простого вырезания из основной таблицы нужного блока.
В ноде Loop End происходит склеивание общего результата работы цикла в общую таблицу. Поэтому лучше её заменять на ноду Variable Loop End, так как она не собирает итоговые таблицы, а только переменные.
Ранее, после ноды завершения цикла, стояла нода записи результата в файл. Но при 225 млн строк, размер конечного файла занимает порядка 8Гб и крайне длительное время записи на диск. Поэтому была введена запись результата внутри цикла в отдельные файлы поменьше. Для дальнейшей обработки это будет также в лучшую сторону влиять на производительность.
Общее время обработки 225 млн. строк при chunk = 1 000 000 строк занимает при указанных выше условиях 11 часов (Нет! Меньше! см. далее). (Но, кажется, мой компьютер схитрил, при долгой отлучке он ушёл в гибернацию и при пробуждении Knime продолжил как ни в чём не бывало, но часа 2 надо убавить, итого 9 часов).
Общее время обработки около 2 млн. строк при chunk = 100 000 строк занимает при указанных выше условиях 0,5 минуты.
Общее время обработки около 2 млн. строк при chunk = 1 000 000 строк занимает при указанных выше условиях 1 минуту.
И да! Я выяснил, что Knime хитрец! Оказывается при переходе компьютера в гибернацию (а также, кажется, что и в сон) он приостанавливает работу. При пробуждении из гибернации он мгновенно начинает работу и кажется что он не прерывался.
А я удивлялся, откуда при объективном времени работы в 9–11 часов, статистика Knime показывала 4–5 часов работы или менее.
Ноды статистики учитывают только время реальной работы ноды, а не время с начала процесса.
Файл описанного процесса Knime, какой он получился в итоговом виде прилагается (см. картинку выше).
Прилагается также файл статистики работы процесса knime для процесса в 223 млн. строк.
Там вы можете увидеть, какие ноды занимают больше всего времени.

В результате, после многих попыток и вариантов обработки 225 млн. строк обрабатываются за 2,5 часа (по замерам Knime это 55 минут).
Зная, какой у меня процессор, вы можете зайти на сайт или аналогичный и сравнить со своим процессором и по бенчмаркам прикинуть во сколько раз медленнее или быстрее ваш процессор обработает подобную задачу.
По итогам этого моего опыта с Knime выгоднее инвестировать в самый производительный процессор, чем в память. По данным наблюдения за производительностью в диспетчере задач Knime съест любую память, ему и 80Гб мало, поэтому его кучу придётся ограничивать по любому. А вот процессор явно не успевает за обработкой даже при памяти в 16Гб.
Политика памяти workflow установлена на "размещать в памяти". Попытка всем нодам назначить "размещать на диске" явного эффекта не дала и на переполнение оперативной памяти особо не влияет. Запись промежуточных выходных данных на диск внутри цикла показала себя более эффективной.
Практика показала, что запись в итоговый файл обработанных результатов при размере файла более 1Гб (а у меня выходило по 8Гб) занимает чрезвычайно много времени. Поэтому, если вы собираетесь подвергать обработанные данные ещё дальнейшей обработке, то лучше записывать в файлы меньшего размера. Отсюда вывод - chunks надо делать таким, чтобы в отдельный файл попадало порядка 1 миллиона строк, не больше. Точное число зависит от вашего компьютера, скорости вашей дисковой системы.
Я в итоге даже в ветке обработки малых файлов переделал окончание процесса на дробное записывание итога основного цикла через цикл с chunk.
Весь процесс написан на Knime без единой строчки кода.
Ни один питон, джаба и R не пострадали при этом эксперименте.
Вот такой расклад.
Я новичок в Knime, первый месяц изучаю его. Буду рад подсказкам, что можно сделать лучше в Knime, как эффективнее построить процесс и ноды.
Особенно буду признателен, если кто подскажет, как настроить Apache Spark в домашней локальной сети под Windows, чтобы распределить вычисления Knime на домашние компьютеры без сервера Knime.
Оперативно связаться со мной можно в Telegram https://t.me/RomanKlmnsn или там же в чате https://t.me/SPPR_1C
Или написать здесь.
Дополнительная информация по производительности
Статистика по 1 потоку на 2 миллиона строк и chunk 1 миллион строк:

Статистика по 1 потоку на 223 миллиона строк и chunk 1 миллион строк:

Ananiev_Genrih
С одной стороны хочется похвалить автора (всего месяц и без единой строки кода решает такие задачи, да еще бенчмарки и оптимизацию проводит), с другой - сильное ощущение что автор чем-то не тем занимается и вот здесь как раз бы Питон и R с удовольствием бы "пострадали", решив эту задачу в несколько потоков в несколько раз быстрее на том же железе
R72 Автор
У меня в итоге вышло 2,5 часа на 223 миллиона строк. Ваше "в несколько раз быстрее" сколько означает времени на 223 миллиона строк, если код написать на питоне?
Ananiev_Genrih
Для ответа на ваш вопрос надо получить доступ именно к вашим исходным файлам и запускать код на вашей же машине. Будет точно быстрее лучшего результата не только за счёт отсутствия "джава-оверхеда", но и за счет использования более оптимальных библиотек чтения/записи (на плюсах, а там уже вызов хоть из питон хоть из R, не так важно, к обоим написаны).
Тут не про критику (если вы так это воспринимаете), а про то что у всех лоу-код есть границы применимости ограничивающие их масштабирование, и чем дальше нырять за такие границы тем будут страшнее велосипеды
R72 Автор
Специально привёл множество деталей про свой комп и условия задачи, чтобы можно было сравнить своё решение на другой машине с другим кодом через сопоставление бенчмарков процессоров. Понятно что это неточно, но вполне достаточно. Конечно, если у меня 2,5 часа, а у кого-то 2 часа, то это ни о чём и бенчмарк ни к чему. Но если есть решение на полчаса, то вполне такого сопоставления по процессорам хватит.
R72 Автор
И такой момент, есть сомнения, что исполнение в чистом коде что-то сильно улучшит. В статье приведены цифры - задача на 1,5-2 миллиона строк решается за 1 минуту. Вполне себе скорость. Задача за 200 млн. строк с таким трендом должна за 3,5 часа решаться. А тут за 2,5.
R72 Автор
Конечно, у лоу-кода есть границы. Но и Knime - решение для тех, кто не хочет тратить 3 года на обучение программированию, чтобы писать код выжимающий капли времени, а хочет получить мощный инструмент здесь и сейчас. В конце-концов, языки программирования развиваются в направлении соответствия человеческому языку, т.е. языку простого пользователя.