

Изменять конфигурацию узла Kubernetes нужно не только в момент создания кластера, но и при его обновлениях или изменениях в инфраструктуре. Хорошо, если узлы можно автоматизированно пересоздать или изменить без перезагрузки узла. А что делать, если такой возможности нет или количество узлов в кластере переваливает за сотню?
Меня зовут Александр Краснов, CTO платформы «Штурвал» в компании «Лаборатория Числитель». Мы занимаемся разработкой программного обеспечения, создаем собственные продукты в области контейнерных платформ, DevOps, облачных решений и мониторинга. Я же проектирую и внедряю Kubernetes в Enterprise.
В основе этого поста — мой доклад с DevOps Conf 2023. Я расскажу про распространенные варианты управления конфигурацией кластеров с помощью Ansible, Cluster API и OpenShift Machine Config.
Day 2 operations
Пока есть лишь чистые узлы и голая инфраструктура, можно крутить кластер как угодно. Но как только в кластер въезжает приложение, начинаются приключения: появляются обязательства, SLA. Иными словами, разработчиков начинают бить по шапке. Потому что нужно постоянно:
обновлять ОС;
обновлять отдельные пакеты и драйверы;
изменять параметры ядра;
управлять доверенными сертификатами.
Ситуация осложняется, когда узлов несколько сотен, и все они в проде.
Сначала придут безопасники и скажут, что кластер торчит всеми местами наружу, его нужно срочно закрывать, чтобы не хакнули.
Следующий вариант развития событий — это изменения в инфраструктуре. Такое случается не часто, но бывает, что меняются NTP и корпоративный центр сертификации, или просто был отозван глобальный сертификат.
Наконец, наименее популярный вариант, который тоже имеет место, — это необходимость часто менять конфигурацию узлов. Такое может быть, если вы используете специфичное железо или специфичный набор технологий. Например, SR-IOV — технология виртуализация сетевых карт — или видеокарты на узлах кластера. В этих случаях потребуется специфическая настройка ядра, драйверов, ОС. Менять эти настройки на узлах придется довольно часто.
Идеальный мир
Давайте пофантазируем и рассмотрим идеальный сценарий развития событий.
Во-первых, как нормальным разработчикам, нам ничего не хочется делать руками.
Во-вторых, хочется уметь конфигурировать как один, так и целые группы узлов в кластере. Также было бы удобно переиспользовать один и тот же конфиг для разных узлов, чтобы не плодить сущности.
В-третьих, если ночью или в любое другое время что-то ломается, то не хочется вставать и исправлять вручную. Пусть оно как-то автоматически разберется с проблемой. Иными словами, хочется автоматический Rollback для отката назад и Self-Healing, чтобы само всё чинилось.
В-четвертых, автоматизация не должна разваливать кластер, иначе всё будет напрасно.
И, наконец, в-пятых, средство управления конфигурациями должно работать с физическими хостами.
Решения
Есть четыре потенциальных способа решения:
Взять Ansible или любой Ansible Like Tool, который позволяет раскатить конфигурацию на нужное количество узлов.
Взять Cluster API или любую другую замену этого фреймворка, чтобы управлять конфигурацией узлов.
Machine Config Operator от RedHat: либо в OpenShift, либо в OKD.
Изобрести свой велосипед.
Ansible
Ansible позволяет ничего не делать руками и раскатить конфигурацию узлов на нужные узлы, в т. ч. в разных кластерах. Кроме того, можно не перезагружать узлы в плейбуке. Это возможно благодаря оператору KUbernetes REboot Daemon — Kured. Он сам отследит необходимость перезагрузки и будет управлять ее очередностью. Он позволяет управлять и автоматизировать сам процесс перезагрузки узлов. В частности, он может отслеживать определенные маркеры, когда узел требует перезагрузки. Мы с командой использовали эту возможность Ansible, чтобы раскатить новую версию ядра. Оператор понял, что нам нужна перезагрузка, мы задали ему определенные параметры, и дальше он сам дирижировал. При этом параметров много: настройка окна перезагрузки, получение нотификации, отметка нод и другие. Всё это позволяет подстраховаться и не развалить кластер. Причем раскатать можно хоть на один хост, хоть на все узлы. На физическом уровне тоже проблем не возникает. Также для Kured’a доступны следующие настройки:
Drain или Force Reboot;
окна перезагрузки;
оповещения (Webhook или Slack).
Но есть трудности:
→ Если кластеру не удается обновиться, то откатиться назад с помощью Rollback проблематично.
Rollback в Ansible — тема для отдельного поста, поэтому здесь мы не будем останавливаться на деталях.
→ Ansible — это внешняя сущность.
Ansible работает по принципу «я всё раскатил, а дальше свободен». Поэтому узел он сам не починит. Придется вручную мониторить и откатывать кластер, который может развалиться, если сделать что-то не то.
Cluster API
Cluster API — самый промышленный и распространенный фреймворк для автоматизации жизненного цикла кластеров. У него меняются «запчасти» и есть плагины. Плагины бывают двух видов — Bootstrap и инфраструктурные провайдеры. Вот схема их взаимодействия:

То, что выделено зеленым — это специфическая реализация инфраструктуры, провайдер которой создает виртуальную машину или подготавливает физический хост. Другой провайдер — Bootstrap-провайдер — генерирует конфигурацию. Ему можно задать в виде параметров, как сконфигурировать узлы и ОС. Весь этот процесс передается в виде Cloud-Init и идет от провайдера, который делает Bootstrap, в инфраструктурный провайдер. То есть Bootstrap-провайдер при создании машины генерирует Cloud-Init, записывает его в секрет, который уже подхватывает инфраструктурный провайдер. Тот начинает создавать машину только тогда, когда этот секрет готов, и он может его вытащить.
Рассмотрим конкретную реализацию Cloud-Init — KubeadmConfigSpec, который представляет собой Bootstrap-провайдер, основанный на Kubeadm. В качестве параметров он поддерживает:
Файлы и директории.
Настройку файловых систем (включая разметку блочных устройств).
Монтирование файловых систем.
Создание пользователей.
NTP.
Императивные команды: PreKubeadmCommand и PostKubeadmCommand, которые выполняются перед и после Kubeadm соответственно. Но важно учитывать, что если хоть одна из этих команд выйдет не с нулем, то установка узла не произойдет. То есть всё будет работать только тогда, когда все команды, включая Kubeadm, выполнятся.
Во всей этой конструкции есть один важный минус — работает она один раз, когда создается узел. Если же добавить в Bootstrap-провайдер новый template, он будет всё перекатывать.
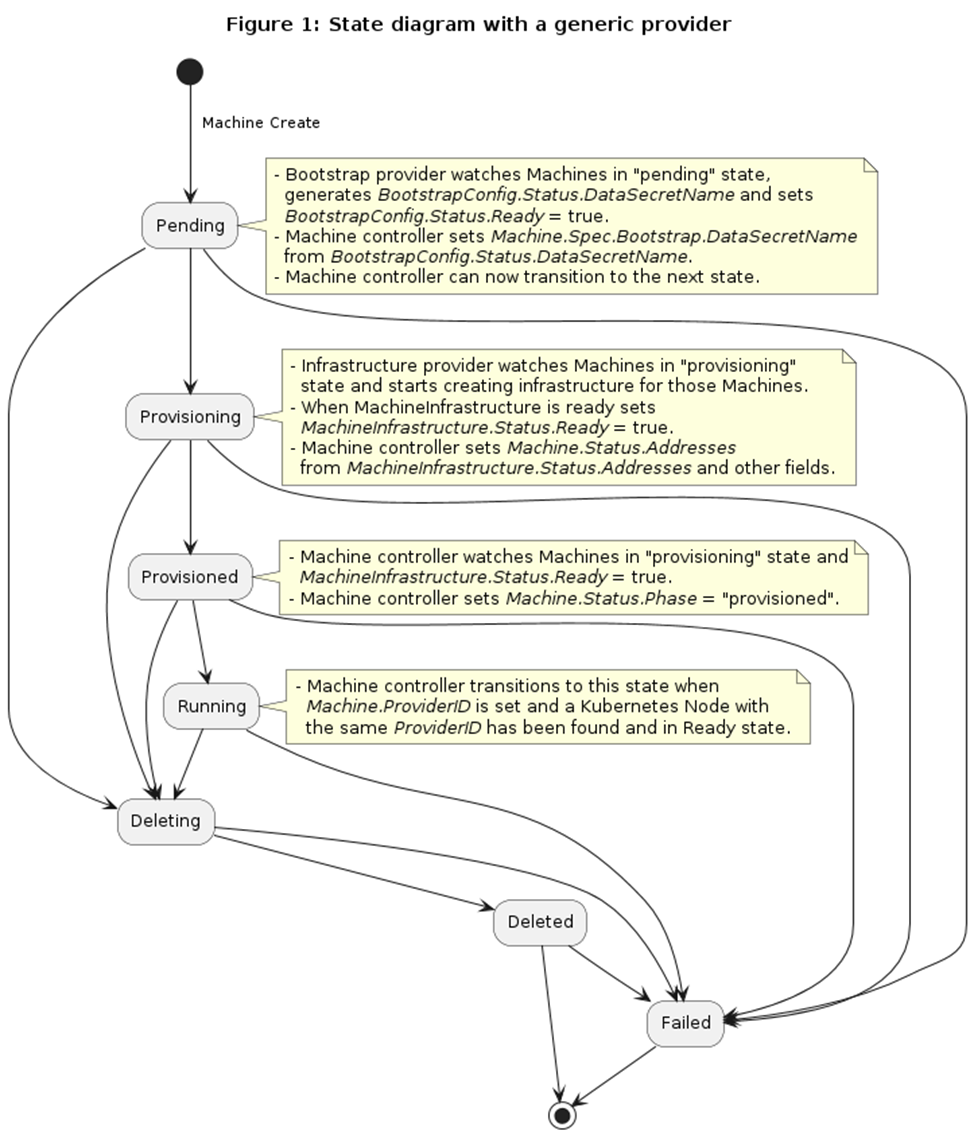
В итоге получается, что ничего не нужно делать руками. Rollback создает новый узел. Если меняется конфигурация и ReplicaSet не срабатывает, то, соответственно, машина не заводится, но и старые удаляться не будут. То есть при поломке кластер не разваливается. Но есть нюансы:
→ Вложенная конфигурация, а не отдельный манифест.
В каждом кластере есть одна обязательная группа узлов, которая называется Control Plane, также может быть несколько групп воркеров. За каждую из этих групп отвечает собственный ресурс, к примеру, Control Plane или Machine Deployment. В каждом из них необходимо прописать свои параметры, которые зашиты внутрь манифеста. Но манифесты различаются для разных групп узлов, поэтому не получится применить настройки в одной группе для всех остальных. Это придется сделать вручную: городить Kustomize и разделять параметры.
→ Если узел сломался, он сам починится.
Можно настроить штатный мониторинг живых узлов. Но если узел отвалился, на его месте будет создан новый.
→ Определенные требования для работы с физическими хостами.
Есть провайдер — Metal3, у которого есть специфические требования.
OpenShift
Мой любимый зверь — это OpenShift. Четвертый OpenShift заметно отличается от всего остального на рынке. В основе этого отличия — механизм Machine Config Operator. Вся работа с кластерами построена вокруг этого механизма. Он использует CoreOS, которая при старте получает определенную конфигурацию в формате Ingnition и полностью переопределяет свою корневую файловую систему: содержимое /etc и /var. То есть новая конфигурация дает, по сути, новый релиз ОС, и это обновление происходит транзакционно. Это возможно благодаря транзакционному механизму обновления ОС rpm-ostree, который вдобавок позволяет откатить транзакцию и вернуться к предыдущему состоянию. Но если что-то пойдет не так, нужно будет разбираться вручную. Ignition дает контроль над следующими параметрами:
ключи SSH (только для пользователя core);
Systemd;
CRI-O/Kuberlet;
Kernel;
NetworkManager;
данные при перезагрузке узла в /etc и /var.
Внутри всё это работает благодаря ресурсам типа Machine Config, которые задает администратор. Они содержат указания, куда применять конфигурацию для Machine Pool — доступных групп узлов. По умолчанию таких групп две: Control Plane и воркеры. На основании этого Machine Config оператор генерирует уже сводную конфигурацию для Machine Pool и распределяет ее по узлам. Демоны, которые запущены на узлах, подхватывают эту конфигурацию и начинают по очереди применять. Очередностью применения заведует оператор. Если обновление не проходит, то должен вмешаться администратор.

Вот итоговые замечания по OpenShift:
→ Можно ничего не делать руками.
Конфиги, которые, по сути, являются отдельными манифестами, можно переиспользовать в разных кластерах. Причем можно следовать разным подходам: CI/CD, GitOps и другим, в зависимости от того, какие вам нравятся. Кластер в любом случае не развалится, так как оператор за ним следит и не даст применить неподходящий конфиг ко всем подряд узлам.
→ Неавтоматический RollBack.
Если у вас есть валидная конфигурация, но вам не нравится результат, то можно просто удалить манифест. Оператор перерендерит Machine Config на новую конфигурацию. Однако если манифест cбойный именно с Machine Config, придется разбираться вручную.
→ Нельзя сделать Machine Config, который бы работал на группу Control Plane и на группу Workers.
Например, нужно раскидать один SSH-ключ по всем узлам. Для этого придется сделать как минимум два Machine Config.
Свой велосипед
В платформе «Штурвал» мы перепробовали все решения. Особенно долго жили с Ansible. Но в конце концов решили строить свой луна-парк со всеми необходимыми атрибутами. В частности, мы написали собственный оператор Shturval Node Config, получились CRD с примерно такой спекой:
spec:
nodeconfigselector:
node-role.kubernetes.io/control-plane: ""
priority: 100
files:
- path: "/etc/kubernetes/audit_policy.yaml"
type: "File"
mode: 0644
owner: "root"
group: "root"
content: |
apiVersion: audit.k8s.io/v1
kind: Policy
# Игнорируем стадию запроса RequestReceived.
omitStages:
- "RequestReceived"
rules:Сам Custom Resource представляет собой обычный манифест, где есть селектор Priority и набор ресурсов, которыми он управляет. К ним относятся:
файлы и директории;
репозитории;
пакеты;
доверенные сертификаты;
NTP;
параметры grub;
модули ядра;
конфигурация Container Runtime;
Sysctl;
Systemd-юниты;
пользователи.
При этом Node Config Items можно хранить в git и переиспользовать в разных кластерах.
Из интересного и неочевидного: оператор может переопределять Registry. Это позволяет переопределить, например, Docker Hub для разработчика, чтобы он даже не узнал, откуда берутся образы контейнеров. Можно также добавить авторизацию для Registry.
Чтобы сделать управление произвольным количеством узлов, мы не стали выдумывать и взяли механизм лейблов узлов. Оператор выбирает, на какие узлы применить Node Config Item на основе совпадения лейблов. Так, максимально широкий лейбл kubernetes.io/os=linux позволяет охватить все Linux-узлы. Или наоборот, для изменения одного узла можно использовать очень узкий лейбл kubernetes.io/hostname=master01. Все эти Node Config Items собираются в Node Config и привязываются к нему.
На каждом узле есть демон, который отслеживает спеку Node Config в кластере, актуализирует локальный кэш конфигурации. После того как все конфигурации оказались на диске, демон их мержит и получает целевую конфигурацию.
Но могут возникнуть отклонения — дрифты. Причины бывают разными. Например, админ может сделать изменения локально на хосте. В любом случае демон анализирует дрифты: насколько они опасны и что нужно менять. Если они безопасны, то демону, например, достаточно поставить пакет, никого не спрашивая. Но если действия потенциально опасны или требуют Reboot, то демон запросит разрешение на перезагрузку у оператора.
При применении конфигурации демон или весь узел может перезагрузиться. Если конфигурация сбойная или мы где-то ошиблись, то применение этой конфигурации сломает узел, и он не сможет подключиться к кластеру. В этом случае демон должен увидеть, что узел не работает, а значит, нужно сделать Rollback.
Самое сложное — выставить однозначные критерии, когда нужен Rollback. Нужно понимать — проблема заключается в наших действиях или сбой на узле был вызван какими-то внешними факторами.
Чтобы кластер не развалился, есть определенная система защиты, которая состоит из оператора и демона. Оператор принимает решения, а демон передает актуальную информацию об узле. Если демон видит дрифт, он запрашивает у оператора перезагрузку через Custom Resources. Оператор, в свою очередь, смотрит, есть ли у группы узлов, которой принадлежит запрашивающий узел, свободные слоты для перезагрузки. Если нет, то оператор не позволит демону перезагрузиться. Но если есть, то он ставит демона в очередь, кордонит и дрейнит. Как только дрейн закончится, он ответит демону, что можно перезагрузиться. В целом, можно даже вручную помочь оператору, поставив статус, что можно запустить Reboot.

В итоге в операторе получилось сделать следующее:
→ Автоматизировать процесс.
Ничего не нужно делать руками. Достаточно просто кинуть манифест. Их можно переиспользовать, объединять между собой в зависимости от приоритета. При этом темплетировать необязательно.
→ Конфигурировать произвольное количество узлов.
Конфигурация применяется на все узлы, у которых есть определенный лейбл.
→ Rollback.
Он отрабатывает в большинстве случаев, где это в принципе возможно.
→ Неразваливаемый кластер.
Оператор управляет очередностью применения опасных конфигураций на узлах.
→ Обеспечить работу с физическими хостами.
В заключение хочу отметить, что у каждого решения есть свои плюсы и минусы, и они могут быть валидны в каждой конкретной ситуации. Тестируйте различные решения на своих задачах и не ленитесь автоматизировать — это действительно полезно.
Александр Краснов
CTO платформы "Штурвал"