
Заполучить определённые сведения с динамического сайта – это не сказать что очень редкая, но всё же специфическая задача, решение которой и предлагает статья (без покидания, насколько возможно, уютных рамок Delphi); под динамической страницей автор понимает не просто сайт, содержащий JavaScript (в современных реалиях найти ресурс без него довольно сложно), а страницу, на которой интересующие разработчика данные изначально отсутствуют в документе, полученном от веб-сервера, появляясь исключительно после отработки JS-кода, каким-то образом вычисляющего их, либо запрашивающего нужную информацию от некоего сервера.
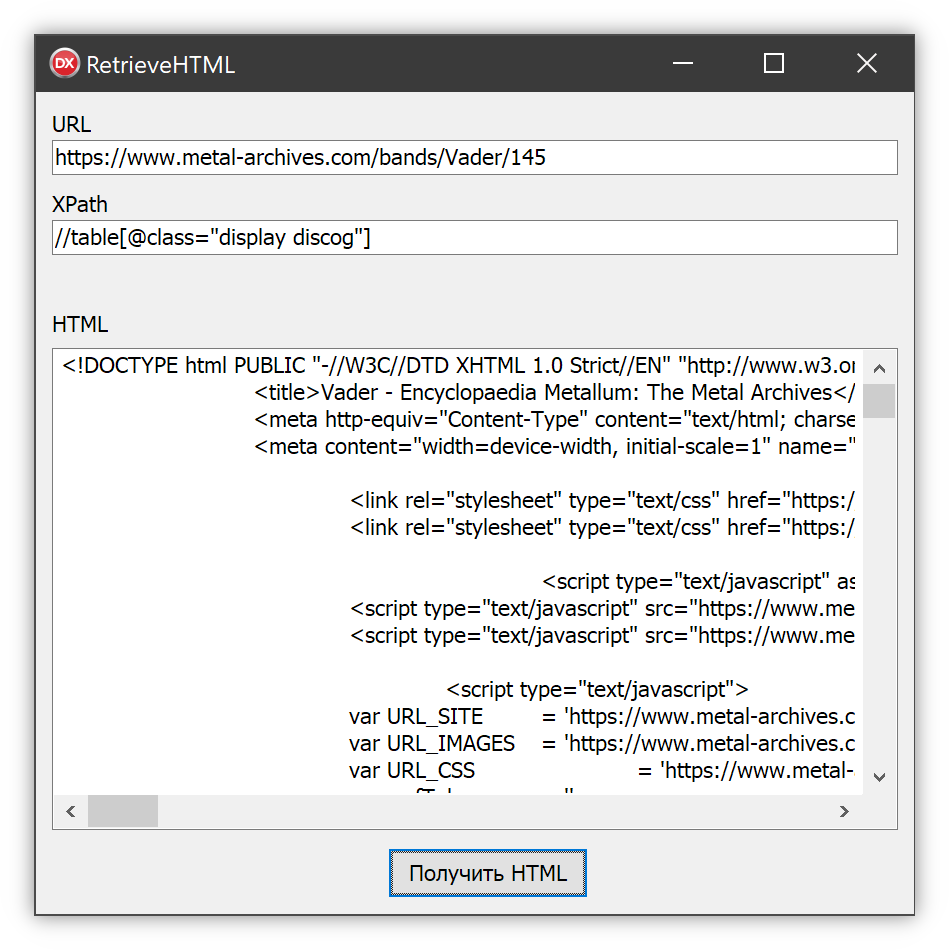
Если читатель раньше не сталкивался с подобной проблематикой, то наверняка приведённое сжатое описание малопонятно, поэтому обратимся к конкретному примеру – пусть требуется извлечь альбомы некоторой группы с metal-archives.com:
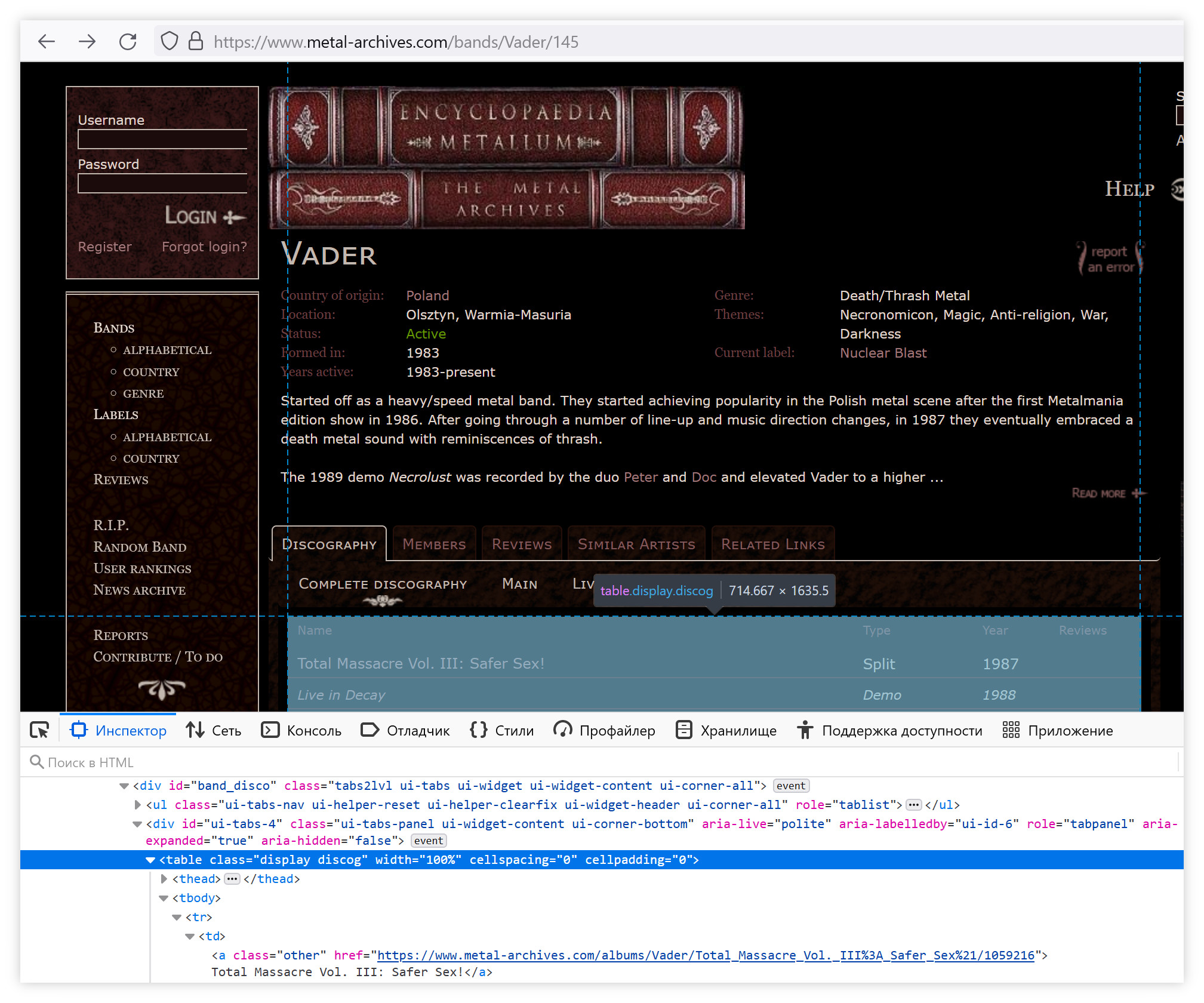
Как можно видеть, их перечень содержится в таблице, входящей в тэг
Таким образом, для подобных сайтов не подходит наиболее предпочтительный и малозатратный метод парсинга, заключающийся лишь в выполнении HTTP-запроса, сразу возвращающего HTML со всем необходимым, – требуется исполнение скриптов; очевидно, что полнее и лучше всего с такой задачей справляется браузер, причём вариантов имеется несколько:
Весь материал делится на две неравные части:
В итоге, поставленная задача станет решаться так (тривиальный код по созданию и уничтожению объектов опущен):
Стоит отметить, что такое решение больше ориентировано на «серверную» многопоточную обработку крупного массива ссылок (по крайней мере у автора так), ибо метод
Далее бо́льшая часть материала посвящена деталям реализации, сосредотачиваясь на вопросах «как» и «почему», поэтому если читателя интересует лишь вопрос использования готового решения, то следует перейти в последний раздел, содержащий примеры двух Delphi-проектов (второй из них необходимый вспомогательный), которые обязательно нужно изучить в случае, если раньше не приходилось иметь дел с CEF, – этот фреймворк требует определённых манипуляций для своего использования.
В плане сложности и объёма кода дальнейшая работа с CEF4Delphi несравнима с крохотными доработками InternetTools, к тому же означенный
Прежде всего стоит немного смутить читателя тем, что предок разрабатываемого класса уже имеет несколько методов
Однако несложно заметить, что это процедуры, к тому же без var- и out-параметров, способных вернуть результат, – всё потому, что методы эти асинхронные (неблокирующие), они лишь запускают процесс формирования кода страницы, а собственно сам результат (HTML) станет доступен только через какое-то время в событии
Одна из особенностей
Здесь метод вызывается не в конструкторе по той причине, что условия для его корректной отработки выполняются только в
Однако это лишь вход в кроличью нору – чуть выше говорилось, что существующие методы
Применительно к
Здесь нет сброса события по той простой причине, что после создания оно уже находится в несигнальном состоянии. Также не нужно считать, что под основным потоком понимается главный VCL-поток (Delphi-проект вообще может из себя представлять DLL, например) – хотя совпадение с ним и возможно, но имеется в виду именно тот поток, где выполняется создание экземпляра
Прежде чем перейти к полному варианту
Таким образом, окончательно процесс создания станет выглядеть чуть сложнее, чем в начале подраздела:
Деструктор, где уничтожается использованное здесь событие, рассматривается далее.
Чтобы завершить затянувшееся, но необходимое вступление и перейти от своего рода сервисного кода к главному, нужно рассмотреть деструктор, где требуется избавиться от «браузера», созданного выше: отвечает за это метод
Отличие только в следующем: метод
Условие
Перейдём непосредственно к внутренностям виновника торжества – функции
Своеобразный эскиз означенного (нерабочий) довольно прост:
Эскизность показанного заключена далеко не только в отсутствии кода по работе с XPath – в таком виде не даст желаемого практически всё. Самая легкопоправимая проблема (даже проблемка) связана с получением HTML, поэтому хотелось бы пойти с конца, начав именно с неё: всё снова упирается в многопоточную архитектуру CEF, из-за чего анонимная процедура отработает не в основном потоке и только через какое-то время – соответственно вновь придётся применить ожидание на основе события; таким образом, первая корректировка наброска должна показаться Вам очень знакомой:
Вторая загвоздка более сложная и состоит в загрузке URL (речь о первом пункте), а именно: применённая процедура
Теперь, в случае успешного открытия сайта, вызовется процедура
Как было оговорено, любая проблема при загрузке должна приводить к исключению, но
Видимость
С учётом сказанного, реализация
В итоге, теперь к простейшему вызову
На повестке остался второй пункт, отвечающий за ожидание нужного элемента на только что загруженной странице, однако всё омрачается тем, что его полная реализация довольно объёмна, поэтому основную часть необходимой работы было решено вынести в дополнительный метод с говорящим названием
И вот теперь-то, добропорядочно отложив самое сложное напоследок, можно с кристально чистой совестью завершить
На этом вполне допустимо поставить точку с данным методом, если бы не одна особенность сайтов в целом, с которой наверняка встречался каждый пользователь: не так часто, но всё же бывает, что динамическая страница не загружается полностью, заставляя бесконечно наблюдать анимированный индикатор на каком-то фрагменте; зачастую подобное происходит в силу разных случайных проблем – скажем сбой внутри скрипта, отвечающего за формирование нужных узлов документа, или же временная проблема на сервере, откуда скрипт пытается запросить данные, и тому подобные преходящие случаи; на практике весьма полезно попытаться перезагрузить страницу один-два раза, прежде чем возбуждать исключение, – в подавляющем большинстве случаев этого будет достаточно. В результате, финальный вариант метода чуть усложнится:
На случай, если из разрозненных фрагментов у Вас не сложилось полного понимания
К сожалению, CEF не предоставляет некоего узкоспециализированного метода, которому хотелось бы передать произвольный XPath, получив обратно результат его вычисления; с другой стороны, печаль развевает гораздо более универсальная возможность – способность выполнить произвольный JS-код, где уже можно без проблем применить стандартную функцию
Если перейти к конкретике, то за JavaScript отвечает интерфейс
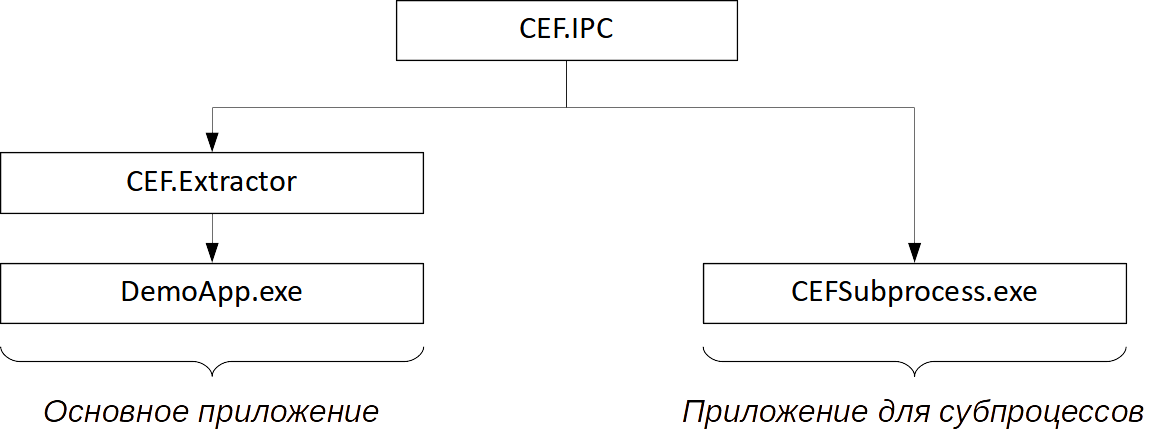
Понимание дальнейшего кода требует разъяснений этой особенности фреймворка. Первоначально создаваясь и существуя в главном (т. н. «браузерном») процессе, CEF в ходе работы плодит ещё и дочерние – если упрощать, то например открытие каждого нового сайта станет порождать как минимум один субпроцесс, отвечающий, в том числе, за исполнение скриптов. Почему так сделано, для каких нужд и т. п. – пояснение всего этого выходит за рамки статьи, не являясь её целью, – важно уяснить, что
Любой процесс, как известно, создаётся на основе некоторого исполняемого файла. Если Delphi-проект представляет из себя, допустим, VCL- или FMX-приложение, то под «браузерным» процессом CEF понимается именно оно, а дочерние по умолчанию создаются, как ни странно, тоже путём запуска того же самого файла (другими словами, в Диспетчере задач Windows будет казаться, что запущено несколько экземпляров Вашего приложения); разумеется, такой проект должен удовлетворять некоторым требованиям фреймворка, но об этом уже во многом позаботилась CEF4Delphi.
Когда же стоит задача инкапсулировать работу с CEF в DLL, то описанный подход с единственным исполняемым файлом права на жизнь не имеет – ведь динамическую библиотеку может задействовать и то приложение, которое знать не знает о CEF, а тем более о требованиях, без выполнения которых невозможно использовать его файл для дочерних процессов. В связи с этим, в статье применяется более универсальный подход, когда для субпроцессов разрабатывается отдельное, легковесное приложение, нужное исключительно ради этой одной цели; применительно к рассматриваемой задаче, в коде именно такого специального Delphi-проекта и должна размещаться логика по вычислению XPath, переданного сообщением от главного процесса, что в первом приближении схематически представляется так:
Рассмотрение деталей лучше всего начать с главного процесса, причём останавливаясь лишь на коде, содержащем новизну, в который раз не разбирая уже шаблонную схему ожидания на событии. Ключевой особенностью рассматриваемого в подразделе метода является обмен сообщениями между процессами, особой сложностью не отличающийся: за отправку отвечает метод
Казалось бы, сообщение-ответ, передаваемое от субпроцесса главному, должно содержать лишь одно логическое значение – результат вычисления присланного XPath:
Однако на этом было бы позволительно остановиться в идеальном мире, в реальном же при обработке XPath могут возникать исключения, причём дело не ограничивается просто другим потоком, как раньше, а всё происходит вообще в ином процессе – в связи с этим, чтобы не терять сведения о возникающих проблемах, все исключения в дочернем процессе будут отлавливаться, а в сообщении станут передаваться их класс и текст. Такой нюанс приведёт к тому, что количество элементов в
Состав же оставшихся станет зависеть от содержимого первого:
Так как тип
Выше при реализации
Вот теперь появляется всё необходимое для метода
После всего вышесказанного может показаться, что сам метод
Необходимо отметить, что
На этом работа с главным процессом завершена, осталось рассмотреть код, выполняемый дочерним – в нём, при поступлении сообщения, генерируется событие у некоего объекта (что он из себя представляет, в какой момент и как нужно установить обработчик этого события – все подобные вопросы рассматриваются в последнем разделе при знакомстве с примерами Delphi-проектов, а здесь указанные детали лишь отвлекут от сути). Таким образом, сейчас будет показана исключительно процедура-обработчик означенного события, назначение которой, как хочется напомнить, – определить, есть ли на странице то, что выражено присланным XPath.
В самом начале подраздела говорилось, что в части JavaScript станет применяться функция
Как видно, тут за преобразование вычисленного к логическому типу отвечает функция
Ещё нелишне остановиться на нюансе с кавычками, а именно: XPath допускает применение как одинарных, так и двойных, однако JS выше корректным является лишь при использовании вторых (ибо одинарные уже задействованы), поэтому, чтобы не накладывать никаких ограничений на XPath по части кавычек, они станут экранироваться, в результате чего становится возможным даже их совмещение, например так –
Если не брать в расчёт только что обговорённых моментов, код обработчика события довольно прост и прямолинеен, в связи с чем приводится сразу, без постепенной выдачи, как практиковалось до этого почти во всей статье:
На этом реализацию
Наверняка кто-то из читающих посчитал странным такой момент: разговор, казалось бы, всё время идёт о сайтах – вещи сугубо визуальной, – между тем материал никак не касался отрисовки загруженных страниц (как это делать, куда, на каком этапе), речь велась лишь об HTML-коде; разгадка здесь очень проста – какая бы то ни было визуализация просто-напросто отсутствует, по причине полной ненужности для решаемой задачи.
Необходимо пояснить, что CEF поддерживает так называемый OSR-режим, когда не создаётся стандартное для ОС окно, куда фреймворк самостоятельно выполняет отрисовку сайта, а вместо этого всё сохраняется в память, в некий буфер, содержимое которого можно, скажем, преобразовать в стандартный формат изображения (JPEG, PNG и т. п.), после чего сохранить, например в файл, или же передать по сети. Разработанный же класс, применяя означенный режим, не делает даже этого – буфер просто игнорируется – ведь нам интересны лишь данные, текстовое наполнение.
Раз имеется полное безразличие к внешнему виду, то выглядит разумным сделать вещь в общем-то необязательную (без данного подраздела работоспособность
Избавиться же от оставшихся загружаемых ресурсов возможно через механизм фильтров, реализовав наследника
А вот задействовать фильтр нужно в специальном виртуальном методе:
Константа
Реализация заявленного в начале нового метода
Для демонстрации применения
Дальнейшее повествование разделено на две части: первая описывает код, который требуется добавить в оба означенных проекта, чтобы они удовлетворяли требованиям CEF (без него проекты хоть и скомпилируются, но будут абсолютно неработоспособны), а во второй части излагается порядок сборки и что нужно проделать перед запуском получившегося основного приложения (которое с формой). Описанные в статье модули соотносятся с проектами указанным образом:
Итак, чтобы с классом
Подобная щепетильность связана с тем, что подготовка фреймворка к работе вполне в состоянии занимать до нескольких секунд, к тому же сразу приводя к запуску как минимум одного дочернего процесса.
Обращаясь к конкретике, прежде всего нужно присвоить значение глобальной объектной переменной
За установкой свойств должен следовать вызов метода
И только после этого допустимо создавать экземпляры
Инициализация в проекте дочерних процессов во многом схожа, с тем лишь принципиальным отличием, что расположена в dpr-файле (содержимое процедуры
Важно, чтобы значения свойств
Если читатель раньше не сталкивался с подобной проблематикой, то наверняка приведённое сжатое описание малопонятно, поэтому обратимся к конкретному примеру – пусть требуется извлечь альбомы некоторой группы с metal-archives.com:
Как можно видеть, их перечень содержится в таблице, входящей в тэг
<div id="band_disco" ...>, однако, если рассмотреть HTML, получаемый просто HTTP-запросом по данной ссылке, то никакой таблицы там не обнаружится:...
<div id="band_tab_discography">
<div id="band_disco" class="tabs2lvl">
<ul>...</ul>
</div>
</div>
...Таким образом, для подобных сайтов не подходит наиболее предпочтительный и малозатратный метод парсинга, заключающийся лишь в выполнении HTTP-запроса, сразу возвращающего HTML со всем необходимым, – требуется исполнение скриптов; очевидно, что полнее и лучше всего с такой задачей справляется браузер, причём вариантов имеется несколько:
- Delphi-программисты чаще всего жаловали Internet Explorer из-за простоты включения в проект и отсутствия проблем с наличием в ОС (речь, например, об использовании интерфейса
IWebBrowser2), но сейчас опираться на него в начинаниях неразумно, мягко говоря. - В случае, когда приложение должно работать только на Windows, а разработчик использует свежую IDE (начиная с 10.4 Sydney), то возможно применить Edge.
- Самый же универсальный вариант, подходящий под условно любой давности ОС и версию Delphi, основывается на Chromium Embedded Framework (далее просто CEF), обёрткой над которым является библиотека CEF4Delphi, – именно он и ляжет в основу решения поставленной проблемы.
Что будет сделано
Весь материал делится на две неравные части:
- Прежде всего, будет создан наследник невизуального компонента
TChromiumиз состава CEF4Delphi, который прирастёт всего лишь одним методом (среди публичных):TDynamicSiteExtractor = class(TChromium) public function RetrieveHTML(const URL: string; const TargetXPath: string): string; end;
Пояснения здесь требует второй параметр функции: он должен содержать XPath того элемента (или же атрибута, текстового узла, либо чего-то ещё – можно использовать любые возможности XPath), появления которого на странице необходимо дождаться, – как только он обнаружится, будет сформирован HTML-документ со всем, что привнесли скрипты, который метод и вернёт. Применительно к рассмотренному примеру, параметр должен указывать на таблицу//table[@class="display discog"]. -
Интерфейс
IXQValueиз статьи про InternetTools также обогатится единственным методом:IXQValue = interface ... function OpenDocument(const Source: WideString): IXQValue; safecall; end;
Он, в отличие отOpenURL, сам не делает никаких HTTP-запросов, а работает с уже готовым HTML, в нашем случае полученным отTDynamicSiteExtractor.
В итоге, поставленная задача станет решаться так (тривиальный код по созданию и уничтожению объектов опущен):
const
BandURL = 'https://www.metal-archives.com/bands/Vader/145';
TableXPath = '//table[@class="display discog"]';
AlbumsXPath = TableXPath + '//tr';
var
Extractor: TDynamicSiteExtractor;
BandHTML: string;
AlbumRow: IXQValue;
begin
...
BandHTML := Extractor.RetrieveHTML(BandURL, TableXPath);
for AlbumRow in GetXQValue.OpenDocument(BandHTML).Map(AlbumsXPath) do
... // Обработка строк таблицы, содержащих сведения об альбомах
...
endСтоит отметить, что такое решение больше ориентировано на «серверную» многопоточную обработку крупного массива ссылок (по крайней мере у автора так), ибо метод
RetrieveHTML – ведь сайты бывают очень разные – вполне может выполняться и несколько десятков секунд, а механизмов досрочного завершения его работы здесь не предлагается.Далее бо́льшая часть материала посвящена деталям реализации, сосредотачиваясь на вопросах «как» и «почему», поэтому если читателя интересует лишь вопрос использования готового решения, то следует перейти в последний раздел, содержащий примеры двух Delphi-проектов (второй из них необходимый вспомогательный), которые обязательно нужно изучить в случае, если раньше не приходилось иметь дел с CEF, – этот фреймворк требует определённых манипуляций для своего использования.
Реализация
В плане сложности и объёма кода дальнейшая работа с CEF4Delphi несравнима с крохотными доработками InternetTools, к тому же означенный
TDynamicSiteExtractor более чем самодостаточен и, само-собой, может использоваться и без связки с чем-либо (если требуется лишь получить HTML сайта, без необходимости анализа), поэтому начать разумно именно с данного класса.TDynamicSiteExtractor
Прежде всего стоит немного смутить читателя тем, что предок разрабатываемого класса уже имеет несколько методов
RetrieveHTML (суть у них всех одна):procedure RetrieveHTML(const aFrameName: ustring = ''); overload;
procedure RetrieveHTML(const aFrame: ICefFrame); overload;
procedure RetrieveHTML(const aFrameIdentifier: int64); overload;Однако несложно заметить, что это процедуры, к тому же без var- и out-параметров, способных вернуть результат, – всё потому, что методы эти асинхронные (неблокирующие), они лишь запускают процесс формирования кода страницы, а собственно сам результат (HTML) станет доступен только через какое-то время в событии
OnTextResultAvailable; причём даже полученный таким образом HTML-код не решает проблему из статьи – там может не оказаться узлов, сформированных скриптами. Если учесть, что TChromium является хоть и невизуальным, но всё же компонентом, почти всегда размещаемым на форме, то данное решение с событием оправдано, т. к. позволяет избежать неприятности с «заморозкой» интерфейса, однако когда взаимодействие с пользователем отсутствует (скажем работа условной Windows-службы) и код исполняется в своём потоке динамически созданным компонентом, то намного удобнее использовать блокирующие методы – ведь даже долгое ожидание их результата ничем не повредит.Инициализация
Одна из особенностей
TChromium состоит в том, что, прежде чем появится возможность выполнить что-то полезное (открыть определённый сайт, например), требуется вызвать метод CreateBrowser (при необходимости, как нетрудно догадаться, его можно задействовать несколько раз, заимев таким образом не один «браузер», но в нашем случае достаточно единственного), поэтому указанное проделывается сразу при создании объекта:unit CEF.Extractor;
interface
uses
System.SysUtils, uCEFChromium;
type
EExtractorException = class(Exception);
TDynamicSiteExtractor = class(TChromium)
public
procedure AfterConstruction; override;
...
end;
implementation
procedure TDynamicSiteExtractor.AfterConstruction;
begin
inherited;
if not CreateBrowser then
raise EExtractorException.Create('...');
end;
end.Здесь метод вызывается не в конструкторе по той причине, что условия для его корректной отработки выполняются только в
AfterConstruction.Однако это лишь вход в кроличью нору – чуть выше говорилось, что существующие методы
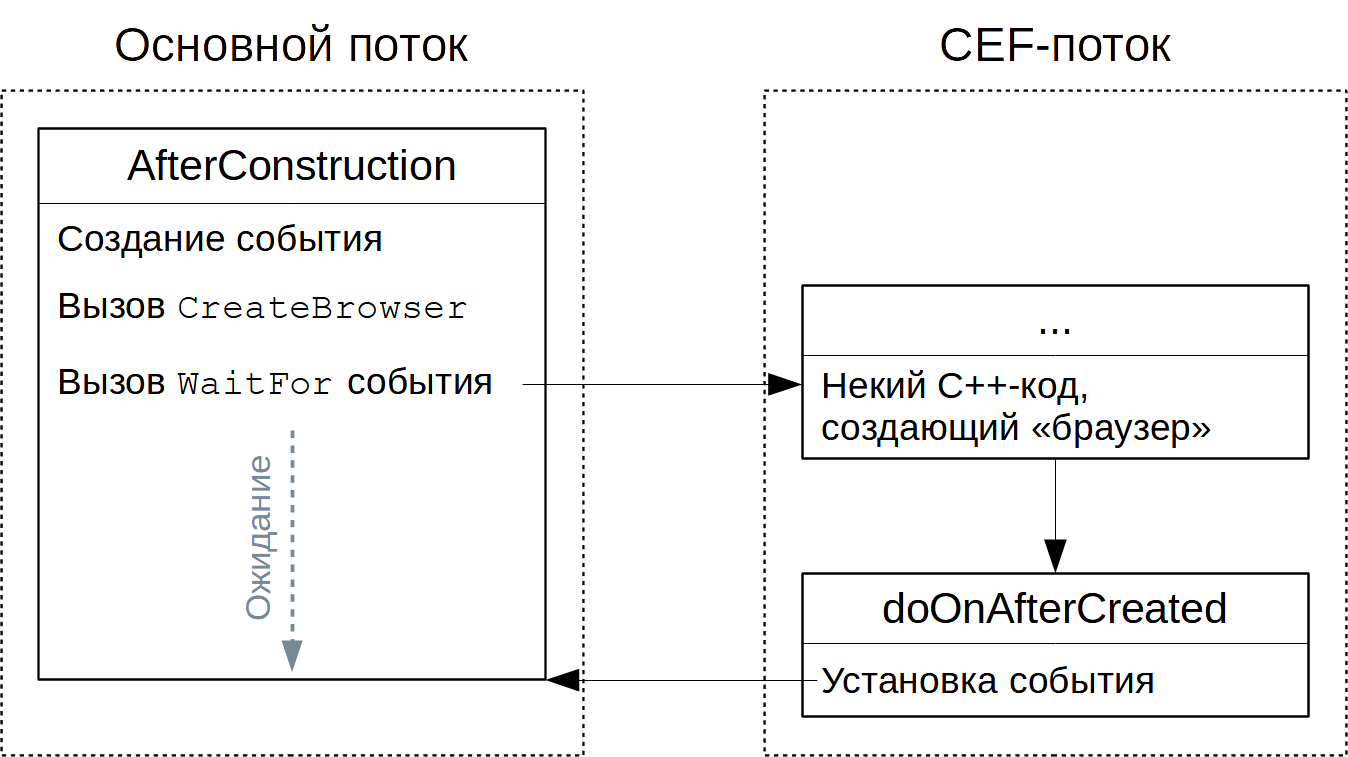
RetrieveHTML только инициируют действие, а сам результат будет через какое-то время в соответствующем событии; так и здесь – CreateBrowser всего-навсего стартует создание «браузера», а окончание этого действа сигнализируется событием OnAfterCreated (но так как разрабатывается наследник TChromium, то намного практичнее работать не с событием, а перекрыть метод, его генерирующий, – doOnAfterCreated). Ещё один нюанс (но являющийся пожалуй самым главным) таков – doOnAfterCreated вызывается в контексте потока, созданного CEF. Это принципиальный момент, поэтому нужно повториться: AfterConstruction работает в нашем (основном) потоке, а метод, извещающий о завершении создания «браузера», выполнится в CEF-потоке; аналогичная ситуация далее ещё не раз встретится, в связи с чем логично именно сейчас описать общую схему по ожиданию результатов подобных неблокирующих методов:-
Создаётся такой примитив синхронизации, как событие (
TEvent), – чаще всего в конструктореTDynamicSiteExtractor, но иногда и просто на лету. - Событие переводится в несигнальное состояние (сбрасывается).
- Вызывается некий неблокирующий метод, плодов работы которого необходимо дождаться.
- Основной поток приостанавливается через
TEvent.WaitFor. - Через какое-то время CEF-поток выполнит метод, оповещающий об окончании операции, где событие устанавливается (переводится в сигнальное состояние).
- Основной поток продолжает свою работу.
Применительно к
CreateBrowser и графически, перечисленное выглядит так:Здесь нет сброса события по той простой причине, что после создания оно уже находится в несигнальном состоянии. Также не нужно считать, что под основным потоком понимается главный VCL-поток (Delphi-проект вообще может из себя представлять DLL, например) – хотя совпадение с ним и возможно, но имеется в виду именно тот поток, где выполняется создание экземпляра
TDynamicSiteExtractor.Прежде чем перейти к полному варианту
AfterConstruction, создадим полезный вспомогательный метод – обёртку над TEvent.WaitFor, позволящую избежать дублирования кода в дальнейшем:procedure TDynamicSiteExtractor.WaitFor(const Event: TEvent; const Timeout: LongWord = INFINITE);
begin
case Event.WaitFor(Timeout) of
wrTimeout: raise EExtractorException.CreateFmt('...', [Timeout]);
wrError: RaiseLastOSError(Event.LastError);
wrAbandoned: raise EExtractorException.Create('...');
end;
end;Таким образом, окончательно процесс создания станет выглядеть чуть сложнее, чем в начале подраздела:
uses
..., System.SyncObjs, uCEFInterfaces;
type
...
TDynamicSiteExtractor = class(TChromium)
private
const
CreateBrowserTimeout = 15 * 1000;
private
FCreateEvent: TEvent;
procedure WaitFor(const Event: TEvent; const Timeout: LongWord = INFINITE);
protected
procedure doOnAfterCreated(const browser: ICefBrowser); override;
...
end;
implementation
procedure TDynamicSiteExtractor.AfterConstruction;
begin
inherited;
FCreateEvent := TEvent.Create;
if not CreateBrowser then
raise EExtractorException.Create('...');
WaitFor(FCreateEvent, CreateBrowserTimeout);
end;
procedure TDynamicSiteExtractor.doOnAfterCreated(const browser: ICefBrowser);
begin
inherited;
FCreateEvent.SetEvent;
end;Деструктор, где уничтожается использованное здесь событие, рассматривается далее.
Уничтожение
Чтобы завершить затянувшееся, но необходимое вступление и перейти от своего рода сервисного кода к главному, нужно рассмотреть деструктор, где требуется избавиться от «браузера», созданного выше: отвечает за это метод
CloseBrowser, являющийся, как и рассмотренный CreateBrowser, лишь инициатором действия, о завершении коего сигнализирует процедура doOnBeforeClose, вызванная CEF-потоком; в связи с этим применяется ровно та же схема с событием, почти один в один:...
TDynamicSiteExtractor = class(TChromium)
...
private
FCloseEvent: TEvent;
...
protected
...
procedure doOnBeforeClose(const browser: ICefBrowser); override;
public
destructor Destroy; override;
...
end;
implementation
...
destructor TDynamicSiteExtractor.Destroy;
begin
if Initialized then
begin
FCloseEvent := TEvent.Create;
CloseBrowser(True);
FCloseEvent.WaitFor;
end;
inherited;
FCreateEvent.Free;
FCloseEvent.Free;
end;
procedure TDynamicSiteExtractor.doOnBeforeClose(const browser: ICefBrowser);
begin
inherited;
FCloseEvent.SetEvent;
end;Отличие только в следующем: метод
WaitFor события используется напрямую, без обёртки, ибо допускать в деструкторе исключения, ради которых она и создавалась, категорически нельзя – это приведёт к утечке ресурсов из-за частично уничтоженного объекта.Условие
if Initialized then покрывает случай, когда в AfterConstruction было исключение и «браузер» не создался – при такой ситуации CloseBrowser фактически ничего не делает (будто его и нет), следовательно и никогда не вызовется doOnBeforeClose, что приведёт к бесконечному ожиданию события из-за отсутствия таймаута.От общего к частному
Перейдём непосредственно к внутренностям виновника торжества – функции
RetrieveHTML. К сожалению, её реализацию не уместить в несколько строк, поэтому код тех новых вспомогательных методов и локальных процедур с функциями, чья необходимость станет постепенно проявляться, будет добавляться постепенно, дабы не перегрузить читателя потоком информации. Если рисовать картину широкими мазками, то новый метод должен проделать нижеследующее:- «Открыть» переданный ему первым параметром сайт – то есть выполнить HTTP-запросы, загрузив все нужные ресурсы (включая скрипты); если же сделать это не удалось, то сгенерировать исключение.
- Дождаться, когда отработают скрипты и появится тот элемент, на который указывает XPath из второго параметра (ждать бесконечно смысла нет, поэтому необходим некоторый таймаут); аналогично, непоявление требуемого приведёт к исключению.
- Сформировать HTML с учётом всех изменений, который и вернуть.
Своеобразный эскиз означенного (нерабочий) довольно прост:
uses
..., uCEFTypes;
...
implementation
...
function TDynamicSiteExtractor.RetrieveHTML(const URL: string; const TargetXPath: string): string;
var
HTML: string;
begin
LoadURL(URL);
// Ожидание TargetXPath
...
Browser.MainFrame.GetSourceProc
(
procedure (const str: ustring)
begin
HTML := str;
end
);
Result := HTML;
end;Эскизность показанного заключена далеко не только в отсутствии кода по работе с XPath – в таком виде не даст желаемого практически всё. Самая легкопоправимая проблема (даже проблемка) связана с получением HTML, поэтому хотелось бы пойти с конца, начав именно с неё: всё снова упирается в многопоточную архитектуру CEF, из-за чего анонимная процедура отработает не в основном потоке и только через какое-то время – соответственно вновь придётся применить ожидание на основе события; таким образом, первая корректировка наброска должна показаться Вам очень знакомой:
function TDynamicSiteExtractor.RetrieveHTML(const URL: string; const TargetXPath: string): string;
var
Event: TEvent;
...
begin
...
Event := TEvent.Create;
try
Browser.MainFrame.GetSourceProc
(
procedure (const str: ustring)
begin
HTML := str;
Event.SetEvent;
end
);
WaitFor(Event);
finally
Event.Free;
end;
Result := HTML;
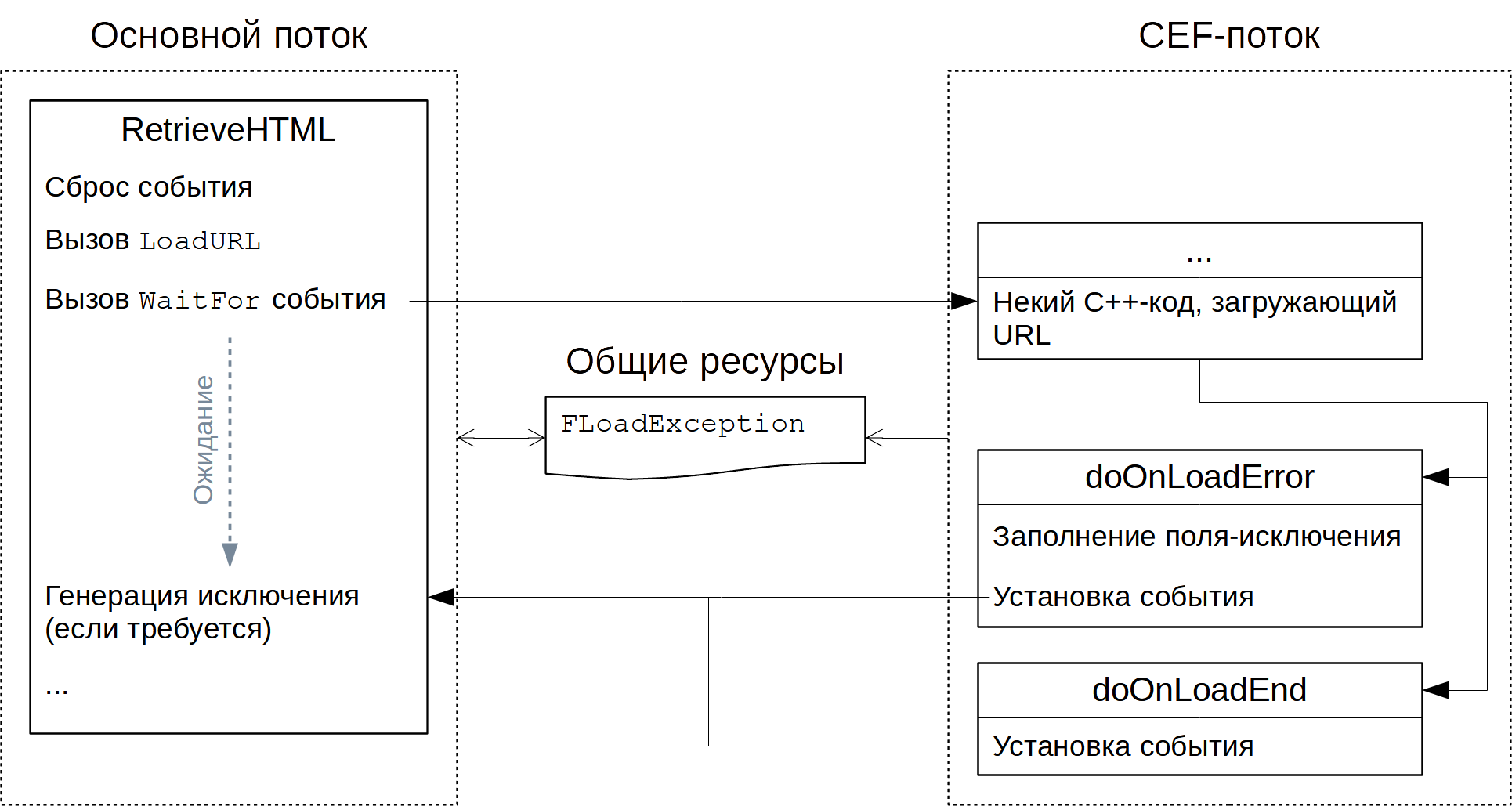
end;Вторая загвоздка более сложная и состоит в загрузке URL (речь о первом пункте), а именно: применённая процедура
LoadURL всё так же неблокирующая, а связаны с ней два события – OnLoadEnd и OnLoadError, назначение которых понятно из названия, – однако как и раньше, напрямую работать с ними никакого резона нет, поэтому далее перекрываются соответствующие им методы – doOnLoadEnd и doOnLoadError. Нюанс здесь исключительно в том, что, видимо ввиду какой-то оптимизации CEF4Delphi, по умолчанию эти методы активируются лишь при назначенных упомянутых событиях, а управляется эта логика виртуальной функцией MustCreateLoadHandler, которую для планируемого сценария нужно примитивизировать:...
TDynamicSiteExtractor = class(TChromium)
...
protected
function MustCreateLoadHandler: Boolean; override;
...
end;
implementation
...
function TDynamicSiteExtractor.MustCreateLoadHandler: Boolean;
begin
Result := True;
end;Теперь, в случае успешного открытия сайта, вызовется процедура
doOnLoadEnd, где при двухсотом коде ответа TEvent установится в сигнальное состояние (если же в Вашем случае успехом считаются и некоторые другие коды, то следует указать их здесь; создание и уничтожение события не показаны, ибо происходят самым обычным образом в конструкторе и деструкторе):...
TDynamicSiteExtractor = class(TChromium)
...
private
FLoadEvent: TEvent;
...
protected
procedure doOnLoadEnd(const browser: ICefBrowser; const frame: ICefFrame;
httpStatusCode: Integer); override;
...
end;
implementation
...
procedure TDynamicSiteExtractor.doOnLoadEnd(const browser: ICefBrowser;
const frame: ICefFrame; httpStatusCode: Integer);
begin
inherited;
if frame.IsMain and (httpStatusCode = 200) then
FLoadEvent.SetEvent;
end;Как было оговорено, любая проблема при загрузке должна приводить к исключению, но
doOnLoadError вызывается не просто в контексте не нашего потока, а того, код которого создан на другом ЯП, ничего, естественно, не знающего о Delphi-исключениях, – в результате в данном методе недопустимы необработанные исключительные ситуации; в связи с этим, doOnLoadError станет только создавать объект-исключение, сохраняя его в поле класса, а генерация исключения на основе такого подготовленного объекта будет выполняться уже позже, в основном потоке, как и положено. Указанное поле выглядит так:TDynamicSiteExtractor = class(TChromium)
...
strict private
FLoadException: EExtractorException;
...
end;Видимость
strict private использована не с целью максимально ограничить доступ к полю (речь ведь об одном классе, где подобное сужение видимости смысла не несёт), а скорее чтобы подчеркнуть его уязвимость и нужность деликатного обращения – являясь ресурсом общим, разделяемым для двух потоков, оно требует защиты при доступе. Но прежде чем перейти к коду, хотелось бы всё же показать этап загрузки схематически:С учётом сказанного, реализация
doOnLoadError может быть следующей (ключевым моментом в ней является использование атомарной операции, благо тип FLoadException поддерживается TInterlocked, позволяя обойтись без, например, критической секции):...
TDynamicSiteExtractor = class(TChromium)
...
protected
procedure doOnLoadError(const browser: ICefBrowser; const frame: ICefFrame;
errorCode: TCefErrorCode; const errorText, failedUrl: ustring); override;
...
end;
implementation
...
procedure TDynamicSiteExtractor.doOnLoadError(const browser: ICefBrowser;
const frame: ICefFrame; errorCode: TCefErrorCode; const errorText, failedUrl: ustring);
begin
inherited;
if not frame.IsMain then
Exit;
TInterlocked.Exchange( FLoadException, EExtractorException.CreateFmt('...',
[failedUrl, errorCode, errorText]) );
FLoadEvent.SetEvent;
end;В итоге, теперь к простейшему вызову
LoadURL добавится, хочется надеяться, уже ставший для читателя почти шаблонным код с ожиданием события:function TDynamicSiteExtractor.RetrieveHTML(const URL: string; const TargetXPath: string): string;
procedure LoadURLAndWait;
begin
FLoadEvent.ResetEvent;
LoadURL(URL);
WaitFor(FLoadEvent);
CheckException(FLoadException);
end;
...
begin
LoadURLAndWait;
...
end;CheckException – это новая процедура, отвечающая за генерацию исключения, вынесенная вне RetrieveHTML из-за необходимости далее применить её ещё раз, в другом методе:...
TDynamicSiteExtractor = class(TChromium)
...
private
procedure CheckException(var PreparedException: EExtractorException);
...
end;
implementation
...
procedure TDynamicSiteExtractor.CheckException(var PreparedException: EExtractorException);
var
ExceptionCopy: Exception;
begin
ExceptionCopy := TInterlocked.Exchange<EExtractorException>(PreparedException, nil);
if Assigned(ExceptionCopy) then
raise ExceptionCopy;
end;На повестке остался второй пункт, отвечающий за ожидание нужного элемента на только что загруженной странице, однако всё омрачается тем, что его полная реализация довольно объёмна, поэтому основную часть необходимой работы было решено вынести в дополнительный метод с говорящим названием
XPathExists – он возвращает True при обнаружении искомого (его коду посвящён целый следующий подраздел):TDynamicSiteExtractor = class(TChromium)
...
private
function XPathExists(const XPath: string): Boolean;
...
end;И вот теперь-то, добропорядочно отложив самое сложное напоследок, можно с кристально чистой совестью завершить
RetrieveHTML:uses
..., System.Classes;
type
...
TDynamicSiteExtractor = class(TChromium)
private
const
XPathTimeout = 5 * 1000;
...
end;
implementation
uses
System.Diagnostics;
...
function TDynamicSiteExtractor.RetrieveHTML(const URL: string; const TargetXPath: string): string;
...
function WaitTargetXPath: Boolean;
const
Pause = 200;
var
Timer: TStopWatch;
begin
Result := True;
Timer := TStopWatch.StartNew;
while not XPathExists(TargetXPath) do
begin
TThread.Sleep(Pause);
if Timer.ElapsedMilliseconds >= XPathTimeout then
Exit(False);
end;
end;
...
begin
LoadURLAndWait;
if not WaitTargetXPath then
raise EExtractorException.Create('...');
...
end;На этом вполне допустимо поставить точку с данным методом, если бы не одна особенность сайтов в целом, с которой наверняка встречался каждый пользователь: не так часто, но всё же бывает, что динамическая страница не загружается полностью, заставляя бесконечно наблюдать анимированный индикатор на каком-то фрагменте; зачастую подобное происходит в силу разных случайных проблем – скажем сбой внутри скрипта, отвечающего за формирование нужных узлов документа, или же временная проблема на сервере, откуда скрипт пытается запросить данные, и тому подобные преходящие случаи; на практике весьма полезно попытаться перезагрузить страницу один-два раза, прежде чем возбуждать исключение, – в подавляющем большинстве случаев этого будет достаточно. В результате, финальный вариант метода чуть усложнится:
function TDynamicSiteExtractor.RetrieveHTML(const URL: string; const TargetXPath: string): string;
...
const
AttemptCount = 3;
var
...
Attempt: Cardinal;
begin
for Attempt := 1 to AttemptCount do
begin
LoadURLAndWait;
if WaitTargetXPath then
Break
else
if Attempt = AttemptCount then
raise EExtractorException.Create('...');
end;
...
end;На случай, если из разрозненных фрагментов у Вас не сложилось полного понимания
RetrieveHTML, в завершение видится здравым привести
весь описанный код единым текстом.
function TDynamicSiteExtractor.RetrieveHTML(const URL: string; const TargetXPath: string): string;
procedure LoadURLAndWait;
begin
FLoadEvent.ResetEvent;
LoadURL(URL);
WaitFor(FLoadEvent);
CheckException(FLoadException);
end;
function WaitTargetXPath: Boolean;
const
Pause = 200;
var
Timer: TStopWatch;
begin
Result := True;
Timer := TStopWatch.StartNew;
while not XPathExists(TargetXPath) do
begin
TThread.Sleep(Pause);
if Timer.ElapsedMilliseconds >= XPathTimeout then
Exit(False);
end;
end;
const
AttemptCount = 3;
var
Attempt: Cardinal;
Event: TEvent;
HTML: string;
begin
for Attempt := 1 to AttemptCount do
begin
LoadURLAndWait;
if WaitTargetXPath then
Break
else
if Attempt = AttemptCount then
raise EExtractorException.Create('...');
end;
Event := TEvent.Create;
try
Browser.MainFrame.GetSourceProc
(
procedure (const str: ustring)
begin
HTML := str;
Event.SetEvent;
end
);
WaitFor(Event);
finally
Event.Free;
end;
Result := HTML;
end;Метод XPathExists
К сожалению, CEF не предоставляет некоего узкоспециализированного метода, которому хотелось бы передать произвольный XPath, получив обратно результат его вычисления; с другой стороны, печаль развевает гораздо более универсальная возможность – способность выполнить произвольный JS-код, где уже можно без проблем применить стандартную функцию
evaluate, делающую ровно то, что требуется.Если перейти к конкретике, то за JavaScript отвечает интерфейс
ICefv8Context (если точнее – его метод Eval), получить который возможно у фрейма через функцию GetV8Context, но огромное препятствие, из-за которого даже понадобился целый подраздел, сводится к следующему: если попробовать заполучить ICefv8Context через, к примеру, Browser.MainFrame.GetV8Context (причём в любом методе TDynamicSiteExtractor, даже работающем в рамках CEF-потока), то эта функция станет всегда возвращать nil. Описание причины такого поведения немногословно, но зато приведёт к обилию труда позже: CEF – не только многопоточное, но и многопроцессное ПО (а работа с JS как раз должна вестись в ином процессе – не том, где создаются экземпляры разрабатываемого класса).Понимание дальнейшего кода требует разъяснений этой особенности фреймворка. Первоначально создаваясь и существуя в главном (т. н. «браузерном») процессе, CEF в ходе работы плодит ещё и дочерние – если упрощать, то например открытие каждого нового сайта станет порождать как минимум один субпроцесс, отвечающий, в том числе, за исполнение скриптов. Почему так сделано, для каких нужд и т. п. – пояснение всего этого выходит за рамки статьи, не являясь её целью, – важно уяснить, что
TDynamicSiteExtractor существует исключительно в главном процессе, а если ему требуется обратиться к возможности, за которую отвечает субпроцесс, то следует воспользоваться механизмом межпроцессного взаимодействия в виде сообщений (его, к счастью, самостоятельно реализовывать не нужно – CEF предоставляет всё необходимое).Любой процесс, как известно, создаётся на основе некоторого исполняемого файла. Если Delphi-проект представляет из себя, допустим, VCL- или FMX-приложение, то под «браузерным» процессом CEF понимается именно оно, а дочерние по умолчанию создаются, как ни странно, тоже путём запуска того же самого файла (другими словами, в Диспетчере задач Windows будет казаться, что запущено несколько экземпляров Вашего приложения); разумеется, такой проект должен удовлетворять некоторым требованиям фреймворка, но об этом уже во многом позаботилась CEF4Delphi.
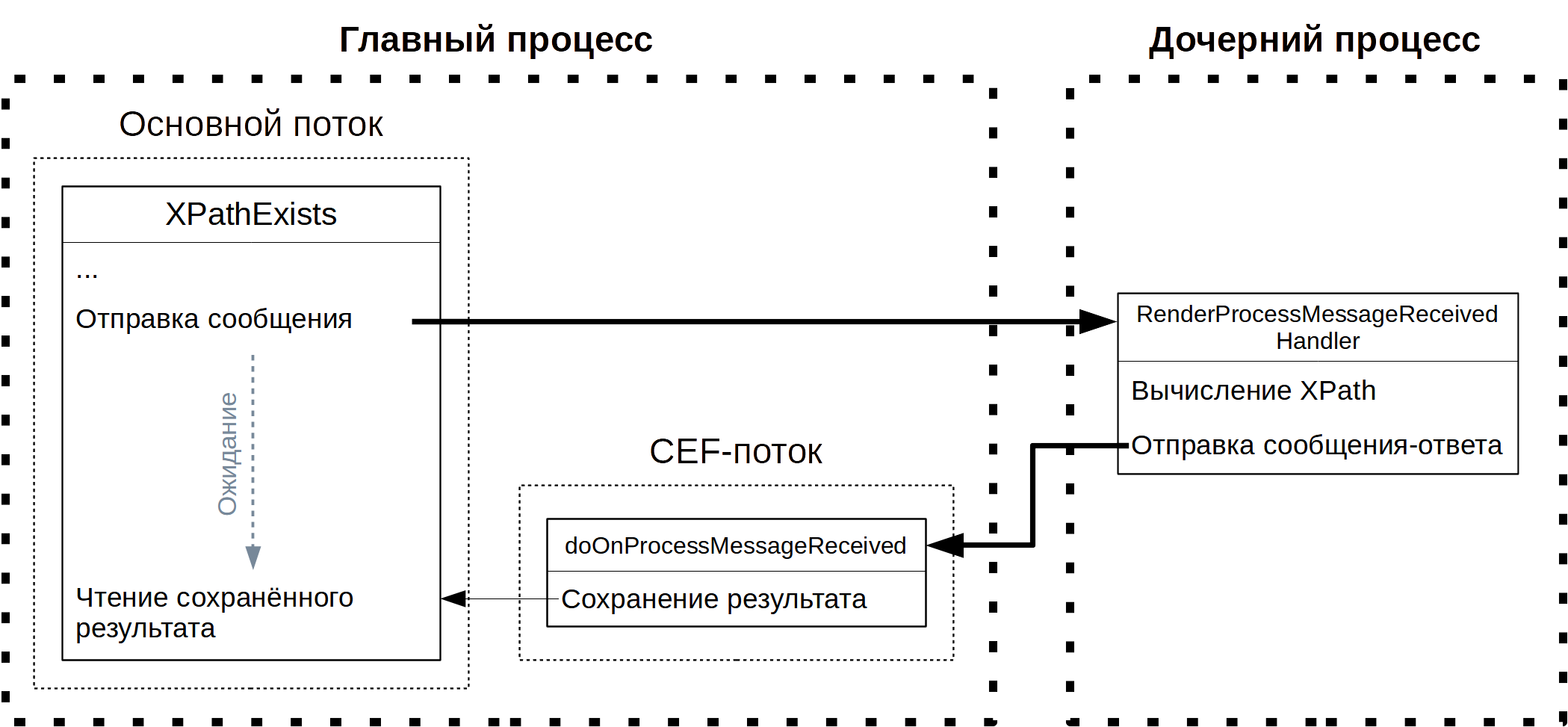
Когда же стоит задача инкапсулировать работу с CEF в DLL, то описанный подход с единственным исполняемым файлом права на жизнь не имеет – ведь динамическую библиотеку может задействовать и то приложение, которое знать не знает о CEF, а тем более о требованиях, без выполнения которых невозможно использовать его файл для дочерних процессов. В связи с этим, в статье применяется более универсальный подход, когда для субпроцессов разрабатывается отдельное, легковесное приложение, нужное исключительно ради этой одной цели; применительно к рассматриваемой задаче, в коде именно такого специального Delphi-проекта и должна размещаться логика по вычислению XPath, переданного сообщением от главного процесса, что в первом приближении схематически представляется так:
Рассмотрение деталей лучше всего начать с главного процесса, причём останавливаясь лишь на коде, содержащем новизну, в который раз не разбирая уже шаблонную схему ожидания на событии. Ключевой особенностью рассматриваемого в подразделе метода является обмен сообщениями между процессами, особой сложностью не отличающийся: за отправку отвечает метод
SendProcessMessage, параметром которому передаётся собственно сообщение, представленное интерфейсом ICefProcessMessage, каковой характеризуется прежде всего именем (речь о свойстве Name), позволяющим отличать сообщения друг от друга, а также свойством ArgumentList, роль которого – хранить те полезные данные, что нужно передать. ArgumentList – это структура с произвольным количеством разнотипных элементов и целочисленной индексацией по ним; сохранение в ней строки с XPath, подлежащей передаче дочернему процессу, выглядит очень просто:var
CEFMessage: ICefProcessMessage;
begin
...
CEFMessage.ArgumentList.SetString(0, '//some/x/path');
end;Казалось бы, сообщение-ответ, передаваемое от субпроцесса главному, должно содержать лишь одно логическое значение – результат вычисления присланного XPath:
var
Answer: ICefProcessMessage;
begin
...
Answer.ArgumentList.SetBool(0, XPathEvalResult);
end;Однако на этом было бы позволительно остановиться в идеальном мире, в реальном же при обработке XPath могут возникать исключения, причём дело не ограничивается просто другим потоком, как раньше, а всё происходит вообще в ином процессе – в связи с этим, чтобы не терять сведения о возникающих проблемах, все исключения в дочернем процессе будут отлавливаться, а в сообщении станут передаваться их класс и текст. Такой нюанс приведёт к тому, что количество элементов в
ArgumentList будет переменным (в зависимости от того, была ли какая-то проблема), для чего в первом элементе (с индексом 0) предлагается хранить значение перечислимого типа:TMessageSuccessfulness = (msOK, msException);Состав же оставшихся станет зависеть от содержимого первого:
| Индекс элемента | Данные (при msOK) |
Данные (при msException) |
|---|---|---|
| 0 | msOK |
msException |
| 1 | Результат вычисления XPath (тип Boolean). |
Класс исключения (тип string). |
| 2 | Текст исключения (тип string). |
TMessageSuccessfulness и индексы из таблицы понадобятся как при реализации TDynamicSiteExtractor, так и в Delphi-проекте дочернего процесса, то следует вынести их в отдельный небольшой модуль (в его имени аббревиатура IPC означает Inter-Process Communication):unit CEF.IPC;
interface
type
TMessageSuccessfulness = (msOK, msException);
const
XPathMessageName = 'EvaluateXPath';
XPathIndex = 0;
SuccessfulnessIndex = 0;
ExceptionClassIndex = SuccessfulnessIndex + 1;
ExceptionTextIndex = ExceptionClassIndex + 1;
XPathResultIndex = ExceptionClassIndex;
implementation
end.Выше при реализации
RetrieveHTML была необходимость в защите общего ресурса в виде поля, хранящего созданное CEF-потоком исключение; здесь аналогичная ситуация – только в дополнение к полю, отвечающему за исключение в дочернем процессе, нужно ещё передать основному потоку логическое значение с результатом обработки XPath. Если тип первого поля позволяет защитить его с помощью TInterlocked, то Boolean-тип второго заставляет прибегнуть к критической секции, обернув обращения к нему в свойство:...
TDynamicSiteExtractor = class(TChromium)
...
strict private
...
FMessageException: EExtractorException;
FXPathResult: Boolean;
FXPathResultGuard: TCriticalSection;
function GetXPathResult: Boolean;
procedure SetXPathResult(const Value: Boolean);
private
...
property XPathResult: Boolean read GetXPathResult write SetXPathResult;
...
end;
implementation
...
function TDynamicSiteExtractor.GetXPathResult: Boolean;
begin
FXPathResultGuard.Enter;
try
Result := FXPathResult;
finally
FXPathResultGuard.Leave;
end;
end;
procedure TDynamicSiteExtractor.SetXPathResult(const Value: Boolean);
begin
FXPathResultGuard.Enter;
try
FXPathResult := Value;
finally
FXPathResultGuard.Leave;
end;
end;Вот теперь появляется всё необходимое для метода
doOnProcessMessageReceived со схемы, обрабатывающего сообщение-ответ от субпроцесса:...
TDynamicSiteExtractor = class(TChromium)
...
protected
function doOnProcessMessageReceived(const browser: ICefBrowser;
const frame: ICefFrame; sourceProcess: TCefProcessId;
const aMessage: ICefProcessMessage): Boolean; override;
...
end;
implementation
uses
..., CEF.IPC;
...
function TDynamicSiteExtractor.doOnProcessMessageReceived(const browser: ICefBrowser;
const frame: ICefFrame; sourceProcess: TCefProcessId;
const aMessage: ICefProcessMessage): Boolean;
begin
Result := inherited;
if not Assigned(aMessage) then
Exit;
if aMessage.Name = XPathMessageName then
begin
case TMessageSuccessfulness( aMessage.ArgumentList.GetInt(SuccessfulnessIndex) ) of
msOK:
XPathResult := aMessage.ArgumentList.GetBool(XPathResultIndex);
msException:
TInterlocked.Exchange
(
FMessageException,
EExtractorException.CreateFmt
(
'...',
[
aMessage.ArgumentList.GetString(ExceptionClassIndex),
aMessage.ArgumentList.GetString(ExceptionTextIndex)
]
)
);
end;
FMessageEvent.SetEvent;
Result := True;
end;
end;После всего вышесказанного может показаться, что сам метод
XPathExists, ради которого затевался целый подраздел, явит миру некую сложность, но на самом деле он довольно краток и состоит в основном из уже встречавшегося кода:...
TDynamicSiteExtractor = class(TChromium)
private
const
AnswerMessageTimeout = 3 * 1000;
...
end;
implementation
uses
..., uCEFProcessMessage;
...
function TDynamicSiteExtractor.XPathExists(const XPath: string): Boolean;
var
CEFMessage: ICefProcessMessage;
begin
CEFMessage := TCefProcessMessageRef.New(XPathMessageName);
CEFMessage.ArgumentList.SetString(XPathIndex, XPath);
FMessageEvent.ResetEvent;
SendProcessMessage(PID_RENDERER, CEFMessage);
WaitFor(FMessageEvent, AnswerMessageTimeout);
CheckException(FMessageException);
Result := XPathResult;
end;Необходимо отметить, что
AnswerMessageTimeout задаёт не время ожидания нужного элемента страницы (это достигалось ранее в RetrieveHTML через константу XPathTimeout), а ограничивает длительность вычисления XPath дочерним процессом – в нормальных условиях подобное должно происходить «мгновенно» (т. е. ни о каких секундах даже речи не идёт), поэтому возникновение необычной задержки указывает на какие-то проблемы с субпроцессом (теоретически, он может вообще аварийно завершиться, в связи с чем сообщения-ответа можно совсем не дождаться).На этом работа с главным процессом завершена, осталось рассмотреть код, выполняемый дочерним – в нём, при поступлении сообщения, генерируется событие у некоего объекта (что он из себя представляет, в какой момент и как нужно установить обработчик этого события – все подобные вопросы рассматриваются в последнем разделе при знакомстве с примерами Delphi-проектов, а здесь указанные детали лишь отвлекут от сути). Таким образом, сейчас будет показана исключительно процедура-обработчик означенного события, назначение которой, как хочется напомнить, – определить, есть ли на странице то, что выражено присланным XPath.
В самом начале подраздела говорилось, что в части JavaScript станет применяться функция
evaluate, а если точнее, то следующая конструкция (позиция XPath из сообщения определена через заполнитель %s):document.evaluate('boolean(%s)', document, null, XPathResult.ANY_TYPE, null).booleanValueКак видно, тут за преобразование вычисленного к логическому типу отвечает функция
boolean, логика которой иногда может оказаться неподходящей – к примеру, если в Вашем случае XPath возвращает не набор узлов, а некое число, то нужно убедиться, что оно преобразуется ожидаемо, именно так, как хотелось.Ещё нелишне остановиться на нюансе с кавычками, а именно: XPath допускает применение как одинарных, так и двойных, однако JS выше корректным является лишь при использовании вторых (ибо одинарные уже задействованы), поэтому, чтобы не накладывать никаких ограничений на XPath по части кавычек, они станут экранироваться, в результате чего становится возможным даже их совмещение, например так –
//table[@class="display discog"]//tr[@id='some_value']. Отвечать за экранирование станет локальная функция:function EscapeQuotes(const UnsafeString: string): string;
const
SingleQuote = '''';
DoubleQuote = '"';
EscapeChar = '\';
begin
Result := UnsafeString.
Replace(SingleQuote, EscapeChar + SingleQuote).
Replace(DoubleQuote, EscapeChar + DoubleQuote);
end;Если не брать в расчёт только что обговорённых моментов, код обработчика события довольно прост и прямолинеен, в связи с чем приводится сразу, без постепенной выдачи, как практиковалось до этого почти во всей статье:
uses
System.SysUtils,
uCEFConstants, uCEFInterfaces, uCEFTypes, uCEFProcessMessage,
CEF.IPC;
type
EJSException = class(Exception);
procedure RenderProcessMessageReceivedHandler(const pBrowser: ICefBrowser;
const pFrame: ICefFrame; uSourceProcess: TCefProcessId;
const pMessage: ICefProcessMessage; var aHandled: boolean);
function EscapeQuotes(const UnsafeString: string): string;
...
const
JSTemplate = 'document.evaluate(''boolean(%s)'', document, null, XPathResult.ANY_TYPE, null).booleanValue';
var
XPath: string;
V8Context: ICefv8Context;
JSReturnValue: ICefv8Value;
JSException: ICefV8Exception;
Answer: ICefProcessMessage;
begin
aHandled := False;
if not Assigned(pMessage) then
Exit;
if pMessage.Name = XPathMessageName then
begin
Answer := TCefProcessMessageRef.New(pMessage.Name);
try
Answer.ArgumentList.SetInt( SuccessfulnessIndex, Ord(msOK) );
XPath := EscapeQuotes( pMessage.ArgumentList.GetString(XPathIndex) );
V8Context := pFrame.GetV8Context;
if V8Context.Enter then
try
V8Context.Eval( Format(JSTemplate, [XPath]), '', 1, JSReturnValue, JSException );
if Assigned(JSException) then
raise EJSException.CreateFmt
(
'...',
[
JSException.Message,
JSException.SourceLine,
JSException.LineNumber,
JSException.StartPosition,
JSException.EndPosition,
JSException.StartColumn,
JSException.EndColumn
]
);
Assert(JSReturnValue.IsBool);
Answer.ArgumentList.SetBool(XPathResultIndex, JSReturnValue.GetBoolValue);
finally
V8Context.Exit;
end
else
raise EJSException.Create('...');
except
on E: Exception do
begin
Answer.ArgumentList.Clear;
Answer.ArgumentList.SetInt( SuccessfulnessIndex, Ord(msException) );
Answer.ArgumentList.SetString(ExceptionClassIndex, E.ClassName);
Answer.ArgumentList.SetString(ExceptionTextIndex, E.Message);
end;
end;
pFrame.SendProcessMessage(PID_BROWSER, Answer);
aHandled := True;
end;
end;На этом реализацию
TDynamicSiteExtractor можно считать почти завершённой.Избавляясь от лишнего
Наверняка кто-то из читающих посчитал странным такой момент: разговор, казалось бы, всё время идёт о сайтах – вещи сугубо визуальной, – между тем материал никак не касался отрисовки загруженных страниц (как это делать, куда, на каком этапе), речь велась лишь об HTML-коде; разгадка здесь очень проста – какая бы то ни было визуализация просто-напросто отсутствует, по причине полной ненужности для решаемой задачи.
Необходимо пояснить, что CEF поддерживает так называемый OSR-режим, когда не создаётся стандартное для ОС окно, куда фреймворк самостоятельно выполняет отрисовку сайта, а вместо этого всё сохраняется в память, в некий буфер, содержимое которого можно, скажем, преобразовать в стандартный формат изображения (JPEG, PNG и т. п.), после чего сохранить, например в файл, или же передать по сети. Разработанный же класс, применяя означенный режим, не делает даже этого – буфер просто игнорируется – ведь нам интересны лишь данные, текстовое наполнение.
Раз имеется полное безразличие к внешнему виду, то выглядит разумным сделать вещь в общем-то необязательную (без данного подраздела работоспособность
TDynamicSiteExtractor ничуть не пострадает), но полезную – не запрашивать у веб-сервера как минимум изображения, видео, шрифты и, возможно, CSS. С первым из «расстрельного» списка всё просто, решение укладывается в одну строчку:constructor TDynamicSiteExtractor.Create(AOwner: TComponent);
begin
inherited;
...
LoadImagesAutomatically := False;
end;Избавиться же от оставшихся загружаемых ресурсов возможно через механизм фильтров, реализовав наследника
TCustomResponseFilter, причём из-за того, что действие со всеми типами ресурсов одно и то же и заключается в их игнорировании (отбрасывании), то и потомка достаточно одного:uses
..., uCEFResponseFilter;
type
...
TDynamicSiteExtractor = class(TChromium)
private
...
type
TRejectionResponseFilter = class(TCustomResponseFilter)
protected
function Filter(data_in: Pointer; data_in_size: NativeUInt;
var data_in_read: NativeUInt; data_out: Pointer; data_out_size: NativeUInt;
var data_out_written: NativeUInt): TCefResponseFilterStatus; override;
end;
...
end;
implementation
...
function TDynamicSiteExtractor.TRejectionResponseFilter.Filter(data_in: Pointer;
data_in_size: NativeUInt; var data_in_read: NativeUInt;data_out: Pointer;
data_out_size: NativeUInt; var data_out_written: NativeUInt): TCefResponseFilterStatus;
begin
Result := inherited;
data_in_read := 0;
data_out_written := 0;
end;А вот задействовать фильтр нужно в специальном виртуальном методе:
...
TDynamicSiteExtractor = class(TChromium)
...
private
FFilter: TRejectionResponseFilter;
...
protected
procedure doOnGetResourceResponseFilter(const browser: ICefBrowser;
const frame: ICefFrame; const request: ICefRequest; const response: ICefResponse;
var aResponseFilter: ICefResponseFilter); override;
...
end;
implementation
...
constructor TDynamicSiteExtractor.Create(AOwner: TComponent);
begin
inherited;
...
FFilter := TRejectionResponseFilter.Create;
end;
destructor TDynamicSiteExtractor.Destroy;
begin
...
inherited;
...
FFilter.Free;
end;
procedure TDynamicSiteExtractor.doOnGetResourceResponseFilter(const browser: ICefBrowser;
const frame: ICefFrame; const request: ICefRequest; const response: ICefResponse;
var aResponseFilter: ICefResponseFilter);
begin
inherited;
case request.ResourceType of
RT_IMAGE,
RT_FONT_RESOURCE,
RT_MEDIA,
RT_FAVICON:
aResponseFilter := FFilter;
else
aResponseFilter := nil;
end;
end;Константа
RT_IMAGE использована на случай, если свойство LoadImagesAutomatically, применённое чуть выше в конструкторе, всё-таки пропустит некоторые изображения; по желанию ещё можно добавить RT_STYLESHEET, если отсутствие CSS на интересующих сайтах никак не влияет на работу скриптов.InternetTools
Реализация заявленного в начале нового метода
IXQValue настолько проста, что даже не нуждается в каких-либо пояснениях:unit InternetTools.Realization;
interface
uses
simpleinternet, ...;
type
...
TXQValue = class(TInterfacedObject, IXQValue, IXQValueEnumerator)
private
...
function OpenDocument(const Source: WideString): IXQValue; safecall;
end;
implementation
...
function TXQValue.OpenDocument(const Source: WideString): IXQValue;
begin
FOriginalXQValue := process(Source, '/node()');
Result := Self;
end;Пример использования
Для демонстрации применения
TDynamicSiteExtractor предлагаются два Delphi-проекта (доступные для скачивания здесь):- VCL-приложение с одной формой, где будут создаваться экземпляры разработанного класса (CEF4Delphi поддерживает и FMX, поэтому данный вариант при надобности несложно переделать).
- Своеобразно урезанное VCL-приложение, не содержащее ни форм, ни модулей данных, – на его базе станут создаваться дочерние CEF-процессы. Как пояснялось в другом разделе, если не предполагается размещать CEF в DLL, то без такого отдельного проекта можно обойтись, однако автор хотел бы продемонстрировать именно универсальный вариант, пусть и добавляющий немного сложностей.
Дальнейшее повествование разделено на две части: первая описывает код, который требуется добавить в оба означенных проекта, чтобы они удовлетворяли требованиям CEF (без него проекты хоть и скомпилируются, но будут абсолютно неработоспособны), а во второй части излагается порядок сборки и что нужно проделать перед запуском получившегося основного приложения (которое с формой). Описанные в статье модули соотносятся с проектами указанным образом:
Инициализация CEF
Итак, чтобы с классом
TDynamicSiteExtractor можно было работать, требуется выполнить некоторые шаги по инициализации фреймворка, вопрос лишь в том – когда:- Если пользователь Вашего приложения использует функционал, требующий CEF, практически при каждом его запуске, то лучше всего вызывать представленный далее код сразу при старте, в dpr-файле (учитывая при этом указания из документации CEF4Delphi).
- Если функционал сосредоточен лишь в какой-то из форм, то код следует разместить в её событии
OnCreate(в примере сделано именно так). - В случае же очень редкого задействования CEF (условно в некой форме только при нажатии на весьма нечасто нужную кнопку) может быть разумно инициализировать и вовсе только в момент обращения к такой функции (то есть когда нажимается кнопка).
Подобная щепетильность связана с тем, что подготовка фреймворка к работе вполне в состоянии занимать до нескольких секунд, к тому же сразу приводя к запуску как минимум одного дочернего процесса.
Обращаясь к конкретике, прежде всего нужно присвоить значение глобальной объектной переменной
GlobalCEFApp и установить некоторые её свойства:uses
uCEFApplication;
procedure TfrMain.FormCreate(Sender: TObject);
begin
GlobalCEFApp := TCefApplication.Create;
GlobalCEFApp.WindowlessRenderingEnabled := True;
GlobalCEFApp.BrowserSubprocessPath := 'CEFSubprocess.exe';
GlobalCEFApp.FrameworkDirPath := 'CEF';
GlobalCEFApp.ResourcesDirPath := 'CEF';
GlobalCEFApp.LocalesDirPath := 'CEF\locales';
end;-
WindowlessRenderingEnabledотвечает за режим OSR, упоминавшийся ранее, обязывая выполнять отрисовку сайта в буфер в памяти. -
BrowserSubprocessPathодновременно и указывает на необходимость применять отдельный исполняемый файл для субпроцессов, и задаёт путь к нему (в данном случае – он должен находиться рядом с DemoApp.exe). - Если не использовать
FrameworkDirPathи два оставшихся параметра, то множество файлов из состава CEF (про них речь пойдёт в следующем подразделе) придётся разместить возле DemoApp.exe, создав тем самым изрядную свалку, поэтому более рациональный и аккуратный вариант подразумевает их складирование в отдельной папке, на которую данные параметры и обязаны указать.
За установкой свойств должен следовать вызов метода
StartMainProcess, имеющего многократно встречавшуюся особенность – он вернёт управление до того, как завершатся все инициированные им действия (информирование об окончании которых возложено на событие OnContextInitialized), поэтому будет применена шаблонная схема с ожиданием:uses
..., System.SyncObjs;
procedure TfrMain.FormCreate(Sender: TObject);
var
Event: TEvent;
begin
GlobalCEFApp := TCefApplication.Create;
...
GlobalCEFApp.OnContextInitialized :=
procedure
begin
Event.SetEvent;
end;
Event := TEvent.Create;
try
GlobalCEFApp.StartMainProcess;
Assert(Event.WaitFor = wrSignaled);
finally
GlobalCEFApp.OnContextInitialized := nil;
Event.Free;
end;
end;И только после этого допустимо создавать экземпляры
TDynamicSiteExtractor. Что касается освобождения ресурсов, то оно выглядит очень просто:procedure TfrMain.FormDestroy(Sender: TObject);
begin
DestroyGlobalCEFApp;
end;Инициализация в проекте дочерних процессов во многом схожа, с тем лишь принципиальным отличием, что расположена в dpr-файле (содержимое процедуры
RenderProcessMessageReceivedHandler приводилось ранее):program CEFSubprocess;
uses
..., uCEFApplicationCore;
...
procedure RenderProcessMessageReceivedHandler(const pBrowser: ICefBrowser;
const pFrame: ICefFrame; uSourceProcess: TCefProcessId;
const pMessage: ICefProcessMessage; var aHandled: boolean);
...
begin
GlobalCEFApp := TCefApplicationCore.Create;
GlobalCEFApp.WindowlessRenderingEnabled := True;
GlobalCEFApp.OnProcessMessageReceived := RenderProcessMessageReceivedHandler;
GlobalCEFApp.FrameworkDirPath := 'CEF';
GlobalCEFApp.ResourcesDirPath := 'CEF';
GlobalCEFApp.LocalesDirPath := 'CEF\locales';
GlobalCEFApp.StartSubProcess;
DestroyGlobalCEFApp;
end.Важно, чтобы значения свойств
WindowlessRenderingEnabled, FrameworkDirPath и двух оставшихся совпадали с тем, что задано для основного приложения.Сборка и запуск
- Прежде всего, разумеется, требуется скачать и установить CEF4Delphi, следуя официальной инструкции (однако имеется нюанс: свежие выпуски библиотеки поддерживают только Windows 10 и новее, поэтому когда необходима работа на иных версиях ОС, нужно ознакомиться с данным разделом документации; в этом ограничении виновата не CEF4Delphi, как можно было бы подумать, а сам проект Chromium).
- Открыть HabrArticle.groupproj и скомпилировать оба проекта (в любом порядке), после чего в папке VCL-приложение\Win64\Debug должны появиться два исполняемых файла – DemoApp.exe и CEFSubprocess.exe.
- Скачать набор 64-разрядных CEF-файлов (не забывая про ремарку о версии Windows в первом пункте) и скопировать, в соответствии с этими указаниями, в папку VCL-приложение\Win64\Debug\CEF.
- Запустить DemoApp.exe.
Robastik
Аплодирую стоя.
Хотелось бы узнать больше о вашей реализации.
1. В какой области применяется?
В т.н. промышленном парсинге, когда заказчик получает готовую БД, рационально использовать селениум-подобные решения по причине удобства поддержки в процессе ротации поддерживальщиков (общераспространенный стек, специалистов море). Когда заказчик сам нажимает кнопку запуска парсинга и поддержка работает удаленно, применяются решения разной степени облачности (которых море).
Какая ниша у вашего решения?
Антиботная повестка актуальна как никогда (Твитер). Поэтому все решения для парсинга оцениваются через призму этого противостояния. Вы используете безголовый режим для экономии на спичках. Данные давно стали дороже этих крох. Хедлес это красный флаг для защиты.
Каков потенциал решения для подделки отпечатка?
Хромиум торт для многих задач, но ведь желательно не тратиться на рутинные задачи типа обновления версий. Как часто обновляется CEF? Насколько он поспевает за Хромом? Edge WebView2 дает возможность evergreen, что существенно снижает издержки поддержки, увеличивает срок жизни приложения до очередного апдейта.
Так почему Хромиум?
SergeyPyankov Автор
Таким образом, речи о промышленном уровне — когда всё сразу гибко, универсально и настраиваемо — не идёт.
Возможно я не очень понял, но каким образом отрисовка в буфер может быть отслежена? Навскидку, с ней даже не должно быть технических препятствий для добавления имитации действий человека (движение мыши, ввод с клавиатуры), если такое вдруг потребуется.
С данной темой совершенно не сталкивался в практическом плане, поэтому могу разве что сослаться на предыдущий абзац — любая имитация человека скорее всего возможна (в том числе со случайными отклонениями, а не по одному и тому же шаблону).
Из-за большей всеядности CEF в плане ОС — в дальнейшем может потребоваться поддержка Линукс.
Robastik
Несколько возможностей.
Ваш парсер живет в службе, о которой вы писали в прошлый раз?
SergeyPyankov Автор