
Недавно на одном из YouTube-каналов я подробно рассматривал работу Kubernetes Scheduler. В процессе подготовки материала я столкнулся с множеством новых и интересных фактов, которыми хотел бы поделиться с вами. В этой статье мы разберём, что именно происходит “под капотом” Kubernetes Scheduler и какие аспекты важны для понимания его функционирования.
Планирую идти от простого к сложному, так что прошу отнестись с пониманием. Если вы уже знакомы с базовыми концепциями, не стесняйтесь пропустить вступительную часть и перейти сразу к ключевым деталям.
Если у рядового разработчика спросить, как бы ты имплементировал работу k8s scheduler?
Ответ скорее всего будет в таком стиле:
while True:
pods = get_all_pods()
for pod in pods:
if pod.node == nil:
assignNode(pod)Но этой статьи бы не было, если бы все было так просто.
Что такое Kubernetes Scheduler и какие задачи он решает?

Планировщик (Scheduler) в Kubernetes отвечает за распределение подов (Pods) по рабочим узлам (Nodes) в кластере. Основная задача планировщика — оптимизировать размещение подов, учитывая доступные ресурсы на узлах, требования каждого пода и различные другие факторы.
Если попросить меня описать функции Kubernetes Scheduler в двух словах, я бы выделил две ключевые задачи:
Выбор подходящей ноды для размещения пода. В этом процессе планировщик проводит анализ, чтобы удостовериться, что под может быть эффективно запущен на выбранной ноде.
Закрепление пода на выбранной ноде.
Где находится Kubernetes Scheduler в архитектуре Kubernetes?
Если попробовать изобразить последовательность действий, которые происходят при создании пода, то получится следующая схема:

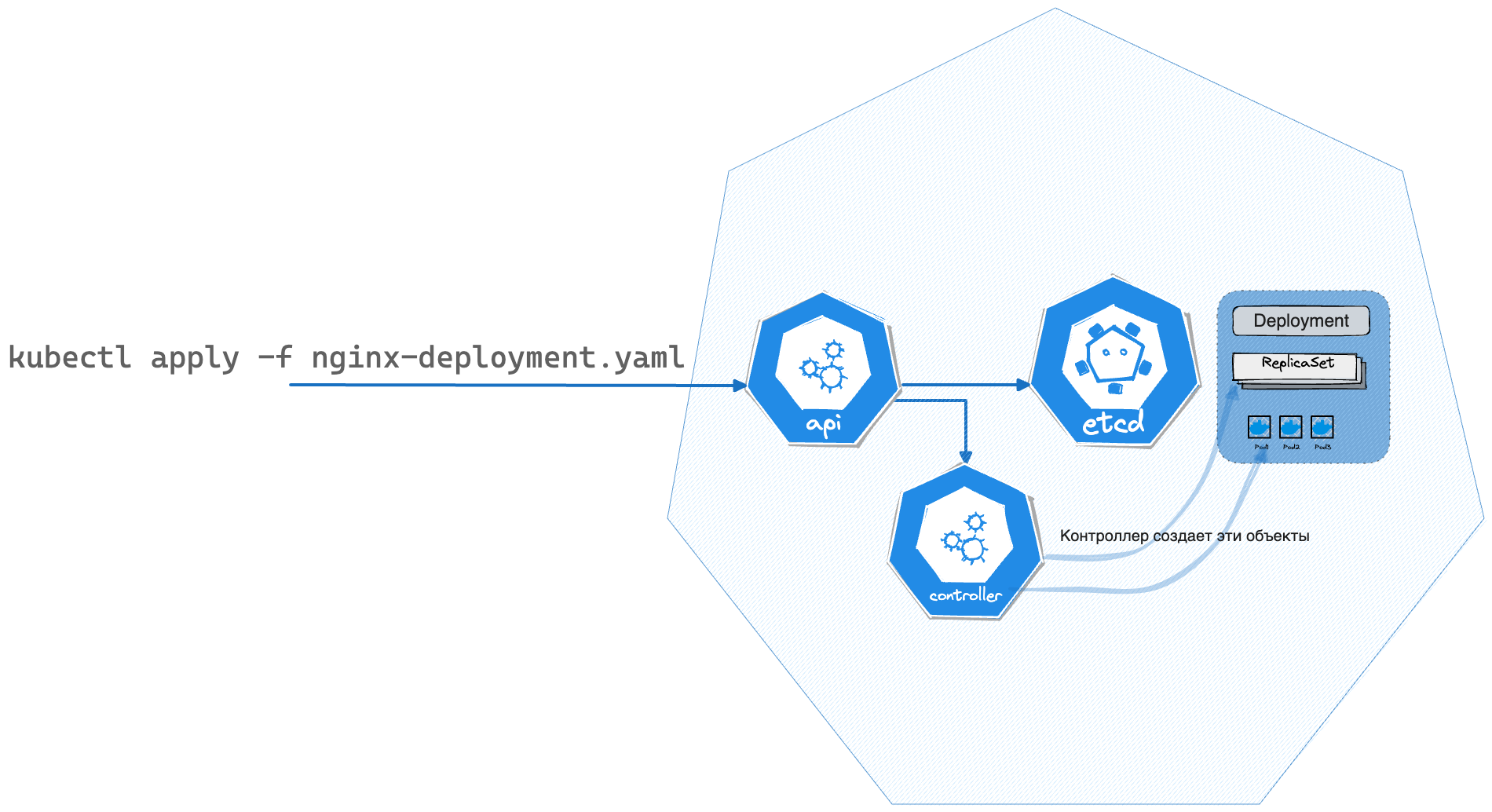
На изображении ниже показана последовательность действий, которые происходят при создании пода.

Под (Pod) создается контролером (Controller), который отвечает за состояние Deployment и replicaSet или непосредственно через API вручную (например через kubectl apply).
Планировщик забирает в работу новый под
Kubelet (не входит в состав планировщика) на рабочем узле (Node) создает и запускает контейнеры (Containers) пода (Pod)
Kubelet очищает ненужные данные о поде (Pod) после его удаления
Как работает Kubernetes Scheduler в базовом понимании?
Сбор информации: Планировщик постоянно мониторит состояние кластера, собирая данные о доступных узлах (Nodes), их ресурсах (CPU, память и так далее), текущем размещении подов (Pods) и их требованиях.
Определение кандидатов: Как только появляется новый под, требующий размещения, планировщик инициирует процесс выбора подходящего рабочего узла. Первым делом создается список всех доступных узлов, соответствующих базовым требованиям пода, таким как архитектура процессора, объем доступной памяти и так далее.
Фильтрация: Из созданного списка удаляются узлы, которые не соответствуют дополнительным требованиям и ограничениям, указанным в спецификации пода. Это могут быть, например, правила affinity/anti-affinity, taints и tolerations.
Ранжирование: После этапа фильтрации планировщик ранжирует оставшиеся узлы с целью выбрать наиболее подходящий для размещения пода.
Привязка пода к узлу: На этом этапе под назначается выбранному рабочему узлу, и соответствующая запись добавляется в etcd. После этого kubelet обнаруживает новое задание и инициирует процесс создания и запуска контейнеров.
Обновление статуса: После успешного размещения пода информация о его местоположении обновляется в etcd (который является единым источником данных), чтобы другие компоненты системы могли получить доступ к этой информации.
Все эти шаги называются “Extension points”(они же плагины), которые позволяют расширять функциональность планировщика. Они реализованы благодаря Scheduler Framework, о котором мы поговорим во 2‑й части статьи.
Например, вы можете добавить новые фильтры или алгоритмы ранжирования, чтобы удовлетворить специфические требования вашего приложения. На самом деле плагинов гораздо больше, мы вернемся к этому в следующей части.
Процесс повторяется: Планировщик продолжает мониторить кластер для следующего пода, который нуждается в размещении.
В упрощенном виде процесс планирования предоставлен на рисунке ниже.
В деталях мы рассмотрим этот процесс во 2-й части, а пока давайте посмотрим на то, как работает планировщик в базовом понимании.

Изображение на схеме умышленно упрощено, дабы не загромождать. В деталях мы рассмотрим этот процесс во 2-й части.
В документации k8s этот процесс имеет ту же структуру, но отображен в более общей форме. Вместо informer отображен event handler. Informer используют обработчики событий(event handler) для запуска конкретных действий при обнаружении изменения в кластере. Например, если создан новый под, который нужно запланировать, обработчик событий информера активирует алгоритм планирования для этого конкретного пода.
Informer: Планировщик Kubernetes активно использует механизм, называемый “Informer”, для мониторинга состояния кластера. Informer — это комплекс контроллеров, которые непрерывно отслеживают определённые ресурсы в etcd. При обнаружении изменений, информация обновляется во внутреннем кэше планировщика. Этот кэш позволяет оптимизировать расход ресурсов и предоставлять актуальные данные о нодах, подах и других элементах кластера.
Schedule Pipeline: Процесс планирования в Kubernetes начинается с добавления новых подов в очередь. Эта операция осуществляется с использованием компонента Informer. Поды затем извлекаются из этой очереди и проходят через так называемый “Schedule Pipeline” — цепочку шагов и проверок, после которых происходит финальное размещение пода на подходящей ноде.
Schedule Pipeline разделен на 3 потока.
-
Основной поток(Main thread): Как видно на картинке, основной поток выполняет шаги фильтрации, ранжирования и предварительного резервирования.
Filter - тут пока понятно, происходит всевозможное отсеивание неподходящих нод.
Score - в этом плагине происходит ранжирование нод, т.е. выбор наиболее подходящей ноды для пода из всех оставшихся.
Reserve - тут происходит предварительное резервирование ресурсов на ноде для пода. Это необходимо для того, чтобы другие поды не могли занять эти ресурсы(предотвращение ситуации race condition). Этот плагин реализует так же метод UnReserve.
UnReserve - это метод, часть плагина Reserve. Этот метод используется для освобождения ресурсов на ноде, которые были зарезервированы для пода ранее. Этот метод вызывается в случае, если под не был привязан к ноде в течение определенного времени(тайм-аут) или плагин Permit назначил статус deny для текущего пода. Это необходимо для того, чтобы другие поды могли занять эти ресурсы.
-
Permit thread: Эта фаза используется для предотвращения зависания пода в подвешенном(неизвестном) состоянии. Этот плагин может сделать одну из 3-х вещей:
approve - Все предыдущие плагины подтвердили, что под может быть запущен на ноде. Значит финальное решение для пода - approve.
deny - Один из предыдущих плагинов вернул не положительный результат. Значит финальное решение для пода - deny.
wait - Если плагин permit возвращает “wait”, то под остается в фазе permit, пока под не получит approve или deny статус. Если происходит тайм-аут, “wait” становится “deny”, и под возвращается в очередь планирования, активируя метод Un-reserve в фазе Reserve.
-
Bind thread: Эта часть отвечает за добавление записи о том, что под был привязан к ноде.
Pre-bind - тут выполняются шаги, которые необходимо выполнить перед привязкой пода к ноде. Например, создание сетевого хранилища и привязки его к ноде.
Bind - тут происходит привязка пода к ноде.
Post-Bind - это самый последний шаг, который выполняется после привязки пода к ноде. Этот шаг можно использовать как для очистки, так и для выполнения дополнительных действий.
Schedule Pipeline так же использует Cache для хранения данных о подах.
Важный аспект:
В Main и Permit потоках поды планируются исключительно последовательно, один за другим. Это означает, что планировщик не может планировать несколько подов одновременно в основном потоке(Main thread) и Permit thread.
Особняком стоит метод UnReserve плагина Reserve. Этот метод может быть вызван из основного потока (Main thread) или Permit thread, или Bind thread.
Это ограничение было введено для того, чтобы избежать ситуации, когда несколько подов пытаются занять одни и те же ресурсы на ноде.
Все остальные потоки могут выполняться асинхронно.
Перейдем к практике и пощупаем все самостоятельно
1. Создадим новый под
Чтобы дать работу планировщику, создадим новый под с помощью команды kubectl apply.
Создадим под с помощью deployment.
Важно отметить, что планировщик работает только с подами, а за состоянием Deployment и replicaSet следит контроллер.
kubectl apply -f https://k8s.io/examples/controllers/nginx-deployment.yamlnginx-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
2. Контроллер создает поды
На самом деле мы создадим Deployment, который в свою очередь создаст replicaSet, который в свою очередь создаст под.
Контроллер, который отвечает за состояние Deployment и replicaSet, видит соответствующие новые объекты и начинает свою работу.
Контроллер увидит deployment выше и будет создан примерно такой объект ReplicaSet
ReplicaSet
apiVersion: v1
items:
- apiVersion: apps/v1
kind: ReplicaSet
metadata:
annotations:
deployment.kubernetes.io/desired-replicas: "3"
deployment.kubernetes.io/max-replicas: "4"
deployment.kubernetes.io/revision: "1"
labels:
app: nginx
name: nginx-deployment-85996f8dbd
namespace: default
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: Deployment
name: nginx-deployment
uid: b8a1b12e-94fc-4472-a14d-7b3e2681e119
resourceVersion: "127556139"
uid: 8140214d-204d-47c4-9538-aff317507dd2
spec:
replicas: 3
selector:
matchLabels:
app: nginx
pod-template-hash: 85996f8dbd
template:
metadata:
labels:
app: nginx
pod-template-hash: 85996f8dbd
spec:
containers:
- image: nginx:1.14.2
imagePullPolicy: IfNotPresent
name: nginx
ports:
- containerPort: 80
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
status:
availableReplicas: 3
fullyLabeledReplicas: 3
observedGeneration: 1
readyReplicas: 3
replicas: 3
kind: List
В результате работы контроллера, который отвечает за replicaset будет создаено 3 пода. Они получают статус Pending, потому что планировщик еще не запланировал их на ноды, эти поды добавляются в очередь планировщика.
3. Планировщик вступает в дело
Таким образом это можно отобразить на нашей схеме.

Каждый под в очереди планировщика в порядке очереди извлекается и:
Проходит через Schedule Pipeline, выбирает максимально подходящую ноду
Закрепляется за выбранной нодой

Фаза планирования
Возможно немного повторюсь, но тут чуть более подробно про сам пайплайн.

Filter - отсеиваем неподходящие ноды.
-
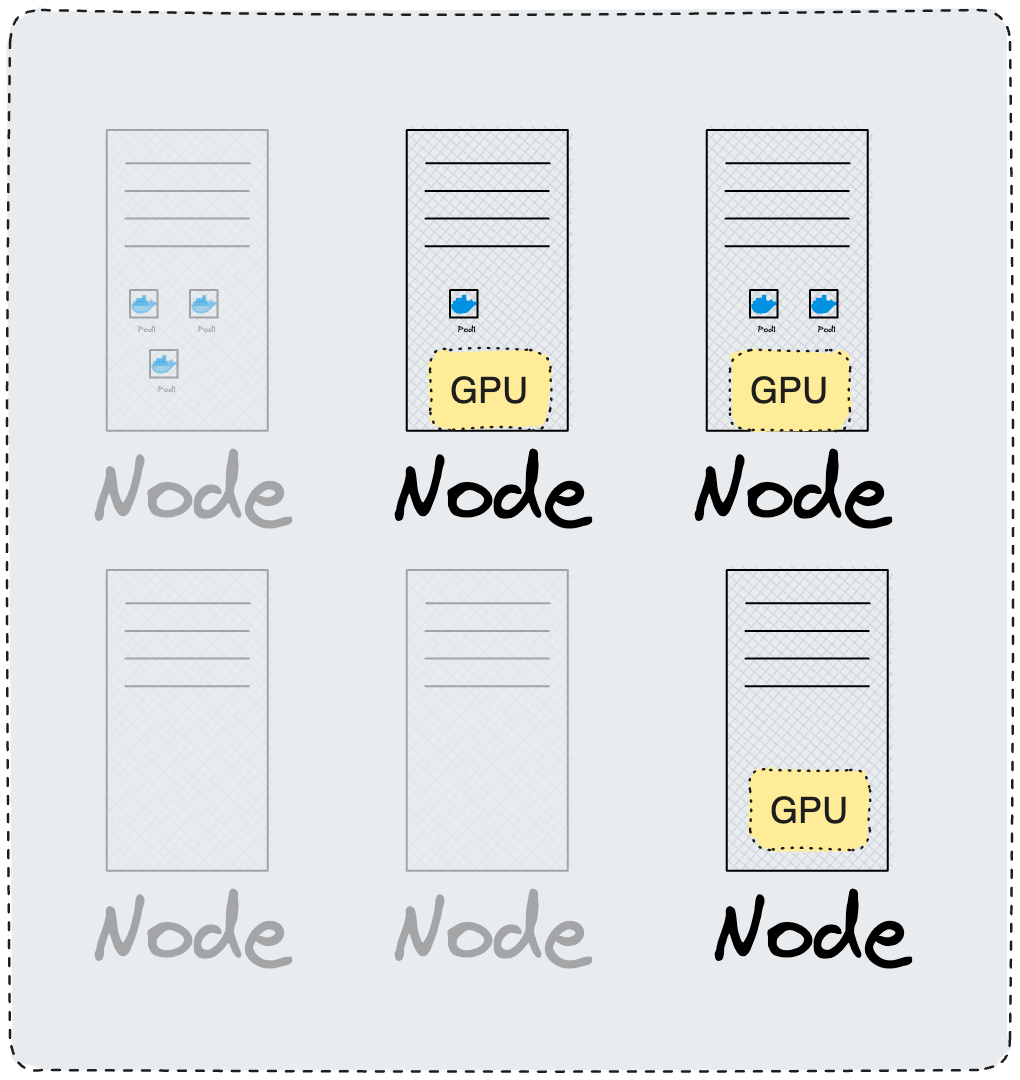
Например, если мы хотим разместить под на ноде, где есть GPU, то нам сразу не нужны ноды без GPU.
-
Далее мы убираем ноды, на которых нет достаточно ресурсов для запуска пода. Например, если под требует 2 CPU, а на ноде есть только 1 CPU, то такая нода не подходит.

etc… Итераций фильтраций может быть достаточно много, вернемся к этому в главе 2.
Score - сортируем оставшиеся ноды.
Если нод больше чем одна, нам же нужно как-то выбрать наиболее подходящую ноду, а не просто использовать random.
Тут вступают в дело различные плагины. Например, плагин ImageLocality позволяет выбрать ноду, на которой уже есть образ контейнера, который мы хотим запустить. Это позволяет сэкономить время на скачивание образа из container registry.

Reserve - резервируем ресурсы на ноде для пода.
Чтобы в следующем потоке не увели ресурсы нашей идеальной ноды, мы бронируем эту ноду.

Un-Reserve - если что-то пошло не так на любом из этапов, ты мы вызываем этот метод, чтобы освободить ресурсы на ноде и отправить под обратно в очередь планировщика.
Permit - проверяем, что под может быть запущен на ноде.
Если все предыдущие шаги прошли успешно, то мы проверяем, что под может быть запущен на ноде. Например, если у нас есть правило affinity, которое говорит, что под должен быть запущен на ноде с определенным label, то мы проверяем, что эта нода соответствует этому правилу. Если все хорошо, то мы возвращаем статус approve, если нет, то deny.
Фаза закрепления
В этой фазе выполняем доп шаги перед окончательным закреплением ноды, само закрепление пода за нодой и необхходимые шаги после закрепления. Больше деталей про эту фазу вы читайте в части 2.
Важно отметить, что этот поток работает асинхронно.

Kubelet - запуск контейнера на ноде

Как только мы закрепили ноду за подом, kubelet видит эти изменения и начинает процесс запуска контейнера на ноде. Еще раз отмечу, что kubelet это компонент не из системы планировщика.
Под запущен на наиболее подходящей ноде, и мы можем увидеть это в выводе команды kubectl get pods. А значит планировщик выполнил свою работу.
kubectl get pods -o wideВот так выглядит Schedule Pipeline в упрощенном виде, а в деталях мы рассмотрим его во 2-й части.
В следующей части мы копнем глубже и узнаем больше о внутренней кухне планировщика.
В частности, мы:
Разберем Scheduler framework
Узнаем как расширить функциональность планировщика
Отодвинем занавес работы очереди планировщика
Посмотрим на примеры плагинов
Тут будет ссылка на 2-ю часть.
Кстати, про Kubernetes Scheduler и не только вы можете узнать в рамках онлайн-уроков от OTUS. По ссылке вы можете ознакомиться с каталогом курсов, а также зарегистрироваться на бесплатные вебинары по интересующим вас темам. Ближайшие бесплатные вебинары: