
Привет, Хабр! Меня зовут Михаил, я backend-разработчик в SimbirSoft. Время от времени я сталкиваюсь с понятием «двоичный», он же «бинарный» интерфейс приложений, или просто ABI (application binary interface). Все найденные мной материалы на эту тему были либо очень скудны, либо вели к многостраничным эпопеям, которые напоминали сборную солянку из описания, например, архитектуры процессора x86, сдобренную стандартом С++.
Но потом я наткнулся на перевод публикации Тита Винтерса в рабочей группе 21 (WG21) — комитета по стандартизации языка C++. В ней он поднимает вопрос поддержки обратной бинарной совместимости. Значит, вопрос актуальный — это и стало мотивацией для написания этой статьи. В ней я сфокусируюсь на примерах и практике использования С++ в других языках программирования. Материал будет полезен middle+ и senior-разработчикам, а также всем, кто хочет сделать гибкий, долгоживущий, легко настраиваемый под заказчика продукт.
Так что заваривайте чай, запасайтесь быстрыми углеводами — вас ждёт увлекательное погружение в мир низкоуровневого программирования. Начнём с теории, затем рассмотрим несколько практических примеров.

Пишем модуль на С++ и применяем его в других языках
ABI — это набор соглашений, которые описывают двоичный интерфейс приложения. В частности, он регламентирует использование стека и регистров процессора, порядок передачи аргументов и возвращаемого значения для функций, размеры базовых типов и многое другое. В целом, ABI описывает детали реализации взаимодействия приложений между собой и между операционной системой (платформой).
Для каждого языка программирования определён свой ABI, но некоторые вещи характерны для всех языков. Например, как компилятор формирует код вызова функции? В ассемблере есть команда CALL, которая передаёт управление подпрограмме (функции), запоминая при этом в стеке смещение к точке возврата. В конце, функция исполняет инструкцию, которая извлекает этот сохранённый адрес из стека обратно, и процессор продолжает исполнять программу именно с этого адреса.
Но если вызов для всех языков осуществляется одинаково, то далее возможны существенные различия. Ведь кроме вызова самой функции, в нее часто необходимо передать различные параметры. Казалось бы, ничего особенного, но нет. Параметры, передаваемые функции, можно положить сразу в регистр, а можно отправить в стек. Общепринятым соглашением считается передача всех параметров именно через стек.
Но и здесь не всё так однозначно — можно ведь отправлять, начиная с последнего переданного параметра, а можно и наоборот. И первым в стек или регистр (это уже зависит от реализации) полетит первый переданный в функцию. К тому же, необходимо позаботиться и об удалении элементов из стека: кто это будет делать — вызывающий или вызываемый? Чаще всего удалением занимается вызываемый, но это не всегда так. Например, в языке С принято, что стек очищает вызывающая программа. Для простоты восприятия, оформим в виде таблицы возможные варианты для компилятора Visual C/C++.
Название |
Кто очищает стек |
Передача параметров |
__cdecl |
Вызывающая функция |
Параметры помещаются в стек в обратном порядке (справа налево) |
__clrcall |
н/д |
Параметры загружаются в стек выражений CLR по порядку (слева направо) |
__stdcall |
Вызываемая функция |
Параметры помещаются в стек в обратном порядке (справа налево) |
__fastcall |
Вызываемая функция |
Хранятся в регистрах, затем помещаются в стек |
__thiscall |
Вызываемая функция |
Отправлено в стек; this указатель, хранящийся в ECX |
__vectorcall |
Вызываемая функция |
Хранятся в регистрах, затем помещаются в стек в обратном порядке (справа налево) |
Необходимо также учитывать, что в том же С или С++ передача параметров может быть как по ссылке, так и по значению. Ассемблерный код для этих случаев будет разным, значит и для ABI это тоже имеет значение.
Последнее, что стоит упомянуть — типы данных. Естественно, речь идет о встроенных типах. В С и С++ размеры типов могут варьироваться в зависимости от платформы. Думаю, не стоит объяснять, что несовместимость по размерам типов делает ABI несовместимым для таких платформ. Классический пример: попробуйте запустить 64-разрядную программу, написанную под Windows x64, в 32-разрядной версии операционки. Вряд ли у вас что-то получится.
Разумеется, это далеко не всё, что входит в ABI. Например, документ под названием System V Application Binary Interface AMD64 Architecture Processor Supplement (With LP64 and ILP32 Programming Models) содержит в себе больше ста страниц увлекательного погружения в мир регистров, примитивных типов данных, их размеров и прочих выравниваний, а также исключений. Просто рай для искушённого гурмана. Но мы не будем акцентировать на этом внимание — это тема для отдельной статьи.
Показываем на практике
Представим, что у нас есть готовая программа и мы хотим расширить её функциональность. Как это сделать? Можно открыть исходники и дописать недостающую фичу. Пересобираем проект — профит! Ах, точно — забыли про ещё одну функциональность. Реализуем, пересобираем, готово! Но нужна еще одна фича. Опять реализуем, пересобираем! Забыли про еще одну деталь. Снова реализуем… Так, стоп, что-то здесь не так, согласны? Хотелось бы упростить постоянную доработку и пересборку — оставить минимально возможный функционал, а остальное добавлять в виде загружаемой библиотеки. Ничего не напоминает? Ведь это то, что сейчас зовётся плагином. Естественно, они могут основываться на разных технологиях, но большинство из тех, с которыми мне приходилось работать, были, по сути, обычными динамическими библиотеками.
Проще говоря, мы пишем приложение на том же С++, добавляем в него возможность загрузки динамических библиотек и получаем расширение функционала без пересборки основного приложения. Например, всем известный Notepad++ работает с плагинами именно так. Причём здесь ABI? Как раз именно правильная реализация двоичного интерфейса позволит нам без проблем использовать единожды написанную динамическую библиотеку для различных версий одной платформы. Помните о тех вещах (порядок передачи параметров в функцию, размер типов), которые я упоминал в начале статьи? Если библиотека и основное приложение собраны одним и тем же компилятором на одной и той же платформе, про ABI можно вообще не вспоминать. Всё и так заработает без проблем. Но если, к примеру, собрать основное приложение при помощи MinGW, а библиотеку — при помощи MSVC, результат будет не таким очевидным.
А что, если связать друг с другом совсем разные языки программирования? Вызов С++ библиотеки из программы на С и наоборот — слишком банально и неинтересно. Давайте вызовем С++ библиотеку из Java и из Python. А в качестве полезного функционала наша С++ библиотека будет возвращать число Пи вплоть до 10 000 знаков после запятой.
Приступим!
Создадим Java-файл и в нём — соответствующий класс NativeLib.java:
public class NativeLib {
static {
System.loadLibrary("piValueLib");
}
public native String getPiValue(); // <--- native method
}Статический метод System.loadLibrary(“название загружаемой библиотеки”) будет загружать нашу динамическую библиотеку (piValueLib.dll).
Эту функцию будем вызывать из piValueLib.dll:
public native String getPiValue(); // <--- native methodТеперь перейдём к разработке самой .dll.
Дальнейшие действия я делал в командной строке MinGW 7.3.0 64-bit. Приведу сами команды и порядок их вызова (вызываем из папки, где всё лежит или пишем пути до нужных файлов).
Компилируем и создаём заголовочник (.h) для плюсовой динамической библиотеки.
javac -h . NativeLib.java
Получаем файл со следующим содержимым:
/* DO NOT EDIT THIS FILE - it is machine generated */
#include <jni.h>
/* Header for class NativeLib */
#ifndef _Included_NativeLib
#define _Included_NativeLib
#ifdef __cplusplus
extern "C" {
#endif
/*
* Class: NativeLib
* Method: getPiValue
* Signature: ()Ljava/lang/String;
*/
JNIEXPORT jstring JNICALL Java_NativeLib_getPiValue
(JNIEnv *, jobject);
#ifdef __cplusplus
}
#endif
#endifОбъявление есть, теперь создадим файл NativeLib.cpp, в котором реализуем алгоритм вычисления числа Пи с точностью до 10 000 знаков после запятой (найден на просторах сети):
Код:
#include "NativeLib.h"
#include <stdio.h>
#include <malloc.h>
#include <math.h>
#include <sstream>
#include <string>
using std::ostringstream;
using std::string;
ostringstream stringBuffer;
long B = 10000;
long LB = 4;
long MaxDiv = 450;
void SetToInteger(long n, long *x, long Integer) {
long i;
for (i = 1; i < n; i++) x[i] = 0;
x[0] = Integer;
}
long IsZero(long n, long *x) {
long i;
for (i = 0; i < n; i++)
if (x[i]) return 0;
return 1;
}
void Add(long n, long *x, long *y) {
long carry = 0, i;
for (i = n - 1; i >= 0; i--) {
x[i] += y[i] + carry;
if (x[i] < B) carry = 0;
else {
carry = 1;
x[i] -= B;
}
}
}
void Sub(long n, long *x, long *y) {
long i;
for (i = n - 1; i >= 0; i--) {
x[i] -= y[i];
if (x[i] < 0) {
if (i) {
x[i] += B;
x[i - 1]--;
}
}
}
}
void Mul(long n, long *x, long q) {
long carry = 0, xi, i;
for (i = n - 1; i >= 0; i--) {
xi = x[i] * q;
xi += carry;
if (xi >= B) {
carry = xi / B;
xi -= (carry*B);
}
else
carry = 0;
x[i] = xi;
}
}
void Div(long n, long *x, long d, long *y) {
long carry = 0, xi, q, i;
for (i = 0; i < n; i++) {
xi = x[i] + carry * B;
q = xi / d;
carry = xi - q * d;
y[i] = q;
}
}
void arccot(long p, long n, long *x, long *buf1, long *buf2) {
long p2 = p * p, k = 3, sign = 0;
long *uk = buf1, *vk = buf2;
SetToInteger(n, x, 0);
SetToInteger(n, uk, 1); /* uk = 1/p */
Div(n, uk, p, uk);
Add(n, x, uk); /* x = uk */
while (!IsZero(n, uk)) {
if (p < MaxDiv)
Div(n, uk, p2, uk); /* One step for small p */
else {
Div(n, uk, p, uk); /* Two steps for large p (see division) */
Div(n, uk, p, uk);
}
/* uk = u(k-1)/(p^2) */
Div(n, uk, k, vk); /* vk = uk/k */
if (sign) Add(n, x, vk); /* x = x+vk */
else Sub(n, x, vk); /* x = x-vk */
k += 2;
sign = 1 - sign;
}
}
void Print(long n, long *x) {
long i;
for (i = 1; i < n; i++)
stringBuffer << x[i];
}
JNIEXPORT jstring Java_NativeLib_getPiValue(JNIEnv* env, jobject thisObject)
{
long NbDigits = 10000, NbArctan;
long p[10], m[10];
long size = 1 + NbDigits / LB, i;
long *Pi = (long *)malloc(size * sizeof(long));
long *arctan = (long *)malloc(size * sizeof(long));
long *buffer1 = (long *)malloc(size * sizeof(long));
long *buffer2 = (long *)malloc(size * sizeof(long));
NbArctan = 3;
m[0] = 12; m[1] = 8; m[2] = -5;
p[0] = 18; p[1] = 57; p[2] = 239;
SetToInteger(size, Pi, 0);
for (i = 0; i < NbArctan; i++) {
arccot(p[i], size, arctan, buffer1, buffer2);
Mul(size, arctan, abs(m[i]));
if (m[i] > 0) Add(size, Pi, arctan);
else Sub(size, Pi, arctan);
}
Mul(size, Pi, 4);
Print(size, Pi);
free(Pi);
free(arctan);
free(buffer1);
free(buffer2);
string endResult = stringBuffer.str();
return env->NewStringUTF(endResult.c_str());
}Обратите внимание вот на эту функцию:
JNIEXPORT jstring Java_NativeLib_getPiValue(JNIEnv* env, jobject thisObject)
{
long NbDigits = 10000, NbArctan;
long p[10], m[10];
long size = 1 + NbDigits / LB, i;
long *Pi = (long *)malloc(size * sizeof(long));
long *arctan = (long *)malloc(size * sizeof(long));
long *buffer1 = (long *)malloc(size * sizeof(long));
long *buffer2 = (long *)malloc(size * sizeof(long));
NbArctan = 3;
m[0] = 12; m[1] = 8; m[2] = -5;
p[0] = 18; p[1] = 57; p[2] = 239;
SetToInteger(size, Pi, 0);
for (i = 0; i < NbArctan; i++) {
arccot(p[i], size, arctan, buffer1, buffer2);
Mul(size, arctan, abs(m[i]));
if (m[i] > 0) Add(size, Pi, arctan);
else Sub(size, Pi, arctan);
}
Mul(size, Pi, 4);
Print(size, Pi);
free(Pi);
free(arctan);
free(buffer1);
free(buffer2);
string endResult = stringBuffer.str();
return env->NewStringUTF(endResult.c_str());
}Именно её результат мы будем возвращать из библиотеки.
Весь код, естественно, на С++. Заголовочный файл есть, файл с определениями — тоже, можем собрать библиотеку. Не забудьте проверить, чтобы в файле NativeLib.cpp была строка
#include "NativeLib.h"и сигнатуры функции
JNIEXPORT jstring Java_NativeLib_getPiValue(JNIEnv* env, jobject thisObject)в NativeLib.h и в NativeLib.cpp полностью совпадали. Иначе получите ошибку линковки.
Команда для получения объектного файла:
g++ -c -I"C:\Program Files\Eclipse Adoptium\jdk-17.0.3.7-hotspot\include" -I"C:\Program Files\Eclipse Adoptium\jdk-17.0.3.7-hotspot\include\win32" NativeLib.cpp -o NativeLib.o
Обратите внимание — пути до файлов Java jdk у вас будут свои.
Команда для создания piValueLib.dll:
g++ -shared -o piValueLib.dll NativeLib.o -Wl,--add-stdcall-alias
Теперь всё собрано, скомпилировано, .dll есть — можно запускать проект:
java -cp . -Djava.library.path="C:\Users\user\Desktop\JNI\JNIProject\src" Main.java
Здесь в path указываем путь до динамической библиотеки. Результат будет примерно таким:
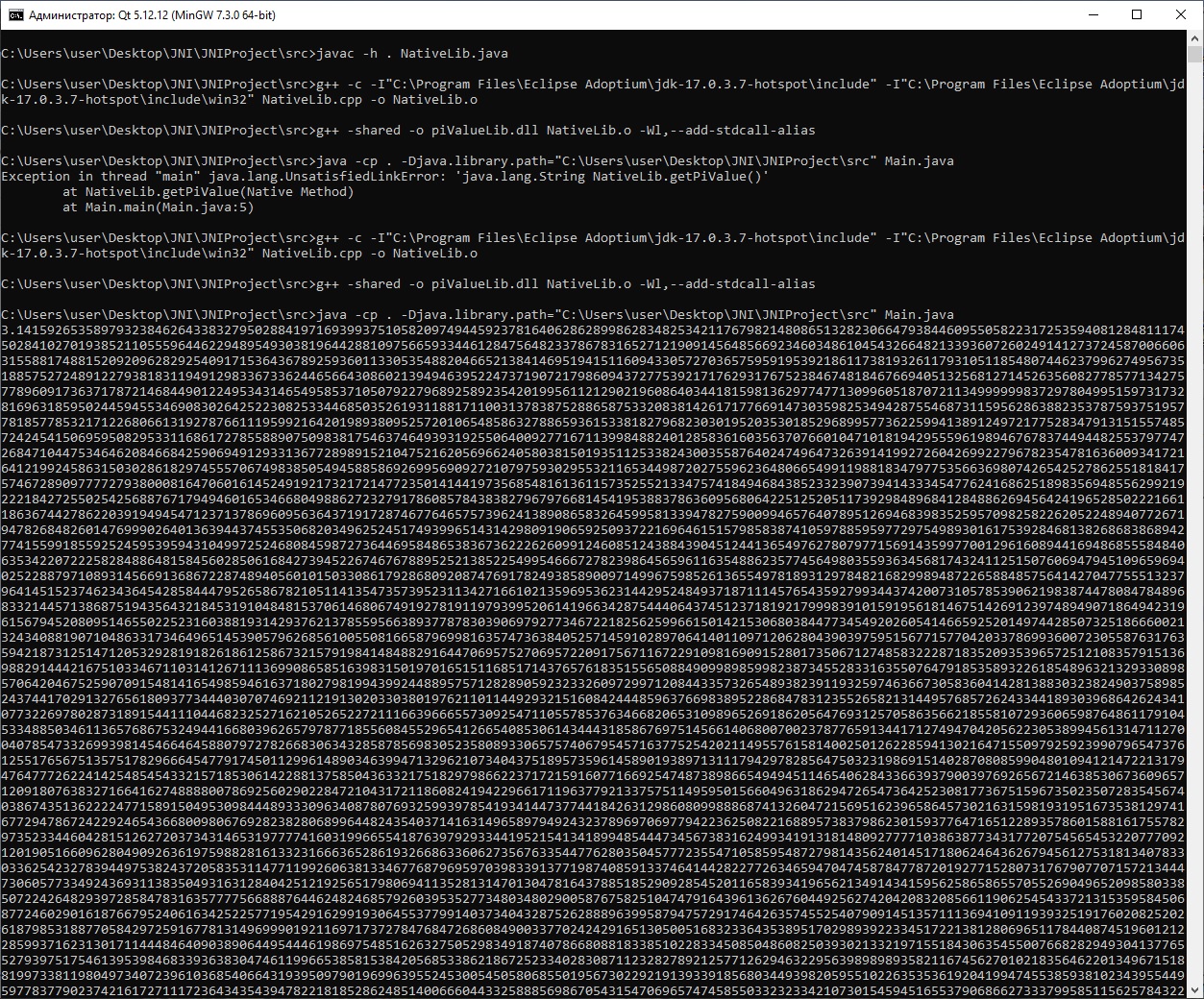
Если не верите, что там 10 000 знаков после запятой — можете посчитать.
Для адептов компиляторов от Microsoft — то же самое можно повторить и с ним. Я экспериментировал с x64 Native Tools Command Prompt for VS 2019. Скомпилировать Java-файл и сделать заголовочник для плюсовой библиотеки:
javac -h . NativeLib.java
Компиляция исходника плюсовой либы (получение объектного файла):
cl /c NativeLib.cpp
Получение .dll-файла:
cl /LD NativeLib.cpp
Запуск Java приложения:
java -cp . -Djava.library.path="C:\Users\user\Desktop\JNI\JNIProject\src" Main.java
Если возникнут проблемы — за подробностями всегда можно обратиться на сайт с документацией Microsoft. Или вызвать справку для командной строки компилятора:
cl /?
Ну что, получилось? Если нет — скорее всего, вы увидите ошибки вида «Ссылка на неразрешенный внешний символ». Это значит, что вы нарушили одно из соглашений ABI (ситуации с ошибками синтаксиса опустим — допустим, вы всё сделали правильно).
С Java разобрались: .dll собрали, код внедрили, результат получен. Займёмся пресмыкающимся? Внедрим нашу библиотеку в Python.
Но сначала нужно внести небольшие изменения в код плюсовой .dll-ки. Изменим сигнатуру (принимаемые параметры и возвращаемый результат) функции, возвращающей результат в питоновский код. Теперь нам не надо работать с JNIEnv *env и jobject. Поэтому эти параметры можно убрать. В результате код нашей .dll-ки будет примерно следующим (собирал в Visual Studio, а не в командной строке, поэтому присутствует функция DllMain):
#include <malloc.h>
#include <math.h>
#include <sstream>
#include <string>
#include <Windows.h>
using std::ostringstream;
using std::string;
ostringstream stringBuffer;
string endResult;
char* stroka;
long B = 10000;
long LB = 4;
long MaxDiv = 450;
void SetToInteger(long n, long* x, long Integer) {
long i;
for (i = 1; i < n; i++) x[i] = 0;
x[0] = Integer;
}
long IsZero(long n, long* x) {
long i;
for (i = 0; i < n; i++)
if (x[i]) return 0;
return 1;
}
void Add(long n, long* x, long* y) {
long carry = 0, i;
for (i = n - 1; i >= 0; i--) {
x[i] += y[i] + carry;
if (x[i] < B) carry = 0;
else {
carry = 1;
x[i] -= B;
}
}
}
void Sub(long n, long* x, long* y) {
long i;
for (i = n - 1; i >= 0; i--) {
x[i] -= y[i];
if (x[i] < 0) {
if (i) {
x[i] += B;
x[i - 1]--;
}
}
}
}
void Mul(long n, long* x, long q) {
long carry = 0, xi, i;
for (i = n - 1; i >= 0; i--) {
xi = x[i] * q;
xi += carry;
if (xi >= B) {
carry = xi / B;
xi -= (carry * B);
}
else
carry = 0;
x[i] = xi;
}
}
void Div(long n, long* x, long d, long* y) {
long carry = 0, xi, q, i;
for (i = 0; i < n; i++) {
xi = x[i] + carry * B;
q = xi / d;
carry = xi - q * d;
y[i] = q;
}
}
void arccot(long p, long n, long* x, long* buf1, long* buf2) {
long p2 = p * p, k = 3, sign = 0;
long* uk = buf1, * vk = buf2;
SetToInteger(n, x, 0);
SetToInteger(n, uk, 1);
Div(n, uk, p, uk);
Add(n, x, uk);
while (!IsZero(n, uk)) {
if (p < MaxDiv)
Div(n, uk, p2, uk);
else {
Div(n, uk, p, uk);
Div(n, uk, p, uk);
}
Div(n, uk, k, vk);
if (sign) Add(n, x, vk);
else Sub(n, x, vk);
k += 2;
sign = 1 - sign;
}
}
void Print(long n, long* x) {
long i;
for (i = 1; i < n; i++)
stringBuffer << x[i];
}
extern "C" {
__declspec(dllexport) char* getPiValue();
}
BOOL APIENTRY DllMain( HMODULE hModule,
DWORD ul_reason_for_call,
LPVOID lpReserved
)
{
switch (ul_reason_for_call)
{
case DLL_PROCESS_ATTACH:
case DLL_THREAD_ATTACH:
break;
case DLL_THREAD_DETACH:
break;
case DLL_PROCESS_DETACH:
break;
}
return TRUE;
}
char * getPiValue()
{
long NbDigits = 10000, NbArctan;
long p[10], m[10];
long size = 1 + NbDigits / LB, i;
long* Pi = (long*)malloc(size * sizeof(long));
long* arctan = (long*)malloc(size * sizeof(long));
long* buffer1 = (long*)malloc(size * sizeof(long));
long* buffer2 = (long*)malloc(size * sizeof(long));
NbArctan = 3;
m[0] = 12; m[1] = 8; m[2] = -5;
p[0] = 18; p[1] = 57; p[2] = 239;
SetToInteger(size, Pi, 0);
for (i = 0; i < NbArctan; i++) {
arccot(p[i], size, arctan, buffer1, buffer2);
Mul(size, arctan, abs(m[i]));
if (m[i] > 0) Add(size, Pi, arctan);
else Sub(size, Pi, arctan);
}
Mul(size, Pi, 4);
Print(size, Pi);
free(Pi);
free(arctan);
free(buffer1);
free(buffer2);
endResult = stringBuffer.str();
stroka = const_cast<char*>(endResult.c_str());
return stroka;
}Компилируем и на выходе получаем, скажем, piValueLib.dll. Название может быть любым.
Далее нам нужно написать код на Python, вызывающий нашу библиотеку:
import ctypes
lib_dll = ctypes.CDLL(r"C:\Users\user\Desktop\PycharmProjects\pythonProject\piValueLib.dll")
# Указываем, что функция возвращает char *
lib_dll.getPiValue.restype = ctypes.c_char_p
# Необходимо строку привести к массиву байтов, затем полученный массив байтов приводим к строке.
#print('pi value from .dll: ', lib_dll.getPiValue().decode("utf-8"))
s = lib_dll.getPiValue().decode("utf-8")
print('pi value from .dll: ', s)
# небольшая функция для
def parse_string(string: str) -> str:
new_string = ""
for letter_index in range(len(string)):
if letter_index % 100 == 0 and letter_index != 0:
new_string += "\n"
else:
new_string += string[letter_index]
return new_string
print(parse_string(s))
def parse_yet_string(string: str) -> str:
return ''.join(letter if index % 200 != 0 else f'{letter}\n' for index, letter in enumerate(string))
# показываем содержимое строки (наше число Пи)
print(parse_yet_string(s))В результате получаем примерно следующее:
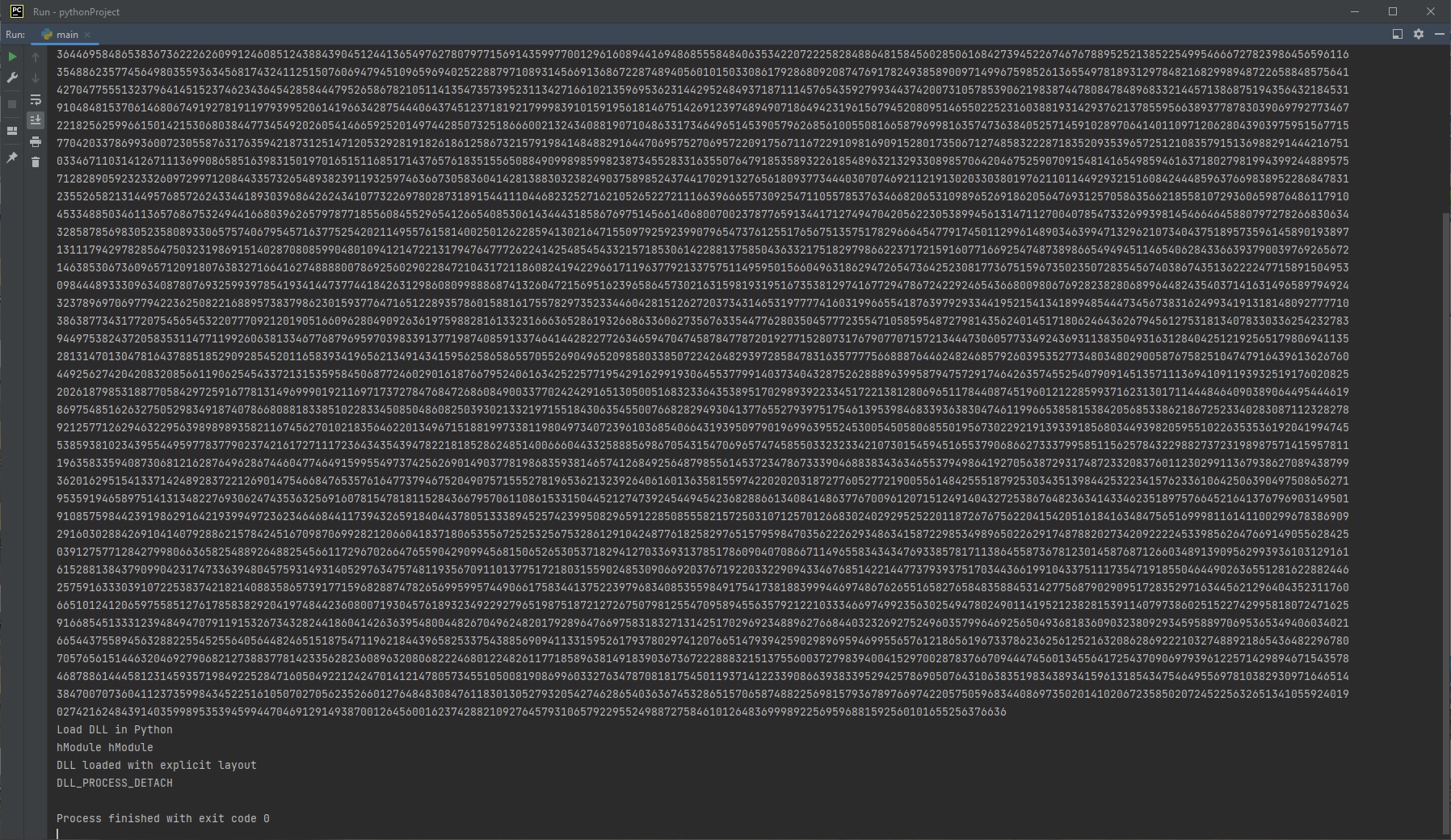
Если у вас не получилось и вы уверены, что синтаксических ошибок нет, то вы нарушили одно из соглашений ABI.
Что мы получаем
Вот так можно писать независимые модули и расширять ими основное приложение. И заметьте — всё это может быть написано на совершенно разных языках. Пример выше иллюстрирует, как, по сути, скриптовый язык взаимодействует с компилируемым. И под капотом всего этого всегда скрыт механизм ABI (разумеется, разные передачи через JSON, по сети и прочее в расчёт не берём — речь именно о взаимодействии с бинарным файлом).
Но чтобы подобные механизмы взаимодействия с библиотеками работали нормально, нужно всегда помнить про некоторые вещи. Например:
В заголовочном файле NativeLib.h используется конструкция вида extern "C" { }. Объясню, что это такое.
Есть такое понятие — Name Mangling. Методы и данные в приложениях на языке C++ имеют внутренние или декорированные имена, отличные от их имен в исходном коде. Декорированное имя — это символьная строка, в которой вместе с именем объекта закодирована дополнительная информация о типе, параметрах, соглашении о вызовах и других полезных для компилятора подсказках, которые помогают найти правильный код функции. Но для языка C++ нет общепринятого ABI, при динамической загрузке библиотеки может возникнуть проблема поиска нужных символов из-за декорирования имен. Если библиотека и программа, которая её будет использовать, скомпилированы одним компилятором — то никаких проблем. Но это решение будет, скорее всего, непереносимым. Никто не сможет гарантировать, что эта .dll заработает на другой машине, с точно такой же программой, но скомпилированной другим плюсовым компилятором.
Чтобы избежать подобного, на помощь приходит язык C. Директива препроцессора extern "C" позволяет отключить декорирование имени для экспортируемых интерфейсов библиотеки, и мы можем пользоваться ими так, как если бы они были написаны на C. А с С-шными библиотеками могут работать очень и очень многие языки программирования.
Подведем итоги
В теории можно написать один универсальный модуль, скомпилировать его, и в рамках одной платформы (например, Windows) он сможет работать с разными версиями операционки и с разными языками программирования.
Для обеспечения максимальной бинарной совместимости нужно:
Экспортировать только функции с припиской extern "C" (т.е. никаких классов, шаблонов, перегруженных функций, пространств имен и т.д.).
Передавать (через границы модулей) только простые типы (встроенные — никаких пользовательских), указатели на них и указатели на функции.
Если все же очень нужно передать пользовательский тип, то пусть это будет структура, первым членом которой будет размер этой структуры. Так, по крайней мере, можно проконтролировать выравнивание полей.
Не забывать про выделенную память — блоки динамической памяти должны освобождаться всегда в том же модуле, в котором были выделены. То есть, если библиотека возвращает программе-клиенту указатель на блок памяти, выделенный malloc внутри себя, она должна предоставлять специальную функцию для его освобождения (вызывающую внутри себя free), вместо того, чтобы полагаться на вызов free в программе-клиенте.
Надеюсь, материал оказался для вас интересным. Спасибо, что дочитали до конца!
А в этой статье мы рассказывали о тонкостях и нюансах того, как писать стабильный, безопасный и надежный код на C/C++.
Авторские материалы для backend-разработчиков мы также публикуем в наших соцсетях – ВКонтакте и Telegram.
Комментарии (24)

vilgeforce
19.06.2023 10:17+2"Общепринятым соглашением считается передача всех параметров именно через стек." - я бы сказал "считалась". Например в x64-мире принято передавать параметры через регистры. У MS - 4 параметра в RCX, RDX, R8, R9, у System V - больше.
И сходу могу вспомнить про интерфейс к ядру Windows, где все еще чуть более иначе
kovserg
19.06.2023 10:17Еще есть подстава с ABI в которых предполагается что некоторые регистры не изменяются. И в разных ABI это разные регистры.
https://habr.com/ru/articles/703894/vilgeforce
19.06.2023 10:17Наверное, я не обращал внимания на XMM-регистры. Или и правда не встречал функций, которые бы сильно расчитывали на сохранность XMM-регистров

SSul Автор
19.06.2023 10:17По умолчанию для компиляторов Microsoft и для ABI x64 — да. Но тут речь не про частности, а про общий случай - чтоб и MSVC "переварил" и MinGW и прочие Clang'и. А для этого нужно использовать __cdecl соглашение о вызовах

panteleymonov
19.06.2023 10:17+1Последнее, что стоит упомянуть — типы данных. Естественно, речь идет о встроенных типах. В С и С++ размеры типов могут варьироваться в зависимости от платформы. Думаю, не стоит объяснять, что несовместимость по размерам типов делает ABI несовместимым для таких платформ. Классический пример: попробуйте запустить 64-разрядную программу, написанную под Windows x64, в 32-разрядной версии операционки. Вряд ли у вас что-то получится.
Мне кажется вы тут путаете теплое с мягким, 64 битные параметры возможны и в 32-x разрядных приложениях. Также как 32-x разрядные и 64-x разрядные были возможны в 16-и битных. Но сравнивать их в бинарном плане (передается по разному) это как сравнивать два разных процессора с разным набором команд. Понятное дело что нет общего ABI для всех процессоров и каждый процессор устанавливает свои порядки в меньшей степени, а за ним уже операционная система делает это более жестко.

domix32
19.06.2023 10:17Я так под msvc 32 бита компилировал. Было забавно узнать, что long long тоже превратился в 32 бита, а не заполифилился в два инта. Так что если вы не писали их, то по-умолчанию выше 32 бит на 32-битной платформе не получишь.
panteleymonov
19.06.2023 10:17Я пишу с 92 года и почему-то таких вот поворотов не встречал. Вы случайно число с указателем не путаете?
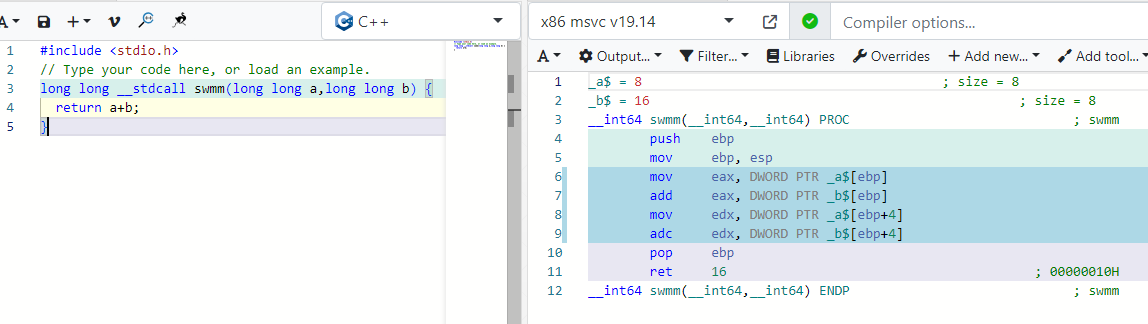
В С++ действительно есть типы которые меняют свой размер в зависимости от разрядности приложения, к примеру int и long, это связанно с размерностью регистров по умолчанию и прочими нюансами. Но это также управляемо.
domix32
19.06.2023 10:17Сейчас уже деталей не помню, но знаю, что определенно сталкивался. Опять же компилятор на godbolt относительно свежий. Тогда это была наверное версия, которая шла с VS Express 2015, или 2017. Там было помимо этого ещё несколько багов компилятора, и кусков 11 стандарта вроде всех не было. Но у нас 32 битный таргет в итоге не использовался, только 64.
SSul Автор
19.06.2023 10:17Тут речь не про приложения, а про целевую платформу. Цитата Microsoft (https://learn.microsoft.com/ru-ru/windows/win32/winprog64/running-32-bit-applications) отсюда: "Обратите внимание, что 64-разрядная версия Windows не поддерживает запуск 16-разрядных приложений windows. Основная причина заключается в том, что дескриптор имеет 32 значимых бита в 64-разрядной версии Windows. Таким образом, дескрипторы не могут быть усечены и переданы в 16-разрядные приложения без потери данных. Попытки запуска 16-разрядных приложений завершаются сбоем со следующей ошибкой: ERROR_BAD_EXE_FORMAT."
kovserg
19.06.2023 10:17Основная причина заключается в том, что дескриптор имеет 32 значимых бита в 64-разрядной версии Windows.
Отмазки, для 16битных приложений можно было сделать таблицы трансляции. Основная причина сбросить груз ответственности за поддержку этой подсистемы.
SSul Автор
19.06.2023 10:17Вероятнее всего, реализация возможности запуска 16-битных приложений в новейших версиях Windows слишком трудозатратна и бесперспективна с коммерческой точки зрения. Ресурсов требуется море, а профит оценят только небольшое число энтузиастов. Все-таки Microsoft — коммерческая организация, а Windows — это не open-source проект, поддерживаемый сообществом.

Chaa
19.06.2023 10:17Проблема в процессоре. Процессор, работая в 32-х разрядном режиме может выполнять 16-ти битные инструкции. Процессор, работая в 64-х разрядном режиме может выполнять 32-х битные инструкции, но уже не может выполнять 16-ти битные.
Поэтому во всех 32-х разрядных Windows работают 16-ти битные программы, а в 64-х битных уже нет.kovserg
19.06.2023 10:1716битные приложение очень скромные по ресурсам и спокойно эмулируются даже на сотовом телефоне.
http://www.columbia.edu/~em36/ntvdmx64.html
https://github.com/leecher1337/ntvdmx64
https://www.vdos.info
https://www.dosbox.com


ilitaiksperta
19.06.2023 10:17+7Суперклей ABI, или Как применять C++ где угодно
Экспортировать только функции с припиской extern "C"
SSul Автор
19.06.2023 10:17Да — но данная конструкция всего лишь отключает искажение имен (Name Mangling) для С++ кода (в С, напомню, ничего подобного нет). Но ничего не говорит о Calling Convention, то есть о технических особенностях вызова (cdecl это или скажем stdcall)
Chaa
19.06.2023 10:17+1Как раз 30 лет назад для решения проблемы с разными компиляторами и языками придумали COM (Component Object Model).
Это ABI для совместного использования кода плюс инструменты (например, язык для описания интерфейсов).

buldo
19.06.2023 10:17+5Статья - полное читерство.
Обычно на руках есть готовая плюсовая либа. В этой либе есть классы и у этих классов есть методы, которые и надо вызывать.
А тут что? Сначала пошли от обратного и условно говоря изменили код "плюсовой" библиотеки. А потом и вовсе extetrn C.
Как использовать C++ библиотеку в других языках? Через боль, страдания и обертки.
SSul Автор
19.06.2023 10:17Речь идет не о готовой плюсовой либе, а о расширении функциональности через готовое решение, написанное на С++. Берем этот код, если нужно — вносим необходимые изменения, собираем из него динамическую библиотеку и подключаем к нужному нам проекту. В статье мы пошагово расписали, как это сделать применительно к Java и Python. Про боль и страдания — вопрос субъективный ????
kovserg
19.06.2023 10:17+1А там внезапно есть FFI
SSul Автор
19.06.2023 10:17Конечно, есть — он и используется. Ведь механизм FFI (Foreign function interface) и создан для интеграции между языками https://ps-group.github.io/compilers/backend_ffi
gatoazul
Иосиф Крейнин раскрыл тему с полным отсутствием совместимости по ABI даже между разными компиляторами C++ пятнадцать лет назад. С тех пор не изменилось ничего...
Viacheslav01
Был случай с компилятором от microsoft так получилось, что встретились два модуля один компилировался одной версией компилятора, а второй следующей в линейке. Я уже волосы на себе рвать начал, почему у меня в рантайме все рушится и работает не пойми как, а отладчик показывает какую то невообразимую дичь. И только в дизасемблере заметил, что порядок передачи параметров поменялся на обратный.
Т.е. формально оба компилятора использовали одно соглашение вызова (какое именно не помню), а во факту два разных! И это компилятор от одной компании, просто двух разных поколений.