
В сети огромное количество мануалов по созданию отказоустойчивых групп доступности AlwaysON Microsoft SQL Server посредством Windows Server Failover Cluster. Но что делать, если экземпляры Microsoft SQL Server развёрнуты на Linux, а очень хочется создать отказоустойчивые группы доступности AlwaysON? В русскоязычном сегменте не нашёл внятных мануалов, посвящённых этому вопросу. Решил написать гайд. Сразу скажу, гайд в некоторых местах будет очень подробный и разжёвыванием банальных вещей может раздражать опытных системных администраторов, однако, как показывает практика, людей которым хотелось бы, чтобы он был ещё подробнее куда больше, чем тех, кому эта подробность не по нраву. Тут мы затронем и вопросы оптимизации производительности, которые актуальны для наверно самого популярного прикладного применения Microsoft SQL Server в России — хранения информационных баз 1С. На самом деле данная задача не особо сложная, но важна к освящению.
Отказоустойчивость информационной базы 1С, которая должна работать 24/7, является необходимостью для каждого уважающего себя системного администратора и руководителя. Данная отказоустойчивость нужна не только и не столько для того, чтобы противостоять сбоям аппаратных комплексов, но и для проведения планового обслуживания оных без остановки работы персонала с информационной базой. Некоторые предприятия не могут себе позволить просто так остановить работу для того, чтобы администратор не спеша занимался обслуживанием SQL сервера. Технологические регламенты у таких предприятий есть, конечно же, но делить время, выделенное на них, приходится с 1С-никами, которым постоянно нужно то конфигурацию обновить, то внести иные правки. Ну и как вы понимаете, они не смогут этого сделать, когда база недоступна по причине обслуживания сервера администратором. Чтобы раз и навсегда решить эту дилемму мы и реализуем отказоустойчивость. После этого мы как минимум получим возможность обслуживать SQL сервер не прерывая работу пользователей или обслуживание информационной базы 1С специалистами, а бонусом получим устойчивость информационной базы к отказам аппаратного обеспечения, на котором развёрнуты экземпляры Microsoft SQL Server.
Отказоустойчивость групп доступности Always On Microsoft SQL Server реализуем при помощи связки Pacemaker и Corosync.
Описание, что есть Pacemaker и Corosync - взято отсюда. Все вполне лаконично, добавить мне нечего.
Corosync — программный продукт, который позволяет создавать единый кластер из нескольких аппаратных или виртуальных серверов. Corosync отслеживает и передает состояние всех участников (нод) в кластере.
Этот продукт позволяет:
мониторить статус приложений;
оповещать приложения о смене активной ноды в кластере;
отправлять идентичные сообщения процессам на всех нодах;
предоставлять доступ к общей базе данных с конфигурацией и статистикой;
отправлять уведомления об изменениях, произведенных в базе.
Pacemaker — менеджер ресурсов кластера. Он позволяет использовать службы и объекты в рамках одного кластера из двух или более нод. Вот вкратце его достоинства:позволяет находить и устранять сбои на уровне нод и служб;
не зависит от подсистемы хранения: можем забыть общий накопитель, как страшный сон;
не зависит от типов ресурсов: все, что можно прописать в скрипты, можно кластеризовать;
поддерживает STONITH (Shoot-The-Other-Node-In-The-Head), то есть умершая нода изолируется и запросы к ней не поступают, пока нода не отправит сообщение о том, что она снова в рабочем состоянии;
поддерживает кворумные и ресурсозависимые кластеры любого размера;
поддерживает практически любую избыточную конфигурацию;может автоматически реплицировать конфиг на все узлы кластера — не придется править все вручную;
можно задать порядок запуска ресурсов, а также их совместимость на одном узле;
поддерживает расширенные типы ресурсов: клоны (когда ресурс запущен на множестве узлов) и дополнительные состояния (master/slave и подобное) — актуально для СУБД (MySQL, MariaDB, PostgreSQL, Oracle, MSSQL);
имеет единую кластерную оболочку CRM с поддержкой скриптов.
Имеем, три виртуальные машины с установленной и предварительно настроенной минимальной ОС Debian 11 из netinstall образа (выбираю только сервер ssh и системные утилиты).
Список IP адресов, используемых в нашем кластере:
10.10.2.228 первый узел кластера с именем mssql-test-1;
10.10.2.229 второй узел кластера с именем mssql-test-2;
10.10.2.240 третий узел кластера с именем mssql-test-3;
10.10.2.18 прослушиватель группы доступности ag1 с именем list-ag1;
10.10.2.19 прослушиватель группы доступности ag2 с именем list-ag2.
Идею предполагаемой работы кластера постарался изложить на схеме ниже:
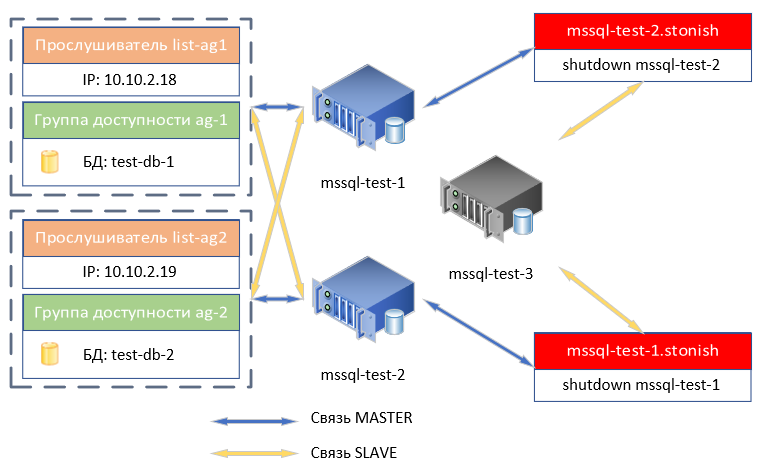
Немного поясним схему. Ресурс прослушивателя list-ag1 жёстко привязан к ресурсу группы доступности ag1, два этих ресурса не могут находиться на разных узлах. Если для ресурса ag1 узел MASTER - это mssql-test-1, то и для ресурса list-ag1 в этот момент MASTER узлом будет mssql-test-1. При переключении ресурса ag1 на другой MASTER узел, list-ag1 автоматически переключится следом. Ресурс прослушивателя list-ag2 также жёстко привязан к ресурсу группы доступности ag2. Третий узел кластера mssql-test-3 со слов Microsoft может не иметь полноценного экземпляра Microsoft SQL, на нём может быть установлен выпуск Express, что позволяет ему хранить только конфигурацию групп доступности ag1 и ag2. Так это или нет, сможете проверить сами, у меня на момент начала написания статьи уже были подняты три виртуальные машины с выпуском Microsoft SQL Server Evaluation Edition. Базы данных в группах доступности не будут синхронизироваться на этот узел (специально помечен на схеме серым цветом). Узел кластера mssql-test-3 не может быть MASTER для ресурсов: list-ag1, list-ag2, ag1, ag2. Поэтому мы поставим самый низкий приоритет переключения этих ресурсов на mssql-test-3.
Также у нас есть два ресурса mssql-test-1.stonish и mssql-test-2.stonish, которые предназначены для отключения одноимённого им узла. Соответственно, они не могут быть MASTER на том узле, для выключения которого они предусмотрены. Что такое STONISH расскажем в самом конце гайда. Ресурсы stonish мы тоже выставлением приоритета попросим не работать на одноимённых им узлах.
Все действия произвожу под root. Не вижу в этом абсолютно ничего плохого на тестовом стенде. Фаервол тоже не включаю, не вижу необходимости в этом внутри защищённой инфраструктуры. Адепты "супер-секурности" заранее извиняйте. Всё умею, но лишний раз не хочу всё это настраивать и описывать.
1. Установка Microsoft SQL Server 2022
Все действия из этого пункта производим на каждом узле нашего будущего кластера.
Обновляем список пакетов и устанавливаем необходимые утилиты:
# apt update
# apt -y install gnupg2 curl wgetДобавляем открытый ключ GPG Microsoft:
# wget -O- https://packages.microsoft.com/keys/microsoft.asc | tee /etc/apt/trusted.gpg.d/microsoft-archive-keyring.ascДобавляем официальный репозиторий Microsoft SQL Server 2022, предназначенный для Ubuntu 20.04:
# curl https://packages.microsoft.com/config/ubuntu/20.04/mssql-server-2022.list | tee /etc/apt/sources.list.d/mssql-server-2022.listОпять обновляем список пакетов и устанавливаем сам SQL сервер:
# apt update
# apt install -y mssql-serverЗапускаем процедуру начальной конфигурации экземпляра Microsoft SQL Server:
# /opt/mssql/bin/mssql-conf setupПервый и главный вопрос конфигуратора - выбор редакции SQL Server или "выпуска" - как их называет сам Microsoft:
1) Evaluation (бесплатный, без прав на использование в рабочем окружении, 180-дневное ограничение)
2) Developer (бесплатный, без прав на использование в рабочем окружении)
3) Express (бесплатная)
4) Web (платный)
5) Standard (платный)
6) Enterprise (платный) - CPU core utilization restricted to 20 physical/40 hyperthreaded
7) Enterprise Core (платный) - CPU core utilization up to Operating System Maximum
8) У меня есть лицензия, купленная через канал розничных продаж, и ключ продукта для ввода.
9) Standard (Billed through Azure) - Use pay-as-you-go billing through Azure.
10) Enterprise Core (Billed through Azure) - Use pay-as-you-go billing through Azure.Надо просто выбрать число, никаких ключей вводить не надо (кроме 8 пункта). Для тестового стенда нам вполне подойдут варианты 1 или 2 для всех узлов. Также обратите внимание на описание отличий 6 и 7 выпуска. Поэтому если, к примеру, на сервере с 36 ядрами и 72 потоками вы хотите задействовать все ресурсы, то приобретайте лицензию Enterprise Core.
Если выберем один из платных выпусков, то конфигуратор поинтересуется, входит ли выбранный выпуск в приобретаемую программу обслуживания Microsoft Software Assurance.
Дальше стандартный вопрос о принятии лицензии.
Затем выбираем язык для SQL Server.
Теперь дважды вводим пароль SA.
Сервер сконфигурирован и запущен. Можем проверить:
# systemctl status mssql-server.serviceМожно включить SQL Server Agent, который необходим для выполнения запланированных заданий средствами самого SQL сервера, таких как: резервное копирование, обслуживание БД. Хотя можно выполнять все эти задания при помощи crontab, запускающего SQL скрипты посредством sqlcmd и снять эту обязанность с SQl agent. Как это сделать, вы узнаете, если прочтёте 2-й пункт (необязательный к прочтению для развёртывания тестового стенда). А пока включаем SQL Server Agent, т.к. он всё равно необходим для AlwaysON:
# /opt/mssql/bin/mssql-conf set sqlagent.enabled trueТакже добрый человек в комментариях посоветовал отключать сбор данных об использовании и данных диагностики:
# /opt/mssql/bin/mssql-conf set telemetry.customerfeedback falseДля применения изменений, перезапускаем службу SQL сервера:
# systemctl restart mssql-server.serviceОпционально устанавливаем пакет, предоставляющий компонент Full-text Search, позволяющий пользователям и приложениям выполнять полнотекстовые запросы к символьным данным в таблицах SQL Server:
# apt -y install mssql-server-ftsДля включения полнотекстового поиска также потребуется перезапустить службу SQL сервера.
Далее (тоже опционально) устанавливаем драйвер Microsoft ODBC и mssql-tools. Пакет mssql-tools содержит инструмент sqlcmd, позволяющий выполнять SQL запросы из командной строки, но он не будет работать без ODBC драйвера.
Добавляем репозиторий:
# curl https://packages.microsoft.com/config/debian/11/prod.list > /etc/apt/sources.list.d/mssql-release.listОбновляем список доступных пакетов и устанавливаем:
# apt update
# ACCEPT_EULA=Y apt install -y msodbcsql18 mssql-tools18Добавляем путь до бинарников mssql-tools в системную переменную PATH. У меня строчка добавления путей в переменную PATH находится в /etc/bash.bashrc. У Вас может находиться в ~/.bashrc, а по умолчанию она вообще не прописана в Debian в отличие от Ubuntu. Кто-то хранит эту переменную в /etc/environment или в ~/.profile или /etc/profile.d/.
# echo 'export PATH="$PATH:/opt/mssql-tools18/bin"' >> /etc/bash.bashrc
# source /etc/bash.bashrcЕсли вдруг кто не понял, зачем это надо, то это для того, чтобы находясь в любой директории, вы могли выполнить:
# sqlcmdА если не добавить путь /opt/mssql-tools18/bin в переменную PATH, то вам вместо этого придется вызывать sqlcmd по полному пути так:
# /opt/mssql-tools18/bin/sqlcmd2. Тюнинг производительности
Все действия производятся на узлах mssql-test-1 и mssql-test-2. Ничего тюнинговать на mssql-test-3 не нужно. Даже если вы будете развёртывать это в продакшн, то mssql-test-3 может быть обычной слабенькой виртуальной машиной.
Если вы просто хотите поднять тестовый кластер, чтобы попробовать, как это делается на Linux, то, вероятно, вам вообще не должно быть интересно, что описано в этом пункте. Можете прям смело пропускать этот пункт и переходить к настройке кластера. Интересен этот пункт тем, что содержит практические советы по оптимизации работы Microsoft SQL Server для работы с высоконагруженными информационными базами 1С.
Для начала надо снять ограничение на количество открытых файлов в ОС, если оно есть. Рекомендуемые от самих Microsoft значения: (soft 16000), (hard 32727).
Приводим к виду файл /etc/security/limits.d/99-mssql-server.conf:
mssql soft stack 8192
root soft stack 8192
mssql hard nofile 32727
mssql soft nofile 16000Для высоконагруженных Microsoft SQL серверов необходимо озаботиться настройкой BIOS сервера, сняв ограничения в основном экономии энергии, чтобы они не мешали работать процессору и памяти на максимальных частотах. Неплохо это описано тут на примере BIOS серверов Supermicro (кстати, на мой взгляд, самый функциональный и одновременно понятный серверный BIOS).
Далее снять все ограничения в самой ОС. Сделать это можно при помощи утилиты tuned.
Устанавливаем её:
# apt update
# apt install -y tuned tuned-utils tuned-utils-systemtapПроверяем название активного профиля (скорее всего по умолчанию будет balanced):
# tuned-adm activeСмотрим список доступных профилей производительности:
# tuned-adm listИ тут радуемся, потому что имеем профиль 'mssql'. Понимаем, что Microsoft позаботился о создании профиля оптимизации производительности системы. Вообще, в тяжелонагруженных серверах я всегда применял профиль 'throughput-performance' и даже сомневался, стоит ли применять профиль от Microsoft, но потом посмотрел содержимое файла /usr/lib/tuned/mssql/tuned.conf и понял, что применяется профиль 'throughput-performance', а уже поверх меняется незначительное количество специфических параметров для mssql.
Поэтому, смело применяем профиль 'mssql':
# tuned-adm profile mssqlНу и перезапустим все наши узлы для применения профилей tuned:
# rebootТакже стоит оговорить нюансы того, какую именно файловую систему выбрать для наших SQL серверов. Microsoft рекомендует XFS, также поддерживается EXT4 и это всё. Если кто-то очень любит BTRFS или ZFS, то самое время огорчиться. Также не получится разместить tempdb на RAM диске, созданном при помощи TMPFS. Но если очень прям хочется использовать ОЗУ для хранения tempdb, то выход вроде как есть. Создаём RAM диск при помощи TMPFS, на нём размещаем файл образа диска .img при помощи dd, создаём loopback устройство из нашего файла образа, создаём файловую систему XFS на loopback устройстве, ну и монтируем наше устройство куда хотим. Как это сделать, можно прочесть здесь.
Единственное, придётся сделать скрипт, выполняющий эти действия, и запускать его в виде systemd юнита при старте системы, а службу mssql сделать зависимой от запуска этого юнита. Тем самым нам таки удастся при помощи костылей разместить tempdb в оперативной памяти.
На сайте Гилева рекомендуют tempdb размещать на noRAID NVMe по типу супербыстрых Samsung 970/980/990. Что не лишено смысла, если у вашего сервера шина PCI-e 4-го ну или хотя бы 3-го поколения, которая способна пропускной способностью реализовать всё быстродействие этих SSD.
Если вы всё-таки решите ускорить свой сервер (а он реально ускорится) при помощи переноса tempdb на NVMe SSD, то делается это так.
Создаем точку монтирования:
# mkdir -p /database/tempdbСоздаем файловую систему на NVMe:
# mkfs.xfs /dev/nvme0n1 -K -f -L tempdbВыясняем ID нашего NVMe:
# blkid /dev/nvme0n1
/dev/nvme0n1: LABEL="tempdb" UUID="db0a867d-7bc6-4129-a1a6-c419b1534c9b" BLOCK_SIZE="512" TYPE="xfs"Добавляем строчку в /etc/fstab:
UUID="db0a867d-7bc6-4129-a1a6-c419b1534c9b" /database/tempdb xfs rw,attr2,noatime 0 0Монтируем:
# mount -aМеняем владельца директории:
# chown -R mssql: /database/tempdbВсе эти настройки актуальны и для отдельных дисков или массивов, предусмотренных для хранения ваших БД и их файлов журналов. Файловую систему для них создавайте с теми же параметрами, монтируете тоже. Вообще, базы отлично работают на SAS SSD массивах RAID5, а лучше RAID10 на дисках типа WD SS20 и подобных. Там скорость чтения и записи около 2000МБ/c, а в массиве и того больше. Также обращаем внимание на DWPD, у WD SS20 этот показатель доходит до 10 единиц. Диск или массив для размещения tempdb по рекомендациям Microsoft должен быть минимум в 2 раза быстрее дисков, на которых хранятся БД. В сети полно ресурсов, где бенчмарки и пользовательский опыт доказывают, что чем быстрее tempdb, тем в целом производительнее сервер SQL. Однако если Вы держите базу на медленных HDD дисках, то скорость tempdb не имеет такого решающего значения.
По умолчанию все базы, в том числе системные хранятся в /var/opt/mssql/data. Там же будут храниться и бэкапы по умолчанию, если не указывать путь резервного копирования.
Директорию хранения баз (.mdf), журналов (.ldf) и резервных копий (.bak) можно изменить при помощи следующих команд:
# /opt/mssql/bin/mssql-conf set filelocation.defaultdatadir /database/local
# /opt/mssql/bin/mssql-conf set filelocation.defaultlogdir /database/local
# /opt/mssql/bin/mssql-conf set filelocation.defaultbackupdir /database/backupsКонечно, если предварительно создать эти директории и назначить им владельца 'mssql:'
А весь список параметров с описанием можно посмотреть так:
# /opt/mssql/bin/mssql-conf list | moreПосмотреть внесенные изменения можно тут:
# cat /var/opt/mssql/mssql.confА вот переназначить хранение системных баз несколько сложнее. Нам нужно переназначить директорию хранения tempdb на быстрый диск. Рассмотрим.
Для того чтобы переназначить tempdb в другую директорию, нам нужно сформировать SQL скрипт. Для этого нам нужно выполнить запрос.Запрос прям из командной строки, т.к. не зря же мы ставили mssql-tools (обязательно с параметром -C (trust the server certificate) иначе получите ошибку проверки самоподписанного сертификата).параметр -Q выполнит запрос и выйдет, если выходить не надо, то следует использовать параметр -q.
Но директория хранения - это не всё важное, что касается tempdb. Хорошей практикой является планировать, сколько места будет занимать tempdb (по умолчанию это не ограничено). К примеру, у нас NVMe-диск объёмом 1ТБ, 8 файлов баз и 1 файл журнала. Мы без проблем можем позволить себе, чтобы каждый из этих файлов рос до 100ГБ.
Также существует параметр автоувеличения файлов по достижении размера. Хорошей практикой является выставлять шаг авторасширения побольше, чтобы файлы расширялись реже, т.к. во время авторасширения запросы к БД не выполняются. Логично предположить, что если информационные базы на сервере большие и работает с ними много народу, при стандартном шаге 64МБ сервер слишком часто будет отвлекаться на авторасширение tempdb. Также стоит отметить и обратную сторону, когда она расширяется на больший шаг, расширение занимает больше времени, но это всё равно меньшее из двух зол.
Итого:
размещаем все файлы tempdb в
/database/tempdb;начальным размером для всех файлов tempdb будет 10ГБ (SIZE=10GB);
порог авторасширения будет равен 1ГБ (FILEGROWTH=1GB);
максимальный размер каждого файла будет ограничен 100ГБ (MAXSIZE=100GB).
Формируем скрипт SQL запросом:
# sqlcmd -o /tmp/tempdb.sql -C -S localhost -Usa -Q "SELECT 'ALTER DATABASE tempdb MODIFY FILE (NAME='+[name]+', SIZE=10GB, MAXSIZE=100GB , FILEGROWTH=1GB, FILENAME='+[physical_name]+')' FROM sys.master_files WHERE database_id = DB_ID(N'tempdb');"Данный запрос сформировал очень сырой SQL скрипт. Удаляем из него пробелы и прочий мусор и добавляем GO после каждой строки:
# sed -i -e 's/^[ \t]*//g' -e 's/[ \t]*$//g' -e 's/^[-]*//g' -e '/^$/d' -e '$d' -i -e '/[)]*$/ a GO' /tmp/tempdb.sqlДобавляем первой строкой 'USE master', а второй 'GO':
# sed -i '1i USE master\nGO' /tmp/tempdb.sqlЭкранируем пути к файлам или получим ошибку 'Неправильный синтаксис около конструкции "/"':
# sed -i -e 's/FILENAME=/FILENAME='"'"'/g' /tmp/tempdb.sql
# sed -i -e 's/df/df'"'"'/g' /tmp/tempdb.sqlТеперь определяем переменной новый путь, в котором собираемся хранить tempdb:
# export TEMPDBPATH="/database/tempdb"Ну и теперь в нашем SQL скрипте меняем старый путь на новый:
# sed -i -e "s|/var/opt/mssql/data|$TEMPDBPATH|g" /tmp/tempdb.sqlПометка для гуру awk и sed. Уверен, что можно с меньшим количеством команд сделать все манипуляции по созданию скрипта, но мне лень было долго сидеть. Если напишете в комментариях однострочник, который всё это сделает, то честь вам и хвала.
Должно получиться вот так:
# cat /tmp/tempdb.sql
USE master
GO
ALTER DATABASE tempdb MODIFY FILE (NAME=tempdev, SIZE=10GB, MAXSIZE=100GB , FILEGROWTH=1GB, FILENAME='/database/tempdb/tempdb.mdf')
GO
ALTER DATABASE tempdb MODIFY FILE (NAME=templog, SIZE=10GB, MAXSIZE=100GB , FILEGROWTH=1GB, FILENAME='/database/tempdb/templog.ldf')
GO
ALTER DATABASE tempdb MODIFY FILE (NAME=tempdev2, SIZE=10GB, MAXSIZE=100GB , FILEGROWTH=1GB, FILENAME='/database/tempdb/tempdb2.ndf')
GO
ALTER DATABASE tempdb MODIFY FILE (NAME=tempdev3, SIZE=10GB, MAXSIZE=100GB , FILEGROWTH=1GB, FILENAME='/database/tempdb/tempdb3.ndf')
GO
ALTER DATABASE tempdb MODIFY FILE (NAME=tempdev4, SIZE=10GB, MAXSIZE=100GB , FILEGROWTH=1GB, FILENAME='/database/tempdb/tempdb4.ndf')
GO
ALTER DATABASE tempdb MODIFY FILE (NAME=tempdev5, SIZE=10GB, MAXSIZE=100GB , FILEGROWTH=1GB, FILENAME='/database/tempdb/tempdb5.ndf')
GO
ALTER DATABASE tempdb MODIFY FILE (NAME=tempdev6, SIZE=10GB, MAXSIZE=100GB , FILEGROWTH=1GB, FILENAME='/database/tempdb/tempdb6.ndf')
GO
ALTER DATABASE tempdb MODIFY FILE (NAME=tempdev7, SIZE=10GB, MAXSIZE=100GB , FILEGROWTH=1GB, FILENAME='/database/tempdb/tempdb7.ndf')
GO
ALTER DATABASE tempdb MODIFY FILE (NAME=tempdev8, SIZE=10GB, MAXSIZE=100GB , FILEGROWTH=1GB, FILENAME='/database/tempdb/tempdb8.ndf')
GOЗапускаем наш скрипт:
# sqlcmd -i /tmp/tempdb.sql -C -S localhost -UsaТут внимательно. При первом изменении размера и местоположения журнала templog.ldf сервер призадумывается. То есть выполняет один запрос первый, пишет: "Файл "tempdev" был изменён в системном каталоге. Данный новый путь будет использован при следующем запуске этой базы данных". И думает. Не паникуем, ничего не нажимаем. Так и должно быть. Ждать минут 5.
Перезапустим службу:
# systemctl restart mssql-server.serviceТеперь можно удалить все файлы tempdb, которые остались в директории по умолчанию:
# rm -rf /var/opt/mssql/data/temp*Ну и можно удалить наш скрипт:
# rm -rf /tmp/tempdb.sqlТеперь tempdb находится на быстром NVMe-диске.
Что касается других параметров, которые стоит оговорить, то этими параметрами будут 'max/min server memory' и 'max degree of parallelism'. Рассмотрим их подробнее.
'max/min server memory' — это минимальное и максимальное количество оперативной памяти, потребляемое экземпляром Microsoft SQL Server. Тут всё просто, если сервер исключительно SQL, то мы оставляем для ОС Windows 6–10ГБ ОЗУ, а всё остальное отдаём Microsoft SQL Server. Если на этом сервере также развёрнута роль сервера 1С-Предприятие или ещё чего хуже сервера терминалов, то подбираем значение эмпирически, вроде даже где-то есть формула какая-то.Но в данном гайде речь идёт про Linux, поэтому, скорее всего, можно делать вывод, что по соседству на этой же ОС нет сервера 1С, потому что это бессмысленно, т. к. Linux-версия сервера 1С не умеет работать с Microsoft SQL (что очень печально). Наличие на той же ОС терминального сервера ещё менее вероятно. Учитывая, что Linux без среды рабочего стола куда менее прожорлив, нежели Windows Server, оставляем самой ОС 4ГБ, а всё остальное смело отдаём Microsoft SQL. Минимальное количество мы не ограничиваем, ибо не видим смысла, но вы можете, если хотите. Настроить 'max server memory' легко из SSMS, провалившись в свойства сервера, но если вы прям сильно хотите, то можете это сделать при помощи SQL запроса так:
sp_configure 'show advanced options', 1;
GO
RECONFIGURE;
GO
sp_configure 'max server memory', 4096;
GO
RECONFIGURE;
GOЗначение в мегабайтах.
Посмотреть установленное значение можно следующим SQL запросом:
SELECT c.value, c.value_in_use
FROM sys.configurations c WHERE c.[name] = 'max server memory (MB)'
GO'max degree of parallelism' — это максимальная степень параллелизма. Вообще 1С в общих случаях рекомендует выставлять это значение в '1', с этим можно ознакомиться тут, но эмпирическим путём мы выяснили, что это совершенно не лучший способ поднять производительность. Если у вас много небольших (быстрых) запросов, то значение '1' возможно как-то и удовлетворит ваши потребности, но если запросы «жирные», то лучше бы серверу обрабатывать их параллельно. Подбираем его эмпирически. На одном сервере с двумя процессорами E5-2697 v4 и быстрой дисковой подсистемой, на котором развёрнута очень большая информационная база, нами было подобрано значение '10', с которым сервер работал быстрее. Поменять настройку можно из SSMS, провалившись в свойства сервера, но если вы прям сильно хотите, то можете это сделать при помощи SQL запроса так:
EXEC sp_configure 'show advanced options', 1;
GO
RECONFIGURE WITH OVERRIDE;
GO
EXEC sp_configure 'max degree of parallelism', 16;
GO
RECONFIGURE WITH OVERRIDE;
GO3. Установка и настройка кластера
Для начала приводим к следующему общему виду файл /etc/hosts на всех узлах кластера:
127.0.0.1 localhost
10.10.2.228 mssql-test-1
10.10.2.229 mssql-test-2
10.10.2.240 mssql-test-3
10.10.2.18 list-ag1
10.10.2.19 list-ag2Теперь включаем функционал высокой доступности и аварийного восстановления (High-Availability and Disaster Recovery) на экземпляре Microsoft SQL Server на всех узлах кластера:
# /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
# systemctl restart mssql-server.serviceУстанавливаем необходимые пакеты на всех узлах кластера:
# apt update
# apt install -y pacemaker pacemaker-cli-utils crmsh resource-agents fence-agents csync2 python3-azure pcsЗадаем одинаковый пароль пользавателю hacluster на всех узлах:
# passwd haclusterГенерируем ключ аутентификации corosync на первом узле кластера:
# corosync-keygenПередаем сгенерированный ключ на второй и третий узел кластера:
# scp /etc/corosync/authkey root@mssql-test-2:/etc/corosync
# scp /etc/corosync/authkey root@mssql-test-3:/etc/corosyncТеперь поговорим о кворуме. Кворум - это когда кластер имеет достаточное количество исправных узлов для дальнейшей работы.
Кворум определяется по формуле:
где n – количество исправных узлов, N – общее количество узлов в кластере.Понимаем, что для соблюдения кворума нужно, чтобы количество исправных узлов было больше (а не больше или равно) половины всех узлов кластера. Если у нас 3 узла в кластере и один из них вышел из строя, то кластер имеет кворум. А если у нас два узла, как в нашем случае, то при выходе из строя одного из них, количество исправных узлов кластера будет равным половине от общего числа узлов кластера. Этого недостаточно для кворума, поэтому кластер остановит ресурсы. Чтобы этого не допустить на кластере, состоящем из двух узлов, рекомендуется включить настройку игнорирования кворума. Делается это так:
# crm configure property no-quorum-policy=ignoreНо можно поднять третий узел, к примеру, на небольшой виртуальной машине с экземпляром Microsoft SQL этот узел будет выступать в роли "голосующего".Вот мы и пошли вторым более правильным путём.
Приводим к виду конфигурацию кластера /etc/corosync/corosync.conf на первом узле кластера:
totem {
version: 2
cluster_name: mssql-test-cluster
transport: udpu
crypto_cipher: none
crypto_hash: none
}
logging {
fileline: off
to_stderr: yes
to_logfile: yes
logfile: /var/log/corosync/corosync.log
to_syslog: yes
debug: off
logger_subsys {
subsys: QUORUM
debug: off
}
}
quorum {
provider: corosync_votequorum
}
nodelist {
node {
name: mssql-test-1
nodeid: 1
ring0_addr: 10.10.2.228
}
node {
name: mssql-test-2
nodeid: 2
ring0_addr: 10.10.2.229
}
node {
name: mssql-test-3
nodeid: 3
ring0_addr: 10.10.2.240
}
}Передаем конфигурацию на второй и третий узел кластера:
# scp /etc/corosync/corosync.conf root@mssql-test-2:/etc/corosync
# scp /etc/corosync/corosync.conf root@mssql-test-3:/etc/corosyncПерезапускаем pacemaker и corosync на всех узлах кластера:
# systemctl restart pacemaker corosyncПроверим состояние кластера:
# crm status
4. Подготовка к созданию групп доступности
Для начала установим компонент mssql-server-ha на всех узлах кластера:
# apt install -y mssql-server-haТеперь добавим пользователя pacemaker как имя входа Microsoft SQL. Для этого на каждом узле выполняем SQL запрос:
USE [master]
GO
CREATE LOGIN [pacemakerLogin] with PASSWORD= N'ComplexP@$$w0rd!';
ALTER SERVER ROLE [sysadmin] ADD MEMBER [pacemakerLogin];
GOТеперь на всех узлах кластера создаем файл, содержащий учетные данные с которыми pacemaker сможет подключиться к экзепляру Microsoft SQL:
# echo 'pacemakerLogin' >> /var/opt/mssql/secrets/passwd
# echo 'ComplexP@$$w0rd!' >> /var/opt/mssql/secrets/passwd
# chown root:root /var/opt/mssql/secrets/passwd
# chmod 400 /var/opt/mssql/secrets/passwdТеперь включаем на всех узлах кластера AlwaysOn_health extended event session (сеанс расширенных событий). На каждом узле кластера выполняем SQL запрос:
ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE=ON);
GOСоздаем мастер-ключ, сертификат и резервную копию сертификата на первом узле кластера:
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'Parol@123';
GO
CREATE CERTIFICATE sqllinuxdb_certificate WITH SUBJECT = 'sqllinuxdb_certificate';
GO
BACKUP CERTIFICATE sqllinuxdb_certificate
TO FILE = '/var/opt/mssql/data/sqllinuxdb_certificate_certificate.cer'
WITH PRIVATE KEY (
FILE = '/var/opt/mssql/data/sqllinuxdb_certificate_certificate.pvk',
ENCRYPTION BY PASSWORD = 'Parol@123'
);После выполнения запроса в директории '/var/opt/mssql/data' появятся два файла:
sqllinuxdb_certificate_certificate.cer
sqllinuxdb_certificate_certificate.pvk
Нам надо передать их на второй и третий узел кластера:
# scp /var/opt/mssql/data/sqllinuxdb_certificate_*.* root@mssql-test-2:/var/opt/mssql/data
# scp /var/opt/mssql/data/sqllinuxdb_certificate_*.* root@mssql-test-3:/var/opt/mssql/dataТеперь меняем владельца этих двух файлов на втором и третьем узле кластера:
# chown mssql: /var/opt/mssql/data/sqllinuxdb_certificate_*.*Теперь на втором и третьем узле кластера создаем сертификат при помощи только что перемещенных файлов. Для этого выподняем SQL запрос:
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'Parol@123';
GO
CREATE CERTIFICATE sqllinuxdb_certificate
FROM FILE = '/var/opt/mssql/data/sqllinuxdb_certificate_certificate.cer'
WITH PRIVATE KEY (
FILE = '/var/opt/mssql/data/sqllinuxdb_certificate_certificate.pvk',
DECRYPTION BY PASSWORD = 'Parol@123'
);Создаем конечные точки аварийного восстановления высокой доступности - HADR (High availability disaster recovery) endpoints. Для этого на всех узлах выполняем запрос:
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE sqllinuxdb_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;5. Создание групп доступности AlwaysON
Теперь на первом узле кластера создаем группу доступности AlwaysON (ag1), при этом сразу инициализируем всех членов группы. Делается это при помощи запроса:
CREATE AVAILABILITY GROUP [ag1]
WITH (CLUSTER_TYPE = EXTERNAL)
FOR REPLICA ON
N'mssql-test-1' WITH (
ENDPOINT_URL = N'tcp://mssql-test-1:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'mssql-test-2' WITH (
ENDPOINT_URL = N'tcp://mssql-test-2:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'mssql-test-3' WITH (
ENDPOINT_URL = N'tcp://mssql-test-3:5022',
AVAILABILITY_MODE = CONFIGURATION_ONLY
);
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE;Теперь присоединяем второй узел к этой группе доступности (ag1) и разрешаем создавать БД. Для этого на втором узле кластера выполняем запросы:
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = EXTERNAL);
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE;А на третьем выполняем только первый из запросов:
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = EXTERNAL);Теперь на втором узле кластера создаем группу доступности AlwaysON (ag2), при этом сразу инициализируем всех членов группы. Делается это при помощи запроса:
CREATE AVAILABILITY GROUP [ag2]
WITH (CLUSTER_TYPE = EXTERNAL)
FOR REPLICA ON
N'mssql-test-2' WITH (
ENDPOINT_URL = N'tcp://mssql-test-2:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'mssql-test-1' WITH (
ENDPOINT_URL = N'tcp://mssql-test-1:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'mssql-test-3' WITH (
ENDPOINT_URL = N'tcp://mssql-test-3:5022',
AVAILABILITY_MODE = CONFIGURATION_ONLY
);
ALTER AVAILABILITY GROUP [ag2] GRANT CREATE ANY DATABASE;Теперь присоединяем первый узел к этой группе доступности (ag2) и разрешаем создавать БД. Для этого на первом узле кластера выполняем запросы:
ALTER AVAILABILITY GROUP [ag2] JOIN WITH (CLUSTER_TYPE = EXTERNAL);
ALTER AVAILABILITY GROUP [ag2] GRANT CREATE ANY DATABASE;А на третьем выполняем только первый из запросов:
ALTER AVAILABILITY GROUP [ag2] JOIN WITH (CLUSTER_TYPE = EXTERNAL);В результате создания групп доступности ag1 и ag2 должно получиться примерно так, как на скриншоте ниже.

6. Создание баз данных
Создаём или восстанавливаем из резервной копии БД на первом узле кластера. Модель восстановления базы данных обязательно должна быть полная для добавления в БД в группу доступности. Поэтому обязательно проверяем в параметрах БД модель восстановления и при необходимости переключаем в "Полная". Теперь обязательно надо сделать бэкап базы. Не для безопасности (хотя и для неё тоже), а потому что без бэкапа она просто не добавится в группу доступности. Выполняем SQL запрос на первом узле кластера
backup database test-db-1 to disk='test-db-1.bak'Добавляем БД в группу доступности ag1, выполнив SQL запрос на первом узле кластера:
ALTER AVAILABILITY GROUP [AG1] ADD Database [test-db-1];Проделываем все теже действия, но теперь на втором узле кластера и для БД test-db-2. Добавляем БД в группу доступности ag2, выполнив SQL запрос на втором узле кластера:
ALTER AVAILABILITY GROUP [AG2] ADD Database [test-db-2];7. Создание ресурсов групп доступности в Pacemaker
Перед созданием первого ресурса, рекомендуется отключить STONITH, для этого на первом узле выполним:
# crm configure property stonith-enabled=falseВ дальнейшем будут выводится предупреждения, связанные с этим, которые можно игнорировать. Выглядят они так: warning: Blind faith: not fencing unseen nodes Кластер предупреждает нас, что мы никак не ограждаем отказавшие узлы. Мы обсудим STONITH немного позже.
Создаем ресурс группы доступности ag1 в pacemaker. Для этого выполняем:
# crm
configure
primitive ag1_cluster \
ocf:mssql:ag \
params ag_name="ag1" \
meta failure-timeout=60s \
op start timeout=60s \
op stop timeout=60s \
op promote timeout=60s \
op demote timeout=10s \
op monitor timeout=60s interval=10s \
op monitor timeout=60s on-fail=demote interval=11s role="Master" \
op monitor timeout=60s interval=12s role="Slave" \
op notify timeout=60s
ms ms-ag1 ag1_cluster \
meta master-max="1" master-node-max="1" clone-max="3" \
clone-node-max="1" notify="true"
commit
quitДля просмотра ресурса ms-ag1 выполним:
# crm resource status ms-ag1
resource ms-ag1 is running on: mssql-test-1 Master
resource ms-ag1 is running on: mssql-test-2
resource ms-ag1 is running on: mssql-test-3Создаем ресурс группы доступности ag2 в pacemaker. Для этого выполняем:
# crm
configure
primitive ag2_cluster \
ocf:mssql:ag \
params ag_name="ag2" \
meta failure-timeout=60s \
op start timeout=60s \
op stop timeout=60s \
op promote timeout=60s \
op demote timeout=10s \
op monitor timeout=60s interval=10s \
op monitor timeout=60s on-fail=demote interval=11s role="Master" \
op monitor timeout=60s interval=12s role="Slave" \
op notify timeout=60s
ms ms-ag2 ag2_cluster \
meta master-max="1" master-node-max="1" clone-max="3" \
clone-node-max="1" notify="true"
commit
quitДля просмотра ресурса ms-ag2 выполним:
# crm resource status ms-ag2
resource ms-ag2 is running on: mssql-test-1
resource ms-ag2 is running on: mssql-test-2 Master
resource ms-ag2 is running on: mssql-test-3Также можем проверить статус кластера:
# crm status8. Создание прослушивателей групп доступности
Создаем прослушиватель группы доступности ag1 в pacemaker, выполняя:
# crm configure primitive list-ag1 \
ocf:heartbeat:IPaddr2 \
params ip=10.10.2.18И теперь создаем прослушиватель группы доступности ag1 в самом SQL, выполнив запрос на первом узле:
ALTER AVAILABILITY GROUP [ag1] ADD LISTENER N'list-ag1' (
WITH IP
((N'10.10.2.18', N'255.255.255.0')), PORT=1433);
GOСоздаем прослушиватель группы доступности ag2 в pacemaker, выполняя:
# crm configure primitive list-ag2 \
ocf:heartbeat:IPaddr2 \
params ip=10.10.2.19И теперь создаем прослушиватель группы доступности ag1 в самом SQL, выполнив запрос на втором узле:
ALTER AVAILABILITY GROUP [ag2] ADD LISTENER N'list-ag2' (
WITH IP
((N'10.10.2.19', N'255.255.255.0')), PORT=1433);
GOТеперь мы можем подключаться к группам доступности по IP адресу или имени прослушивателя, если добавлена A запись в DNS предприятия.
9. Связывание ресурсов групп доступности и прослушивателей
Теперь чтобы гарантировать, что ресурсы группы доступности ag1 и прослушивателя list-ag1 pacemaker всегда работают на одном и том же сервере в кластере, нам надо связать ресурсы ms-ag1 и list-ag1, чтобы они не могли отдельно друг от друга переключиться на другой узел. Для этого выполним:
# crm configure colocation ag1-with-listener INFINITY: list-ag1 ms-ag1:MasterТеперь виртуальный IP прослушивателя всегда будет работать на сервере, который является основным узлом в группе доступности.
Чтобы при отработке отказа группа доступности ag1 перешла в оперативный режим на новом первичном сервере, выполним:
# crm configure order ag1-before-listener Mandatory: ms-ag1:promote list-ag1:startНу и теперь нам необходимо сделать так, чтобы переключение MASTER на третий узел осуществлялось в самую последнюю очередь. Сначала посмотрим какие приоритеты для этого ресурса существуют по умолчанию:
# crm_simulate -sL | grep "ms-ag1" | grep "alloc"
pcmk__clone_allocate: ms-ag1 allocation score on mssql-test-1: INFINITY
pcmk__clone_allocate: ms-ag1 allocation score on mssql-test-2: 0
pcmk__clone_allocate: ms-ag1 allocation score on mssql-test-3: 0Видим, что максимальный приоритет у узла mssql-test-1, т.к. равен бесконечности, а вот два остальные узла имеют равный приоритет. Это значит что при выходе из строя mssql-test-1, кластер наобум выберет из двух живых узлов, куда переместить роль MASTER. Но на mssql-test-3 нет базы, значит и перемещать туда ничего не надо. Поэтому мы поднимем приоритет mssql-test-2 выше нуля:
# crm configure location loc-ag1 ms-ag1 100: mssql-test-2Проверим заново:
# crm_simulate -sL | grep "ms-ag1" | grep "alloc"
pcmk__clone_allocate: ms-ag1 allocation score on mssql-test-1: INFINITY
pcmk__clone_allocate: ms-ag1 allocation score on mssql-test-2: 100
pcmk__clone_allocate: ms-ag1 allocation score on mssql-test-3: 0Кстати, все это еще можно сделать из web-интерфейса, который находится на порту 2224 (HTTPS) на всех узлах кластера. Для входа используется учетная запись "hacluster", а пароль мы устанавливали в данном гайде выше. Выглядит это все так:

Связываем ресурсы группы доступности ag2 и прослушивателя list-ag2. Для этого выполняем:
# crm configure colocation ag2-with-listener INFINITY: list-ag2 ms-ag2:MasterТеперь виртуальный IP прослушивателя всегда будет работать на сервере, который является основным узлом в группе доступности.
Чтобы при отработке отказа группа доступности ag2 перешла в оперативный режим на новом первичном сервере, выполним:
# crm configure order ag2-before-listener Mandatory: ms-ag2:promote list-ag2:startНу и теперь нам необходимо сделать так, чтобы переключение MASTER на третий узел осуществлялось в самую последнюю очередь. Делаем все тоже самое, что и для ms-ag1, только теперь поднимаем приоритет для mssql-test-1:
# crm configure location loc-ag2 ms-ag2 100: mssql-test-1Теперь можем проверить как это выглядит:
# crm status
10. Обработка отказа
Так как тип кластера группы доступности AlwaysON внешний, мы не сможем запустить обработку отказа при помощи SSMS или посредством выполнения SQL запроса. В данном случае обработка отказа производится средствами pacemaker. Для того чтобы переключить ресурс группы доступности ms-ag1 на второй узел mssql-test-2, чтобы последний занял место MASTER, выполним:
# crm resource move ms-ag1 mssql-test-2Выжидаем минутку (переключение не мгновенное) и проверяем:
# crm status
Вот так это выглядит в SSMS:

Как мы видим ресурс ms-ag1 перешел на mssql-test-2, а вместе с ним перешел и ресурс list-ag1 потому что ранее мы их связали друг с другом. Это была обработка отказа, выполненная вручную.
Давайте переключим ресурс обратно:
# crm resource move ms-ag1 mssql-test-1Немного подождём, пока пройдут все переключения и попробуем проверить, как работает не ручная, а автоматическая (аварийная) обработка отказа. Для этого просто выключим второй узел командой:
# shutdown -h nowНу и обождав немного проверим:
# crm status
Как видим, все отработало штатно. Роль мастера перешла узлу mssql-test-1.
11. Настройка fencing (STONISH)
Пришло время настройки STONITH, который мы отключили в самом начале создания кластера.
STONITH (Shoot The Other Node In The Head) метод изоляции отказавшего узла. STONITH изолирует неисправные узлы, перезагружая или отключая неисправный узел, чтобы он не вызывал нарушения работы кластера. Вот тут отличная статья на Хабре, где даже заголовок "Как добить лежачего" лаконично точно и с юмором передает суть STONITH.
Вообще, в данном конкретном случае фенсинг, в общем-то, и не нужен. Чаще всего он применяется на кластерах, узлы которых монопольно используют какой-нибудь общий ресурс. Например, ISCSI. Также стоит помнить о подводных камнях. К примеру, вот мы решили обслужить один из серверов в кластере, выполнили вручную обработку отказа, переключив обслуживаемый сервер в SLAVE для всех важных ресурсов. Останавливаем службу mssql, начинаем обновлять пакеты, узел переходит в аварийное состояние, срабатывает таймаут фенсинга и узел перезагружается или выключается прямо во время обновления. Поэтому стоит либо увеличивать время таймаута, либо отключать механизм ограждения во время регламентных работ с узлом. В данном конкретном гайде настройка STONISH скорее имеет цель демонстрации возможностей, нежели практической необходимости.
Посмотреть весь список доступных ресурсов фенсинга можно так:
# crm ra list stonithТут есть и IPMI и возможность взаимодействия с проприетарными веб-мордами брендовых серверов таких как: ilo, imm, drac, и прочие. Есть возможность взаимодействия с API популярных гипервизоров и систем контейнеризации таких как: pve, xenapi, vbox, azure, vmware, libvirt, docker и т.д. Можно даже добить узел, отдав команду ИБП, к которому он подключён, если, конечно, этот ИБП есть в списке поддерживаемых, но на крайний случай можно отдать команду NUT, а тот "погасит" ИБП отказавшего узла.
Конкретно в данном случае узлы являются виртуальными машинами XCP-NG (Свободный аналог Citrix XenServer), который точно также использует XenAPI для управления виртуальными машинами. В списке доступных ресурсов он значится как 'fence_xenapi'.
Ознакомимся с полным списком параметров этого ресурса:
# crm ra info stonith:fence_xenapiЧтобы выйти из режима просмотра параметров нажмите 'q'.
Создаем ресурс stonish для mssql-test-1:
# crm configure primitive mssql-test-1.stonish stonith:fence_xenapi \
params \
username="root" \
password="очень сложный пароль" \
session_url="http://IP гипервизора" \
plug="8d5140e9-9a20-f2a0-e712-1dee4fbdf067" \
pcmk_host_list=mssql-test-1Создаем ресурс stonish для mssql-test-2:
# crm configure primitive mssql-test-2.stonish stonith:fence_xenapi \
params \
username="root" \
password="очень сложный пароль" \
session_url="http://IP гипервизора" \
plug="8d5140e9-9a20-f2a0-e712-1dee4fbdf067" \
pcmk_host_list=mssql-test-2После создания ресурсов stonish для каждого узла, необходимо настроить их таким образом, чтобы они не запускались на тех узлах, для перезагрузки которых они созданы.
# pcs constraint location mssql-test-1.stonish avoids mssql-test-1=INFINITY
# pcs constraint location mssql-test-2.stonish avoids mssql-test-2=INFINITYНу и включаем STONISH:
# crm configure property cluster-recheck-interval=2min
# crm configure property start-failure-is-fatal=true
# crm configure property stonith-timeout=60
# crm configure property stonith-action=reboot
# crm configure property concurrent-fencing=true
# crm configure property stonith-enabled=trueЧтобы проверить, что ресурс STONISH работает как надо:
# stonith_admin -t 20 --reboot mssql-test-2И если на кластере есть ресурс, который предназначен для управления узлом mssql-test-2, то виртуальная машина уйдет в перезагрузку.
Вот в принципе и все что хотелось рассказать о создании отказоустойчивого кластера для групп доступности AlwaysON.
Комментарии (10)


DonAlPAtino
08.06.2023 22:33Вопрос - а 1С с MS SQL под Linux кто-нибудь тестировал под нагрузкой? Овчинка выделки-то стоит? Или это скорее академический интерес?

Jedi-Knight Автор
08.06.2023 22:33Тестировали и под нагрузкой и бенчмарками типа теста Гилева. Ничуть не хуже работает, чем Windows версия. В тестах Гилева переход на Linux на том же железе даёт небольшой прирост в 2-3 единицы условные, учитывая что на Windows все процедуры оптимизации рекомендуемые также были проделаны. В продакшн вообще не заметили разницы. Все работает штатно. Академический интерес в отрыве от практического применения не имеет никакого смысла. Поэтому в статье и затронуты моменты оптимизации работы под 1С. Можете смело развертывать в продакшн. Причем мы прям сразу попробовали именно две огромные информационные базы пересадить на Linux. Никаких сожалений не испытываем.
Johan_Palych
Спасибо!. Интересно было почитать.
Очень против такого: apt install -y. Не надо со всем соглашаться - можно случайно поставить пол Gnome-a или KDE
В конце прошлого года разворачивал стенд с mssql-server-2022 на Вullseye
Репы Ubuntu 20.04 LTS (Focal Fossa) совместимы с Debian 11 Вullseye
В Ubuntu 20.04: cat /etc/debian_version > bullseye/sid
Настройка сбора данных об использовании и данных диагностики для SQL Server на Linux. Всегда делаю так:
sudo /opt/mssql/bin/mssql-conf set telemetry.customerfeedback false
sudo systemctl restart mssql-server
Есть Azure Data Studio. Скачивание и установка Azure Data Studio:
Jedi-Knight Автор
Пожалуйста!
Ой, да не драматизируйте. Не пугайте тут народ, как в одном чёрном-чёрном городе, в чёрном-чёрном доме, в чёрной-чёрной квартире один мальчик устанавливал Midnight Commander, а у него установился Gnome. И теперь этот мальчик бродит по ночам и ищет мейнтейнера, который виновен в этом, но на всякий случай убивает всех, кого встретит. Боитесь зависимостей бинарных пакетов - собирайте всё из исходников. Это не FreeBSD, где порт можно полностью сконфигурировать и все его зависимости и зависимости его зависимостей. Печально ли это? Да. Но от зависимостей никуда не денетесь. Вы же не слепой, видите, что устанавливается. Не нравится вам, переходите на другой дистрибутив или другой репозиторий или собирайте из исходников. Конкретно в этом случае, ничего лишнего не установилось. Поэтому ИМЕННО тут и написано '-y'. Слишком мнительные люди могут не ставить '-y', разархивировать пакет, декомпилировать бинарники, изучить их, а то вдруг там код отличается от того, который доступен открытым для этого бинарника. Зависимостей бояться - в .deb не ходить. :)
Про отключение сбора данных добавлю в статью. Спасибо! Это полезно.
Azure Data Studio мне не зашёл. Вроде всё удобнее делать в SSMS из того, что мне надо.
Johan_Palych
Лучше бы мальчик почитал хорошие книжки:
Настольная книга администратора Debian
https://www.debian.org/doc/manuals/debian-handbook/index.ru.html
apt install -s mssql-server
-s, --simulate:Не выполнять никаких действий; выполняет симуляцию событий, который должны происходить, но которые реально не будут выполнены и не изменят состояние системы.
sudo apt install mssql-server
sudo apt install --no-install-recommends mssql-server
sudo apt install --install-recommends mssql-server
Печали нет. И есть py-pymssql Python database interface for MS-SQL. Version 2
Jedi-Knight Автор
Как встретите его, обязательно ему посоветуйте. А лучше напишите статью об этом. Призовите всех неразумных, рискующих поставить себе половину GNOME и KDE быть аккуратнее. Но моя статья не об этом, увы...
Тут вообще не понял к чему мне ссылка на порт FreeBSD с интерфейсом MSSQL, написанном на Python в контексте моих сожалений, что коллекции портов с исходниками не получили достаточного распространения в мире Linux (хоть я и понимаю причины этого). У Вас там своя атмосфера какая-то.
Johan_Palych
There was neither good nor bad there. Засим разрешите откланяться.
Богатая документация на аглицком:
https://github.com/MicrosoftDocs/sql-docs/tree/live/docs/linux
Failover Cluster Instances - SQL Server on Linux
https://github.com/MicrosoftDocs/sql-docs/blob/live/docs/linux/sql-server-linux-shared-disk-cluster-concepts.md
Configure failover cluster instance - iSCSI - SQL Server on Linux
https://github.com/MicrosoftDocs/sql-docs/blob/live/docs/linux/sql-server-linux-shared-disk-cluster-configure-iscsi.md
Configure failover cluster instance - NFS - SQL Server on Linux
https://github.com/MicrosoftDocs/sql-docs/blob/live/docs/linux/sql-server-linux-shared-disk-cluster-configure-nfs.md
Configure failover cluster instance - SMB - SQL Server on Linux
https://github.com/MicrosoftDocs/sql-docs/blob/live/docs/linux/sql-server-linux-shared-disk-cluster-configure-smb.md
Jedi-Knight Автор
Разрешаем)