
Несколько месяцев назад мне захотелось написать компилятор C на 500 строк Python. Сложно ли это? О да, даже если отказаться от многих функций. Но, в то же время, это ужасно интересно, а результат оказался на удивление функциональным и несложным для понимания!
Кода получилось слишком много, чтобы разобрать его полностью в одной статье, поэтому тут будет просто обзор решений, принятых в ходе работы, фрагментов, которые пришлось вырезать, и общей архитектуры компилятора. Это должно сделать код более доступным.
Решения, решения
Первым и наиболее важным решением стало то, что компилятор будет однопроходным. 500 строк — слишком мало для определения и преобразования абстрактного синтаксического дерева! Что это значит?
Большинство компиляторов — сплошная возня с синтаксическими деревьями
Большинство внутренних компонентов компилятора выглядит примерно так:
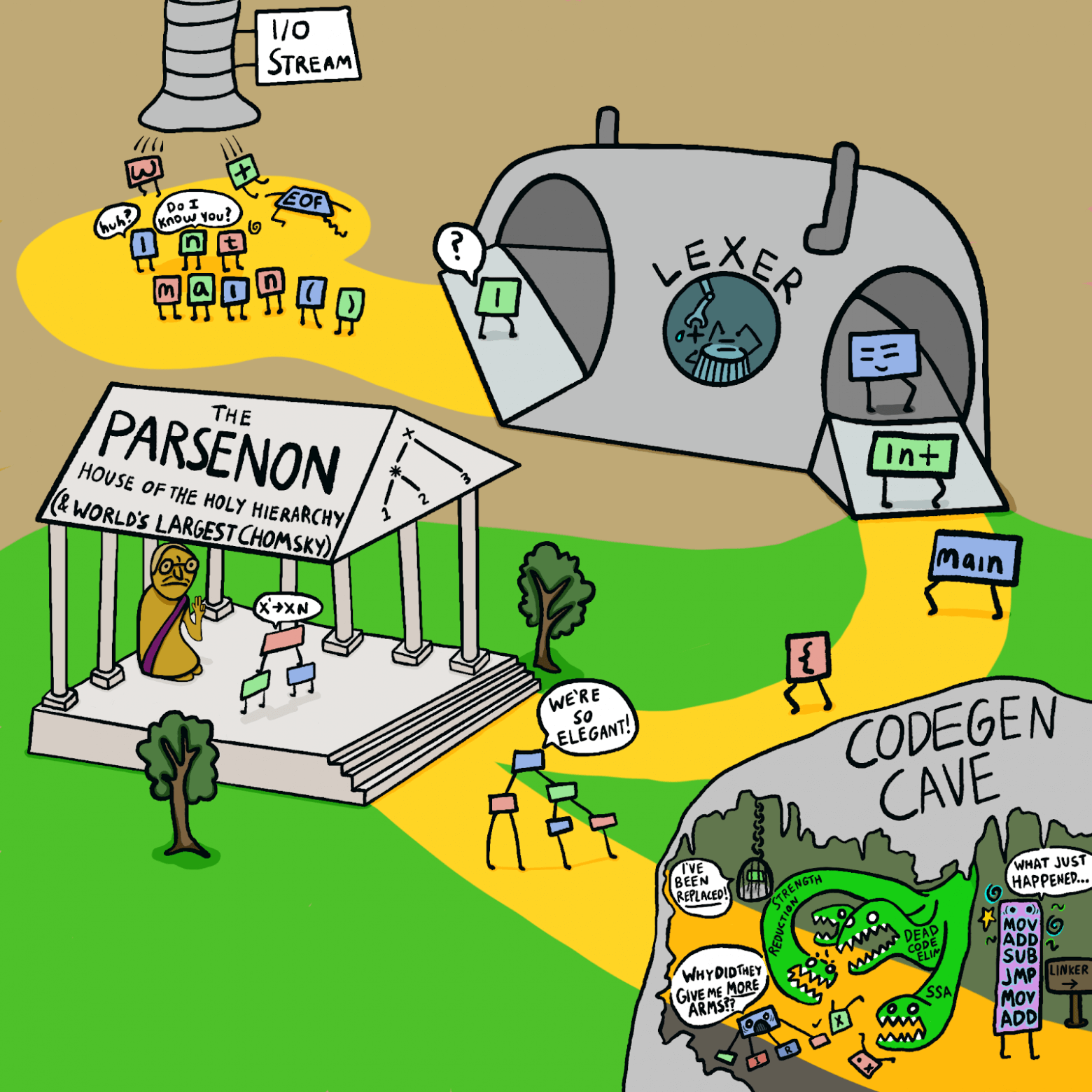
Токены лексируются, затем анализатор обрабатывает их и строит маленькие синтаксические деревья:
# hypothetical code, not from anywhere
def parse_statement(lexer) -> PrettyLittleSyntaxTree:
...
if type := lexer.try_next(TYPE_NAME):
variable_name = lexer.next(IDENTIFIER)
if lexer.try_next("="):
initializer = parse_initializer(lexer)
else:
initializer = None
lexer.next(SEMICOLON)
return VariableDeclarationNode(
type = type,
name = variable_name,
initializer = initializer,
)
...
# much later...
def emit_code_for(node: PrettyLittleSyntaxTree) -> DisgustingMachineCode:
...
if isinstance(node, VariableDeclarationNode):
slot = reserve_stack_space(node.type.sizeof())
add_to_environment(node.name, slot)
if node.initializer is not None:
register = emit_code_for(node.initializer)
emit(f"mov {register}, [{slot}]")
...Есть два прохода: сначала синтаксический анализ выстраивает синтаксическое дерево, затем второй проход пережёвывает это дерево и превращает его в машинный код. Это действительно полезно для большинства компиляторов! Оно разделяет процесс синтаксического анализа и создание кода, поэтому каждый из них может развиваться независимо. Это также означает, что вы можете преобразовать синтаксическое дерево перед его использованием для генерации кода, например, применив к нему оптимизацию. Фактически, большинство компиляторов имеют несколько уровней «промежуточных представлений» между синтаксическим деревом и генератором кода.
Это действительно круто, бест практис и всё такое, но требует чертовски много кода! Поэтому мы так делать не можем.
Вместо этого будем делать однопроходный компилятор: генерация кода происходит прямо в процессе синтаксического анализа. Мы чуть-чуть анализируем, выдаём немного кода, анализируем ещё немного, выдаём ещё чуть-чуть кода. Например, вот реальный код компилятора С500 для анализа префикса ~op:
# lexer.try_next() checks if the next token is ~, and if so, consumes
# and returns it (truthy)
elif lexer.try_next("~"):
# prefix() parses and generates code for the expression after the ~,
# and load_result emits code to load it, if needed
meta = load_result(prefix())
# immediately start yeeting out the negation code!
emit("i32.const 0xffffffff")
emit("i32.xor")
# webassembly only supports 32bit types, so if this is a smaller type,
# mask it down
mask_to_sizeof(meta.type)
# return type information
return metaОбратите внимание: здесь нет ни синтаксических деревьев, ни PrefixNegateOp узлов. Видим какие-то токены и тут же выплёвываем соответствующие инструкции.
Возможно, вы заметили, что эти инструкции — WebAssembly, поэтому…
Зачем использовать WebAssembly
… поэтому было решено сделать компилятор ориентированным на WebAssembly. Честно говоря, не знаю, почему я это сделала, легче от этого не стало — наверное, мне просто было любопытно. WebAssembly — действительно странное решение, особенно для C. Помимо ряда побочных проблем (например, я надолго зависла, пока не осознала, что WebAssembly v2 сильно отличается от WebAssembly v1), сам набор инструкций тоже странный.
Во-первых, нет оператора goto. Вместо этого у вас есть блоки — структурированная сборка, только представьте себе! — и инструкции «разрыва», которые переходят либо в начало, либо в конец определённого уровня вложенности блока. Для if и while это было несущественно, а в процессе реализации for я прокляла всё на свете, но об этом позже.
Кроме того, в WebAssembly нет регистров, есть стек и стековая машина. Поначалу вы можете сказать: да это же круто! Для языка C нужен стек! Мы можем просто использовать стек WebAssembly в качестве стека C! А вот и нет. Вы не можете брать ссылки на стек WebAssembly. Поэтому нам в любом случае придётся поддерживать собственный стек в памяти, а затем включать и выключать shuffle из стека параметров WASM.
В итоге получилось немного больше кода, чем было бы при более нормальной ISA, такой как x86 или ARM. Но это было интересно! И теоретически вы можете запустить код, скомпилированный c500 с помощью браузера, хотя я не пробовала (я использую wasmerCLI).
Обработка ошибок
Такого нет в принципе. Есть функция die, которая вызывается, когда происходит что-то странное. Она выводит трассировку стека компилятора, и если вам повезет, вы получите номер строки и расплывчатое сообщение об ошибке.
------------------------------
File "...compiler.py", line 835, in <module>
compile("".join(fi)) # todo: make this line-at-a-time?
File "...compiler.py", line 823, in compile
global_declaration(global_frame, lexer)
<snip>
File "...compiler.py", line 417, in value
var, offset = frame.get_var_and_offset(varname)
File "...compiler.py", line 334, in get_var_and_offset
return self.parent.get_var_and_offset(name)
File "...compiler.py", line 336, in get_var_and_offset
die(f"unknown variable {n}", None if isinstance(name, str) else name.line)
File "...compiler.py", line 14, in die
traceback.print_stack()
------------------------------
error on line 9: unknown variable cЭто вам не компилятор Rust :-)
От чего отказаться?
Наконец, мне пришлось решить, от каких функций отказаться, поскольку уместить весь C в 500 строк было просто невозможно (уж извините!). Я решила, что мне нужна действительно хорошая выборка функций, которая позволит проверить возможности моего подхода к реализации в целом — например, если бы я отказалась от типа данных «указатели», я могла бы просто обойтись без стека параметров WASM и значительно всё упростить, но это было бы читерством.
В итоге я реализовала следующие функции:
арифметические операции и бинарные операторы с надлежащим приоритетом
типы int, short и char
строковые константы (с escapes)
указатели (любого количества уровней), включая правильную арифметику указателей (приращение на int*4)
массивы (только одноуровневые, не int[][])
функции
Определения типов typedefs (и lexer hack!)
Примечательно, что он не поддерживает:
структуры :-( Это было бы возможно, если бы было больше кода. У меня даже были основы, но я просто не смогла их втиснуть
enums (перечисления)/unions (объединения)
директивы препроцессора (это само по себе уже может занять 500 строк...)
плавающая запятая. Тоже можно реализовать, wasm_type материал есть, но, опять же, просто не смог его втиснуть
8-байтовые типы ( long/long long или double)
некоторые другие мелочи, такие как операторы pre/post increments, инициализация на месте и т. д., которые просто не совсем подходили
любая стандартная библиотека или ввод-вывод, который не возвращает целое число из main()
выражения приведения
Компилятор проходит 34 из 220 тестов в c-testsuite. Что еще важнее, он может успешно скомпилировать и запустить следующую программу:
int swap(int* a, int* b) {
int t;
t = *a; *a = *b; *b = t;
return t;
}
int fib(int n) {
int a, b;
for (a = b = 1; n > 2; n = n - 1) {
swap(&a, &b);
b = b + a;
}
return b;
}
int main() {
return fib(10); // 55
}Ну всё, хватит о решениях, давайте перейдем к коду!
Типы помощников
Компилятор использует небольшую коллекцию вспомогательных типов и классов. Они все довольно обычные, поэтому я просто быстренько по ним пробегусь.
Emitter (compiler.py:21)
Это одноэлементный помощник для создания красиво отформатированного WebAssembly кода.
WebAssembly, по крайней мере текстовый формат, форматируется как s-выражения, но отдельные инструкции не нужно заключать в круглые скобки:
(module
;; <snip...>
(func $swap
(param $a i32)
(param $b i32)
(result i32)
global.get $__stack_pointer ;; prelude -- adjust stack pointer
i32.const 12
i32.sub
;; <snip...>
)
)Emitter просто помогает создавать код с красивыми отступами, чтобы его было легче читать.
StringPool ( compiler.py:53 )
StringPool хранит все строковые константы, чтобы их можно было расположить в непрерывной области памяти, и передаёт в нее адреса для использования генератором кода. Когда вы пишете char *s = "abc" в c500, на самом деле происходит следующее:
StringPool добавляет нуль-терминатор
StringPool проверяет, хранит ли он уже "abc", и если да, просто возвращает этот адрес
В противном случае StringPool добавляет его в словарь вместе с базовым адресом + общей длиной сохраненных на данный момент байтов (адрес этой новой строки в пуле).
StringPool возвращает этот адрес
Когда весь код завершен, мы создаем раздел rodata с гигантской объединенной строкой, созданной StringPool, хранящейся по базовому адресу пула строк (задним числом делая все переданные адреса StringPool действительными).
Lexer ( compiler.py:98 )
Класс Lexer сложен, потому что и лексирование C сложное ( (\\([\\abfnrtv'"?]|[0-7]{1,3}|x[A-Fa-f0-9]{1,2})) это настоящее регулярное выражение в этом коде для escape-символов), но концептуально всё просто: лексер идентифицирует токен в текущей позиции. Вызыватель (the caller) может просмотреть этот токен или использовать next, чтобы лексер двигался дальше, «потребляя» этот токен. Он также может использовать try_next для условного продвижения, только если следующий токен определенного типа — по сути, try_next это сокращение для выражения if self.peek().kind == token: return self.next().
Есть некоторая дополнительная сложность из-за так называемого «Lexer hack». По сути, при анализе C вы хотите знать, является ли что-то именем типа или именем переменной (потому что контекст имеет значение для компиляции определенных выражений), но между ними нет синтаксического различия: int int_t = 0; для C абсолютно корректен, как и typedef int int_t; int_t x = 0;.
Чтобы узнать, является ли произвольный токен int_t именем типа или именем переменной, нам нужно передать информацию о типе со стадии синтаксического анализа/генерации кода обратно в лексер. Это огромная проблема для обычных компиляторов, которые хотят сохранить свои модули лексера, парсера и кодогенератора чистыми и отделёнными, но на самом деле для нас это не очень сложно! Я объясню это подробнее, когда дойдём до раздела typedef, но в основном мы просто сохраняем types: set[str], Lexer и при лексировании проверяем, есть ли токен в этом наборе, прежде чем присваивать ему тип токена:
if m := re.match(r"^[a-zA-Z_][a-zA-Z0-9_]*", self.src[self.loc :]):
tok = m.group(0)
...
# lexer hack
return Token(TOK_TYPE if tok in self.types else TOK_NAME, tok, self.line)CType ( compiler.py:201 )
Это просто класс данных для представления информации о типе C, как если бы вы писали int **t или short t[5] или char **t[17], за вычетом t.
Там содержится:
имя типа (с разрешенными определениями типов), например int или short
уровень указателя ( 0= не указатель, 1= int *t, 2= int **t и т. д.)
размер массива ( None= не массив, 0= int t[0], 1= int t[1] и т. д.)
Примечательно, что этот тип поддерживают только одноуровневые массивы, а не вложенные массивы, такие как int t[5][6].
FrameVar и StackFrame ( compiler.py:314 )
Эти классы обрабатывают наши фреймы стека C. Поскольку вы не можете использовать ссылки на стек WASM, приходится вручную обрабатывать стек C.
Чтобы настроить стек C, в, __main__, устанавливается глобальная переменная __stack_pointer, а затем каждый вызов функции уменьшает её на столько, сколько функции требуется для своих параметров и локальных переменных. Это рассчитывает экземпляр StackFrame данной функции.
Я более подробно расскажу о том, как работает это вычисление, когда мы перейдём к анализу функций, но, по сути, каждый параметр и локальная переменная получают слот в этом пространстве стека и увеличиваются (и, следовательно, происходит смещение StackFrame.frame_size следующей переменной) в зависимости от размера. Смещение, информация о типе и другие данные для каждого параметра и локальной переменной хранятся в экземпляре FrameVar в StackFrame.variables в порядке объявления.
ExprMeta ( compiler.py:344 )
Этот последний класс данных используется для отслеживания того, является ли результат выражения значением или местом. Нам необходимо учитывать это различие, чтобы по-разному обрабатывать определённые выражения в зависимости от того, как они используются.
Например, если у вас есть переменная x типа int, её можно использовать двумя способами:
Чтобы продолжить вычисление, выражению x + 1 требуется значение x, например, 1
А выражению &x требуется адрес x , скажем 0xcafedead
Когда мы анализируем выражение x, мы можем легко получить адрес из фрейма стека:
# look the variable up in the `StackFrame`
var, offset = frame.get_var_and_offset(varname)
# put the base address of the C stack on top of the WASM stack
emit(f"global.get $__stack_pointer")
# add the offset (in the C stack)
emit(f"i32.const {offset}")
emit("i32.add")
# the address of the variable is now on top of the WASM stackНо что теперь? Если мы загрузим этот адрес по i32., чтобы получить значение, то у &x не будет возможности получить адрес. Но если мы его не загрузим, x + 1 попытается прибавить к адресу единицу, в результате вместо 2 получится 0xcafedeae!
Вот тут-то и выходит на сцену ExprMeta: мы оставляем адрес в стеке и возвращаем ExprMeta указывающее, что это — то самое место :
return ExprMeta(True, var.type)Затем, для операций типа +, которые всегда хотят работать со значениями, а не с местами, есть функция load_result, которая превращает любые места в значения:
def load_result(em: ExprMeta) -> ExprMeta:
"""Load a place `ExprMeta`, turning it into a value
`ExprMeta` of the same type"""
if em.is_place:
# emit i32.load, i32.load16_s, etc., based on the type
emit(em.type.load_ins())
return ExprMeta(False, em.type)
...
# in the code for parsing `+`
lhs_meta = load_result(parse_lhs())
...Между тем, операция типа & просто не загружает результат, а вместо этого оставляет адрес в стеке: таким образом, & — это пустая операция в нашем компиляторе, поскольку она не генерирует никакого кода!
if lexer.try_next("&"):
meta = prefix()
if not meta.is_place:
die("cannot take reference to value", lexer.line)
# type of &x is int* when x is int, hence more_ptr
return ExprMeta(False, meta.type.more_ptr())Также обратите внимание: несмотря на то, что это адрес, результат & не является местом! (Код возвращает ExprMeta со значением is_place=False) Результат & следует рассматривать как значение, поскольку к адресу &x + 1 следует добавить 1 ( или даже sizeof(x)). Вот почему нам нужно различать места и значения, поскольку просто «быть адресом» недостаточно, чтобы знать, следует ли загружать результат выражения.
Ладно, хватит о вспомогательных классах. Перейдем к сути кодегена!
Парсинг и генерация кода
Общий поток управления компилятором выглядит следующим образом:

Синие прямоугольники - основные функции компилятора __main__— , compile(), global_declaration(), statement()и expression().
Длинная цепочка квадратов внизу показывает приоритет оператора — однако большинство этих функций автоматически генерируются функцией более высокого порядка!
Я по очереди пройдусь по синим квадратам и про каждый расскажу что-нибудь интересное.
__main__ ( compiler.py:827)
Он довольно короткий и скучный. Вот он полностью:
if __name__ == "__main__":
import fileinput
with fileinput.input(encoding="utf-8") as fi:
compile("".join(fi)) # todo: make this line-at-a-time?Очевидно, я так и не закончила это TODO! Единственная действительно интересная штука тут — это модуль fileinput, о котором вы, возможно, не слышали. Из документации модуля:
Типичное использование:
import fileinput
for line in fileinput.input(encoding="utf-8"):
process(line)При этом происходит перебор строк всех файлов, перечисленных в sys.argv[1:], если список пуст, по умолчанию используется sys.stdin. Если имя файла равно «-», оно также заменяется на sys.stdin, а необязательные аргументы mode и openhook игнорируются. Чтобы указать альтернативный список имён файлов, передайте его в качестве аргумента функции input(). Также допускается одно имя файла.
Технически это означает, что поддерживается несколько файлов! (Если вы не против, что они все объединены и имеют перепутанные номера строк :-) fileinput на самом деле довольно сложен и работает по методу filelineno(), я просто не использовала его из соображений экономии места.)
compile() (compiler.py:805)
compile() — это первая интересная функция из описанных тут, и она достаточно короткая, чтобы я могла вставить её целиком:
def compile(src: str) -> None:
# compile an entire file
with emit.block("(module", ")"):
emit("(memory 3)")
emit(f"(global $__stack_pointer (mut i32) (i32.const {PAGE_SIZE * 3}))")
emit("(func $__dup_i32 (param i32) (result i32 i32)")
emit(" (local.get 0) (local.get 0))")
emit("(func $__swap_i32 (param i32) (param i32) (result i32 i32)")
emit(" (local.get 1) (local.get 0))")
global_frame = StackFrame()
lexer = Lexer(src, set(["int", "char", "short", "long", "float", "double"]))
while lexer.peek().kind != TOK_EOF:
global_declaration(global_frame, lexer)
emit('(export "main" (func $main))')
# emit str_pool data section
emit(f'(data $.rodata (i32.const {str_pool.base}) "{str_pool.pooled()}")')Эта функция обрабатывает создание прелюдии уровня модуля.
Сначала мы выдаём прагму, позволяющую виртуальной машине WASM зарезервировать 3 страницы памяти ( (memory 3)), и устанавливаем указатель стека так, чтобы он начинался в конце этой зарезервированной области (он будет расти вниз).
Затем мы определяем двух помощников, которые будут взаимодействовать со стеком __dup_i32 и __swap_i32. Если вы когда-нибудь использовали Forth, то уже знакомы с ними: dup дублирует элемент на вершине стека WASM ( a -- a a), а swap меняет положение двух верхних элементов стека WASM ( a b -- b a) .
Затем мы инициализируем фрейм стека для хранения глобальных переменных, инициализируем лексер со встроенными именами типов для Lexer Hack и обрабатываем глобальные объявления, пока они не закончатся!
Наконец, мы экспортируем main и сбрасываем пул строк.
global_declaration() (compiler.py:743)
Эта функция слишком длинная, чтобы показать её целиком, но сигнатура выглядит так:
def global_declaration(global_frame: StackFrame, lexer: Lexer) -> None:
# parse a global declaration -- typedef, global variable, or function.
...Она обрабатывает определения типов, глобальные переменные и функции.
Typedefs — это круто, поскольку именно здесь происходит Lexer hack!
if lexer.try_next("typedef"):
# да, `typedef int x[24];` корректно (но безумно) c
type, name = parse_type_and_name(lexer)
# lexer hack!
lexer.types.add(name.content)
typedefs[name.content] = type
lexer.next(";")
returnМы повторно используем общий инструмент парсинга имён типов, поскольку определения типов (typedefs) наследует странное правило C “declaration reflects usage” (объявление диктует использование), что удобно для нас. (особенно для озадаченного новичка!) Затем мы сообщаем лексеру, что обнаружили новое имя типа, так что в будущем этот токен будет лексироваться как имя типа, а не имя переменной.
Наконец, для определений типов мы сохраняем тип в глобальном реестре определений типов, используем завершающую точку с запятой и возвращаемся к следующему глобальному объявлению compile(). Важно отметить, что тип, который мы храним, является целым разобранным типом, поскольку вы прописали typedef int* int_p;, а затем int_p *x, x должен получить результирующий тип int**— уровень указателя является аддитивным! Это означает, что мы не можем просто хранить базовое имя типа C, вместо этого нужно хранить целый CType.
Если объявление не было typedef, мы парсим тип и имя переменной. Если мы находим токен ;, мы знаем, что это объявление глобальной переменной (поскольку мы не поддерживаем глобальные инициализаторы). В этом случае мы добавляем глобальную переменную во фрейм глобального стека и таким образом фиксируем ее.
if lexer.try_next(";"):
global_frame.add_var(name.content, decl_type, False)
returnОднако если точки с запятой нет, мы определённо имеем дело с функцией. Чтобы сгенерировать код функции, нам необходимо:
Создать новую функцию StackFrame с именем frame
Проанализировать все параметры и сохранить их во фрейме с помощью frame.add_var(varname.content, type, is_parameter=True)
Проанализировать все объявления переменных с помощью variable_declaration (lexer, frame), который добавит их во frame
Теперь мы знаем, насколько большим должен быть фрейм стека функции ( frame.frame_size), поэтому можем начать генерировать прелюдию!
Во-первых, для всех параметров во фрейме стека (добавленных с помощью is_parameter=True) мы генерируем param объявления WASM, чтобы функцию можно было вызывать с соглашением о вызовах WASM (передавая параметры в стек WASM):
for v in frame.variables.values():
if v.is_parameter:
emit(f"(param ${v.name} {v.type.wasmtype})")Затем мы можем создать аннотацию result для возвращаемого типа и настроить указатель стека C, чтобы освободить место для параметров и переменных функции:
for v in reversed(frame.variables.values()):
if v.is_parameter:
emit("global.get $__stack_pointer")
emit(f"i32.const {frame.get_var_and_offset(v.name)[1]}")
emit("i32.add")
# fetch the variable from the WASM stack
emit(f"local.get ${v.name}")
# and store it at the calculated address in the C stack
emit(v.type.store_ins())Для каждого параметра (в обратном порядке, потому что они в стеке) скопируйте его из стека WASM в наш стек:
while not lexer.try_next("}"):
statement(lexer, frame)Наконец, мы можем вызвать цикл statement(lexer, frame) для кодирования всех операторов функции, пока не нажмём закрывающую скобку:
while not lexer.try_next("}"):
statement(lexer, frame)Бонусный шаг: мы предполагаем, что функция всегда будет иметь return, поэтому анализатор WASM emit("unreachable") не сходит с ума.
Ух! Этот пункт получился огромным. Но зато мы закончили с функциями и с global_declaration(), поэтому давайте перейдём к statement().
statement() (compiler.py:565)
В statement() много кода. Однако большая часть повторяется, поэтому я просто объясню про while и for.
Помните, что в WASM нет переходов, а есть структурированный поток управления? Сейчас это пригодится.
Для начала давайте посмотрим, как это работает с while, где особых проблем не возникло. Цикл while в WASM выглядит следующим образом:
block
loop
;; <test>
i32.eqz
br_if 1
;; <loop body>
br 0
end
endКак видите, есть два типа блоков — block и loop (есть ещё if тип блока, который я не использовала). Каждый включает в себя некоторое количество операторов и заканчивается на end. Внутри блока вы можете делать разбивки с помощью br, или через условие на основе вершины стека WASM с помощью br_if (также есть br_table, который я не использовала).
Семейство br принимает параметр labelidx, в нашем случае либо 1, либо 0, указывающий, к какому уровню блока применяется операция. Таким образом, в нашем цикле while, br_if 1 применяется к внешнему блоку — index 1, в то время как br 0 применяется к внутреннему блоку — index 0. (Индексы всегда относятся к рассматриваемой инструкции — 0 — это самый внутренний блок этой инструкции .)
Наконец, последнее правило, которое нужно знать: br в блоке переходит вперёд к концу блока, тогда как br в цикле уходит назад к началу цикла.
Так что, надеюсь, код цикла while теперь имеет смысл! Посмотрим на него снова,
block
loop
;; <test>
i32.eqz
;; if test == 0, jump forwards (1 = labelidx of the `block`),
;; out of the loop
br_if 1
;; <loop body>
;; unconditionally jump backwards (0 = labelidx of the `loop`).
;; to the beginning of the loop
br 0
end
endВ более обычной сборке это будет:
.loop_start
;; <test>
jz .block_end
;; <loop body>
jmp .loop_start
.block_endНо с помощью переходов вы можете выразить то, что вы не сможете (по крайней мере без геморроя) сделать в WASM — например, вы можете перескочить сразу в середину блока.
(В основном это проблема компиляции C goto, которую я даже не пробовала — существует алгоритм, который может преобразовать любой используемый код goto в эквивалентную программу, используя структурированный поток управления, но он сложен, и я не думаю, что он будет работать с нашим однопроходным методом.)
Но для циклов while это не так уж и плохо. Все, что нам нужно сделать, это:
# `emit.block` is a context manager to emit the first parameter ("block" here),
# and then the second ("end") on exit
with emit.block("block", "end"):
with emit.block("loop", "end"):
# emit code for the test, ending with `i32.eqz`
parenthesized_test()
# emit code to exit the loop if the `i32.eqz` was true
emit("br_if 1")
# emit code for the body
bracketed_block_or_single_statement(lexer, frame)
# emit code to jump back to the beginning
emit("br 0")Однако с циклами for это уже не очень хорошо работает. Рассмотрим такой цикл for:
for (i = 0; i < 5; i = i + 1) {
j = j * 2 + i;
}Порядок, в котором части цикла for будут видны лексеру/генератору кода:
i = 0
i < 5
i = i + 1
j = j * 2 + i
Но порядок их размещения в коде для работы со структурированным потоком управления WASM следующий:
block
;; < code for `i = 0` (1) >
loop
;; < code for `i < 5` (2) >
br_if 1
;; < code for `j = j * 2 + i` (4!) >
;; < code for `i = i + 1` (3!) >
br 0
end
endОбратите внимание, что 3 и 4 в сгенерированном коде инвертированы, образуя порядок 1, 2, 4, 3. Это проблема однопроходного компилятора! В отличие от обычного компилятора, мы не можем сохранить оператор продвижения на будущее. Или… так можем или нет?
В итоге я справилась с этим, сделав лексер клонируемым и повторно сделав парсинг оператора after после парсинга тела кода. По сути, код выглядит так:
elif lexer.try_next("for"):
lexer.next("(")
with emit.block("block", "end"):
# parse initializer (i = 0)
# (outside of loop since it only happens once)
if lexer.peek().kind != ";":
expression(lexer, frame)
emit("drop") # discard result of initializer
lexer.next(";")
with emit.block("loop", "end"):
# parse test (i < 5), if present
if lexer.peek().kind != ";":
load_result(expression(lexer, frame))
emit("i32.eqz ;; for test")
emit("br_if 1 ;; exit loop")
lexer.next(";")
# handle first pass of advancement statement, if present
saved_lexer = None
if lexer.peek().kind != ")":
saved_lexer = lexer.clone()
# emit.no_emit() disables code output inside of it,
# so we can skip over the advancement statement for now
# to get to the for loop body
with emit.no_emit():
expression(lexer, frame)
lexer.next(")")
# parse body
bracketed_block_or_single_statement(lexer, frame)
# now that we parsed the body, go back and re-parse
# the advancement statement using the saved lexer
if saved_lexer != None:
expression(saved_lexer, frame)
# jump back to beginning of loop
emit("br 0")Как видите, хитрость заключается в том, чтобы сохранить лексер, а затем использовать его для возврата и обработки оператора продвижения after, вместо сохранения синтаксического дерева, как это делает обычный компилятор. Не очень элегантно вышло — именно компиляция циклов for — и это, пожалуй, самый корявый код в компиляторе, — но работает достаточно хорошо!
Остальные части компилятора statement() во многом схожи, поэтому я пропущу их, чтобы перейти к последней основной части компилятора — expression().
expression() (compiler.py:375)
expression() — это последний большой метод в компиляторе, который, как и следовало ожидать, обрабатывает выражения синтаксического анализа. Он содержит множество внутренних методов, по одному для каждого уровня приоритета, каждый из которых возвращает структуру ExprMeta, описанную ранее (которая обрабатывает различие «место и значение» и может быть преобразована в значение с помощью load_result).
Нижняя часть стека приоритетов имеет value() (несколько запутанное название, поскольку оно может возвращать ExprMeta(is_place=True, ...)). Он обрабатывает константы, выражения в скобках, вызовы функций и имена переменных.
Помимо этого, базовым шаблоном уровня приоритета является такая функция:
def muldiv() -> ExprMeta:
# lhs is the higher precedence operation (prefix operators, in this case)
lhs_meta = prefix()
# check if we can parse an operation
if lexer.peek().kind in ("*", "/", "%"):
# if so, load in the left hand side
lhs_meta = load_result(lhs_meta)
# grab the specific operator
op_token = lexer.next()
# the right hand side should use this function, for e.g. `x * y * z`
load_result(muldiv())
# emit an opcode to do the operation
if op_token == "*":
emit(f"i32.mul")
elif op_token == "/":
emit(f"i32.div_s")
else: # %
emit(f"i32.rem_s")
# mask down the result if this is a less-than-32bit type
mask_to_sizeof(lhs_meta.type)
# we produced a value (is_place=False)
return ExprMeta(False, lhs_meta.type)
# if we didn't find a token, just return the left hand side unchanged
return lhs_metaЭтот шаблон настолько последователен, что большинство операций, включая muldiv, не записываются, а определяются функцией более высокого порядка makeop:
# function for generating simple operator precedence levels from declarative
# dictionaries of { token: instruction_to_emit }
def makeop(
higher: Callable[[], ExprMeta], ops: dict[str, str], rtype: CType | None = None
) -> Callable[[], ExprMeta]:
def op() -> ExprMeta:
lhs_meta = higher()
if lexer.peek().kind in ops.keys():
lhs_meta = load_result(lhs_meta)
op_token = lexer.next()
load_result(op())
# TODO: type checking?
emit(f"{ops[op_token.kind]}")
mask_to_sizeof(rtype or lhs_meta.type)
return ExprMeta(False, lhs_meta.type)
return lhs_meta
return op
muldiv = makeop(prefix, {"*": "i32.mul", "/": "i32.div_s", "%": "i32.rem_s"})
...
shlr = makeop(plusminus, {"<<": "i32.shl", ">>": "i32.shr_s"})
cmplg = makeop(
shlr,
{"<": "i32.lt_s", ">": "i32.gt_s", "<=": "i32.le_s", ">=": "i32.ge_s"},
CType("int"),
)
cmpe = makeop(cmplg, {"==": "i32.eq", "!=": "i32.ne"}, CType("int"))
bitand = makeop(cmpe, {"&": "i32.and"})
bitor = makeop(bitand, {"|": "i32.or"})
xor = makeop(bitor, {"^": "i32.xor"})
...Необходимо явно определить только несколько операций со специальным поведением, например, plusminus, которые должны обрабатывать нюансы математики указателей C.
Вот и все! Это была последняя основная часть компилятора.
Подводим итоги…
Это был наш тур по компилятору C в 500 строках Python ! Компиляторы имеют репутацию чего-то сложного и громоздкого — GCC и Clang огромны, и даже TCC, компилятор Tiny C, состоит из десятков тысяч строк кода. Но если вы готовы пожертвовать качеством кода и сделать всё за один проход, компиляторы могут быть удивительно компактными!
Что ещё интересного есть в блоге Cloud4Y
→ Спортивные часы Garmin: изучаем GarminOS и её ВМ MonkeyC
→ Взлом Hyundai Tucson, часть 1, часть 2