

Мы – команда «Модели управления Жизненным Циклом Клиента». Ранее мы рассказывали о нашей работе и задачах вот здесь. Сегодня мы расскажем вам про инструмент, которым пользуемся для построения моделей и оптимизации.
Как все начиналось
Рождение autobinary, как и многих других фреймворков, началось с автоматизации рутинных задач. На тот момент мы создавали много look-alike моделей (в основе - модель бинарной классификации) по разным продуктам банка. Одни и те же скрипты писать было скучно. Более того – накопилось много разрозненных скриптов, которые хотелось привести к единому формату.
Начали мы с алгоритма XGBoost и модели бинарной классификации. Сначала сделали функционал для кросс-валидации, далее сделали методы для получения различных метрик, важностей факторов, построения графиков и т.д. И, в результате, назвали библиотеку autobinary, подразумевая, что это фреймворк для простого обучения бинарной классификации на бустинге.
Что сейчас?
Шло время, появлялось все больше разнообразных задач.
Теперь библиотека поддерживает не только задачи бинарной классификации, но и регрессии, мультиклассовой классификации, а также uplift задачи на различных алгоритмах, например, XGBoost, Catboost, LightGBM, Decision Tree, Random Forest.
Функционал библиотеки расширился, а название осталось тем же.
Помимо обучения самих моделей, реализованы различные методы, которые позволяют построить стабильную модель с небольшим количеством факторов, а также интерпретировать результаты обучения модели.

Базовый анализ факторов
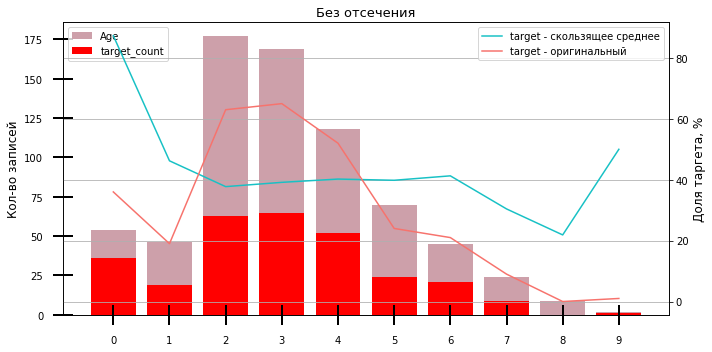
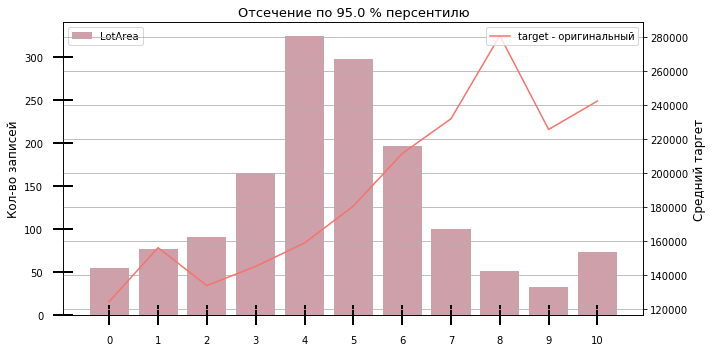
Зачастую факторы имеют разные распределения. Для проведения быстрого однофакторного анализа для задач бинарной классификации и регрессии мы используем графики фактора против таргета.
Класс TargetPlot позволяет разбить фактор по заданному количеству бакетов с настройкой по отсечениям, специальным значениям и др.


Pipeline обработки
Типичная ошибка при моделировании – это лики в данных. Например, моделист сначала заполняет пустые значения в фичах средним значением, а только потом разделяет выборку на train и test. В результате происходит смещение среднего, и в нем содержится информация как о train, так и о test.
Правильная стратегия в этом случае – сначала разделить данные, посчитать среднее на train, а потом этим средним, посчитанном на train, заменить пустые значения и на train и на test.
Если шагов обработки много, то за всем этим становится сложно следить. Именно поэтому обычно используют pipeline из sklearn.
Таким образом, пайплайн сначала обучается на train, а потом применяется и на train и на test.
Мы для быстрых тестов сделали базовый пайплайн обработки, который принимает на вход категориальные и числовые фичи в виде списков и делает следующее:
Пустые значения заполняет большим отрицательным числом для числовых
Категориальные фичи обрабатываются с помощью CatBoostEncoder из библиотеки Category Encoders.
P.S. Рекомендую попробовать разные энкодеры из этой библиотеки, они действительно очень удобные и показывают хорошее качество.
Кросс-валидация
Кросс-валидацию мы обычно используем для отбора факторов, подбора параметров, или, в целом, для проверки модели на стабильность, расчета важностей, расчета средних метрик и т.д.
Давайте посмотрим детально на конкретный пример – кросс-валидация для задачи бинарной классификации «Титаник» с использованием Catboost.
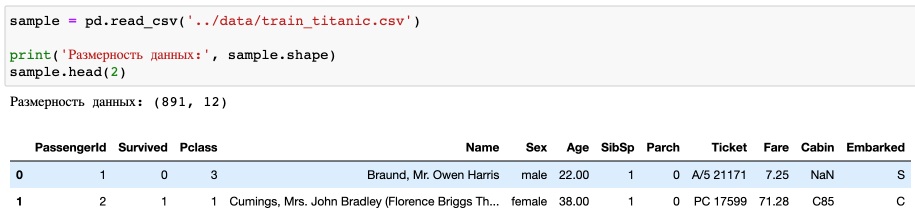
Загружаем данные:
Задаем списки числовых и категориальных фичей, а также название таргета:

Делим выборку на train и test. На train будем учить кросс-валидацию:

Задаем пайплайн обработки данных, в который передаем списки фичей:

Передача пайплайна позволяет упростить преобразование данных и избежать ликов.
Если у нас 5 фолдов, как в этом примере, то на каждой итерации кросс-валидации пайплайн заново переобучается на 4 частях, а потом применяется и к 4 частям и к одной части.
Так как используется pipeline из sklearn, то можно сделать его сколь угодно сложным, а также некоторые части можно написать самому.
Теперь задаем параметры модели, параметры для обучения модели, сам инстанс модели, а также стратегию кросс-валидации:

Стратегию кросс-валидации можно задать любую из sklearn, или написать свою!
Теперь передаем в модель все параметры, которые задали ранее:
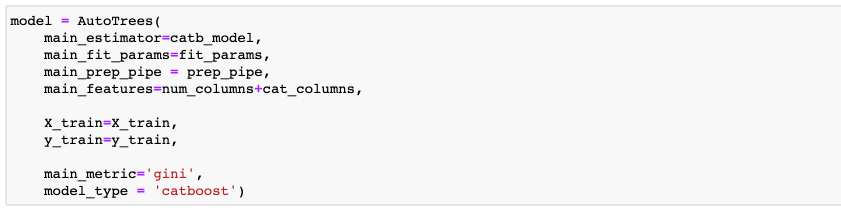
Main_estimator – инстанс модели, которую будем обучать
Main_fit_params – параметры обучения модели
Main_prep_pipe – пайплайн обработки данных
Main_features – все фичи, на которых будет учиться модель
Почему main? Есть некоторые uplift-модели, которые состоят из двух моделей. Поэтому придется передавать сразу две модели в класс AutoTrees. Но об этом мы вам расскажем в следующих частях.
X_train, y_train – выборка и целевая метка
Main_metric – метрика, которая будет выводиться для справки на каждом шаге кросс-валидации и усредняться в методе model.get_mean_cv_scores().
Model_type – модель, которую обучаем.
Теперь запускаем обучение кросс-валидации, передавая стратегию (задали ее выше).
Пример логов обучения одного фолда показан ниже:
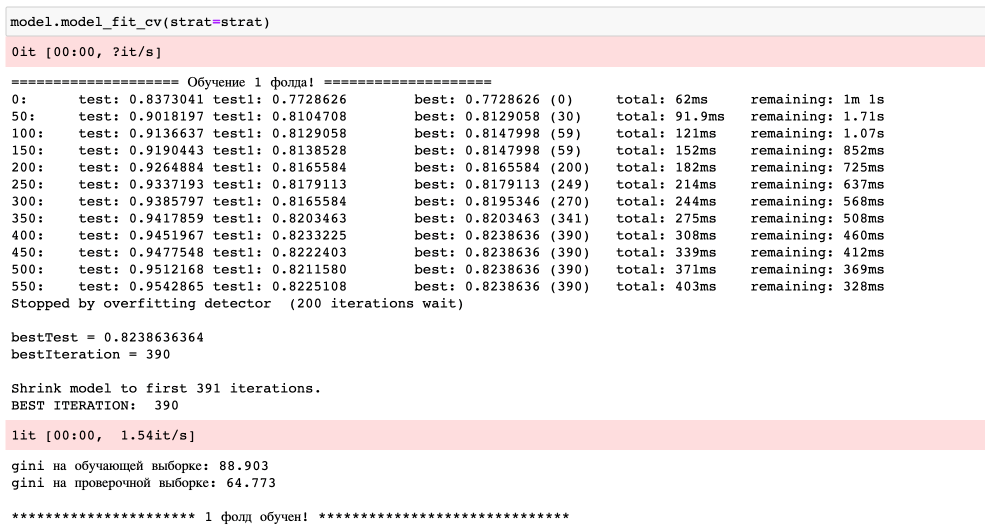
Особенность обучения бустингов нашей библиотекой в том, что мы передаем в параметрах модели большое количество итераций (в данном случае 1000), а также в параметрах обучения указываем early_stopping_rounds (в данном случае 200). В результате, на каждом фолде срабатывает остановка, как только модель начинает переобучаться.
Результаты кросс-валидации
Теперь давайте посмотрим, какие можно получить результаты после обучения кросс-валидации.
В первую очередь это средняя метрика, которую задали в main_metric. Для этой задачи это gini (2*roc_auc-1):

Также это количество итераций на каждом фолде:

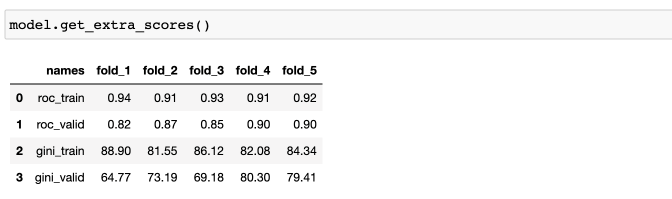
Дополнительная информация по метрикам на каждом из фолдов:
Важности факторов:
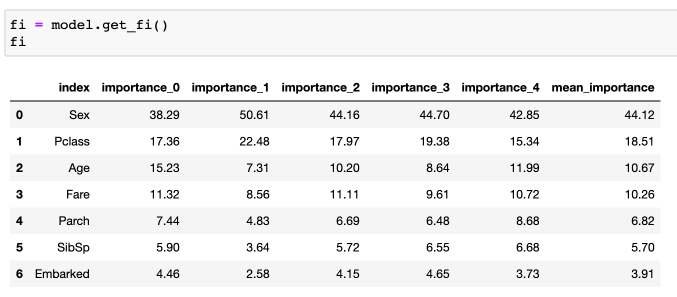
Видов важностей у бустингов много, мы взяли стандартные gain важности.
Графики roc-кривых:
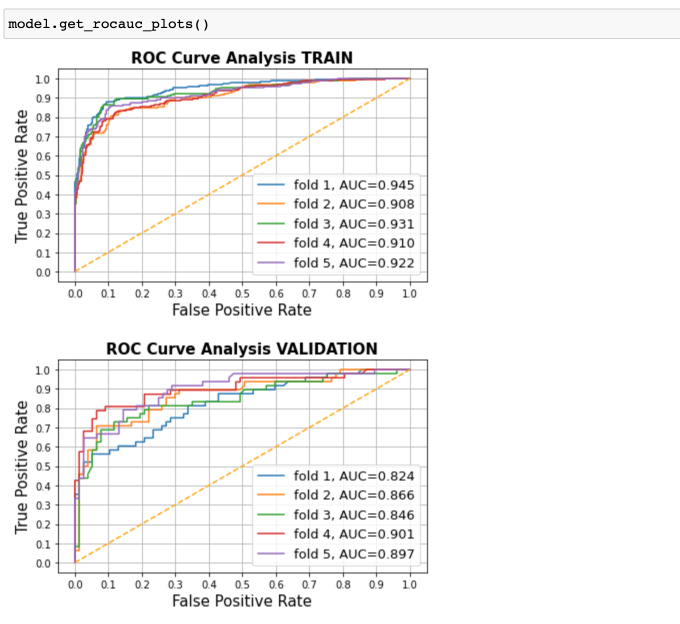
И, наконец, графики обучения модели на всех фолдах. Для примера на первом фолде:
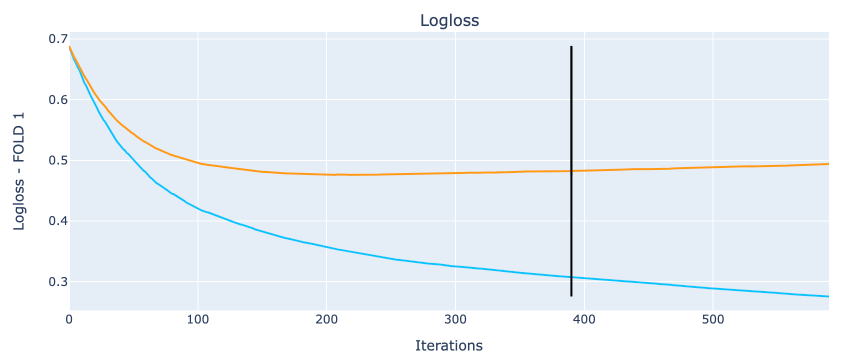
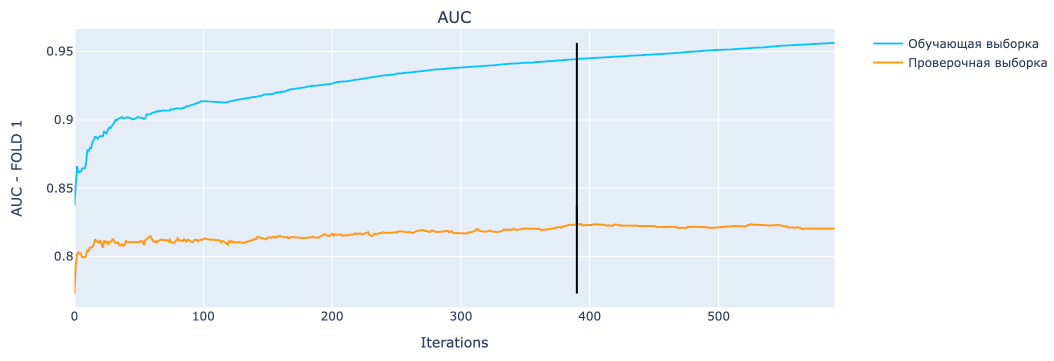
Черная прямая указывает на место, где сработала остановка из-за переобучения!
Итоги
На этом все!
Сегодня мы рассказали о базовом анализе факторов, пайплайне обработки данных, а также кросс-валидации, которая используется во многих других методах моделирования.
В следующих частях мы расскажем вам об отборе факторов, подборе параметров и других интересных особенностях нашей библиотеки!
Над библиотекой работали:
Василий Сизов - https://github.com/Vasily-Sizov
Дмитрий Тимохин - https://github.com/dmitrytimokhin
Павел Зеленский - https://github.com/vselenskiy777
Руслан Попов - https://github.com/RuslanPopov98