

Я опубликовала в интернет-журнале статью на тему двоичного представления информации компьютерами и, среди прочих, неоднократно получала вопрос: «Почему в архитектуре x86 используются байты, состоящие именно из 8 бит, а не иного их количества?»
Я считаю, что на любой подобный вопрос можно дать два основных ответа и некую их комбинацию:
- Так сложилось исторически, и другой размер (например, 4, 6 или 16 бит) тоже вполне сработает.
- Восемь бит по какой-то причине является лучшим вариантом, и даже если бы история сложилась иначе, мы бы всё равно использовали именно 8-битные байты.
- Некая комбинация этих двух версий.
Я не большой специалист по компьютерной истории (мне куда больше нравится использовать компьютеры, чем читать про них), но меня всегда интересовало, есть ли какая-то весомая причина, по которой мир компьютеров сегодня выглядит именно так, или это, по большому счёту, просто историческая случайность. Так что в этой статье речь пойдёт об истории компьютеров.
Приведу пример исторической случайности: в DNS есть поле
class, которое может содержать одно из пяти значений – internet, chaos, hesiod, none и any). Для меня это явный пример исторической случайности – не могу представить себе, чтобы мы, воссоздавая это поле сегодня, определили его таким же образом, не беспокоясь об обратной совместимости. Не уверена, что мы бы вообще стали использовать поле класса.В этой статье не приводятся однозначные объяснения, но я задала вопрос на Mastodon, и собрала из полученных ответов несколько возможных причин 8-битного размера байта. Думаю, что ответ представляет некое сочетание этих причин.
▍ В чём отличие между байтом и словом?
Начну с того, что в этой статье будут активно обсуждаться байты и слова. В чём же отличие между ними? Вот моё понимание этого вопроса:
- Размер байта представляет минимальную единицу данных, которую можно адресовать. Например, в программе на моей машине
0x20aa87c68может быть адресом одного байта, а значит0x20aa87c69будет адресом следующего байта. - Размер слова является кратным размеру байта. Для меня это оставалось непонятным долгие годы, причём в Wikipedia этому даётся весьма туманное определение («слово – это естественная единица данных, используемая в конкретной архитектуре процессора»). Изначально я думала, что размер слова равен размеру регистра (64 бита на x86-64). Но, согласно разделу 4.1 («Fundamental Data Types») мануала по архитектурам Intel, в системах x86 слово имеет размер 16 бит при том, что размер регистров 64 бита. Это сбивает с толку. Какой всё-таки размер слова в системах x86 – 16 или 64 бита? Может ли это зависеть от контекста?
Ну а теперь поговорим о возможных причинах использования именно 8-битных байтов.
▍ Причина 1: чтобы любой символ английского алфавита вписывался в 1 байт
Статья на Wikipedia гласит, что 8-битный байт впервые начал использоваться в IBM System/360 в 1964 году.
Вот видео интервью с Фредом Бруксом (руководителем проекта), в котором обсуждается причина этого. Вот часть его содержания:
… 6-битные байты по факту лучше подходят для научного вычисления, а 8-битные – для коммерческого. При этом каждый вариант можно приспособить для работы в роли другого. Поэтому всё свелось к принятию ответственного решения, и я склонился к варианту с 8 битами, который предложил Джерри.
[….]
Моим самым важным техническим решением за всю карьеру в IBM был переход на использование 8-битных байтов в модели 360. Это решение также подкреплялось моей верой в то, что обработка знаков станет более значимой, чем обработка десятичных цифр.
Идея о том, что 8-битный байт больше подходит для обработки текста, вполне логична: 2^6 равно 64, значит 6 бит оказалось бы недостаточно для букв нижнего/верхнего регистра и символов.
Для перехода на использование 8-битного байта в System/360 также была реализована кодировка 8-битных символов EBCDIC.
Похоже, что следующим значительным шагом в истории 8-битного байта стал процессор Intel 8008, который создавался для использования в терминале Datapoint 2200. Терминалам необходима возможность представлять буквы, а также управляющие коды, поэтому в них есть смысл использовать 8-битные байты. В руководстве к Datapoint 2200 из музея компьютерной истории на странице 7 сказано, что эта модель поддерживала кодировки ASCII (7 бит) и EBCDIC (8 бит).
▍ Почему 6-битный байт лучше подходит для научных вычислений?
Меня заинтересовал комментарий о том, что 6-битный байт оказался бы более подходящим для научных вычислений. Вот цитата из интервью с Джином Амдалем:
Я хотел сделать его 24-х и 48-битным, а не 32-х и 64-х, поскольку тогда бы я получил более рациональную систему с плавающей запятой. Дело в том, что в системе с плавающей запятой при 32-битном слове вы оказывались ограничены всего 8 битами для знака возведения в степень, а чтобы это было практично в плане охватываемого численного диапазона, приходилось выполнять корректировку по 4 бита, а не по одному. В результате часть информации терялась быстрее, чем в случае двоичного сдвига.
Мне это рассуждение совсем непонятно – почему при использовании 32-битного слова возведение числа в степень должно быть 8-битным? Почему нельзя использовать 9 или 10 бит? Но это всё, что мне удалось найти в результате недолгого поиска.
▍ Почему в мейнфреймах использовалось 36 бит?
Это также связано с 6-битным байтом: во многих мейнфреймах использовались 36-битные слова. Почему? Кто-то указал на прекрасное объяснение в статье Wikipedia, посвящённой 36-битному вычислению:
До появления компьютеров эталоном в точных научных и инженерных вычислениях был 10-циферный электромеханический калькулятор… В этих калькуляторах для каждой цифры присутствовал ряд клавиш, и операторы обучались использовать для ввода чисел все десять пальцев, поэтому, хоть в некоторых специализированных калькуляторах и было больше рядов, десять являлось практичным ограничением.
В связи с этим в первых двоичных компьютерах, нацеленных на тот же рынок, использовались 36-битные слова. Этой длины было достаточно для представления положительных и отрицательных целых чисел с точностью до десяти десятичных цифр (35 бит оказалось бы минимумом).
Получается, что поводом для использования 36 бит стал тот факт, что
log_2(20000000000) равен 34.2.Я предполагаю, что причина тому лежит где-то в 50-х годах – тогда компьютеры были невероятной роскошью. Поэтому, если вам требовалось, чтобы устройство поддерживало десять цифр, его нужно было спроектировать с поддержкой ровно достаточного для этого числа бит и не более.
Сегодня компьютеры стали быстрее и дешевле, поэтому, если вам по какой-то причине нужно представить десять цифр, то вы можете просто использовать 64 бита – потеря некоторого пространства памяти вряд ли станет проблемой.
Кто-то другой писал, что некоторые из этих машин с 36-битными словами позволяли выбирать размер байта – в зависимости от контекста можно было использовать 5, 6, 7 или 8-битные байты.
▍ Причина 2: для эффективной работы с десятичными значениями в двоичной кодировке
В 60-е годы существовала популярная кодировка целых чисел под названием BCD (binary-coded decimal), которая кодировала каждую цифру в 4 бита. Например, если бы вам понадобилось закодировать 1234, то в BCD это бы выглядело так:
0001 0010 0011 0100Поэтому в целях удобства работы с закодированным в двоичную форму десятичным значением размер байта должен был быть кратным 4 битам – например, 8 бит.
▍ Почему BCD была популярна?
Такое представление целых чисел мне показалось реально странным – почему бы не использовать двоичную форму, которая позволяет намного более эффективно хранить целые числа? Ведь эффективность в первых компьютерах была крайне важна.
Лично я склоняюсь к тому, что причина заключалась в специфике дисплеев первых компьютеров, на которых содержимое байта отображалось непосредственно в состояние лампочек – вкл/выкл.
Вот картинка IBM 650 с лампочками на дисплее (CC BY-SA 3.0):

Поэтому, если мы хотим, чтобы человеку было относительно удобно прочитывать десятичное число из его двоичного представления, то такой вариант будет намного более разумным. Я думаю, что сегодня кодировка BCD уже неактуальна, потому что у нас есть мониторы, и наши компьютеры умеют автоматически конвертировать числа из двоичной формы в десятичную, отображая итоговый результат.
Мне также было интересно, не из BCD ли родился термин «nibble» (полубайт), означающий 4 бита – в контексте BCD вы много обращаетесь к полубайтам (поскольку каждая цифра занимает 4 бита), поэтому есть смысл использовать слово для «4 бит», которые люди и прозвали «nibble». Сегодня для меня этот термин уже выглядит архаичным – если я его когда-то и использовала, то только смеха ради (оно такое забавное). Причём эта теория подтверждается статьёй в Wikipedia:
Термин «полубайт» использовался для описания количества памяти, используемой в мейнфреймах IBM для хранения цифры числа в упакованном десятичном формате (BCD) .
В качестве ещё одной причины использования BCD кто-то назвал финансовые вычисления. Сегодня, если вам нужно сохранить какое-то количество долларов, то вы обычно просто используете целочисленное значение в центах и делите это значение на 100, если хотите получить его долларовую часть. Это несложно, деление выполняется быстро. Но в 70-х деление на 100 целого числа, представленного в двоичном формате, явно выполнялось очень медленно, поэтому был смысл перестроить систему представления целых чисел во избежание деления на 100.
Ладно, хватит о BCD.
▍ Причина 3: 8 – это степень 2
Многие люди указали на важность того, чтобы размер байта был равен степени 2. Я не могу выяснить, правда это или нет, и меня не удовлетворило объяснение, что «компьютеры используют двоичную систему счисления, поэтому степень двойки подойдёт лучше всего». Это утверждение выглядит весьма правдоподобным, но мне хотелось разобраться глубже. За всю историю определённо было множество машин, в которых использовались байты с размером, не являющимся степенью 2. Вот несколько примеров, взятых из темы о ретрокомпьютерах со Stack Exchange:
- в мейнфреймах Cyber 180 использовались 6-битные байты;
- в серии Univac 1100 / 2200 использовались 36-битные слова;
- PDP-8 был 12-битным компьютером.
А вот пара пока не понятных мне причин, названных в качестве объяснения, почему оптимальный размер байта должен быть кратен 2:
- каждому биту в слове требуется линия шины, а количество линий должно быть кратно 2 (почему?);
- значительная часть логики электросхем предрасположена к техникам «разделяй и властвуй» (мне нужен пример для понимания этого утверждения).
А вот причины, которые мне показались более обоснованными:
- Это упрощает проектирование делителей частоты, способных измерять «отправку 8 бит по такому-то каналу» и работающих на основе деления пополам – можно установить 3 таких делителя последовательно. Грэхем Сазерленд рассказал мне об этом и создал классный симулятор делителей частоты, демонстрирующий их устройство. На том же сайте (Falstad) есть и много других примеров схем, и он отлично подходит для создания различных симуляторов.
- Если у вас есть инструкция, обнуляющая конкретный бит в байте, то при размере байта 8 (2^3) вы можете использовать всего три бита этой инструкции для указания, какой это бит. В системах x86 такой возможности нет, зато она есть у инструкций тестирования битов в Z80.
- Кто-то также сказал, что в некоторых процессорах используются сумматоры с опережением переноса, которые работают с группами по 4 бита. Недолгий поиск в Google показал, что существует большое разнообразие схем сумматоров.
- Битовые карты: память вашего компьютера организована по страницам (обычно размером 2^n). При этом компьютеру необходимо отслеживать каждую страницу на предмет того, свободна она или нет. Для этого в операционных системах используются битовые карты, в которых каждый бит соответствует странице и равен 0 или 1 в зависимости от того, свободна ли она. Если бы в компьютере использовался 9-битный байт, то для нахождения нужной страницы в битовой карте пришлось бы делить на 9. Деление на 9 медленнее деления на 8, потому что деление на степени 2 всегда является самым быстрым.
Возможно, я исказила некоторые из приведённых объяснений, так как в этой области знаний я не особо сильна.
▍ Причина 4: небольшой размер байта – это хорошо
Вы можете поинтересоваться: «Если 8-битные байты оказались лучше 4-битных, почему бы не продолжить увеличивать их размер? Можно же использовать 16-битные!»
Вот пара причин для сохранения небольшого размера байта:
- Это приведёт к пустой трате пространства – байт является минимальной адресуемой единицей, и если компьютер хранит много текста в кодировке ASCII (которой требуется всего 7 бит), то выделение для каждого символа не 8, а 12 или 16 бит приведёт к значительным потерям памяти.
- Если размер байта увеличивается, то и система процессора должна усложняться. К примеру, вам требуется по одной линии шины на бит. Так что, думаю, чем проще, тем лучше.
Моё понимание архитектуры процессоров очень шаткое, поэтому углубляться в эту тему я не стану. Хотя причина «пустой траты пространства» выглядит для меня весьма убедительной.
▍ Причина 5: совместимость
Процессор Intel 8008 (1972 год) был предшественником модели 8080 (1974 год), которая предшествовала 8086 (1976 год) – первому процессору семейства x86. Похоже, что 8080 и 8086 были очень популярны, и именно с них пошли все современные компьютеры x86.
Думаю, здесь уместен принцип «не чини того, что не сломано» – мне кажется, что 8-битные байты отлично работали, поэтому в Intel не увидели необходимости менять их размер. Сохранение 8-битного байта позволяет повторно использовать более обширную часть набора инструкций.
К тому же, в 80-х начали появляться сетевые протоколы вроде TCP, в которых использовались 8-битные байты (обычно называемые «октеты»), и если вы соберётесь реализовать сетевые протоколы, то наверняка решите использовать в них 8-битный байт.
Вот и всё!
На мой взгляд, основные причины, по которым байт состоит из 8 бит, следующие:
- Многие из первых компьютерных компаний базировались в США, где самым распространённым языком является английский.
- Разработчики хотели, чтобы компьютеры хорошо справлялись с обработкой текста.
- Небольшие размеры байтов, как правило, более эффективны.
- Минимальный размер, в который впишутся любые английские символы и знаки пунктуации, составляет 7 бит.
- Число 8 лучше 7, потому что является степенью 2.
- Когда у вас уже есть популярные 8-битные компьютеры, которые отлично работают, вы предпочтёте сохранить такую архитектуру для совместимости.
Кто-то также отметил, что на 65-й странице этой книги 1962 года, объясняющей причины, по которым в IBM решили использовать 8-битный байт, по сути, говорится то же самое:
- Полный охват в 256 символов был сочтён достаточным для подавляющего большинства возможных применений.
- В рамках этого охвата один символ представляется одним байтом, чтобы длина любой отдельной записи не зависела от совпадения символов в этой записи.
- 8-битные байты обеспечивают разумную экономию пространства хранилища.
- При работе с числами десятичную цифру можно представить всего 4 битами, и два таких 4-битных байта можно упаковать в один 8-битный. И хотя подобное упаковывание численных данных не представляет особой значимости, это распространённая практика, позволяющая увеличить скорость и эффективность хранилища. Строго говоря, 4-битные байты относятся к другому коду, но простота 4- и 8-битной схемы в сравнении, например, с комбинацией 4 и 6 бит ведёт к более простому устройству машины и логики адресации.
- Размеры байтов в 4 и 8 бит, являясь степенью 2, позволяют разработчику компьютеров задействовать мощные возможности двоичной адресации и индексации вплоть до уровня бит (см. главы 4 и 5).
В целом у меня сложилось ощущение, что 8-битный байт является естественным выбором, если вы проектируете двоичный компьютер в англоязычной стране.

Комментарии (123)

saboteur_kiev
28.06.2023 13:07+15Причина 1: чтобы любой символ английского алфавита вписывался в 1 байт
Для умещения всех букв достаточно 7 бит, и ASCII это подтверждает - все влазит в первые 127 символов. И 8бит уже нужно для региональных символов или псевдографики
Размер слова является кратным размеру байта. Для меня это оставалось непонятным долгие годы, причём в Wikipedia этому даётся весьма туманное определение («слово – это естественная единица данных, используемая в конкретной архитектуре процессора»).
Также как есть int, char, float, в архитектуре процессора есть byte, word, dword, qword. Если у тебя что-то не влазит в байт, берешь слово, не влазит в слово - берешь двойное слово. Это просто архитектура процессоров, которая вам неинтересна.
Ну и напоследок - 7-битная архитектура вполне себе существовала.
Но 8 бит выбраны из-за удобства и кратности.
Исторически выбирали как можно меньше, потому что и память тогда была крайне дорогая. Если бы выбирали сейчас, вполне может быть что выбор был бы 10 или 16.

forthuse
28.06.2023 13:07+3Интересная статья и логично всё представляющая,
а если бы в использование вошли копьютеры на троичной логике, то каким бы тогда был
и назывался байт? (трайт) :)P.S. Ещё для половинок байта в системе команд процессоров была их возможность обменивать местами (вроде XCHG команда в 8080, Z80 прцессоре), а вообще реальное понимание, что байт произошёл удвоением количества 4-ёх бит.
А в FPGA сейчас аппаратно применены 9-ть бит. (в этом варианте удобно их делить в группироке в 8-ричной системы счисления)

mpa4b
28.06.2023 13:07То, что было
XCHGв 8080, сталоEX DE,HLв z80. И очевидно, к обмену половинок байта никак не относится.forthuse
28.06.2023 13:07+1Да, спасибо что обратили внимание на это, забыл уже систему команд 8080, Z80 :)
(примерно после 30-ти лет её ассемблерного не использования)
но один раз в одном месте кода была использована команда:RLD (RRD) Левый (или правый) арифметический циклический перенос тетрады из аккумулятора в ячейку памяти, адресуемую регистром HL. Старшая тетрада (биты 7… 4) ячейки памяти переносится в младшую тетраду аккумулятора (биты 3...0), младшая
тетраде аккумулятора переносится в младшую тетраду ячейки памяти, а младшая тетрада ячейки памяти — в старшую тетраду ячейки памяти.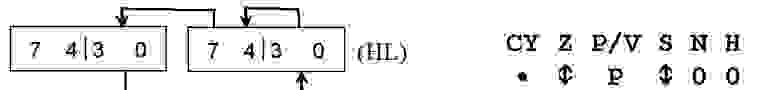

МИКРОПРОЦЕССОР Z80, СИСТЕМА КОМАНД
Но, ещё к слову, у Z80 были недокументированные команды работающие с половинками байта.
у Z80 удобная и мощная система команд, но аппаратную конкуренцию выиграла исторически x86.
balamutang
28.06.2023 13:07+4х86 выиграл конкуренцию потому что Z80 был просто расширением восьмибитного 8080, а 8086 был шагом вперед в новый 16-битный мир.
Встречались мнения что Интел просто слила Зилогу 8-битный рынок, т.к. самой ей он был неинтересен, но при этом контролируемое присутствие Zilog на рынке процессоров позволяло Интелу избежать претензий от антимонопольных служб.

PuerteMuerte
28.06.2023 13:07Встречались мнения что Интел просто слила Зилогу 8-битный рынок, т.к. самой ей он был неинтересен, но при этом контролируемое присутствие Zilog на рынке процессоров позволяло Интелу избежать претензий от антимонопольных служб.
Да это просто легенды. Во-первых, Интел честно пыталась конкурировать и на 8-битном рынке, выпустив своего конкурента Z80 практически одновременно с ним, который был и быстрее 8080, и требовал только +5В питание, и работал на более высоких частотах, и к тому же был обратно совместим по инструкциям. Просто Z80 оказался лучше. А следующие поколения процессоров всеми чипмейкерами уже разрабатывались под 16 бит и больше, и выпускать новую 8-битку было просто не актуально.
Во-вторых, Интел рынок Зилогу и не слила. Зилог был лидером 8-битного рынка только в ехСССР. В остальном мире Зилог был хоть и популярным процессором, но подавляющее большинство 8-битных машин было на MOS 6502.
В-третьих, популярность 16-битной архитектуре Интела обеспечила IBM и её клонмейкеры. Это не заслуга самой Интел.
mpa4b
28.06.2023 13:07+2> подавляющее большинство 8-битных машин было на MOS 6502.
Среди тех, которые не могли запустить CP/M?
Просто CP/M-машины до распространения писюков занимали нишу бизнес-машин, и их было много, хотя каких-то однозначных лидеров там не было.
PuerteMuerte
28.06.2023 13:07+1Просто CP/M-машины до распространения писюков занимали нишу бизнес-машин, и их было много
Ну как много? Много - это всякие вариации Commodore, Apple II, Atari 400/800, ну или там даже NES, тоже вполне себе потребитель процессора на 8-битном рынке. А машин на CP/M было не очень много.
mpa4b
28.06.2023 13:07Настолько много, что конец 70х и начало 80х в журнале Byte например забиты рекламой всеразличных cp/m машин. Ближе к 90ым стало забито рекламой и статьями о писюках.
В штуках естественно я не могу сказать. Но касательно комодов и атарей с синклерами -- они начали своё победное шествие уже после или во время появления писюков и жили в общем-то параллельно, как чисто домашние компы для игр. А вот cp/m-машины, ориентировавшиеся на бизнес -- стремительным домкратом вымерли после появления писюков.
PuerteMuerte
28.06.2023 13:07+1Настолько много, что конец 70х и начало 80х в журнале Byte например забиты рекламой всеразличных cp/m машин.
Ну как бы логично, что в компьютерном журнале было много рекламы компьютеров :)
Но касательно комодов и атарей с синклерами -- они начали своё победное шествие уже после или во время появления писюков
Комоды и эпплы - с 1977 года, атари с 1979-го.. Собственно, эпоха CP/M машин была вообще короткая, лет пять, но 6502 продолжил своё распространение, а бизнес-компьютеры на CP/M - нет (Роботрон 1715 не в счёт). Если верить интернетам, к 1980 году было продано 250 тыс копий СР/М, вот, собственно, и точка для отсчёта. Комодов разных моделей было продано около 20 млн. Эпплов - шесть млн.
saboteur_kiev
28.06.2023 13:07x86 выиграл конкуренцию, потому что он
стандартизировал отрасль
лицензировал сторонних производителей выпускать совместимые чипы и оборудование
PuerteMuerte
28.06.2023 13:07лицензировал сторонних производителей выпускать совместимые чипы и оборудование
Это не он лицензировал. Это опять же таки, IBM заставила лицензировать. Одним из условий допуска каких-либо компонент в производственную цепочку у них было наличие альтернативных поставщиков. Поэтому они заключили договор с Интел только на условии, что Интел лицензирует свою архитектуру другим поставщикам.
saboteur_kiev
28.06.2023 13:07IBM заставила, но именно интел согласился и лицензировал. И вот и результат.
PuerteMuerte
28.06.2023 13:07Ну что значит "согласился"? У них был выбор вида "или вступаете в колхоз или расстреляем". Конечно, согласился :)

DmitryZlobec
28.06.2023 13:07+3Не выиграл, а проиграл. Те же Rabbit живее всех живых. А чистый x86 давно мертв.
mpa4b
28.06.2023 13:07+1Каким образом? Ну вот когда ibm в 1981ом выбирало себе процессор, каким образом к этому моменту х86 что-то стандартизировал?
В те времена (70ые-80ые) любой, кто серьёзно подходил к делу хотел пролезть во все ниши был вынужден искать себе second source производителей. Это делал и zilog в том числе.

DanilinS
28.06.2023 13:07Сверх популярный 8080 имел своего предшественника: 4040. Он был 4-х битный. И соответственно внутри этой линейки шло простое удвоение по разрядности.
mpa4b
28.06.2023 13:07+1Прямой предшественник 8080 -- это 8008, сделанный как однокристальный вариант процессора на рассыпухе для какого-то там терминала. 4004 и 4040 тут никаким боком, общего у них с 8008 разве что технология p-mos.
Да и 8080 нельзя назвать сверх-популярным, т.к. тот же Z80 выдернул у него флаг популярности довольно быстро. Нынешнее обоготворение 8080 -- это уже мифотворчество. До того момента, как 8088 выбрали в ibm, интел была одной из многих и наравне со многими другими производителями микропроцессоров.

SIISII
28.06.2023 13:07Ну, 8080 действительно был очень популярен, и Z80, хотя и превзошёл его по популярности, был программно совместим с 8080 -- собственно, это и стало одной из причин его популярности. Нередко Z80 использовался именно как более быстрая и удобная для электронщика (одно напряжение питания и готовые управляющие сигналы шины) замена 8080, при этом программы оставались старые, рассчитанные на 8080, и не использовали дополнительные возможности Z80,




RAMona91
28.06.2023 13:07Спасибо за статью, быто интересно)
Вспоминаю как на экзамене по информатике мне попался на эту тему билет. Ммм, ностальгия)


SlFed
28.06.2023 13:07+2В студенческие годы даже песня с припевом была :
Байт, байт - восемь бит всего лишь.
Байт, байт, слёз моих не стоишь.
Байт, байт, бисова личина.
Байт, байт - ABENDа причина.
PuerteMuerte
28.06.2023 13:07+7Размер слова является кратным размеру байта. Для меня это оставалось непонятным долгие годы, причём в Wikipedia этому даётся весьма туманное определение («слово – это естественная единица данных, используемая в конкретной архитектуре процессора»). Изначально я думала, что размер слова равен размеру регистра (64 бита на x86-64).
Это верное определение. Машинное слово - аппаратно-зависимая величина, и равна она не размеру регистра, а размеру шины процессора. Т.е. слово определяет естественный размер "порции данных", которые процессор получает из памяти и прочих устройств. И даже если процессор умеет адресовать информацию побайтово, получать он будет её все равно словами, но будет выполнять дополнительные действия по извлечению конкретного байта из слова.
С другой стороны, типы данных в конкретных языках программирования а-ля WORD/DWORD и т.д. создавались в те времена, когда машинное слово в х86 было 16-битным, и ради совместимости их не стали менять тогда, когда машинное слово стало сначала 32, а потом 64 бита. Поэтому теперь надо различать машинное слово как характеристику архитектуры, и тип данных "слово" в конкретном языке.
SIISII
28.06.2023 13:07Слово с точки зрения электронщика действительно связано с аппаратной реализацией, но оно может не соотносится со словом с точки зрения программиста. ЕС-1020 -- архитектурно 32-разрядная машина (Система 360), однако имеет 8-битовое АЛУ и 18-битовую ширину доступа к ОЗУ (16 информационных и два контрольных разряда). ЕС-1050 -- это тоже 32-разрядная машина (та же Система 360), но основное АЛУ там 64 бита, если память не изменяет, а слово памяти -- 72 бита (8 информационных байтов плюс по одному контрольному биту на каждый байт). Ну и чему тут будет равен размер слова, если исходить из аппаратуры, а не архитектуры (т.е. представления машины с точки зрения программиста)? Плюс исторический контекст влияет. Вот отсюда и весь хаос с этим термином.

tania_012
28.06.2023 13:07+1Лучше бы задаться вопросом: почему Билл родил DOS?

bolk
28.06.2023 13:07+6Он его не родил, а купил.
saboteur_kiev
28.06.2023 13:07Все-таки он портировал и допилил.
И вообще, хватит принижать достоинства Билла. В те годы лучшие программисты писали именно так.PuerteMuerte
28.06.2023 13:07+1Он как раз купил. Портировать ему не надо было, DOS уже изначально писался под 8086, а пилил не он, пилил Тим Патерсон, и до Майкрософт, и продолжил уже в Майкрософт.
saboteur_kiev
28.06.2023 13:07Свечку держали?
Я вот вижу исторические примеры кода, которые лично Билл добавлял. Пусть он сделал не самую большую часть технической работы, но он отлично представлял себе что нужно делать, и как это делать, чтобы оно стало популярным и востребованным.PuerteMuerte
28.06.2023 13:07+4Простите, но история MS DOS - вообще не секрет, и даже если там есть чуть-чуть кода, который добавил лично БГ (возможно, что есть, но далеко не факт), это не меняет того факта, что он там ничего не портировал, и не допилил. Вместе с покупкой MS DOS Майкрософт наняла в команду чувака, который её и написал, и он же её продолжил разрабатывать уже на новом месте. А так, ну что там БГ себе представлял, вопрос остаётся открытым, мы можем только фантазировать на эту тему. Что-то представлял, вероятно. Но с другой стороны, ранняя (да и поздняя, чего греха таить) MS DOS по юзабилити ничем не отличалась от других файловых мониторов 1970-х годов, и сказать, что там кто-то принимал какие-то особые технические решения, чтобы оно стало популярным и востребованным - было бы чересчур опрометчиво.
Главное решение, которое обеспечило DOS популярность и востребованность - договор с IBM.
UPD: Ради любопытства полистал сейчас исходники MS DOS, которые Майкрософт выложила, версии 1.25 и 2.0. Где вы там код БГ увидели-то? Там вообще в комментариях не фигурирует ни один разработчик, кроме упомянутого Тима Паттерсона в версии 1.25.

Wesha
28.06.2023 13:07Где вы там код БГ увидели-то?
Ну, Королёв "семёрку" тоже не сам разработал...
bolk
28.06.2023 13:07+1Причём тут Королёв, человек пишет очень конкретно: «я вот вижу исторические примеры кода, которые лично Билл добавлял».
Wesha
28.06.2023 13:07А ему в ответ другой человек пишет не менее конкретно: "Где вы там код БГ увидели-то?"
bolk
28.06.2023 13:07+1Именно. Один человек утверждает, что там есть примеры кода, который добавлял Гейтс, второй спрашивает где они. Причём тут Королёв неясно совершенно.
Wesha
28.06.2023 13:07При том, что "Гейтс разработал MS-DOS" примерно как "Королёв разработал Р-7". Руками водили — это да.
bolk
28.06.2023 13:07+1Причём тут вождение руками, если человек утверждает, что Гейтс код писал и это где-то видно? Где тут про вождение руками?
Wesha
28.06.2023 13:07-4Ни при чём тут Королёв, ни при чём, ради Сагана успокойтесь и ступайте себе с миром!
saboteur_kiev
28.06.2023 13:07+1А так, ну что там БГ себе представлял, вопрос остаётся открытым, мы можем только фантазировать на эту тему. Что-то представлял, вероятно
Ну конечно совсем ничего. Просто будучи школьником, еще задолго до MS-DOS написал пару программ, заработав десяток-другой тысяч долларов (на те деньги). Все же так могли?
Как минимум он смог написать свою реализацию Бейсика для 8080, по его словам это наверное самый крупный самостоятельный проект.
Ну и вы забываете, что в те годы систем контроля версий не существовало, коммитов не существовало, поэтому кроме отдельно взятых комментариев, найти что-либо не выйдет. Оно не спрятано, его просто нет.
Вот я вот могу предположить, что вы никогда в жизни не рисовали в детстве. Или докажите скриншотами? Ну может найдете 1-2, но ведь это будет даже не 1%?
также и в исходниках ДОС - могло быть куча мелких правок, дополнений. Не обязательно какая-то утилита от начала и до конца написана и исправлена одним человеком. На заре все делали свой технический вклад, кто больше, кто меньше.И добавьте к этому отсутствие интернета, отсутствие комьюнити, отсутствие документации в том виде, в котором она есть сейчас, отсутствие open source и примеров готового кода на разные случаи жизни.
Я вот изучал бейсик в похожих условиях, когда в лучшем случае доступно описание нескольких команд и простенькая программка в журнале. На самом компе берешь тот же БК010-01, оператор circle и методом тыка догадываешься какие там могут быть параметры. Много сможешь сделать в школьном возрасте?
В общем относиться к его знаниям снисходительно - неуважать собственное понимание истории ИТ.PuerteMuerte
28.06.2023 13:07+1Ну конечно совсем ничего. Просто будучи школьником, еще задолго до MS-DOS написал пару программ
Простите, но мы вроде вполне определённо про портирование и допиливание MS DOS Гейтсом говорили, а не про разработку Бейсика, разве нет? Причём тут вообще Бейсик-то? Что Гейтс написал реализацию Бейсика под Альтаир на 8080, это тоже общеизвестный факт, но он никакого отношения к обсуждаемому топику не имеет.
также и в исходниках ДОС - могло быть куча мелких правок, дополнений.
А могло и не быть. Не забывайте, что систем контроля версий не существовало, общего репозитория - тоже не было. И если у программы есть свой выделенный разработчик, другие в неё просто не лезли. Потому что возможности объединить изменения тоже никакой не было. Рабочий экземпляр кода хранился на машине у собственно разработчика, и чтобы Гейтс внёс туда какие-то изменения, он должен был садиться за компьютер Патерсона. Зачем бы ему это делать? Плюс, также не забывайте, что ранний DOS с одной стороны маленькая софтинка, в которой совершенно нечего делать второму разработчику, с другой стороны - достаточно сложная софтинка с кучей различных структур данных и мудрёных алгоритмов, и чтобы её разрабатывать, во всём этом надо хорошо ориентироваться. И знаете, подробно разбираться во всего лишь ещё одном продукте среди кучи других - непозволительная роскошь для топ-менеджера активно растущей компании.
В общем относиться к его знаниям снисходительно - неуважать собственное понимание истории ИТ.
Даже не представляю, в каком месте мы перешли от "Билл Гейтс не портировал MS DOS" к "Относимся к его знаниям снисходительно" через "Гейтс написал Бейсик". Давайте всё-таки темы не будем подменять по ходу дела, а?

mikelavr
28.06.2023 13:07+10"Размер слова является кратным размеру байта." - ОШИБКА.
Размер слова может быть любым, как было удобно разработчику аппаратуры. Вот пример из документации на микроконтроллер PIC16F628:
Separating program and data memory further allows instructions to be sized differently than 8-bit
wide data word. Instruction opcodes are 14-bits wide making it possible to have all single-word instructions. A 14-bit wide program memory access bus fetches a 14-bit instruction in a single cycle.

nikolz
28.06.2023 13:07+11"В качестве ещё одной причины использования BCD кто-то назвал финансовые вычисления. "
и далее Ваши рассуждения ошибочны.
Причина в том , что десятичное дробное число может не иметь точного представления в двоичном формате, но имеет точное представление в формате BCD.
Поэтому преобразование дробных значений долларов из десятичной системы счисления в двоично-десятичную и обратно выполняется точно, а в двоичную и обратно с ошибкой округления.

NooneAtAll3
28.06.2023 13:07Эй, вы тут карты не путайте
БЦД для целых чисел. И удобней потому что "единицы и десятки" отбросить легче.
А уж целочисленное деление погрешностей не создаёт хоть в двоичной, хоть в десятичной форме
nikolz
28.06.2023 13:07+5Относительно Intel 8008 как оправдание применения байта рассуждение ошибочное.
До этого процессора был Intel 4004.
И все калькуляторы прошлого века имели 4 разрядный сумматор по причине, что 4 двоичных разряда достаточны для хранения одной десятичной цифры. Поэтому 4 бита - достаточно для вычисления над десятичными числами любой разрядности.

gnomeby
28.06.2023 13:07+5и меня не удовлетворило объяснение, что «компьютеры используют двоичную
систему счисления, поэтому степень двойки подойдёт лучше всего».Потому что один из наборов линий мультиплексора и демультиплексора и соответственно шифратора и дешифратора кратно степени 2, а это очень важный компонент железа.

Javian
28.06.2023 13:07Мне недавно рассказывали версию, что происхождение 8 бит связано с системой команд PDP11.

omxela
28.06.2023 13:07+2PDP11 - шестнадцати разрядная машинка 70-х. А коммерчески весьма успешная IBM-360 - машинка 60-х, и именно в этой системе был 8-ми битный байт. Естественно, причин могло быть несколько, и они в статье перечислены. Но не все они равнозначны по весам. У меня с 70-х гг. сложилось ощущение, что именно успех системы 360 породил 8-ми битный мэйнстрим.
Javian
28.06.2023 13:07Итого — искать надо в англоязычной литературе, когда появилось это слово, и что понимали под этим термином.
nikolz
28.06.2023 13:07+4Рассказываю, почему процессоры Intel (x86) есть байт и почему байт - это 8 бит.
Вычислительная техника создавалась для обработки чисел, в основном, для банков и печатания текстов - замена машинописи.
Поэтому для финансовых вычислений придумали двоично-десятичный код = это 4 бита. И это был следующий за битом минимальный размер.
Для представления текста имеем:
1837 - код Морзе 6 бит
1874 - код Бордо 5 бит . Код Бодо допускал передачу заглавных и строчных букв, цифр и некоторых специальных символов. Однако его способность представлять нелатинские письмена была ограничена, и в конечном итоге он был заменен более продвинутыми стандартами кодирования, такими как ASCII - 8 бит -официально 1961 год.
Первый процессор Intel 4004 - 1971 год, как и следующий Intel 8008 -1972 год не получили широкого распространения и лишь Intel 8080 -1974 оказался самым востребованным.
Резюме: Для обработки цифр надо 4 бита, а для ASCII - 8 бит, которые удобно хранят две двоично-десятичные цифры. Поэтому не было процессоров не на 3 , 5 или 6 бит.
------------------
Про байт из 8 бит ...
-
Бемер, Роберт Уильям (2000-08-08). "Почему в байте 8 бит? Или так и есть?". Виньетки компьютерной истории. Заархивировано с оригинала 2017-04-03. Извлечено 2017-04-03.
Я пришел работать в IBM и увидел всю путаницу, вызванную ограничением на 64 символа. Особенно когда мы начали думать об обработке текста, для которой требовались бы как верхний, так и нижний регистры.
Добавьте 26 строчных букв к 47 существующим, и получится 73 - на 9 больше, чем могли бы представлять 6 бит.
Я даже внес предложение (с учетом STRETCH, самого первого из известных мне компьютеров с 8-битным байтом), которое позволило бы увеличить количество кодов символов на перфокартах до 256 .
Некоторые люди восприняли это всерьез. Я думал об этом как о подделке.
Итак, некоторые люди начали думать о 7-битных символах, но это было нелепо. В качестве фона используется компьютер IBM STRETCH, обрабатывающий 64-символьные слова, разбитые на группы по 8 (я разработал для него набор символов под руководством доктора Вернера Бухгольца, человека, который придумал термин "байт" для обозначения 8-разрядной группировки). Казалось разумным создать универсальный 8-битный набор символов, обрабатывающий до 256. В те дни моей мантрой было "степени 2 - это магия". И вот группа, которую я возглавлял, разработала и обосновала такое предложение .
Это был слишком большой прогресс, когда его представили группе стандартов, которая должна была формализовать ASCII, поэтому они на данный момент остановились на 7-битном наборе, или же на 8-битном наборе, оставив верхнюю половину для будущей работы.
IBM 360 использовал 8-разрядные символы, хотя и не ASCII напрямую. Таким образом, "байт" Бухгольца прижился повсюду. Мне самому это название не нравилось по многим причинам. В проекте было 8 битов, перемещающихся параллельно. Но затем появилась новая часть IBM с 9 битами для самоконтроля, как внутри центрального процессора, так и в ленточных накопителях. Я представил этот 9-битный байт прессе в 1973 году. Но задолго до этого, когда я возглавлял отдел программного обеспечения Cie. Булл во Франции в 1965-66 годах я настаивал на том, чтобы слово "байт" устарело в пользу "октета".
Вы можете заметить, что мое предпочтение тогда теперь является предпочтительным термином.
Это оправдано новыми методами связи, которые могут передавать 16, 32, 64 и даже 128 бит параллельно. Но некоторые глупцы теперь ссылаются на "16-битный байт" из-за этой параллельной передачи, которая видна в наборе UNICODE. Я не уверен, но, возможно, это следует называть "hextet".
Но вы заметите, что я по-прежнему прав. Степени 2 по-прежнему волшебны!.

allter
28.06.2023 13:07+2ASCII требует 7 бит. Причём один бит, если не учитывать несущественную пунктуацию, нужен только для выражения строчных букв и управляющих символов. Т.е. 6 бит хватит для выражения всех символов 0x20-0x5F, которые достаточны для написания любой программы на фортране и даже на C использованием триграфов.
Статья говорит о многом, но так и не даёт адекватного ответа, что было решающим: более удачная упаковка BCD или все другие причины.
nikolz
28.06.2023 13:07+1Это был слишком большой прогресс, когда его представили группе стандартов, которая должна была формализовать ASCII, поэтому они на данный момент остановились на 7-битном наборе, или же на 8-битном наборе, оставив верхнюю половину для будущей работы.
8-ой бит - альтернативная кодировка.
8-разрядные коды Расширенный ASCII и ISO /IEC 8859, : UTF-8
allter
28.06.2023 13:07Не заметил таких соображений в представленных документах. ASCII разрабатывался как телеграфный (телетайпный) код, поэтому, разумеется, лишний бит им был не нужен. Т.е. про Extended ASCII при его разработке никто не думал - это уже позже разработали различные варианты и назвали "задним числом".
К слову, триграфы в C добавили, разумеется, не для того, что бы писать на 6bit ASCII (который, оказывается, существует и реально применяется в AIS для предупреждения о столкновении судов на море). А из-за того, что сделали разновидность 7-bit ASCII, где некоторые символы пунктуации заменили на национальные буквы.
Wesha
28.06.2023 13:07ASCII разрабатывался как телеграфный (телетайпный) код, поэтому, разумеется, лишний бит им был не нужен.
Как это "не нужен"? А контроль чётности???
PuerteMuerte
28.06.2023 13:07+1Резюме: Для обработки цифр надо 4 бита, а для ASCII - 8 бит
ASCII требует 7 бит, и собственно, даже ранние сетевые протоколы это учитывали.
nikolz
28.06.2023 13:07+1Это был слишком большой прогресс, когда его представили группе стандартов, которая должна была формализовать ASCII, поэтому они на данный момент остановились на 7-битном наборе, или же на 8-битном наборе, оставив верхнюю половину для будущей работы.
8-ой бит - альтернативная кодировка.
8-разрядные коды Расширенный ASCII и ISO /IEC 8859, : UTF-8
IBM 360 использовал 8-разрядные символы, хотя и не ASCII напрямую. Таким образом, "байт" Бухгольца прижился повсюду.

vadimr
28.06.2023 13:07IBM S/360, конечно, использовала 8-разрядные символы EBCDIC, но как следствие байтовой архитектуры, а не как причину. В EBCDIC того времени больше половины кодового пространства не заполнено, а сама кодировка представляет собой уплотнённую форму 12-битового кода для перфокарт, который, в свою очередь, выбирался из тех соображений, чтобы было поменьше единичек рядом, так как от большого количества соседних дырок рвался картон.
nikolz
28.06.2023 13:07Я привел вроде бы перевод статьи с упоминанием автора слова байт.
Что не понятно?
В дополнение могу сказать следующее.
Так как основа вычислительной техники двоичный элемент и булевая алгебра (Джордж Буль ( "Математический анализ логики" -1847 г и "Исследовании законов мышления" -1854 г) , то создание вычислительных устройств аппаратно проще всего делать на основе 2^n системы счисления.
Поэтому сначала была логика и триггер - элемент с двумя устойчивыми состояниями , потом 4-х разрядный регистр, 8-ми, 16, 32, 64 и т д. А микропроцессор по словам его создателей(основателей Intel) - (не дословно) это логическое устройство , логику которого можно создать после производства самого устройства в виде чипа.
При этом 50 лет назад никто не заморачивался вопросом сколько бит назвать байтом или изготовление 3 , 5,6 или 7 разрядных вычислителей.
Полагаю, что и разрядность вычислителя выбирали как степень двойки, т е 4,8,16 и т д.
vadimr
28.06.2023 13:07Непонятно, почему вы отождествляете байт как единицу адресации с байтом как единицей кодирования текста.
Именно байтовая адресация была придумана в S/360, и она закрепила 8-битовый байт (выделив его среди прочих) как способ кодирования текста тоже. Хотя больше 128 актуальных кодов символов в то время и ещё 15-20 лет после этого ни одна машина не использовала.
При этом большинство компьютеров времён появления S/360 имело размер слова, не равный степени двойки. Так как обычно не требуется дешифратор номеров битов в слове.
nikolz
28.06.2023 13:07поясняю, я не отождествляю.
Вопрос в статье не про ASCIIZ, а про происхождение слова "байт" как название 8 бит. Привел перевод статьи, где рассказывается как обозвали 8 бит байтом (могли бы и бейтом или кейтом) никакого в этом тайного смысла нет. Пришло на ум слово байт , как объяснял автор, чтобы не путать со словом "бит". Ну и все.
------------------------
Далее я попытался объяснить разрядность вычислителей (микропроцессоров ) в том числе x86 и изложил свое представление. Для вычислений достаточно 4 разряда, а для хранения и обработки текста 4 мало, но разрядность вычислителей ( сумматоров) никто не думал даже в страшном сне делать 5 или 6 или 7 разрядов. Делали тоже как степень 2 и следующее за 4 разрядами это 8. И вот это 8 подходит для обработки текста так как ASCIIZ хотя и 7 бит, но как приведено в переводе выше представленного мною, 8-ой бит - расширение. На самом деле полагаю, что проблема опять в сложности обработки на вычислителе 7 бит вместо 8 бит. Чтобы использовать свободный восьмой бит в памяти надо делать упаковку и распаковку, а 50 лет назад никто упаковкой и распаковкой не заморачивался никто.
А вот для обращения с памятью изначально в 8080 заложили 16 разрядный регистр адреса.
В итоге при обработке финансов IBM внедрила 2-10 код. Для научных вычислений фиксированную и плавающую точку, для текста байт - это символ.
Адресация памяти побайтно, так как вычислитель в Intel8080 - 8 разрядов.
vadimr
28.06.2023 13:07Но в старших моделях S/360 вычислитель был 32-разрядный, а адресация памяти всё равно побайтно. До 8080 ещё жить и жить надо было.
nikolz
28.06.2023 13:07Тогда читайте перевод статьи, который я привел выше. Это про IBM.
я рассказал свое понимание и историю процессоров Intel (x86)
Про IBM я подробно не интересовался. Будет время -посмотрю.
вот на хабре статья по теме:
-

victor_1212
28.06.2023 13:07+2>Статья на Wikipedia гласит, что 8-битный байт впервые начал использоваться в IBM System/360 в 1964 году.
Brooks, Amdahl и др. пришли в группу разработки system 360 после stretch (ibm 7030), там байт мог быть равен 4,6,8 bit, вообще архитектура 360 примерно вышла из 7030 как сильно упрощенный вариант, ниже приведена страничка из ранней спецификации stretch 1957 года с обсуждением байтовой организации



FakeOctopus
28.06.2023 13:07+2"если вы проектируете двоичный компьютер в англоязычной стране"
При чём здесь английский язык. Русский язык то же умещается в 7 бит. И европейские языки умещаются. Другое дело если в стране иероглифы.

lealxe
28.06.2023 13:07Мне нравится версия, что потому, что степени двойки (-1, что можно использовать на четность) - оптимальный размер слова кода Хэмминга. Во всяком случае она чуть более весомой кажется.
vadimr
28.06.2023 13:07+4В статье содержится ряд истинных фактов, но кроме этого написано очень много ерунды, являющейся результатом предположений автора от незнания.
По поводу научных вычислений. Просто в 1960-е годы в научных вычислениях лидировали компьютеры фирмы CDC, конструктором которых, кстати, был небезызвестный Крей. И там использовались 60-разрядные слова. Которые ни на какие байты не делились, но в них можно было упихать 10 штук символов в 6-битовой кодировке.
60-разрядное слово – это объективно достаточно хороший вариант, если не запариваться на байты. В теперешнем 64-разрядном типе IEEE 704 double можно без потери общности убрать 4-5 бит из мантиссы. В CDC можно было использовать ненормализованные вещественные числа, в которых мантисса могла рассматриваться как 48-разрядное целое. Иметь один и тот же формат для целых и вещественных чисел было удобно для математических расчётов, так как не нужны были отдельные операции для преобразования.
С тем же успехом, конечно, слова в CDC могли бы быть и 64-разрядными, но они просто не додумались до концепции байта.
victor_1212
28.06.2023 13:07+1> С тем же успехом, конечно, слова в CDC могли бы быть и 64-разрядными, но они просто не додумались до концепции байта
следущее поколение - CDC STAR-100, Cray-1 были 64-разрядными, требования к точности поднялись + стандартизация ASCII

boh_muh
28.06.2023 13:07Да, только вот упихивать туда уже ничего не стали! Никогда не смотрели на CHAR_BIT на Cray? :-)
vadimr
28.06.2023 13:07Это следствие неприспособленности языка Си к машинам с небайтовой архитектурой и отсутствия в нём packed array. На Паскале в таких случаях можно было упихать (собственно, в первой версии Паскаля строки символов существовали именно в виде такого упиханного в слово типа ALFA). А в Си требуется, чтобы на каждый элемент массива существовал указатель.
Поэтому упихать-то на Крее можно, но язык Си не позволяет описать такую структуру данных на основе типа char.
boh_muh
28.06.2023 13:07Ну возьмем примерно любую архитектуру с байтами и большим словом (SPARC, Alpha, HP и т.п.). Байты есть, массив сделать можно, указатель можно, но вот если обратиться по указателю, не выровненному по границе слова - bus error.
victor_1212
28.06.2023 13:07> Никогда не смотрели на CHAR_BIT на Cray?
нет работать не пришлось, на stackoverflow есть об этом слегка, дело в адресации конечно, если нет возможности доступа к отдельным байтам как на Cray, как-то не вижу что компилятор может с этим сделать, в этом смысле Cray бескомпромиссная машина, в отличие от той же ibm stretch, разработка которой обошлась намного дороже, как и многие неудачные проекты супер поучительный пример
boh_muh
28.06.2023 13:07Ну адресация да, но вообще, может просто забили - у них там Наука, чего им байтики и символы.
Просто, кажется, примерно во всех больших микропроцессорных архитектурах к памяти можно обратиться только с каким-то выравниванием (иначе BUS ERROR), но байтики есть и как-то работать с ними можно.

int0Ah
28.06.2023 13:07+2Мой папа до 1992 года работал памятником в почтовом ящике (то есть разрабатывал ОЗУ для всяких специальных машин на одном из предприятий ВПК СССР) и рассказывал всякие вещи, которые мне - школьнику, знавшему кое-что о ПК на х86 - казались дикими. Например: "У нас там было 37-битное слово". Чуть позже я узнал о коде Хемминга. То есть в данном примере в слове было 32 бита данных и 5 бит кода коррекции ошибок.
В общем, это я к чему... Слово может иметь разный размер даже в разных частях одного процессора. А тот факт, что в x86 принято называть словом 16-битный тип данных - обычный историзм.boh_muh
28.06.2023 13:07+1Предполагаю, он говорил про Минск-22, в котором слово было честные 37 бит. Байт ("информационный символ") там был при этом 7 бит.
PuerteMuerte
28.06.2023 13:07Про Минск-22 ему бы дедушка разве что рассказывал. В 1980-е эти Мински уже на металл все порезали, они по быстродействию уступали даже настольным калькуляторам Искра-1250.
boh_muh
28.06.2023 13:07Ну я ориентировался на "было", то есть думал, что папа не прям про 1992 год рассказывает, а про то, с чем довелось работать. А так да, последний Минск сделали в 1975, думаю к 1992 все уже выключили.
PuerteMuerte
28.06.2023 13:07Просто он написал, что "мне - школьнику, знавшему кое-что о ПК на х86", ну т.е. речь явно шла уже как минимум, о конце 80-х, или начале 90-х.
int0Ah
28.06.2023 13:07Нет, речь шла о бортовых машинах под сравнительно узкие задачи, например, в области гидроакустики. Скорее всего, кроме номера изделия у них других имён и не было. Однако, диапазон дат разработки как раз мог быть с конца 60-х до начала 90-х.
Но конкретное количество бит, которое мне тогда показалось странным я естественно не помню, всё-таки под 30 лет прошло. И да, как отметили ниже пример с Хеммингом я привёл явно некорректный, то есть наверняка там было не 37. Возможно, слово было 32, а из них 27 - данные.
SIISII
28.06.2023 13:07Точней, Минск-2, -22 и -32. Ну и добавлю, что путаница может возникать ещё и из-за разного представления машинного слова для программиста и электронщика. Скажем, для программиста Система 360 (ЕС ЭВМ) -- всегда 32-разрядная, однако в зависимости от модели память могла быть организована по-разному (у ЕС-1020 ширина доступа -- 18 бит, из коих два -- контрольные разряды для двух информационных байтов, у ЕС-1035 -- 72 бита: 8 информационных байтов плюс восемь разрядов для контроля и коррекции по коду Хэмминга, и т.п.), поэтому электронщик, рассуждая о памяти, мог использовать термин "слово" по отношению к физическому слову памяти, а не в том значении, в котором его использует программист.

brawaga
28.06.2023 13:07+1Не хватит 5 бит в коде Хэмминга для этого случая, потому что для адресации 37 бит надо 6 бит. Таким образом, слово получается 38 бит.

checkpoint
28.06.2023 13:07+7"В начале было слово, и слово было 2 байта, а больше ничего не было"...
Hidden text
1 В начале было слово, и слово было 2 байта, а больше ничего не было.
2 И отделил Бог единицу от нуля, и увидел, что это хорошо.
3 И сказал Бог: да будут данные, и стало так.
4 И сказал Бог: да соберутся данные каждые в свое место, и создал
дискеты, и винчестеры, и компакт-диски.
5 И сказал Бог: да будут компьютеры, чтобы было куда пихать дискеты, и
винчестеры, и компакт-диски, и сотворил компьютеры, и нарек их хардом, и
отделил хард от софта.
6 Софта же еще не было, но Бог быстро исправился, и создал программы
большие и маленькие, и сказал им: плодитесь и размножайте, и заполняйте
всю память.
7 Hо надоело Ему создавать программы самому, и сказал Бог: создадим
программиста по образу и подобию нашему, и да владычествует над
компьютерами, и над программами, и над данными. И создал Бог
программиста, и поселил его в своем ВЦ, чтобы работал в нем. И повел Он
программиста к дереву каталогов, и заповедал: из всякого каталога можешь
запускать программы, только из каталога Windows не запускай, ибо маст
дай.
8 И сказал Бог: не хорошо программисту быть одному, сотворим ему
пользователя, соответственно ему. И взял Он у программиста кость, в коей
не было мозга, и создал пользователя, и привел его к программисту; и
нарек программист его юзером. И сидели они оба под голым ДОСом, и не
стыдились.
9 Билл был хитрее всех зверей полевых. И сказал Билл юзеру: подлинно ли
сказал Бог: не запускайте никакого софта? И сказал юзер: всякий софт мы
можем запускать, и лишь из каталога Windows не можем, ибо маст дай. И
сказал Билл юзеру: давайте спорить о вкусе устриц с теми, кто их ел! В
день, когда запустите Windows, будете как боги, ибо одним кликом мышки
сотворите что угодно. И увидел юзер, что винды приятны для глаз и
вожделенны, потому что делают ненужным знание, и поставил их на свой
компьютер; а затем сказал программисту, что это круто, и он тоже
поставил.
0A И отправился программист искать свежие драйвера, и воззвал Бог к
программисту и сказал ему: где ты? Программист сказал: ищу свежие
драйвера, ибо нет их под голым ДОСом. И сказал Бог: кто тебе сказал про
драйвера? уж не запускал ли ты винды? Программист сказал: юзер, которого
Ты мне дал, сказал, что отныне хочет программы только под винды, и я их
поставил. И сказал Бог юзеру: что это ты сделал? Юзер сказал: Билл
обольстил меня.
0B И сказал Бог Биллу: за то, что ты сделал, проклят ты пред всеми
скотами и всеми зверями полевыми, и вражду положу между тобою и
программистом: он будет ругать тебя нехорошими словами, а ты будешь
продавать ему винды.
0C Юзеру сказал: умножу скорбь твою и истощу кошелек твой, и будешь
пользоваться кривыми программами, и не сможешь прожить без программиста,
и он будет господствовать над тобой.
0D Программисту же сказал: за то, что послушал юзера, прокляты
компьютеры для тебя; глюки и вирусы произведут они тебе; со скорбью
будешь вычищать их во дни работы твоей; в поте лица своего будешь
отлаживать код свой.
0E И выслал Бог их из своего ВЦ, и поставил пароль на вход.
0F General protection fault

Akina
28.06.2023 13:07+2байты и слова. В чём же отличие между ними?
Если "байт" - это устоявшееся именование минимальной единицы адресуемой памяти, то со "словом" всё плохо - нет для него столь же однозначного определения...
Что же до слова в x86 - там этот термин был использован для именования наибольшей единицы информации, которая может быть помещена в регистр процессора. Если Вы помните, то у процессора была горсть 16-битных регистров, часть из которых были доступны только "всё сразу", а часть были "поделены" на два 8-битных регистра, доступных независимо (например, 16-битный регистр AX делился на два 8-битных регистра AH и AL).
Отображение это всё нашло, например, в ассемблере. Ключевое слово DB обозначало байт, DW соответственно слово. Ну и двойное слово DD - единица информации, составляющая полный адрес ячейки оперативной памяти, который в памяти занимал 4 байта, а в процессоре использовал два регистра, регистр сегмента и регистр смещения в нём (например, ES:BX). Позже, когда появилась 32-битная архитектура, появились и дополнительные ключевые слова (скажем, DQ - четверное слово). А уже имеющиеся - не менялись. Считайте что по причине обеспечения обратной совместимости.
SIISII
28.06.2023 13:07Ну а в Системе 360 или в ARM, которые изначально были 32-разрядными, слово -- именно 32 бита, а 16 бит -- полуслово. Поэтому и путаница с этим термином, но автору статьи явно было лень посмотреть на историю разных архитектур.

kasiopei
28.06.2023 13:07+1А еще путаница между килобайтами и кибибайтами
checkpoint
28.06.2023 13:07+3Согласен, кибибайты - нелепое изобретение, которое зачем-то массово навязывается.
checkpoint
28.06.2023 13:07+1На счет кодировки символов. Старички хорошо помнять, что в машинах DEC (СМ ЭВМ) использовалась кодировка RADIX-50 которая предполагала размещение сразу трех символов в двух байтах (в одном 18-битном слове + два резервных бита на ранних PDP и в одном 16-битном слове на PDP-11 и VAX-ах). Это позволяло машине работать сразу с 6-ю символами одним машинным словом размером 36 бит. Теория о том, что ASCII является причиной байта IMHO не состоятельна, скорее наоборот - таблица ASCII была подогнана под 8-битный байт.
SIISII
28.06.2023 13:07На момент появления байта US ASCII была 7-битной кодировкой, насколько помню; 8-битной ASCII стал уже в 1970-80-х. RADIX-50 позволял плотнее упаковывать символы для экономии памяти, что было важно для мини-ЭВМ с их небольшой разрядностью (64 Кбайта адресуемой памяти, если говорить про наиболее популярные PDP-11; VAX можно не рассматривать, ибо это уже вторая половина 1970-х). В то же время, эта кодировка очень ограничивала набор символов: собственно, только большие английские буквы, цифры и ещё несколько знаков, что совершенно недостаточно во многих задачах (из-за этого, кстати, столь ограничен был набор допустимых символов в именах файлов на PDP-11). Кроме того, упаковка-распаковка требовали выполнения дополнительных операций, т.е. прилично снижали производительность.


emusic
28.06.2023 13:07Размер байта представляет минимальную единицу данных, которую можно адресовать
Это верно только для относительно современных компьютеров (где-то с 1970-х). В более ранних часто встречалась только словная адресация.

SuperFly
28.06.2023 13:07Чуть-чуть оффтоп - а есть ли какая-то объективная причина, почему человечество использует десятичную систему счисления? Т.е. были же в истории и 6-ричные, 12-ричные, и 20-ричные, и даже 60-ричные. Есть ли какое-то объективное (математическое?) преимущество у 10? Или просто так сложилось, 10 пальцев и все тут?

Tuvok
28.06.2023 13:07Та же причина, что способствовала переходу на СИ от имперской - более удобные вычисления в уме, кратности 10. Легко возводить числа в степень, легко делить на 10, достаточно только перенести запятую.
PuerteMuerte
28.06.2023 13:07+2То, что вы пишете - это преимущества позиционной системы счисления, а не десятичной. Вот позиционная появилась из-за удобства. А десятичное основание - да, всего лишь потому что десять пальцев.
Tuvok
28.06.2023 13:07Отнюдь! Ведь и поныне существуют и используются иные системы счисления там, где десятичная неудобна. Например, время - 12-ричная и 60-ричная, были попытки перейти на 10-тичное время, но как видим они провалились. Дата - 12, 30, 365. Угловые градусы - 360. Имперская система, дюжины - 12. Неделя - 7-ричная. В музыке частично 7-ричная, частично по иррациональным основаниям. Ну и в цифровой электронике - двоичная (и как её ассистенты - 8-ричная и 16-ричная). Какой вывод? В общей практике удобнее 10-тичная, в узких специализациях - своя конкретная, наиболее оптимальная для использования. Был бы, к примеру, тристабильный элемент в электронике, была бы тринарная система счисления выгодней бинарной.
Tuvok
28.06.2023 13:07Но по сути да, 10 пальцев исторически сложилось, как 2 состояния реле/транзистора. Было бы у нас 4 пальца...
PuerteMuerte
28.06.2023 13:07В общей практике удобнее 10-тичная, в узких специализациях - своя конкретная, наиболее оптимальная для использования.
Простите, но какие системы счисления, кроме тех, которые имеют основанием степени двойки, являются оптимальными для использования? То, что мы имеем рудименты 60-ричной системы во временных исчислениях и тому подобные вещи, это вообще не оптимально, это просто легаси, к которому слишком привыкли, чтобы оптимизировать.
Это не говоря уже о том, что позиционность системы счисления - это ортогональная характеристика к величине её основания :)
SuperFly
28.06.2023 13:07А не путается ли тут причина и следствие? Была б у нас 8-ричная система - считали бы запросто в уме, было б удобно делить на 8, и далее по списку?
Tuvok
28.06.2023 13:07+1На самом деле удобство использования системы счисления лежит в нахождении оптимума между основанием, количеством делителей для максимального значения и сложностью таблицы умножения. Если учесть все эти факторы, то внезапно окажется что 12-ричная система счисления удобнее 10-ичной и она была практически у всех распространена и лежит в основе имперской системы мер. Однако же в распространённости она уступила десятипальцевой. Тут сыграл роль антропометрический аспект использования.
PuerteMuerte
28.06.2023 13:07+1и лежит в основе имперской системы мер
А систему мер какой империи вы имеете в виду? Там, где в ярде три фута, в роде 5.5 ярдов, в чейне 4 рода, а в миле 80 чейнов, что ли? Или ту, где в аршине 16 вершков, в сажени 3 аршина, а в версте 500 саженей?
Имперские системы мер имеют сугубо биологическое происхождение, как и 10 пальцев. Дюйм - фаланга пальца, фут - длина стопы, аршин - длина руки, сажень - длина размаха рук. У них вообще в основе нет никакой системы счисления, это изначально совершенно произвольные цифры, когда-то стандартизованные в процессе формирования государственной метрологии.
Tuvok
28.06.2023 13:07Тут ещё бы добавить что 12-ричная и 60-ричная системы хоть и существуют в рудименте сейчас, однако в выражении своём они используют десятичную систему. Ведь 0..12 (0..24) часов и 0..60 секунд мы пишем используя десятичный алфавит и представление числа, в отличие от 16-ричной где вполне себе расширен алфавит за счёт латинских литер.
vadimr
28.06.2023 13:07+2Объективно десятичная система неудобна. В ней непредставима 1/3, зато представимы 1/5 и 1/10, непредставимые в двоичной. Это плодит огромное количество ошибок.
Если рассуждать с позиций ручного счёта, то объективно была бы удобнее всего 12-ричная система (и даже таблицу умножения легче учить, так как она длиннее, но регулярнее), а с появлением компьютеров, понятное дело, 16-ричная.
Но так получилось, что из-за 10 пальцев имеем то, что имеем.
Tuvok
28.06.2023 13:07Ну как бы я это и написал: https://habr.com/ru/companies/ruvds/articles/743000/#comment_25701562

LesnikSBR
28.06.2023 13:07+2В книжке, доставшейся с zx-spectrum, двоичные вычисления и работа процессора объяснялись на пальцах в буквальном смысле. Я так и запомнил и был уверен что 8 бит - это длинные пальцы обеих рук(большой палец не удобен), а 4-битные половинки байта, переводимые в 16-ричную для удобства - это пальцы одной руки. И 8-битный байт получается удобен для ручной проверки вычислений программистом
SIISII
28.06.2023 13:07Хотя сами изложенные факты верны, выводы зачастую довольно бредовые: автор явно не стремился тщательно обдумать собранную информацию, в т.ч. в историческом контексте (тогда, например, сразу стало бы понятно, почему слово в архитектуре IA-32 aka x86 -- это 16 бит, а не 32 или 64). Постараюсь кратко изложить свою точку зрения на причины появления и закрепления 8-разрядных байтов.
Разрядность разных машин, создаваемых для научных расчётов, т.е. для операций с плавающей запятой, определялась до начала разработки машины, исходя из требуемой точности и диапазона представления чисел. Поэтому до конца 1960-х с разрядностью наблюдается полный хаос. Скажем, у нас "Стрела" была 51-разрядной, машины серии "Минск" -- 37-разрядными, БЭСМ-6 и ряд её предков -- 48-разрядными, а вот "уралы" -- 18-разрядными. То же самое было и на Западе. В общем, везде царили полный разброд и шатание, что, очевидно, было неудобно, когда стали задумываться о переносимости ПО по мере развития техники. В то же время, разрядность как таковая не очень важна, важно лишь обеспечить представление нужного диапазона чисел. Соответственно, если достаточно 24 разрядов, то 32 тоже устроят, если последняя величина представляется удобной, исходя из других соображений.
Необходимость в посимвольной обработке информации, а не только в расчётах. Скажем, хотя БЭСМ-6 и уделывала первые модели ЕС ЭВМ по производительности на математических расчётах, в обработке символьной информации она уступала старшим моделям (хотя и обгоняла самые младшие, но только "грубой силой", за счёт намного более высокого быстродействия -- около 1 млн. оп/с против, скажем, примерно 30 тыс. у ЕС-1020). Причина этого как в неэффективной системе команд, так и в адресации памяти только словами (48 бит для БЭСМ-6), что требовало для выделения отдельного символа использования логических и сдвиговых операций. Соответственно, необходима "символьная" адресация памяти, а сам "символ" должен вмещать достаточно информации для представления необходимых знаков. 6 разрядов для этого мало даже для английского языка, 7 разрядов хватает для английского, но мало для двухъязычных систем (скажем, в западноевропейских языках наберётся ещё десятка два различных дополнительных букв, а ведь среди "капиталистов" были ещё и греки, да и про кириллицу наверняка помнили; вот китайцев-корейцев-японцев с их десятками тысяч иероглифов, надо полагать, в расчёт уже не брали). 8-битный символ, исходя из этих соображений, представляется наиболее подходящим.
Популярность обработки двоично-кодированных десятичных данных (BCD), сохраняющаяся на мэйнфреймах IBM до сих пор (z/Architecture). Причин здесь три. Во-первых, если почти всё время занимает человекочитаемый ввод-вывод, а не расчёты, потеря времени на необходимость перевода из десятичной системы в двоичную и обратно (довольно долгие операции!) может не окупиться по сравнению с прямыми вычислениями в BCD (их поддержка "в железе" не так уж и сложна). Во-вторых, чтоб гарантировать правильность усечения/округления результатов вычислений с точки зрения "десятичного" пользователя -- а это критически важно, скажем, в финансовой сфере, где правила учёта вырабатывались веками и, естественно, для десятичной системы -- надо либо выполнять расчёты полностью по правилам десятичной арифметики, либо учитывать и корректировать возможные искажения при использовании двоичной арифметики. В-третьих, полезно иметь возможность обрабатывать десятичные данные переменной длины, хранимые не в регистрах, ограничивающих разрядность данных, а в памяти. С точки зрения обработки BCD адресуемая единица памяти должна иметь размер, кратный 4 битам, -- и тут 8-разрядный байт, удобный для хранения символов, оказывается очень удобен.
Подозреваю, что эти соображения и привели в итоге IBM к появлению 32-разрядной Системы 360 с памятью, организованной из 8-разрядных байтов. Это, естественно, не изменило в одночасье весь "компьютерный ландшафт", но преимущества подобной организации памяти были вполне очевидны, поэтому постепенно и другие фирмы стали реализовывать аналогичный подход -- благо, патентами всё это огорожено не было. Для вещественных чисел, чтобы обеспечить большой диапазон, была принята "шестнадцатеричная" мантисса (данные хранились не по одному биту, а по четыре, и при нормализации производился сдвиг сразу на 4 разряда, что ухудшало точность). О этом в статье говорится, хотя и неочевидным образом для любых читателей, кроме тех, кто знаком с особенностями Системы 360. Добавлю, что в современной z/Architecture сохранены унаследованные от Системы 360 "шестнадцатеричные" вещественные числа (HFP) и добавлены двоичные вещественные, соответствующие современному стандарту IEEE 754 (BFP), а также десятичные вещественные (DFP) -- в дополнение к тоже унаследованным от Системы 360 десятичным целым переменной длины.

{kind=link}
dlinyj
Об этом тоже писал в своей (не самой удачной) статье Ретроспектива решений прошлого, которое влияет на наше настоящее и будет влиять на будущее
vadimr
Кодировка ASCII исторически не имела никакого отношения к появлению 8-битового байта, тем более что она сначала была 6-битной, потом 7-битной и только к 1980-м годам получила 8-битные расширения.
А что касается байта, то его придумали в IBM (где, кстати, пользовались кодировкой EBCDIC), чтобы иметь возможность масштабировать архитектуру. Младшие модели S/360 по сути на микропрограммном уровне были 8-разрядными, ради дешевизны. Они исполняли 8-разрядные микропрограммы, которые уже реализовывали 32-разрядный машинный язык S/360. А старшие модели сразу аппаратно работали с 32 разрядами. Подробно об этих вещах написано в статьях уважаемого @SIISII.
dlinyj
Да я допускаю, что заблуждаюсь. Но, это тоже не мои фантазии и тоже читал в различных источниках, почему байт стал восьмибитным. И мой вариант таков. Там ниже в статье есть другое объяснение, которое полностью совпадает с вашим.
vadimr
Просто это явный анахронизм. Я ещё застал время, когда 8-битного ASCII не существовало. А байты, естественно, уже давно были.
dlinyj
Ну не прав, не прав. Добросовестно заблуждался.
Dr_Faksov
Я хотел бы заметить, что система IBM 360 строилась для работы с УЖЕ СУЩЕСТВУЮЩЕЙ высокоразвитой телетайпной сетью. Как центры обработки информации передаваемой телетайпами. Именно телетайпы были основными устройствами ввода-вывода данных машин.
PuerteMuerte
Как бы и да, и нет. С одной стороны, телетайпы действительно были первыми диалоговыми терминалами для ЭВМ, с другой стороны, это было сделано просто для удобства, ну потому что телетайп был уже готовой железякой, которая могла вводить данные с клавиатуры и отображать ответ компьютера. Телетайпная сеть тут была не причём, непосредственный ввод информации с неё может быть где-то и был, но уж точно был экзотикой даже для инженеров IBM. Да и сам по себе диалоговый режим при работе с компьютерами тех лет далеко не сразу стал основным. В составе семейства System/360 огромное количество разнообразной периферии, начиная от перфораторов и заканчивая системами оптического распознавания текстов, но телетайпов IBM даже и не предлагала, это уже на местах кто-то колхозил, кому было надо.
vadimr
Телетайпы никогда не были основными устройствами ввода-вывода IBM S/360 и не предполагались к использованию. S/360 в основном была ориентирована на пакетный режим работы, читала данные с перфокарт и печатала результаты на цепном строчном принтере. Все устройства S/360 подключались к специальному канальному интерфейсу. Чтобы туда подключить телетайп, надо было, как верно замечено в предыдущем комментарии, много колхозить с непонятной целью.
SIISII
Консольным терминалом ранних моделей Системы 360 был не телетайп, а пишущая машинка, но уже вскоре появились первые дисплеи. В СССР с ЕС ЭВМ была та же история, разве что дисплеи у нас подзадержались. В частности, лично я в конце 1980-х -- начале 1990-х работал на ЕС-1035, у которой, хотя и были дисплеи (ЕС-7927), но консолью по-прежнему была пишущая машинка. Кстати, это было весьма удобно: в отличие от дисплея, всегда можно посмотреть, что творилось в системе, без дополнительных телодвижений (распечатки файла журнала). Что ж до телетайпов... Да, они были, но относились к тому, что у нас назвали "устройствами телеобработки данных" -- подключались к машине через телефонные/телеграфные линии и модемы, грубо говоря. Плюс, как народ уже говорил, IBM рассматривала свои машины как средства для пакетной, а не диалоговой обработки данных, а им терминалы, кроме консоли, не нужны, так что наличие/отсутствие телетайпов на появление и развитие ранних моделей никакого влияния не оказывало.