
Fibers (волокна) менее узнаваемая концепция по сравнению с coroutines (сопрограммами), является довольно мощным дополнением к кооперативной многозадачности. Как графический программист в игровой индустрии, я ценю большую гибкость, которую дают волокна. Я считаю, что эта технология немного недооценена из-за отсутствия достаточного количества общедоступных материалов.
В этой публикации я изложу некоторые из моих знаний об основах волокон. Все, что упомянуто, будет конкретно касаться C++, хотя аналогичная концепция существует и в других языках. Читатели, не имеющие начальных знаний о волокнах, узнают, что это такое и как мы можем использовать их преимущества при рендеринге графики.
Многозадачность
Как мы все знаем, современным играм обычно требуется значительная вычислительная мощность, чтобы они своевременно реагировали на действия игроков. Повышение производительности, достигнутое в одноядерных процессорах, уже давно не могло удовлетворить огромные вычислительные потребности. Ни для кого неудивительно, что более десяти лет назад индустрия перешла от однопоточного игрового движка к многопоточному. Многопоточность стала неотъемлемой частью разработки игр. Это также очень зрелая технология, которая хорошо поддерживается и оптимизирована основными операционными системами.
При многопоточности необходимо разделить вычисление кадра на несколько подзадач в зависимости от их характеристик, чтобы каждому потоку было чем заняться. Некоторые задачи обрабатывают физику, некоторые — рендеринг, список можно продолжать. Неизбежно введение некоторых зависимостей между задачами. Соблюдение зависимостей требует тщательной синхронизации. Чтобы правильно управлять задачами, в игровые движки вводятся системы задач (иногда называемые системами заданий). Они используются для эффективного управления многоядерной мощностью, обеспечиваемой процессорами.
Ограничение вытесняющей многозадачности
Нередко можно увидеть, что количество активных потоков превышает количество физических ядер. Чтобы дать пользователям иллюзию многозадачности, операционные системы обычно выполняют несколько задач в чередующемся порядке. Каждый поток получает часть всей временной шкалы физических ядер. Пока частота смены потоков достаточно высока, пользователи будут чувствовать, что они работают одновременно. Эта модель широко известна как вытесняющая многозадачность [1] .
Несмотря на то, что эта модель работает достаточно хорошо для большинства приложений, разработка игр — одна из редких областей, где разработчики пытаются выжать из целевой платформы каждую мелочь. При вытесняющей многозадачности наблюдается некоторая потеря гибкости, что иногда может раздражать. В частности, разработчиков игр беспокоят следующие факты о вытесняющей многозадачности.
Переключение контекста происходит с частотой, которая не контролируется напрямую разработчиками. Именно так ОС в первую очередь поддерживает многозадачность. Однако это не дешево, так как требует обращения к ядру. А всякий раз, когда в этом нет необходимости, это можно рассматривать как пустую трату ресурсов. Чтобы лучше понять, откуда берутся эти потери, представьте, что у нас есть 10 задач, выполняемых в первые 2 мс кадра на машине всего с 4 физическими ядрами, действительно ли нам нужно создать иллюзию, что все 10 задач выполняются? В то же время? На самом деле это не так, всё, что нас волнует, это то, чтобы в пределах временного интервала все задачи в этом кадре были выполнены в правильном порядке. Однако ОС об этом не знает, необходимость сохранения такого поведения является основной причиной потерь.
Планировщик потоков сильно зависит от операционной системы. Всякий раз, когда активный поток собирается быть приостановлен, именно ОС решает, какой следующий поток получит возможность взять на себя управление физическим ядром в следующем временном окне. Несмотря на то, что большинство интерфейсов ОС предлагают некоторый уровень управления, например приоритет потока, алгоритм планирования прозрачен для программистов. И это может быть проблематично время от времени. Опять же, планировщик не имеет никаких предварительных знаний об игровом движке. Ему придется относиться к этой системе как к обычной системе. Поэтому следующий поток, который будет запущен, иногда может не соответствовать ожиданиям разработчиков.
В некоторой степени мы можем думать о вытесняющей многопоточности как о виртуальных потоках, борющихся за физические ресурсы. В этой игре ни один поток не имеет полного контроля, поскольку планировщик может в любой момент заранее приостановить поток. И очевидно, что за это приходится платить определенную цену и неопределенность.
Если они находятся в пределах допуска, то то, что еще больше подтолкнуло некоторые игровые студии к переходу к более эффективному проектированию системы, — это проблематичный случай, когда задаче приходится ждать некоторых входных данных, которые еще не созданы другой задачей.
-
Непрактичным решением было бы планировать больше потоков, чем количество физических ядер, и передавать управление потоку, если он чего-то ожидает, чтобы ОС могла запланировать для него другой поток. Это может звучать нормально. К сожалению, у него есть недостатки.
Прежде всего, ОС понятия не имеет, когда входы будут готовы, она будет пытаться вернуть этот поток обратно на физическое ядро, чтобы время от времени предпринимать попытки возобновить его. Очевидно, что это очень неэффективно, поскольку до тех пор, пока ввод не будет готов, все предыдущие попытки являются бесполезными усилиями, которые только приводят к потере аппаратных ресурсов.
-
Если это звучит недостаточно страшно, то еще хуже ситуация, когда система может оказаться в состоянии тупиковой блокировки, если все потоки в пуле потоков ждут чего-то, что не готово, что в конечном итоге приведет к зависанию игры, поскольку ожидающие задачи не могу найти поток для его запуска, и все потоки уступают место из-за отсутствия входных данных. Чтобы решить проблему
Один из вариантов — создать в таком случае новый поток, чтобы гарантировать, что ожидающие задачи всегда смогут найти поток для выполнения. Если оставить в стороне тот факт, что создание потока не является бесплатным, это не только увеличит сложность системы, но и приведет к появлению большего количества потоков, а это означает, что в будущем потенциально произойдет большее вытеснение.
Другой подход — это система размещения заданий, которая вместо того, чтобы приостанавливать текущее задание в ожидании готовности чего-либо, захватывает другое задание и выполняет новое задание поверх существующего стека вызовов. Большая проблема этого решения заключается в том, что стек вызовов задач, возможно, будет накладываться друг на друга, и нет никакой возможности, чтобы задание в нижней части стека завершилось раньше, чем то, что находится наверху, завершилось первым.
Есть и другие способы решения проблемы. Однако идеальное решение — это выполнить задачу, когда это необходимо, без значительных затрат. К сожалению, с помощью вытесняющей многозадачности добиться этого нелегко.
Альтернативным решением было бы разделить задачу на две на границе ожидания. Хотя это звучит как более практичное решение, такое решение больше похоже на последнее средство, которое вряд ли можно масштабировать, поскольку определенные случаи возникают чаще, что заставит нас создавать больше задач.
Если в чем и виновата, так это в том, что вытесняющая многозадачность не позволяет задачам уступить во время выполнения.
Кооперативная многозадачность
Кооперативная многозадачность отличается тем, что позволяет программисту взять на себя планирование, а не работу с ОС. Как следует из названия, он позволяет различным задачам совместно работать друг с другом. Это будет означать, что они передают управление только тогда, когда уступают, и другие задачи предпочтут довериться этой выполняемой задаче, чтобы она передавала им управление в разумный момент. Когда это доверие установлено, нет необходимости с упреждением прерывать выполняемую задачу без ее разрешения, как это делает ОС при вытесняющей многозадачности. Совместная многозадачность больше похожа не на борьбу задач за аппаратные ресурсы, а на то, что задачи счастливо работают вместе, как одна семья.
При таком дизайне каждая задача будет нести больше ответственности, так как, если они не передают контроль другим, другие вообще не будут иметь никакого контроля. Необходимость передать управление другим задачам требует, чтобы подпрограмма уступала, когда они этого хотят. Такую подпрограмму обычно рассматривают как более обобщенную версию обычной подпрограммы, ее называют сопрограммой. Это наиболее широко известное решение, которое позволяет нам запрограммировать поток так, чтобы он работал совместно.
Конечно, даже если программа полностью выполняется посредством кооперативной многозадачности, это не означает, что никакого вытеснения не произойдет, поскольку ОС потребуется время от времени планировать запуск других фоновых приложений, таких как электронная почта, на общих физических ядрах. Но минимизация переключения контекста в нашем собственном приложении уже имеет большую ценность.
Прежде чем двигаться дальше, для тех, кто не знаком с терминами подпрограмма и сопрограмма. Краткое объяснение приведено ниже.
Подпрограмма (subroutine) — это вещь, которая может быть вызвана вызывающей стороной и может вернуть управление обратно вызывающей стороне, вызвавшей ее. Я думаю, что все программисты быстро поймут, что концепция функции — это реализация подпрограммы.
Сопрограмма (coroutine) обладает всеми свойствами подпрограммы. Кроме того, она может приостановить себя и вернуть управление вызывающей функции. И она также может возобновиться позже и продолжить всё с точки приостановки, даже в совершенно другом потоке.
Чтобы пост был кратким, предполагается, что читатели обладают некоторыми базовыми знаниями о сопрограммах. Для читателей, которые не очень знакомы с сопрограммами в C++, вот замечательный доклад о Cpp con.
Основные сведения о волокнах
Помимо сопрограммы, интересным дополнением для решения совместной многозадачности является волокна. Волокно (fiber) – довольно легкий поток исполнения. Как и сопрограмма, волокно позволяет выполнять операции в любой точке внутри него. В некоторой степени мы можем рассматривать волокно как форму стековой сопрограммы, которая недоступна в языке программирования C++. Под «недоступно» я имею в виду отсутствие поддержки родного языка. Конечно, есть библиотеки, такие как boost, которые поддерживают такого рода сопрограммы или даже волокна.
Не пугайтесь его причудливого названия: на самом деле волокно — это всего лишь метод, который позволяет программистам переключаться между различными стеками памяти без регулярной команды возврата. Поскольку он дает нам возможность переключаться между различными стеками вызовов, мы можем выделить собственную память стека и использовать ее в качестве стека волокна.
Ниже приведена диаграмма, демонстрирующая, как волокна вписываются в программу.
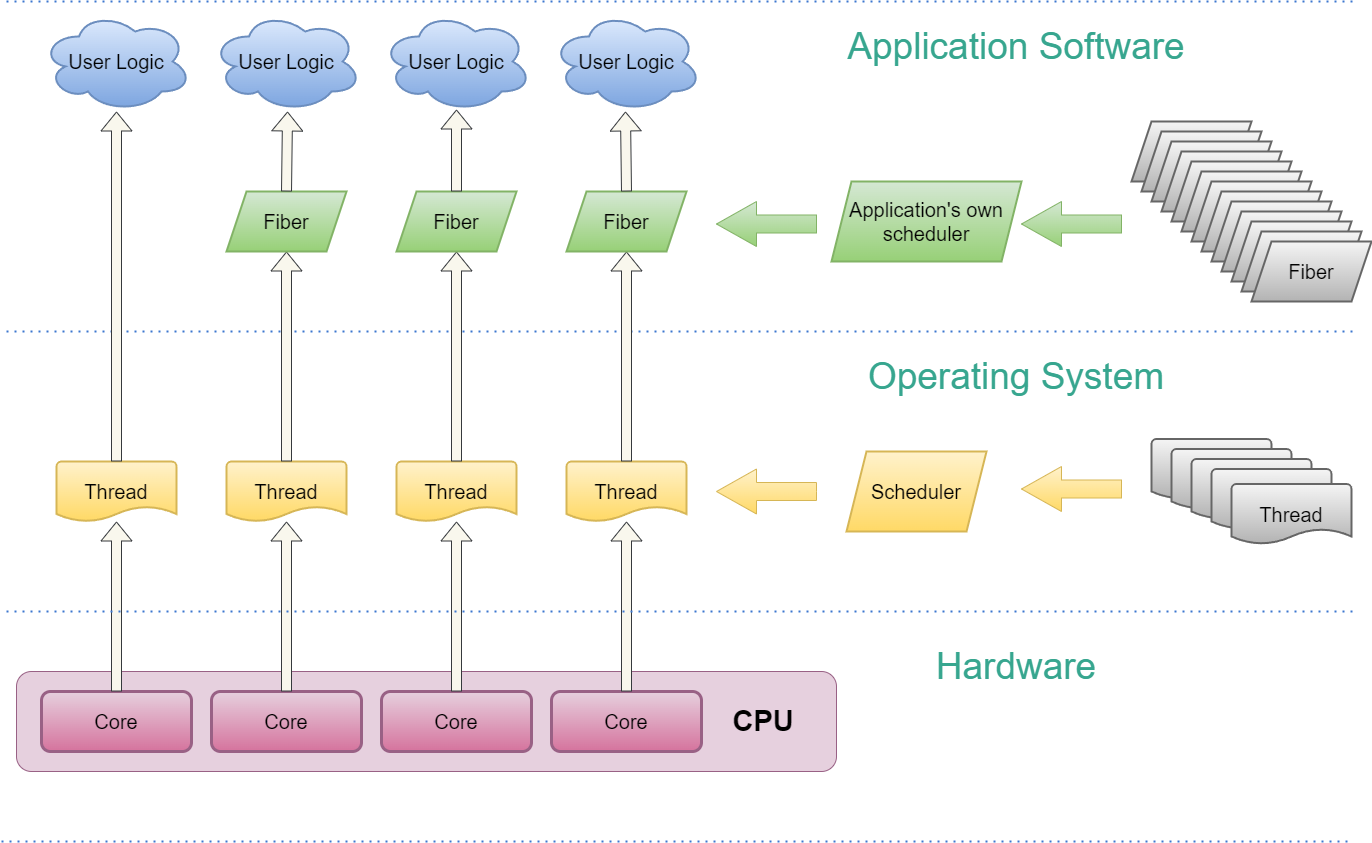
Мы можем увидеть несколько вещей на этой диаграмме.
Код пользовательской логики может выполняться либо в обычном потоке, либо в волокне, которое само выполняется в потоке.
В отличие от потоков, планировщик волокна зависит от приложения, а это означает, что разработчик программного обеспечения должен взять на себя ответственность за планирование волокон. ОС в этом уже не поможет.
Как показано на диаграмме, пользователь обычно может создавать гораздо больше волокон, чем потоков, поскольку такие вещи, как распределение памяти стека, разработчики гораздо лучше контролируют.
Хотя это и не показано на схеме, системы с волокнами обычно используют привязку потоков для фиксации потоков на выделенных ядрах для повышения производительности, при этом количество фоновых потоков не должно быть большим. Обычно для блокирующих операций, таких как ввод-вывод, требуется лишь несколько потоков с низким приоритетом.
Есть еще много интересного для изучения. Мы упомянем их в следующих главах более подробно.
Разница между волокном и потоком
По сравнению с волокном, поток — более известное понятие. Предполагая, что все читатели уже имеют четкое представление о потоках, ниже приведены некоторые очень очевидные различия между потоком и волокном.
Поток может быть запланирован операционной системой и выполняться на физическом ядре ЦП. В то время как волокно может работать только по потоку. Мы можем думать о волокне как о концепции более высокого уровня, поскольку оно находится поверх потока.
Хотя оба они могут поддерживать многозадачность. Потоки поддерживают многозадачность посредством планирования вытесняющего стиля ОС. Волокно поддерживает многозадачность, предлагая программисту взять на себя ответственность за их правильное планирование.
Переключение потоков намного сложнее, чем переключение волокон. Переключение потоков требует, чтобы программа перешла в режим ядра, и это может быть намного дороже. Переключение волокна — это не что иное, как замена регистров с ранее сохраненным контекстом волокна.
Память для стеков вызовов потока контролируется ОС, тогда как память для стека волокон может явно контролироваться программистами. Это обеспечивает большую гибкость, поскольку программисты обычно знают систему, которую они строят, и могут упростить задачу, используя эти предположения.
Локальное хранилище потоков безопасно для потоков, но оно не может быть на 100% безопасным для волокон, поскольку некоторые системы предпочитают планировать волокна в разных потоках между исполнениями одного и того же волокна.
Встроенные в операционную систему примитивы синхронизации, такие как мьютекс, не будут работать с волокнами, если волокна могут возобновиться в других потоках, а не в том, в котором они были приостановлены. Нам следует быть предельно осторожными при использовании примитивов синхронизации внутри волокна.
Разница между Fiber и сопрограммой C++
Гораздо проще сравнивать поток и волокно, чем сравнивать волокно и сопрограмму. Помните, что концепция сопрограммы, о которой мы здесь говорим, — это всего лишь сопрограмма, поддерживаемая языком C++. Мы не сравниваем волокно с какой-либо специальной реализацией сопрограммы.
Сопрограмма C++ — это концепция языка. На самом деле, C++ начал поддерживать языковую сопрограмму только с C++ 20. Хотя волокно — это концепция уровня ОС, обычно предоставляемая интерфейсом библиотеки ОС. Волокно может быть полностью реализовано самими программистами на языках ассемблера. Позже мы увидим, как этого можно достичь.
Функции сопрограммы обычно немного сложнее реализовать. Есть несколько концепций конфигураций, таких как дескриптор сопрограммы, обещание. Программисту придется либо реализовать свой собственный тип, либо использовать типы, предлагаемые сторонней библиотекой, для реализации функции сопрограммы. Хотя на самом деле не существует такого понятия, как функция волокна, обычная функция может использовать преимущества, чтобы выйти из нее без какой-либо специальной обработки.
-
Сопрограмма C++ автоматически добавит дополнительный код конфигурации для реализации сопрограммы. Такой скрытый код зависит не только от компилятора, но и может различаться на разных платформах. Программисты будут иметь мало контроля над тем, как генерируется этот код. С другой стороны, поскольку волокно не является концепцией уровня языка, компилятор не будет делать с ним ничего особенного. Здесь есть хорошее и плохое в разнице
Одним из преимуществ сопрограммы является то, что все переменные будут правильно уничтожены после завершения сопрограммы. Его можно завершить, выйдя из функции сопрограммы по команде
co_return. Другой способ завершить время жизни сопрограммы — завершить время жизни дескриптора сопрограммы, даже если сопрограмма еще не завершила выполнение. Конечно, будут уничтожены только те переменные, которые действительно затрагиваются в процессе выполнения. Переменные, даже не затронутые в сопрограммах, не будут уничтожены, поскольку они вообще никогда не создаются. К сожалению, волокно не может этого сделать. Не существует простого способа отследить все локальные переменные в волокнах и должным образом уничтожить их все, если волокно приостановится и выйдет из строя. Ответственность программиста заключается в том, чтобы убедиться, что все локальные переменные, которые необходимо уничтожить, будут уничтожены в нужное время, прежде чем отключать волокно. Интересный пример — умные указатели. Умные указатели в C++ реализуются путем объединения всего выделения кучи в стек. Поскольку при завершении программы все стеки исчезают, можно быть уверенным, что вся память в куче, привязанная к умным указателям, также будет освобождена. Однако такой механизм не сможет защитить утечку памяти при распределении кучи в контексте волокна. Мы упомянем об этом позже, когда поговорим о реализациях волокна, чтобы не запутать читателей.Поскольку сопрограмма C++ представляет собой концепцию уровня языка, компиляторы имеют возможность максимально оптимизировать ее. Одним из примеров является то, что компилятор может иногда выбирать встроенную функцию сопрограммы, даже заставляя их исчезать в воздухе [3] . Такая оптимизация явно невозможна при использовании волокон. Позже мы увидим, нам придется что-то сделать, чтобы компилятор не оптимизировал код, чтобы логика волокна могла вести себя так, как ожидается.
Управление памятью в сопрограмме немного более прозрачно, чем в волокне. Размер выделяемой памяти сильно зависит от компилятора. Для волокон программисты должны выделить часть памяти в виде стека. Программисты сами решают, сколько байтов им нужно для выполнения волокна. Конечно, программистам необходимо убедиться, что то, что выполняется по волокну, не приведет к переполнению стека, выделив достаточно памяти для стека волокон.
Сопрограмма может возвращать значение, тогда как волокно не позволяет программисту делать это традиционным способом возврата значения.
Мы можем завершить функцию сопрограммы, пропустив код до конца. Хотя мы не можем перейти к концу функции входа в волокно, так как для функции входа в волокно не существует правильного адреса возврата.
Сопрограмма C++ — это асимметричная сопрограмма, которая позволяет возвращать управление вызывающей стороне, только вызывающей стороне. Функция сопрограммы не может передать управление другой сопрограмме, которая была приостановлена ранее. Хотя существует концепция, называемая симметричной сопрограммой, которая позволяет одной сопрограмме передавать управление другой. По умолчанию волокно симметрично. На самом деле он никогда не возвращается к вызывающему коду, а только уступает другому волокну.
Сопрограмма C++ не имеет стека, а это означает, что ей разрешено работать только внутри самой функции сопрограммы. Если ваша функция-сопрограмма вызывает другую обычную функцию, ей запрещено возвращать управление вызывающей стороне, которая вызывает функцию-сопрограмму. Волокно позволяет передать управление на любой глубине стека вызовов.
Выше приведены некоторые основные различия между сопрограммой уровня языка C++ и волокна. Среди всех этих различий последние два практически являются препятствием для внедрения гибкой системы задач. Конечно, примеры использования сопрограмм для реализации системы задач наверняка есть [4] [5] , это технически возможно. Но гибкость, обеспечиваемая волокнами, намного мощнее, чем то, что предлагает сопрограмма. Система задач игрового движка Naughty Dog — успешный пример использования волокон для распараллеливания игрового движка [6] .
Реализация волокон
Понимание деталей реализации волокон может оказаться полезным. Несмотря на то, что волокна предлагают большую гибкость, их реализация представляет собой не что иное, как несколько сотен строк кода.
В этом разделе мы рассмотрим подробную реализацию волокон на архитектуре x64, аналогичная версия, работающая на архитектуре Arm64, также представлена в виде исходного кода .
В отличие от реализации функций высокого уровня, реализация волокон немного необычна и хаотична. Это требует от программистов четкого понимания того, как процессор обрабатывает стеки вызовов во время выполнения программы. Поэтому, прежде чем перейти к подробной реализации волокон, нам нужно будет взглянуть на некоторые основы того, как процессоры обрабатывают стек вызовов на x64 и Arm64 соответственно.
Детали реализации волокон на языках ассемблера на архитектуре Arm64 очень похожи на то, что нужно сделать на x64. Самая большая разница в том, что наборы регистров отличаются друг от друга. Поэтому мы не будем повторять подобный процесс. Читатели, интересующиеся его реализацией, могут ознакомиться с моей реализацией по ссылке выше.
Реализация волокон во многом зависит от ABI (двоичный интерфейс приложения). В этой публикации реализация волокон на x64 построена на основе System V ABI . Разный ABI требует разной реализации волокон.
Архитектура целевой платформы
Вместо того, чтобы перечислять все, что явно невозможно, я лишь вкратце упомяну то, что связано с волокнами. И мы будем тратить время только на 64-битную программу. Хотя в 32-битных программах это должно работать аналогичным образом.
В следующих двух разделах мы раскроем тайну того, как ЦП «под капотом» обрабатывает стеки вызовов. Вот программа высокого уровня, которую мы рассмотрим. Я намеренно делаю программу предельно простой и бессмысленной, чтобы мы могли сосредоточиться на стеке вызовов, а не отвлекаться на что-то еще.
int Interface(int g) {
int k = g * g;
return k * k;
}
int main(int argc, char** argv) {
int a = Interface(argc);
return a;
}х64-архитектура
Всего в современной архитектуре процессора x64 имеется 16 64-битных регистров общего назначения. Это RAX, RBX, RCX, RDX, RSI, RDI, RBP, RSP, R8соответственно R16. Помимо регистров общего назначения, существует также специальный регистр с именем RIP— указатель инструкции, который сообщает процессору, что делать дальше.
Помимо этих регистров, конечно, есть еще. Например, все процессоры, совместимые с x86-64, поддерживают SSE2 и включают 16 128-битных SIMD-регистров, сXMM0поXMM15. Довольно часто можно увидеть и AVX SIMD, это достигается за счет еще 16 256-битных регистров, а YMM0именно YMM15. Более того, существует AVX-512, расширение, позволяющее процессору одновременно обрабатывать 16 32-битных числовых операций. Процессоры, поддерживающие это, имеют еще 16 регистров ( ZMM0- ZMM15), каждый из которых имеет длину 256 бит.
Очень часто мы сохраняем что-то в регистре и извлекаем значение из этого регистра позже. Однако нередко нам нужно изменить значение регистра между двумя инструкциями, особенно если между ними есть вызовы функций. Чтобы гарантировать, что к моменту чтения регистра значение не будет перезаписано, значение должно быть где-то сохранено (обычно в стеке), прежде чем оно будет изменено между ними. Есть несколько регистров, которые сохраняются вызываемой функцией. Это означает, что вызывающей функции необходимо сохранить регистр перед тем, как прикасаться к регистрам, и восстановить значение регистров перед выходом из функции, чтобы вызывающая функция даже не знала, какое значение регистра изменено. Эти регистры RBX, RBP,R12R15. Все остальные регистры сохраняются вызываемой функцией, что означает обратное: вызываемая функция может изменить значения регистров в любое время, когда захочет, предполагая, что вызывающая функция будет следить за тем, чтобы значения регистров соответствовали инструкциям вызываемой функции.
Далее давайте посмотрим на ассемблерный код, созданный компилятором g++ ниже. Обратите внимание: чтобы понять, как процессор работает со своими регистрами для правильной поддержки стека, мне придется отключить оптимизацию компилятора, поскольку в противном случае компилятор может решить оптимизировать их, избегая использования регистра rbp, чтобы его можно было использовать в качестве другого регистра общего назначения. Иногда он даже встраивает всю функцию вообще без перехода. Вот ассемблерный код, сгенерированный g++ 7.5.0 в Ubuntu:
0x400667 <Interface(int)> push %rbp
0x400668 <Interface(int)+1> mov %rsp,%rbp
0x40066b <Interface(int)+4> mov %edi,-0x14(%rbp)
0x40066e <Interface(int)+7> mov -0x14(%rbp),%eax
0x400671 <Interface(int)+10> imul -0x14(%rbp),%eax
0x400675 <Interface(int)+14> mov %eax,-0x4(%rbp)
0x400678 <Interface(int)+17> mov -0x4(%rbp),%eax
0x40067b <Interface(int)+20> imul -0x4(%rbp),%eax
0x40067f <Interface(int)+24> pop %rbp
0x400680 <Interface(int)+25> retq
0x400681 <main(int, char**)> push %rbp
0x400682 <main(int, char**)+1> mov %rsp,%rbp
0x400685 <main(int, char**)+4> sub $0x20,%rsp
0x400689 <main(int, char**)+8> mov %edi,-0x14(%rbp)
0x40068c <main(int, char**)+11> mov %rsi,-0x20(%rbp)
0x400690 <main(int, char**)+15> mov -0x14(%rbp),%eax
0x400693 <main(int, char**)+18> mov %eax,%edi
0x400695 <main(int, char**)+20> callq 0x400667 <Interface(int)>
0x40069a <main(int, char**)+25> mov %eax,-0x4(%rbp)
0x40069d <main(int, char**)+28> mov -0x4(%rbp),%eax
0x4006a0 <main(int, char**)+31> leaveq
0x4006a1 <main(int, char**)+32> retqТо, что показано выше, представляет собой код на языке ассемблера для двух функций в приведенной выше программе на C++. Помните, что одна и та же программа может создавать совершенно разные ассемблерные инструкции с разными компиляторами, но общая структура программы должна быть похожа друг на друга. Вместо того, чтобы рассматривать все инструкции по отдельности, мы сосредоточимся только на тех, которые имеют отношение к нашей теме. Ниже показано, что происходит, когда эта программа выполняется, с пропуском некоторых инструкций, поскольку они не имеют значения.
В самом начале значение
RIP0x400681 означает, что следующей инструкцией будетpush %rbp, та которая находится в начале основной функции.Начиная с 0x400681, первое, что делает процессор, — сохраняет
RBPрегистр в памяти стека. Эта push-операция также уменьшит значениеRSPна 8.RSP— это указатель стека, указывающий на текущий верхний адрес стека. Обратите внимание, что в архитектуре x86/x64 адрес стека уменьшается при каждом его увеличении. В этом случае, посколькуRBPэто 64-битные регистры, указатель стека (RSP) необходимо уменьшить на 8, чтобы избежать перезаписи сохраненного значенияRBPчем-либо еще. Конечно, после выполнения этой инструкцииRIPтакже будет изменена, чтобы процессор знал, что выполнять дальше.Следующее, что он делает, это устанавливает текущее значение указателя стека в регистр
RBP. Это даст нам некоторое представление о том, что такоеRBP. Нетрудно заметить, что вRBPрегистре сохраняется значение нижней части кадра стека текущей функции.Пропустив некоторые не относящиеся к делу инструкции, давайте взглянем на инструкцию 0x400695. Это инструкция, которая вызывает
Interfaceфункцию. Здесь ЦП сначала помещает в стек адрес следующей инструкции, то есть 0x40069a. Конечно, поскольку это push,RSPбудет снова уменьшено, чтобы сохранить передаваемое значение в безопасности. Это то, что обычно называют обратным адресом. В частности, это следующая инструкция, которую должен выполнить процессор после завершения вызываемой функции, какInterfaceв нашем случае. Конечно, помимо помещения адреса следующей инструкции в стек, ЦП необходимо выполнить первую инструкцию в функцииInterface. Это достигается путем измененияRIPрегистра на 0x400667, чтобы процессор знал, что выполнять дальше.Глядя на первую инструкцию в функции, которая находится по адресу 0x400667, это сразу напоминает нам, что делается в начале основной функции, помещая значение
RBPв стек. На данный момент мы знаем, значениеRBP, это базовый адрес основного кадра стека вызовов. Поскольку в данный момент мы находимся в функцииInterface, нам необходимо убедиться, чтоRBPзначение находится в нижней части кадра стека функцииInterface, а не кадра стека функцииmain. Для этого нам просто нужно переместить значениеRSPвRBP. Однако нижняя информация кадра стека функцииmainбудет потеряна. Выше мы упоминали, чтоRBPэто регистр, сохраняемый вызываемой функцией, это означает, что вызываемая функция (Interface) отвечает за то, чтобыRBPс точки зрения вызывающей функции не изменился. Для этого нам просто нужно поместить элементRBPв стек, прежде чем присваивать ему новое значение. И именно об этом идет речь в этой строке.Следующая инструкция 0x400668 очень похожа на инструкцию 0x400682, которую мы рассматривали ранее. Его единственная цель — убедиться, что
RBPсохраняет значение нижней части кадра стека текущей функции.Инструкции между 0x40066b и 0x40067b (включительно) представляют собой просто реализацию тела функции. На самом деле это вполне понятно даже тому, кто не знаком с языками ассемблера. Здесь следует иметь в виду, что
RSPв инструкциях не меняется.Далее, глядя на 0x40067f, процессор увеличивает значение
RSPна 8 и принимает текущее значение, указанное вRSP. Это то, что мы обычно называем «выталкиванием стека». ПосколькуRSPуказывает на следующий адрес, соседний с адресом, имеющим староеRBPзначение, нижнюю часть основного кадра стека вызовов, эта инструкция сотрет то, что хранится в данный момент вRBPи восстановитRBPзначение перед выходом из функции.Прямо перед выходом из функции процессор выполнит
retqинструкцию. Это увеличивает значениеRSPна 8, берет значение, указанное вRSPи присваивает егоRIP. Внимательные читатели, возможно, уже поняли, что это именно 0x40069a, поскольку мы сохранили это значение в инструкции 0x400695.
На этом этапе мы полностью рассмотрели способ вызова функции. Как мы видим, здесь RBPони RSPиграют решающую роль в сохранении информации о стеке вызовов и обеспечении ее видимости для ЦП. Опять же, на самом деле, во многих случаях компиляторы будут пытаться оптимизировать его, поэтому вполне возможно, что мы не увидим некоторые из них в сборке релиза. Обратите внимание, что эта оптимизация RBPни в коем случае не то же самое, что попытка компилятора оптимизировать функцию путем ее встраивания. Он по-прежнему переключаетRIPна другой фрагмент кода, принадлежащий функции Interface.
0x4004d0 <Interface(int)> mov %edi,%eax
0x4004d2 <Interface(int)+2> imul %edi,%eax
0x4004d5 <Interface(int)+5> imul %eax,%eax
0x4004d8 <Interface(int)+8> retq
0x4003e0 <main(int, char**)> jmpq 0x4004d0 <Interface(int)>Выше приведен ассемблерный код, созданный с оптимизацией (уровень 3) тем же компилятором. Чтобы компилятор не встраивал эту функцию, я вынес ее Interfaceв отдельный модуль компиляции. Как мы видим из этого, он требует инструкции перехода в основной функции, а не расширения того, что находится Interfaceвнутри main.
Опция-flto для компилятора даёт возможность выполнить оптимизацию времени компоновки, что позволяет компилятору оптимизировать различные модули компиляции. Подобная опция доступна во всех основных компиляторах C++. При использовании этой опции будет создан следующий ассемблерный код.
0x4003e0 <main(int, char**)> mov %edi,%eax
0x4003e2 <main(int, char**)+2> imul %edi,%eax
0x4003e5 <main(int, char**)+5> imul %eax,%eax
0x4003e8 <main(int, char**)+8> retqКак мы видим из приведенного выше кода, инструкция перехода полностью удалена, то есть функция уже встроена в эту оптимизацию. Позже мы увидим, что нам нужно будет предотвратить это в контексте переключения волокон.
Arm64 Архитектура
Помимо архитектуры x64, я также хотел бы кратко упомянуть в этом посте об архитектуре Arm64 в связи с растущей популярностью платформы, особенно после выхода новой линейки Mac от Apple с Apple Silicon. Цель введения волокон в этом посте в основном ориентирована на разработку игр. Отсутствие решения для Arm64 станет препятствием для коммерческого внедрения этой технологии, поскольку большинство мобильных устройств, включая Apple Silicon Mac, работают на этой платформе.
Ниже приведен краткий обзор регистров, доступных на процессорах Arm64.
X0-X29 : Эти 30 регистров в основном предназначены для общего использования. Программисты могут использовать большинство из них для чего угодно. Хотя обычная практика предполагает определенное использование нескольких регистров, например,
X29обычно используемых в качестве указателя кадра, что-то похожее наRBPв архитектуре x64.X30, LR : в отличие от x64, здесь имеется специальный регистр для отслеживания адреса возврата при вызове функции. И этот регистр
X30иногда еще называютLR.SP, XZR : это указатель стека в архитектуре Arm64, аналог
RSPв x64. Однако небольшое отличие здесь состоит в том, что этот регистр также можно использовать в качестве нулевого регистра при использовании в инструкциях, не связанных со стеком.PC : это версия Arm
RIP, указатель команд или счетчик программ. Он записывает, что будет выполняться процессором дальше.V0-V31 : это 32 регистра, которые используются для операций с плавающей запятой и операций Neon, 4-way SIMD.
Выше представлена лишь часть всего набора регистров. Есть больше регистров, таких как D0- D31, S0- S30и т. д. Однако нас интересует только изучение вышеуказанных регистров, поскольку только они имеют значение, когда мы реализуем волокна на процессорах Arm64.
Как и в x64, некоторые из вышеперечисленных регистров сохраняются вызываемой функцией. Это X16- X30, V8- V15. Остальные доступные регистры сохраняются вызывающей функцией.
Опять же, начнем с ассемблерного кода, созданного без оптимизации. В данном случае я скомпилировал исходный код с помощью Apple clang версии 14.0.0 на MacOS Ventura 13.1.
Во-первых, вот код основной функции
0x100003f7c <+0>: sub sp, sp, #0x30
0x100003f80 <+4>: stp x29, x30, [sp, #0x20]
0x100003f84 <+8>: add x29, sp, #0x20
0x100003f88 <+12>: stur wzr, [x29, #-0x4]
0x100003f8c <+16>: stur w0, [x29, #-0x8]
0x100003f90 <+20>: str x1, [sp, #0x10]
0x100003f94 <+24>: ldur w0, [x29, #-0x8]
0x100003f98 <+28>: bl 0x100003f50 ; Interface at main.cpp:5
0x100003f9c <+32>: str w0, [sp, #0xc]
0x100003fa0 <+36>: ldr w0, [sp, #0xc]
0x100003fa4 <+40>: ldp x29, x30, [sp, #0x20]
0x100003fa8 <+44>: add sp, sp, #0x30
0x100003fac <+48>: ret Поскольку у нас уже есть некоторый опыт чтения ассемблерного кода, давайте пройдемся по этому вопросу немного быстрее.
Начиная с самого начала,
PCрегистр (счетчик программиста) равен 0x100003f7c, что означает, что первая инструкция —sub sp, sp, #0x30это не что иное, как увеличение стека вызовов. Как и в случае с x64, адрес стека вызовов уменьшается по мере роста стека. В этом примере стек вызовов увеличивается на 48 байт.Как мы упоминали ранее,
X29(FP, указатель кадра) иX30(LR) сохраняются вызываемой функцией, нам придется сохранить значения, прежде чем двигаться дальше. Инструкция 0x100003f80 делает именно это. Позже мы увидим, что если мы не изменяем ни один из них в функции, тогда нет необходимости хранить их в начале функции.Переходя к инструкции 0x100003f98, она сначала сохраняет 0x100003f9c в регистр
x30(LR), а затем устанавливаетPCзначение 0x100003f50, первую инструкцию в функцииInterface.
Прежде чем продолжить работу с этой программой, давайте быстро заглянем внутрь функции Interface.
0x100003f50 <+0>: sub sp, sp, #0x10
0x100003f54 <+4>: str w0, [sp, #0xc]
0x100003f58 <+8>: ldr w8, [sp, #0xc]
0x100003f5c <+12>: ldr w9, [sp, #0xc]
0x100003f60 <+16>: mul w8, w8, w9
0x100003f64 <+20>: str w8, [sp, #0x8]
0x100003f68 <+24>: ldr w8, [sp, #0x8]
0x100003f6c <+28>: ldr w9, [sp, #0x8]
0x100003f70 <+32>: mul w0, w8, w9
0x100003f74 <+36>: add sp, sp, #0x10
0x100003f78 <+40>: retПервая инструкция (0x100003f50) увеличивает стек вызовов на 16 байт.
Инструкции между 0x100003f54 и 0x100003f70 выполняют вычисления внутри
Interfaceфункции.Инструкция 0x100003f74 извлекает стек.
Последняя инструкция ret просто просит программу перейти к инструкции,
LRна которую указывает регистр, и в основной функции ей присваивается значение 0x100003f9c с помощью инструкции 0x100003f98.
Одна вещь, которую мы можем заметить в этой программе, это то, что ассемблерный код в Interfaceфункции не требует сохранения и восстановления , X29и X30это нормально, поскольку он никогда не вносит никаких изменений в эти параметры внутри этой функции.
После Interfaceзавершения функции значение PCстановится 0x100003f9c, следующей инструкцией после вызова Interfaceфункции.
Глядя на 0x100003fa4, эта программа восстанавливает
X29иX30регистрирует. Важно восстановить эти два регистра. В частности, в этой программе этоLRважно, поскольку после вызова инструкции возврата по адресу 0x100003fac основная функция должна вернуться туда, куда указываетLR.Разумеется, на вызываемой функции лежит ответственность за то, чтобы
SPрегистр не изменился. Поскольку мы увеличиваем стек по инструкции 0x100003f7c, нам придется вытолкнуть стек, чтобы регистрSPне пострадал.
Аналогично посмотрим на ассемблерный код, созданный тем же компилятором, но с оптимизацией. Ниже приведен код, созданный компилятором, в котором две функции разделены на два разных модуля компиляции.
Ниже приведен ассемблерный код для main.
0x100003fa8 <+0>: b 0x100003fac ; Interface at test.cpp:3:15А вот ассемблерный код интерфейса.
0x100003fac <+0>: mul w8, w0, w0
0x100003fb0 <+4>: mul w0, w8, w8
0x100003fb4 <+8>: retЭто не требует пояснений. Хочу отметить один интересный трюк, который в данном случае проделал компилятор. Помните, что инструкция перехода — это bне blинструкция, как раньше. Эта bинструкция не сохраняет адрес возврата в регистре LR. Это нормально, поскольку компилятор поступает разумно, воспользовавшись тем фактом, что после вызова функции нет дальнейших инструкций Interface. Таким образом, после Interfaceзавершения функции она сразу переходит к следующей инструкции любого кода, который вызывает main.
Наконец, давайте взглянем на ассемблерный код, созданный с оптимизацией времени компоновки.
0x100003fac <+0>: mul w8, w0, w0
0x100003fb0 <+4>: mul w0, w8, w8
0x100003fb4 <+8>: retОчень простой код, который делает именно то, что нам нужно.
Краткое резюме, прежде чем двигаться вперед
В этом разделе мы кратко упомянули некоторые основы того, как ЦП обрабатывает стек вызовов в архитектуре x64 и Arm64. Теперь нам также ясно, какие регистры сохраняются вызываемой функцией, а какие — вызывающей.
Несмотря на то, что то, чего мы коснулись, — это всего лишь верхушка айсберга, это должно послужить нам хорошей основой для дальнейшего изучения того, что такое волокно и как оно может работать при необходимости.
Существующий интерфейс волокон в Windows
Далее, прежде чем мы наконец углубимся в детали реализации волокон, давайте кратко рассмотрим, какой интерфейс операционная система Windows предлагает для этого. Он действительно прост в использовании.
ConvertThreadToFiber: Эта функция помогает преобразовать текущий поток в волокно. Прежде чем передать управление другому волокну, необходимо преобразовать поток в волокно.ConvertFiberToThread: Эта функция является обратной версией предыдущей функции. Он преобразует текущее волокно в исходный поток, который был преобразован в него изначально.CreateFiber: Это интерфейс для создания волокна. Программисты могут указать размер стека и указатель функции входа волокна, чтобы при первом получении управления оно запускалось из этой точки.DeleteFiber: Как следует из названия, это запрос ОС на удаление волокна. Конечно, ответственность за то, чтобы работающее волокно не было удалено, лежит на программисте, что вполне может привести к сбою.SwitchToFiber: Это самая пикантная часть. Это интерфейс, который позволяет волокну переходить на другое волокно. И эта реализация функции довольно дешевая, затраты на производительность далеки от переключения потоков, запланированного ОС.
Вот и все. Это важная часть интерфейсов волокон, необходимая для реализации системы заданий, позволяющей выполнять работу в середине задачи. Как мы видим, на самом деле это совсем не сложно.
Для читателей, которые все еще не понимают, как их использовать, вот краткий пример, демонстрирующий, как использовать интерфейсы.
#include <iostream>
#include <Windows.h>
#define FiberHandle LPVOID
void RegularFunction(FiberHandle* fiber)
{
// We are done executing this fiber, yield control back
SwitchToFiber(fiber);
std::cout << "Hello Fiber Again" << std::endl;
}
void WINAPI FiberEntry(PVOID arg)
{
// this is the fiber that yields control to the current fiber
FiberHandle* fiber = reinterpret_cast<FiberHandle*>(arg);
// do whatever you would like to do here.
std::cout << "Hello Fiber" << std::endl;
RegularFunction(fiber);
// We are done executing this fiber, yield control back
SwitchToFiber(fiber);
}
int main(int argc, char** argv) {
// convert the current thread to a fiber
FiberHandle fiber = ConvertThreadToFiber(nullptr);
// create a new fiber
FiberHandle new_fiber = CreateFiber(1024, FiberEntry, fiber);
// yield control to the new fiber
SwitchToFiber(new_fiber);
SwitchToFiber(new_fiber);
// convert the fiber back to thread
ConvertFiberToThread();
// delete the fibers
DeleteFiber(new_fiber);
return 0;
}Если возникнет путаница, вот краткое объяснение. Порядок выполнения таков, что функция main выполняется до строки 36, где она передает управление новому волокну, созданному в строке 33. После передачи функция main больше не будет управлять, ЦП начнет выполнение со строки 14. Имейте в виду, что в строке 9 программа переходит непосредственно из функции, которая, как следует из названия, является обычной функцией C++, к основной функции, чтобы она продолжала выполнение в строке 37. Для этого RegularFunctionнет необходимости переходить в FiberEntry. Также возможно перейти куда угодно глубоко в стек вызовов волокна. Поскольку строка 37 немедленно передает управление волокну,new_fiberполучает управление во второй раз, за исключением того, что на этот раз оно возобновляет выполнение с того места, где оно было приостановлено ранее (строка 9), а не начинает снова с нуля. И последнее, но не менее важное: программисты обязаны следить за тем, чтобы волокно всегда уступало правильному волокну для выполнения. В этом случае строка 25 обеспечивает возврат управления в основной режим и выполнение остальной части основной функции. Не ждите, что компилятор поможет в этом случае, у него недостаточно информации для принятия такого решения.
Надеемся, что на этом простом примере читатели смогут понять мощь и гибкость волокон. Он предлагает большую мощность, которая крайне необходима в системе задач с множеством зависимостей.
Реализация Fiber на x64
Этого поста не существовало, если бы не эта забавная часть. Самое интересное начинается в этом разделе, когда мы начинаем возиться с регистрами, чтобы обмануть ЦП, чтобы мы могли переключать волокна, как это делает интерфейс, предоставляемый ОС. Чтобы сделать этот пост более познавательным, я создал небольшую библиотеку, которая делает только это. Вот ссылка на созданный мной gist. Читателям рекомендуется прочитать эту публикацию в блоге вместе с исходным кодом, чтобы глубже понять эту технологию.
На самом деле такая реализация необходима на MacOS, поскольку на момент написания этой статьи ОС не предлагает интерфейсов для управления волокнами. В MacOS действительно существовал интерфейсucontext. Однако он был признан устаревшим. Использование такого интерфейса было бы рискованным в будущем. В Linux мы действительно можем использовать его для достижения того же самого.
Процесс реализации интерфейса волокна должен оказаться весьма полезным. А реализация волокна x64, о которой мы упомянем в этом разделе, будет работать на всех платформах, поддерживающих System V ABI.
Чтобы реализовать волокно на x64 самостоятельно, нам нужно всего лишь реализовать 5 интерфейсов, упомянутых выше. На самом деле, хорошая новость заключается в том, что нужно сделать совсем немного в ConvertThreadToFiberи ConvertFiberToThread. Позже мы объясним, почему это так. Это оставляет нам только три функции для реализации: CreateFiber, DeleteFiberи SwitchToFiber.
Определение структуры волокна
Для начала нам нужно сначала определить структуру волокна. Ниже приведено определение волокна в моей реализации. Давайте сначала взглянем на него.
//! Abstruction for fiber struct.
struct Fiber {
/**< Pointer to stack. */
void* stack_ptr = nullptr;
/**< fiber context, this is platform dependent. */
FiberContexInternal context;
};Как мы видим из этой структуры данных, в ней всего два члена. stack_ptr, как следует из названия, — это просто указатель на адрес стека, который будет использоваться волокном. В отличие от обычной подпрограммы или сопрограммы, поддерживаемой языком, Волокно требует, чтобы программисты самостоятельно выделяли свою собственную стековую память. С интерфейсом волокна Windows это делается «под капотом»CreateFiber. Однако при такой низкоуровневой реализации asm нам необходимо взять на себя ответственность за создание стековой памяти. В действительности, этот явный контроль над распределением памяти обычно приветствуется разработчиками игр, поскольку они отвечают за распределение памяти, а не передают ее сторонней библиотеке. Помните, что нет никаких реальных требований к тому, чтобы память, на которую должен указывать этот указатель, обычно находится в куче, но совершенно нормально, если эта память стека волокна выделена в другом стеке волокна или потока, пока синхронизация выполняется правильно, поэтому память стека волокна не будет уничтожена до того, как она будет использована. Единственная причина, по которой мы это отслеживаем, заключается в том, что мы хотим правильно освободить эту память при разрушении волокна. Код сборки вообще не будет использовать этот элемент для отслеживания стека. Вместо этого он будет использовать указатель стека, который хранится вFiberContextInternal, чтобы отслеживать стек.
context— это структура данных, которая отслеживает регистры. Структура контекста таинственного волокна просто отслеживает несколько регистров, конкретно определенных, как показано ниже.
struct FiberContexInternal {
// callee-saved registers
Register rbx;
Register rbp;
Register r12;
Register r13;
Register r14;
Register r15;
// stack and instruction register
Register rsp;
Register rip;
};У некоторых читателей уже могут возникнуть вопросы. Каково обоснование выбора регистров, которые необходимо хранить? Это очень важный вопрос для нас, чтобы понять, как это работает. Чтобы ответить на вопрос, давайте посмотрим на регистры в структуре данных.
Зачем нам нужно хранить
RIP? Это действительно простой вопрос. Как упоминалось ранее,RIPэто указатель инструкции, который указывает на следующую инструкцию, которая будет выполнена ЦП.FiberContextInternal— это место для данных между приостановкой и возобновлением волокна. При приостановке волокно должно знать, где оно приостановлено, чтобы при возобновлении оно знало, какую следующую инструкцию должен выполнить ЦП, чтобы возобновить работу именно с того места, где оно было приостановлено.Зачем нам нужно хранить
RSP? На этот вопрос тоже легко ответить. Поскольку мы выделяем собственную волоконную память,RSPдолжна указывать на собственный стек. Поскольку компилятор не знает, где находится вершина стека, нам нужно убедиться, что мы знаем, где она находится. ИRSPделает именно это.Зачем нам нужно хранить сохраненные регистры вызываемой функции? Представьте, что у нас есть функция A, которая переключила волокно с волокна 0 на волокно 1. Предположим, что регистр
R12записан непосредственно перед переключением. После переключения функция A будет приостановлена, а волокно 1 будет либо возобновлено, либо запущено. Если волокно 1 было приостановлено ранее и возобновилось, следующие инструкции волокна 1 также могут прочитать регистрR12. Однако его ни в коем случае не интересует чтение значенияR12, записанного функцией A, все, что ему нужно знать, это то, каким было значение регистраR12до его приостановки. С другой стороны, значение, записанное в регистрR12функцией A, вполне вероятно, будет прочитано и внутри него позже. Чтобы это значение не потерялось после его возобновления в будущем, его необходимо где-то кэшировать. То же самое относится не только кR12, но и ко всем сохраненным регистрам вызываемой функции. И именно поэтому нам необходимо хранить все сохраненные регистры вызываемой функции.Почему нас не волнуют сохраненные регистры вызывающих функций? Если мы посмотрим на тот же пример, что и выше, мы должны помнить, что переключатель волокна сам по себе является функцией. Даже если переключение волокна представляет собой обычную подпрограмму, пока она не встроена, компилятору необходимо убедиться, что он восстанавливает значения сохраненных регистров вызывающей стороны после ее вызова. В приведенном выше примере представьте, что после переключения волокна какое-то другое волокно перезаписывает значение сохраненных регистров вызывающей функции и переключает управление обратно на волокно 0, компилятор по-прежнему несет ответственность за то, чтобы убедиться, что сохраненные регистры вызывающей функции правильно восстановлены, прежде чем повторно использовать их. в коде вызывающей функции. Такой процесс восстановления обычно выполняется путем кэширования значения в стеке. В некоторой степени мы можем рассматривать сам стек вызовов как частичный кеш нашего контекста волокна, что освобождает нас от необходимости делать это. Чтобы подчеркнуть это, нам очень важно убедиться, что компилятор не оптимизирует нашу функцию переключения волокон во встроенную версию. В противном случае нам также пришлось бы нести ответственность за хранение сохраненных регистров вызывающей стороны в контексте волокна. В зависимости от того, насколько агрессивна оптимизация компилятора, может быть недостаточно просто поместить это определение функции в другой модуль компиляции, особенно когда включена оптимизация времени компоновки. Самый надежный способ убедиться в этом — просмотреть ассемблерный код, созданный компилятором, чтобы убедиться, что он делает то, что мы ожидаем.
На этом этапе, я считаю, должно быть понятно, почему мы определяем структуру контекста волокна такой, какая она есть. Благодаря тому, что все регистры SIMD сохраняются вызывающей функцией, нам нужно сохранить только несколько регистров в контексте нашего волокна.
Переключение между волокнами
Вместо того, чтобы начинать с CreateFiber, я решил начать с SwitchFiber, поскольку первый требует знаний о том, как работает второй. Мы уже узнали, что ЦП будет использовать свои регистры только для общения с остальной частью системы, если что-то не может быть разрешено во время компиляции, например адреса функций. Поскольку статическая информация одинакова для всех выполняющихся потоков/волокон, нас тогда интересуют только регистры для переключения волокон. Поскольку мы работаем с регистрами, для этого нам придется прикоснуться к языкам ассемблера. Ниже приведена реализация волокна, которую я реализовал на архитектуре x64.
.text
.align 4
_switch_fiber_internal:
// Store callee-preserved registers
movq %rbx, 0x00(%rdi) /* FIBER_REG_RBX */
movq %rbp, 0x08(%rdi) /* FIBER_REG_RBP */
movq %r12, 0x10(%rdi) /* FIBER_REG_R12 */
movq %r13, 0x18(%rdi) /* FIBER_REG_R13 */
movq %r14, 0x20(%rdi) /* FIBER_REG_R14 */
movq %r15, 0x28(%rdi) /* FIBER_REG_R15 */
/* call stores the return address on the stack before jumping */
movq (%rsp), %rcx
movq %rcx, 0x40(%rdi) /* FIBER_REG_RIP */
/* skip the pushed return address */
leaq 8(%rsp), %rcx
movq %rcx, 0x38(%rdi) /* FIBER_REG_RSP */
// Load context 'to'
movq %rsi, %r8
// Load callee-preserved registers
movq 0x00(%r8), %rbx /* FIBER_REG_RBX */
movq 0x08(%r8), %rbp /* FIBER_REG_RBP */
movq 0x10(%r8), %r12 /* FIBER_REG_R12 */
movq 0x18(%r8), %r13 /* FIBER_REG_R13 */
movq 0x20(%r8), %r14 /* FIBER_REG_R14 */
movq 0x28(%r8), %r15 /* FIBER_REG_R15 */
// Load stack pointer
movq 0x38(%r8), %rsp /* FIBER_REG_RSP */
// Load instruction pointer, and jump
movq 0x40(%r8), %rcx /* FIBER_REG_RIP */
jmp *%rcxНиже приведено объявление функционального интерфейса.
void _switch_fiber_internal(FiberContexInternal* src_fiber, const FiberContexInternal* dst_fiber);В этой функции есть два параметра: src_fiberи dst_fiber. В приведенном выше ассемблерном коде RDIэто первый параметр ( src_fiber) и RSIвторой параметр ( dst_fiber). Ассемблерный код настолько прост, что не требует подробного объяснения. В двух словах, он берет содержимое соответствующих регистров ( RBX, RBP, R12to R15, RIP, RSP) и сохраняет его в контексте волокна, на который src_fiberуказывает, после чего также загружает содержимое в контексте волокна, на которое указывает, dst_fiberв регистры. После замены значений в регистрах ЦП обманывает последовательность выполнения. Он забудет весь предыдущий контекст инструкций и притворится, что эта функция вызывается откуда.dst_fiberосталось от последнего времени, которое также включает в себя начальное состояние файла dst_fiber.
Следующий очевидный вопрос заключается в том, откуда берется значение контекста волокна, на которое указывает dst_fiber. Тогда есть два случая. Если волокно было приостановлено ранее, оно должно было пройти через тот же интерфейс, который должен был заполнить контекст волокна правильным значением в первой половине функции _switch_fiber_internal. Конечно, ответственность за проверку правильности переключения волокна лежит на программистах. Неправильное переключение волокон легко приведет к сбою программы.
Однако если волокно создается заново и никогда раньше не выполнялось, нам также необходимо убедиться, что оно работает должным образом.
Создание нового волокна
Теперь, когда мы знаем, как переключаться между волокнами, остается ответить на вопрос: как мы можем создать волокно с нуля, чтобы его можно было использовать в качестве целевого волокна в приведенном выше вызове SwitchFiber.
Прежде всего определим основную функцию волокна, которая служит началом выполнения волокна.
void FiberMain(){
// do whatever you want to do in this fiber
} Вход моего волокна определен, как указано выше. Хотя вполне возможно определить это и по-другому. Это лишь одна из возможностей. Следующий шаг — подключить эту функцию к волокну, чтобы при первом получении управления, оно начиналось с неё.
bool _create_fiber_internal(void* stack, uint32_t stack_size, FiberContexInternal* context) {
// it is the users responsibility to make sure the stack is 16 bytes aligned, which is required by the Arm64 architecture
if((((uintptr_t)stack) & (FIBER_STACK_ALIGNMENT - 1)) != 0)
return false;
uintptr_t* stack_top = (uintptr_t*)((uint8_t*)(stack) + stack_size);
context->rip = (uintptr_t)FiberMain;
context->rsp = (uintptr_t)&stack_top[-3];
stack_top[-2] = 0;
return true;
}Выше представлена реализация для архитектуры x64. На самом деле это довольно просто: всё, что нам нужно сделать, это настроить указатель стека и указатель инструкции. Поскольку указатель инструкции указывает на FiberMain, волокно будет запускаться сначала из этой точки входа в функцию, что точно соответствует нашим ожиданиям. В стек мы можем передать любую память, если мы можем быть уверены, что во время выполнения волокна эта память не будет уничтожена. Память стека должна быть выровнена по 16 байтам, что требуется для ABI. Как упоминалось ранее, адрес стека увеличивается вниз, а это означает, что каждый раз, когда мы помещаем что-то в стек, адрес вершины стека уменьшается. И из-за этого нам приходится устанавливать указатель стека в конец памяти, а не в начало.
Если мы подумаем о первом выполнении такого волокна, то вторая половина функции _switch_fiber_internalпросто загрузит мусорные значения в сохраненные регистры вызываемой функции, за исключением rspи rip, но это нормально, поскольку компилятор позаботится о том, чтобы сохраненные регистры вызываемой функции не были прочитайте, прежде чем они будут написаны.
В приведенной выше конструкции есть одна неприятная вещь. Функция FiberMainне имеет никакой связи с кодом создания. Конечно, можно передавать информацию через глобальные данные с тщательной синхронизацией. Лучшая альтернатива — позволить программистам передавать один указатель на объект, FiberMainчтобы он мог получить доступ к основной информации о FiberMainкоде его создания. Если вы можете передать указатель, вы можете передать что угодно.
Чтобы это произошло, нам нужно добавить еще один регистр в контексте нашего волокна. И этот регистр — RDI, который используется для представления первого аргумента, переданного в функцию.
struct FiberContexInternal {
// callee-saved registers
Register rbx;
Register rbp;
Register r12;
Register r13;
Register r14;
Register r15;
// stack and instruction register
Register rsp;
Register rip;
// the first parameter
Register rdi;
};С помощью этого дополнительного регистра мы можем просто передать указатель из нашего переопределенного интерфейса таким образом.
bool _create_fiber_internal(void* stack, uint32_t stack_size, void* arg, FiberContexInternal* context) {
// it is the users responsibility to make sure the stack is 16 bytes aligned, which is required by the Arm64 architecture
if((((uintptr_t)stack) & (FIBER_STACK_ALIGNMENT - 1)) != 0)
return false;
uintptr_t* stack_top = (uintptr_t*)((uint8_t*)(stack) + stack_size);
context->rip = (uintptr_t)FiberMain;
context->rdi = (uintptr_t)arg;
context->rsp = (uintptr_t)&stack_top[-3];
stack_top[-2] = 0;
return true;
}И, конечно же, нам также необходимо внести некоторые изменения в наш ассемблерный код.
.text
.align 4
_switch_fiber_internal:
// Store callee-preserved registers
movq %rbx, 0x00(%rdi) /* FIBER_REG_RBX */
movq %rbp, 0x08(%rdi) /* FIBER_REG_RBP */
movq %r12, 0x10(%rdi) /* FIBER_REG_R12 */
movq %r13, 0x18(%rdi) /* FIBER_REG_R13 */
movq %r14, 0x20(%rdi) /* FIBER_REG_R14 */
movq %r15, 0x28(%rdi) /* FIBER_REG_R15 */
/* call stores the return address on the stack before jumping */
movq (%rsp), %rcx
movq %rcx, 0x40(%rdi) /* FIBER_REG_RIP */
/* skip the pushed return address */
leaq 8(%rsp), %rcx
movq %rcx, 0x38(%rdi) /* FIBER_REG_RSP */
// Load context 'to'
movq %rsi, %r8
// Load callee-preserved registers
movq 0x00(%r8), %rbx /* FIBER_REG_RBX */
movq 0x08(%r8), %rbp /* FIBER_REG_RBP */
movq 0x10(%r8), %r12 /* FIBER_REG_R12 */
movq 0x18(%r8), %r13 /* FIBER_REG_R13 */
movq 0x20(%r8), %r14 /* FIBER_REG_R14 */
movq 0x28(%r8), %r15 /* FIBER_REG_R15 */
// Load first parameter
movq 0x30(%r8), %rdi /* FIBER_REG_RDI */
// Load stack pointer
movq 0x38(%r8), %rsp /* FIBER_REG_RSP */
// Load instruction pointer, and jump
movq 0x40(%r8), %rcx /* FIBER_REG_RIP */
jmp *%rcxСо всеми вышеперечисленными изменениями мы вводим аргумент в FiberMain. И этот единственный аргумент позволяет нам получить доступ ко всему, что мы хотим, внутри FiberMain.
void FiberMain(void* arg){
// do whatever you want to do in a this fiber
} Внимательные читатели уже могут заметить здесь неэффективность производительности. Пока волокно выполнено, строка 32 бесполезна. На практике я сомневаюсь, что этот единственный цикл инструкций вообще может оказать какое-либо влияние на производительность. Подобно этой неэффективности, если у нас есть новое волокно, получающее управление через вызов переключения, все инструкции между 24 и 30 также бесполезны. Решением этой проблемы является прогрев волокна при его создании с помощью упрощенной функции сборки, не имеющей строк 24 и 30, путем переключения на вновь созданное волокно сразу после создания. И волокно может переключиться обратно в началеFiberMainк волокну создания немедленно, чтобы вернуть ему контроль. Код вызывающей функции даже ничего не заметит в таком путешествии туда и обратно. И тогда мы можем убрать инструкцию, загружающую первый параметр, через отдельную функцию сборки, которая будет использоваться только для будущего переключения волокон. Для простоты моя реализация не реализует эту оптимизацию.
Преобразование между потоком и волокном
Теперь мы можем создать волокно и переключиться на него с другого волокна. Остался один вопрос. Наша программа начинается с потока, а не с волокна. Нам нужно иметь возможность преобразовывать поток в волокно, чтобы это позволило нам осуществить переключение, поскольку мы не можем переключиться с потока на волокно.
Для этого нам нужно реализовать две разные функции ConvertToFiberFromThreadи ConvertToThreadFromFiber. Начнем с первой.
В отличие от вновь создаваемых волокон с помощью функции CreateFiber, которые по умолчанию находятся в приостановленном режиме, волокна, созданные посредством, ConvertToFiberFromThreadуже работают, когда они «создаются» или, в частности, преобразуются. Это вновь преобразованное волокно следует использовать в качестве исходного волокна, чтобы оно переключилось на какое-либо другое волокно. Ни при каких обстоятельствах мы не должны переходить с волокна на вновь преобразованное волокно производства ConvertToFiberFromThread, это не имеет смысла.
Воспользовавшись этим фактом, мы можем представить, что указатель стека или инструкция по умолчанию в таком преобразованном указателе нигде не служат никакой цели. Ни один код никогда не прочитает эти два члена ( RIP, RSP) в контексте волокна до того, как он будет впервые записан переключением волокна. То же самое справедливо для всех регистров в FiberContexInternal. Это дает нам возможность игнорировать такие поля во время преобразования потока в волокно.
inline FiberHandle CreateFiberFromThread() {
Fiber* ptr = (Fiber*)TINY_FIBER_MALLOC(sizeof(Fiber));
ptr->context = {};
return ptr;
}Выше представлена функция преобразования потока в волокно. Помимо выделения памяти структуры волокна, даже стека волокон, больше ничего не делается. Опять же, это совершенно нормально, поскольку этот контекст волокна не будет прочитан первым.
Довольно просто понять, что ConvertToThreadFromFiberэто просто пустая реализация. Альтернативное решение — удалить волокно в такой функции, чтобы обеспечить большее соответствие интерфейсу Windows. Однако в своей реализации я скрыл интерфейс из библиотеки. Это делается автоматически, как только заканчивается время жизни волокна.
Удаление волокна
Удаление волокна – самый простой метод по сравнению со всеми вышеперечисленными методами. Все, что нам нужно сделать на этом этапе, — это освободить память стека и память для самой структуры волокна.
Еще раз отметим: удаление работающего волокна может привести к сбою, если оно работает или будет работать в будущем. Ответственность за то, чтобы после удаления волокна никто не использовал, лежит на программистах.
Проблемы, вызванные волокнами
На данный момент, я считаю, мы поняли, как работают волокна. Как мы видим из реализации, волокно работает путем взлома регистров, чтобы обмануть ЦП, оно меняло местами стеки вызовов и другую соответствующую информацию, чтобы ЦП мог переключиться. Сделать такое переключение чрезвычайно дешево. Эта технология обеспечивает большую гибкость. И это может быть весьма полезно для разработки системы задач игрового движка.
Однако, пользуясь преимуществами волокон, мы должны осознавать риски и ответственность, которые мы принимаем на себя в то же время, чтобы избежать проблем.
Не выходите из FiberMain
Как мы узнали ранее, у компиляторов есть способы убедиться, что возвращаемый адрес правильно настроен при вызове функции. Однако мы должны помнить, что функция входа в волокно не имеет адреса возврата. Это не называется обычным способом. Не ждите, что волокно вернет контроль тому, кто его передал, это не произойдет автоматически.
Поэтому мы должны быть уверены, что функция входа в волокно никогда не будет завершать работу регулярно, как другие обычные функции. Что нам следует сделать, так это переключиться на какое-то другое волокно, как только ожидается, что оно больше не будет выполняться. Завершить выполнение волокна можно, даже если функция входа в волокно не завершена полностью. На самом деле необходимо избегать неожиданного поведения. Альтернативой является правильная настройка обратного адреса. Однако это немного усложнит реализацию волокна, и мы мало что от этого выиграем.
Умные указатели памяти
Умные указатели — это механизм предотвращения утечки памяти. Для каждого фрагмента выделения памяти в куче он связывает это выделение с выделением умного указателя, который представляет собой небольшой объект, управляющий временем жизни памяти кучи. Пока сам умный указатель уничтожается, выделение кучи, связанное с ним, также гарантированно освобождается. Если все умные указатели распределены в стеке, как мы знаем, к концу программы вся память стека правильно извлекается, мы можем легко сделать вывод, что всё выделение кучи также освобождается. Этот механизм также распространяется на умные указатели, расположенные в куче, которая сама контролируется другим умным указателем в стеке. Освобождение памяти будет происходить рекурсивно на любой уровень глубины, когда умный указатель верхнего уровня умрет.
Одним из крайних случаев, который делает этот механизм недействительным, является волокно. Представьте, что у вас есть волокно со стеком волокон в куче. Внутри этого волокна мы используем умный указатель, выделяющий часть памяти в куче. Однако затем волокно приостанавливается и никогда не возобновляется, пока волокно не будет разрушено. Здесь произойдет утечка умного указателя, находящегося в стеке волокон, который по сути находится в куче. Это отличается от выделения объекта с умным указателем в качестве его переменной-члена в куче: когда этот объект выходит за пределы области видимости, он уничтожает выделение кучи, связанное с элементом умного указателя. Это можно сделать, поскольку компилятор может гарантировать, что это произойдет. Однако аналогичный упомянутый случай не будет работать для волокон, поскольку компилятор ничего не знает о том, как мы используем наш стек волокон.
Таким образом, с помощью волокон технически возможно вызвать утечку памяти, даже если выделение памяти всей вашей программы защищено умными указателями. Нам, безусловно, нужно обратить внимание, чтобы избежать этого. Один из способов гарантировать, что этого не произойдет, — оставить переключение волокна непосредственно перед завершением функции FiberMainи всегда выполнять его для переключения последнего волокна. И даже при этом необходимо убедиться, что нет умного указателя, срок жизни которого все еще существует после последнего переключения волокна.
Уничтожение объекта
Мы упоминали, что не можем позволить функции входа в волокно завершить работу нормально. Это означает, что мы должны передать управление другим волокнам до того, как оно закончится. Это может означать, что в этом стеке все еще могут находиться активные объекты, такие как умные указатели, о которых мы говорили. В более общем смысле любые объекты, кроме умных указателей, могут нуждаться в правильном разрушении. Точно так же, как умные указатели теряют контроль над управлением памятью, если у нас есть объект, использующий свой деструктор для выполнения чего-то важного, он также может быть пропущен.
На программистах лежит ответственность за то, чтобы в случае разрушения волокна ничего, оставшегося в волокне, не нужно было выполнять. Обычно компиляторы могут защитить его для нас, но не в среде волокон.
Чтобы внести ясность, поведение компилятора в стеке волокон совершенно нормально. Это означает, что если у вас есть объект, который находится в стеке вызовов и который извлекается, компилятор позаботится о том, чтобы деструктор был вызван правильно. Нам нужно быть осторожными, чтобы убедиться, что при разрушении волокна не требуется выполнение ожидающего деструктора.
Нет сброса волокна в интерфейсе волокна Windows
Это скорее неудобство, чем проблема. Волокно обычно встречается в системе заданий игровых движков. Такие системы заданий обычно фиксируют потоки на физических ядрах ЦП посредством привязки потоков. Волокно похоже на контейнер для задания: задание может быть выполнено только тогда, когда оно находит доступное простаивающее волокно и поток. После завершения выполнения волокно будет возвращено в пул простаивающих волокон. Когда мы помещаем использованное волокно обратно в пул простаивающих волокон, нас больше не волнует его предыдущее состояние. Хорошая вещь, которую можно сделать, — это сбросить волокно в исходное состояние, прежде чем помещать его в пул свободных волокон. Этого можно легко достичь с помощью ассемблера, поскольку мы можем просто сбросить контекст волокна, как мы это делали при создании волокна. Конечно, нам не следует сбрасывать волокно, преобразованное из потока, поскольку в этом все равно нет смысла.
У этого простого решения есть проблема, поскольку Windows не предоставляет интерфейс для сброса волокна. Нереалистичным решением является удаление волокна и создание его заново каждый раз, когда нам нужно поместить его обратно в свободный пул, что, к сожалению, работает практически так же, как и отсутствие пула простаивающих волокон. Поскольку Windows создает интерфейс волокон, мы не можем выделить собственный стек. Распределение волокон в Windows связано с внутренним распределением памяти, что делает его немного дороже. Учитывая высокую частоту выполнения заданий во время кадра в игровом движке, это ни в коем случае не хорошее решение.
Есть как минимум два решения этой проблемы. Одним из решений является просто ассемблерная реализация волоконного интерфейса в Windows. Это не должно быть слишком сложно, поскольку мы уже реализовали архитектуру как x64, так и Arm64. Скорее всего, это просто вопрос переключения нескольких макросов.
Другое решение — поместить бесконечный цикл внутри FiberMainфункции, вот так.
void FiberMain(void* arg){
while(true){
// execute the task here
DoTask();
// yield the control back to another fiber
SwitchFiber(current_fiber, other_fiber);
}
}Это выходит за рамки самой темы библиотеки волокон. Это больше касается системы заданий. Здесь я кратко упомяну некоторые детали
Неактивное волокно должно начинаться либо с первой строки, либо с линии 8, которая является концом последней итерации цикла.
Помните, что мы вполне можем передать управление любому другому волокну внутри функции
DoTask. Мы можем передать данные где угодно глубоко внутри стека вызовов волокна.other_fiberможет быть либо волокно, ожидающее выполнения задачи, либо ранее приостановленное волокно. Какое волокно выбрать — это вопрос планирования системы заданий.
Исполнение волокна между потоками
В разных системах задач действуют разные политики. В каждой системе задач, основанной на волокнах, необходимо принять одно важное решение. Речь идет о том, разрешить ли приостановленному волокну возобновить работу в другом потоке. Здесь явно есть некоторый компромисс, который следует учитывать.
Если мы позволим это сделать, нам придется реализовать все предусмотренные системой примитивы синхронизации, такие как мьютекс и условная переменная. И мы не можем использовать локальное хранилище потоков так же свободно, как раньше. Это не значит, что мы вообще можем использовать TLS, нам просто нужно быть осторожным, чтобы наш шаблон доступа TLS не пересекал переключение волокна, поскольку до переключения TLS может быть из потока A, а после потока - из потока B. , что легко приведет к проблеме.
Если мы этого не позволяем. Мы можем использовать все вышеперечисленные запрещенные вещи. Однако балансировка нагрузки может быть не такой хорошей, как наоборот. Подумайте о том, что там 4 потока (4 физических ядра), каждый из которых тянет задачи. При этом первый поток каким-то образом тянет 100 задач, которые приостанавливаются вскоре после выполнения, а остальные три потока просто тянут задачи, которые никогда не приостанавливаются. После того, как пул задач будет исчерпан, остальные три потока могут быть завершены позднее. Однако, поскольку 100 задач уже запланированы для потока 1, и если система не разрешает выполнение межпоточного волокна, нам придется дождаться, пока поток 1 завершит выполнение всех 100 задач, которые необходимо выполнить, пока другие потоки ждут на холостом ходу.
В идеальном мире, с точки зрения производительности, мы должны рассмотреть возможность использования перекрестного волокна. Это, безусловно, означало бы, что мы берем на себя гораздо больше ответственности, чем наоборот.
Будьте бдительны в отношении оптимизации компилятора
Оптимизация компилятора всегда была нашим лучшим другом. Он оптимизирует код за нас, при этом мы не делаем ничего низкого уровня. Однако в такой волоконной среде, где мы взламываем регистры низкого уровня, все может пойти совсем не так, если мы не будем достаточно осторожны.
В качестве конкретного примера мы только что кратко упомянули, что до тех пор, пока шаблон доступа к памяти TLS не пересекает переключатель волокна, все должно быть в порядке. На самом деле это оказывается проблематичным из-за низкоуровневой оптимизации компилятора, позволяющей компилятору оптимизировать доступ к памяти TLS с кешем для повышения производительности. Чтобы прояснить ситуацию, давайте взглянем на следующий фрагмент кода.
thread_local int tls_data = 0;
void WINAPI FiberEntry(PVOID arg)
{
0x00B21010 push ebp
0x00B21011 mov ebp,esp
0x00B21013 push ecx
0x00B21014 push esi
0x00B21015 mov esi,dword ptr fs:[2Ch]
0x00B2101C push edi
0x00B2101D mov edi,dword ptr [__imp__SwitchToFiber@4 (0B23004h)]
0x00B21023 nop dword ptr [eax]
0x00B21027 nop word ptr [eax+eax]
while (true)
{
volatile int k = tls_data;
0x00B21030 mov eax,dword ptr [esi]
SwitchToFiber(thread_fiber);
0x00B21032 push dword ptr [thread_fiber (0x0B253F4h)]
0x00B21038 mov eax,dword ptr [eax+4]
0x00B2103E mov dword ptr [k],eax
0x00B21041 call edi
}
0x00B21043 jmp FiberEntry+20h (0x0B21030h)
}Выше представлено смешанное представление кода C++ и ассемблера для лучшей наглядности. Я намеренно помечаю временную переменнуюkкак изменчивую, чтобы компилятор не оптимизировал ее, поскольку она нигде не читается.
В этом коде скрыта очень тонкая ошибка. Мы можем заметить, что значение временной переменной kустанавливается из регистра eaxв строке 20. А значение eaxпоступает из esiинструкции в строке 16. Однако значение esiзагружается до того, как программа входит в цикл. Таким образом, компилятор пытается быть умным, предполагая, что цикл кода всегда будет выполняться в одном и том же потоке, чтобы он мог кэшировать выборку памяти через строку 8. В большинстве случаев это неплохое предположение. Однако мы знаем, что существует реальный риск того, что итерации цикла могут выполняться в разных потоках. И эта оптимизация приведет к тому, что программа будет читать TLS неправильного потока, что легко приведет к сбою.
В Windows существует специальный флаг /GT , позволяющий избежать такой недружественной оптимизации волокна. Однако на некоторых других платформах такого флага нет. В этом случае мы можем предотвратить умную работу компилятора, изолировав доступ к TLS внутри невстроенной функции. Распространенный подход заключается в определении метода доступа в другой единице компиляции. Как упоминалось ранее, нам все еще нужно быть осторожными с оптимизацией времени компоновки компиляторов, чтобы снова встроить ее.
Переходим к FiberSwitch
Помимо функциональности, почти столь же важна возможность отладки.
В отличие от потоков, подвешенные волокна практически невидимы для отладчиков. Например, если мы приостановим функцию в волокне, даже если у нас есть другие приостановленные волокна, стек параллельных вызовов Visual Studio не будет видеть приостановленные волокна. Это, безусловно, усложняет отладку в некоторых случаях, особенно когда она связана с проблемами синхронизации. Я лично обнаружил, что печать журнала — это реальный вариант получить больше информации о подвешенных волокнах.
Еще одна деталь, на которую нам следует обратить внимание, — это возможность войти в вызов переключателя волокна. Большую часть времени нас не волнует детальная реализация, но наша суть в том, что мы должны иметь возможность пройти через этот вызов, чтобы перейти на другую сторону переключателя волокна, к целевому коду волокна. GDB и LLDB очень хорошо подходят для этой цели, поскольку реализация волокна осуществляется с помощью ассемблерного кода. Однако в Visual Studio есть флаг, который оказывает большое влияние на поведение при подключении к переключателю волокна. Этот флаг можно найти с помощью следующей настройки: Project Property Page-> Configuration Properties-> Advanced-> Advanced Properties->Use Debug Library. Если мы хотим войти в функцию переключения волокна, как и в случае с другими обычными функциями, для этого параметра необходимо установить значение true. В противном случае отладчик просто переступит через него, не переходя на другую сторону переключателя волокна.
Избегайте блокирующих вызовов
Определенные операции, такие как чтение ввода-вывода, на некоторое время блокируют выполнение потока из-за ожидания. Когда происходит такая блокировка, операционная система обычно приостанавливает этот поток и назначает физическому ядру какой-либо другой поток для дальнейшего выполнения, чтобы использовать доступные аппаратные ядра.
Однако системы заданий на основе волокон обычно используют привязку потоков для фиксации потоков на физических ядрах. Количество потоков должно совпадать с количеством физически доступных ядер. Волокно — это наша новая концепция потоков пользовательского режима, которая позволяет переключать задачи намного быстрее. Мы должны быть предельно осторожны, чтобы избежать блокировки вызовов в волокне, в том же приложении не будет другого потока, который ОС могла бы запланировать, чтобы заполнить пробел во время ожидания ввода-вывода.
Однако мы не можем избежать вызовов ввода-вывода в игре. Решением в игровом движке является выделение фоновых потоков, предназначенных для таких вызовов. И чтобы избежать этого, выполняйте блокирующие вызовы только в этих потоках, а не в каких-либо волокнах.
Резюме
Подводя итог, мы много упомянули о волокнах в этом посте. Начиная с самых основ архитектуры ЦП и затем подробной реализации волокон, вплоть до их проблем.
Как мы видим, волокна обеспечивают большую гибкость, которая обычно недоступна другим методам, поэтому игровые студии предпочитают его, стремясь к повышению производительности. Конечно, возможности волокон явно не ограничиваются только разработкой игр. Его можно использовать практически во всех программах, требующих больших вычислительных ресурсов ЦП, которые заботятся о производительности.
Ссылки
Создание системы заданий на основе сопрограммы без стандартной библиотеки
Распараллеливание движка Naughty Dog с использованием волокон
Современное программирование на языке ассемблера x86
Приложение System V. Двоичный интерфейс. Дополнение к процессору с архитектурой AMD64.
Программирование на 64-битном языке ассемблера Arm
Комментарии (23)

DmitryShm
24.09.2023 19:50+1В статье ссылки на строки в коде, но листинги без номеров. Наверное для того, чтобы пост был кратким. :)

XRSD
24.09.2023 19:50+2При таком дизайне каждая задача будет нести больше ответственности, как будто они не передают контроль другим, другие вообще не будут иметь никакого контроля.
Скорее всего, в оригинале было «as if», которое в этом контексте должно переводиться «так как, если», а не «как будто»:
При таком дизайне каждая задача будет нести больше ответственности, так как, если они не передадут контроль другим, другие вообще не будут иметь никакого контроля.

bak
24.09.2023 19:50+8Они используются для упряжки многоядерной мощности, обеспечиваемой процессорами.
Однако это не дешево, так как требует поездки в ядро.
Если они находятся в пределах допуска, то то, что еще больше подтолкнуло
некоторые игровые студии к переходу к более эффективному проектированию
системы, — это проблемный случайДействительно проблемный случай

codecity
24.09.2023 19:50На самом деле такая реализация необходима на MacOS, поскольку на момент написания этой статьи ОС не предлагает интерфейсов для управления волокнами.
А реализация boost не работает что ли? Или почему пришлось писать свое?

unreal_undead2
24.09.2023 19:50+2В этой публикации реализация волокон на x64 построена на основе System V ABI
Казалось бы, тогда и getcontext/setcontext из System V можно запользовать. Или предполагается, что у нас своя ОС, которая позаимствовала только ABI?

bel1k0v Автор
24.09.2023 19:50Рискну предположить, что из-за примечаний о совместимости. Автор хотел показать простейший вариант реализации, "на пальцах".
unreal_undead2
24.09.2023 19:50Да, почитал повнимательнее, оно упомянуто
В MacOS действительно существовал интерфейс
ucontext. Однако он был признан устаревшим. Использование такого интерфейса было бы рискованным в будущем. В Linux мы действительно можем использовать его для достижения того же самого.От Apple, конечно, всего можно ожидать, но выкидывать не такие уж нишевые функции - это чересчур...


erley
24.09.2023 19:50+1Благодарю за подробный разбор и систематизацию, такой материал однозначно должен быть в закладках


Pitkin_zadov
24.09.2023 19:50+1Из кучи комментариев 99% - это "фи, ты не умеешь переводить". Но написано то нормально, чё придираться то, токсики :).

Mingun
24.09.2023 19:50-1Гм. У меня сомнения, что вы вообще читали статью. Оригинал может и написан нормально, но вот перевод — ниже плинтуса. Если в первых абзацах еще какое-то подобие вычитки вроде как есть, то ближе к концу автор вообще забил на это.

orefkov
24.09.2023 19:50Не раскрыта тема исключений C++ в волокнах - есть ли там какие-то подводные камни? Скорее всего в игровом движке они просто не используют исключения.
Keeper9
Статью Гугл переводил?
bel1k0v Автор
Было бы здорово, если бы целый гугл на меня работал для перевода, но увы не могу себе такого позволить. А вот их переводчик помогает иногда, никак не отменяя того, что всё приходится по 2 раза перечитывать и всё-равно будут ошибки ;)
Xadok
Для некоторых терминов намного лучше подходят англицизмы. Гугл переводчик этого знать не может :)
bel1k0v Автор
Есть такой момент, стараюсь выбирать в пользу русских аналогов, по возможности.
unreal_undead2
Но "оптоволокно" - никак не аналог fiber в контексте конкурентного программирования.
bel1k0v Автор
Спасибо, думал всё выпилил, а нет, это был последний.
Mingun
А вызывающие абоненты вас не смущают?