

Меня давно волнует вопрос, как подступиться к разработке на голом железе, на чистом си. Хотелось понять, каким же образом идёт запуск BIOS, u-boot, grub и прочих первичных загрузчиков. Ведь необходимо перейти от ассемблера к тёплому ламповому си и соблюсти условие, собрать всё это в линукс любимым компилятором gcc.
Хотя я и имею достаточный опыт BareMetal-разработки, тем не менее, всё это были чужие проекты со своим кодом. А мне хотелось понять, как начать свой проект с чистого листа, когда есть только чистая железка и идея. Толковых статей как подступится к этой задаче достаточно мало, при этом совершенно непонятно, с какого же края к ней подходить.
Здесь я хочу свести основные моменты разработки BIOS в одном месте и разобраться обо всех проблемах, которые я получил во время своих опытах в разработке (первая и вторая части).
Чтобы подступиться к этой задаче, мне пришлось переработать просто кучу различной информации, прочитать несколько книг, часть из которых была на английском языке. На русском информации вообще исчезающе мало, поэтому и хочется немного добавить своей.
Поскольку пересказать объёмы переработанного материала не представляется возможным, остановлюсь на некоторых ключевых моментах, которые помогут стартануть.
Помните: лучший способ начать программировать – это начать разбираться и править чужие проекты. Поэтому в качестве примера приведу обзор референсных проектов, с которых я черпал вдохновение.
Рéференс (англ. reference — справка, сноска) — вспомогательное изображение: рисунок или фотография, которые художник или дизайнер изучает перед работой, чтобы точнее передать детали, получить дополнительную информацию, идеи.
Википедия.
❯ Референсные проекты
Возможно, корректнее было бы назвать их эталонными, но я смотрел на них скорее для вдохновения.
iPXE — open source boot firmware
Проект iPXE – это фактически и есть разработка ROM BIOS для сетевой карты, при этом iPXE уже имеет внутри себя поддержку достаточно обширного функционала.

Исходный код проекта я изучал пару недель, практически как открытую книгу, читал буквально как фантастический приключенческий роман. Он прекрасен всем, там можно посмотреть, как реализовывать свою библиотеку libc на голом железе, как производить копирование областей памяти в защищённом и реальном режиме, как осуществлять переключение между режимами, для различного функционала, как сделать свой tcp/ip cтек и многое другое. Для меня это эталонный проект, с которого можно начинать (правда, имея уже некоторый багаж знаний). Ещё он крут тем, что много кода можно позаимствовать из него (с соблюдением соответствующих лицензий).
К недостаткам проекта можно отнести только то, что он достаточно объёмный, хотя основные моменты можно изучить за пару недель, более глубокое погружение в него потребует большего количества времени. Но ценен он тем, что собирается gcc, а значит, может быть применен в будущих проектах в дальнейшем.
К плюсам можно отнести также то, что он достаточно неплохо документирован. В общем, это идеальный вариант для обучения.
Для моих задач он оказался слишком объёмным и не давал ответа на некоторые мелкие ключевые вопросы, найти решение которых, в дебрях тысяч строк кода и скриптов, не представлялось для меня возможным.
BIOS Terminal
Поиск по github вывел меня на проект превращения старенького ПК в терминал. Для этого понадобится просто видеокарта, плата с ROM-BIOS и COM-порт.

Автор даже приводит фотографию самодельной платы расширения для запуска своего кода. Фактически он реализовал полноценный VT100 терминал. К сожалению, документация к этому проекту есть только на польском языке, но в целом понятная.
Проект очень полезен для изучения, но у него имеется два фатальных недостатка: он собран компилятором bcc, и фактически представляет собой один cи-файл (который просто собирается из инклудов).
Сам же компилятор bcc просто делает на выходе ассемблеровский файл, который потом уже транслируется в бинарный вид. Это замечательный лайфхак для таких систем, но для моих целей он не подходит, потому что я искал примеры с компилятором gcc.
В этом проекте есть интересный пример загрузчика кода loader.asm, на котором я подробнее остановлюсь ниже.
Резюмируя: проект очень хорош для старта, но фактически это ассемблер, хоть и написанный на си. Есть некоторые технические решения, которые я нашёл полезными для себя, часть из них описана здесь. Однако сам проект лежит вне технической задачи, которую я ставил для себя: написать свой BIOS на си и собрать его компилятором gcc.
Как собрать досовский COM-файл компилятором GCC
Проект — прекрасный образец того, как можно с помощью gcc под linux собирать программы для других операционных систем, например DOS. Есть оригинальная статья на английском, но также на хабре был её перевод.

Есть несколько ценных моментов в этом проекте. К одним из них можно отнести примеры реализации «стандартной» библиотеки, которые позволяют использовать стандартный код. Другая полезная часть, которая будет полезна начинающим биосописателям — это скрипт линкера. Исполняемые COM-файлы имеют особенность: они загружаются строго по адресу 0x100, и далее идёт выполнение по этому адресу. Таким образом, при компиляции, необходимо указывать компоновщику, по каким адресам будет располагаться код, чтобы все переходы и вызовы функций работали корректно. Для этого и создаётся скрипт компоновщика.
Процитирую перевод оригинальной статьи, потому что это очень важно.
Параметр--scriptуказывает, что мы хотим использовать особый скрипт компоновщика. Это позволяет точно разместить разделы (text,data,bss,rodata) нашей программы. Вот скриптcom.ld.OUTPUT_FORMAT(binary) SECTIONS { . = 0x0100; .text : { *(.text); } .data : { *(.data); *(.bss); *(.rodata); } _heap = ALIGN(4); }OUTPUT_FORMAT(binary)говорит не помещать это в файл ELF (или PE и т. д.). Компоновщик должен просто сбросить чистый код. COM-файл — это просто чистый код, то есть мы даём команду компоновщику создать файл COM!
Я говорил, что COM-файлы загружаются в адрес0x0100. Четвёртая строка смещает туда бинарник. Первый байт COM-файла по-прежнему остаётся первым байтом кода, но будет запускаться с этого смещения в памяти.
Далее следуют все разделы:text(программа),data(статичные данные),bss(данные с нулевой инициализацией),rodata(строки). Наконец, я отмечаю конец двоичного файла символом_heap. Это пригодится позже при написанииsbrk(), когда мы закончим с «Hello, World». Я указал выровнять_heapпо 4 байтам.
Вообще толкового, исчерпывающего мануала на русском по тому, как писать скрипт компоновщика я не нашёл. Но, лучший и подробный учебник по созданию ld-скриптов был найден тут. Надеюсь, что на него обратят внимание, и кто-нибудь таки переведёт эту серию бесценных статей.
Магия скриптов такова, что можно «магические числа», объём кода, байт для crc, сразу включать в код с помощью линкер-скрипта. Например:
_rom_size_multiple_of = 512;
SECTIONS
{
.header :
{
SHORT(0xaa55); /* signature */
BYTE(_bloks); /* initialization size in 512 byte blocks */
}
.text :
…
}
_rom_end = .;
_rom_size = (((_rom_end - 1)/_rom_size_multiple_of)+1)*_rom_size_multiple_of;
_bloks = _rom_size / 512; /* initialization size in 512 byte blocks */
}Это уже моя самодеятельность, которая тоже может применяться в ваших проектах. Но линкер-скрипта выше вполне хватит для цели создания своей программы на си в БИОС ПЗУ.
К недостаткам последнего проекта можно отнести то, что там тоже существует подход одного файла (сишники инклудятся в единый файл). Это чревато всякими проблемами с областями видимости переменных, и отсутствием возможности добавлять-удалять дополнительные библиотеки. Этим грешат многие любительские проекты, но так делать нельзя.
Поэтому, видимо, придётся всё писать самому, проведя хорошую работу над ошибками.
SeaBIOS
В этом списке нельзя не упомянуть самого большого мастодонта SeaBIOS – это BIOS, который используется в эмуляторе qemu.

Проект интересен тем, что это открытый BIOS с прекрасной документацией, его можно собрать, погонять, проверить, и он будет работать на реальном железе, а также в эмуляции. Обязательно рекомендую заглянуть в его github. Из этого репозитория тоже можно много полезного подчерпнуть. В общем, можно считать, что это готовый учебник в исходных кодах.
С таким багажом знаний пришла пора делать свой BIOS. Но для начала надо поработать над ошибками, чтобы понять, где же я был не прав и избежать их повторения в дальнейшем.
❯ Архитектурнозависимые проблемы и их решение
A: Такой понятный и простой этот ваш мир x86…
B: X86 == мир чудес, туда попал и там исчез...
Из Embedded Group чатика.
Для того чтобы привести всё к единому стандарту, чтобы код работал везде, где я его запускаю, пришлось прочитать просто безумное количество литературы. И чтобы вас не грузить этой информацией, я просто дам основной тезисный срез, если кто-то пойдёт по моим стопам.
Если вы помните мои мытарства с BIOS, то обратили внимание, что какой-то код успешно работал на более современном железе, и редкая программа работала на 386 машине. Как оказалось, это была вообще большая удача, что вообще что-либо работало. Были ошибки расчёта контрольной суммы, особенности запуска на старом и новом железе, и всякие другие архитектурные неприятности. Оглашу весь список.
Особенности BIOS ROM на PCI
Если внимательно ознакомится со стандартом PCI, в частности, требования к формату BIOS, то можно узнать, что вначале ROM-BIOS должен ещё включать указатель на структуру данных PCI, и эта структура должна быть определена в ROM.

Пример структуры ROM BIOS для PCI карты
Подробнее можно прочитать здесь (оттуда же и эта картинка). Кстати, если открыть пример, с которого я начал свой боевой путь в разработку BIOS, то там в самом начале присутствует эта структура.
org 0
rom_size_multiple_of equ 512
bits 16
; PCI Expansion Rom Header
; ------------------------
db 0x55, 0xAA ; signature
db rom_size/512; initialization size in 512 byte blocks
entry_point: jmp start
times 21 - ($ - entry_point) db 0
dw pci_data_structure
; PCI Data Structure
; ------------------
pci_data_structure:
db 'P', 'C', 'I', 'R'
dw PCI_VENDOR_ID
dw PCI_DEVICE_ID
dw 0 ; reserved
dw pci_data_structure_end - pci_data_structure
db 0 ; revision
db 0x02, 0x00, 0x00 ; class code: ethernet
dw rom_size/512
dw 0 ; revision level of code / data
db 0 ; code type => Intel x86 PC-AT compatible
db (1<<7) ; this is the last image
dw 0 ; reserved
pci_data_structure_end:Где
PCI_VENDOR_ID и PCI_DEVICE_ID подставляются макросами в Makefile:nasm main.asm -fbin -o $@ -dPCI_VENDOR_ID=0x8086 -dPCI_DEVICE_ID=0x100EИ являются реальными ID-шниками сетевой карты Realtek RTL8139!
Однако, в своих проектах я не использовал эту структуру, и, на удивление всё работало. Не уверен, что это будет работать на любой материнской плате, с любым BIOS, поэтому рекомендую обращать внимание на неё.
Ошибка расчёта контрольной суммы
Каким образом эта ошибка проявлялась на 386 машине, но при этом всё прекрасно работало на Pentium 4 и qemu, мне неясно. Полагаю, что там менее жёсткие требования к подсчёту контрольной суммы.
Я обнаружил эту багу, когда прошил BIOS Terminal, и он у меня таки без проблем заработал на 386 материнской плате. Хм, странно — работать не должно. После этого я начал разбираться, что же в этом проекте есть такого, что позволяет ему на ней запускаться.
Как оказалось, я считал контрольную сумму в последнем байте после всего кода. А остальное всё заполнял 0xFF. Разумеется, так контрольная сумма не могла сойтись. Чтобы всё было правильно, нужно весь бинарь, который будем зашивать на микросхему, дополнить до конца нулями.
Саму идею взял из проекта BIOS Terminal, о которой говорил выше. Автор, правда, контрольную сумму вообще делал со смещением в 6 байт от начала файла, я же решил оставить свой подход. Теперь ROM для прошивки формируется следующим образом (выдержка из Makefile):
result .rom: program.bin addchecksum
dd if=/dev/zero of=$@ bs=1 count=32768 #Здесь формируем пустой файл 32 KiB
dd if= program.bin of=$@ bs=1 conv=notrunc #Записываем вначале наш код
./addchecksum $@ #И добавляем в конец контрольную суммуПосле исправления этого досадного недоразумения у меня завелись практически все мои тестовые программы на 386 компьютере! Вроде простая, но такая важная мелочь.
Отличия в способе запуска кода на разной архитектуре
В своей последней статье «SSD технологии древних: DiskOnChip», когда я пытался запустить BASIC-ROM на 386 плате, то потерпел фиаско:
Изначально планировал попробовать точно так же запустить BASIC-ROM, но как я не бился, так и не смог его стартануть. То есть, видно, что происходит успешная инициализация, системный BIOS «зависает» без ошибок, значит переход на код ПЗУ состоялся, о чём также свидетельствовали POST-коды. Но ничего больше не происходило.
При этом BASIC-ROM прекрасно работал на более современной PCI-плате. К этому моменту я уже разобрался с ошибкой контрольной суммы, и дело было явно не в ней.
Самое забавное, что в эмуляторах и виртуальных машинах, таких как qemu, VirtualBox, Bochs всё прекрасно работало. В чём же дело?
Пришлось подключать тяжёлую артиллерию и ковырять всё это отладчиком. Все эти ночные посиделки с отладчиком gdb могут тянуть на ещё одну большую статью. Поэтому тезисно.
Для того чтобы прогнать всё это с помощью gdb, пришлось собрать из исходников эмулятор Bochs с поддержкой gdb. После этого начались ночные бдения с дизассемблированием и брекпоинтами. И вот что было удивительно! Брекпоинты на областях памяти, в которых мапился код – не срабатывали! А это означает то, что код выполняется из другого места!
Я дошёл до того, что начал смотреть исходники BIOS Bochs (ещё одни полезные исходники BIOS для изучения) для того, чтобы понять, как же он инициализирует код из ROM, но сломался. Слишком много времени надо было, чтобы просмотреть это всё и проанализировать.
Короче говоря, мне в эмбендеровском чате объяснили в чём же проблема. Если взглянуть на краткое описание, что такое BIOS Extension, то там сказано:
(3) Installation of extension BIOS
After a valid section of code is identifies, system control (BIOS program execution) jumps to the 4th byte in the extension BIOS and performs any functions specified in the machine language. Typically these instructions tell the BIOS how to install the extra code.
(3) Установка расширения BIOS
После того как правильный участок кода идентифицирован, управление системой (выполнение программы BIOS) переходит к 4-му байту в расширении BIOS и выполняет любые функции, указанные на машинном языке. Обычно эти инструкции сообщают BIOS, как установить дополнительный код.
Проще говоря, код выполняется из ПЗУ! А вот в приложении BASIC-ROM у меня были досадные ошибки, когда переменные размещались в тех же областях памяти, где и сам код.
Как вы понимаете, ПЗУ, оно потому и ПЗУ, что эти области памяти не могут быть изменены, поэтому код работать НЕ ДОЛЖЕН (я не могу изменять переменные, они константы)! И он, справедливо не работает на старой 386 материнской плате.
Но позвольте, как же этот код работает на более современном железе, и во всех возможных эмуляторах?
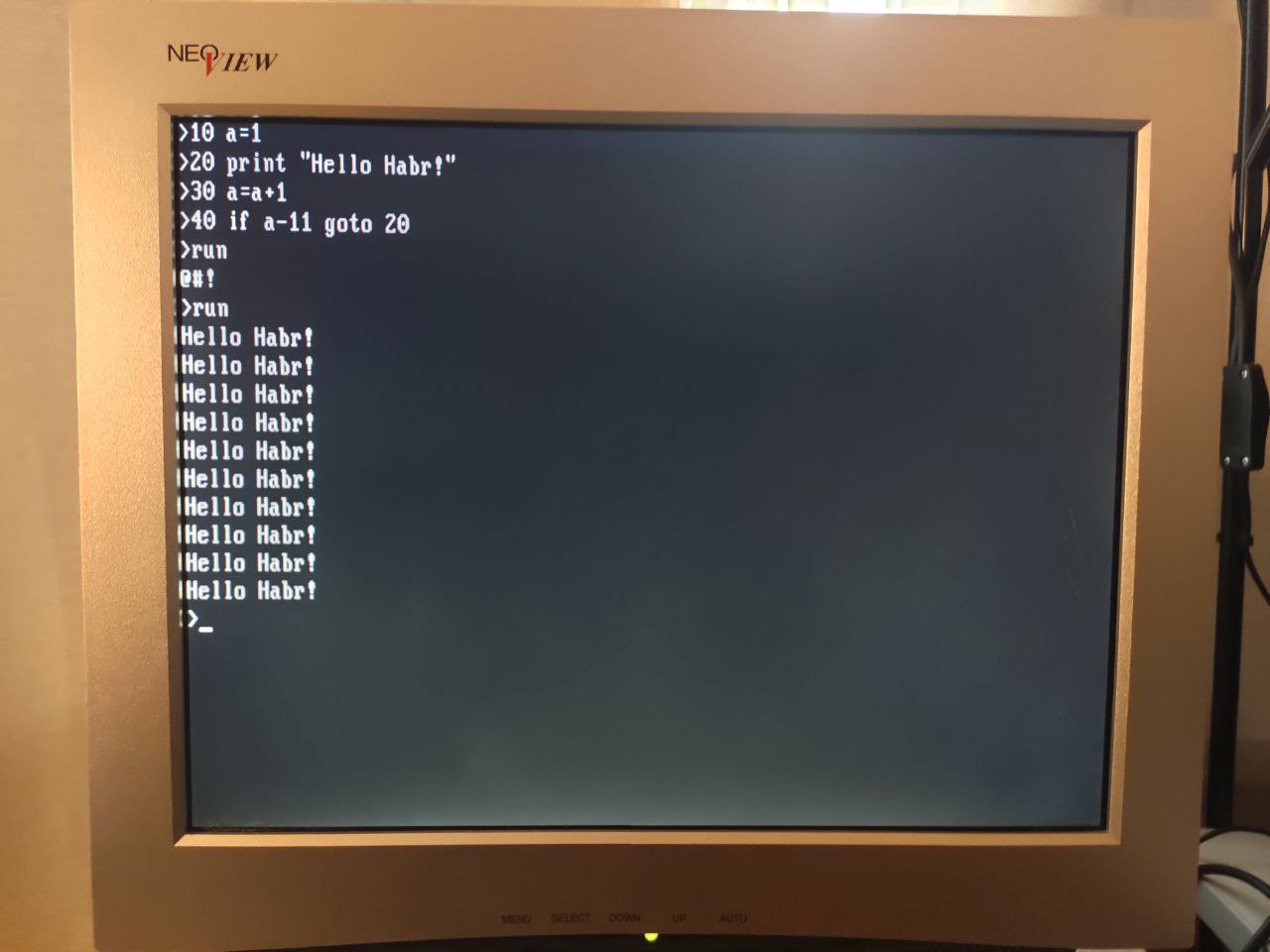
ROM-BIOS на реальном железе Pentium4
Думаю, внимательный читатель сопоставил факт того, что я не смог в gdb поймать брекпоинт в месте расположения кода, потому что он исполняется в другом месте!
Проще говоря, современный BIOS не запускает код непосредственно в ПЗУ (возможно это слишком медленно), а заранее копирует этот участок кода в область ОЗУ и далее уже ему передаёт управление! И именно поэтому на более современном железе все мои кривые программы, которые размещали переменные в тех же участках памяти, где и сам код – в ПЗУ, прекрасно работали, потому что выполнение шло уже в оперативной памяти.
Если я вас окончательно запутал, то тезисно:
- В старом железе код выполняется прямо в ПЗУ на плате расширения.
- В более современном железе, а также эмуляторах типа qemu, VirtualBox, Bochs код предварительно копируется в область оперативной памяти и потом уже выполняется в области ОЗУ.
Годной документации, где это могло бы быть описано, я не нашёл (но и не особо искал).
Решение этой проблемы достаточно банальное: реализовать самостоятельное копирование своего кода в оперативную память и выполнять его уже там. Даже если этот код заранее скопируют в ОЗУ, небольшие накладные расходы на дополнительное копирование с лихвой компенсируют обратную аппаратную совместимость.
И так сделано в проекте bios-terminal, о котором я писал выше. Вся реализация идёт в файле loader.asm. Приведу основной кусок кода с моими комментариями и пояснениями.
db 0x55 // Сигнатура BIOS
db 0xaa
db 32768/512 // BIOS занимает 32kB
jmp _init //Переходим на код инициализации
db 0x00 // байт контрольной суммы offset 0x0006
// копирование данных из сегмента d000: (ROM) до 8000: (RAM)
_init:
cld //определяем направление копирования (очищаем флаг направления)
xor si,si //очистка индексных регистров
xor di,di //очистка индексных регистров
mov cx,#0x8000 //загружаем счётчик копирования (32 KiB) и это же адрес
mov es,cx //Загружаем адрес сегмента куда копировать
mov ax,cs //Сохраняем через AX откуда копировать
mov ds,ax
rep //повторяем нижнюю команду CX-раз
movsb //копируем слово из DS:SI в ES:DI инкрементируя адрес
//Ниже код инициализации стека, который не интересен
…
//Переходим по новому адресу со смещением main
jmp 0x8000:_mainЕщё раз проговорю текстом: очищаем направление копирования, затем в
CX загружаем сколько мы должны скопировать, и это же число является адресом для копирования. Затем в регистры DS загружаем откуда копировать (текущий сегмент), и куда копировать в ES (0x8000 из регистра CX).Команда
REP повторяет следующий за ней операнд CX раз, декрементируя регистр CX.Последним шагом мы передаём управление нашей же программе, но уже по другому адресу, со смещением main. Обращаю внимание, что этот код тоже будет скопирован в те области, но никогда не будет выполнен.
Ещё обратите внимание, что автор для контрольной суммы определил байт в самом начале программы (смещение 6 байт от начала). Это очень удобно, и не зависит от размера получаемой прошивки. Программа подсчёта контрольной суммы у него тоже отличается о того, что я приводил ранее в своей статье.
Фух, вроде разобрал все ошибки. Но статья получилась столь большая, а я не рассказал и половины того, что собирался.
❯ Выводы
Вместить весь багаж знаний всё в рамках одной статьи просто невозможно, но и не сказать об очень важных моментах тоже нельзя. В следующей статье подробно разберу пример того, как написать свою BIOS-демку, там будет работа с памятью, VGA в графическом режиме и много ещё чего вкусного.
❯ Полезные ссылки
- Пишем свой ROM BIOS
- SSD технологии древних: DiskOnChip
- iPXE — open source boot firmware
- github iPXE
- BIOS Terminal
- How to build DOS COM files with GCC
- Как собрать досовский COM-файл компилятором GCC (перевод)
- The GNU linker — прекрасный мануал по скриптам компоновщика
- SeaBIOS для эмулятора qemu
- Github проекта SeaBIOS
- Malicious code execution in PCI expansion ROM
- Bochs x86 Emulator BIOS Source Code
- BIOS Extension
P.S. Если вам интересно моё творчество, вы можете следить за мной ещё в телеграмме.

Комментарии (54)

le2
11.04.2023 08:33+1Справедливости ради у прикладных процессоров всегда все плохо с документацией (даже если вы получили под NDA). Но писать под православный Эльбрусий или вот под x86 это отдельный садомазо. Если вы даже не знаете сколько и каких процессорных ядер у вас на материнской плате или даже не знаете истинную систему команд, ведь x86 уже давно RISC, а не CISC.
Под ARM уже можно найти драйвер GPU и софтверный DSP камеры в исходниках. А здесь блоб на блобе и блобом погоняет.
Я считаю, что жизнь слишком коротка чтобы работать без документации, без исходников и становиться специалистом по вендор-локам.
dlinyj Автор
11.04.2023 08:33+1Я считаю, что жизнь слишком коротка чтобы работать без документации, без исходников и становиться специалистом по вендор-локам.
К счастью, это просто хобби :)

edo1h
11.04.2023 08:33+1даже не знаете истинную систему команд, ведь x86 уже давно RISC, а не CISC
Как это влияет на программиста?
Под ARM уже можно найти драйвер GPU и софтверный DSP камеры в исходниках. А здесь блоб на блобе и блобом погоняет
Честно говоря, не понял о чём вы. И на arm, и на x86 есть системы как с blob, так и без них.

MaFrance351
11.04.2023 08:33+1Отличная статья.
Сам когда-то думал, что же может пойти не так при запуске ваших ROMов. О копировании в оперативную память даже не догадывался.И, как я понял, именно по этой причине у вас изначально не запускалась та маленькая плата с ROM для расширения BIOS?
dlinyj Автор
11.04.2023 08:33О копировании в оперативную память даже не догадывался.
Самое удивительное, что нигде не встречал даже описания по этому поводу. А главное, как такое дебажить.И, как я понял, именно по этой причине у вас изначально не запускалась та маленькая плата с ROM для расширения BIOS?
Именно поэтому не работал BASIC-ROM, он просто не мог работать.MaFrance351
11.04.2023 08:33+1Тогда понятно. Просто я помнил, что он виделся в памяти, но не стартовал...

MinimumLaw
11.04.2023 08:33+3Самое удивительное, что нигде не встречал даже описания по этому поводу. А главное, как такое дебажить.
Да ладно вам. BIOS RAM SHADOW - загадочный пункт в 486-ых и первых пентюхах. Прямо в описании на материнскую плату. Да и во всяких прочих источниках.
А вот про код, который непосредственно из ROM... Это да - надо уметь. Особенно когда RAMа еще вообще нет, а значит нет даже стека и располагаем мы только регистрами...
Впрочем, не знаю как там про современный gcc, но Borland троечка в свое время умел... Полагаю и gcc умеет, но надо много доков перерыть. Что-нить в стиле __attribute__((naked)) чтоб стандартную преамбулу со стеком не включать.

thevlad
11.04.2023 08:33+3В современных биосах используется технология CAR(cache as ram), которая инициализируется практически сразу после самого старта, а дальше обычный Си.
MinimumLaw
11.04.2023 08:33+1Спасибо, буду знать... Я нынче очень далек от мира x86, а все мои ARMы имеют на борту небольшое количество SRAM. Потому проблемы "кода из ROM" давно не встречал.
dlinyj Автор
11.04.2023 08:33+1

garus_ru
11.04.2023 08:33+2Да ладно вам. BIOS RAM SHADOW - загадочный пункт в 486-ых и первых пентюхах.
Боже мой, какой старинный пазл у меня сейчас сложился, благодаря вам и автору ))

s-a-u-r-o-n
11.04.2023 08:33+5В coreboot (это проект по разработке свободного BIOS) есть компилятор romcc, который генерирует машинный код, не использующий оперативную память.

axe_chita
11.04.2023 08:33Да ладно вам. BIOS RAM SHADOW — загадочный пункт в 486-ых и первых пентюхах.
BIOS RAM SHADOW появился уже в 386, если не в 286. А всё потому что ROM это очень медленно, и программы которые активно использовали функции BIOS ощутимо так тормозили. И чтоб победить эти тормоза, BIOS копировал себя в блок RAM, отключал ROM и командовал чипсету переключить этот блок RAM в адреса ROM. Попутно чипсет мог запретить запись в этот блок, а мог и оставить её открытой для записи. ;)
Именно так, разрешением записи в верхние блоки RAM, можно было организовать UMB без EMM386.А вот про код, который непосредственно из ROM… Это да — надо уметь. Особенно когда RAMа еще вообще нет, а значит нет даже стека и располагаем мы только регистрами...
MRBIOS, если мне не изменяет память, при своей инициализации (когда оперативная память еще не была активна) использовал регистры DMA контроллера для хранения переменных.MinimumLaw
11.04.2023 08:33+1У меня есть провал с 286-ми. PС-XT в техникуме, 386-е, 486-ые, программирование РФ ПЗУ на ЕС-1841. И свои первый был 486ым. Я не помню этого пункт в BIOS "трешки". Это, безусловно, не говорит о том что его там не было.
"Код из ром" впервые возник в контексте "Питерской телефонии". Тогда окучивали i386ex в части замены им привычного 186-ого и столкнулись с тем, что уже хочется использовать защищенный режим и писать без оглядки на сегменты, но при всем при этом стартуем-то мы по прежнему из ПЗУ и ОЗУ надо еще правильно проинициализировать. Впрочем, тогда я не программист. Скорее схемотехник
с уклоном во взлом демоверсий софта для разработки. Но все работали в одной комнате и курилка была общая. А молодой и любопытный организм как губка - впитывал все.axe_chita
11.04.2023 08:33+1У меня есть провал с 286-ми. PС-XT в техникуме, 386-е, 486-ые, программирование РФ ПЗУ на ЕС-1841. И свои первый был 486ым. Я не помню этого пункт в BIOS «трешки». Это, безусловно, не говорит о том что его там не было.
Навскидку поиском изображений в Яндексе «AMI BIOS 386DX»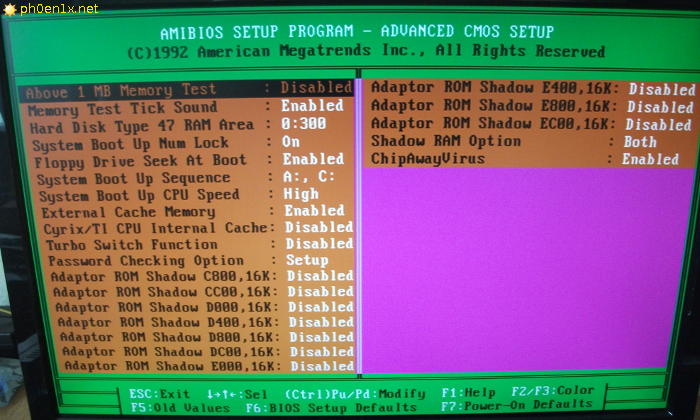
По запросу «ami bios 286»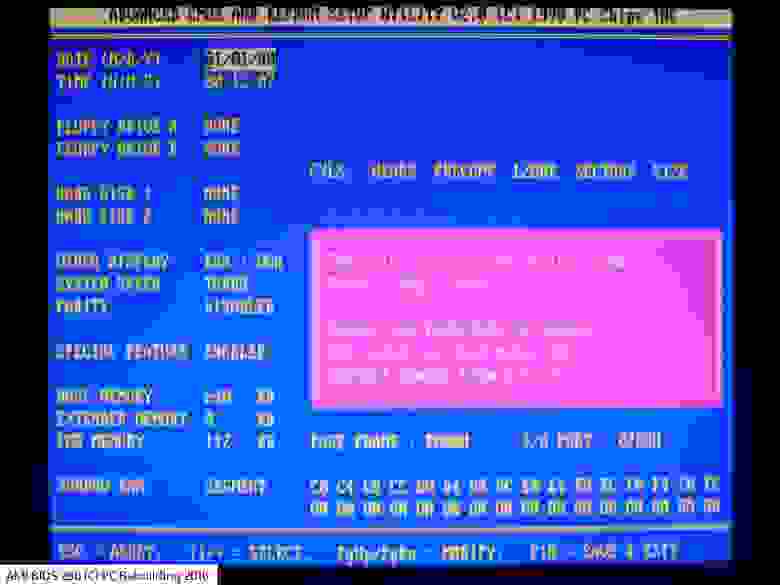
А ещё можно скачать PCEm с ROM-ами и насладится их видом и настройкой BIOS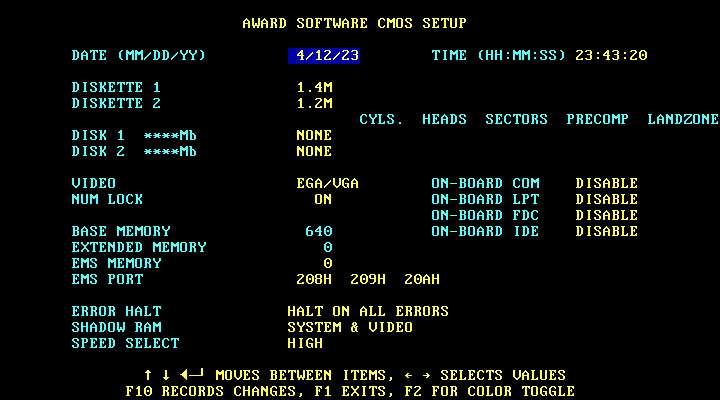
Тогда окучивали i386ex в части замены им привычного 186-ого и столкнулись с тем, что уже хочется использовать защищенный режим и писать без оглядки на сегменты,
Это уже был не защищённый (protected) режим доступный с 286, а virtual 8086 mode (он же virtual real mode, он же V86-режим, ещё известный как VM86) святой грааль программистов DOS эры, страстно желавших вырваться за пределы сегмента в 64кб. Но информации по программированию в этом режиме, было реально крупицы, как говориться пара абзацев на последних страницах толстого тома по 386 процессору. :(dlinyj Автор
11.04.2023 08:33+1Это уже был не защищённый (protected) режим доступный с 286, а virtual 8086 mode (он же virtual real mode, он же V86-режим, ещё известный как VM86) святой грааль программистов DOS эры, страстно желавших вырваться за пределы сегмента в 64кб. Но информации по программированию в этом режиме, было реально крупицы, как говориться пара абзацев на последних страницах толстого тома по 386 процессору. :(
Кулаков В. Программирование на аппаратном уровне: специальный справочник
Очень подробно описывает, и почти вся книга в этом режиме работает.axe_chita
11.04.2023 08:33+1В те времена издательства "Питер" ещё не существовало. :(
Опять же, ЕМНИП назывался этот переводной том "Архитектура и программирование процессора 386", и вроде был издан издательством "Статистика". И в библиотеке политена этот том находился в перманентном состоянии "на руках".
MinimumLaw
11.04.2023 08:33+3Но информации по программированию в этом режиме, было реально крупицы, как говориться пара абзацев на последних страницах толстого тома по 386 процессору. :(
То были славные времена, когда пусть и под NDA, но можно было найти информацию о самых последних новинках. Siemens тогда еще был Siemens'ом а не Infenion'ом, Harris был Harrisom а не Intersil'ом, Motorolla была одним из крупнейших игроков, а Mitel практически безоговорочно лидировал в новых разработках и вообще был совсем на коне в частности как производитель чипов (не безызвестная своим эротическим именем minet.dll в Windows это их приветы).
В те славные времена мы разжились (дай бог памяти - в Питерской Гамме вроде) двумя дисками от Intel. Как раз в связи с желанием приобрести некоторое количество 386ЕХ'ов. Один был полностью про embedded и содержал отличную документацию, которую в последствии неоднократно цитировали и пользовались как справочником. В частности тема режимов работы процессора была расписана просто отлично и скорее вопрос был в компиляторах C, которые могли бы плодить код для того или иного режима (да всяких exe2bin, которые могли бы "вытащить" бинарь для прошивки в ПЗУ станции). Сейчас любая objcopy так умеет, а тогда... И да - вне этого диска информации было крайне мало, а издательство "Питер" только начинало свою работу и печатало откровенную дичь типа перевода мануалов (хорошо как не Prompt'овского перевода). Второй диск был посвещен коммерции. Все тогда популярные чипсеты с подробной документацией. Нам, правда, именно он был совсем не интересен.
Но еще раз повторюсь. Я тогда планомерно работал над тем, чтоб из "курьера, а по совместительству монтажника-настройщика РЭА" превратиться в разработчика. Осваивал схемотехнические CAD'ы (а тогда PCAD 4.5, самые модные смотрели на PCAD 6, но пользоваться им не решались). А у меня в фаворе OrCAD для Windows 3.1 - первый "человеческий" схемотехнический CAD, гербера из которого вполне брало производство. Ну и всякие софтинки... Спасибо нодам, дававшим доступ к Fido (2:5030/666 - если вдруг меня читают) и Крису Касперскому с его учебниками... FlexLM до сих пор ничего кроме легкой ухмылки не вызывает - ибо "математикой" ломать почти не возможно, за то методом " грубого хака" или патча - за пару минут.
А поскольку помимо всего прочего прошло 30 лет... Что-то могу не помнить или помнить не правильно.

fshp
11.04.2023 08:33+1Кажется в CoreBoot был компилятор C, генерирующий код, не использующий память. Как раз для ее инициализации.
UPD: Я буду читать комментарии, я буду читать комментарии....
dlinyj Автор
11.04.2023 08:33+1UPD: Я буду читать комментарии, я буду читать комментарии....
Для меня комментарии были очень ценны.
fshp
11.04.2023 08:33+1Из интересного на счёт скриптов ld.
http://books.gigatux.nl/mirror/kerneldevelopment/0672327201/ch10lev1sec3.html
В linux линкером наложили 32 и 64 битный счетчики друг на друга.

vanxant
11.04.2023 08:33+2Ну хз, когда в девяносто лохматом у меня был 386, там уже был Shadow ROM. И эта зараза отъедала какое-то количество "расширенного ОЗУ" (около 40кб). Для винды рекомендовалось эту опцию отключить в биосе, т.к. там дрова 16-битного реального режима, и винда ими не пользовалась. А вот для доса скорее помогало.
dlinyj Автор
11.04.2023 08:33Ну хз, когда в девяносто лохматом у меня был 386, там уже был Shadow ROM.
Век жив, век учись
axe_chita
11.04.2023 08:33Shadow ROM народ массово отключал во времена выхода DOOM, чтобы DOOM-у хватило памяти для запуска. ;)

strvv
11.04.2023 08:33+1насколько я помню в старых стартап кодах, было в некоторых режимах выделение рам области, копирование туда переменных, потом только запуск main.
а почему вспомнил - смотрел стартапы для cosmic компилятора stm8 и stm32, и тот код напомнил то, с чем сталкивался в начале 90х, до перехода на Windows-NT 3.51 и 4.0 и Vax/VMS.
не помню, на каком компиляторе я сталкивался с таким кодом.
почитал комментарии, возможно с внедрением ShadowRam в биосе убрали возможность работы даже без озу совсем. надо попробовать на 80286 маме.
Да, и надо тогда проверять наличие памяти, т.е. выполнять memory test

alecv
11.04.2023 08:33+2Насколько помню, копирование ROM в RAM появилось в замечательном, прямо таки революционном чипсете для 286 процессора: Chips&Techologies NEAT в далеком 1988 году.
https://en.wikipedia.org/wiki/NEAT_chipset
Там внизу есть ссылки на документацию. Технология называлась Shadow RAM и реализуется в чипе контроллера памяти 82С212.
"The Shadow RAM feature allows faster execution of code stored in EPROM, by downloading code from EPROM to RAM. The RAM then shadows the EPROM for further code execution. "
Производителям мамок на чипсете C&T и биосо-писателям давался "кит" с примерами, как правильно программировать чипсет.





Lebets_VI
11.04.2023 08:33+7Супер.
Думаю, может написать "эссе" ;) как в девяностых годах дизассемблировал DOS-овские "io.sys", "msdos.sys" и "command.com" (по сути - ядро) просто для интереса понять как эта хрень работает и дизассемблировал BIOS PC-XT, для написания драйвера (нет, "резидента", если кто помнит что это такое) для принтера "Электроника МС 6313" :)
Но, думаю, это никому не интересно, если в соседней ветке спрашивают: "зачем вам калькулятор".dlinyj Автор
11.04.2023 08:33+3Это очень интересно! Пожалуйста, напишите!
Lebets_VI
11.04.2023 08:33+6Спасибо, за интерес. К сожалению, я выкинул за ненадобностью все свои записи и ассемблерные распечатки с комментариями, пролежавшие больше 20-ти лет, но по памяти попробую восстановить всю историю, в том числе о том, как я нашел баг в boot-секторе DOS и он был в неизменном состоянии вплоть до Win-95 (дальше я просто не исследовал), о котором я писал товарисчу Б. Гейтсу:) (нет, только в Microsoft) и, естественно, не получил ответа. Но это длинная история, требующая качественного описания ( для Хабра :) ).

VBKesha
11.04.2023 08:33+3это никому не интересно
Если хорошо написано это всегда интересно почитать. А так всегда кто то спрашивает а зачем вам X когда есть Y.
alecv
11.04.2023 08:33+1Нынче имеются "убежавшие" (пссс...) исходники MS-DOS примерно beta 6.xx . Можно посмотреть, как многие вещи реализованы на самом деле, в частности мифический DOS List-of-Lists.

mark_ablov
11.04.2023 08:33+2Тоже когда-то писал свой BIOS :) Тогда кроме coreboot'a очень помогли статьи Pinczakko's Guide to BIOS Reverse Engineering.


emusic
11.04.2023 08:33как подступиться к разработке на голом железе, на чистом си
Почему не C++?
dlinyj Автор
11.04.2023 08:33+1Думаю как бы вежливее ответить.
Есть ли проект ROM BIOS на плюсах? И вообще, много ли проектов под железо на плюсах (ардуино не берём, это скорее недоразумение). Ничего не имею против языка, но он избыточен для этой задачи. Ну и плюс, я его не люблю.emusic
11.04.2023 08:33+1Есть ли проект ROM BIOS на плюсах?
Не знаю, но не вижу ни одной причины, по которой не следовало бы их делать.
много ли проектов под железо на плюсах
Для современных МК (того же STM32) - достаточно, ибо это и удобнее, и надежнее, чем на чистом C.
ардуино не берём
И совершенно зря. Я несколько лет назад развлекался, переписывая программки для ATTiny13 с C на C++, применяя наследование, виртуальные функции и шаблоны, и получая идентичный (с точностью до мелких различий в CRT) двоичный код. Нескольких знакомых разработчиков для МК на это подсадил. :)
он избыточен для этой задачи
В каком смысле "избыточен"? Слава богу, даже современные компиляторы C++ не вставляют неявных вызовов функций CRT для подавляющего большинства возможностей языка, а код почти всегда получается идентичным аналогичному по смыслу коду на C. Если вдруг кто-то заявит, что программирование на C++ непременно подразумевает использование контейнеров std, исключений, многоярусных шаблонов и прочего - плюньте ему в глаза, и дело с концом. :)
Там, где на C Вы определите структуру и набор функций для работы с нею, на C++ Вы определите ту же структуру в виде класса, и те же функции в виде методов, но при этом сможете задать ряд ограничений и автоматизмов, которые на C придется делать вручную, а двоичный код все равно будет одинаковым. Если какие-то структуры расширяют уже существующие, на C++ Вы просто определите производный класс, и за правильностью преобразования указателей/ссылок будет следить компилятор, а на C это придется делать руками, вылавливая ошибки только на стадии выполнения. Даже более строгие ограничения на преобразования типов помогают избежать ряда ошибок.
А возможность создания временных объектов "на лету" (в стеке) очень удобна для отладки, чтобы выводить в лог в разных форматах. Тут уже код получается не самый оптимальный, но для отладочных вариантов сгодится.
я его не люблю
У меня была неприязнь к C++ в начале 90-х, когда на фоне компактного, быстрого и очень удобного TC 2.0 пытался освоить TC++ 2.0, который был значительно более тормозным, а сам язык тогда изобиловал подводными камнями. Не последнюю роль сыграла и тогдашняя массовая практика - "в программе на C++ положено использовать множественное наследование, виртуальные функции, исключения, сложные шаблоны и прочее, иначе это нецелевое использование языка". :)
А вот MS VC++ 4.0 как-то сразу зашел, я на нем довольно долго писал виртуальные драйверы ядра (VxD) для Win9x, которые традиционно было положено писать только на чистом C.
dlinyj Автор
11.04.2023 08:33+2Каждый кулик своё болото хвалит. Но правда ваша есть в этом.
Но не спроста всё низкоуровневое пишут на сях, linux, BIOS, uefi. Причина проста, код на сях проще отлаживать чем на плюсах. На плюсах прекрасно писать, но отлаживать, а особенно легаси — это адовый ад. Поэтому большие проекты часто на си. И, к моему счастью, это будет долго.
emusic
11.04.2023 08:33Объективная причина писать на сях только одна - отсутствие адекватного компилятора под платформу. Остальные - или привычка, или религия. :)
Отладка плюсового кода ничем не отличается от отладки соответствующего ему по смыслу сишного. Конечно, если Вы в заголовке конструктора записали вызовы всех конструкторов базовых/вложенных классов в одну строку, то обходить их в отладчике будет неудобно. Если же записать каждый на своей строке, их пошаговый обход выглядеть так же, как и пачки сишных функций инициализации.
Ад в плюсах возникает при отладке только чисто плюсовых сущностей - многоярусных шаблонов или сложной обработки исключений. Остальной код совершенно прозрачен и выглядит так же, как сишный. Если не замудряться, то по двоичному коду, выданному приличным компилятором, Вы даже не поймете, с какого исходника он получен - сишного или плюсового.
dlinyj Автор
11.04.2023 08:33+1Настоящий ад в легаси. Мне доводилось искать баги в чужом коде на си и на плюсах. Плюсы имеют много крутых преимуществ: быстрая разработка, шикарная работа со строками и прочее, прочее. Отличный язык. Но поддерживать его, править чужие баги это прям боль. Особенно когда идёт наследование перезагрузка функций, и ещё чел писал как ему было удобно.
Я встречал и железячные проекты, когда всякие извращенцы через врапер внедряли плюсовый код, при этом основной проект был на си. И дебажить (под словом дебаг я понимаю не отладчик GDB, а поиск ошибки и её разрешение), просто очень болезненно и тяжело.
Ещё раз, не нужно микроскопом бить гвозди, он прекрасный инструмент, но для своей сферы задач. Не стоит его пихать везде, особенно там где он не нужен от слова совсем. Причина популярности плюсов в ардуино и контроллерах, в том что можно легко клепать кривой код, но совершенно невозможно его потом поддерживать.

esaulenka
11.04.2023 08:33+2быстрая разработка, шикарная работа со строками
Вы плюсы с питоном не путаете? :-)
Плюсовый компилятор больнее бьёт по рукам за неправильное использование типов, сам синтаксис заставляет выстраивать хоть какую-то иерархию (методы внутри класса, а не просто горсть функций с именами от генератора случайных слов) и т.д. Ну а если чел писал
как ему удобноне включая мозг - так это не язык виноват...Мне вот последнее время платят деньги за подпиливание мелких фишек в древнем софте. Один - на сях, второй - на плюсах. И вот плюсовый на порядок лучше структурирован.
emusic
11.04.2023 08:33-1Настоящий ад в легаси
Не может там быть никакого ада лишь потому, что компилятор работает в режиме C++, а не C. Вот есть у Вас программа на чистом C, отлаживать которую Вам легко и приятно. Вы переименовали файлы из .c в .cpp и обработали их в режиме C++ (тут, возможно, придется подавить ряд предупреждений, ибо в C++ более строгие правила преобразования типов). Должен ли с этого момента начаться ад? Если да, то почему?
Далее, у Вас в программе на C есть структура, с которой работает несколько функций. Вы переносите объявления этих функций, сделанные в виде обычных прототипов, внутрь определения структуры (можно даже пока не менять struct на class), в определениях этих функций добавляете квалификатор - имя структуры/класса через "::", убираете из параметров указатель на структуру (это будет неявный this), а из тел функций - этот указатель с "->" для обращения к каждому полю. Все, у Вас получился класс и методы (функции-члены) работы с ним. :) В вызовах этих функций меняете "func (strptr, ...)" на "strptr->func (...)", и вуаля. :).
Теперь все работает в точности так же, как и работало в чистом C, ни малейших отличий нет. Но можно добавить конструктор, который и установит нужные значения полей, инициализирует порты и т.п., и деструктор, который корректно все это освободит/закроет, то и другое будет вызвано автоматически. Туда можно добавить отладочный вывод. Внутри самого класса, рядом с определениями полей, можно определить метод контроля состояния объекта, который будет проверять, нет ли противоречий между значениями полей, и добавить условную трансляцию, чтобы в финальном коде вызывался пустой метод, который компилятор успешно выкинет.
В каком месте здесь возникает ад? Все остается таким же, как и было, ничто не теряется, но добавляется автоматизация контроля - как синтаксиса, так и поведения. Неужели это не имеет для Вас ценности?
Плюсы имеют много крутых преимуществ: быстрая разработка, шикарная работа со строками
То, что Вы перечислили - это не плюсы. Это то, что их обычно сопровождает - стандартная библиотека шаблонов и функций, фреймворки и т.п. Там почти все, кстати, сделано на плюсах же.
Собственно плюсы - это именно ядро языка, базовые возможности, реализуемые на уровне компилятора, а не внешних средств.
ещё чел писал как ему было удобно
Напиши он в том же стиле на C - было бы легче?
Не стоит его пихать везде, особенно там где он не нужен от слова совсем
А если я Вам предложу в программах на C избавиться, например, от условной операции, цикла for, модификатора const и еще чего-нибудь, поскольку без всего этого можно обойтись - а значит, оно и не нужно "от слова совсем"? :) Где провести границу между полезным и бесполезным,и как ее обосновать? Я вот когда-то писал огромные программы на ассемблерах, и искренне считал, что и C на фиг не нужен... :)

CrashLogger
11.04.2023 08:33+1Лет 20 назад был у меня проект под AVR на плюсах. Там работа с разными похожими индикаторами была сделана через полиморфизм - для core модуля это всегда выглядело одинаково, а функции вызывались для каждого индикатора свои. Было довольно удобно. Потом на основе этого же кода был написан эмулятор, который работал на PC и за интерфейсом индикаторов скрывалось уже графическое окошко на WinAPI.
dlinyj Автор
11.04.2023 08:33Я допускаю, что могу ошибаться в своей позиции. Но пока в основном рулит си. Плюс, мне не очень нравится объектно-ориентированное программирование (прошу понять, это лично моя вкусовщина с которой я не иду в чужой монастырь). То есть, выбор си в данном случае однозначно потому, что я его люблю.
Меня скорее удивляет вопрос: а почему это, а не то? Почему синее, а не красное, почему си, не си плюс плюс? Ну люблю я синее больше.
emusic
11.04.2023 08:33-1пока в основном рулит си
Я уже пояснял, почему - исключительно в силу привычки и ложных представлений. Вот как у Вас. :) А объективных, не зависящих от личных предпочтений, доводов в пользу чистого C просто нет, ибо C++ его и полностью перекрывает, и нигде не ущемляет.
мне не очень нравится объектно-ориентированное программирование
То есть, в Ваших программах все переменные определены россыпью, без группировки, и нет ни одной структуры, для работы с полями которой написаны специальные функции, в которые передается указатель на структуру? Если такое есть, то у Вас самое, что ни на есть, объектно-ориентированное программирование. :)
Почему синее, а не красное, почему си, не си плюс плюс?
Потому, что красное не содержит в себе синего, а C++ содержит в себе C. :)
dlinyj Автор
11.04.2023 08:33+1Более того, я в программах на си пихаю указатели на функции в структуру. Но тем не менее, я сторонник лампового си.
C++ содержит в себе C.
На первый взгляд только. И это заблуждение.
Я уже пояснял, почему — исключительно в силу привычки и ложных представлений.
Это ваше заблуждение.

{kind=link}
jobless
Вам может быть интересен проект на тему как ... без GCC и даже ASM но для win[pe]/lin[elf], хотя при желании и базовых знаниях опуститься до уровня железа думаю возможно.
http://phix.x10.mx/
https://openeuphoria.org/forum/137643.wc?last_id=137793