
 Надеюсь не будет откровением, если я скажу, что тестирование отыгрывает важную роль при разработке любого программного продукта. Чем качественнее тестирование, тем лучше в итоге должен выйти конечный продукт.
Надеюсь не будет откровением, если я скажу, что тестирование отыгрывает важную роль при разработке любого программного продукта. Чем качественнее тестирование, тем лучше в итоге должен выйти конечный продукт.Часто можно столкнуться с ситуацией, когда тестирование программного кода проходит очень кропотливо, а на тестирование базы данных времени уже не остается либо оно делается по остаточному принципу. Подчеркну, что это формулировка весьма сдержанная, на практике все бывает еще хуже… про базу вспоминают только когда с ней начинаются проблемы.
В итоге работа с БД может стать узким местом в производительности нашего приложения.
Чтобы избавить себя от подобного рода проблем, я предлагаю рассмотреть различные аспекты тестирования баз данных. К которым можно отнести нагрузочное тестирование и проверку производительности SQL Server в целом при помощи юнит-тестов.
Возьмем какую-нибудь абстрактную задачу. Например, мы разрабатываем движок для интернет-магазинов. У наших клиентов может быть разный объём продаж, разные типы товаров… но чтобы не нагружать лишним мы сделаем структуру базой относительно простой.
USE [master]
GO
IF DB_ID('db_sales') IS NOT NULL BEGIN
ALTER DATABASE [db_sales] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [db_sales]
END
GO
CREATE DATABASE [db_sales]
GO
USE [db_sales]
GO
CREATE TABLE dbo.Customers (
[CustomerID] INT IDENTITY PRIMARY KEY
, [FullName] NVARCHAR(150)
, [Email] VARCHAR(50) NOT NULL
, [Phone] VARCHAR(50)
)
GO
CREATE TABLE dbo.Products (
[ProductID] INT IDENTITY PRIMARY KEY
, [Name] NVARCHAR(150) NOT NULL
, [Price] MONEY NOT NULL CHECK (Price > 0)
, [Image] VARBINARY(MAX) NULL
, [Description] NVARCHAR(MAX)
)
GO
CREATE TABLE dbo.Orders (
[OrderID] INT IDENTITY PRIMARY KEY
, [CustomerID] INT NOT NULL
, [OrderDate] DATETIME NOT NULL DEFAULT GETDATE()
, [CustomerNotes] NVARCHAR(MAX)
, [IsProcessed] BIT NOT NULL DEFAULT 0
)
GO
ALTER TABLE dbo.Orders WITH NOCHECK
ADD CONSTRAINT FK_Orders_CustomerID FOREIGN KEY (CustomerID)
REFERENCES dbo.Customers (CustomerID)
GO
ALTER TABLE dbo.Orders CHECK CONSTRAINT FK_Orders_CustomerID
GO
CREATE TABLE dbo.OrderDetails
(
[OrderID] INT NOT NULL
, [ProductID] INT NOT NULL
, [Quantity] INT NOT NULL CHECK (Quantity > 0)
, PRIMARY KEY (OrderID, ProductID)
)
GO
ALTER TABLE dbo.OrderDetails WITH NOCHECK
ADD CONSTRAINT FK_OrderDetails_OrderID FOREIGN KEY (OrderID)
REFERENCES dbo.Orders (OrderID)
GO
ALTER TABLE dbo.OrderDetails CHECK CONSTRAINT FK_OrderDetails_OrderID
GO
ALTER TABLE dbo.OrderDetails WITH NOCHECK
ADD CONSTRAINT FK_OrderDetails_ProductID FOREIGN KEY (ProductID)
REFERENCES dbo.Products (ProductID)
GO
ALTER TABLE dbo.OrderDetails CHECK CONSTRAINT FK_OrderDetails_ProductID
GO
Также предположим, что наш тонкий клиент будет работать с базой посредством заранее написанных хранимых процедур. Все они достаточно простые. Вставить нового пользователя либо получить ID уже существующего:
CREATE PROCEDURE dbo.GetCustomerID
(
@FullName NVARCHAR(150)
, @Email VARCHAR(50)
, @Phone VARCHAR(50)
, @CustomerID INT OUT
)
AS BEGIN
SET NOCOUNT ON;
SELECT @CustomerID = CustomerID
FROM dbo.Customers
WHERE Email = @Email
IF @CustomerID IS NULL BEGIN
INSERT INTO dbo.Customers (FullName, Email, Phone)
VALUES (@FullName, @Email, @Phone)
SET @CustomerID = SCOPE_IDENTITY()
END
END
Разместить новый заказ:
CREATE PROCEDURE dbo.CreateOrder
(
@CustomerID INT
, @CustomerNotes NVARCHAR(MAX)
, @Products XML
)
AS BEGIN
SET NOCOUNT ON;
DECLARE @OrderID INT
INSERT INTO dbo.Orders (CustomerID, CustomerNotes)
VALUES (@CustomerID, @CustomerNotes)
SET @OrderID = SCOPE_IDENTITY()
INSERT INTO dbo.OrderDetails (OrderID, ProductID, Quantity)
SELECT @OrderID
, t.c.value('@ProductID', 'INT')
, t.c.value('@Quantity', 'INT')
FROM @Products.nodes('items/item') t(c)
END
Предположим перед нами стоит задача обеспечить минимальный отклик при выполнении запросов. На пустой базе проблем с производительностью, даже при желании, вряд ли можно ожидать. Поэтому чтобы проверить производительность наших процедур нам нужны хоть какие-то тестовые данные. Как вариант воспользуемся скриптом, чтобы сгенерировать тестовые данные для таблицы Customers:
DECLARE @obj INT = OBJECT_ID('dbo.Customers')
, @sql NVARCHAR(MAX)
, @cnt INT = 10
;WITH
E1(N) AS (
SELECT * FROM (
VALUES
(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1)
) t(N)
),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
E8(N) AS (SELECT 1 FROM E4 a, E4 b)
SELECT @sql = '
DELETE FROM ' + QUOTENAME(OBJECT_SCHEMA_NAME(@obj))
+ '.' + QUOTENAME(OBJECT_NAME(@obj)) + '
;WITH
E1(N) AS (
SELECT * FROM (
VALUES
(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1)
) t(N)
),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
E8(N) AS (SELECT 1 FROM E4 a, E4 b)
INSERT INTO ' + QUOTENAME(OBJECT_SCHEMA_NAME(@obj))
+ '.' + QUOTENAME(OBJECT_NAME(@obj)) + '(' +
STUFF((
SELECT ', ' + QUOTENAME(name)
FROM sys.columns c
WHERE c.[object_id] = @obj
AND c.is_identity = 0
AND c.is_computed = 0
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '')
+ ')
SELECT TOP(' + CAST(@cnt AS VARCHAR(10)) + ') ' +
STUFF((
SELECT '
, ' + QUOTENAME(name) + ' = ' +
CASE
WHEN TYPE_NAME(c.system_type_id) IN (
'varchar', 'char', 'nvarchar',
'nchar', 'ntext', 'text'
)
THEN (
STUFF((
SELECT TOP(
CASE WHEN max_length = -1
THEN CAST(RAND() * 10000 AS INT)
ELSE max_length
END
/
CASE WHEN TYPE_NAME(c.system_type_id) IN ('nvarchar', 'nchar', 'ntext')
THEN 2
ELSE 1
END
) '+SUBSTRING(x, (ABS(CHECKSUM(NEWID())) % 80) + 1, 1)'
FROM E8
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 1, '')
)
WHEN TYPE_NAME(c.system_type_id) = 'tinyint'
THEN '50 + CRYPT_GEN_RANDOM(10) % 50'
WHEN TYPE_NAME(c.system_type_id) IN ('int', 'bigint', 'smallint')
THEN 'CRYPT_GEN_RANDOM(10) % 25000'
WHEN TYPE_NAME(c.system_type_id) = 'uniqueidentifier'
THEN 'NEWID()'
WHEN TYPE_NAME(c.system_type_id) IN ('decimal', 'float', 'money', 'smallmoney')
THEN 'ABS(CAST(NEWID() AS BINARY(6)) % 1000) * RAND()'
WHEN TYPE_NAME(c.system_type_id) IN ('datetime', 'smalldatetime', 'datetime2')
THEN 'DATEADD(MINUTE, RAND(CHECKSUM(NEWID()))
*
(1 + DATEDIFF(MINUTE, ''20000101'', GETDATE())), ''20000101'')'
WHEN TYPE_NAME(c.system_type_id) = 'bit'
THEN 'ABS(CHECKSUM(NEWID())) % 2'
WHEN TYPE_NAME(c.system_type_id) IN ('varbinary', 'image', 'binary')
THEN 'CRYPT_GEN_RANDOM(5)'
ELSE 'NULL'
END
FROM sys.columns c
WHERE c.[object_id] = @obj
AND c.is_identity = 0
AND c.is_computed = 0
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 8, '
')
+ '
FROM E8
CROSS APPLY (
SELECT x = ''0123456789-ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz''
) t'
EXEC sys.sp_executesql @sql
Скрипт создавался с тем расчетом, чтобы генерировать случайные тестовые данные для таблиц с произвольной структурой. В итоге мы выиграли в универсальности, но проиграли в реалистичности:
CustomerID FullName Email Phone
----------- ------------------------------------ ---------------- ---------------
1 uN9UiFZ9i0pALwQXIfC628Ecw35VX9L i6D0FNBuKo9I ZStNRH8t1As2S
2 Jdi6M0BqxhE-7NEvC1 a12 UTjK28OSpTHx 7DW2HEv0WtGN
3 0UjI9pIHoyeeCEGHHT6qa2 2hUpYxc vN mqLlO 7c R5 U3ha
4 RMH-8DKAmewi2WdrvvHLh w-FIa wrb uH
5 h76Zs-cAtdIpw0eewYoWcY2toIo g5pDTiTP1Tx qBzJw8Wqn
6 jGLexkEY28Qd-OmBoP8gn5OTc FESwE l CkgomDyhKXG
7 09X6HTDYzl6ydcdrYonCAn6qyumq9 EpCkxI01tMHcp eOh7IFh
8 LGdGeF5YuTcn2XkqXT-92 cxzqJ4Y cFZ8yfEkr
9 7 Ri5J30ZtyWBOiUaxf7MbEKqWSWEvym7 0C-A7 R74Yc KDRJXX hw
10 D DzeE1AxUHAX1Bv3eglY QsZdCzPN0 RU-0zVGmU
Конечно нам никто не мешает написать запрос для генерации данных более приближенных к действительности для все той же таблицы Customers:
DECLARE @cnt INT = 10
DELETE FROM dbo.Customers
;WITH
E1(N) AS (
SELECT * FROM (
VALUES
(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1)
) t(N)
),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
E8(N) AS (SELECT 1 FROM E4 a, E4 b)
INSERT INTO dbo.Customers (FullName, Email, Phone)
SELECT TOP(@cnt)
[FullName] = txt
, [Email] = LOWER(txt) + LEFT(ABS(CHECKSUM(NEWID())), 3) + '@gmail.com'
, [Phone] =
'+38 (' + LEFT(ABS(CHECKSUM(NEWID())), 3) + ') ' +
STUFF(STUFF(LEFT(ABS(CHECKSUM(NEWID())), 9)
, 4, 1, '-')
, 7, 1, '-')
FROM E8
CROSS APPLY (
SELECT TOP(CAST(RAND(N) * 10 AS INT)) txt
FROM (
VALUES
(N'Boris_the_Blade'),
(N'John'), (N'Steve'),
(N'Mike'), (N'Phil'),
(N'Sarah'), (N'Ann'),
(N'Andrey'), (N'Liz'),
(N'Stephanie')
) t(txt)
ORDER BY NEWID()
) t
Данный стали чуть более реалистичными:
FullName Email Phone
--------------- -------------------------- -------------------
Boris_the_Blade boris_the_blade1@gmail.com +38 (146) 296-33-10
John john130@mail.com +38 (882) 688-98-59
Phil phil155@gmail.com +38 (125) 451-73-71
Mike mike188@gmail.com +38 (111) 169-59-14
Sarah sarah144@gmail.com +38 (723) 124-50-60
Andrey andrey100@gmail.com +38 (193) 160-91-48
Stephanie stephanie188@gmail.com +38 (590) 128-86-02
John john723@gmail.com +38 (194) 101-06-65
Phil phil695@gmail.com +38 (164) 180-57-37
Mike mike200@gmail.com +38 (110) 131-89-45
Однако не забываем, что у нас между таблицами существуют внешние ключи и сгенерировать согласованные данные для всех остальных сущностей выходит уже на порядок сложнее. Чтобы не придумывать решения этой проблемы предлагаю воспользоваться dbForge Data Generator for SQL Server, который позволяет генерировать осмысленные тестовые данные для таблиц в базе.

SELECT TOP 10 *
FROM dbo.Customers
ORDER BY NEWID()
CustomerID FullName Email Phone
----------- -------------- ----------------------------------- -----------------
18319 Noe Pridgen Doyle@example.com (682) 219-7793
8797 Ligia Gaddy CrandallR9@nowhere.com (623) 144-6165
14712 Marry Almond Cloutier39@nowhere.com (601) 807-2247
8280 NULL Lawrence_Z_Mortensen85@nowhere.com (710) 442-3219
8012 Noah Tyler RickieHoman867@example.com (944) 032-0834
15355 Fonda Heard AlfonsoGarcia@example.com (416) 311-5605
10715 Colby Boyd Iola_Daily@example.com (718) 164-1227
14937 Carmen Benson Dennison471@nowhere.com (870) 106-6468
13059 Tracy Cornett DaniloBills@example.com (771) 946-5249
7092 Jon Conaway Joey.Redman844@example.com (623) 140-7543
Тестовые данные готовы. Перейдем к тестированию производительности наших хранимых процедур.
У нас есть процедура GetCustomerID, которая возвращает ID клиента, если его нет, то создает соответствующую запись в таблице Customers. Попробуем ее выполнить предварительно включив показ актуального плана выполнения:
DECLARE @CustomerID INT
EXEC dbo.GetCustomerID @FullName = N'Сергей'
, @Email = 'sergeys@mail.ru'
, @Phone = '7105445'
, @CustomerID = @CustomerID OUT
SELECT @CustomerID
На плане выполнения видно, что происходит полное сканирование кластерного индекса:

И чтобы это сделать SQL Server-у приходится сделать 200 логических чтений из таблицы и все это занимает примерно 20 миллисекунд:
Table 'Customers'. Scan count 1, logical reads 200, physical reads 0, ...
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 20 ms.
Но это мы говорим про время выполнения одного запроса. Что если у нас данная хранимая процедура будет выполняться очень активно? Постоянное сканирование индекса будет снижать производительность сервера.
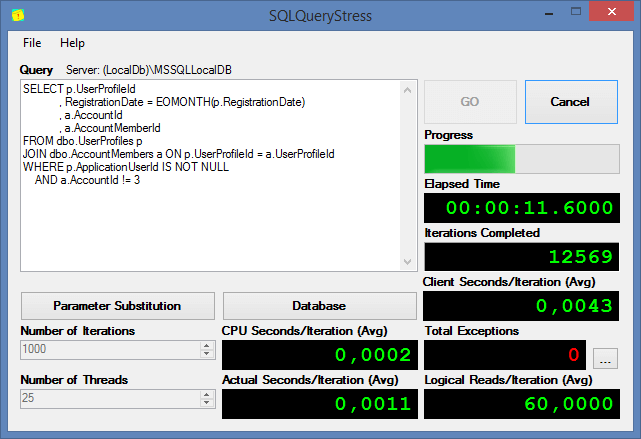
Давайте попробуем выполнить стресс тестирования нашей хранимой процедуры с помощью одной интересной опенсорсной тулы SQLQueryStress, которую разработал Adam Machanic (ссылка на GitHub).

Мы видим, что вызов 2 тысячи раз процедуры GetCustomerID в два потока заняло на сервере чуть меньше 4ти секунд. Теперь попробуем посмотреть, что будет если мы добавим индекс на поле по которому происходит наш поиск:
CREATE NONCLUSTERED INDEX IX_Email ON dbo.Customers (Email)
На плане выполнения вместо Index Scan появился Index Seek:

Сократились логические чтения и общее время выполнения:
Table 'Customers'. Scan count 1, logical reads 2, ...
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 8 ms.
Если повторить наш стресс-тест в SQLQueryStress, то мы сможем увидеть, что теперь наша процедура при многократном вызове будет меньше нагружать сервер и быстрее выполняться:

Теперь попробуем с помощью SQLQueryStress эмулировать массовое размещение заказов:
DECLARE @CustomerID INT
, @CustomerNotes NVARCHAR(MAX)
, @Products XML
SELECT TOP(1) @CustomerID = CustomerID
, @CustomerNotes = REPLICATE('a', RAND() * 100)
FROM dbo.Customers
ORDER BY NEWID()
SELECT @Products = (
SELECT [@ProductID] = ProductID
, [@Quantity] = CAST(RAND() * 10 AS INT)
FROM dbo.Products
ORDER BY ProductID
OFFSET CAST(RAND() * 1000 AS INT) ROWS
FETCH NEXT CAST(RAND() * 10 AS INT) + 1 ROWS ONLY
FOR XML PATH('item'), ROOT('items')
)
EXEC dbo.CreateOrder @CustomerID = @CustomerID
, @CustomerNotes = @CustomerNotes
, @Products = @Products

Выполнение процедуры 100 раз в два потока одновременно заняло 2,5 секунды. Давайте очистим статистику ожиданий:
DBCC SQLPERF("sys.dm_os_wait_stats", CLEAR)
Повторно запустим SQLQueryStress и посмотрим какие ожидания возникали при выполнении нашей хранимой процедуры:
wait_type wait_time
--------------------------------- -----------
WRITELOG 2.394000
PARALLEL_REDO_WORKER_WAIT_WORK 0.264000
PAGEIOLATCH_SH 0.157000
ASYNC_NETWORK_IO 0.125000
PAGEIOLATCH_UP 0.097000
PREEMPTIVE_OS_FLUSHFILEBUFFERS 0.049000
IO_COMPLETION 0.048000
PAGEIOLATCH_EX 0.043000
PREEMPTIVE_OS_WRITEFILEGATHER 0.037000
LCK_M_IX 0.033000
Видим, что на первом месте WRITELOG, который по времени примерно соответствует общему времени выполнения нашего стресс-теста. Что означает подобная задержка? Поскольку у нас каждая команда на вставку является атомарной, то после ее выполнения происходит физическая фиксация изменений в логе. Когда у нас большое число коротких транзакций, то возникает очередь, потому что операции с логом происходят синхронно в отличие от файлов данных.
В SQL Server 2014 добавилась возможность настройки отложенной записи в лог Delayed Durability, которая включается на уровне базы данных:
ALTER DATABASE db_sales SET DELAYED_DURABILITY = ALLOWED
И далее нам нужно лишь будет немного изменить хранимую процедуру:
ALTER PROCEDURE dbo.CreateOrder
(
@CustomerID INT
, @CustomerNotes NVARCHAR(MAX)
, @Products XML
)
AS BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION t
DECLARE @OrderID INT
INSERT INTO dbo.Orders (CustomerID, CustomerNotes)
VALUES (@CustomerID, @CustomerNotes)
SET @OrderID = SCOPE_IDENTITY()
INSERT INTO dbo.OrderDetails (OrderID, ProductID, Quantity)
SELECT @OrderID
, t.c.value('@ProductID', 'INT')
, t.c.value('@Quantity', 'INT')
FROM @Products.nodes('items/item') t(c)
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
END
Очистим статистику и выполним стресс-тест повторно:

Видим, что общее время выполнение сократилось в два раза, а задержки WRITELOG стали минимальными:
wait_type wait_time
-------------------------- ----------
PREEMPTIVE_OS_WRITEFILE 0.027000
PAGEIOLATCH_EX 0.024000
PAGELATCH_EX 0.020000
WRITELOG 0.014000
Теперь рассмотрим другую ситуацию, когда нужно периодически проверять производительность выполнения того или иного запроса. Использовать для этого SQLQueryStress будет уже не так удобно, потому что придётся открывать приложение, копировать туда запрос и ждать выполнения.
Можно ли это как автоматизировать?..
В 2014 году я впервые познакомился с tSQLt, который оказался весьма замечательным бесплатным фреймворком для юнит-тестирования. Давайте попробуем установить tSQLt и создать с помощью него автотест для проверки производительности нашей хранимой процедуры.
Скачаем последнюю версию tSQLt, настроим экземпляр SQL Server для работы с CLR:
EXEC sys.sp_configure 'clr enabled', 1
RECONFIGURE
GO
ALTER DATABASE [db_sales] SET TRUSTWORTHY ON
GO
После этого выполним из архива скрипт tSQLt.class.sql на нашей базе. Скрипт создаст собственную схему tSQLt, CLR сборку и множество скриптовых объектов. Часть процедур будут содержать префикс Private_ которые предназначены для внутреннего использования самим фреймворком.
Если все правильно установилось, то в Output мы получим следующее сообщение:
+-----------------------------------------+
| |
| Thank you for using tSQLt. |
| |
| tSQLt Version: 1.0.5873.27393 |
| |
+-----------------------------------------+
Теперь создадим схему в которой будем создавать автотесты:
USE [db_sales]
GO
CREATE SCHEMA [Performance]
GO
EXEC sys.sp_addextendedproperty @name = N'tSQLt.Performance'
, @value = 1
, @level0type = N'SCHEMA'
, @level0name = N'Performance'
GO
Нужно обратить внимание, что Extended Property определяет принадлежность того или иного объекта к функциональности tSQLt.
Создаем тест в схеме Performance обязательно указывая префикс test в имени теста:
CREATE PROCEDURE [Performance].[test ProcTimeExecution]
AS BEGIN
SET NOCOUNT ON;
EXEC tSQLt.Fail 'TODO: Implement this test.'
END
Пробуем выполнить созданный автотест. Для этого мы можем либо выполнить:
EXEC tSQLt.RunAll
Либо явно указать схему:
EXEC tSQLt.Run 'Performance'
или конкретный тест:
EXEC tSQLt.Run 'Performance.test ProcTimeExecution'
Если требуется запустить последний выполненный тест, то можно вызвать Run без параметров:
EXEC tSQLt.Run
После выполнения одной из команд выше получим следующую информацию:
[Performance].[test ProcTimeExecution] failed: (Failure) TODO: Implement this test.
+----------------------+
|Test Execution Summary|
+----------------------+
|No|Test Case Name |Dur(ms)|Result |
+--+--------------------------------------+-------+-------+
|1 |[Performance].[test ProcTimeExecution]| 0|Failure|
Попробуем изменить в автотесте содержимое на что-то более полезное. Например, возьмем процедуру GetUnprocessedOrders, которая возвращает список необработанных заказов:
CREATE PROCEDURE dbo.GetUnprocessedOrders
AS BEGIN
SET NOCOUNT ON;
SELECT
o.OrderID
, o.OrderDate
, c.FullName
, c.Email
, c.Phone
, OrderSum = (
SELECT SUM(p.Price + d.Quantity)
FROM dbo.OrderDetails d
JOIN dbo.Products p ON d.ProductID = p.ProductID
WHERE d.OrderID = o.OrderID
)
FROM dbo.Orders o
JOIN dbo.Customers c ON o.CustomerID = c.CustomerID
WHERE o.IsProcessed = 0
END
и создадим автотест, который будет выполнять процедуру n-ое количество раз и завершаться с ошибкой, если среднее время выполнения больше заданного порогового значения.
ALTER PROCEDURE [Performance].[test ProcTimeExecution]
AS BEGIN
SET NOCOUNT ON;
DECLARE @time DATETIME
, @duration BIGINT = 0
, @cnt TINYINT = 10
WHILE @cnt > 0 BEGIN
SET @time = GETDATE()
EXEC dbo.GetUnprocessedOrders
SET @duration += DATEDIFF(MILLISECOND, @time, GETDATE())
SET @cnt -= 1
END
IF @duration / 10 > 100 BEGIN
DECLARE @txt NVARCHAR(MAX) = 'High average execution time: '
+ CAST(@duration / 10 AS NVARCHAR(10)) + ' ms'
EXEC tSQLt.Fail @txt
END
END
Выполняем автотест:
EXEC tSQLt.Run 'Performance'
И получаем следующее сообщение:
[Performance].[test ProcTimeExecution] failed: (Error) High execution time: 161 ms
+----------------------+
|Test Execution Summary|
+----------------------+
|No|Test Case Name |Dur(ms)|Result|
+--+--------------------------------------+-------+------+
|1 |[Performance].[test ProcTimeExecution]| 1620|Error |
Попробуем оптимизировать запрос и сделать так чтобы тест проходил. Вначале посмотрим на план выполнения:

Видим, что проблема в часто обращении к кластерному индексу таблицы Products. Большое число логических чтений тоже подтверждают это утверждение:
Table 'Customers'. Scan count 1, logical reads 200, ...
Table 'Orders'. Scan count 1, logical reads 3886, ...
Table 'Products'. Scan count 0, logical reads 73607, ...
Table 'OrderDetails'. Scan count 1, logical reads 235, ...
Как ситуацию можно исправить? Можно добавить некластерный индекс и включить туда поле Price, сделать предварительный расчет значений в отдельной таблице, либо как вариант создать агрегированное индексное представление:
CREATE VIEW dbo.vwOrderSum
WITH SCHEMABINDING
AS
SELECT d.OrderID
, OrderSum = SUM(p.Price + d.Quantity)
, OrderCount = COUNT_BIG(*)
FROM dbo.OrderDetails d
JOIN dbo.Products p ON d.ProductID = p.ProductID
GROUP BY d.OrderID
GO
CREATE UNIQUE CLUSTERED INDEX IX_OrderSum
ON dbo.vwOrderSum (OrderID)
И изменить хранимую процедуру:
ALTER PROCEDURE dbo.GetUnprocessedOrders
AS BEGIN
SET NOCOUNT ON;
SELECT
o.OrderID
, o.OrderDate
, c.FullName
, c.Email
, c.Phone
, s.OrderSum
FROM dbo.Orders o
JOIN dbo.Customers c ON o.CustomerID = c.CustomerID
JOIN dbo.vwOrderSum s WITH(NOEXPAND) ON o.OrderID = s.OrderID
WHERE o.IsProcessed = 0
END
Хинт NOEXPAND желательно указывать, чтобы заставить оптимизатор всегда использовать индекс из нашего представления. Кроме того, чтобы сократить количество логических чтений из Orders можно создать фильтрованный индекс:
CREATE NONCLUSTERED INDEX IX_UnProcessedOrders
ON dbo.Orders (OrderID, CustomerID, OrderDate)
WHERE IsProcessed = 0
Теперь при выполнении нашей хранимой процедуры будет использоваться более простой план:

Логический чтений станет меньше:
Table 'Customers'. Scan count 1, logical reads 200, ...
Table 'Orders'. Scan count 1, logical reads 21, ...
Table 'vwOrderSum'. Scan count 1, logical reads 44, ...
Выполнение хранимой процедуры сократиться и наш тест будет выполняться успешно:
|No|Test Case Name |Dur(ms)|Result |
+--+--------------------------------------+-------+-------+
|1 |[Performance].[test ProcTimeExecution]| 860|Success|
Можно сказать, что мы справились. Оптимизировали все узкие места и сделали реально классный продукт. Но посмотрим правде в глаза. Данные имеют свойство накапливаться, а SQL Server генерирует план выполнения исходя из ожидаемого числа строк. Сейчас мы провели тестирование на вырост, однако не гарантии, что через год работы план выполнения будет таким же эффективным, не изменится схема, кто-то по ошибке не удалит нужный индекс и так далее… Поэтому крайне важно запускать подобного рода автотесты на регулярной основе, чтобы оперативно выявлять проблемы.
Теперь давайте посмотрим, что еще такого полезного можно сделать с помощью юнит-тестов.
Например, мы можем посмотреть во всех планах выполнения, есть ли секция MissingIndexGroup. Если она есть, то SQL Server считает, что для определенного запроса не хватает индекса:
CREATE PROCEDURE [Performance].[test MissingIndexes]
AS BEGIN
SET NOCOUNT ON
DECLARE @msg NVARCHAR(MAX)
, @rn INT
SELECT t.text
, p.query_plan
, q.total_worker_time / 100000.
FROM (
SELECT TOP 100 *
FROM sys.dm_exec_query_stats
ORDER BY total_worker_time DESC
) q
CROSS APPLY sys.dm_exec_sql_text(q.sql_handle) t
CROSS APPLY sys.dm_exec_query_plan(q.plan_handle) p
WHERE p.query_plan.exist('//*:MissingIndexGroup') = 1
SET @rn = @@ROWCOUNT
IF @rn > 0 BEGIN
SET @msg = 'Missing index in ' + CAST(@rn AS VARCHAR(10)) + ' queries'
EXEC tSQLt.Fail @msg
END
END
Также можно автоматизировать поиск неиспользуемых индексов. Делается это все достаточно просто – достаточно узнать статистику использования того или иного индекса в dm_db_index_usage_stats:
CREATE PROCEDURE [Performance].[test UnusedUndexes]
AS BEGIN
DECLARE @tables INT
, @indexes INT
, @msg NVARCHAR(MAX)
SELECT @indexes = COUNT(*)
, @tables = COUNT(DISTINCT o.[object_id])
FROM sys.objects o
CROSS APPLY (
SELECT s.index_id
, index_usage = s.user_scans + s.user_lookups + s.user_seeks
, usage_percent =
(s.user_scans + s.user_lookups + s.user_seeks) * 100.
/
NULLIF(SUM(s.user_scans + s.user_lookups + s.user_seeks) OVER (), 0)
, index_count = COUNT(*) OVER ()
FROM sys.dm_db_index_usage_stats s
WHERE s.database_id = DB_ID()
AND s.[object_id] = o.[object_id]
) t
WHERE o.is_ms_shipped = 0
AND o.[schema_id] != SCHEMA_ID('tSQLt')
AND o.[type] = 'U'
AND (
(t.usage_percent < 5 AND t.index_usage > 100 AND t.index_count > 1)
OR
t.index_usage = 0
)
IF @tables > 0 BEGIN
SET @msg = 'Database contains ' + CAST(@indexes AS VARCHAR(10))
+ ' unused indexes in ' + CAST(@tables AS VARCHAR(10)) + ' tables'
EXEC tSQLt.Fail @msg
END
END
При разработке больших и сложных систем, часто можно встретить ситуации, когда таблицу добавили в систему, вставили туда данные и забыли о ее существовании.
Как определить такие таблицы? Например, на них нет ссылок, выборка из этих таблиц с момента старта сервера не происходила при условии того, что сервер работает больше недели. Условия относительные и их можно для каждой конкретной задачи модифицировать.
CREATE PROCEDURE [Performance].[test UnusedTables]
AS BEGIN
SET NOCOUNT ON
DECLARE @msg NVARCHAR(MAX)
, @rn INT
, @txt NVARCHAR(1000) = N'Starting up database ''' + DB_NAME() + '''.'
DECLARE @database_start TABLE (
log_date SMALLDATETIME,
spid VARCHAR(50),
msg NVARCHAR(4000)
)
INSERT INTO @database_start
EXEC sys.xp_readerrorlog 0, 1, @txt
SELECT o.[object_id]
, [object_name] = SCHEMA_NAME(o.[schema_id]) + '.' + o.name
FROM sys.objects o
WHERE o.[type] = 'U'
AND o.is_ms_shipped = 0
AND o.[schema_id] != SCHEMA_ID('tSQLt')
AND NOT EXISTS(
SELECT *
FROM sys.dm_db_index_usage_stats s
WHERE s.database_id = DB_ID()
AND s.[object_id] = o.[object_id]
AND (
s.user_seeks > 0
OR s.user_scans > 0
OR s.user_lookups > 0
OR s.user_updates > 0
)
)
AND NOT EXISTS(
SELECT *
FROM sys.sql_expression_dependencies s
WHERE o.[object_id] IN (s.referencing_id, s.referenced_id)
)
AND EXISTS(
SELECT 1
FROM @database_start t
HAVING MAX(t.log_date) < DATEADD(DAY, -7, GETDATE())
)
SET @rn = @@ROWCOUNT
IF @rn > 0 BEGIN
SET @msg = 'Database contains ' + CAST(@rn AS VARCHAR(10)) + ' unused tables'
EXEC tSQLt.Fail @msg
END
END
И подобных тестов, как я привел выше, можно создать еще много…
В качестве выводов, я честно не знаю что можно еще добавить к тому, что было написано ранее. Наверное только одно. Попробуйте tSQLt и SQLQueryStress. Эти продукты полностью бесплатны и на практике выручали меня не раз при нагрузочном тестировании SQL Server и оптимизации производительности на сервере.
Небольшой оффтопик
Еще забыл добавить о ближайших мероприятиях по SQL Server. В 26 ноября в Днепре будет проходить SQL Saturday 2016 Dnepr — однодневный бесплатный тренинг для разработчиков и тех кто хочет узнать что-то новое по SQL Server. Лично я себе красным карандашом уже отметил эту дату, поэтому приглашаю всех кто может посетить это мероприятие.
Комментарии (10)

AlanDenton
19.09.2016 13:19+1Рад, что Вам понравилось. Если народу будет интересно, потом планировал написать пост как можно с помощью запросов к системным представлениям определять узкие места в конфигурации сервера и автоматизировать проверку с помощью tSQLt.

fishca
19.09.2016 16:10как можно с помощью запросов к системным представлениям определять узкие места в конфигурации сервера и автоматизировать проверку с помощью tSQLt
Это было бы архиполезно! Двумя руками за! Ждем.
AlexLeonov
19.09.2016 16:43Пост безумно интересный, спасибо.
Но уж очень режет глаз
SQL Server
вместо MS SQL Server. Задевает этот нелепый (и непроизвольный) снобизм, как будто бы других серверов, кроме MS, на свете нет!


Vicking
20.09.2016 16:25+1Спасибо за статью. Нашел у себя пару проблем. Статью однозначно в закладки.
AlanDenton
20.09.2016 16:39Спасибо и Вам что прочитали. Можно вопрос… а в чем нашли проблемы? Не во всех ситуациях запросы будут возвращать 100% адекватную информацию. Например, MissingIndexGroup секция строится на основе предположений оптимизатора и не всегда предлагает самый оптимальный индекс. Очень рекомендую взглянуть на DEFAULT TRACE.
G-M-A-X
20.09.2016 18:06Хм, но многие не то что процедуры вручную не пишут, но и запросы не пишут и не следят за индексами.
Они надеются на фреймворки :)
Аргументируют это тем, что бизнесу дешевле оплатить сервера, чем работу программиста. :)
П.С.
А по mysql можете написать? :)AlanDenton
21.09.2016 09:02Что сказать… полностью поддерживаю Вашу точку зрения. На текущем проекте использовался Entity Framework, который в отдельных случаях такую ересь пытался выполнить на сервере. Неявное преобразование типов, Index Scan вместо Index Seek при выборе единичного значения, и прочие радости жизни… Вычистили все проблемные места, но осадок от использования подхода Code First остался при использовании на больших объемах данных.
Про MySQL не планировал, потому что мало с ним работал. Однако, в планах сделать еще большой пост про типичные ошибки при написании запросов на T-SQL.
fishca
Спасибо, однозначно в закладки!