
 У меня есть подборка простеньких вопросов, которые я люблю задавать при собеседовании. Например, как посчитать общее число записей к таблице? Вроде бы ничего сложного, но если копнуть глубже, то можно много интересных нюансов рассказать собеседнику.
У меня есть подборка простеньких вопросов, которые я люблю задавать при собеседовании. Например, как посчитать общее число записей к таблице? Вроде бы ничего сложного, но если копнуть глубже, то можно много интересных нюансов рассказать собеседнику.Давайте начнем с простого… Эти запросы отличаются чем-то друг от друга с точки зрения конечного результата?
SELECT COUNT(*) FROM Sales.SalesOrderDetail
SELECT COUNT_BIG(*) FROM Sales.SalesOrderDetail
Большинство отвечали: «Нет».
Реже старались долее детально формировать ответ: «Запросы вернут идентичный результат, но COUNT вернет значение типа INT, а COUNT_BIG – тип BIGINT».
Если проанализировать план выполнения, то можно заметить различия, которые многие упускают из вида. При использовании COUNT на плане будет операция Compute Scalar:

Если посмотреть в свойства оператора, то мы увидим там:
[Expr1003] = Scalar Operator(CONVERT_IMPLICIT(int,[Expr1004],0))
Это происходит потому, что при вызове COUNT неявно используется COUNT_BIG после чего результат преобразуется в INT.
Не сказал бы, что существенно, но преобразования типов увеличивает нагрузку на процессор. Многие, конечно, могут сказать, что этот оператор ничего не стоит при выполнении, но нужно отметить простой факт – SQL Server очень часто недооценивает Compute Scalar операторы.
Еще я знаю людей, которые любят использовать SUM вместо COUNT:
SELECT SUM(1) FROM Sales.SalesOrderDetail
Такой вариант примерно равнозначен COUNT. Мы также получим лишний Compute Scalar на плане выполнения:
[Expr1003] = Scalar Operator(CASE WHEN [Expr1004]=(0) THEN NULL ELSE [Expr1005] END)
Теперь более детально затронем вопросы производительности.…
Если использовать запросы выше, то чтобы посчитать количество записей SQL Server необходимо выполнить Full Index Scan (или Full Table Scan если таблица является кучей). В любом случае, эти операции далеко не самые быстрые. Лучше всего для получения количества записей использовать системные представления: sys.dm_db_partition_stats или sys.partitions (есть еще sysindexes, но оставлен для обратной совместимости с SQL Server 2000).
USE AdventureWorks2012
GO
SET STATISTICS IO ON
SET STATISTICS TIME ON
GO
SELECT COUNT_BIG(*)
FROM Sales.SalesOrderDetail
SELECT SUM(p.[rows])
FROM sys.partitions p
WHERE p.[object_id] = OBJECT_ID('Sales.SalesOrderDetail')
AND p.index_id < 2
SELECT SUM(s.row_count)
FROM sys.dm_db_partition_stats s
WHERE s.[object_id] = OBJECT_ID('Sales.SalesOrderDetail')
AND s.index_id < 2
Если сравнить планы выполнения, то доступ к системным представлениям менее затратный:

На AdventureWorks преимущество от применения системных представлений явно не проявляется:
Table 'SalesOrderDetail'. Scan count 1, logical reads 276, ...
SQL Server Execution Times:
CPU time = 12 ms, elapsed time = 26 ms.
Table 'sysrowsets'. Scan count 1, logical reads 5, ...
SQL Server Execution Times:
CPU time = 4 ms, elapsed time = 4 ms.
Table 'sysidxstats'. Scan count 1, logical reads 2, ...
SQL Server Execution Times:
CPU time = 2 ms, elapsed time = 1 ms.
Время выполнения на секционированной таблице с 30 миллионами записей:
Table 'big_test'. Scan count 6, logical reads 114911, ...
SQL Server Execution Times:
CPU time = 4859 ms, elapsed time = 5079 ms.
Table 'sysrowsets'. Scan count 1, logical reads 25, ...
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 2 ms.
Table 'sysidxstats'. Scan count 1, logical reads 2, ...
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 2 ms.
В случае если нужно проверить наличие записей в таблице, то использование метаданных как было показано выше не даст особых преимуществ…
IF EXISTS(SELECT * FROM Sales.SalesOrderDetail)
PRINT 1
IF EXISTS(
SELECT * FROM sys.dm_db_partition_stats
WHERE [object_id] = OBJECT_ID('Sales.SalesOrderDetail')
AND row_count > 0
) PRINT 1
Table 'SalesOrderDetail'. Scan count 1, logical reads 2,...
SQL Server Execution Times:
CPU time = 1 ms, elapsed time = 3 ms.
Table 'sysidxstats'. Scan count 1, logical reads 2,...
SQL Server Execution Times:
CPU time = 4 ms, elapsed time = 5 ms.
И на практике будет даже капельку медленнее, поскольку SQL Server генерирует более сложный план выполнения для выборки из метаданных.

Еще интереснее становиться, когда нужно посчитать количество записей по всем таблицам сразу. На практике встречал несколько вариантов, которые можно обобщить.
Вариант #1 с применением недокументированной процедуры, которая курсором обходит все пользовательские таблицы:
IF OBJECT_ID('tempdb.dbo.#temp') IS NOT NULL
DROP TABLE #temp
GO
CREATE TABLE #temp (obj SYSNAME, row_count BIGINT)
GO
EXEC sys.sp_MSForEachTable @command1 = 'INSERT #temp SELECT ''?'', COUNT_BIG(*) FROM ?'
SELECT *
FROM #temp
ORDER BY row_count DESC
Вариант #2 – динамический SQL которые генерирует запросы SELECT COUNT(*):
DECLARE @SQL NVARCHAR(MAX)
SELECT @SQL = STUFF((
SELECT 'UNION ALL SELECT ''' + SCHEMA_NAME(o.[schema_id]) + '.' + o.name + ''', COUNT_BIG(*)
FROM [' + SCHEMA_NAME(o.[schema_id]) + '].[' + o.name + ']'
FROM sys.objects o
WHERE o.[type] = 'U'
AND o.is_ms_shipped = 0
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 10, '') + ' ORDER BY 2 DESC'
PRINT @SQL
EXEC sys.sp_executesql @SQL
Вариант #3 – быстрый вариант на каждый день:
SELECT SCHEMA_NAME(o.[schema_id]), o.name, t.row_count
FROM sys.objects o
JOIN (
SELECT p.[object_id], row_count = SUM(p.row_count)
FROM sys.dm_db_partition_stats p
WHERE p.index_id < 2
GROUP BY p.[object_id]
) t ON t.[object_id] = o.[object_id]
WHERE o.[type] = 'U'
AND o.is_ms_shipped = 0
ORDER BY t.row_count DESC
Уж очень много я выдал дифирамбов, что системные представления такие хорошие. Однако, при работе с ними нас могут подстерегать «приятные» неожиданности.
Помнится, был такой веселый баг, когда при миграции с SQL Server 2000 на 2005 некоторые системные представления некорректно обновлялись. Особо везучим людям, в таком случае, из метаданных возвращались неверные значения о количестве записей в таблицах. Лечилось это все командой DBCC UPDATEUSAGE.
Вместе с SQL Server 2005 SP1 этот баг исправили и все бы ничего… Но подобную ситуацию я наблюдал еще один раз, когда восстановил бекап с SQL Server 2005 SP4 на SQL Server 2012 SP2. Воспроизвести проблему на реальном окружении увы не смогу, поэтому немного обманув оптимизатор:
UPDATE STATISTICS Person.Person WITH ROWCOUNT = 1000000000000000000
расскажу на простом примере.
Самый безобидный запрос начал выполняться дольше чем обычно:
SELECT FirstName, COUNT(*)
FROM Person.Person
GROUP BY FirstName
Посмотрел на план запроса и увидел там явно неадекватное значение Estimated number of rows:
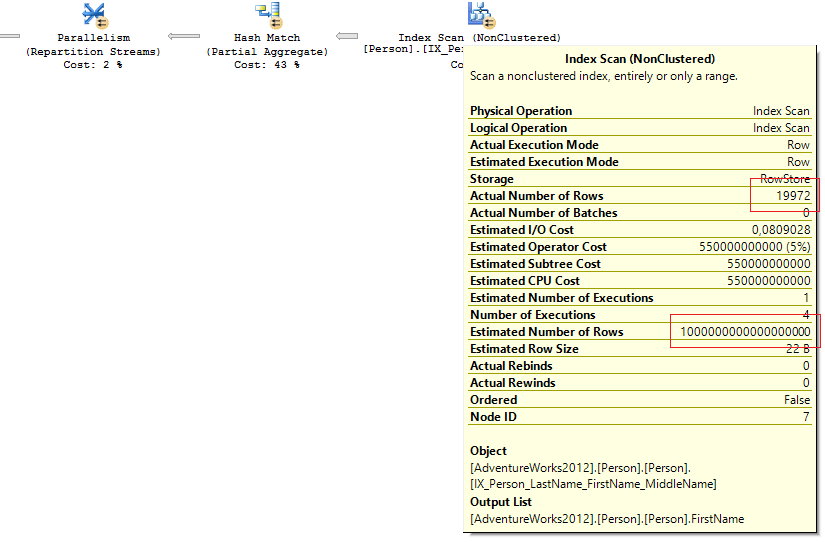
Заглянул в статистику по кластерному индексу:
DECLARE @SQL NVARCHAR(MAX)
DECLARE @obj SYSNAME = 'Person.Person'
SELECT @SQL = 'DBCC SHOW_STATISTICS(''' + @obj + ''', ' + name + ') WITH STAT_HEADER'
FROM sys.stats
WHERE [object_id] = OBJECT_ID(@obj)
AND stats_id < 2
EXEC sys.sp_executesql @SQL
Все было в норме:

Но в системных представления о которых мы говорили ранее:
SELECT rowcnt
FROM sys.sysindexes
WHERE id = OBJECT_ID('Person.Person')
AND indid < 2
SELECT SUM([rows])
FROM sys.partitions p
WHERE p.[object_id] = OBJECT_ID('Person.Person')
AND p.index_id < 2
была печаль:

В запросе не было предикатов для фильтрации и оптимизатор выбрал Full Index Scan. При Full Index/Table Scan ожидаемое количество строк оптимизатор не берет из статистики, а обращается к метаданным (точно не уверен всегда ли это происходит).
Не секрет, что на основе Estimated number of rows SQL Server генерирует план выполнения и вычисляет сколько нужно памяти чтобы его выполнить. Если оценка будет неверной, то может быть выделено больше памяти на выполнение запроса, чем нужно на самом деле.
SELECT session_id, query_cost, requested_memory_kb, granted_memory_kb, required_memory_kb, used_memory_kb
FROM sys.dm_exec_query_memory_grants
Вот к чему приводит неверная оценка количества строк:
session_id query_cost requested_memory_kb granted_memory_kb required_memory_kb used_memory_kb
---------- ---------------- -------------------- -------------------- -------------------- --------------------
56 11331568390567 769552 769552 6504 6026
Проблема решилась достаточно просто:
DBCC UPDATEUSAGE(AdventureWorks2012, 'Person.Person') WITH COUNT_ROWS
DBCC FREEPROCCACHE
После рекомпиляции запроса все пришло в норму:
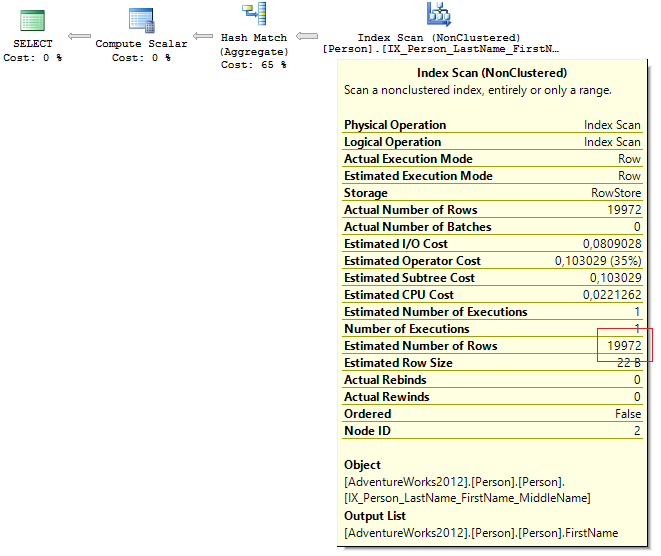
session_id query_cost requested_memory_kb granted_memory_kb required_memory_kb used_memory_kb
---------- ------------------- -------------------- -------------------- -------------------- --------------------
52 0,291925808638711 1168 1168 1024 952
Если системные представления уже не кажутся «спасительной палочкой», то какие варианты у нас остаются? Можно делать все по-старинке:
SELECT COUNT_BIG(*) FROM ...
Но при интенсивной вставке в таблицу я бы не доверял результатам. «Волшебный» хинт NOLOCK тем более не гарантирует правильного значения:
SELECT COUNT_BIG(*) FROM ... WITH(NOLOCK)
По сути, чтобы получить правильное значение количества строк в таблице, нужно выполнять запрос под уровнем изоляции SERIALIZABLE либо используя хинт TABLOCKX:
SELECT COUNT_BIG(*) FROM ... WITH(TABLOCKX)
И что мы получаем в итоге… монопольную блокировку таблицы на период выполнении запроса. И тут каждый должен решать сам, что ему лучше использовать. Мой выбор — метаданные.
Еще интереснее, когда нужно быстро подсчитать число строк по условию:
SELECT City, COUNT_BIG(*)
FROM Person.[Address]
--WHERE City = N'London'
GROUP BY City
Если в таблице не происходят частые операции вставки-удаления, то можно создать индексированное представление:
IF OBJECT_ID('dbo.CityAddress', 'V') IS NOT NULL
DROP VIEW dbo.CityAddress
GO
CREATE VIEW dbo.CityAddress
WITH SCHEMABINDING
AS
SELECT City, [Rows] = COUNT_BIG(*)
FROM Person.[Address]
GROUP BY City
GO
CREATE UNIQUE CLUSTERED INDEX IX ON dbo.CityAddress (City)
Для этих запросов оптимизатор будет генерировать идентичный план на основе кластерного индекса вьюхи:
SELECT City, COUNT_BIG(*)
FROM Person.[Address]
WHERE City = N'London'
GROUP BY City
SELECT *
FROM dbo.CityAddress
WHERE City = N'London'
План выполнения с индексным представлением и без:
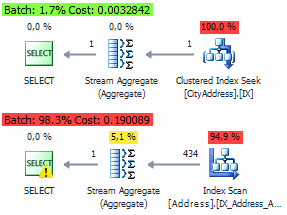
Этим постом я хотел показать, что идеальных решений на все случаи жизни не бывает. И в каждом конкретной ситуации нужно действовать с индивидуальным подходом.
Все тестировалось на SQL Server 2012 SP3 (11.00.6020).
Планы выполнения брал из SSMS 2014 и dbForge.
В качестве выводов… Когда нужно подсчитать общее число строк по таблице, то я использую метаданные — это самый быстрый способ. И пусть Вас не пугает ситуация с старым багом, который я привел выше.
Если нужно быстро подсчитать количество строк в разрезе какого-то поля или по условию — то я стараюсь использовать индексированные представления либо фильтрованные индексы. Все зависит от ситуации.
Когда таблица маленькая или вопросы с производительностью не стоят так остро, то проще уж действительно по-старинке написать SELECT COUNT(*)…
Надеюсь всем было интересно :)
Комментарии (74)

zuborg
26.11.2015 20:26-6Удивлен, что всеми везде используется COUNT(*), хотя COUNT(1) дешевле (а зачастую и корректнее).

AlanDenton
26.11.2015 20:35+9Оптимизатор для этих запросов генерирует идентичный план выполнения:
SELECT COUNT_BIG(*) FROM t1 SELECT COUNT_BIG(1) FROM t1
Если сравнить планы, то разница только в * и 1:
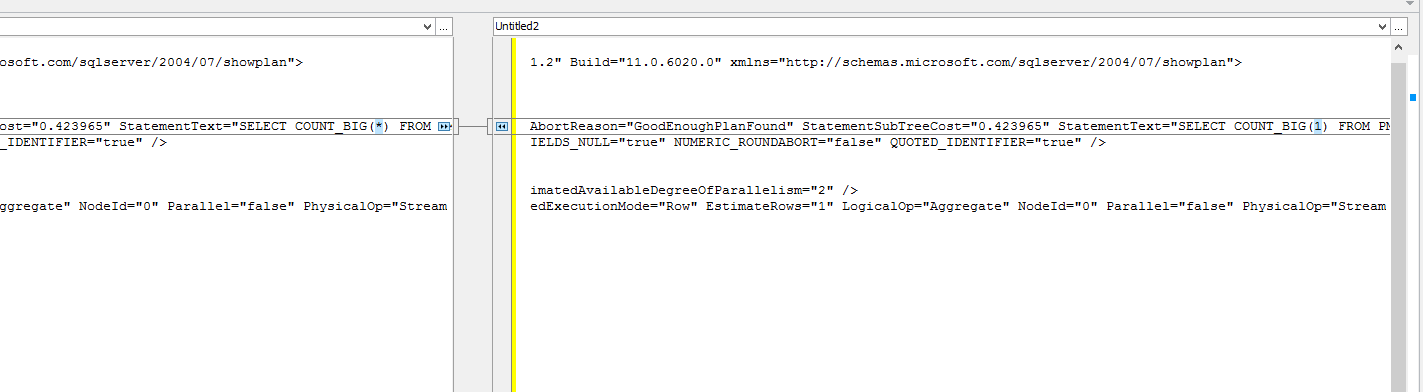
Table 't1'. Scan count 6, logical reads 114911, physical reads 0, .... SQL Server Execution Times: CPU time = 2673 ms, elapsed time = 1787 ms. Table 't1'. Scan count 6, logical reads 114911, physical reads 0, .... SQL Server Execution Times: CPU time = 2625 ms, elapsed time = 1878 ms.zuborg
26.11.2015 20:42-5Конкретно на этой таблице да. Но семантика этих запросов, согласно стандартам SQL — разная.
AlanDenton
26.11.2015 20:47+1Приведите, пожалуйста, пример.
Разница между 1 и * была еще во времена SQL Server 2000. Точно могу сказать, что с 2005 планы генерируются одинаково. Если планы одинаковые, то и выполнение будет одинаковым (в рамках погрешности и при условии, что ресурсы сервера ничем другим в это время не нагружены). Единственное что может отличаться, время компиляции.zuborg
26.11.2015 21:09+1Да, верно, сейчас это одно и то же. Когда я впервые изучал sql, были различия, из которых я вынес что COUNT(1) предпочтительней.
AlanDenton
26.11.2015 21:14+1WHERE EXISTS(SELECT * FROM ...)
в такой конструкции тоже раньше советовали использовать константу. Даже Ицик Бен-Ган об этом в книжке своей писал :)
BalinTomsk
27.11.2015 19:00+1Это потому что если procedure/function/view захочется сделать WITH SCHEMABINDING то звездочку не пропустит парсер

aalebedev
26.11.2015 21:47+11Люблю в конце подведение итогов в таблицу:
1) как правильно посчитать количество строк
2) как правильно проверить наличие данных
Тема интересная, но вывода нет, это плохо.
90% не нужны промежуточные результаты, им нужны best practices.AlanDenton
26.11.2015 22:27+2Такого плана комментарии мне по душе. Спасибо. Завтра утром выводы добавлю.

shai_hulud
26.11.2015 23:24+8«Многие, конечно, могут сказать, что этот оператор ничего не стоит при выполнении, но нужно отметить простой факт – SQL Server очень часто недооценивает Compute Scalar операторы.»
Скажу, и скажу что весь пример высосан из пальца. Операция результирующего усечения Int64 до Int32 не просто дешевая, она почти бесплатная.AlanDenton
26.11.2015 23:30+1Фраза относилась к оператору Computed Scalar в целом, а не к усечению. Общепризнанные факт, что данный оператор по стоимости на плане практически всегда нулевой или близкий к нему. А по факту может существенно снижать производительность.

defuz
27.11.2015 01:16+6Вы не могли бы аргументировать вашу точку зрения?
AlanDenton
27.11.2015 12:32Я подумаю по поводу репро для на выходных. К слову будет сказано… SQL Server как правило недооценивает Computed Scalar, и в тоже время переоценивает XML операторы…

Insspb
26.11.2015 23:43+18Тут у меня возникает только один вопрос (Я системный администратор, не проектировщик/разработчик БД, но опыт разбора планов запросов имею, да и Microsoft SQL Server 2014 Query Tuning & Optimization читал и очень вдохновился, ну и скули разные видел :D).
Так вопрос вот в чём. Какого ответа вы ждёте на собеседовании, если это вопрос для него? Разработчик должен помнить план запроса на память? Или просто представлять, что существует несколько техник выполнения одной операции? (Практически всегда).
Ведь любой план запроса проектируется под конкретную БД, конкретной системой, в зависимости от кучи факторов: размеров таблиц, уровня параллелизма, информации в статистике и т.д. и т.п.AlanDenton
26.11.2015 23:49-9Хороший вопрос. Если честно, то ответа я не жду. У меня свое видение процесса собеседования. Просто задвавать вопросы быстро наскучивает. Гораздо интереснее начать с простого и понятного вопроса и на основе него построить беседу. Многие из тех кого я побеседовал приходили проверить свой уровень, а не устраиваться на работу. Такие моменты быстро можно уловить и тогда остается просто поговорить о чем-то интересном. Опытом обменяться…
AlanDenton
27.11.2015 00:00Между прочим и меня часто ловили на всякой ереси :) не всегда же можно все держать в голове на собеседовании. Люди же подсознательно всегда волнуются. А так начал с простого и диалог сам собой начинается.

Labutin
27.11.2015 07:19+15Подобные вопросы на собеседованиях нужно задавать в двух случаях:
1. Если кандидату на вакансию после трудоустройства нужно будет каждый день отвечать на подобные вопросы (это скорее всего DBA, а не программист или админ)
2. Если вы хотите на собеседовании показать свое превосходство в знаниях перед кандидатом.
Если хотите завязать беседу этим вопросом, то дайте кандидату демонстрационный стенд и посмотрите, как он будет сам смотреть планы запросов и проводить тесты. Или заглянет в документацию. Вы не ждете, что во время штатного рабочего процесса, когда возникает подобный вопрос, то ваш сотрудник убирает руки от клавиатуры и как на собеседовании прямо из головы выдает версии и ответы?AlanDenton
27.11.2015 11:09+1Надеюсь у Вас не сложилось мнение, что я люблю «доминировать» на собеседовании. :) Это далеко не так… Ничего сложного я никогда не спрашивал. Лишь то что нужно для работы. И такие вот моменты что были в этом посте… я их не спрашивал, а рассказывал… потому что с людьми было приятно поделиться опытом. Точно также они и мне рассказывали вещи, которые я не знал.
Теперь по поводу простых вопросов… Многие даже не могут на такой вопрос ответить:
DECLARE @t TABLE (a INT) INSERT INTO @t (a) VALUES (1), (2), (3), (NULL) SELECT AVG(a), COUNT(*), COUNT(a) FROM @t
Одного он вообще повергнул в шок… И мы вместе сидели и разбирались. Почему AVG вернет — 3, а не 1.5 и тд…
Alexeyslav
27.11.2015 11:31Я в смятении… на Informix синтаксис несколько другой видимо…
Но результат выдало 2, 4, 3.
Почему среднее значение должно быть 3?AlanDenton
27.11.2015 11:59Опечатался… Сорри :)
Оптимизатор раскладывает AVG(a) на операции SUM(a) / COUNT(a)
COUNT(a) подсчитывает значения, которые не NULL. Поэтому и получается результат, который привел BelAnt.
и тут еще был нюанс. Раз столбец INT, то и результат операции AVG будет целочисленным. Например, в такой ситуации среднее значение вернется не совсем такое как ожидается:
SELECT AVG(a) FROM (VALUES(1), (2)) t(a)
Т.е. мы ожидаем 1.5, а будет 1… :)

BelAnt
27.11.2015 11:40+1AVG вернет 2
(1 + 2 + 3) / 3 = 2
COUNT(a) вернет 3AlanDenton
27.11.2015 11:50

bay73
28.11.2015 18:19Интересно, а как понять простой вопрос или нет.
Я вот за много лет работы с sql ни разу не использовал функцию AVG — вот не было таких задач, где она нужна. Да и COUNT(a) я не использовал и постараюсь не использовать именно из-за его семантической неоднозначности — код должен не только выполняться правильно, но еще и легко читаться.
Поэтому ответить на ваш «простой вопрос» я могу только из-за того, что это — самый любимый вопрос на собеседованиях, а отнюдь не из-за опыта работы или хорошего знания. Соответственно и выявляет этот простой вопрос не тех, кто имеет работать, а тех, кто умеет готовиться к собеседованиям.
AlanDenton
27.11.2015 11:13По поводу такого количества минусов, я немного удивлен. Неужели всем интересно приходить на собеседование и отвечать на вопросы с листочка? Это конвейер чистой воды… :)

NYBR
28.11.2015 21:35-2просто придя на собеседование ожидаешь разговора по специальности. Какие задачи вы решали, как именно решали и тд. А если внезапно тебя просят ВСПОМНИТЬ какую то фигню, которая конечно где то преподовалась, но смысла держать ее в голове особо нету, но человек проводящий интервью выглядит мудаком, извините.
Особенно актуально это сейчас, когда за ответом на правильно поставленный вопрос даже не стоит лезть в msdn, значительно быстрее и проще он найдется в гугле. Проверять нужно умеет ли человек задавать правильные вопросы гуглу, а не может ли он вспомнить что то из основ.

ComodoHacker
27.11.2015 00:53+2В случае если нужно проверить наличие записей в таблице, то использование метаданных как было показано выше не даст особых преимуществ…
А как насчет случая, когда в таблице было много данных, а потом их удалили оператором DELETE?AlanDenton
27.11.2015 10:55+1При выполнении разница будет только во времени компиляции запроса.
IF OBJECT_ID('dbo.test', 'U') IS NOT NULL DROP TABLE dbo.test GO ;WITH E1(N) AS ( SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 ) , E2(N) AS (SELECT 1 FROM E1 a, E1 b) , E4(N) AS (SELECT 1 FROM E2 a, E2 b) , E8(N) AS (SELECT 1 FROM E4 a, E4 b) SELECT val = 1 INTO dbo.test FROM E8 IF EXISTS(SELECT * FROM dbo.test) PRINT 1 IF EXISTS( SELECT * FROM sys.dm_db_partition_stats WHERE [object_id] = OBJECT_ID('dbo.test') AND row_count > 0 AND index_id < 2 ) PRINT 1 TRUNCATE TABLE dbo.test --DELETE TOP(50) PERCENT FROM dbo.test IF EXISTS(SELECT * FROM dbo.test) PRINT 1 IF EXISTS( SELECT * FROM sys.dm_db_partition_stats WHERE [object_id] = OBJECT_ID('dbo.test') AND row_count > 0 AND index_id < 2 ) PRINT 1
План будет одинаковый:
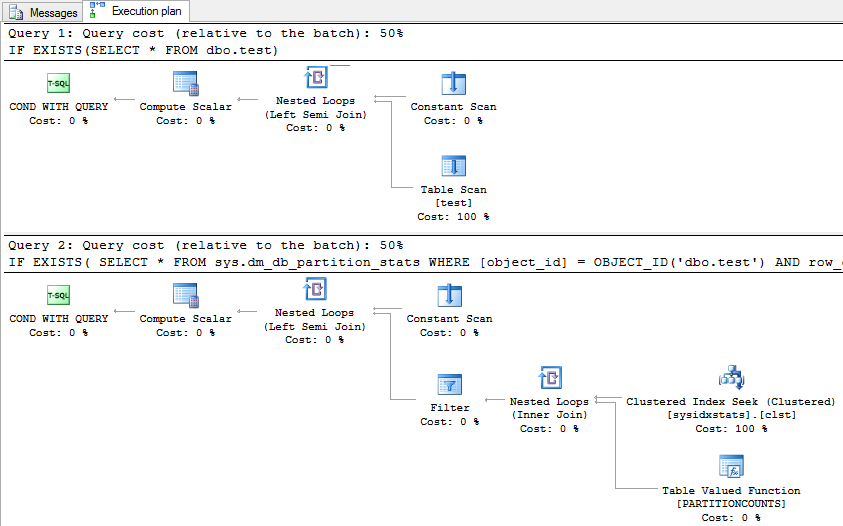
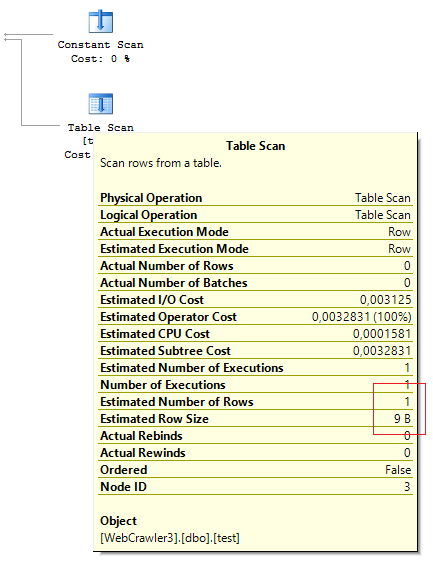
Estimated Number of Rows тоже будет идентичным в обоих случаях. А вот количество Actual Number of Rows будет различаться (когда данные есть в таблице и когда их нет, что вполне логично).
ComodoHacker
27.11.2015 12:16Исходный вопрос был не про планы, а про то, что «использование метаданных как было показано выше не даст особых преимуществ».
И ыы что, притворяетесь, что не видите разницу между TRUNCATE и DELETE?AlanDenton
27.11.2015 12:22-1«использование метаданных как было показано выше не даст особых преимуществ» эта фраза была в контексте чего приведена?.. Когда нужно проверить есть ли записи в таблице — разницы нет, какой подход применять. Если надо узнать количество строк в таблице, то быстрее всего это можно получить из метаданных. Это данность бытия…
Разница между TRUNCATE и DELETE есть, но вопрос был не о них ранее. Или все же о них?ComodoHacker
27.11.2015 12:28Когда нужно проверить есть ли записи в таблице — разницы нет, какой подход применять.
Я хочу уточнить: в случае «когда в таблице было много данных, а потом их удалили оператором DELETE» тоже нет разницы?
Так понятно?AlanDenton
27.11.2015 12:37У нас сейчас начинается холивар… Мне что рассказать как работают операции DELETE и TRUNCATE? Про минимальное протоколирование и т.д… Приведите, пожалуйста, пример и расскажите людям что Вас интересует. Я честно, не понимаю сути того, что Вы от меня хотите услышать.
ComodoHacker
27.11.2015 12:43Поверьте, у меня нет никакого намерения начинать холивар. Мы обсуждаем техническую статью, и я прошу уточнить интересующий меня момент. Вы можете ответить на мой вопрос?
У меня с SQL Server опыта меньше, чем с другими СУБД. И в других СУБД (некоторых) разница есть и существенная. Поэтому я и интересуюсь, как обстоит дело здесь.AlanDenton
27.11.2015 13:01Предположим, что в таблице миллион записей. Мы пытаемся их удалить. Значение количества строк в метаданных не будет изменяться, до тех пор пока в журнале не зафиксируются изменения командой DELETE. Если мы пытаемся очистить таблицу с помощью TRUNCATE, то страницы на которых хранятся таблицы будут помечены как свободные для записи, будет сброшен счетчик числа строк в метаданных…
Надеюсь я смог ответить на Ваш вопрос.ComodoHacker
27.11.2015 13:22+1Нет. Меня сейчас не интересует процесс удаления. Предположим, записи удалили вчера или вообще неделю назад. Я просто хочу проверить наличие данных в таблице. Есть лм разница между двумя вашими способами с точки зрения:
а) точности;
б) производительности.
Да, еще я часто встречал такой способ «SELECT TOP 1 1 FROM Table», как насчет него?AlanDenton
27.11.2015 13:39а) если метаданные для таблицы содержат
б) разницы, как уже говорил ранее — нет. погрешность лишь во времени компиляции каждого конкретного запроса
Да, еще я часто встречал такой способ «SELECT TOP 1 1 FROM Table», как насчет него?
SELECT TOP 1 1 FROM Sales.SalesOrderDetail SELECT 1 WHERE EXISTS( SELECT * FROM Sales.SalesOrderDetail )
SQL Server считает что с TOP(1) будет немного быстрее:
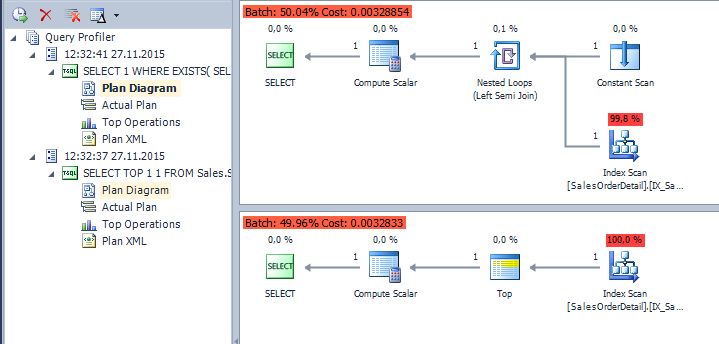
Время выполнения в рамках погрешности:
Table 'SalesOrderDetail'. Scan count 1, logical reads 2, physical reads 0, ... SQL Server Execution Times: CPU time = 5 ms, elapsed time = 5 ms. Table 'SalesOrderDetail'. Scan count 1, logical reads 2, physical reads 0, ... SQL Server Execution Times: CPU time = 4 ms, elapsed time = 6 ms.
План сравнивал не в SSMS, а в dbForge, чтобы Вы увидели разницу в оценке батчей.ComodoHacker
27.11.2015 14:49+1а) если метаданные для таблицы содержат
Не понял, что если?AlanDenton
27.11.2015 14:56+1Прощу прощение, видимо часть фразы затер случайно и не заметил.
с точки зрения точности, наиболее корректное число строк можно получить при Full Scan. Но в зависимости от уровня изоляции, хинтов и т.д. понятие «корректное» уйдет на второй план. Например, когда используется хинт NOLOCK — это приводит к грязные чтениям.
По этой причине, я всегда стараюсь смотреть в метаданных эту информацию.
Еще раз спасибо, что обратили внимание на ошибку в ответе.
vlivyur
27.11.2015 17:46+2И быстрее обращения к системным таблицам. Но для задачи «а есть ли там вообще данные» select count(*) будет самым тормознутым, если данные там вдруг оказались.
AlanDenton
27.11.2015 17:49Спасибо за комментарий. Вспомнил еще один хороший пример «как не надо делать»:
IF (SELECT COUNT(*) FROM ...) > 0 BEGIN ... END
Видел примеры такого кода для проверки есть в таблице записи.
ComodoHacker
28.11.2015 20:09+1Мне стало интересно разобраться до конца. Оказалось, что разница в производительности все-таки есть. Причем она зависит от физической организации таблицы. Если таблица организована как куча, то когда мы удаляем строки оператором DELETE, в таблице остаются пустые страницы (в отличие от TRUNCATE). После этого при выполнении запроса, выбирающего хотя бы одну строку, придется просканировать все страницы, чтобы убедиться, что строк нет. В случае же с кластерным индексом пустые страницы, образующиеся при удалении строк, сразу освобождаются.
Эксперимент.
Создаем таблицу-кучу, без кластерного индекса.
use test_dev; go if object_id('T4', 'U') is not null drop table T4; create table T4 ( ID int , Data varchar(500) ); with V as ( select 1 as N union all select N+1 from V where N < 10000 ) insert into T4 (Data) select cast(replicate(ltrim(str(n)), 100) as varchar(500)) as data from V option (maxrecursion 0) ; (строк обработано: 10000)
Проверяем наличие строк разными способами, обращающимися к таблице. Проверку по представлению sys.dm_db_partition_stats я не включил, так как с ней все понятно, вы уже приводили ее результаты.
select 1 where exists (select * from T4); select top 1 1 from T4; if exists(select 1 from t4) print 1; ----------- 1 (строк обработано: 1) ----------- 1 (строк обработано: 1) 1
Посмотрим на статистику выполнения и заодно на количество страниц в таблице.
select cast(object_name(object_id) as varchar(20)) as object_name ,object_id ,used_page_count ,row_count from sys.dm_db_partition_stats t where object_id = object_id('T4') ; select cast(replace(substring(s2.text, statement_start_offset / 2+1 , ( (case when statement_end_offset = -1 then (len(convert(nvarchar(max),s2.text)) * 2) else statement_end_offset end) - statement_start_offset) / 2+1), char(13)+char(10), ' ') as varchar(50)) as sql_statement ,execution_count ,last_physical_reads ,last_logical_reads ,last_logical_writes ,last_elapsed_time from sys.dm_exec_query_stats as s1 cross apply sys.dm_exec_sql_text(sql_handle) as s2 where s2.objectid is null order by s1.sql_handle, s1.statement_start_offset, s1.statement_end_offset ;
object_name object_id used_page_count row_count -------------------- ----------- -------------------- -------------------- T4 741577680 514 10000 (строк обработано: 1) sql_statement execution_count last_physical_reads last_logical_reads last_logical_writes last_elapsed_time -------------------------------------------------- -------------------- -------------------- -------------------- -------------------- -------------------- select cast(object_name(object_id) as varchar(20 1 0 2 0 0 with V as ( select 1 as N union all select N+1 1 0 106953 505 204012 select 1 where exists (select * from T4); 1 0 5 0 0 select top 1 1 from T4; 1 0 5 0 0 if exists(select 1 from t4) 1 0 5 0 0 (строк обработано: 5)
Как видно, все три способа требуют 5 логических чтений при заполненной таблице, которая занимает 514 страниц.
Удаляем строки:
delete from T4; (строк обработано: 10000)
Снова проверяем наличие строк.
select 1 where exists (select * from T4); select top 1 1 from T4; if exists(select 1 from t4) print 1; ----------- (строк обработано: 0) ----------- (строк обработано: 0)
Смотрим статистику.
object_name object_id used_page_count row_count -------------------- ----------- -------------------- -------------------- T4 773577794 300 0 (строк обработано: 1) sql_statement execution_count last_physical_reads last_logical_reads last_logical_writes last_elapsed_time -------------------------------------------------- -------------------- -------------------- -------------------- -------------------- -------------------- select 1 where exists (select * from T4); 1 0 303 0 0 select top 1 1 from T4; 2 0 303 0 1001 if exists(select 1 from t4) 1 0 303 0 3001 delete from T4; 1 0 3048 129 121007
Таблица теперь занимает 300 страниц, и для проверки наличия строк пришлось просканировать их все.
Кстати интересно, почему 300. Видимо сработала какая-то внутренняя оптимизация при выполнении DELETE, освободившая часть страниц. Я пробовал удалять в цикле по 10 строк и по одной. В этом случае количество занятых страниц не уменьшается.
Эксперимент с кластерным индексом я не привожу. (Проверка наличия строк делает 2 лог. чтения, а всего в пустой таблице 4 страницы.)
Итак, вывод. В данном частном случае, когда таблица организована как куча и в ней происходят частые вставки и удаления, проверка наличия данных по системным представлениям дает существенное преимущество в производительности.
P.S. Под рукой у меня оказался только SQL 2005, в старших версиях возможно будут отличия.ComodoHacker
28.11.2015 20:10+1М-да, форматирование съезжает. Если скопировать в редактор, будет лучше видно.
AlanDenton
30.11.2015 11:11Большое спасибо за Ваш комментарий. Было очень интересно почитать и новые нюансы для себя узнать.
mayorovp
27.11.2015 08:45+4По сути, чтобы получить правильное значение количества строк в таблице, нужно выполнять запрос под уровнем изоляции SERIALIZABLE либо используя хинт TABLOCKX
Это смешно.
При интенсивных вставках-удалениях это самое «правильное значение» устареет очень быстро. Любой алгоритм, работающий с этим значением, должен вести себя так, будто его значение уже устарело — во избежание гонок. Но если оно уже устарело — зачем вообще бороться за его точность?AlanDenton
27.11.2015 10:32Никто не говорил, что нужно гоняться за точностью. Лично я всегда использую sys.partitions вместо COUNT(*) по таблице. Но знать о потенциальных проблемах с некорректными данными в системных представлениях нужно. Или хотя бы иметь представление куда копать в случае проблем подобного рода.
bay73
01.12.2015 17:31+1На мой взгляд, надо по возможности использовать count(*). А уж sys.partitions использовать только там, где это критично. Читабельность и сопровождаемость кода в большинстве случаев важнее, чем выигранные микросекунды. То есть использовать системные представления надо только для действительно больших таблиц в критичых местах.
Я правда плохо представляю случаи, когда бизнес-логика приложения реально зависит от числа строк в большой и нагруженной таблице. Обычно такие подсчеты нужны не для бизнес-логики, а для задач административного характера. Но тут опыт у всех разный.
BelAnt
27.11.2015 11:34А в чем практический смысл отслеживания количества записей по всем таблицам? По идее полезнее считать объем данных и темпы роста этого объема
В SSMS по правому клику на БД можно достаточно быстро сформировать отчет, который содержит как количество строк, так и объем данных по всем таблицам: Reports -> Standard Reports -> Disk Usage by TableAlanDenton
27.11.2015 11:44Этот отчет не настолько информативный, чтобы мне было ним удобно пользоваться. Я вот таким запросом смотрю то что мне нужно:
SELECT o.[object_id] , s.name + '.' + o.name , o.[type] , i.total_rows , total_space = CAST(i.total_pages * 8. / 1024 AS DECIMAL(18,2)) , used_space = CAST(i.used_pages * 8. / 1024 AS DECIMAL(18,2)) , unused_space = CAST((i.total_pages - i.used_pages) * 8. / 1024 AS DECIMAL(18,2)) , index_space = CAST(i.inx_pages * 8. / 1024 AS DECIMAL(18,2)) , data_space = CAST(data_pages * 8. / 1024 AS DECIMAL(18,2)) , is_heap , i.[partitions] , i.[indexes] FROM sys.objects o JOIN sys.schemas s ON o.[schema_id] = s.[schema_id] JOIN ( SELECT i.[object_id] , is_heap = MAX(CASE WHEN i.index_id = 0 THEN 1 ELSE 0 END) , total_pages = SUM(a.total_pages) , used_pages = SUM(a.used_pages) , inx_pages = SUM(a.used_pages - CASE WHEN a.[type] !=1 THEN a.used_pages WHEN p.index_id IN(0,1) THEN a.data_pages ELSE 0 END) , data_pages = SUM(CASE WHEN a.[type] != 1 THEN a.used_pages WHEN p.index_id IN (0,1) THEN a.data_pages END) , total_rows = SUM(CASE WHEN i.index_id IN (0, 1) AND a.[type] = 1 THEN p.[rows] END) , [partitions] = COUNT(DISTINCT p.partition_number) , [indexes] = COUNT(DISTINCT p.index_id) FROM sys.indexes i JOIN sys.partitions p ON i.[object_id] = p.[object_id] AND i.index_id = p.index_id JOIN sys.allocation_units a ON p.[partition_id] = a.container_id WHERE i.is_disabled = 0 AND i.is_hypothetical = 0 GROUP BY i.[object_id] ) i ON o.[object_id] = i.[object_id] WHERE o.[type] IN ('V', 'U') AND o.is_ms_shipped = 0 ORDER BY i.total_pages DESC

landy
27.11.2015 12:50Простите, но
всё(почти) вышесказанное относится исключительно к Microsoft SQL Server?!
Можно было упомянуть об этом в заголовке и/или начале статьи.AlanDenton
27.11.2015 12:54Только для SQL Server, поскольку с другими DBMS работал мало.
landy
27.11.2015 13:36Об этом и говорю.
Такой интригующий заголовок (смотрю через ленту), а по факту лично для меня ничего интересного :)AlanDenton
27.11.2015 13:59До редактирования статьи заголовок был менее пафосных… Зато народ привлек. Много мнений услышал. Кое-что новое для себя узнал. Кстати, за Ваш пост спасибо… альтернативу для Zabbix недавно искал.

burzzo
27.11.2015 13:13Я не работал с большими объёмами данных именно на Sql.
Вы смотрите количество строк в таблице с помощью ANSI и не ANSI версии декларативного языка sql.
Люди на собеседовании вам так говорят, потому что они получили знание или напрямую или опосредованно через книги, которые используют первоисточник: https://msdn.microsoft.com/en-us/library/ms190317.aspx
Попробуйте написать туда, если вы уверены что нашли что-то новое.
burzzo
27.11.2015 13:21-11. С моей точки зрения такое спрашивать на собеседовании не надо: «Не сказал бы, что существенно, но преобразования типов увеличивает нагрузку на процессор» Лучше спросите какие представления целых чисел со знаком и без знака люди знают или как представлено «действительное» число в компьютере. (Если вы сами не сильно плаваете здесь)
2. Программисты проходят в том или ином виде курс структуры данных (кеширование, списки, хешы, деревья, графы).
Тема дискуссионная, но основной перф мне кажется
1. использоваие правильных структур данных (e.g. хеш таблицы)
2. не вычисление того, что уже вычислено (e.g. кеширование)
3. то, что программисты пишут могло эволюционировать дальше (e.g. развитие)
4. возможность наращивать мощь программы (субд) за счёт поддержки новой аппаратуры (e.g. новые хосты)
Sql не позволяет их сильно вам влиять на все эти аспекты. В этом его прелесть и беда. Если вы считаете кол-во строк во всех таблицах, и так вышло что их 10^6 штук — то посмотрите метаинфу в субд если она есть, или пройдитесь по всем с помощью языка который поддерживает СУБД. Мне кажется это неправильный запрос в рамках данной модели вообще.AlanDenton
27.11.2015 13:26У меня есть подборка простеньких вопросов, которые я люблю задавать при собеседовании. Например, как посчитать общее число записей к таблице? Вроде бы ничего сложного, но если копнуть глубже, то можно много интересных нюансов рассказать собеседнику.
Повторюсь… Я такие тонкости не спрашиваю. Ключевое слово рассказать… Многие на работу приходят не только за деньгами, а но из за новыми знаниями. Если показать человеку, чему его могут здесь научить, то больше вероятность его положительного ответа на предложение о работе.burzzo
27.11.2015 13:47Это не тонкости, а обычные фундаментальные знания, на которые ответит любой студент средних курсов. И спрашивать надо это. Я уверен, что в моём окружении программистов нет людей, которые считают что count(1), count(*) содержат хоть какое-либо «знание». Вам нравится спрашивать это — спрашивайте.
Зачем люди приходят — там много начиная от социального желания человека работать, так и аспектов как деньги и знания…
«Его могут здесь научить» взаимная учёба здесь и вас тоже научит человек этот новому, если у него есть страсть к области. Главное уметь учиться, а вот вопрос про count это не показатель обучаемости,..., но!!! — Это по крайней мере повод для начала разговора)AlanDenton
27.11.2015 13:55Предположим человек приходит на должность SQL Server Database Developer. В резюме 3 года опыта работы с БД под SQL Server. Если он не может ответить на такой вопрос… какие результаты вернет запрос… даже после получаса наводящих вопросов, то поневоле стоит задуматься…
SELECT COUNT(1), COUNT(*), COUNT(val), COUNT(DISTINCT val) FROM ( VALUES (1), (1), (2), (NULL), (NULL) ) t (val)
А по поводу этого примера, так это конструкция языка, которой пользуются очень часто. Нужно понимать возможности того языка, который используешь.burzzo
27.11.2015 17:01-2Мне незнакомы конструкции когда в from стоит не имя таблицы, и не select-expression, но я и работать к вам идти не собираюсь.
Если вы девушку выбираете, посмотрите какие у ноги — красивые или нет. Я работ много поменял, и такие как вы мне встречались часто. Дело не в ногах, и не в count синтаксисе, а дело в страсти к области.
Вот как подходил к этой проблеме Леонардо Да Винчи (рассказывает Арнольд В.И.): https://www.youtube.com/watch?v=Fl33ryn9Xs8AlanDenton
27.11.2015 17:26К чему такая латентная агрессия...? Не пойму чем я Вас задел. «Такие как вы»… Это какие? :)
Теперь по существу. Ситуации номер раз. Приходит на работу джуниор, коим и я когда-то был. С него, что должен быть спрос много-чего знать? Нет. Только желание работать и развиваться.
Ситуация номер два. Приходит человек с «опытом» и просит соответствующий оклад. Мне про что с ним нужно говорить...? Про абстрактные основы институтской программы? Думаю, что нет. Нужно понять его уровень квалификации и готов ли он выполнять свою работу. А для этого нет необходимости пудрить серое вещество спрашивая про вещи, которые в повседневности не нужны. И тут мы возвращаемся к тому простому вопросу о котором было написано в самом начале.burzzo
27.11.2015 17:56+1У меня никакой аггрессии, если что)
Это какие?
Такие кто задают вопросы ответ на который можно получить открыв стандарт или документацию по программе.
Не инженеры, а юристы.
Вам нужно понять подходит ли человек, а ему понять подходит ли контора по «засемплированному» (выборочным) впечатлениям.
Совсем не семплировать тоже не правильно, понимаю, что-то ведь спрашивать надо…
Мне про что с ним нужно говорить...? — про фундаментальные основы.
Про абстрактные основы институтской программы? — да в том числе. с упором на те которые применимы в вашей ситуации.
«Основы институтской программы» — да, они позволяют мыслить и заниматься инженерной деятельностью и развиваться.
Суть в том, чтобы спросить чему обучиться тяжело и долго…
Но если ваша компания не занимается инженерной деятельностью (ну не Яндекс вы, не Майкрософт, не Оракл) вы не занимаетесь инженерной деятельностью с большой буквы — то нет ничего страшного и паниковать не надо.
Такие люди всё равно смогут вас чему-то научить лично и вы будете более умный с течением времени, если будете с ними общаться. Вы сами будете рости. Вам самому польза будет и вы побольше о мире узнаете. Только не стесняйтесь спрашивать их. Когда я когда-то кого-то выбирал я ориентировался на своё впечатление и всё.
Это тема как говориться очень «холиварная».AlanDenton
27.11.2015 18:01Спасибо за ответ :)
В целом с Вами согласен. Но все же нужно знать возможности того инструмента которым работаешь.
mayorovp
27.11.2015 17:56+1Мне незнакомы конструкции когда в from стоит не имя таблицы, и не select-expression, но я и работать к вам идти не собираюсь.
Тут из контекста понятно, даже есть не знать эту конструкцию.
В данной задаче, это всего лишь компактный способ задать таблицу с тестовыми данными. Подвох — не в VALUES.burzzo
27.11.2015 18:15Спасибо. А конструкция а сама синтаксически валидная с таким созданием временной таблицы на лету?
AlanDenton
27.11.2015 18:21SELECT * FROM ( SELECT val = 1 UNION ALL SELECT 2 UNION ALL SELECT 3 ) t SELECT * FROM ( VALUES(1), (2), (3) ) t (val)
Первый пример работает на всех актуальных версиях. Второй только с 2008.
Нет. Это не временная таблица. Просто возможность задать константный набор строк.

Vest
27.11.2015 16:29+1Я бы сказал, что эта статья любопытная, но теперь получается, что когда у меня стоит вопрос посчитать число записей в таблице, то я должен заморачиваться поиском нужной системной таблицы (ведь у каждого сервера она своя), потому что это быстрей?
Просто все подсказки, что я в своё время находил в интернете — люди просто использовали COUNT(*) и всё.BelAnt
27.11.2015 16:37+3Если в ваших таблицах меньше десятка миллионов записей — используйте COUNT(*) и не заморачивайтесь.
burzzo
27.11.2015 17:16Я не разрабатывал СУБД. А работал только с ansi sql только на малых таблицах 8 лет назад.
count(*) выдаёт кол-во строк в таблице влючая дубликаты и null значения — СУБД может понять запрос на кол-во строк в таблице и взять её из метафинмормации… Более того это официальная ручка для получение кол-во строчек в таблице, всякие каталоги (как я знаю) не стандартизированы.
И всё же если это не так — поменяйтся СУБД на новую версию или на совершенно другую....(правда в последнем случае возможно придётся переписывать код)Vest
28.11.2015 14:26+2Спасибо. Про дубликаты и null значения я знаю.
Мне стало любопытно, неужели сам сервер не может «подсмотреть» в системную таблицу в тех случаях, когда у меня просто примитивный SELECT COUNT(*).ComodoHacker
28.11.2015 20:15+2Не может. Дело в том, что в системном представлении (это все-таки не таблица) данные не всегда точные.

mekegi
01.12.2015 11:07Еще я знаю людей, которые любят использовать SUM вместо COUNT:
Не верю. Вот реально есть люди которые количество элементов через сумму считают?
джеки_чан.жепегAlanDenton
01.12.2015 11:42SELECT E2WP.DepID , [total] = SUM(1) , [boss_male] = SUM(CASE WHEN ET.Code LIKE N'Boss' AND E2WP.Code LIKE N'M' THEN 1 ELSE 0 END) , [boss_female] = SUM(CASE WHEN ET.Code LIKE N'Boss' AND E2WP.Code LIKE N'F' THEN 1 ELSE 0 END) FROM dbo.tbl_Emp2WP E2WP JOIN dbo.tbl_EmpType ET ON E2WP.EmpTypeID = ET.EmpTypeID GROUP BY E2WP.DepID
далеко ходить не надо :) пример из жизни… с проекта, который когда рефакторил.
AlanDenton
Добрые люди, если минусуете, то просьба говорить за что… а то получается «анонимных клуб народных мстителей» :)
defuz
Готов предположить, что минусуют за мнение о том, что одно единственное преобразование int 64 в int 32 может хоть как-то существенно повлиять на вычисление количества элементов в таблице. На фоне сканирования индекса стоимость этой операции равна нулю (о чем говорят ваши же скриншоты). Так что разницы нет практически никакой.
AlanDenton
Спасибо за комментарий. Позвольте еще раз обратить внимание на то, что мнение это касается преобразования типов в целом. Любые Compute Scalar операторы требуют ресурсов при их выполнении. Одни больше… другие меньше.