
Привет! Меня зовут Даниил Марданов, я бэкенд-разработчик в Контуре.
SLO — это практика, входящая в состав SRE-методологии, которая помогает найти баланс между скоростью развития сервиса и его надёжностью.
В статье хочу поделиться опытом внедрения SLO в наш продукт и рассказать, какие результаты это принесло.
Итак, обо всём по порядку.
Введение
Предлагаю начать с вводной части, в которой я познакомлю вас со своим продуктом и мы вместе погрузимся в предметную область SLO.
О продукте
Я работаю в команде Коннекторы ЭДО. Мы занимаемся разработкой интеграционных решений для других продуктов Контура внутри направления Электронного документооборота. В частности мы помогаем федеральным торговым сетям обмениваться документами с их поставщиками.
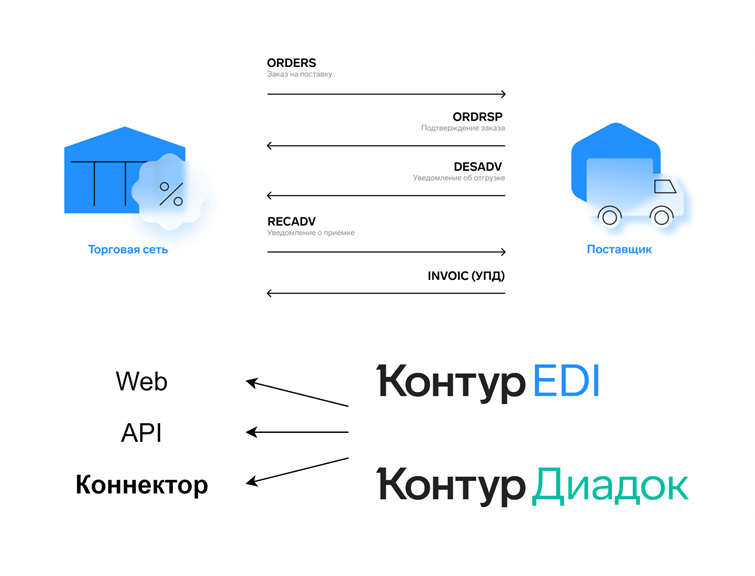
Стандартная цепочка обмена документами начинается с формирования торговой сетью заказа — ORDERS, его подтверждения поставщиком — ORDRSP, последующего уведомления об отгрузке — DESADV и уведомления о приёмке — RECADV. Для обмена этими сообщениями существует сервис Контур.EDI. Затем поставщик отправляет в сеть счет-фактуру в формате УПД, чтобы рассчитаться за поставку и завершить документооборот. Делают это через сервис Контур.Диадок, чтобы документ был заверен электронной подписью и имел юридическую значимость.
С обоими сервисами можно работать руками через Web, написать собственную интеграцию через API либо воспользоваться нашим Коннектором, в котором мы предлагаем коробочное решение с возможностью гибкой кастомизации для быстрой и бесшовной интеграции с учетной системой клиента.
Основная мысль отсюда, что наши клиенты — это крупный бизнес, которому важны гарантии.
Что такое SLO
Теперь давайте разберёмся в терминах
SLA (Service Level Arggement) — соглашение с клиентом об измеримых показателях уровня сервиса, а также о мерах ответственности
SLO (Service Level Objective) — цель, обозначающая уровень сервиса, который мы должны обеспечивать
SLI (Service Level Indicator) — индикатор, отображающий фактический уровень сервиса
Под SLA обычно подразумевается формальный договор, в котором мы "обещаем" клиенту, насколько надёжными будут наши сервисы. В противном случае к нам применят санкции (обычно — денежный штраф). Физический смысл этого договора в том, что клиент завязывается на наше ПО в критичных для себя бизнес-процессах, при поломке которого он понесёт убытки по нашей вине. Поэтому часть ответственности перекладывается на нас.
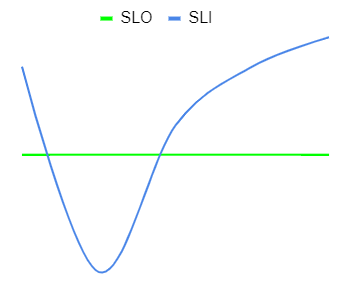
В упрощенном виде можно сформулировать SLA примерно следующим образом: "Сервис должен быть доступен 99% времени в течение месяца". То есть появляется вполне конкретная цель в 99% аптайма — это и будет нашим SLO. Чтобы следить, выполняется ли цель, нужно научиться измерять фактическое время аптайма — это будет нашим SLI.
На графике SLO будет представлено горизонтальной линией, которая играет роль порога. В свою очередь SLI — это величина, которая изменяется во времени в зависимости от того, насколько хорошо работает сервис.
На деле у термина SLO есть ещё одно значение.
SLO (в широком смысле) — это практика, входящая в состав SRE-методологии, которая помогает найти баланс между скоростью развития сервиса и его надёжностью.
Под практикой здесь подразумевается некоторая совокупность инструментов и процессов.
Суть практики SLO — явно поставленная цель, насколько надёжный сервис мы делаем.
При работе с ней мы:
Измеряем надёжность — определяем SLI и начинаем собирать необходимые метрики
Ставим себе цель — формулируем SLO (в узком смысле) и задаём целевые пороги
Следим, чтобы цель выполнялась — ради этого меняем приоритеты задач, выбираем архитектуру и технические решения
Зачем это делать
Любой продукт можно делать с разной надёжностью.
Можно фигачить в прод без ревью и тестов, а можно кропотливо дотачивать каждую фичу, доводя её до совершенства. Недостатки первого подхода очевидны — сервис получится хрупким, ненадёжным и быстро растеряет доверие своих пользователей. На его фоне другой вариант, делать всё основательно и "на совесть", смотрится куда более выигрышно. Ведь не зря говорят "нормально делай — нормально будет". Но стремление к абсолютному качеству и 100%-ной надёжности на самом деле тоже могут навредить продукту и вот почему.
Во-первых, 100%-ная надёжность попросту недостижима. Как минимум потому, что код пока всё ещё пишем мы, люди, и время от времени допускаем в нём ошибки. Но даже если свой код мы напишем идеально без багов, то у сервиса все равно останутся зависимости от внешних провайдеров услуг, которые также влияют на его надёжность В датацентре может пропасть электричество, а интернет-провайдер устроить внезапные тех. работы на линии. Также всегда остаётся шанс нарваться на баг в сторонней библиотеке или даже операционной системе, которые точно так же были написаны людьми. В общем, как бы мы ни старались минимизировать эти риски, свести их к нулю все равно не удастся, а значит добиться 100%-ной надёжности тоже.
Во-вторых, абсолютная надёжность коммерчески невыгодна, причём как вам, так и вашему пользователю. Всё дело в том, что с повышением надёжности растут и затраты на её обеспечение, причём, как правило, нелинейно (можно вспомнить про закон Парето). Это значит, что каждая следующая "девятка" в значении SLI будет обходиться вам всё дороже, как с точки зрения вычислительных ресурсов, так и по времени разработки. При этом, после определённого порога пользователь перестанет замечать эти улучшения, зато он заметит отсутствие важной для него функциональности, развитием которой вы пожертвовали.
В большинстве случаев (за исключением специфических отраслей, таких как, например, авиастроение) пользователь выберет просто хорошо работающую фичу через месяц, чем идеальную через год. Практика SLO помогает определить и поддерживать достаточный уровень качества в продукте, соблюдая оптимальный баланс между развитием функциональности и отказоустойчивости.

Кому нужно SLO
— Инженерам или менеджерам?
Такой вопрос мог совершенно справедливо появиться у вас.
На мой взгляд, практика SLO лежит на стыке этих двух зон ответственности, и я бы охарактеризовал её как инженерный подход к решению менеджерской задачи.
Менеджерской, потому что практика SLO в конечном счёте влияет на распределение ресурсов и расстановку приоритетов для команды разработки. Этим, как правило, занимаются менеджеры.
Инженерный, потому что мы хотим делать это объективно и обоснованно, опираясь не на интуитивные представления о качестве и надёжности, а на их численные показатели, выраженные в виде метрик, графиков и формул. Так обычно поступают инженеры.
Кроме того, практика SLO будет полезна в следующих ситуациях, если вы менеджер:
Разработчики становятся заложниками перфекционизма, оперируют к малоизмеримому понятию отказоустойчивости и качества кода вместо решения реальных проблем пользователей
Время команды уходит на улучшения надёжности, а измеримого результата нет. Только уверенность, что сделали что-то правильное
Есть подписанный с клиентом SLA
И если вы инженер:
В ходе добавления всё новых и новых фич сервис становится слишком хрупким. Часто случаются факапы, поддержка требует много сил. Вы недовольны качеством разрабатываемого продукта, хотите что-то поменять, но не можете это аргументировать
Вам сложно объективно оценить, хорошо ли работал сервис последнюю неделю, месяц или квартал
Возможно, некоторые из них окажутся для вас знакомыми.
Внедрение SLO
С вводной частью мы закончили, теперь можем переходить к внедрению SLO, которое, в свою очередь, можно разделить на 5 этапов. Предлагаю подробно пройтись по каждому из них.
1. Найти ключевые сценарии
Здесь будет уместно вспомнить про то, что SLO базируется на пользовательском представлении о качестве. Поэтому на самом первом этапе нам нужно постараться поставить себя на место пользователя и ответить на вопрос — какую самую важную задачу решает ваш сервис и какой сценарий является в нём основным. Для этого бывает полезно запустить небольшое исследование, провести анкетирование или пообщаться с пользователями в формате интервью. Также можно дойти до вашего аналитика или продакта, если таковые имеются, потому что кто, как не они, знают потребности вашего пользователя лучше всего.
В нашей команде под это дело запускался целый процесс под названием производственный аудит, одним из результатов которого был вывод, что нам нужно SLO, а основной сценарий в нашем сервисе — это доставка сообщений. То есть пересылка документов между двумя источниками данных, одним из которых является API сервиса Контура, а другим — например, FTP-сервер, откуда они попадают в учётную систему клиента.
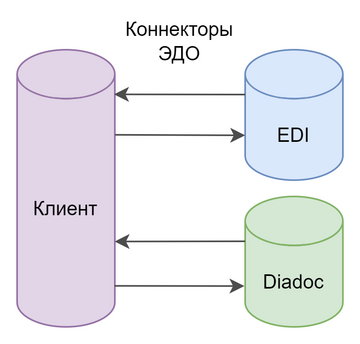
Учитывая, что мы главным образом интегрируемся с двумя сервисами Контура, а документы в них ходят в обе стороны, то можно выделить 4 подсценария, на каждую из стрелочек на схеме:
EDI → Клиент
Клиент → EDI
Диадок → Клиент
Клиент → Диадок
Верхнеуровнево все подсценарии схожи, но под капотом они имеют специфичную бизнес-логику, обслуживаются разным кодом и, как следствие, могут иметь разную надёжность. Поэтому в свой SLO мы заложили возможность рассматривать их как все вместе, так и каждый в отдельности.
2. Определить SLI
Вспомним, что SLI — это метрика, численно отражающая качество сервиса. Если таких метрик у вас несколько, то лучше выделить из них какую-то одну, чтобы они не противоречили друг другу. Здесь важно качество, а не количество.
Хорошая метрика SLI будет идти вверх и стремиться к 100% во время штатной работы вашего сервиса. А при возникновении факапов она должна снижаться пропорционально тому, как долго продолжался сбой и сколько пользователей от этого пострадали. В общем случае SLI считается по формуле:
SLI = X / Y * 100%
как отношение числа положительных сценариев в вашем сервисе — X, к их общему числу — Y. Удачными примерами SLI будут: доля успешных запросов, процент времени аптайма.
Кроме того, метрика SLI всегда считается за какой-то период, от размера которого зависит как быстро она будет восстанавливаться после просадок. Чем меньше он будет, тем быстрее будет отрастать SLI. Физический смысл этого периода в том, что пользователь не сразу забывает о случившихся неполадках, а помнит о них ещё какое-то время. Как правило, его выбирают равным неделе, месяцу или кварталу.
В нашем случае в качестве основной метрики было выбрано время доставки сообщений. За X берётся число сообщений, доставленных вовремя, за Y — общее число сообщений. Порог своевременной доставки N задаётся в минутах и может варьироваться в зависимости от клиента и сценария. Например, в сценариях обмена с сервисом Контур.EDI этот порог будет ниже, потому что требования к скорости доставки ритейловских документов более строгие. В качестве основного периода для агрегации метрик мы выбрали 90 дней, то есть квартальный SLI.
3. Выбрать пороговые значения
При выборе порогов важно учитывать как потребности пользователей, так и возможности сервиса. Это нужно, чтобы заложенная в SLO цель была объективной и отражала в себе ожидания клиентов от вашего продукта, но оставалось при этом достижимой.
Для этого бывает полезно заранее реализовать логику подсчёта SLI, с учётом выбранных на предыдущих этапах параметров, и собрать эту метрику ретроспективно, если у вас имеется такая возможность. В нашем случае данные, необходимые для подсчёта SLI, хранятся 6 месяцев и мы смогли построить черновой вариант графиков будущего SLO
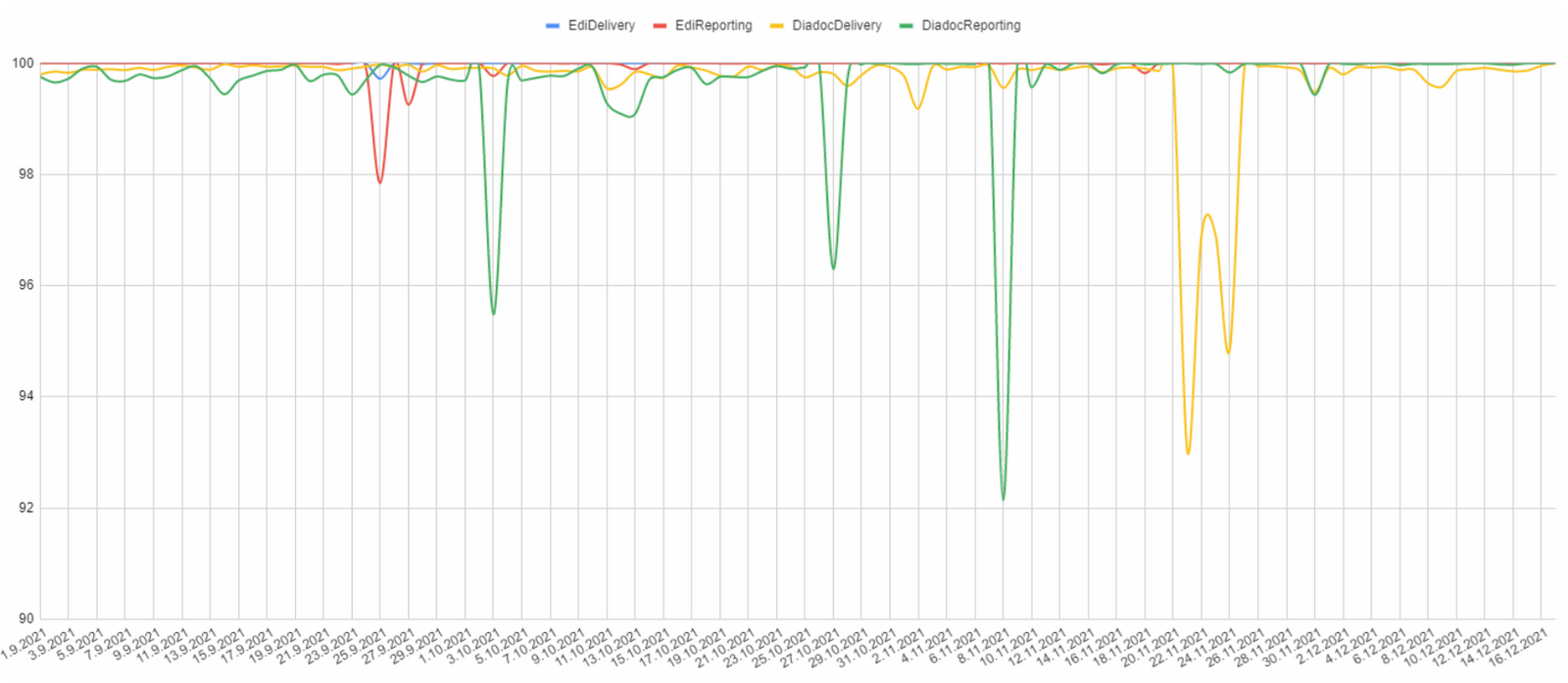
Для простоты анализа метрики разделены по подсценариям, а период агрегации задан в 1 день, т.е. накопительный эффект отсутствует. Таким образом, можно увидеть, насколько хорошо работал каждый сценарий в конкретные дни. Чтобы убедиться в корректности получаемых данных, нужно проверить, что отсутствуют ложные срабатывания и каждая просадка на графиках соответствует реальному сбою в работе сервиса. И с другой стороны, что ни один из известных факапов не "прошёл мимо" вашего SLI и каждый из них вызвал соразмерное снижение соответствующих показателей. При выявлении несоответствий, нужно найти и исправить проблему, например, поправить баг в алгоритме сборе метрик, после чего собрать исправленные метрики и повторить упражнение. Как правило, этот процесс занимает несколько итераций, пока на выходе не получатся корректные и объективные графики.
Теперь можно посчитать SLI с использованием периода агрегации, выбранного на 2-ом этапе. В нашем случае метрика колебалась от 99,2% до 99,8% со средним значением в районе 99,6%. Посмотрев на эти показатели, мы пришли к выходу, что хотим иметь не один, а сразу два порога. Внешний был взят из реальных SLA договоров с клиентами и равен 99%. Он отражает требования к качеству со стороны пользователей. Эта цель является строгой и за весь период рассмотрения ни разу не нарушалась. Чтобы цель была не только достижимой, но и амбициозной, мы ввели ещё и внутренний порог равный 99,5%. Он стимулирует нас работать чуть лучше, чем минимально достаточный клиентам уровень, чтобы всегда иметь небольшой резерв на ошибку.
Таким образом, метрики могут находиться в одном из 3-х состояний:
SLI ≤ 99% — нарушаем оба порога
99% < SLI ≤ 99,5% — нарушаем внутренний порог
SLI > 99,5% — выполняем оба порога
По завершению этого этапа можно начать сбор метрик в продакшне и настроить красивые графики.
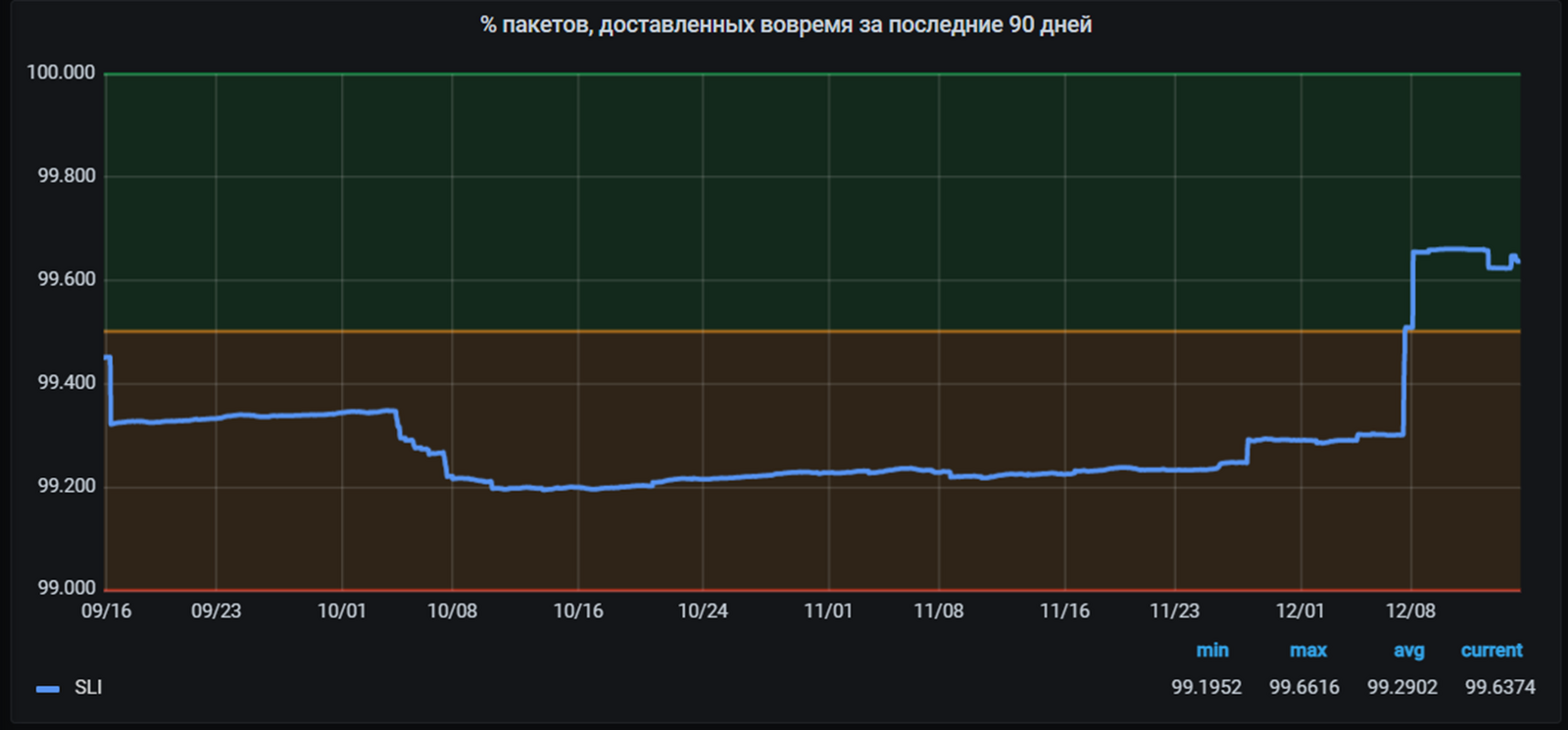
Однако, это ещё не полноценное SLO. Если вернуться к определению и вспомнить, из чего состоит практика SLO, то получится, что к этому моменту у нас готовы только инструменты, которые сами по себе ещё не приносят никакой пользы. Чтобы полученные метрики и графики не остались просто цифрами, которые ни на что не влияют, нужно также поработать над процессами, чему и будут посвящены оставшиеся два этапа.
4. Опубликовать SLO
На этом этапе нужно подготовить подробную документацию на ваш SLO, в которой будет объясняться, как были получены представленные на графиках значения. Это необходимо, чтобы получить доверие к SLI, SLO как к мерилу качества, причем как внутри вашей команды, так и за её пределами.
Для этих целей, как правило, составляют SLO-doc, который включает в себя следующие разделы:
Описание сервиса — рассказываем всё самое необходимое, что нужно знать о продукте и предметной области. За основу можно взять результаты первого этапа c поиском ключевых сценариев
Описание SLI, SLO и обоснование выбранных значений — объясняем, почему были выбраны именно такие метрики и пороги, по какой формуле они считаются. Документируются решения, сделанные на этапах 2 и 3 — определение SLI и выбор пороговых значенией соответственно
Границы применимости — перечисляем сценарии, которые не покрывает SLO. Для нас это будут, например, отказы клиентских источников. В этом случае в качестве времени доставки будет считаться время первой попытки отправки с нашей стороны
Политика реакции на нарушение пороговых значений — говорим, что будем делать, если SLO перестанет выполняться. Если наш SLI окажется в жёлтой зоне, то мы начнём разбираться с проблемой и при необходимости делать фиксы. А если дойдёт до красной, то будем менять приоритеты разработки с развития функциональности на отказоустойчивость, вплоть до полной остановки разработки новых фич на какое-то время
Важно отметить, что SLO-doc должен писаться на языке пользователя и быть понятен людям без глубокого продуктового и технического контекста. Опубликовать его можно как внутри компании, так и за её пределами, в зависимости от того, какие цели вы преследуете. В нашем случае нам было достаточно непубличного SLO, описание которого было размещено в специальном трекере внутри Контура.
5. Встроить в процессы
Теперь нам остаётся только поддерживать актуальность SLO и учитывать его в работе. Поскольку речь идёт про процессы, то на этом этапе бывает полезно заколлабиться с человеком из вашей команды, кто за эти процессы отвечает. Обычно это менеджер разработки или тимлид.
Для поддержания актуальности нужен процесс регулярного пересмотра SLO, на котором мы будем задавать себе следующие вопросы:
Выполняется ли цель?
Актуальны ли метрики?
Не появился ли новый важный сценарий?
В зависимости от ответов на эти вопросы определяем необходимость доработки нашего SLO: сценариев, метрик и алгоритмов их сбора или порогов. Это необходимо делать не реже, чем период агрегации вашего SLI, т.е. в нашем случае — раз в 3 месяца.
Кроме того, нужно решить, каким образом SLO будет использоваться в работе. В нашем случае значение SLI влияет на распределение ресурсов разработки при планировании спринтов. Все задачи мы разбиваем на потоки и задаём целевую квоту для каждого из них:
Бизнесовые + продуктовые = 40%
Отказоустойчивость = 25%
Рефакторинг = 15%
Тесты = 10%
Облегчение поддержки = 5%
Разное = 5%
Соблюдение этих квот обеспечивается тем, что мы собираем с нашей agile-доски метрики фактического распределения ресурсов и стараемся приблизить эти показатели к целевым, выбирая на очередном планировании больше или меньше задач определенного типа. Эти квоты тоже регулярно пересматриваются и процент "Отказоустойчивости" в общей доле определяется исходя из текущего положения дел с SLO — чем ближе метрика к красной зоне, тем больше он будет.
Результаты
Теперь, когда мы завершили внедрение SLO, самое время посмотреть, что у нас получилось и какие результаты это принесло.
Графики
Самое интересное здесь, конечно же, графики, с них и предлагаю начать. Метрики мы храним в Graphite, а дашборд у нас построен в Grafana.
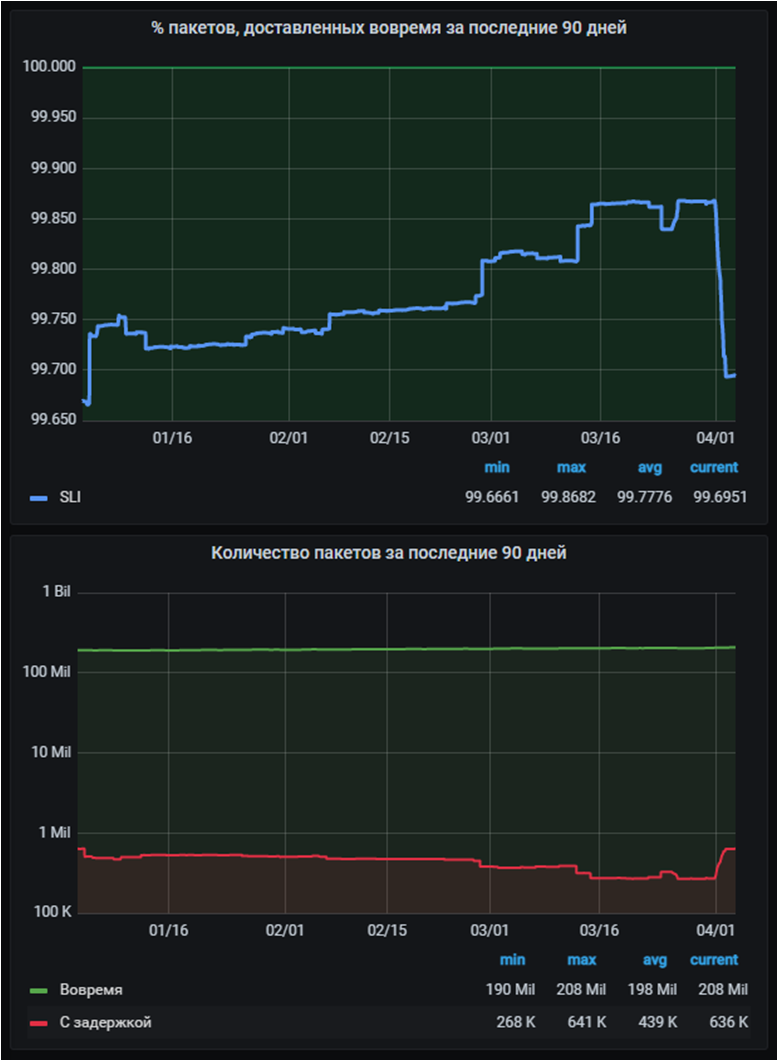
Главный график это SLI с агрегацией за 90 дней, который мы уже видели ранее. Сейчас он находится в зелёной зоне. Вместе с ним мы строим график скользящей суммы с тем же периодом агрегации по числу сообщений, доставленных вовремя, и с задержкой. По сути это те самые X и Y из формулы SLI. Поскольку это величины разных порядков, график построен в логарифмическом масштабе.
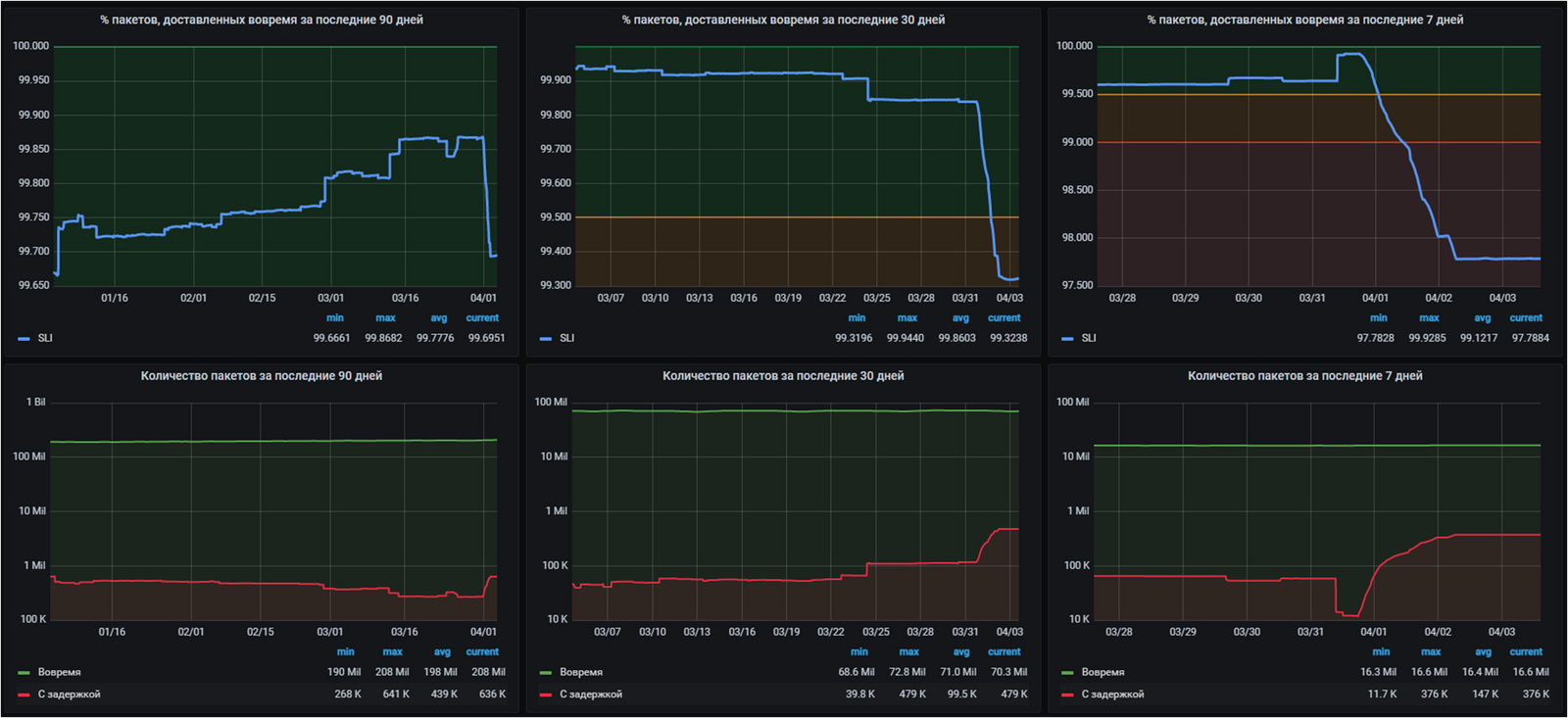
Не смотря на то, что в качестве основного был выбран квартальный SLI, мы также строим аналогичную пару графиков с периодом агрегации за 30 и за 7 дней. Их ценность заключается в том, что они являются куда более чувствительными и с их помощью можно значительно раньше обнаружить наметившийся тренд. На примере отметившегося на графиках факапа видно, что в то время как SLI за 90 дней просел всего на 0,15% и остался в зелёной зоне, SLI за 30 дней пробил границу желтой зоны, а SLI за 7 дней и вовсе за несколько часов перешёл из зелёной зоны в красную и замер на отметке меньше 98%. Если этот сбой будет единичным, то спустя неделю доставленные с задержкой документы выйдут из диапазона рассмотрения SLI за 7 дней и он вернётся в зелёную зону. Затем, спустя месяц то же самое произойдёт с SLI за 30 дней. Но если сбои будут продолжаться и появятся новые несвоевременно доставленные документы, то SLI за 7 дней останется висеть в красной зоне и со временем неуклонно потянет за собой SLI за 30. А тот, в свою очередь, ещё чуть погодя сделает то же само с основным SLI за 90 дней. Таким образом, графики с меньшим периодом агрегации позволяют как бы "заглянуть в будущее" и понять, куда движется наш основной SLI.
Все эти графики можно построить отдельно для одного конкретного клиента или подсценария.
Это бывает важно потому, что у разных клиентов или сценариев объём отправляемых документов может значительно отличаться, из-за чего они будут вносить разный вклад в совокупную метрику. Допустим, у нас есть клиенты с трафиком в десятки или даже сотни тысяч документов в день, а есть те, у кого обрабатывается лишь несколько тысяч документов в месяц. Если у такого "малыша" какой-то сценарий будет работать из рук вон плохо или не будет работать вообще, то в огромной массе успешных документов "большого" клиента они просто растворятся и не будут видны. Поэтому мы дополнительно считаем изолированные метрики по всем нашим основным клиентам и выводим их в виде числа в цветном квадратике в самом верху нашего дашборда, чтобы они всегда были у нас перед глазами.

Так, например, видно, что у одно из клиентов SLI пожелтел, притом что совокупная метрика уверенно находится в зелёной зоне. Давайте попробуем найти причину, почему это произошло.
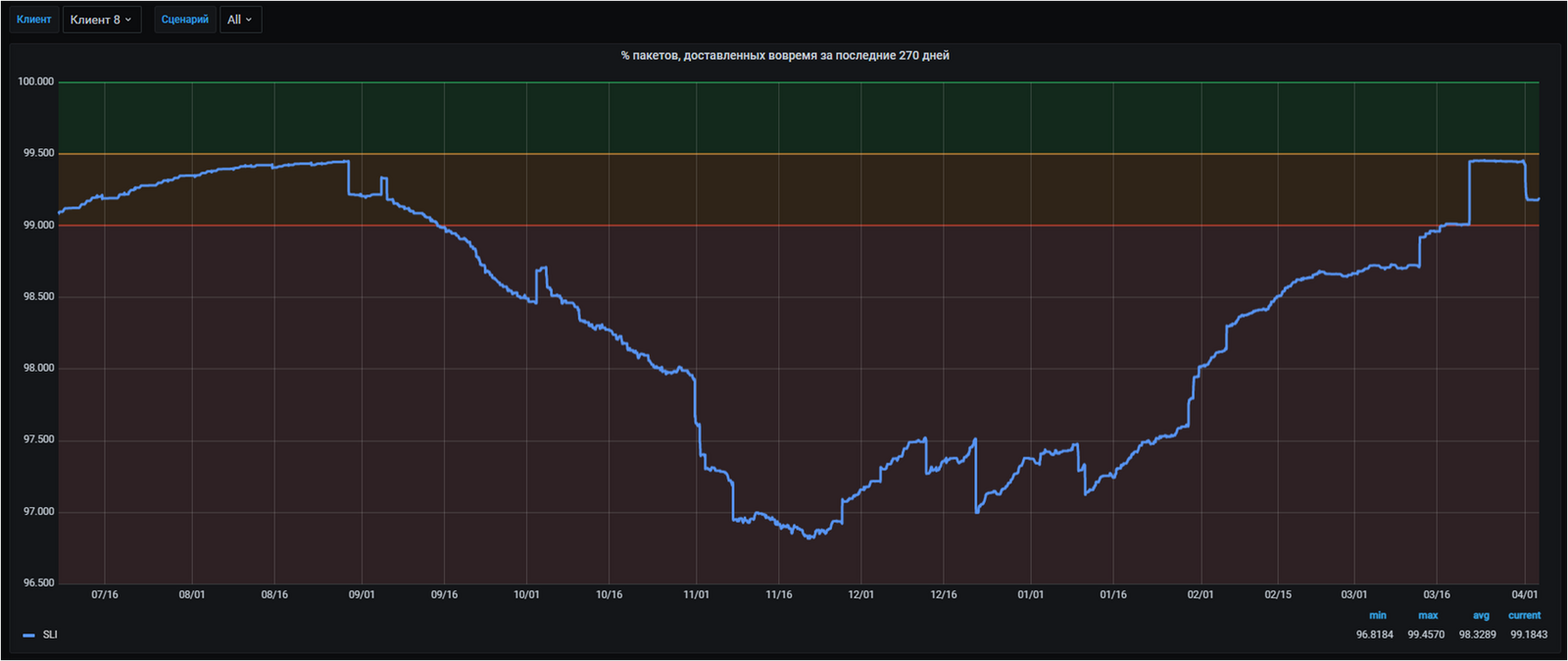
Если построить график за более длительный срок (период агрегации остался неизменным — 90 дней), то можно увидеть, как у клиента образовался негативный тренд, который утянул метрику в красную зону. Затем, в нижней точке этот тренд переломился и SLI начал постепенно отрастать и восстанавливаться в норму. Из красного он перешёл в желтый, а если бы не недавний сбой, то метрика скорее всего бы уже позеленела.
В действительности за этой проблемой у клиента скрывается процесс генерации печатных форм к документам — человекочитаемых PDF-ок из формализованных XML-ек. Эта операция довольно дорогая, и у нас она реализована асинхронно, т.е. от начала генерации печатной формы до её готовности проходит некоторое время. Оказалось, что из-за неоптимальной стратегии повтора в некоторых случаях это ожидание могло занимать слишком много времени и приводить к задержкам в доставке документов. В общем случае на большом объёме документов это работает достаточно хорошо, а вот на клиенте с небольшим трафиком это становится заметно. Эта проблема была обнаружена лишь с помощью SLO на очередном его пересмотре. Чтобы заметить это, требовалось посмотреть на сценарий глазами пользователя, с чем системные метрки не могли справиться в полной мере. Лечилась же она довольно легко — достаточно было поправить неоптимальные настройки повтора.
И, наконец, самые последние графики с детализацией. На них показывается количество документов, обработанных в конкретный момент времени с разбивкой по клиентам и подсценариям. Выводим по паре диаграмм для документов, доставленных вовремя и с задержкой
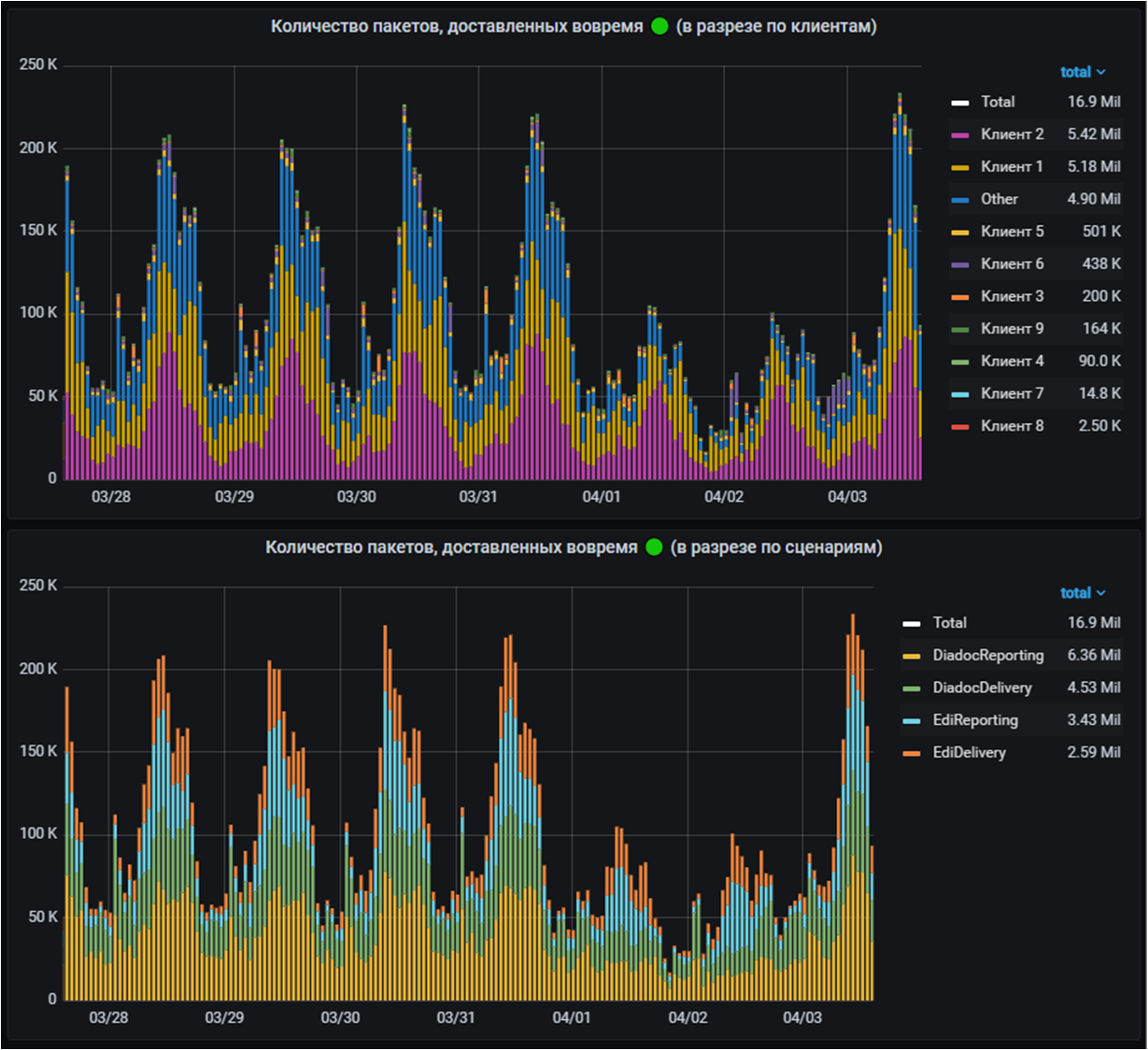
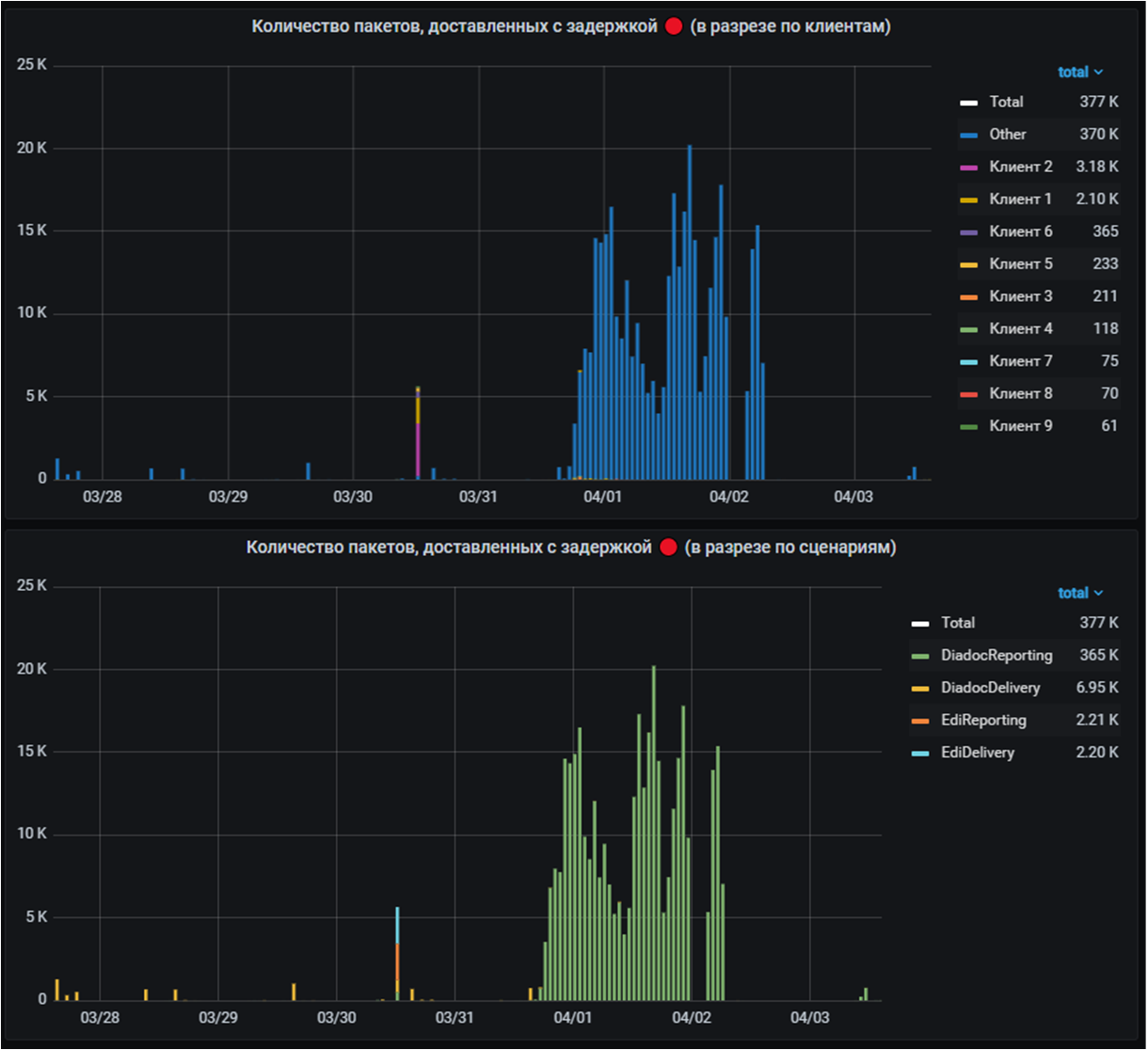
По последним бывает очень удобно анализировать последствия факапа. По размеру "холма" на графике можно определить масштаб его последствий, а также оперативно оценить какие клиенты и подсценарии пострадали больше всего.
Как мы используем SLO
Подведём краткий итог, где и какую пользу оно нам приносит. С помощью SLO:
При планировании ресурсов отвечаем себе на вопрос: пилить новые фичи или улучшать надежность?
Замечаем и лечим неочевидные проблемы с надёжностью и производительностью в наших сервисах
Оперативно оцениваем последствия факапов и выделяем самые важные задачи для их предотвращения
Простые первые шаги
Если в процессе моего рассказа практика SLO вас заинтересовала, то я подготовил несколько простых шагов, как можно попробовать примерить её на свой продукт:
Выберите самый важный сценарий — чтобы не заморачиваться с исследованием, можно определить самый часто используемый и для начала выбрать его
Начните измерять его SLI — в первую очередь обратите внимание на те метрики, которые будет легче всего собрать или те, которые у вас уже есть
Спустя месяц постройте графики и посмотрите, что получилось — коррелируют ли они с действительностью и насколько ваш сервис надёжный
Главный совет — не бояться допустить ошибку и сделать неправильный выбор на одном из этапов. Процесс внедрения SLO — итеративный, вполне реально начать с чего-то очень простого, что можно будет постепенно улучшать и дорабатывать
Ведь лучше месяц проработать с несовершенным SLO, чем бесконечно откладывать его внедрение!
arkultic
Вы хотите что бы компании разорились?) Если клиент не заметил простоя, значит его не было (если только ты не банк).