

Привет! Я Василий Сизов, тим-лид команды «Модели управления Жизненным Циклом Клиента», и мы продолжаем нашу серию материалов о библиотеке autobinary.
Ранее мы рассказали вам о кросс-валидации в autobinary, которую можно использовать не только для расчета усредненной оценки модели или расчета усредненных важностей фичей, но и для подбора параметров модели, отбора фичей в модель и т.д.
В этой статье мы расскажем вам о том, как можно использовать библиотеку autobinary для подбора параметров с помощью Optuna, а также о том, как можно интерпретировать вклад фичей с помощью Shap и PDPbox.
Подбор параметров
Методов подбора параметров существует достаточно много. Самые базовые из них – это GridSearchCV, RandomizedSearchCV и HalvingRandomSearchCV.
Базовые методы представляют собой либо полный, либо случайный перебор по заданной заранее сетке параметров. Это хорошие методы подбора, но проблема из коробки в них заключается в том, что их довольно сложно совместить с конвейером обработки данных (pipeline из sklearn) и обучением модели.
Существуют и другие методы подбора параметров, реализованные в библиотеках Optuna, Hyperopt, Skopt.
Мы покажем, как можно подбирать параметры модели с помощью нашей библиотеки и Optuna.
Все довольно просто! Сначала создаем функцию create_model, в которой задаем словарь параметров param, с которым будет работать Optuna. А далее создаем инстанс класса AutoTrees, как и делали до этого в первой части серии гайдов по библиотеке autobinary.
После этого задаем функцию objective, в которой сначала создается модель, а потом вызывается метод model_fit_cv – обучение кросс-валидации. Сама же функция возвращает результат метода get_mean_cv_scores – средняя метрика модели по всем фолдам.
Обращаю внимание, что в данном случае средней метрикой здесь будет gini, так как именно ее мы задали в качестве параметра main_metric. Вы можете задать и другую метрику.

Подготовительная работа сделана. Теперь можно запускать подбор параметров (в данном случае будет 30 итераций):

Что мы сейчас сделали?
Мы задали какую-то очень сложную функцию с небольшим количеством параметров – это модель машинного обучения, еще и обученная в кросс-валидации. Но мы сделали это довольно просто и элегантно.
В этом и прелесть Optuna! Можно задавать очень сложные функции и подбирать параметры для этих функций, максимизируя или минимизируя какую-либо метрику, а библиотека справится с такой задачей практически из коробки.
Теперь давайте посмотрим на результаты работы optuna.
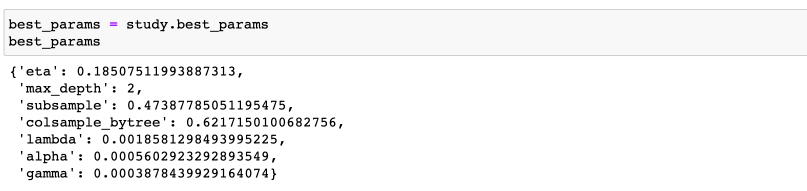
Лучшие параметры хранятся в атрибуте best_params:
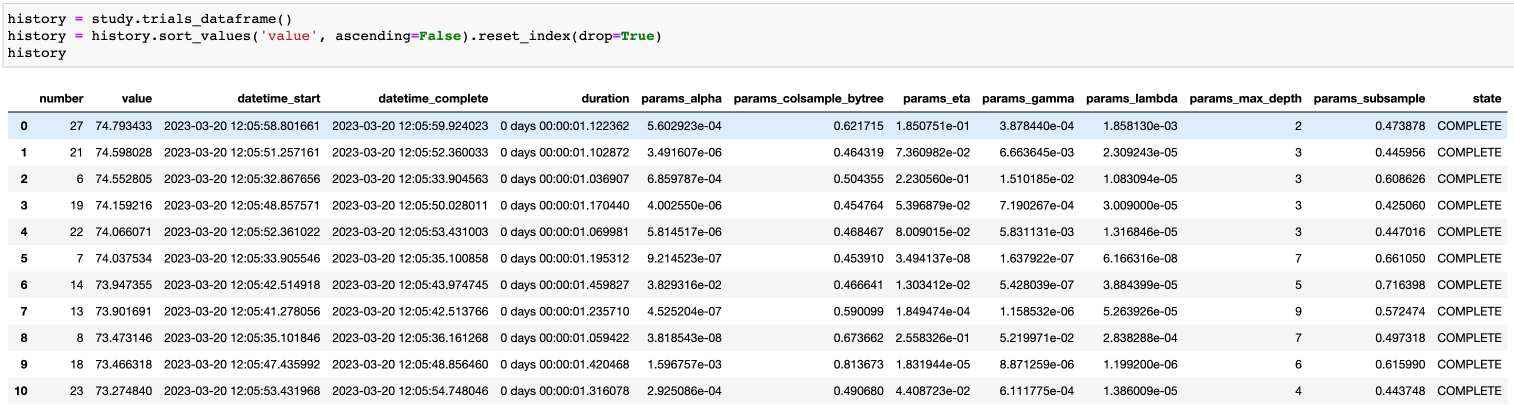
Также можно вывести и все итерации подбора для более глубокого анализа и интерпретации:
Лучшее значение метрики хранится в атрибуте best_value:

Помимо простой работы с самой библиотекой, Optuna позволяет строить хорошие графики для интерпретации результатов подбора. Например, график целевой метрики от номера итерации:

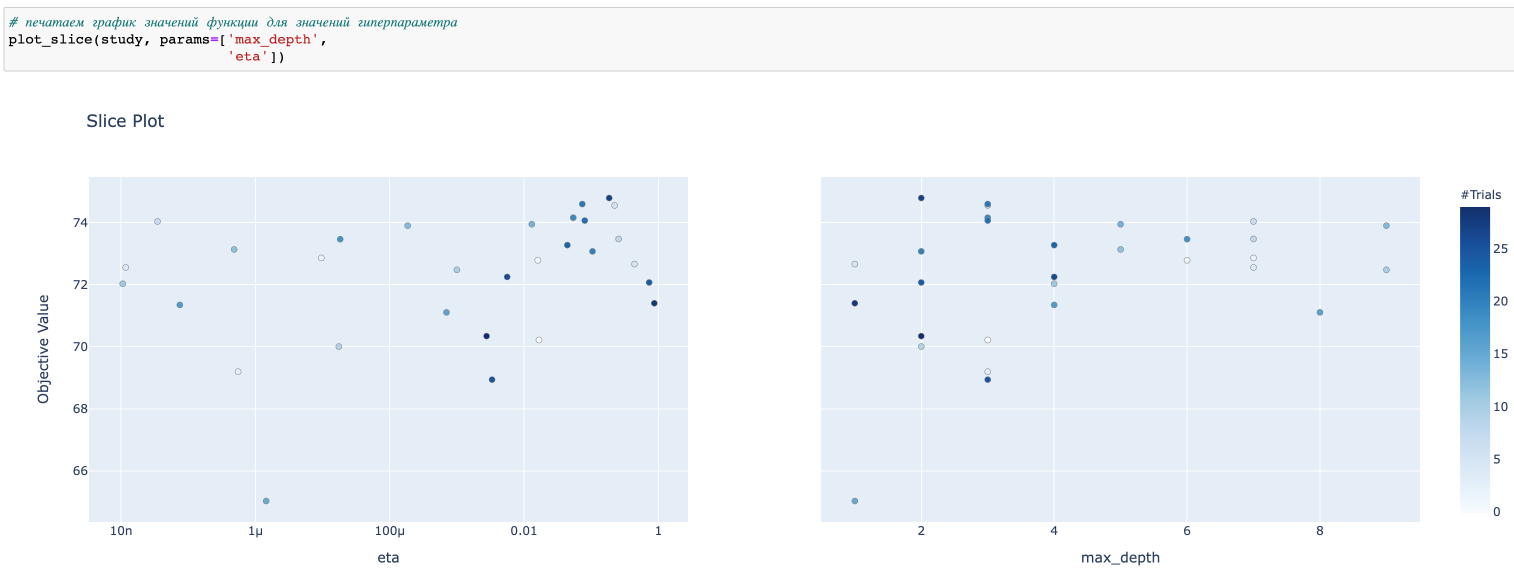
Также можно построить Slice Plot, который показывает график целевой метрики в зависимости от конкретного параметра:
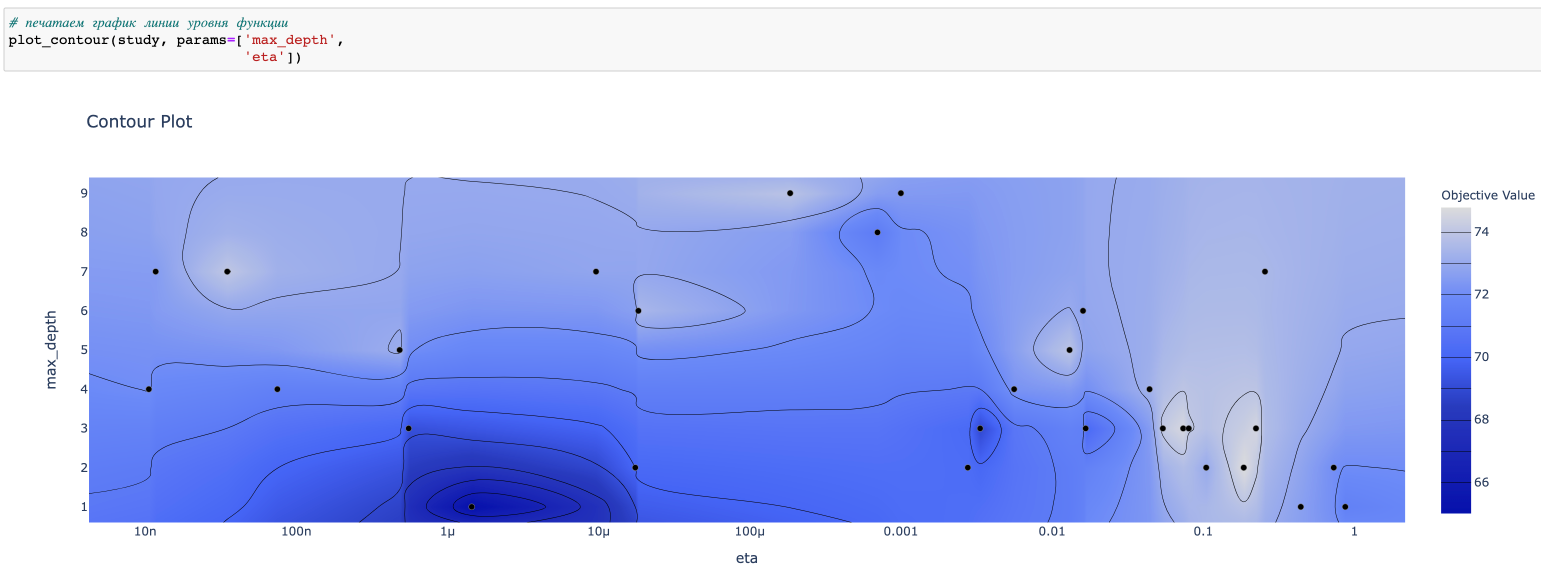
Очень часто бывает полезен и график с линиями уровня. Здесь можно оценить результат, который дают сразу два параметра:
Интепретация фичей: shap
К этому моменту фичи отобраны, параметры подобраны. С этими данными можно обучить модель.
Модель обучили, но что делать с интерпретацией фичей?
Конечно, можно еще раз запустить кросс-валидацию и получить список усредненных важностей факторов. Важность фактора говорит только о важности для модели, но не говорит о влиянии на таргет.
Другими словами, для задачи «Титаника» мы хотим получить ответ на вопрос: «При увеличении возраста пассажир более склонен выжить?»
Отвечать на такие вопросы позволяют библиотеки shap и PDPbox.
Начнем с shap.
Для удобства воспользуемся классом-оберткой из autobinary – PlotShap. В данный класс нужно передать обученную модель (в данном случае xgb_model) и выборку, на которой училась эта модель (new_X_train):

После обучения можно вывести графики интерпретации.
Например, вызвать метод create_plot_shap. Про интерпретацию данного графика можно почитать в официальной документации. Именно этот график позволяет ответить на вопрос «Как влияет рост значения фичи на целевую переменную?»:
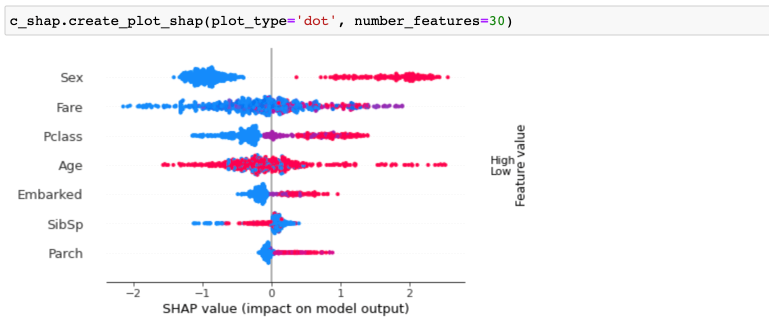
Например, возраст (age). Красные точки – это более высокие значения признака, синие – наоборот, более низкие. По графику нет какой-то четкой определенности относительно возраста. Высокие значения находятся и в правой (выжил) и в левой (не выжил) областях.
А вот пол довольно четко разделен на два множества. Пол был преобразован с помощью catboost_encoder:
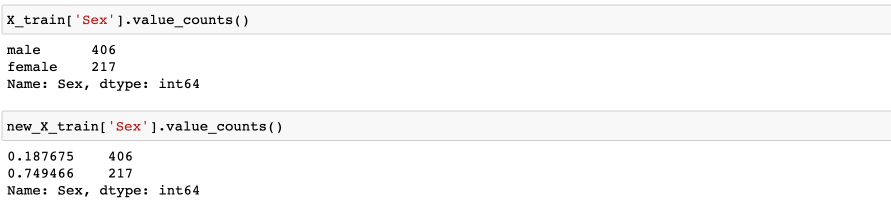
Женский пол соответствует большему значению фичи (female – 0.74). Получается, что женщины более склонны к выживанию на титанике.
Также можно вывести важности фичей в виде гистограммы:

А для дальнейшего использования, например, для отбора фичей, в виде таблицы:

Очень часто бывают такие ситуации, что необходимо вывести фичи в виде графика в строго определенном порядке. Например, для презентации. Это тоже можно сделать:
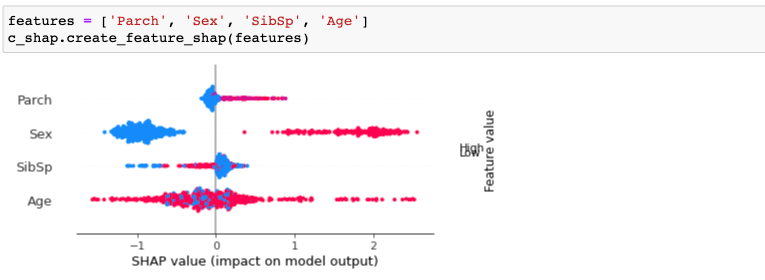
Интепретация фичей: PDPbox
Другая библиотека для интерпретации фичей – PDPbox.
Для использования данной библиотеки также сделана удобная обертка – PlotPDP. В нее передаем обученную модель, выборку, на которой учили модель, а также список фичей для отрисовки.

После этого вызываем метод для создания графиков (в качестве примера приведен график для возраста):
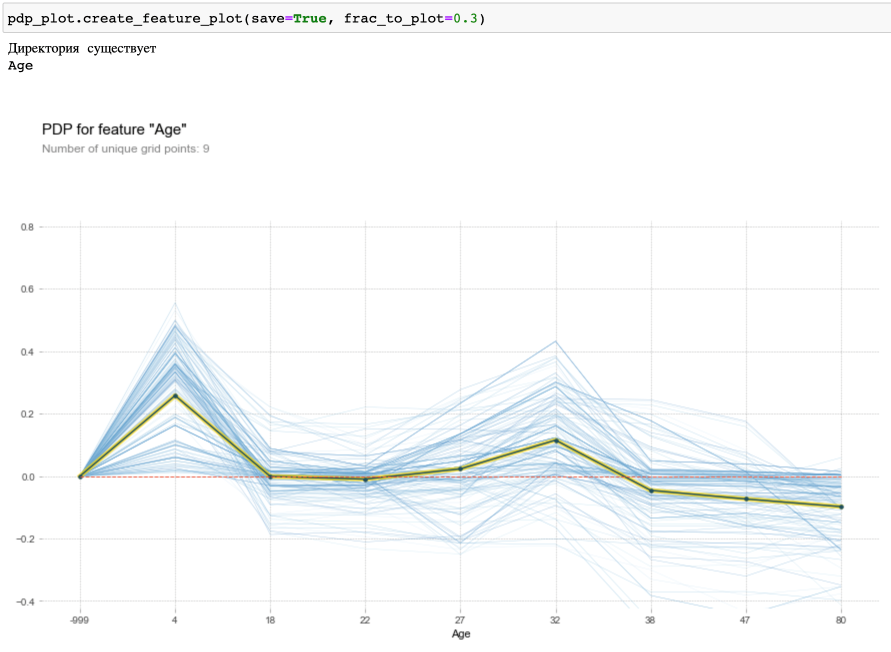
По оси X – значения фичи. По оси Y – склонности к целевой метке. В данной фиче были пропуски, они заполнены значением -999.
На графике видно, что склонны к выживанию дети (возраст до 4 лет) и люди с 27 до 32 (скорее всего их родители).
Итоги
Сегодня мы обсудили некоторые этапы моделирования: подбор параметров модели и интерпретацию фичей обученной модели.
Больше примеров работы с библиотекой autobinary можно найти здесь.
Над библиотекой работали:
Василий Сизов - https://github.com/Vasily-Sizov
Дмитрий Тимохин - https://github.com/dmitrytimokhin
Павел Зеленский - https://github.com/vselenskiy777
Руслан Попов - https://github.com/RuslanPopov98